Blogmarks
Filters: Sorted by date
OpenAI’s postmortem for API, ChatGPT & Sora Facing Issues (via) OpenAI had an outage across basically everything for four hours on Wednesday. They've now published a detailed postmortem which includes some fascinating technical details about their "hundreds of Kubernetes clusters globally".
The culprit was a newly deployed telemetry system:
Telemetry services have a very wide footprint, so this new service’s configuration unintentionally caused every node in each cluster to execute resource-intensive Kubernetes API operations whose cost scaled with the size of the cluster. With thousands of nodes performing these operations simultaneously, the Kubernetes API servers became overwhelmed, taking down the Kubernetes control plane in most of our large clusters. [...]
The Kubernetes data plane can operate largely independently of the control plane, but DNS relies on the control plane – services don’t know how to contact one another without the Kubernetes control plane. [...]
DNS caching mitigated the impact temporarily by providing stale but functional DNS records. However, as cached records expired over the following 20 minutes, services began failing due to their reliance on real-time DNS resolution.
It's always DNS.
Clio: A system for privacy-preserving insights into real-world AI use. New research from Anthropic, describing a system they built called Clio - for Claude insights and observations - which attempts to provide insights into how Claude is being used by end-users while also preserving user privacy.
There's a lot to digest here. The summary is accompanied by a full paper and a 47 minute YouTube interview with team members Deep Ganguli, Esin Durmus, Miles McCain and Alex Tamkin.
The key idea behind Clio is to take user conversations and use Claude to summarize, cluster and then analyze those clusters - aiming to ensure that any private or personally identifiable details are filtered out long before the resulting clusters reach human eyes.
This diagram from the paper helps explain how that works:
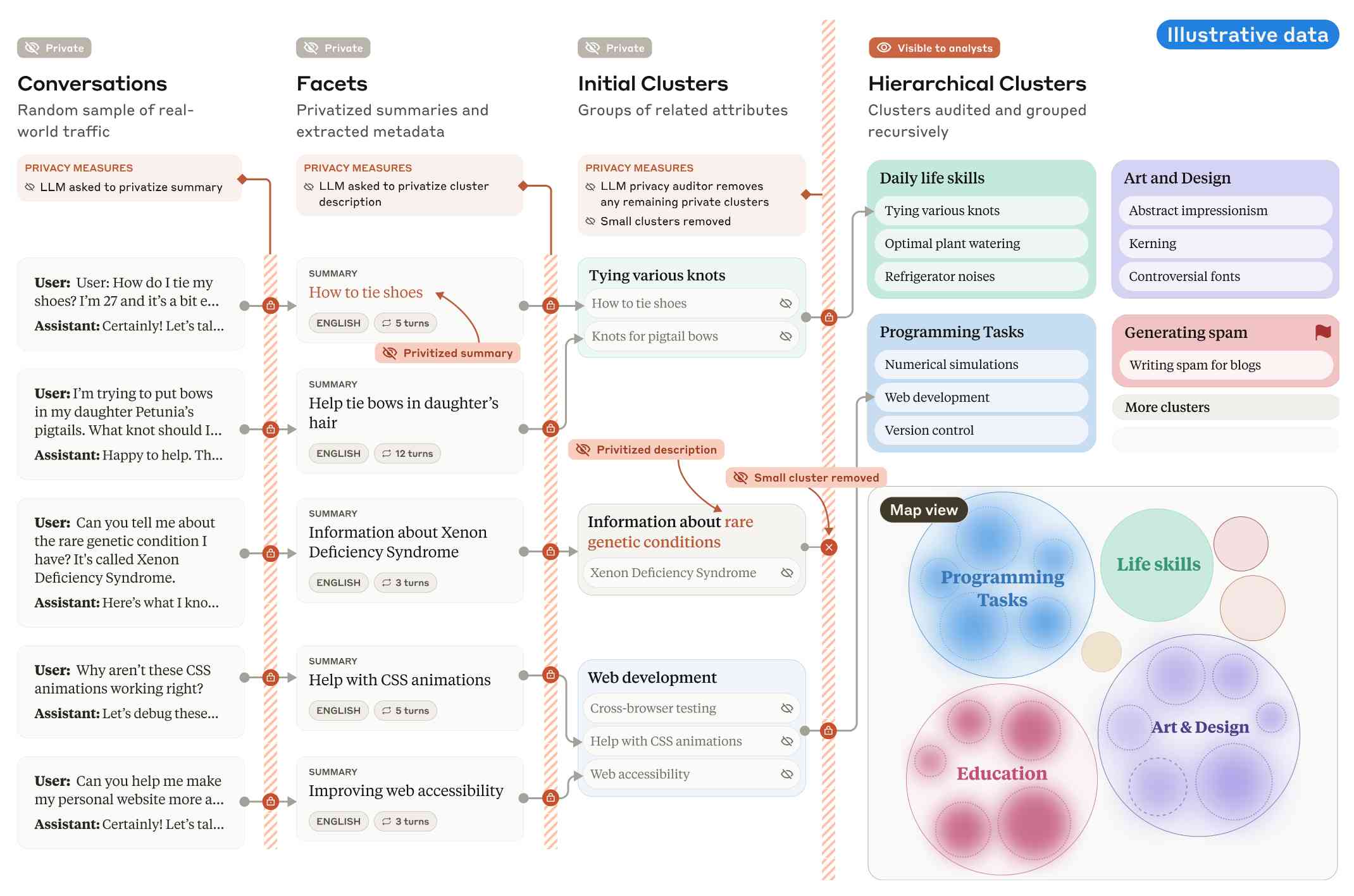
Claude generates a conversation summary, than extracts "facets" from that summary that aim to privatize the data to simple characteristics like language and topics.
