New in Datasette: filters, foreign keys and search
25th November 2017
I’ve released Datasette 0.13 with a number of exciting new features (Datasette previously).
Filters
Datasette’s table view supports query-string based filtering. 0.13 introduces a new user interface for constructing those filters. Let’s use it to find every episode where Bob Ross painted clouds and mountains in season 3 of The Joy of Painting:
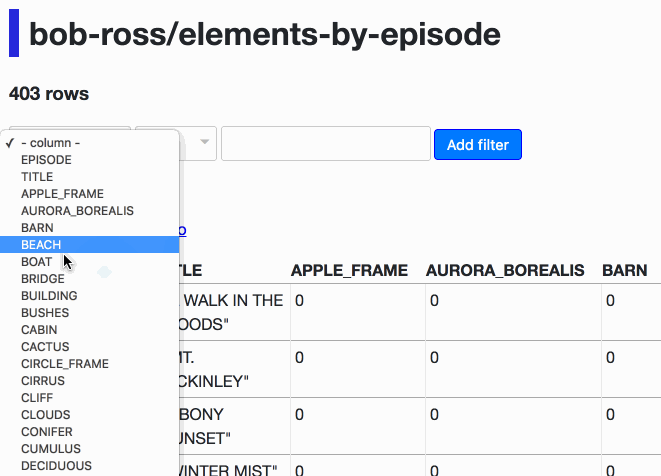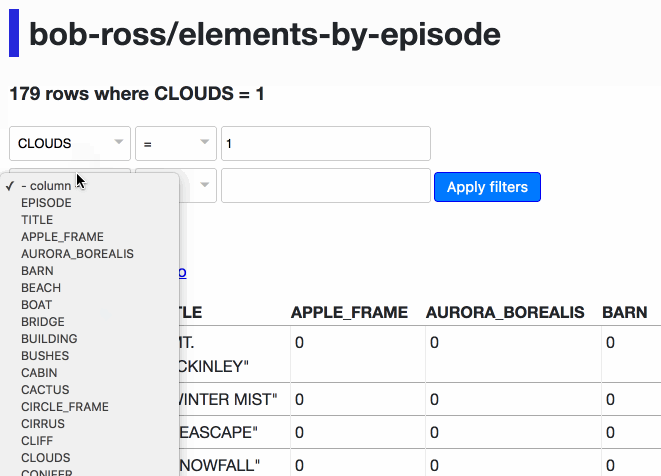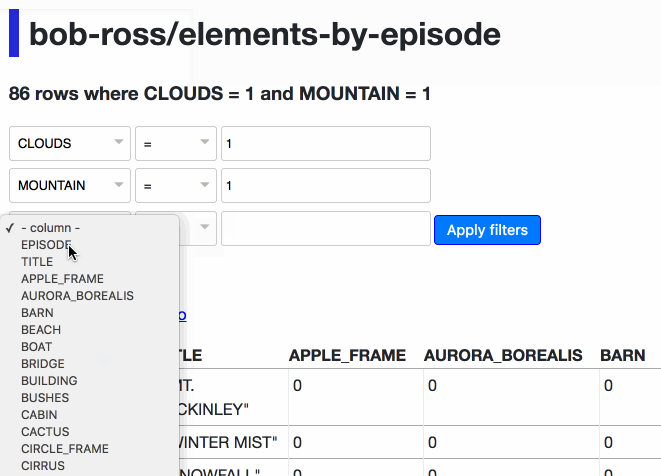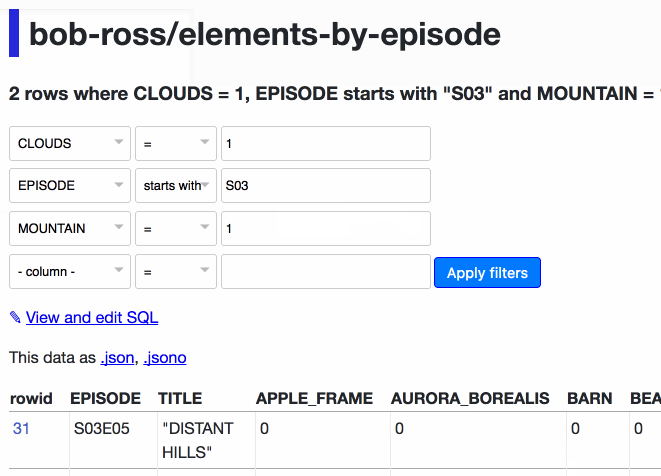
The resulting querystring looks like this:
?CLOUDS__exact=1&EPISODE__startswith=S03&MOUNTAIN__exact=1
Using the .json or .jsono extension on the same URL returns JSON (in list-of-lists or list-of-objects format), so the new filter UI also acts as a simple API explorer. If you click “View and edit SQL” you will get the generated SQL in an editor, ready for you to further modify it.
