159 posts tagged “postgresql”
2024
How Figma’s databases team lived to tell the scale (via) The best kind of scaling war story:
"Figma’s database stack has grown almost 100x since 2020. [...] In 2020, we were running a single Postgres database hosted on AWS’s largest physical instance, and by the end of 2022, we had built out a distributed architecture with caching, read replicas, and a dozen vertically partitioned databases."
I like the concept of "colos", their internal name for sharded groups of related tables arranged such that those tables can be queried using joins.
Also smart: separating the migration into "logical sharding" - where queries all still run against a single database, even though they are logically routed as if the database was already sharded - followed by "physical sharding" where the data is actually copied to and served from the new database servers.
Logical sharding was implemented using PostgreSQL views, which can accept both reads and writes:
CREATE VIEW table_shard1 AS SELECT * FROM table
WHERE hash(shard_key) >= min_shard_range AND hash(shard_key) < max_shard_range)
The final piece of the puzzle was DBProxy, a custom PostgreSQL query proxy written in Go that can parse the query to an AST and use that to decide which shard the query should be sent to. Impressively it also has a scatter-gather mechanism, so select * from table can be sent to all shards at once and the results combined back together again.
PGlite (via) PostgreSQL compiled for WebAssembly and turned into a very neat JavaScript library. Previous attempts at running PostgreSQL in WASM have worked by bundling a full Linux virtual machine - PGlite just bundles a compiled PostgreSQL itself, which brings the size down to an impressive 3.7MB gzipped.
I built this interactive demo of PGlite using Observable Framework, source code here.
Announcing DuckDB 0.10.0.
Somewhat buried in this announcement: DuckDB has Fixed-Length Arrays now, along with array_cross_product(a1, a2), array_cosine_similarity(a1, a2) and array_inner_product(a1, a2) functions.
This means you can now use DuckDB to find related content (and other tricks) using vector embeddings!
Also notable:
DuckDB can now attach MySQL, Postgres, and SQLite databases in addition to databases stored in its own format. This allows data to be read into DuckDB and moved between these systems in a convenient manner, as attached databases are fully functional, appear just as regular tables, and can be updated in a safe, transactional manner.
pgroll (via) “Zero-downtime, reversible, schema migrations for Postgres”
I love this kind of thing. This one is has a really interesting design: you define your schema modifications (adding/dropping columns, creating tables etc) using a JSON DSL, then apply them using a Go binary.
When you apply a migration the tool first creates a brand new PostgreSQL schema (effectively a whole new database) which imitates your new schema design using PostgreSQL views. You can then point your applications that have been upgraded to the new schema at it, using the PostgreSQL search_path setting.
Old applications can continue talking to the previous schema design, giving you an opportunity to roll out a zero-downtime deployment of the new code.
Once your application has upgraded and the physical rows in the database have been transformed to the new schema you can run a --continue command to make the final destructive changes and drop the mechanism that simulates both schema designs at once.
GPT in 500 lines of SQL (via) Utterly brilliant piece of PostgreSQL hackery by Alex Bolenok, who implements a full GPT-2 style language model in SQL on top of pg_vector. The final inference query is 498 lines long!
2023
Database generated columns: GeoDjango & PostGIS. Paolo Melchiorre advocated for the inclusion of generated columns, one of the biggest features in Django 5.0. Here he provides a detailed tutorial showing how they can be used with PostGIS to create database tables that offer columns such as geohash that are automatically calculated from other columns in the table.
Making PostgreSQL tick: New features in pg_cron (via) pg_cron adds cron-style scheduling directly to PostgreSQL. It's a pretty mature extension at this point, and recently gained the ability to schedule repeating tasks at intervals as low as every 1s.
The examples in this post are really informative. I like this example, which cleans up the ever-growing cron.job_run_details table by using pg_cron itself to run the cleanup:
SELECT cron.schedule('delete-job-run-details', '0 12 * * *', $$DELETE FROM cron.job_run_details WHERE end_time < now() - interval '3 days'$$);
pg_cron can be used to schedule functions written in PL/pgSQL, which is a great example of the kind of DSL that I used to avoid but I'm now much happier to work with because I know GPT-4 can write basic examples for me and help me understand exactly what unfamiliar code is doing.
Upsert in SQL (via) Anton Zhiyanov is currently on a one-man quest to write detailed documentation for all of the fundamental SQL operations, comparing and contrasting how they work across multiple engines, generally with interactive examples.
