Blogmarks
Filters: Sorted by date
jo (via) Neat little C utility (available via brew/apt-get install etc) for conveniently outputting JSON from a shell: “jo -p name=jo n=17 parser=false” will output a JSON object with string, integer and boolean values, and you can nest it to create nested objects. Looks very handy.
Think before you speak: Training Language Models With Pause Tokens. Another example of how much low hanging fruit remains to be discovered in basic Large Language Model research: this team from Carnegie Mellon and Google Research note that, since LLMs get to run their neural networks once for each token of input and output, inserting “pause” tokens that don’t output anything at all actually gives them extra opportunities to “think” about their output.
An Interactive Intro to CRDTs (via) Superb interactive essay by Jake Lazaroff, providing a very clear explanation of how the fundamental mechanisms behind CRDTs (Conflict-free Replicated Data Types) work. The interactive explanatory demos are very neatly designed and a lot of fun to play with.
Translating Latin demonology manuals with GPT-4 and Claude (via) UC Santa Cruz history professor Benjamin Breen puts LLMs to work on historical texts. They do an impressive job of translating flaky OCRd text from 1599 Latin and 1707 Portuguese.
“It’s not about getting the AI to replace you. Instead, it’s asking the AI to act as a kind of polymathic research assistant to supply you with leads.”
New sqlite3 CLI tool in Python 3.12. The newly released Python 3.12 includes a SQLite shell, which you can open using “python -m sqlite3”—handy for when you’re using a machine that has Python installed but no sqlite3 binary.
I installed Python 3.12 for macOS using the official installer from Python.org and now “/usr/local/bin/python3 -m sqlite3” gives me a SQLite 3.41.1 shell—a pleasantly recent version from March 2023 (the latest SQLite is 3.43.1, released in September).
Weird A.I. Yankovic, a cursed deep dive into the world of voice cloning. Andy Baio reports back on his investigations into the world of AI voice cloning.
This is no longer a niche interest. There’s a Discord with 500,000 members sharing tips and tricks on cloning celebrity voices in order to make their own cover songs, often built with Google Colab using models distributed through Hugging Face.
Andy then makes his own, playing with the concept “What if every Weird Al song was the original, and every other artist was covering his songs instead?”
I particularly enjoyed Madonna’s cover of “Like A Surgeon”, Lady Gaga’s “Perform This Way” and Lorde’s “Foil”.
jq 1.7. First new release of jq in five years! The project has moved from a solo maintainer to a new team with a dedicated GitHub organization. A ton of new features in this release—I’m most excited about the new pick(.key1, .key2.nested) builtin for emitting a selected subset of the incoming objects, and the --raw-output0 option which outputs zero byte delimited lists, designed to be piped to “xargs -0”.
Database Migrations. Vadim Kravcenko provides a useful, in-depth description of the less obvious challenges of applying database migrations successfully. Vadim uses and likes Django’s migrations (as do I) but notes that running them at scale still involves a number of thorny challenges.
The biggest of these, which I’ve encountered myself multiple times, is that if you want truly zero downtime deploys you can’t guarantee that your schema migrations will be deployed at the exact same instant as changes you make to your application code.
This means all migrations need to be forward-compatible: you need to apply a schema change in a way that your existing code will continue to work error-free, then ship the related code change as a separate operation.
Vadim describes what this looks like in detail for a number of common operations: adding a field, removing a field and changing a field that has associated business logic implications. He also discusses the importance of knowing when to deploy a dual-write strategy.