Foreign key relationships
Datasette now provides special treatment for SQLite foreign key relationships: if it detects a foreign key when displaying a table it will show values in that column as links to the related records—and if the foreign key table has an obvious label column, that label will be displayed in the column as the link label.
Here’s an example, using San Francisco’s Mobile Food Facility Permit dataset… aka food trucks!
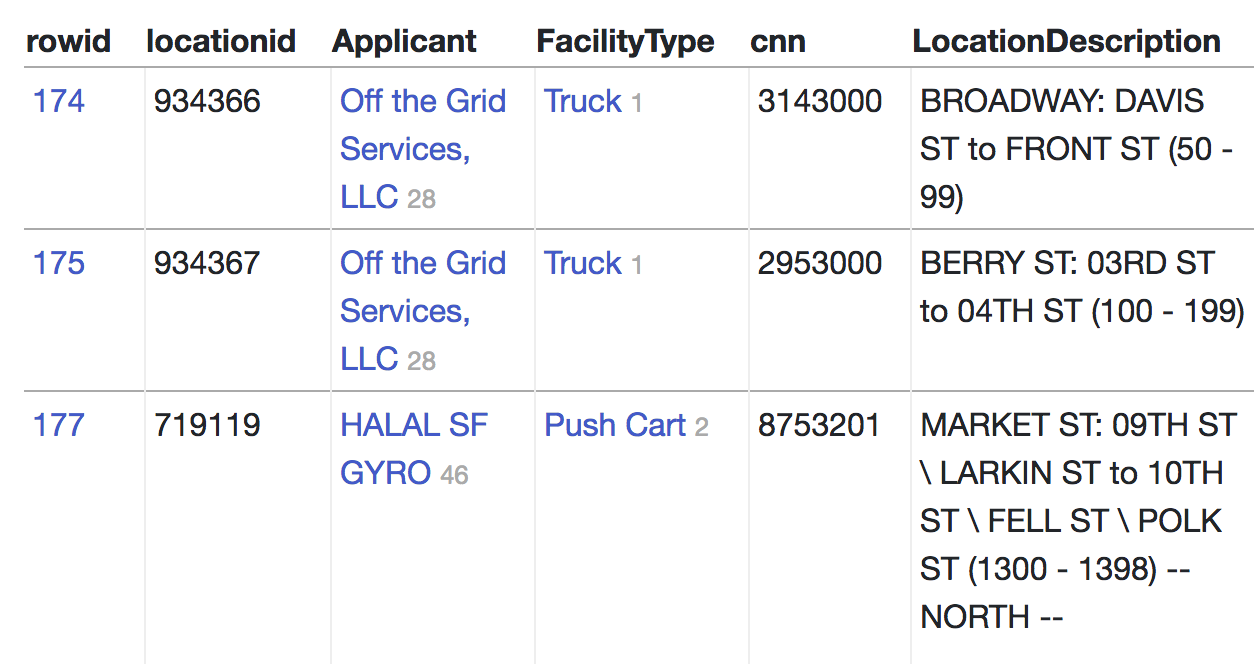
And here’s a portion of the corresponding CREATE TABLE statements showing the foreign key relationships:
CREATE TABLE "Mobile_Food_Facility_Permit" (
"locationid" INTEGER,
"Applicant" INTEGER,
"FacilityType" INTEGER,
"cnn" INTEGER,
"LocationDescription" TEXT,
...,
FOREIGN KEY ("Applicant") REFERENCES [Applicant](id),
FOREIGN KEY ("FacilityType") REFERENCES [FacilityType](id)
);
CREATE TABLE "Applicant" (
"id" INTEGER PRIMARY KEY ,
"value" TEXT
);
CREATE TABLE "FacilityType" (
"id" INTEGER PRIMARY KEY ,
"value" TEXT
);
If you click through to one of the linked records, you’ll see a page like this:
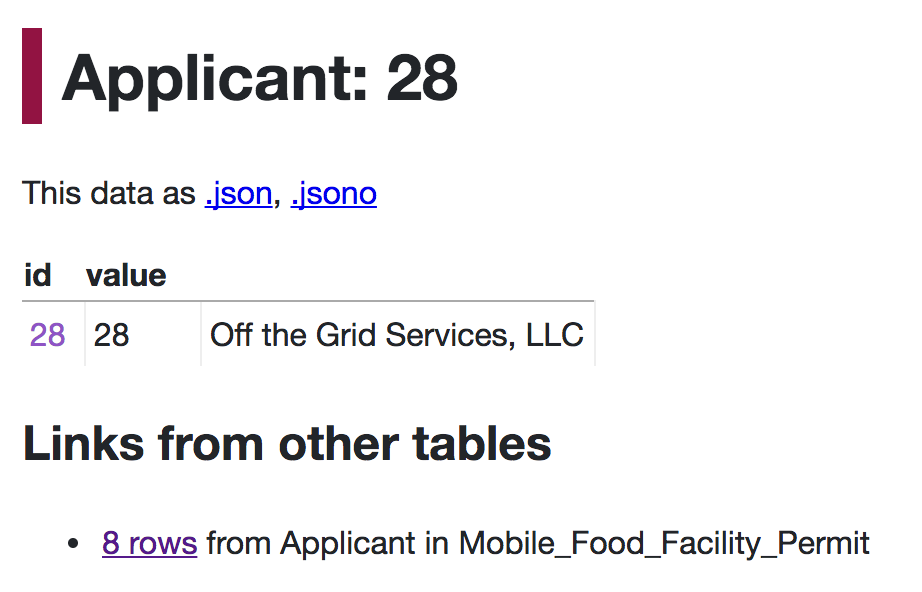
The “Links from other tables” section lists all other tables that reference this row, and links to a filtered query showing the corresponding records.
Using csvs-to-sqlite to build foreign key tables
The latest release of my csvs-to-sqlite utility adds a feature which complements Datasette’s foreign key support: you can now tell csvs-to-sqlite to “extract” a specified set of columns and use them to create additional tables.
Here’s how to create the food-trucks.db database used in the above examples.
First step: make sure you have Python 3 installed. On OS X with homebrew you can run brew install python3, otherwise follow the instructions on Python.org.
Ensure you have the most recent releases of csvs-to-sqlite and datasette:
pip3 install csvs-to-sqlite -U