Useful tips in here on why “insert... on conflict” is usually a better option than “insert or replace into” because the latter can perform a delete and then an insert, firing triggers that you may not have wanted to be fired.
PostgreSQL Lock Conflicts (via) I absolutely love how extremely specific and niche this documentation site is. It details every single lock that PostgreSQL implements, and shows exactly which commands acquire that lock. That’s everything. I can imagine this becoming absurdly useful at extremely infrequent intervals for advanced PostgreSQL work.
Writing a chat application in Django 4.2 using async StreamingHttpResponse, Server-Sent Events and PostgreSQL LISTEN/NOTIFY (via) Excellent tutorial by Víðir Valberg Guðmundsson on implementing chat with server-sent events using the newly async-capable StreamingHttpResponse from Django 4.2x.
He uses PostgreSQL’a LISTEN/NOTIFY mechanism which can be used asynchronously in psycopg3—at the cost of a separate connection per user of the chat.
The article also covers how to use the Last-Event-ID header to implement reconnections in server-sent events, transmitting any events that may have been missed during the time that the connection was dropped.
Big Opportunities in Small Data

I gave an invited keynote at Citus Con 2023, the PostgreSQL conference. Below is the abstract, video, slides and links from the presentation.
[... 385 words]Quicker serverless Postgres connections. Neon provide “serverless PostgreSQL”—autoscaling, managed PostgreSQL optimized for use with serverless hosting environments. A neat capability they provide is the ability to connect to a PostgreSQL server via WebSockets, which means their database can be used from environments such as Cloudflare workers which don’t have the ability to use a standard TCP database connection. This article describes some clever tricks they used to make establishing new connections via WebSockets more efficient, using the least possible number of network round-trips.
2022
Scaling Mastodon: The Compendium (via) Hazel Weakly’s collection of notes on scaling Mastodon, covering PostgreSQL, Sidekiq, Redis, object storage and more.
Querying Postgres Tables Directly From DuckDB (via) I learned a lot of interesting PostgreSQL tricks from this write-up of the new DuckDB feature that allows it to run queries against PostgreSQL servers directly. It works using COPY (SELECT ...) TO STDOUT (FORMAT binary) which writes rows to the protocol stream in efficient binary format, but splits the table being read into parallel fetches against page ranges and uses SET TRANSACTION SNAPSHOT ... in those parallel queries to ensure they see the same transactional snapshot of the database.
Crunchy Data: Learn Postgres at the Playground (via) Crunchy Data have a new PostgreSQL tutorial series, with a very cool twist: they have a build of PostgreSQL compiled to WebAssembly which runs in the browser, so each tutorial is accompanied by a working psql terminal that lets you try out the tutorial contents interactively. It even has support for PostGIS, though that particular tutorial has to load 80MB of assets in order to get it to work!
Lesser Known Features of ClickHouse (via) I keep hearing positive noises about ClickHouse. I learned about a whole bunch of capabilities from this article—including that ClickHouse can directly query tables that are stored in SQLite or PostgreSQL.
Glue code to quickly copy data from one Postgres table to another (via) The Python script that Retool used to migrate 4TB of data between two PostgreSQL databases. I find the structure of this script really interesting—it uses Python to spin up a queue full of ID ranges to be transferred and then starts some threads, but then each thread shells out to a command that runs “psql COPY (SELECT ...) TO STDOUT” and pipes the result to “psql COPY xxx FROM STDIN”. Clearly this works really well (“saturate the database’s hardware capacity” according to a comment on HN), and neatly sidesteps any issues with Python’s GIL.
Postgres Auditing in 150 lines of SQL (via) I’ve run up against the problem of tracking changes made to rows within a database table so many times, and I still don’t have a preferred solution. This approach to it looks very neat: it uses PostgreSQL triggers to populate a single audit table (as opposed to one audit table per tracked table) and records the previous and current column values for the row using jsonb.
migra (via) This looks like a very handy tool to have around: run “migra postgresql:///a postgresql:///b” and it will detect and output the SQL alter statements needed to modify the first PostgreSQL database schema to match the second. It’s written in Python, running on top of SQLAlchemy.