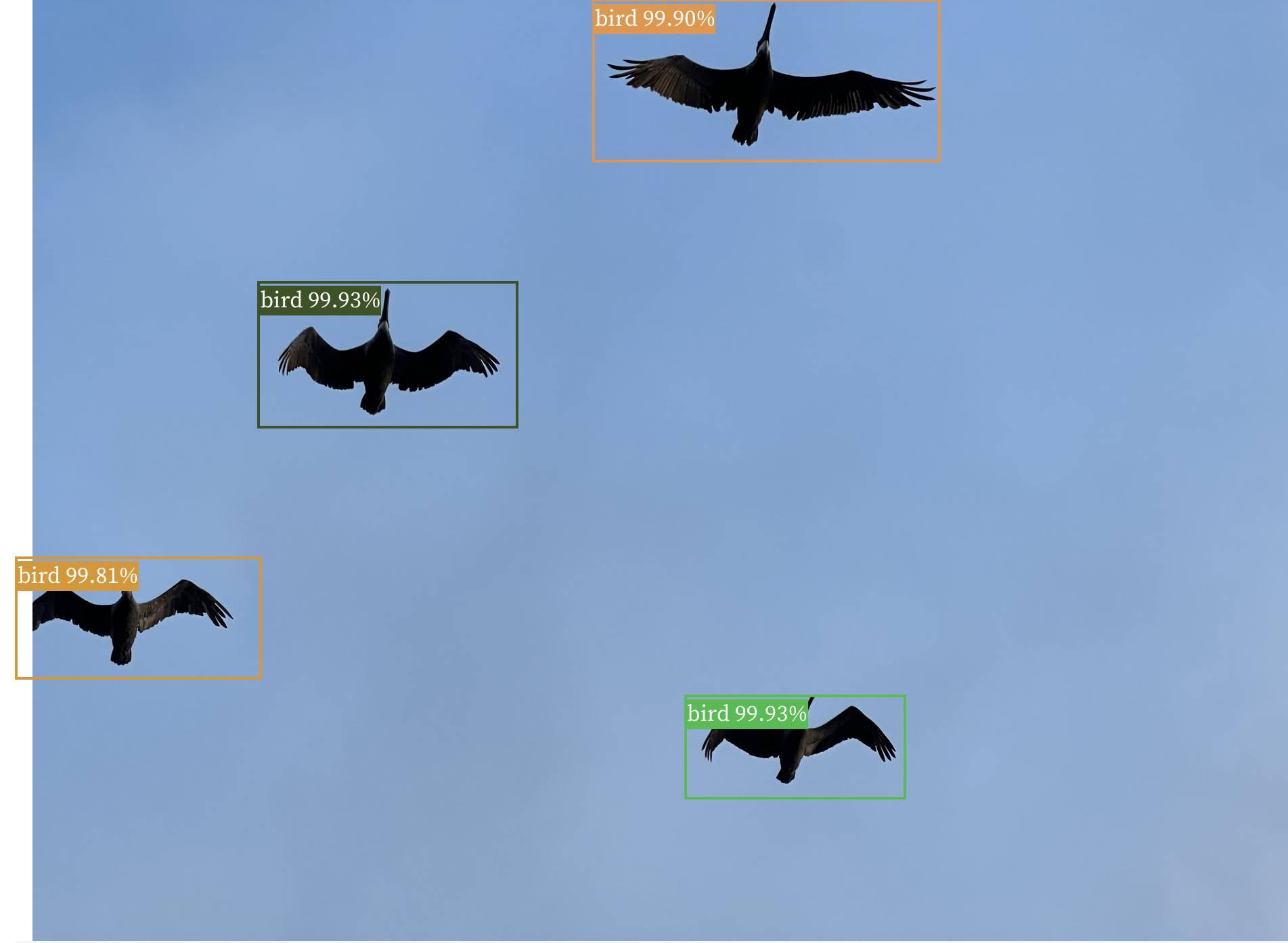
Observable notebook: Detect objects in images (via) I built an Observable notebook that uses Transformers.js and the Xenova/detra-resnet-50 model to detect objects in images, entirely running within your browser. You can select an image using a file picker and it will show you that image with bounding boxes and labels drawn around items within it. I have a demo image showing some pelicans flying ahead, but it works with any image you give it - all without uploading that image to a server.
