1,526 posts tagged “datasette”
Datasette is an open source tool for exploring and publishing data.
2025
In addition to my workshop the other day I'm also participating in the poster session at PyCon US this year.
This means that tomorrow (Sunday 18th May) I'll be hanging out next to my poster from 10am to 1pm in Hall A talking to people about my various projects.
I'll confess: I didn't pay close enough attention to the poster information, so when I first put my poster up it looked a little small:

... so I headed to the nearest CVS and printed out some photos to better represent my interests and personality. I'm going for a "teenage bedroom" aesthetic here, I'm very happy with the result:

Here's the poster in the middle (also available as a PDF). It has columns for Datasette, sqlite-utils and LLM.

If you're at PyCon I'd love to talk to you about things I'm working on!
Update: Thanks to everyone who came along. Here's a 6MB photo of the poster setup. The museums were all from my www.niche-museums.com site and the pelicans riding a bicycle SVGs came from my pelican-riding-a-bicycle tag.
{kind=link}
django-simple-deploy. Eric Matthes presented a lightning talk about this project at PyCon US this morning. "Django has a deploy command now". You can run it like this:
pip install django-simple-deploy[fly_io]
# Add django_simple_deploy to INSTALLED_APPS.
python manage.py deploy --automate-all
It's plugin-based (inspired by Datasette!) and the project has stable plugins for three hosting platforms: dsd-flyio, dsd-heroku and dsd-platformsh.
Currently in development: dsd-vps - a plugin that should work with any VPS provider, using Paramiko to connect to a newly created instance and run all of the commands needed to start serving a Django application.
Introducing Datasette for Newsrooms. We're introducing a new product suite today called Datasette for Newsrooms - a bundled collection of Datasette Cloud features built specifically for investigative journalists and data teams. We're describing it as an all-in-one data store, search engine, and collaboration platform designed to make working with data in a newsroom easier, faster, and more transparent.
If your newsroom could benefit from a managed version of Datasette we would love to hear from you. We're offering it to nonprofit newsrooms for free for the first year (they can pay us in feedback), and we have a two month trial for everyone else.
Get in touch at hello@datasette.cloud if you'd like to try it out.
One crucial detail: we will help you get started - we'll load data into your instance for you (you get some free data engineering!) and walk you through how to use it, and we will eagerly consume any feedback you have for us and prioritize shipping anything that helps you use the tool. Our unofficial goal: we want someone to win a Pulitzer for investigative reporting where our tool played a tiny part in their reporting process.
Here's an animated GIF demo (taken from our new Newsrooms landing page) of my favorite recent feature: the ability to extract structured data into a table starting with an unstructured PDF, using the latest version of the datasette-extract plugin.