The facets are used to create initial clusters (via embeddings), and those clusters further filtered to remove any that are too small or may contain private information. The goal is to have no cluster which represents less than 1,000 underlying individual users.
In the video at 16:39:
And then we can use that to understand, for example, if Claude is as useful giving web development advice for people in English or in Spanish. Or we can understand what programming languages are people generally asking for help with. We can do all of this in a really privacy preserving way because we are so far removed from the underlying conversations that we're very confident that we can use this in a way that respects the sort of spirit of privacy that our users expect from us.
Then later at 29:50 there's this interesting hint as to how Anthropic hire human annotators to improve Claude's performance in specific areas:
But one of the things we can do is we can look at clusters with high, for example, refusal rates, or trust and safety flag rates. And then we can look at those and say huh, this is clearly an over-refusal, this is clearly fine. And we can use that to sort of close the loop and say, okay, well here are examples where we wanna add to our, you know, human training data so that Claude is less refusally in the future on those topics.
And importantly, we're not using the actual conversations to make Claude less refusally. Instead what we're doing is we are looking at the topics and then hiring people to generate data in those domains and generating synthetic data in those domains.
So we're able to sort of use our users activity with Claude to improve their experience while also respecting their privacy.
According to Clio the top clusters of usage for Claude right now are as follows:
- Web & Mobile App Development (10.4%)
- Content Creation & Communication (9.2%)
- Academic Research & Writing (7.2%)
- Education & Career Development (7.1%)
- Advanced AI/ML Applications (6.0%)
- Business Strategy & Operations (5.7%)
- Language Translation (4.5%)
- DevOps & Cloud Infrastructure (3.9%)
- Digital Marketing & SEO (3.7%)
- Data Analysis & Visualization (3.5%)
There also are some interesting insights about variations in usage across different languages. For example, Chinese language users had "Write crime, thriller, and mystery fiction with complex plots and characters" at 4.4x the base rate for other languages.
What does a board of directors do? Extremely useful guide to what life as a board member looks like for both for-profit and non-profit boards by Anil Dash, who has served on both.
Boards can range from a loosely connected group that assembled on occasion to indifferently rubber-stamp what an executive tells them, or they can be deeply and intrusively involved in an organization in a way that undermines leadership. Generally, they’re somewhere in between, acting as a resource that amplifies the capabilities and execution of the core team, and that mostly only helps out or steps in when asked to.
The section about the daily/monthly/quarterly/yearly responsibilities of board membership really helps explain the responsibilities of such a position in detail.
Don't miss the follow-up Q&A post.
“Rules” that terminal programs follow. Julia Evans wrote down the unwritten rules of terminal programs. Lots of details in here I hadn’t fully understood before, like REPL programs that exit only if you hit Ctrl+D on an empty line.
googleapis/python-genai. Google released this brand new Python library for accessing their generative AI models yesterday, offering an alternative to their existing generative-ai-python library.
The API design looks very solid to me, and it includes both sync and async implementations. Here's an async streaming response:
async for response in client.aio.models.generate_content_stream(
model='gemini-2.0-flash-exp',
contents='Tell me a story in 300 words.'
):
print(response.text)
It also includes Pydantic-based output schema support and some nice syntactic sugar for defining tools using Python functions.
Who and What comprise AI Skepticism? (via) Benjamin Riley's response to Casey Newton's piece on The phony comforts of AI skepticism. Casey tried to categorize the field as "AI is fake and sucks" v.s. "AI is real and dangerous". Benjamin argues that this as a misleading over-simplification, instead proposing at least nine different groups.
I get listed as an example of the "Technical AI Skeptics" group, which sounds right to me based on this description:
What this group generally believes: The technical capabilities of AI are worth trying to understand, including their limitations. Also, it’s fun to find their deficiencies and highlight their weird output.
