Datasette: instantly create and publish an API for your SQLite databases
13th November 2017
I just shipped the first public version of datasette, a new tool for creating and publishing JSON APIs for SQLite databases.
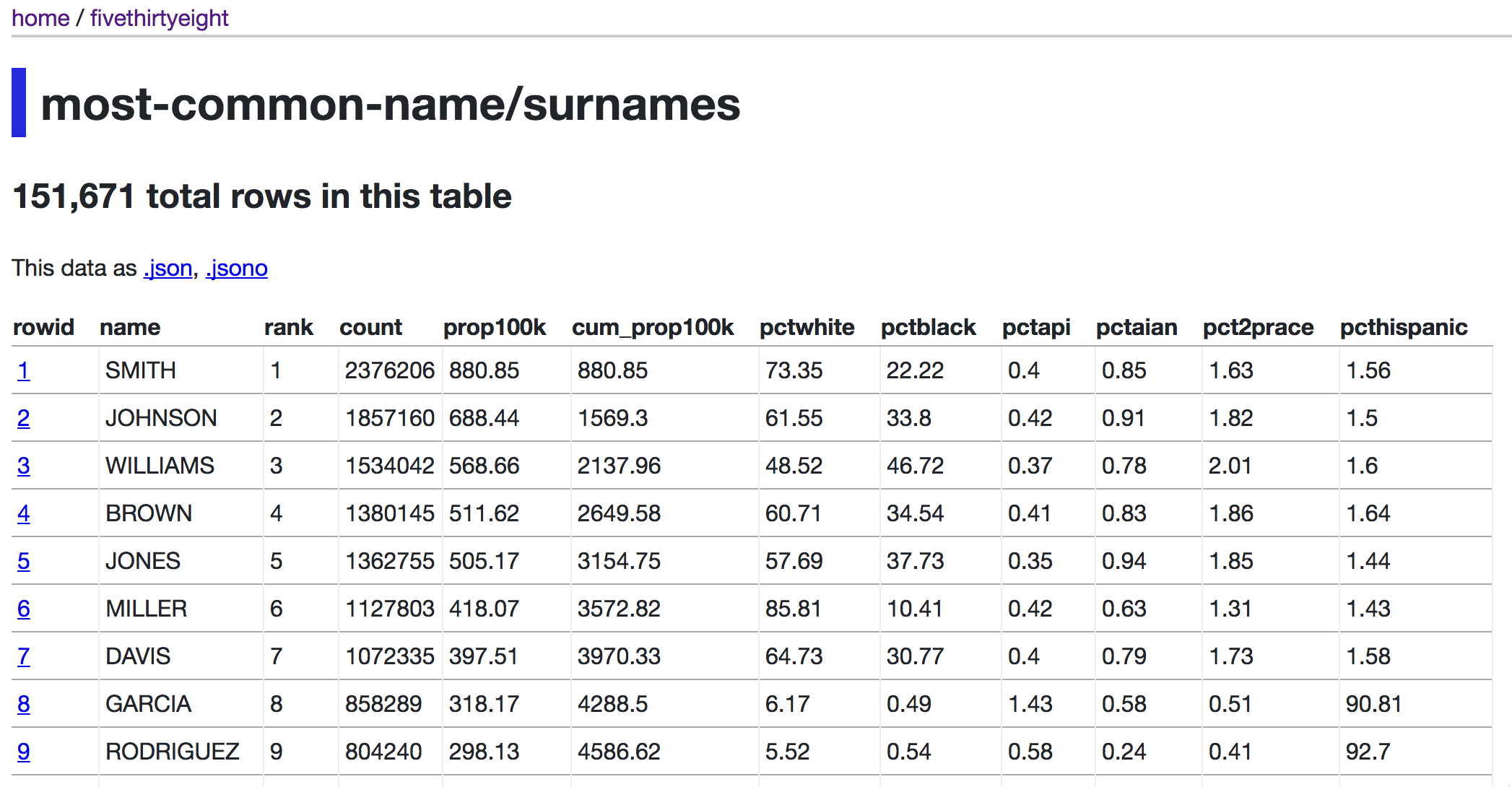
You can try out out right now at fivethirtyeight.datasettes.com, where you can explore SQLite databases I built from Creative Commons licensed CSV files published by FiveThirtyEight. Or you can check out parlgov.datasettes.com, derived from the parlgov.org database of world political parties which illustrates some advanced features such as SQLite views.
Or you can try it out on your own machine. If you run OS X and use Google Chrome, try running the following:
pip3 install datasette
datasette ~/Library/Application\ Support/Google/Chrome/Default/History
This will start a web server on http://127.0.0.1:8001/ displaying an interface that will let you browse your Chrome browser history, which is conveniently stored in a SQLite database.