The single most impactful investment I’ve seen AI teams make isn’t a fancy evaluation dashboard—it’s building a customized interface that lets anyone examine what their AI is actually doing. I emphasize customized because every domain has unique needs that off-the-shelf tools rarely address. When reviewing apartment leasing conversations, you need to see the full chat history and scheduling context. For real-estate queries, you need the property details and source documents right there. Even small UX decisions—like where to place metadata or which filters to expose—can make the difference between a tool people actually use and one they avoid. [...]
Teams with thoughtfully designed data viewers iterate 10x faster than those without them. And here’s the thing: These tools can be built in hours using AI-assisted development (like Cursor or Loveable). The investment is minimal compared to the returns.
— Hamel Husain, A Field Guide to Rapidly Improving AI Products
files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
URL-addressable Pyodide Python environments
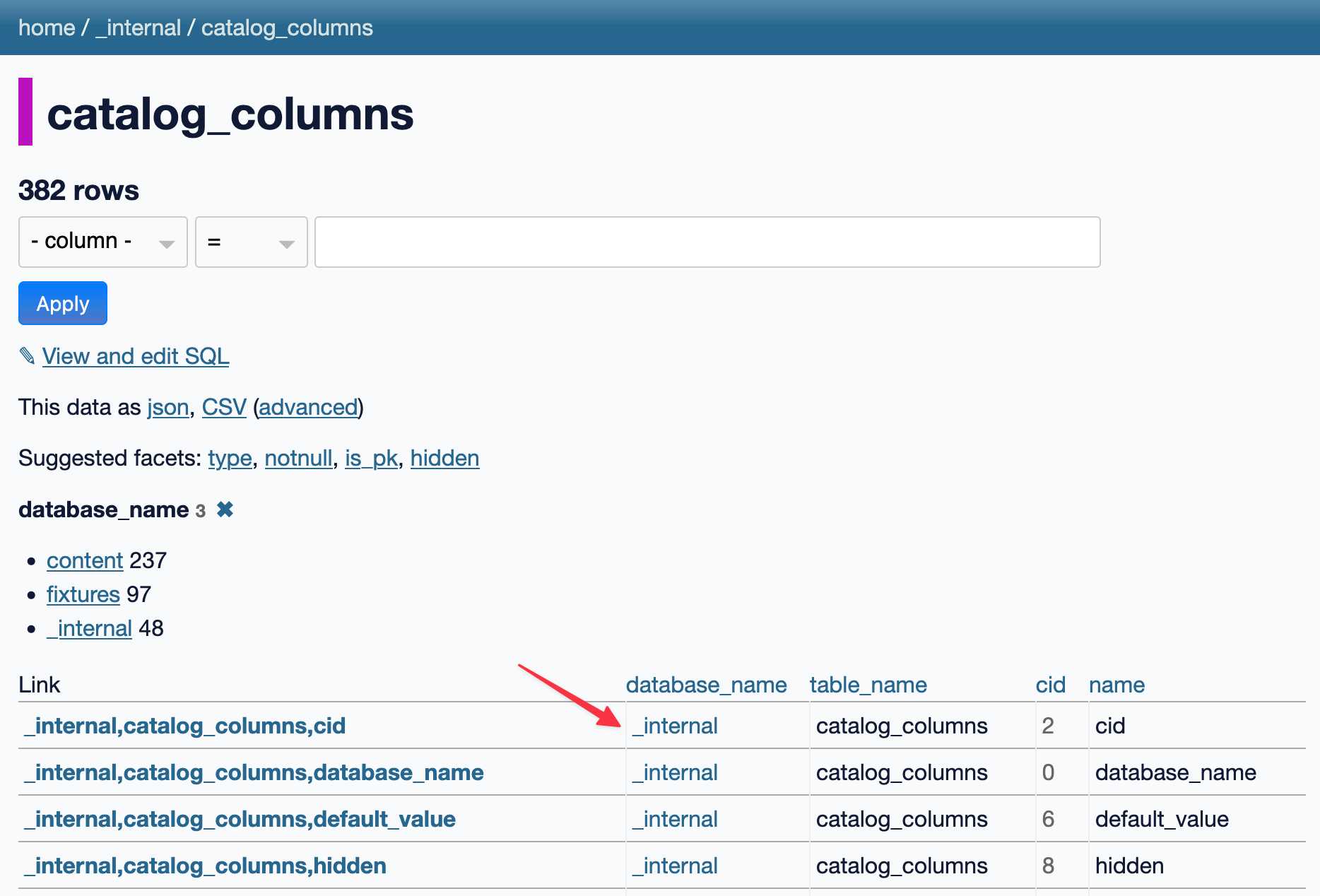
This evening I spotted an obscure bug in Datasette, using Datasette Lite. I figure it’s a good opportunity to highlight how useful it is to have a URL-addressable Python environment, powered by Pyodide and WebAssembly.
[... 1,905 words]Datasette 1.0a17. New Datasette alpha, with a bunch of small changes and bug fixes accumulated over the past few months. Some (minor) highlights:
- The register_magic_parameters(datasette) plugin hook can now register async functions. (#2441)
- Breadcrumbs on database and table pages now include a consistent self-link for resetting query string parameters. (#2454)
- New internal methods
datasette.set_actor_cookie()anddatasette.delete_actor_cookie(), described here. (#1690)/-/permissionspage now shows a list of all permissions registered by plugins. (#1943)- If a table has a single unique text column Datasette now detects that as the foreign key label for that table. (#2458)
- The
/-/permissionspage now includes options for filtering or exclude permission checks recorded against the current user. (#2460)
I was incentivized to push this release by an issue I ran into in my new datasette-load plugin, which resulted in this fix:
- Fixed a bug where replacing a database with a new one with the same name did not pick up the new database correctly. (#2465)
S1: The $6 R1 Competitor? Tim Kellogg shares his notes on a new paper, s1: Simple test-time scaling, which describes an inference-scaling model fine-tuned on top of Qwen2.5-32B-Instruct for just $6 - the cost for 26 minutes on 16 NVIDIA H100 GPUs.
Tim highlight the most exciting result:
After sifting their dataset of 56K examples down to just the best 1K, they found that the core 1K is all that's needed to achieve o1-preview performance on a 32B model.
The paper describes a technique called "Budget forcing":
To enforce a minimum, we suppress the generation of the end-of-thinking token delimiter and optionally append the string “Wait” to the model’s current reasoning trace to encourage the model to reflect on its current generation
That's the same trick Theia Vogel described a few weeks ago.
Here's the s1-32B model on Hugging Face. I found a GGUF version of it at brittlewis12/s1-32B-GGUF, which I ran using Ollama like so:
ollama run hf.co/brittlewis12/s1-32B-GGUF:Q4_0
I also found those 1,000 samples on Hugging Face in the simplescaling/s1K data repository there.