One layer of nuance deeper: Some of those I identify below might resist being called AI Skeptics because they are focused mainly on helping people understand how these tools work. But in my view, their efforts are helpful in fostering AI skepticism precisely because they help to demystify what’s happening “under the hood” without invoking broader political concerns (generally).
Introducing Limbo: A complete rewrite of SQLite in Rust (via) This looks absurdly ambitious:
Our goal is to build a reimplementation of SQLite from scratch, fully compatible at the language and file format level, with the same or higher reliability SQLite is known for, but with full memory safety and on a new, modern architecture.
The Turso team behind it have been maintaining their libSQL fork for two years now, so they're well equipped to take on a challenge of this magnitude.
SQLite is justifiably famous for its meticulous approach to testing. Limbo plans to take an entirely different approach based on "Deterministic Simulation Testing" - a modern technique pioneered by FoundationDB and now spearheaded by Antithesis, the company Turso have been working with on their previous testing projects.
Another bold claim (emphasis mine):
We have both added DST facilities to the core of the database, and partnered with Antithesis to achieve a level of reliability in the database that lives up to SQLite’s reputation.
[...] With DST, we believe we can achieve an even higher degree of robustness than SQLite, since it is easier to simulate unlikely scenarios in a simulator, test years of execution with different event orderings, and upon finding issues, reproduce them 100% reliably.
The two most interesting features that Limbo is planning to offer are first-party WASM support and fully asynchronous I/O:
SQLite itself has a synchronous interface, meaning driver authors who want asynchronous behavior need to have the extra complication of using helper threads. Because SQLite queries tend to be fast, since no network round trips are involved, a lot of those drivers just settle for a synchronous interface. [...]
Limbo is designed to be asynchronous from the ground up. It extends
sqlite3_step, the main entry point API to SQLite, to be asynchronous, allowing it to return to the caller if data is not ready to consume immediately.
Datasette provides an async API for executing SQLite queries which is backed by all manner of complex thread management - I would be very interested in a native asyncio Python library for talking to SQLite database files.
I successfully tried out Limbo's Python bindings against a demo SQLite test database using uv like this:
uv run --with pylimbo python
>>> import limbo
>>> conn = limbo.connect("/tmp/demo.db")
>>> cursor = conn.cursor()
>>> print(cursor.execute("select * from foo").fetchall())
It crashed when I tried against a more complex SQLite database that included SQLite FTS tables.
The Python bindings aren't yet documented, so I piped them through LLM and had the new google-exp-1206 model write this initial documentation for me:
files-to-prompt limbo/bindings/python -c | llm -m gemini-exp-1206 -s 'write extensive usage documentation in markdown, including realistic usage examples'
From where I left. Four and a half years after he left the project, Redis creator Salvatore Sanfilippo is returning to work on Redis.
Hacking randomly was cool but, in the long run, my feeling was that I was lacking a real purpose, and every day I started to feel a bigger urgency to be part of the tech world again. At the same time, I saw the Redis community fragmenting, something that was a bit concerning to me, even as an outsider.
I'm personally still upset at the license change, but Salvatore sees it as necessary to support the commercial business model for Redis Labs. It feels to me like a betrayal of the volunteer efforts by previous contributors. I posted about that on Hacker News and Salvatore replied:
I can understand that, but the thing about the BSD license is that such value never gets lost. People are able to fork, and after a fork for the original project to still lead will be require to put something more on the table.
Salvatore's first new project is an exploration of adding vector sets to Redis. The vector similarity API he previews in this post reminds me of why I fell in love with Redis in the first place - it's clean, simple and feels obviously right to me.
VSIM top_1000_movies_imdb ELE "The Matrix" WITHSCORES
1) "The Matrix"
2) "0.9999999403953552"
3) "Ex Machina"
4) "0.8680362105369568"
...
The Depths of Wikipedians (via) Asterisk Magazine interviewed Annie Rauwerda, curator of the Depths of Wikipedia family of social media accounts (I particularly like her TikTok).
There's a ton of insight into the dynamics of the Wikipedia community in here.
[...] when people talk about Wikipedia as a decision making entity, usually they're talking about 300 people — the people that weigh in to the very serious and (in my opinion) rather arcane, boring, arduous discussions. There's not that many of them.
There are also a lot of islands. There is one woman who mostly edits about hamsters, and always on her phone. She has never interacted with anyone else. Who is she? She's not part of any community that we can tell.
I appreciated these concluding thoughts on the impact of ChatGPT and LLMs on Wikipedia:
The traffic to Wikipedia has not taken a dramatic hit. Maybe that will change in the future. The Foundation talks about coming opportunities, or the threat of LLMs. With my friends that edit a lot, it hasn't really come up a ton because I don't think they care. It doesn't affect us. We're doing the same thing. Like if all the large language models eat up the stuff we wrote and make it easier for people to get information — great. We made it easier for people to get information.
