Weeknotes: git-history, created for a Git scraping workshop
15th November 2021
My main project this week was a 90 minute workshop I delivered about Git scraping at Coda.Br 2021, a Brazilian data journalism conference, on Friday. This inspired the creation of a brand new tool, git-history, plus smaller improvements to a range of other projects.
git-history
I still need to do a detailed write-up of this one (update: git-history: a tool for analyzing scraped data collected using Git and SQLite), but on Thursday I released a brand new tool called git-history, which I describe as “tools for analyzing Git history using SQLite”.
This tool is the missing link in the Git scraping pattern I described here last October.
Git scraping is the technique of regularly scraping an online source of information and writing the results to a file in a Git repository... which automatically gives you a full revision history of changes made to that data source over time.
The missing piece has always been what to do next: how do you turn a commit history of changes to a JSON or CSV file into a data source that can be used to answer questions about how that file changed over time?
I’ve written one-off Python scripts for this a few times (here’s my CDC vaccinations one, for example), but giving an interactive workshop about the technique finally inspired me to build a tool to help.
The tool has a comprehensive README, but the short version is that you can take a JSON (or CSV) file in a repository that has been tracking changes to some items over time and run the following to load all of the different versions into a SQLite database file for analysis with Datasette:
git-convert file incidents.db incidents.json --id IncidentID
This assumes that incidents.json contains a JSON array of incidents (reported fires for example) and that each incident has a IncidentID identifier key. It will then loop through the Git history of that file right from the start, creating an item_versions table that tracks every change made to each of those items—using IncidentID to decide if a row represents a new incident or an update to a previous one.
I have a few more improvements I want to make before I start more widely promoting this, but it’s already really useful. I’ve had a lot of fun running it against example repos from the git-scraping GitHub topic (now at 202 repos and counting).
Workshop: Raspando dados com o GitHub Actions e analisando com Datasette
The workshop I gave at the conference was live-translated into Portuguese, which is really exciting! I’m looking forward to watching the video when it comes out and seeing how well that worked.
The title translates to “Scraping data with GitHub Actions and analyzing with Datasette”, and it was the first time I’ve given a workshop that combines Git scraping and Datasette—hence the development of the new git-history tool to help tie the two together.