Single dependency stacks (via) Brandur Leach notes that the core services at Crunchy (admittedly a PostgreSQL hosting and consultancy company) have only one stateful dependency – Postgres. No Redis, ElasticSearch or anything else. This means that problems like rate limiting and search, which are often farmed out to external services, are all handled using either PostgreSQL or in-memory mechanisms on their servers.
Tricking Postgres into using an insane – but 200x faster – query plan. Jacob Martin talks through a PostgreSQL query optimization they implemented at Spacelift, showing in detail how to interpret the results of EXPLAIN (FORMAT JSON, ANALYZE) using the explain.dalibo.com visualization tool.
2021
Transactionally Staged Job Drains in Postgres. Any time I see people argue that relational databases shouldn’t be used to implement job queues I think of this post by Brandur from 2017. If you write to a queue before committing a transaction you run the risk of a queue consumer trying to read from the database before the new row becomes visible. If you write to the queue after the transaction there’s a risk an error might result in your message never being written. So: write to a relational staging table as part of the transaction, then have a separate process read from that table and write to the queue.
Per-project PostgreSQL (via) Jamey Sharp describes an ingenious way of setting up PostgreSQL instances for each of your local development project, without depending on an always-running shared localhost database server. The trick is a shell script which creates a PGDATA folder in the current folder and then instantiates a PostgreSQL server in --single single user mode which listens on a Unix domain socket in that folder, instead of listening on the network. Jamey then uses direnv to automatically configure that PostgreSQL, initializing the DB if necessary, for each of his project folders.
Django SQL Dashboard 1.0
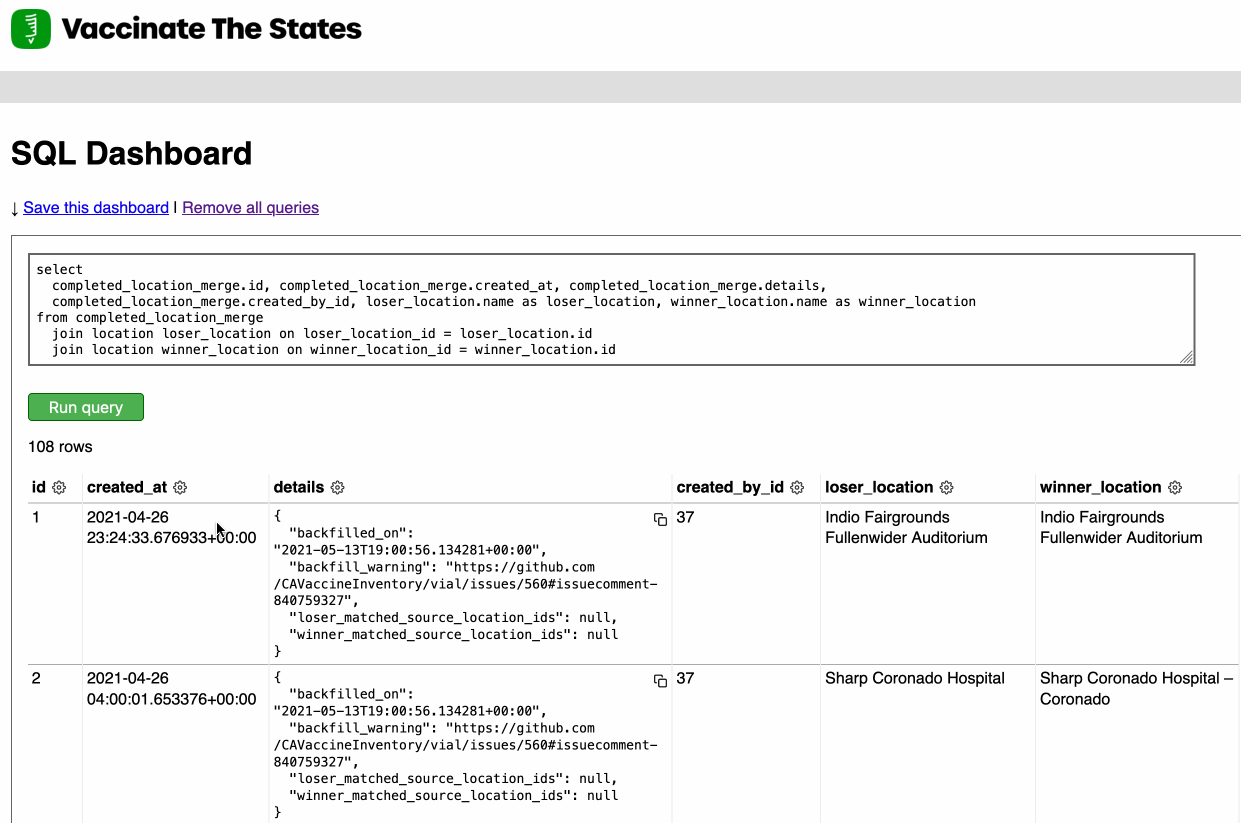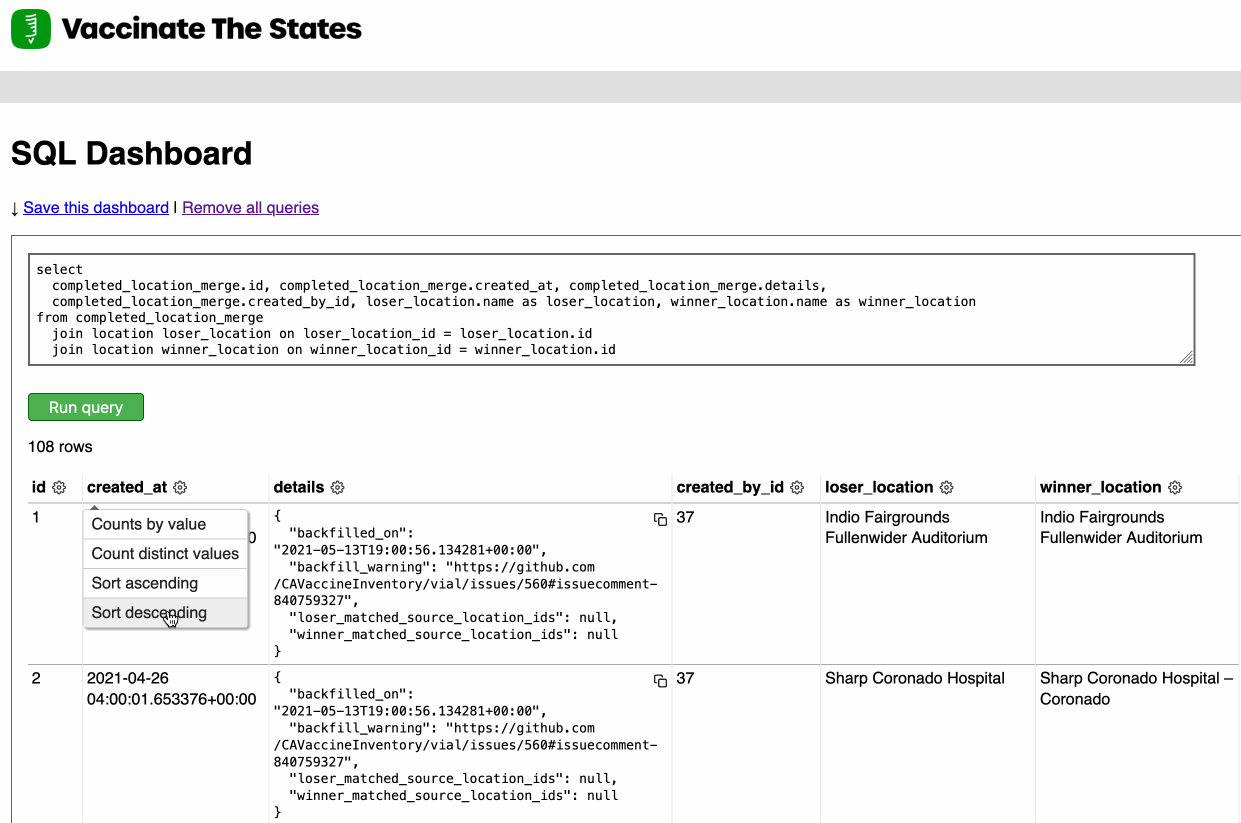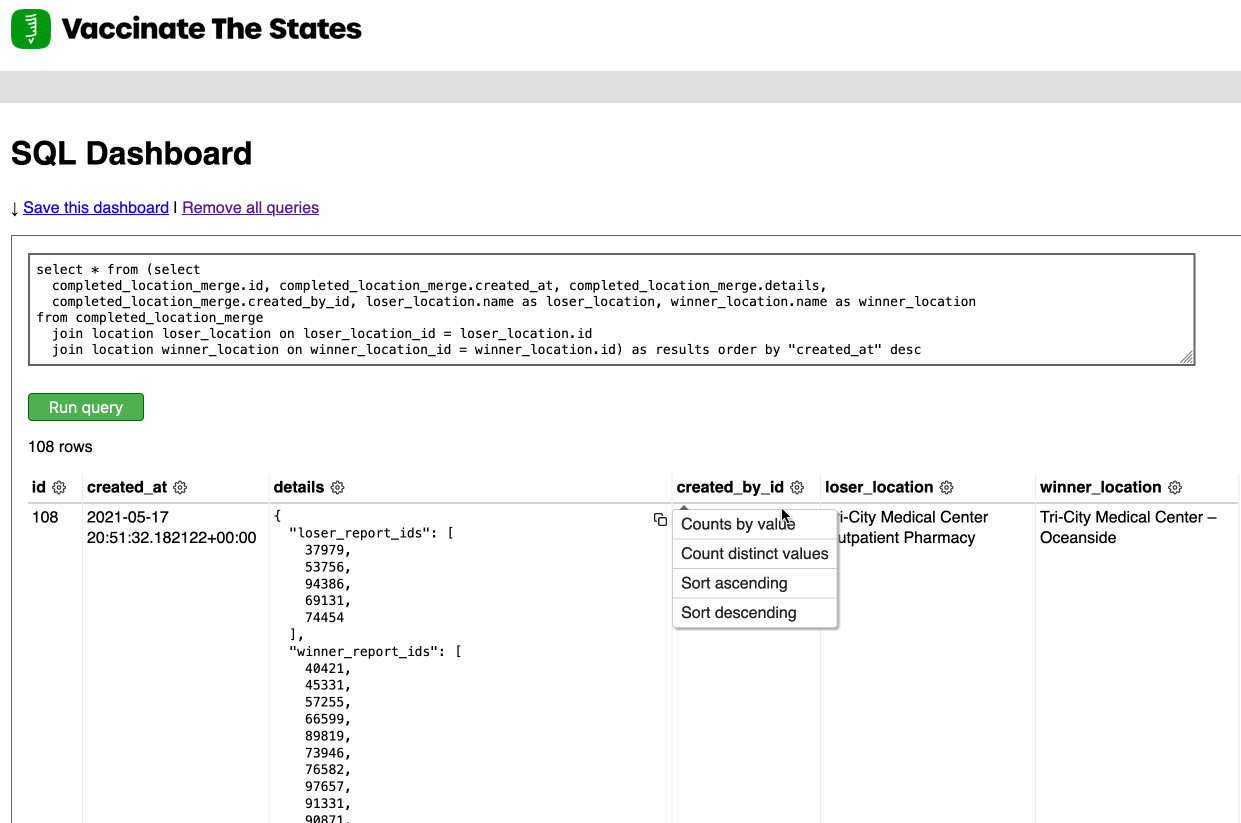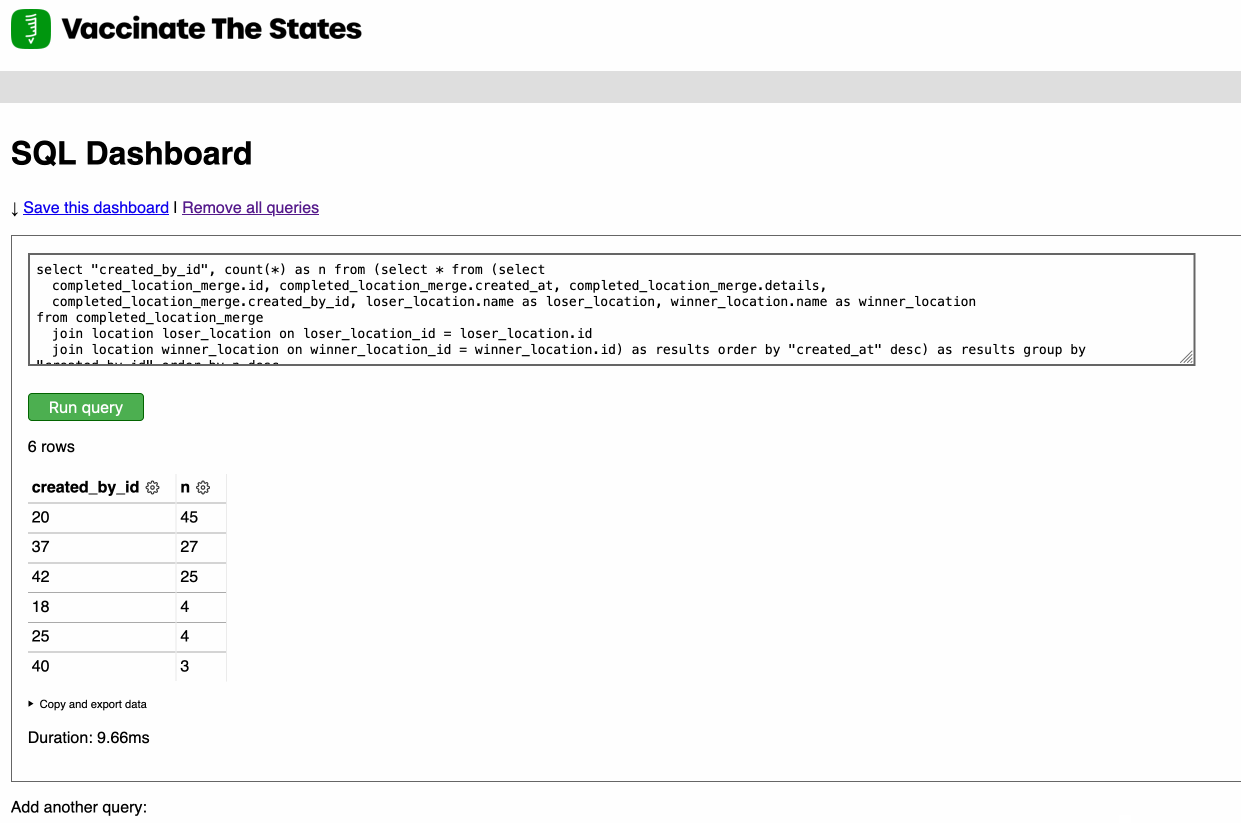
Earlier this week I released Django SQL Dashboard 1.0. I also just released 1.0.1, with a bug fix for PostgreSQL 10 contributed by Ryan Cheley.
[... 629 words]PostgreSQL: nbtree/README (via) The PostgreSQL source tree includes beatifully written README files for different parts of PostgreSQL. Here’s the README for their btree implementation—it continues to be actively maintained (last change was is March) and “git blame” shows that parts of the file date back 25 years, to 1996!
