Weeknotes: Vaccinate The States, and how I learned that returning dozens of MB of JSON works just fine these days
26th April 2021
On Friday VaccinateCA grew in scope, a lot: we launched a new website called Vaccinate The States. Patrick McKenzie wrote more about the project here—the short version is that we’re building the most comprehensive possible dataset of vaccine availability in the USA, using a combination of data collation, online research and continuing to make a huge number of phone calls.
VIAL, the Django application I’ve been working on since late February, had to go through some extensive upgrades to help support this effort!
VIAL has a number of responsibilities. It acts as our central point of truth for the vaccination locations that we are tracking, powers the app used by our callers to serve up locations to call and record the results, and as-of this week it’s also a central point for our efforts to combine data from multiple other providers and scrapers.
The data ingestion work is happening in a public repository, CAVaccineInventory/vaccine-feed-ingest. I have yet to write a single line of code there (and I thoroughly enjoy working on that kind of code) because I’ve been heads down working on VIAL itself to ensure it can support the ingestion efforts.
Matching and concordances
If you’re combining data about vaccination locations from a range of different sources, one of the biggest challenges is de-duplicating the data: it’s important the same location doesn’t show up multiple times (potentially with slightly differing details) due to appearing in multiple sources.
Our first step towards handling this involved the addition of “concordance identifiers” to VIAL.
I first encountered the term “concordance” being used for this in the Who’s On First project, which is building a gazetteer of every city/state/country/county/etc on earth.
A concordance is an identifier in another system. Our location ID for RITE AID PHARMACY 05976 in Santa Clara is receu5biMhfN8wH7P—which is e3dfcda1-093f-479a-8bbb-14b80000184c in VaccineFinder and 7537904 in Vaccine Spotter and ChIJZaiURRPKj4ARz5nAXcWosUs in Google Places.
We’re storing them in a Django table called ConcordanceIdentifier: each record has an authority (e.g. vaccinespotter_org) and an identifier (7537904) and a many-to-many relationship to our Location model.
Why many-to-many? Surely we only want a single location for any one of these identifiers?
Exactly! That’s why it’s many-to-many: because if we import the same location twice, then assign concordance identifiers to it, we can instantly spot that it’s a duplicate and needs to be merged.
Raw data from scrapers
ConcordanceIdentifier also has a many-to-many relationship with a new table, called SourceLocation. This table is essentially a PostgreSQL JSON column with a few other columns (including latitude and longitude) into which our scrapers and ingesters can dump raw data. This means we can use PostgreSQL queries to perform all kinds of analysis on the unprocessed data before it gets cleaned up, de-duplicated and loaded into our point-of-truth Location table.
How to dedupe and match locations?
Initially I thought we would do the deduping and matching inside of VIAL itself, using the raw data that had been ingested into the SourceLocation table.
Since we were on a tight internal deadline it proved more practical for people to start experimenting with matching code outside of VIAL. But that meant they needed the raw data—40,000+ location records (and growing rapidly).
A few weeks ago I built a CSV export feature for the VIAL admin screens, using Django’s StreamingHttpResponse class combined with keyset pagination for bulk export without sucking the entire table into web server memory—details in this TIL.
Our data ingestion team wanted a GeoJSON export—specifically newline-delimited GeoJSON—which they could then load into GeoPandas to help run matching operations.
So I built a simple “search API” which defaults to returning 20 results at a time, but also has an option to “give me everything”—using the same technique I used for the CSV export: keyset pagination combined with a StreamingHttpResponse.
And it worked! It turns out that if you’re running on modern infrastructure (Cloud Run and Cloud SQL in our case) in 2021 getting Django to return 50+MB of JSON in a streaming response works just fine.
Some of these exports are taking 20+ seconds, but for a small audience of trusted clients that’s completely fine.
While working on this I realized that my idea of what size of data is appropriate for a dynamic web application to return more or less formed back in 2005. I still think it’s rude to serve multiple MBs of JavaScript up to an inexpensive mobile phone on an expensive connection, but for server-to-server or server-to-automation-script situations serving up 50+ MB of JSON in one go turns out to be a perfectly cromulent way of doing things.