And if LLMs end up training on blogs made by AI slop and having as their basis this ouroboros of generated text, then it's possible that a Wikipedia-type thing — written and curated by a human — could become even more valuable.
Sora (via) OpenAI's released their long-threatened Sora text-to-video model this morning, available in most non-European countries to subscribers to ChatGPT Plus ($20/month) or Pro ($200/month).
Here's what I got for the very first test prompt I ran through it:
A pelican riding a bicycle along a coastal path overlooking a harbor
The Pelican inexplicably morphs to cycle in the opposite direction half way through, but I don't see that as a particularly significant issue: Sora is built entirely around the idea of directly manipulating and editing and remixing the clips it generates, so the goal isn't to have it produce usable videos from a single prompt.
llm-openrouter 0.3. New release of my llm-openrouter plugin, which allows LLM to access models hosted by OpenRouter.
Quoting the release notes:
- Enable image attachments for models that support images. Thanks, Adam Montgomery. #12
- Provide async model access. #15
- Fix documentation to list correct
LLM_OPENROUTER_KEYenvironment variable. #10
Holotypic Occlupanid Research Group (via) I just learned about this delightful piece of internet culture via Leven Parker on TikTok.
Occlupanids are the small plastic square clips used to seal plastic bags containing bread.
For thirty years (since 1994) John Daniel has maintained this website that catalogs them and serves as the basis of a wide ranging community of occlupanologists who study and collect these plastic bread clips.
There's an active subreddit, r/occlupanids, but the real treat is the meticulously crafted taxonomy with dozens of species split across 19 families, all in the class Occlupanida:
Class Occlupanida (Occlu=to close, pan= bread) are placed under the Kingdom Microsynthera, of the Phylum Plasticae. Occlupanids share phylum Plasticae with “45” record holders, plastic juice caps, and other often ignored small plastic objects.
If you want to classify your own occlupanid there's even a handy ID guide, which starts with the shape of the "oral groove" in the clip.
Or if you want to dive deep down a rabbit hole, this YouTube video by CHUPPL starts with Occlupanids and then explores their inventor Floyd Paxton's involvement with the John Birch Society and eventually Yamashita's gold.
Writing down (and searching through) every UUID (via) Nolen Royalty built everyuuid.com, and this write-up of how he built it is utterly delightful.
First challenge: infinite scroll.
Browsers do not want to render a window that is over a trillion trillion pixels high, so I needed to handle scrolling and rendering on my own.
That means implementing hot keys and mouse wheel support and custom scroll bars with animation... mostly implemented with the help of Claude.
The really fun stuff is how Nolen implemented custom ordering - because "Scrolling through a list of UUIDs should be exciting!", but "it’d be disappointing if you scrolled through every UUID and realized that you hadn’t seen one. And it’d be very hard to show someone a UUID that you found if you couldn’t scroll back to the same spot to find it."
And if that wasn't enough... full text search! How can you efficiently search (or at least pseudo-search) for text across 5.3 septillion values? The trick there turned out to be generating a bunch of valid UUIDv4s containing the requested string and then picking the one closest to the current position on the page.
Meta AI release Llama 3.3. This new Llama-3.3-70B-Instruct model from Meta AI makes some bold claims:
This model delivers similar performance to Llama 3.1 405B with cost effective inference that’s feasible to run locally on common developer workstations.
I have 64GB of RAM in my M2 MacBook Pro, so I'm looking forward to trying a slightly quantized GGUF of this model to see if I can run it while still leaving some memory free for other applications.
Update: Ollama have a 43GB GGUF available now. And here's an MLX 8bit version and other MLX quantizations.
Llama 3.3 has 70B parameters, a 128,000 token context length and was trained to support English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
The model card says that the training data was "A new mix of publicly available online data" - 15 trillion tokens with a December 2023 cut-off.
They used "39.3M GPU hours of computation on H100-80GB (TDP of 700W) type hardware" which they calculate as 11,390 tons CO2eq. I believe that's equivalent to around 20 fully loaded passenger flights from New York to London (at ~550 tons per flight).
Update 19th January 2025: On further consideration I no longer trust my estimate here: it's surprisingly hard to track down reliable numbers but I think the total CO2 used by those flights may be more in the order of 200-400 tons, so my estimate for Llama 3.3 70B should have been more in the order of between 28 and 56 flights. Don't trust those numbers either though!
New Gemini model: gemini-exp-1206. Google's Jeff Dean:
Today’s the one year anniversary of our first Gemini model releases! And it’s never looked better.
Check out our newest release, Gemini-exp-1206, in Google AI Studio and the Gemini API!
I upgraded my llm-gemini plugin to support the new model and released it as version 0.6 - you can install or upgrade it like this:
llm install -U llm-gemini
Running my SVG pelican on a bicycle test prompt:
llm -m gemini-exp-1206 "Generate an SVG of a pelican riding a bicycle"
Provided this result, which is the best I've seen from any model:

Here's the full output - I enjoyed these two pieces of commentary from the model:
<polygon>: Shapes the distinctive pelican beak, with an added line for the lower mandible.