Get Your Mac Python From Python.org. Glyph recommends the official Python installer from python.org as the best way to get started with a Python environment on macOS—with require-virtualenv = true in your ~/.pip/pip.conf to help avoid accidentally installing global packages.
Meta in Myanmar, Part I: The Setup. The first in a series by Erin Kissane explaining in detail exactly how things went so incredibly wrong with Facebook in Myanmar, contributing to a genocide ending hundreds of thousands of lives. This is an extremely tough read.
Draggable objects (via) Amit Patel’s detailed write-up of a small but full-featured JavaScript function for creating draggable objects, with support for both mouse and touch devices “using browser features that are widely supported since 2020”.
Getting started with the Datasette Cloud API. I wrote an introduction to the Datasette Cloud API for the company blog, with a tutorial showing how to use Python and GitHub Actions to import data from the Federal Register into a table in Datasette Cloud, then configure full-text search against it.
Google was accidentally leaking its Bard AI chats into public search results. I’m quoted in this piece about yesterday’s Bard privacy bug: it turned out the share URL and “Let anyone with the link see what you’ve selected” feature wasn’t correctly setting a noindex parameter, and so some shared conversations were being swept up by the Google search crawlers. Thankfully this was a mistake, not a deliberate design decision, and it should be fixed by now.
Finding Bathroom Faucets with Embeddings. Absolutely the coolest thing I’ve seen someone build on top of my LLM tool so far: Drew Breunig is renovating a bathroom and needed a way to filter through literally thousands of options for facet taps. He scraped 20,000 images of fixtures from a plumbing supply site and used LLM to embed every one of them via CLIP... and now he can ask for “faucets that look like this one”, or even run searches for faucets that match “Gawdy” or “Bond Villain” or “Nintendo 64”. Live demo included!
Optimizing for Taste. David Cramer’s detailed explanation as to why his company Sentry mostly avoids A/B testing. David wrote this as an internal blog post originally, but is now sharing it with the world. I found myself nodding along vigorously as I read this—lots of astute observations here.
I particularly appreciated his closing note: “The strength of making a decision is making it. You can always make a new one later. Choose the obvious path forward, and if you don’t see one, find someone who does.”
Rethinking the Luddites in the Age of A.I. I’ve been staying way clear of comparisons to Luddites in conversations about the potential harmful impacts of modern AI tools, because it seemed to me like an offensive, unproductive cheap shot.
This article has shown me that the comparison is actually a lot more relevant—and sympathetic—than I had realized.
In a time before labor unions, the Luddites represented an early example of a worker movement that tried to stand up for their rights in the face of transformational, negative change to their specific way of life.
“Knitting machines known as lace frames allowed one employee to do the work of many without the skill set usually required” is a really striking parallel to what’s starting to happen with a surprising array of modern professions already.
Batch size one billion: SQLite insert speedups, from the useful to the absurd (via) Useful, detailed review of ways to maximize the performance of inserting a billion integers into a SQLite database table.
Upsert in SQL (via) Anton Zhiyanov is currently on a one-man quest to write detailed documentation for all of the fundamental SQL operations, comparing and contrasting how they work across multiple engines, generally with interactive examples.
Useful tips in here on why “insert... on conflict” is usually a better option than “insert or replace into” because the latter can perform a delete and then an insert, firing triggers that you may not have wanted to be fired.
Geospatial SQL queries in SQLite using TG, sqlite-tg and datasette-sqlite-tg. Alex Garcia built sqlite-tg—a SQLite extension that uses the brand new TG geospatial library to provide a whole suite of custom SQL functions for working with geospatial data.
Here are my notes on trying out his initial alpha releases. The extension already provides tools for converting between GeoJSON, WKT and WKB, plus the all important tg_intersects() function for testing if a polygon or point overlap each other.
It’s pretty useful already. Without any geospatial indexing at all I was still able to get 700ms replies to a brute-force point-in-polygon query against 150MB of GeoJSON timezone boundaries stored as JSON text in a table.
