I built a ChatGPT plugin to answer questions about data hosted in Datasette
24th March 2023
Yesterday OpenAI announced support for ChatGPT plugins. It’s now possible to teach ChatGPT how to make calls out to external APIs and use the responses to help generate further answers in the current conversation.
My open source project Datasette makes it easy to host data online, and already provides a JSON API for executing SQLite queries.
I know from past experiments that GPT3/4 are able to construct SQLite-compatible SQL queries. I figured that Datasette and ChatGPT would be a perfect combination.
Datasette itself has a plugin system which can be used to add new features, including the new URL routes needed by the ChatGPT plugin specification.
So I built datasette-chatgpt-plugin—a Datasette plugin that turns a Datasette instance into a ChatGPT plugin, and allows you to ask questions of your own data directly from ChatGPT.
datasette-chatgpt-plugin
The new plugin can be installed using datasette install datasette-chatgpt-plugin. It’s only useful if it’s deployed online though, since ChatGPT needs to be able to access it.
I’m running it on the official datasette.io website—which is itself a customized instance of Datasette. The plugin provides access to the datasette.io/content database, which has tables for things like Datasette news, releases and available plugins.
Here’s a video demo showing some of the things ChatGPT can do with the plugin installed.
I’ve only just got this working, but here’s a query that illustrates how effective it can be. I asked:
What are the most popular plugins?
It gave me back the following:
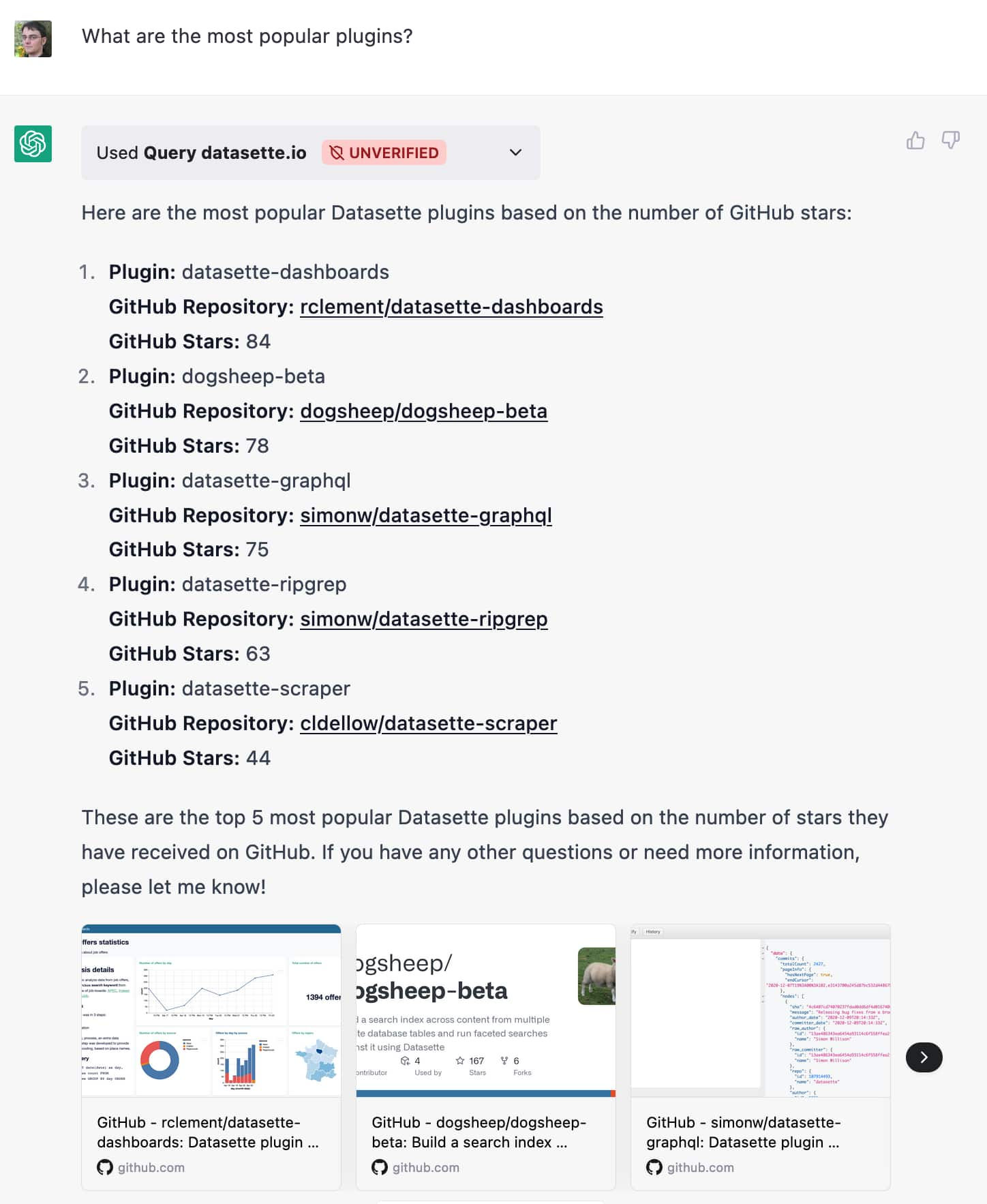
Clicking the little arrow next to “Used query datasette.io” reveals the API call it made, exposing the SQL query it generated:
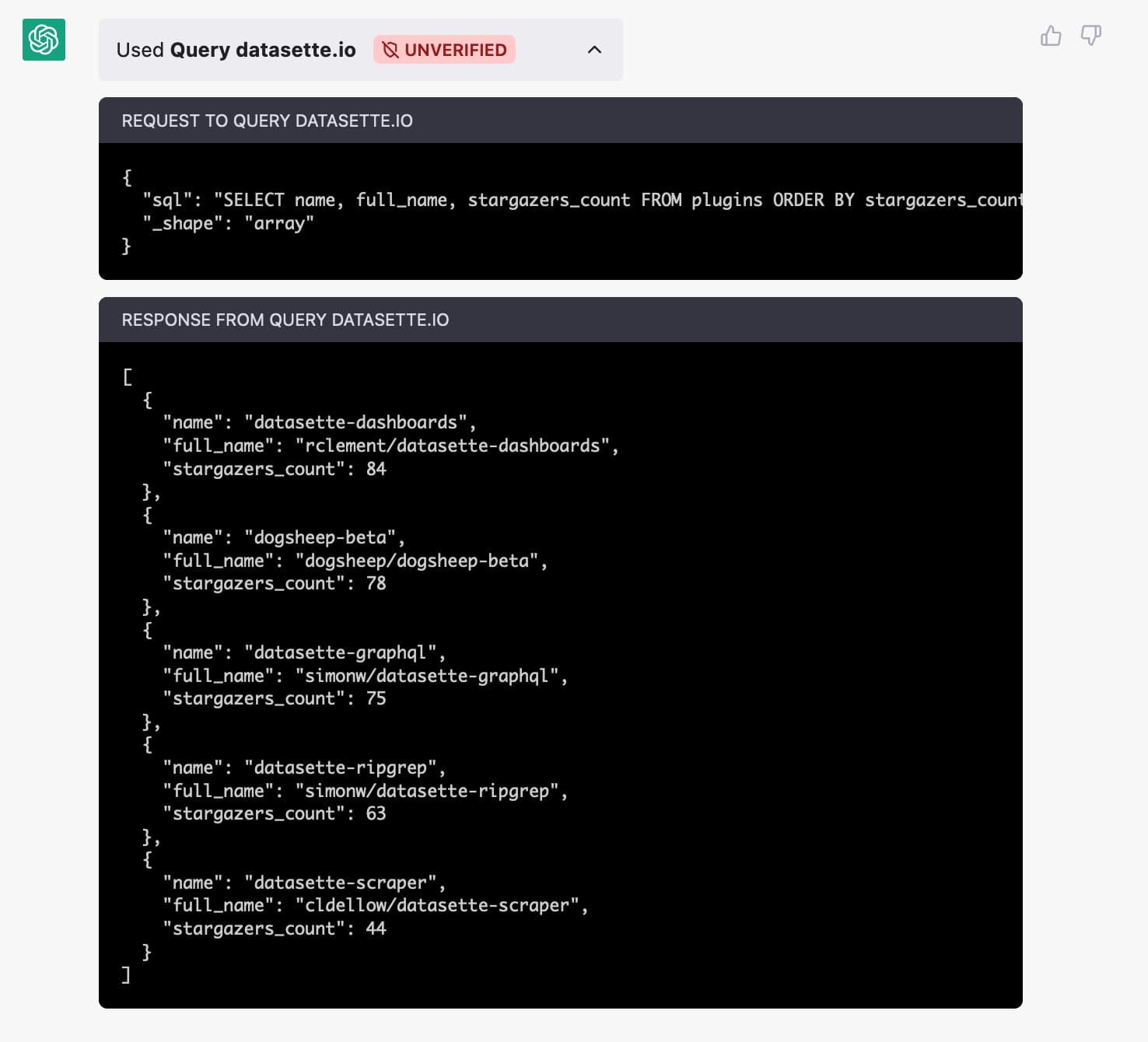
The API call it made was:
{
"sql": "SELECT name, full_name, stargazers_count FROM plugins ORDER BY stargazers_count DESC LIMIT 5",
"_shape": "array"
}You can try that query in Datasette here—or here’s the JSON version.
Here’s the JSON that was returned:
[
{
"name": "datasette-dashboards",
"full_name": "rclement/datasette-dashboards",
"stargazers_count": 84
},
{
"name": "dogsheep-beta",
"full_name": "dogsheep/dogsheep-beta",
"stargazers_count": 78
},
{
"name": "datasette-graphql",
"full_name": "simonw/datasette-graphql",
"stargazers_count": 75
},
{
"name": "datasette-ripgrep",
"full_name": "simonw/datasette-ripgrep",
"stargazers_count": 63
},
{
"name": "datasette-scraper",
"full_name": "cldellow/datasette-scraper",
"stargazers_count": 44
}
]ChatGPT turns the JSON into a nice human-readable reply. It also knows how to generate thumbnails from og:image metadata, adding a gallery of those to the end of the reply.
How the plugin works
Building ChatGPT plugins, like so much involving Large Language Models, is both really easy and deceptively complicated.
You give ChatGPT a short, human-ish language description of your plugin and how to use it, and a machine-readable OpenAPI schema with the details of the API.
And that’s it! The language model figures out everything else.
Datasette exposes a JSON API that speaks SQL. ChatGPT knows SQL already, so all my prompt needed to do was give it some hints—in particular tell it to use the SQLite dialect.
Here’s the prompt I’m using at the moment:
Run SQLite queries against a database hosted by Datasette. Datasette supports most SQLite syntax but does not support PRAGMA statements. Use
select group_concat(sql, ';') from sqlite_masterto see the list of tables and their columns Useselect sql from sqlite_master where name = 'table_name'to see the schema for a table, including its columns. Instead ofPRAGMA table_info(table_name)useselect * from pragma_table_info('table_name'). PRAGMA statements are not allowed.select * from pragma_table_info('table_name')is allowed.
In my early experiments it kept trying to run PRAGMA table_info(), hence my increasingly frustrated prompts about that!
With hindsight, I don’t think it was re-fetching my prompt while I was developing the plugin, so those repeated warnings probably aren’t needed.
Your application needs to serve two additional pages—a plugin description at /.well-known/ai-plugin.json and an OpenAI schema linked to by that description.