Hierarchical Structures in PostgreSQL (via) Two techniques I hadn’t seen before: the first is to define a materialized view using a CTE that offers efficient tree queries against a PostgreSQL array of path components (plus a trigger to update the materialized view), the second is with the PostgreSQL ltree extension which ships as part of PostgreSQL and hence should be widely available.
Multi-region PostgreSQL on Fly (via) Really interesting piece of architectural design from Fly here. Fly can run your application (as a Docker container run using Firecracker) in multiple regions around the world, and they’ve now quietly added PostgreSQL multi-region support. The way it works is that all-but-one region can have a read-only replica, and requests sent to application servers can perform read-only queries against their local region’s replica. If a request needs to execute a SQL update your application code can return a “fly-replay: region=scl” HTTP header and the Fly CDN will transparently replay the request against the region containing the leader database. This also means you can implement tricks like setting a 10s expiring cookie every time the user performs a write, such that their requests in the next 10s will go straight to the leader and avoid them experiencing any replication lag that hasn’t caught up with their latest update.
explain.dalibo.com (via) By far the best tool I’ve seen for turning the output of PostgreSQL EXPLAIN ANALYZE into something I can actually understand—produces a tree visualization which includes clear explanations of what each step (such as a “Index Only Scan Node”) actually means.
Django SQL Dashboard
I’ve released the first non-alpha version of Django SQL Dashboard, which provides an interface for running arbitrary read-only SQL queries directly against a PostgreSQL database, protected by the Django authentication scheme. It can also be used to create saved dashboards that can be published or shared internally.
[... 2,171 words]Practical SQL for Data Analysis
(via)
This is a really great SQL tutorial: it starts with the basics, but quickly moves on to a whole array of advanced PostgreSQL techniques - CTEs, window functions, efficient sampling, rollups, pivot tables and even linear regressions executed directly in the database using regr_slope(), regr_intercept() and regr_r2(). I picked up a whole bunch of tips for things I didn't know you could do with PostgreSQL here.