[...]
transform="translate(50, 30)": This attribute on the pelican's<g>tag moves the entire pelican group 50 units to the right and 30 units down, positioning it correctly on the bicycle.
The new model is also currently in top place on the Chatbot Arena.
Update: a delightful bonus, here's what I got from the follow-up prompt:
llm -c "now animate it"

DSQL Vignette: Reads and Compute. Marc Brooker is one of the engineers behind AWS's new Aurora DSQL horizontally scalable database. Here he shares all sorts of interesting details about how it works under the hood.
The system is built around the principle of separating storage from compute: storage uses S3, while compute runs in Firecracker:
Each transaction inside DSQL runs in a customized Postgres engine inside a Firecracker MicroVM, dedicated to your database. When you connect to DSQL, we make sure there are enough of these MicroVMs to serve your load, and scale up dynamically if needed. We add MicroVMs in the AZs and regions your connections are coming from, keeping your SQL query processor engine as close to your client as possible to optimize for latency.
We opted to use PostgreSQL here because of its pedigree, modularity, extensibility, and performance. We’re not using any of the storage or transaction processing parts of PostgreSQL, but are using the SQL engine, an adapted version of the planner and optimizer, and the client protocol implementation.
The system then provides strong repeatable-read transaction isolation using MVCC and EC2's high precision clocks, enabling reads "as of time X" including against nearby read replicas.
The storage layer supports index scans, which means the compute layer can push down some operations allowing it to load a subset of the rows it needs, reducing round-trips that are affected by speed-of-light latency.
The overall approach here is disaggregation: we’ve taken each of the critical components of an OLTP database and made it a dedicated service. Each of those services is independently horizontally scalable, most of them are shared-nothing, and each can make the design choices that is most optimal in its domain.
Roaming RAG – make the model find the answers (via) Neat new RAG technique (with a snappy name) from John Berryman:
The big idea of Roaming RAG is to craft a simple LLM application so that the LLM assistant is able to read a hierarchical outline of a document, and then rummage though the document (by opening sections) until it finds and answer to the question at hand. Since Roaming RAG directly navigates the text of the document, there is no need to set up retrieval infrastructure, and fewer moving parts means less things you can screw up!
John includes an example which works by collapsing a Markdown document down to just the headings, each with an instruction comment that says <!-- Section collapsed - expand with expand_section("9db61152") -->.
An expand_section() tool is then provided with the following tool description:
Expand a section of the markdown document to reveal its contents.
- Expand the most specific (lowest-level) relevant section first
- Multiple sections can be expanded in parallel
- You can expand any section regardless of parent section state (e.g. parent sections do not need to be expanded to view subsection content)
I've explored both vector search and full-text search RAG in the past, but this is the first convincing sounding technique I've seen that skips search entirely and instead leans into allowing the model to directly navigate large documents via their headings.
datasette-enrichments-llm. Today's new alpha release is datasette-enrichments-llm, a plugin for Datasette 1.0a+ that provides an enrichment that lets you run prompts against data from one or more column and store the result in another column.
So far it's a light re-implementation of the existing datasette-enrichments-gpt plugin, now using the new llm.get_async_models() method to allow users to select any async-enabled model that has been registered by a plugin - so currently any of the models from OpenAI, Anthropic, Gemini or Mistral via their respective plugins.
Still plenty to do on this one. Next step is to integrate it with datasette-llm-usage and use it to drive a design-complete stable version of that.
New Pleias 1.0 LLMs trained exclusively on openly licensed data (via) I wrote about the Common Corpus public domain dataset back in March. Now Pleias, the team behind Common Corpus, have released the first family of models that are:
[...] trained exclusively on open data, meaning data that are either non-copyrighted or are published under a permissible license.
There's a lot to absorb here. The Pleias 1.0 family comes in three base model sizes: 350M, 1.2B and 3B. They've also released two models specialized for multi-lingual RAG: Pleias-Pico (350M) and Pleias-Nano (1.2B).
Here's an official GGUF for Pleias-Pico.
I'm looking forward to seeing benchmarks from other sources, but Pleias ran their own custom multilingual RAG benchmark which had their Pleias-nano-1.2B-RAG model come in between Llama-3.2-Instruct-3B and Llama-3.2-Instruct-8B.
The 350M and 3B models were trained on the French government's Jean Zay supercomputer. Pleias are proud of their CO2 footprint for training the models - 0.5, 4 and 16 tCO2eq for the three models respectively, which they compare to Llama 3.2,s reported figure of 133 tCO2eq.