Export full results from django-sql-dashboard
django-sql-dashboard is my Datasette-inspired library for adding read-only arbitrary SQL queries to any Django+PostgreSQL application.
I built the first version last month to help compensate for switching VaccinateCA away from Airtable—one of the many benefits of Airtable is that it allows all kinds of arbitrary reporting, and Datasette has shown me that bookmarkable SQL queries can provide a huge amount of that value with very little written code, especially within organizations where SQL is already widely understood.
While it allows people to run any SQL they like (against a read-only PostgreSQL connection with a time limit) it restricts viewing to the first 1,000 records to be returned—because building robust, performant pagination against arbitrary SQL queries is a hard problem to solve.
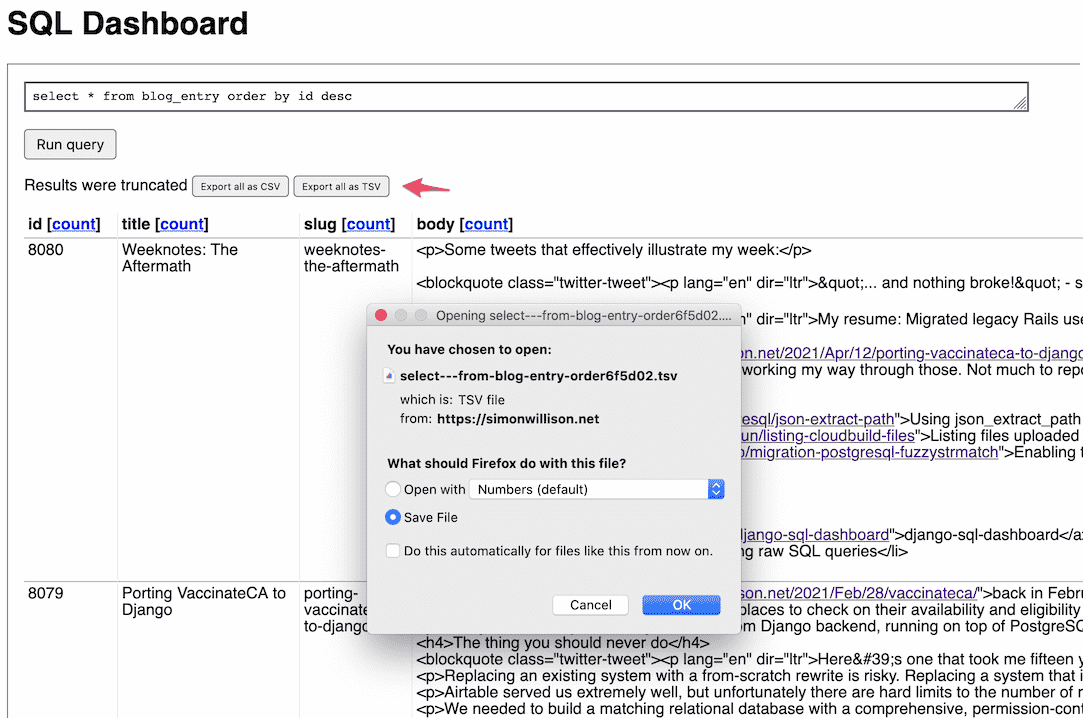
Today I released django-sql-dashboard 0.10a0 with the ability to export all results for a query as a downloadable CSV or TSV file, using the same StreamingHttpResponse technique as my Django admin CSV export and all-results-at-once search endpoint.
I expect it to be pretty useful! It means I can run any SQL query I like against a Django project and get back the full results—often dozens of MBs—in a form I can import into other tools (including Datasette).
TIL this week
- Usable horizontal scrollbars in the Django admin for mouse users
- Filter by comma-separated values in the Django admin
- Constructing GeoJSON in PostgreSQL
- Django Admin action for exporting selected rows as CSV
Releases this week
-
django-sql-dashboard: 0.10a1—(21 total releases)—2021-04-25
Django app for building dashboards using raw SQL queries
More recent articles
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026