Got a SQLite database you want to share with the world? Provided you have Zeit Now set up on your machine, you can publish one or more databases with a single command:
datasette publish now my-database.db
The above command will whir away for about a minute and then spit out a URL to a hosted version of datasette with your database (or databases) ready to go. This is how I’m hosting the fivethirtyeight and parlgov example datasets, albeit on a custom domain behind a Cloudflare cache.
The datasette API
Everything datasette can do is driven by URLs. Queries can produce responsive HTML pages (I’m using a variant of this responsive tables pattern for smaller screens) or with the .json or .jsono extension can produce JSON. All JSON responses are served with an Access-Control-Allow-Origin: * HTTP header, meaning you can query them from any page.
You can try that right now in your browser’s developer console. Navigate to http://www.example.com/ and enter the following in the console:
fetch(
"https://fivethirtyeight.datasettes.com/fivethirtyeight-2628db9/avengers%2Favengers.jsono"
).then(
r => r.json()
).then(data => console.log(
JSON.stringify(data.rows[0], null, ' ')
))
You’ll see the following:
{
"rowid": 1,
"URL": "http://marvel.wikia.com/Henry_Pym_(Earth-616)",
"Name/Alias": "Henry Jonathan \"Hank\" Pym",
"Appearances": 1269,
"Gender": "MALE",
"Full/Reserve Avengers Intro": "Sep-63",
"Year": 1963,
"Years since joining": 52,
...
}
Since the API sits behind Cloudflare with a year-long cache expiry header, responses to any query like this should be lightning-fast.
Datasette supports a limited form of filtering based on URL parameters, inspired by Django’s ORM. Here’s an example: by appending ?CLOUDS=1&MOUNTAINS=1&BUSHES=1 to the FiveThirtyEight dataset of episodes of Bob Ross’ The Joy of Painting we can see every episode in which Bob paints clouds, bushes AND mountains:
And here’s the same episode list as JSON.
Arbitrary SQL
The most exciting feature of datasette is that it allows users to execute arbitrary SQL queries against the database. Here’s a convoluted Bob Ross example, returning a count for each of the items that can appear in a painting.
Datasette has a number of limitations in place here: it cuts off any SQL queries that take longer than a threshold (defaulting to 1000ms) and it refuses to return more than 1,000 rows at a time—partly to avoid too much JSON serialization overhead.
Datasette also blocks queries containing the string PRAGMA, since these statements could be used to modify database settings at runtime. If you need to include PRAGMA in an argument to a query you can do so by constructing a prepared statement:
select * from [twitter-ratio/senators] where "text" like :q
You can then construct a URL that incorporates both the SQL and provides a value for that named argument, like this: https://fivethirtyeight.datasettes.com/fivethirtyeight-2628db9?sql=select+rowid%2C+*+from+[twitter-ratio%2Fsenators]+where+“text”+like+%3Aq&q=%25pragmatic%25—which returns tweets by US senators that include the word “pragmatic”.
Why an immutable API?
A key feature of datasette is that the API it provides is very deliberately read-only. This provides a number of interesting benefits:
- It lets us use SQLite in production in high traffic scenarios. SQLite is an incredible piece of technology, but it is rarely used in web application contexts due to its limitations with respect to concurrent writes. Datasette opens SQLite files using the immutable option, eliminating any concurrency concerns and allowing SQLite to go even faster for reads.
- Since the database is read-only, we can accept arbitrary SQL queries from our users!
- The datasette API bakes the first few characters of the sha256 hash of the database file contents into the API URLs themselves—for example in https://parlgov.datasettes.com/parlgov-25f9855/cabinet. This lets us serve year-long HTTP cache expiry headers, safe in the knowledge that any changes to the data will result in a change to the URL. These cache headers cause the content to be cached by both browsers and intermediary caches, such as Cloudflare.
- Read-only data makes datasette an ideal candidate for containerization. Deployments to Zeit Now happen using a Docker container, and the
datasette packagecommand can be used to build a Docker image that bundles the database files and the datasette application together. If you need to scale to handle vast amounts of traffic, just deploy a bunch of extra containers and load-balance between them.
Implementation notes
Datasette is built on top of the Sanic asynchronous Python web framework (see my previous notes), and makes extensive use of Python 3’s async/await statements. Since SQLite doesn’t yet have an async Python module all interactions with SQLite are handled inside a thread pool managed by a concurrent.futures.ThreadPoolExecutor.
The CLI is implemented using the Click framework. This is the first time I’ve used Click and it was an absolute joy to work with. I enjoyed it so much I turned one of my Jupyter notebooks into a Click script called csvs-to-sqlite and published it to PyPI.
This post is being discussed on a Hacker News.
More recent articles
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026