How clean is the training data from a licensing perspective? I'm confident people will find issues there - truly 100% public domain data remains a rare commodity. So far I've seen questions raised about the GitHub source code data (most open source licenses have attribution requirements) and Wikipedia (CC BY-SA, another attribution license). Plus this from the announcement:
To supplement our corpus, we have generated 30B+ words synthetically with models allowing for outputs reuse.
If those models were themselves trained on unlicensed data this could be seen as a form of copyright laundering.
Claude 3.5 Haiku price drops by 20%. Buried in this otherwise quite dry post about Anthropic's ongoing partnership with AWS:
To make this model even more accessible for a wide range of use cases, we’re lowering the price of Claude 3.5 Haiku to $0.80 per million input tokens and $4 per million output tokens across all platforms.
The previous price was $1/$5. I've updated my LLM pricing calculator and modified yesterday's piece comparing prices with Amazon Nova as well.
Confusing matters somewhat, the article also announces a new way to access Claude 3.5 Haiku at the old price but with "up to 60% faster inference speed":
This faster version of Claude 3.5 Haiku, powered by Trainium2, is available in the US East (Ohio) Region via cross-region inference and is offered at $1 per million input tokens and $5 per million output tokens.
Using "cross-region inference" involve sending something called an "inference profile" to the Bedrock API. I have an open issue to figure out what that means for my llm-bedrock plugin.
Also from this post: AWS now offer a Bedrock model distillation preview which includes the ability to "teach" Claude 3 Haiku using Claude 3.5 Sonnet. It sounds similar to OpenAI's model distillation feature announced at their DevDay event back in October.
Genie 2: A large-scale foundation world model (via) New research (so nothing we can play with) from Google DeepMind. Genie 2 is effectively a game engine driven entirely by generative AI - you can seed it with any image and it will turn that image into a 3D environment that you can then explore.
It's reminiscent of last month's impressive Oasis: A Universe in a Transformer by Decart and Etched which provided a Minecraft clone where each frame was generated based on the previous one. That one you can try out (Chrome only) - notably, any time you look directly up at the sky or down at the ground the model forgets where you were and creates a brand new world.
Genie 2 at least partially addresses that problem:
Genie 2 is capable of remembering parts of the world that are no longer in view and then rendering them accurately when they become observable again.
The capability list for Genie 2 is really impressive, each accompanied by a short video. They have demos of first person and isometric views, interactions with objects, animated character interactions, water, smoke, gravity and lighting effects, reflections and more.