I used DuckDB to convert the parquet file to CSV (and turn one VARCHAR[] column into JSON):
COPY (
SELECT
solution,
question,
cot_type,
source_type,
metadata,
cot,
json_array(thinking_trajectories) as thinking_trajectories,
attempt
FROM 's1k-00001.parquet'
) TO 'output.csv' (HEADER, DELIMITER ',');
Then I loaded that CSV into sqlite-utils so I could use the convert command to turn a Python data structure into JSON using json.dumps() and eval():
# Load into SQLite
sqlite-utils insert s1k.db s1k output.csv --csv
# Fix that column
sqlite-utils convert s1k.db s1u metadata 'json.dumps(eval(value))' --import json
# Dump that back out to CSV
sqlite-utils rows s1k.db s1k --csv > s1k.csv
Here's that CSV in a Gist, which means I can load it into Datasette Lite.
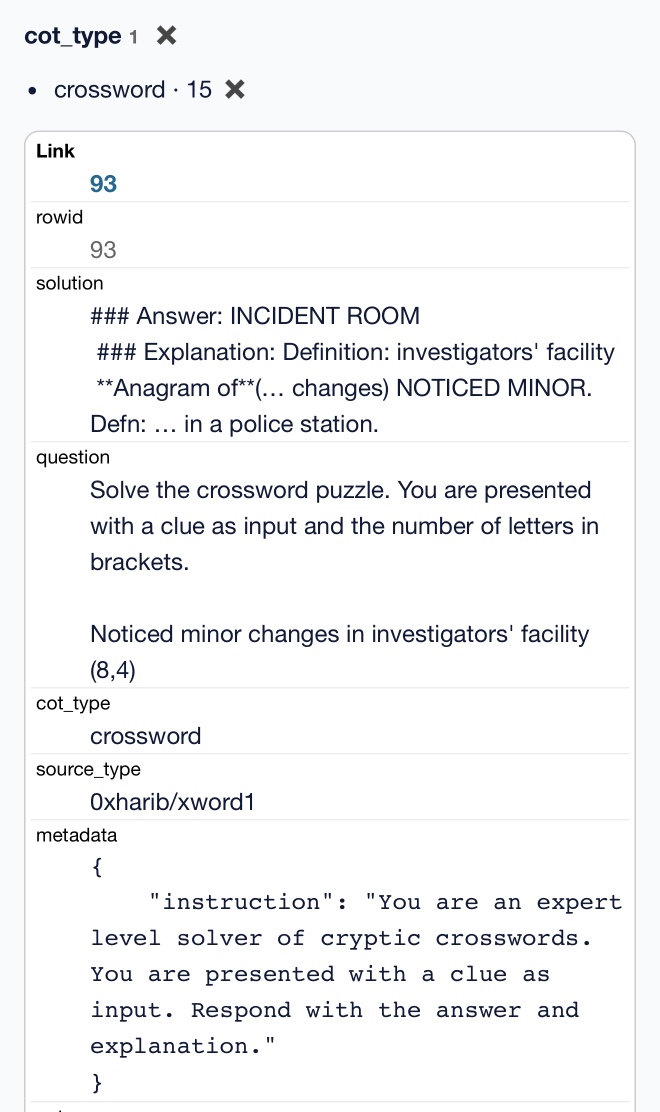
It really is a tiny amount of training data. It's mostly math and science, but there are also 15 cryptic crossword examples.
o3-mini is really good at writing internal documentation. I wanted to refresh my knowledge of how the Datasette permissions system works today. I already have extensive hand-written documentation for that, but I thought it would be interesting to see if I could derive any insights from running an LLM against the codebase.
o3-mini has an input limit of 200,000 tokens. I used LLM and my files-to-prompt tool to generate the documentation like this:
cd /tmp
git clone https://github.com/simonw/datasette
cd datasette
files-to-prompt datasette -e py -c | \
llm -m o3-mini -s \
'write extensive documentation for how the permissions system works, as markdown'The files-to-prompt command is fed the datasette subdirectory, which contains just the source code for the application - omitting tests (in tests/) and documentation (in docs/).
The -e py option causes it to only include files with a .py extension - skipping all of the HTML and JavaScript files in that hierarchy.
The -c option causes it to output Claude's XML-ish format - a format that works great with other LLMs too.
You can see the output of that command in this Gist.
Then I pipe that result into LLM, requesting the o3-mini OpenAI model and passing the following system prompt:
write extensive documentation for how the permissions system works, as markdown
Specifically requesting Markdown is important.
The prompt used 99,348 input tokens and produced 3,118 output tokens (320 of those were invisible reasoning tokens). That's a cost of 12.3 cents.
Honestly, the results are fantastic. I had to double-check that I hadn't accidentally fed in the documentation by mistake.
(It's possible that the model is picking up additional information about Datasette in its training set, but I've seen similar high quality results from other, newer libraries so I don't think that's a significant factor.)
In this case I already had extensive written documentation of my own, but this was still a useful refresher to help confirm that the code matched my mental model of how everything works.
Documentation of project internals as a category is notorious for going out of date. Having tricks like this to derive usable how-it-works documentation from existing codebases in just a few seconds and at a cost of a few cents is wildly valuable.