A Hackers’ Guide to Language Models. Jeremy Howard’s new 1.5 hour YouTube introduction to language models looks like a really useful place to catch up if you’re an experienced Python programmer looking to start experimenting with LLMs. He covers what they are and how they work, then shows how to build against the OpenAI API, build a Code Interpreter clone using OpenAI functions, run models from Hugging Face on your own machine (with NVIDIA cards or on a Mac) and finishes with a demo of fine-tuning a Llama 2 model to perform text-to-SQL using an open dataset.
Should you give candidates feedback on their interview performance? Jacob provides a characteristically nuanced answer to the question of whether you should provide feedback to candidates you have interviewed. He suggests offering the candidate the option to email asking for feedback early in the interview process to avoid feeling pushy later on, and proposes the phrase “you failed to demonstrate...” as a useful framing device.
TG: Polygon indexing (via) TG is a brand new geospatial library by Josh Baker, author of the Tile38 in-memory spatial server (kind of a geospatial Redis). TG is written in pure C and delivered as a single C file, reminiscent of the SQLite amalgamation.
TG looks really interesting. It implements almost the exact subset of geospatial functionality that I find most useful: point-in-polygon, intersect, WKT, WKB, and GeoJSON—all with no additional dependencies.
The most interesting thing about it is the way it handles indexing. In this documentation Josh describes two approaches he uses to speeding up point-in-polygon and intersection using a novel approach that goes beyond the usual RTree implementation.
I think this could make the basis of a really useful SQLite extension—a lighter-weight alternative to SpatiaLite.
The WebAssembly Go Playground (via) Jeff Lindsay has a full Go 1.21.1 compiler running entirely in the browser.
LLM 0.11. I released LLM 0.11 with support for the new gpt-3.5-turbo-instruct completion model from OpenAI.
The most interesting feature of completion models is the option to request “log probabilities” from them, where each token returned is accompanied by up to 5 alternatives that were considered, along with their scores.
Notes on using a single-person Mastodon server. Julia Evans experiences running a single-person Mastodon server (on masto.host—the same host I use for my own) pretty much exactly match what I’ve learned so far as well. The biggest disadvantage is the missing replies issue, where your server only shows replies to posts that come from people who you follow—so it’s easy to reply to something in a way that duplicates other replies that are invisible to you.
How CPython Implements and Uses Bloom Filters for String Processing. Fascinating dive into Python string internals by Abhinav Upadhyay. It turns out CPython uses very simple bloom filters in several parts of the core string methods, to solve problems like splitting on newlines where there are actually eight codepoints that could represent a newline, and a tiny bloom filter can help filter a character in a single operation before performing all eight comparisons only if that first check failed.
CAISO Grid Status (via) CAISO is the California Independent System Operator, a non-profit managing 80% of California’s electricity flow. This grid status page shows live data about the state of the grid and it’s fascinating: right now (2pm local time) California is running 71.4% on renewables, having peaked at 80% three hours ago. The current fuel mix is 52% solar, 31% natural gas, 7% each large hydro and nuclear and 2% wind. The charts on this page show how solar turns off overnight and then picks up and peaks during daylight hours.
Introducing datasette-litestream: easy replication for SQLite databases in Datasette. We use Litestream on Datasette Cloud for streaming backups of user data to S3. Alex Garcia extracted out our implementation into a standalone Datasette plugin, which bundles the Litestream Go binary (for the relevant platform) in the package you get when you run “datasette install datasette-litestream”—so now Datasette has a very robust answer to questions about SQLite disaster recovery beyond just the Datasette Cloud platform.
Some notes on Local-First Development (via) Local-First is the name that has been coined by the community of people who are interested in building apps where data is manipulated in a client application first (mobile, desktop or web) and then continually synchronized with a server, rather than the other way round. This is a really useful review by Kyle Mathews of how the space is shaping up so far—lots of interesting threads to follow here.