I think it went really well. I put together four detailed exercises for the attendees, and then worked through each one live with the goal of attendees working through them at the same time—a method I learned from the Carpentries training course I took last year.
Four exercises turns out to be exactly right for 90 minutes, with reasonable time for an introduction and some extra material and questions at the end.
The worst part of running a workshop is inevitably the part where you try and get everyone setup with a functional development environment on their own machines (see XKCD 1987). This time round I skipped that entirely by encouraging my students to use GitPod, which provides free browser-based cloud development environments running Linux, with a browser-embedded VS Code editor and terminal running on top.
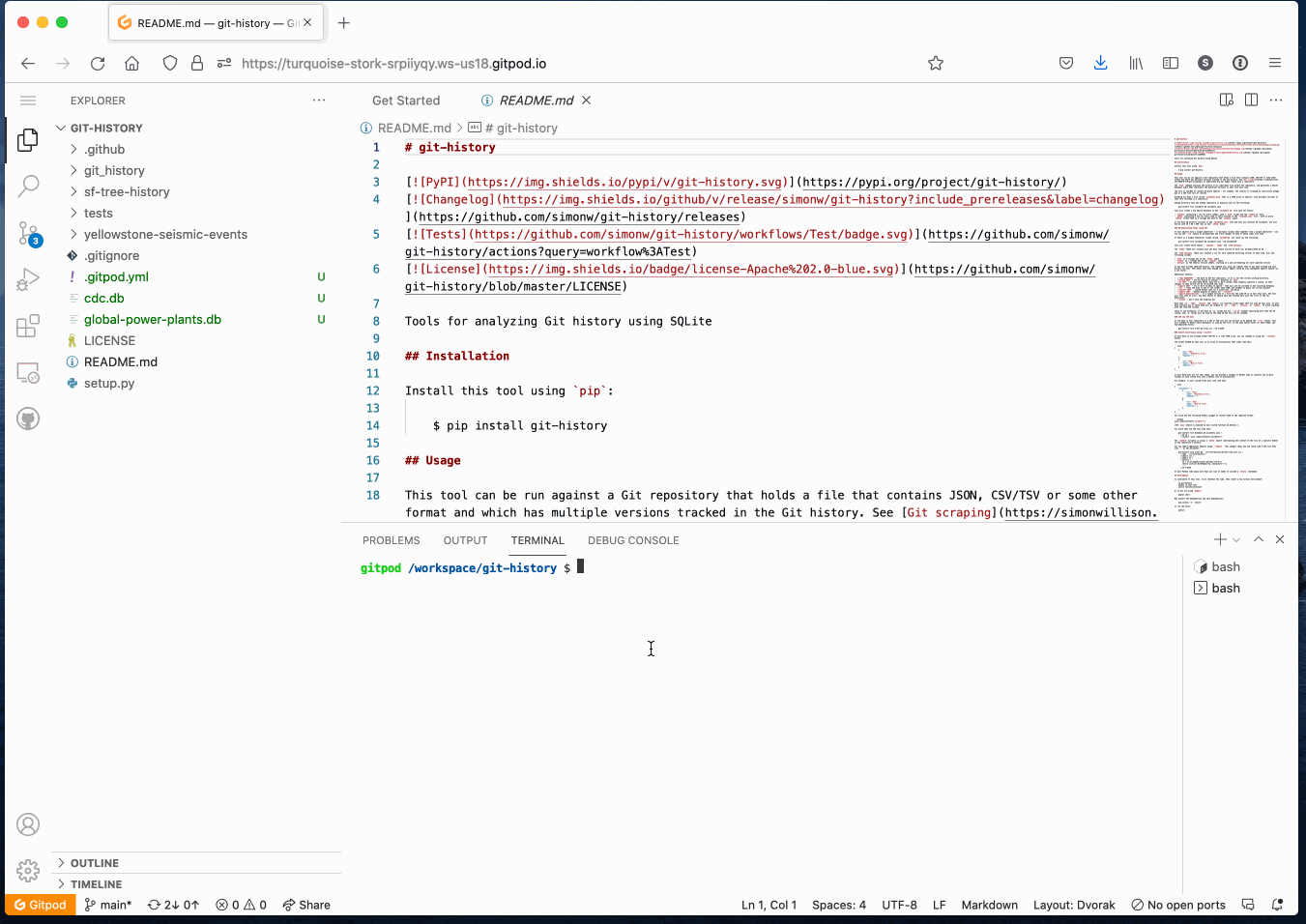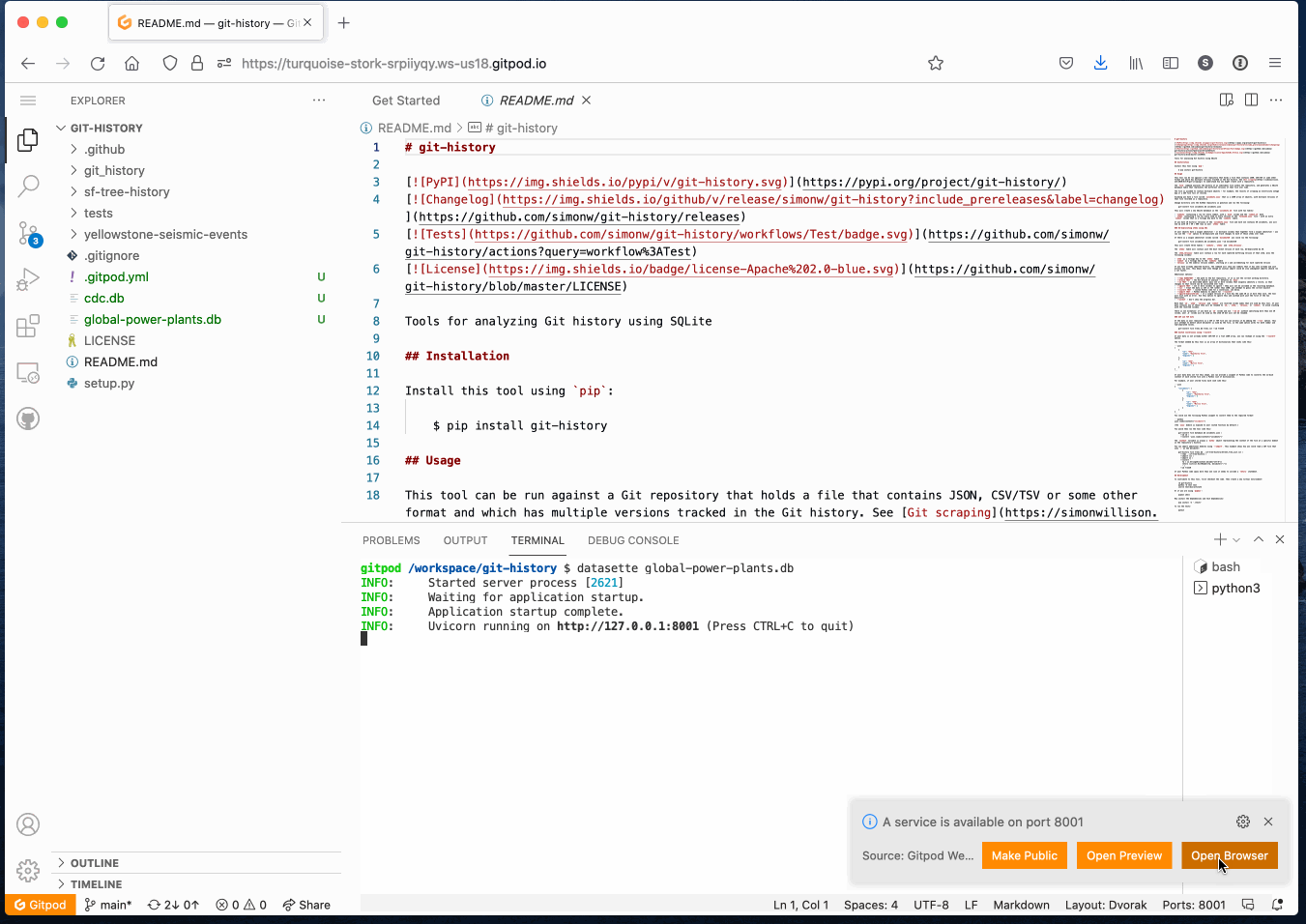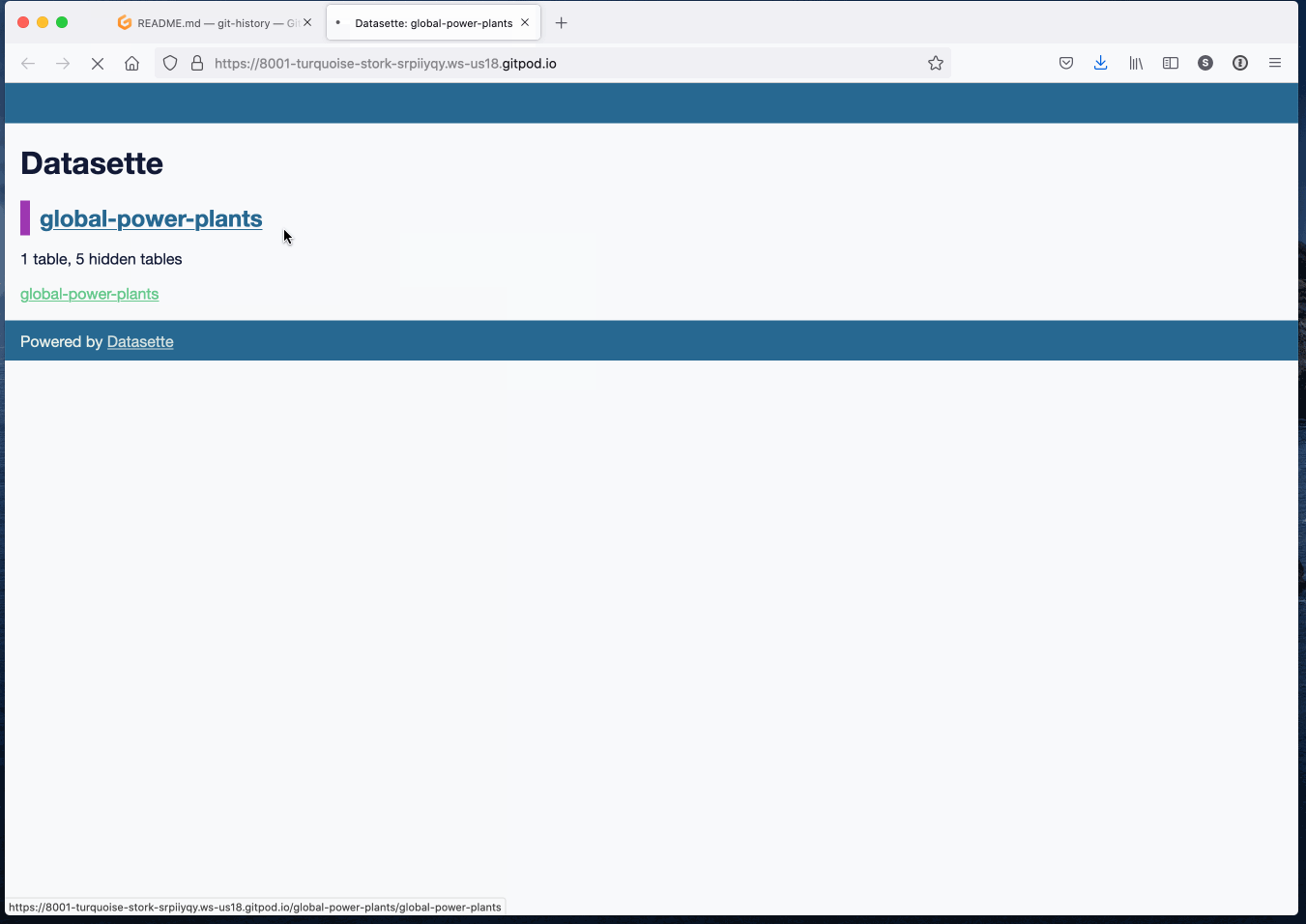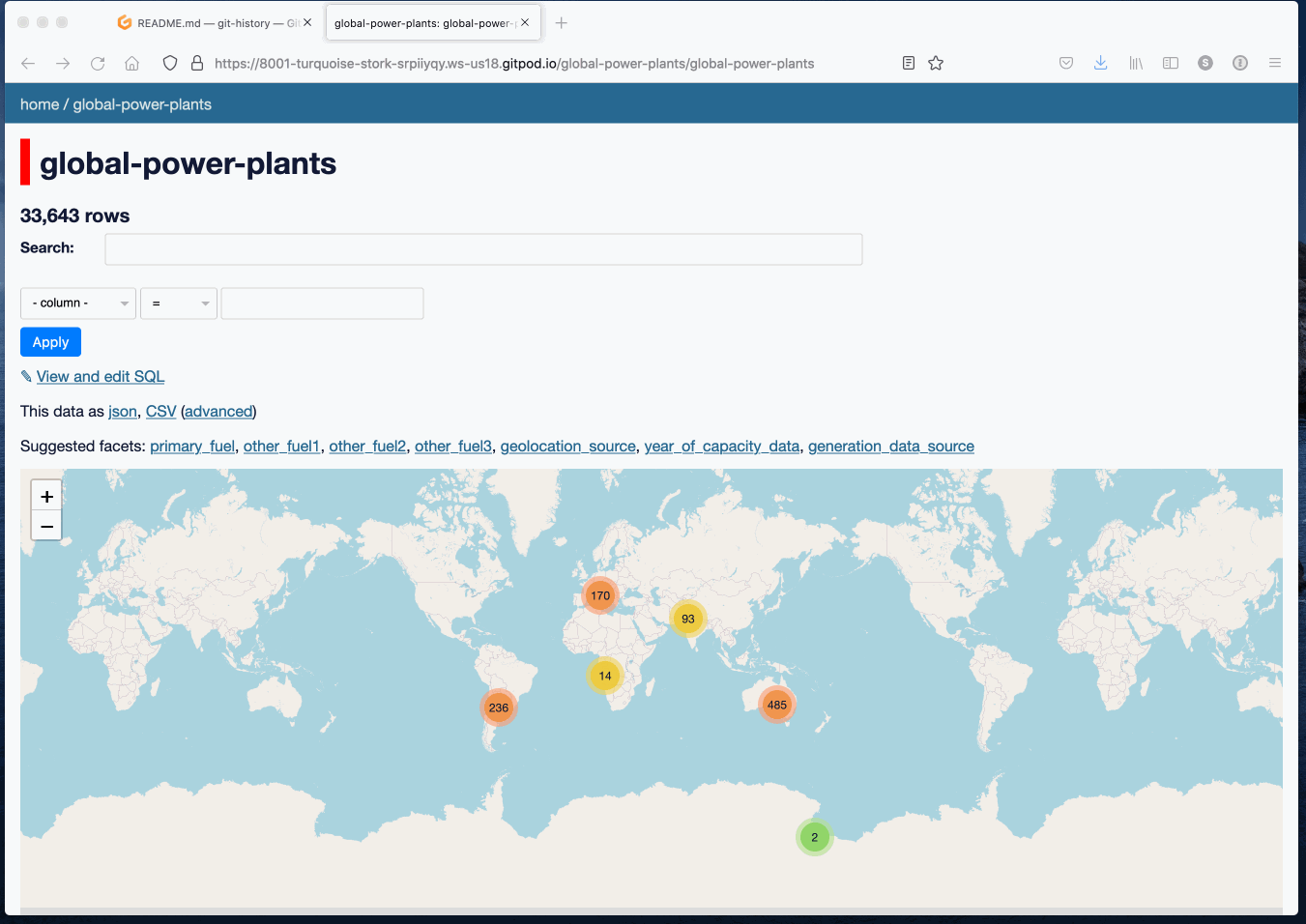
(It’s similar to GitHub Codespaces, but Codespaces is not yet available to free customers outside of the beta.)
I demonstrated all of the exercises using GitPod myself during the workshop, and ensured that they could be entirely completed through that environment, with no laptop software needed at all.