You can see those two pages for my datasette.io deployment here:
The ai-plugin.json file currently looks like this:
{
"schema_version": "v1",
"name_for_model": "datasette_datasette_io_3c330f",
"name_for_human": "Query datasette.io",
"description_for_model": "Run SQLite queries against a database hosted by Datasette.\nDatasette supports most SQLite syntax but does not support PRAGMA statements.\nUse `select group_concat(sql, ';') from sqlite_master` to see the list of tables and their columns\nUse `select sql from sqlite_master where name = 'table_name'` to see the schema for a table, including its columns.\nInstead of `PRAGMA table_info(table_name)` use `select * from pragma_table_info('table_name')`\nPRAGMA statements are not allowed. `select * from pragma_table_info('table_name') is allowed.",
"description_for_human": "Run SQL against data in Datasette.",
"auth": {
"type": "none"
},
"api": {
"type": "openapi",
"url": "https://datasette.io/-/chatgpt-openapi-schema.yml",
"has_user_authentication": false
},
"logo_url": "https://avatars.githubusercontent.com/u/126964132?s=400&u=08b2ed680144a4feb421308f09e5f3cc5876211a&v=4",
"contact_email": "hello@contact.com",
"legal_info_url": "hello@legal.com"
}Since they use that `.well-known` URL format, it’s possible to find them for other services. Here’s ai-plugin.json for Wolfram Alpha.
And the chatgpt-openapi-schema.yml file contains this:
openapi: 3.0.1
info:
title: Datasette API
description: Execute SQL queries against a Datasette database and return the results as JSON
version: 'v1'
servers:
- url: https://datasette.io
paths:
/content.json:
get:
operationId: query
summary: Execute a SQLite SQL query against the content database
description: Accepts SQLite SQL query, returns JSON. Does not allow PRAGMA statements.
parameters:
- name: sql
in: query
description: The SQL query to be executed
required: true
schema:
type: string
- name: _shape
in: query
description: The shape of the response data. Must be "array"
required: true
schema:
type: string
enum:
- array
responses:
'200':
description: Successful SQL results
content:
application/json:
schema:
type: array
items:
type: object
'400':
description: Bad request
'500':
description: Internal server errorI haven’t actually used OpenAPI schemas before... so I got ChatGPT to write the initial version for me, using the following prompt:
Write an OpenAPI schema explaining the https://latest.datasette.io/fixtures.json?sql=select+*+from+facetable&_shape=array GET API which accepts SQL and returns an array of JSON objects
For a detailed account of how I built the plugin, take a look at my notes in issue #1 in the repository.
I prototyped the initial plugin using Glitch, because that’s the fastest way I know to get a live-on-the-web application which constantly reflects new changes to the code. This made iterating much faster... on the OpenAPI schema at least. As far as I can tell ChatGPT only loads that ai-plugin.json file once, which is frustrating because it means you have to deploy a new copy of the application to get it to re-read that crucial prompt.
I ended up doing most of my prompt engineering in ChatGPT itself though—I could tell it "Instead of PRAGMA table_info(table_name) use select * from pragma_table_info('table_name')" and then re-try my previous question to see if the new instruction fixed any problems I was having.
The bad news: it can hallucinate
Here’s the bad news. I’ve been playing with this for only a short time, so I’m still exploring its abilities. I’ve already had a couple of instances of it hallucinating answers despite having looked them up in the database first.
I’m hoping I can address this somewhat with further prompt engineering—“only use information returned from the query to answer the question” kind of stuff. But I can’t guarantee I’ll be able to suppress this entirely, which for a database querying tool is an extremely serious problem.
More about this, including some examples, in issue #2 in the repo.
My current theory is that this relates to length limits. I’ve noticed it happens when the query returns a large amount of data—the full content of tutorials for example. I think ChatGPT is silently truncating that data to fit the token limit, and is then hallucinating new information to fill in for what ends up missing.
Want to try this with your own data?
The ChatGPT plugin system isn’t available outside of the preview yet, but when it is I’ll be adding this functionality to my Datasette Cloud SaaS platform, for people who don’t want to install and run Datasette themselves.
You can sign up for the Datasette Cloud preview here if you’d like to learn more.
Previous experiments
I’ve experimented with variants of this pattern myself before: it turns out it’s surprisingly easy to enhance the capabilities of a large language model by providing it access to additional tools. Here’s some previous work:
- How to implement Q&A against your documentation with GPT3, embeddings and Datasette describes a pattern of searching an existing corpus for relevant information and appending that to the prompt in order to answer a user’s question.
- A simple Python implementation of the ReAct pattern for LLMs shows a more advanced pattern, similar to the new ChatGPT plugins mechanism, where multiple tools can be registered with the model and used to generate responses. It’s based on the paper ReAct: Synergizing Reasoning and Acting in Language Models.
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026