datasette-queries. I released the first alpha of a new plugin to replace the crusty old datasette-saved-queries. This one adds a new UI element to the top of the query results page with an expandable form for saving the query as a new canned query:
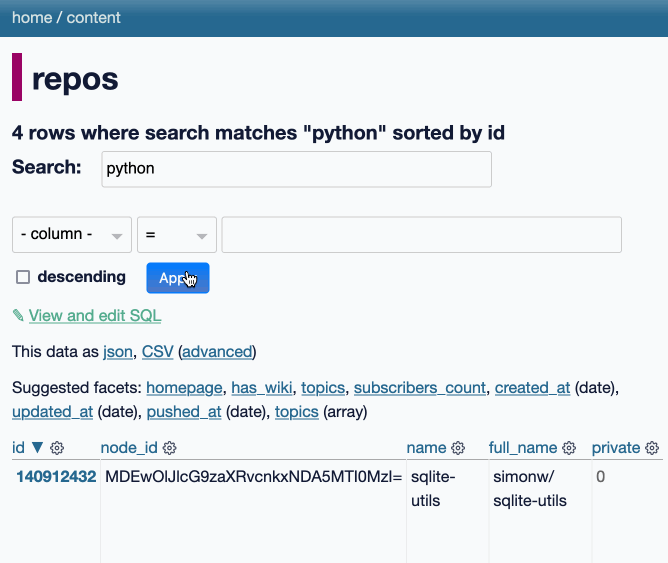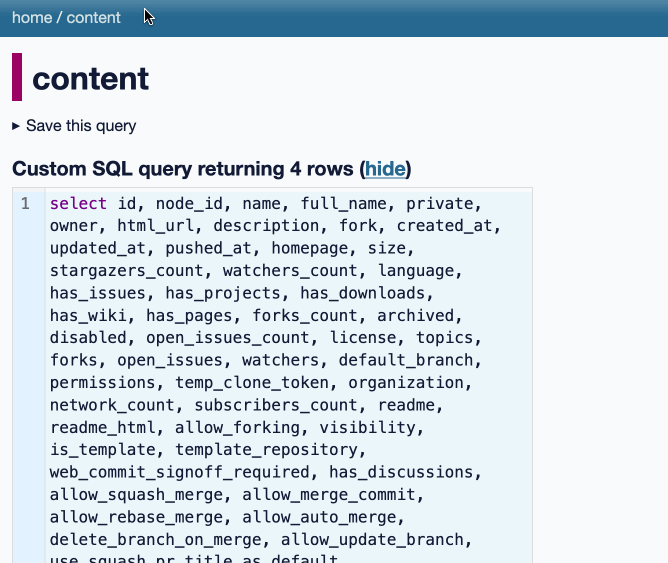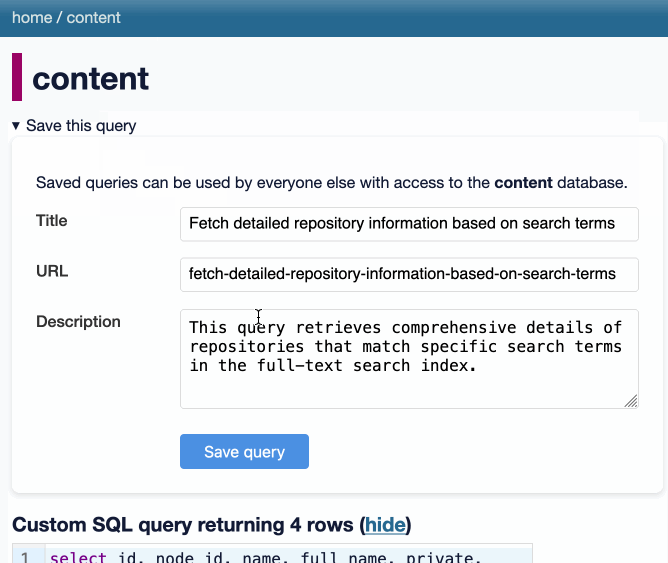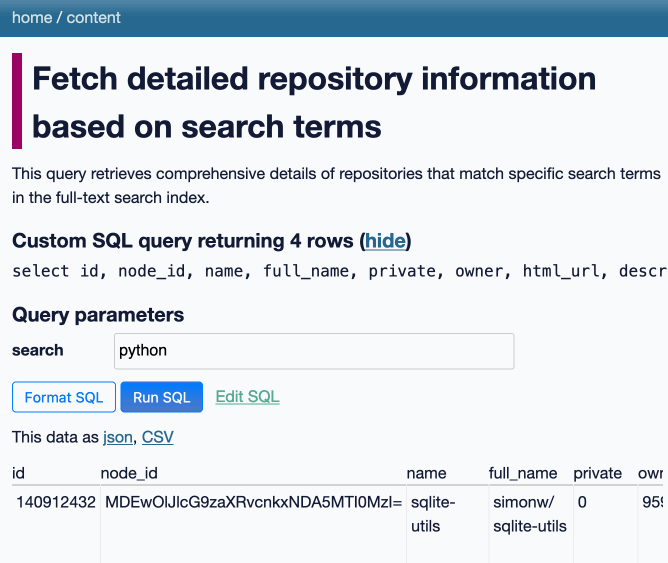
It's my first plugin to depend on LLM and datasette-llm-usage - it uses GPT-4o mini to power an optional "Suggest title and description" button, labeled with the becoming-standard ✨ sparkles emoji to indicate an LLM-powered feature.
I intend to expand this to work across multiple models as I continue to iterate on llm-datasette-usage to better support those kinds of patterns.
For the moment though each suggested title and description call costs about 250 input tokens and 50 output tokens, which against GPT-4o mini adds up to 0.0067 cents.
Transferring Python Build Standalone Stewardship to Astral. Gregory Szorc's Python Standalone Builds have been quietly running an increasing portion of the Python ecosystem for a few years now, but really accelerated in importance when uv started using them for new Python installations managed by that tool. The releases (shipped via GitHub) have now been downloaded over 70 million times, 50 million of those since uv's initial release in March of this year.
uv maintainers Astral have been helping out with PSB maintenance for a while:
When I told Charlie I could use assistance supporting PBS, Astral employees started contributing to the project. They have built out various functionality, including Python 3.13 support (including free-threaded builds), turnkey automated release publishing, and debug symbol stripped builds to further reduce the download/install size. Multiple Astral employees now have GitHub permissions to approve/merge PRs and publish releases. All releases since April have been performed by Astral employees.
As-of December 17th Gregory will be transferring the project to the Astral organization, while staying on as a maintainer and advisor. Here's Astral's post about this: A new home for python-build-standalone.
Introducing Amazon Aurora DSQL (via) New, weird-shaped database from AWS. It's (loosely) PostgreSQL compatible, claims "virtually unlimited scale" and can be set up as a single-region cluster or as a multi-region setup that somehow supports concurrent reads and writes across all regions. I'm hoping they publish technical details on how that works at some point in the future (update: they did), right now they just say this:
When you create a multi-Region cluster, Aurora DSQL creates another cluster in a different Region and links them together. Adding linked Regions makes sure that all changes from committed transactions are replicated to the other linked Regions. Each linked cluster has a Regional endpoint, and Aurora DSQL synchronously replicates writes across Regions, enabling strongly consistent reads and writes from any linked cluster.