This worked so well. Not having to worry about development environments makes workshops massively more productive. I will absolutely be doing this again in the future.
The workshop exercises are available in this Google Doc, and I hope to extract some of them out into official tutorials for various tools later on.
Datasette 0.58.2
Yesterday was Datasette’s fourth birthday—the four year anniversary of the initial release announcement! I celebrated by releasing a minor bug-fix, Datasette 0.58.2, the release notes for which are quoted below:
- Column names with a leading underscore now work correctly when used as a facet. (#1506)
- Applying
?_nocol=to a column no longer removes that column from the filtering interface. (#1503) - Official Datasette Docker container now uses Debian Bullseye as the base image. (#1497)
That first change was inspired by ongoing work on git-history, where I decided to use a _id underscoper prefix pattern for columns that were reserved for use by that tool in order to avoid clashing with column names in the provided source data.
sqlite-utils 3.18
Today I released sqlite-utils 3.18—initially also to provide a feature I wanted for git-history (a way to populate additional columns when creating a row using table.lookup()) but I also closed some bug reports and landed some small pull requests that had come in since 3.17.
s3-credentials 0.5
Earlier in the week I released version 0.5 of s3-credentials—my CLI tool for creating read-only, read-write or write-only AWS credentials for a specific S3 bucket.
The biggest new feature is the ability to create temporary credentials, that expire after a given time limit.
This is achived using STS.assume_role(), where STS is Security Token Service. I’ve been wanting to learn this API for quite a while now.
Assume role comes with some limitations: tokens must live between 15 minutes and 12 hours, and you need to first create a role that you can assume. In creating those credentials you can define an additional policy document, which is how I scope down the token I’m creating to only allow a specific level of access to a specific S3 bucket.
I’ve learned a huge amount about AWS, IAM and S3 through developming this project. I think I’m finally overcoming my multi-year phobia of anything involving IAM!
Releases this week
-
sqlite-utils: 3.18—(88 releases total)—2021-11-15
Python CLI utility and library for manipulating SQLite databases -
datasette: 0.59.2—(100 releases total)—2021-11-14
An open source multi-tool for exploring and publishing data -
datasette-hello-world: 0.1.1—(2 releases total)—2021-11-14
The hello world of Datasette plugins -
git-history: 0.3.1—(5 releases total)—2021-11-12
Tools for analyzing Git history using SQLite -
s3-credentials: 0.5—(5 releases total)—2021-11-11
A tool for creating credentials for accessing S3 buckets
TIL this week
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026