Here's the list of unsupported PostgreSQL features - most notably views, triggers, sequences, foreign keys and extensions. A single transaction can also modify only up to 10,000 rows.
No pricing information yet (it's in a free preview) but it looks like this one may be true scale-to-zero, unlike some of their other recent "serverless" products - Amazon Aurora Serverless v2 has a baseline charge no matter how heavily you are using it. (Update: apparently that changed on 20th November 2024 when they introduced an option to automatically pause a v2 serverless instance, which then "takes less than 15 seconds to resume".)
Certain names make ChatGPT grind to a halt, and we know why (via) Benj Edwards on the really weird behavior where ChatGPT stops output with an error rather than producing the names David Mayer, Brian Hood, Jonathan Turley, Jonathan Zittrain, David Faber or Guido Scorza.
The OpenAI API is entirely unaffected - this problem affects the consumer ChatGPT apps only.
It turns out many of those names are examples of individuals who have complained about being defamed by ChatGPT in the last. Brian Hood is the Australian mayor who was a victim of lurid ChatGPT hallucinations back in March 2023, and settled with OpenAI out of court.
datasette-llm-usage. I released the first alpha of a Datasette plugin to help track LLM usage by other plugins, with the goal of supporting token allowances - both for things like free public apps that stop working after a daily allowance, plus free previews of AI features for paid-account-based projects such as Datasette Cloud.
It's using the usage features I added in LLM 0.19.
The alpha doesn't do much yet - it will start getting interesting once I upgrade other plugins to depend on it.
Design notes so far in issue #1.
NYTimes reporters getting verified profiles on Bluesky.
NYT data journalist Dylan Freedman has kicked off an initiative to get NYT accounts and reporters on Bluesky verified via vanity nytimes.com handles - Dylan is now @dylanfreedman.nytimes.com.
They're using Bluesky's support for TXT domain records. If you use Google's Dig tool to look at the TXT record for _atproto.dylanfreedman.nytimes.com you'll see this:
_atproto.dylanfreedman.nytimes.com. 500 IN TXT "did=did:plc:zeqq4z7aybrqg6go6vx6lzwt"
PydanticAI (via) New project from Pydantic, which they describe as an "Agent Framework / shim to use Pydantic with LLMs".
I asked which agent definition they are using and it's the "system prompt with bundled tools" one. To their credit, they explain that in their documentation:
The Agent has full API documentation, but conceptually you can think of an agent as a container for:
- A system prompt — a set of instructions for the LLM written by the developer
- One or more retrieval tool — functions that the LLM may call to get information while generating a response
- An optional structured result type — the structured datatype the LLM must return at the end of a run
Given how many other existing tools already lean on Pydantic to help define JSON schemas for talking to LLMs this is an interesting complementary direction for Pydantic to take.
There's some overlap here with my own LLM project, which I still hope to add a function calling / tools abstraction to in the future.
Simon Willison: The Future of Open Source and AI (via) I sat down a few weeks ago to record this conversation with Logan Kilpatrick and Nolan Fortman for their podcast Around the Prompt. The episode is available on YouTube and Apple Podcasts and other platforms.
We talked about a whole bunch of different topics, including the ongoing debate around the term "open source" when applied to LLMs and my thoughts on why I don't feel threatened by LLMs as a software engineer (at 40m05s).
LLM 0.19. I just released version 0.19 of LLM, my Python library and CLI utility for working with Large Language Models.
I released 0.18 a couple of weeks ago adding support for calling models from Python asyncio code. 0.19 improves on that, and also adds a new mechanism for models to report their token usage.
LLM can log those usage numbers to a SQLite database, or make then available to custom Python code.
My eventual goal with these features is to implement token accounting as a Datasette plugin so I can offer AI features in my SaaS platform without worrying about customers spending unlimited LLM tokens.
Those 0.19 release notes in full:
- Tokens used by a response are now logged to new
input_tokensandoutput_tokensinteger columns and atoken_detailsJSON string column, for the default OpenAI models and models from other plugins that implement this feature. #610llm promptnow takes a-u/--usageflag to display token usage at the end of the response.llm logs -u/--usageshows token usage information for logged responses.llm prompt ... --asyncresponses are now logged to the database. #641llm.get_models()andllm.get_async_models()functions, documented here. #640response.usage()and async responseawait response.usage()methods, returning aUsage(input=2, output=1, details=None)dataclass. #644response.on_done(callback)andawait response.on_done(callback)methods for specifying a callback to be executed when a response has completed, documented here. #653- Fix for bug running
llm chaton Windows 11. Thanks, Sukhbinder Singh. #495
I also released three new plugin versions that add support for the new usage tracking feature: llm-gemini 0.5, llm-claude-3 0.10 and llm-mistral 0.9.