pip3 install datasette -U
You may need to sudo these.
Now export the full CSV file from the Mobile Food Facility Permit page.
Here’s a sample of that CSV file:
$ head -n 2 Mobile_Food_Facility_Permit.csv
locationid,Applicant,FacilityType,cnn,LocationDescription,Address,blocklot,block,lot,permit,Status,FoodItems,X,Y,Latitude,Longitude,Schedule,dayshours,NOISent,Approved,Received,PriorPermit,ExpirationDate,Location
751253,Pipo's Grill,Truck,5688000,FOLSOM ST: 14TH ST to 15TH ST (1800 - 1899),1800 FOLSOM ST,3549083,3549,083,16MFF-0010,REQUESTED,Tacos: Burritos: Hot Dogs: and Hamburgers,6007856.719,2107724.046,37.7678524427181,-122.416104892532,http://bsm.sfdpw.org/PermitsTracker/reports/report.aspx?title=schedule&report=rptSchedule¶ms=permit=16MFF-0010&ExportPDF=1&Filename=16MFF-0010_schedule.pdf,,,,2016-02-04,0,,"(37.7678524427181, -122.416104892532)"
Next, run the following command:
csvs-to-sqlite Mobile_Food_Facility_Permit.csv \
-c FacilityType \
-c block \
-c Status \
-c Applicant \
food-trucks.db
The -c options are the real magic here: they tell csvs-to-sqlite to take that column from the CSV file and extract it out into a lookup table.
Having created the new database, you can use Datasette to browse it:
datasette food-trucks.db
Then browse to http://127.0.0.1:8001/ and start exploring.
Full-text search with Datasette and csvs-to-sqlite
SQLite includes a powerful full-text search implementation in the form of the FTS3, FTS4 and (in the most recent versions) FTS5 modules.
Datasette will look for tables that have a FTS virtual table configured against them and, if detected, will add support for a _search= query string argument and a search text interface as well.
Here’s an example of Datasette and SQLite FTS in action, this time using the DataSF list of Film Locations in San Francisco provided by the San Francisco Film Commission.
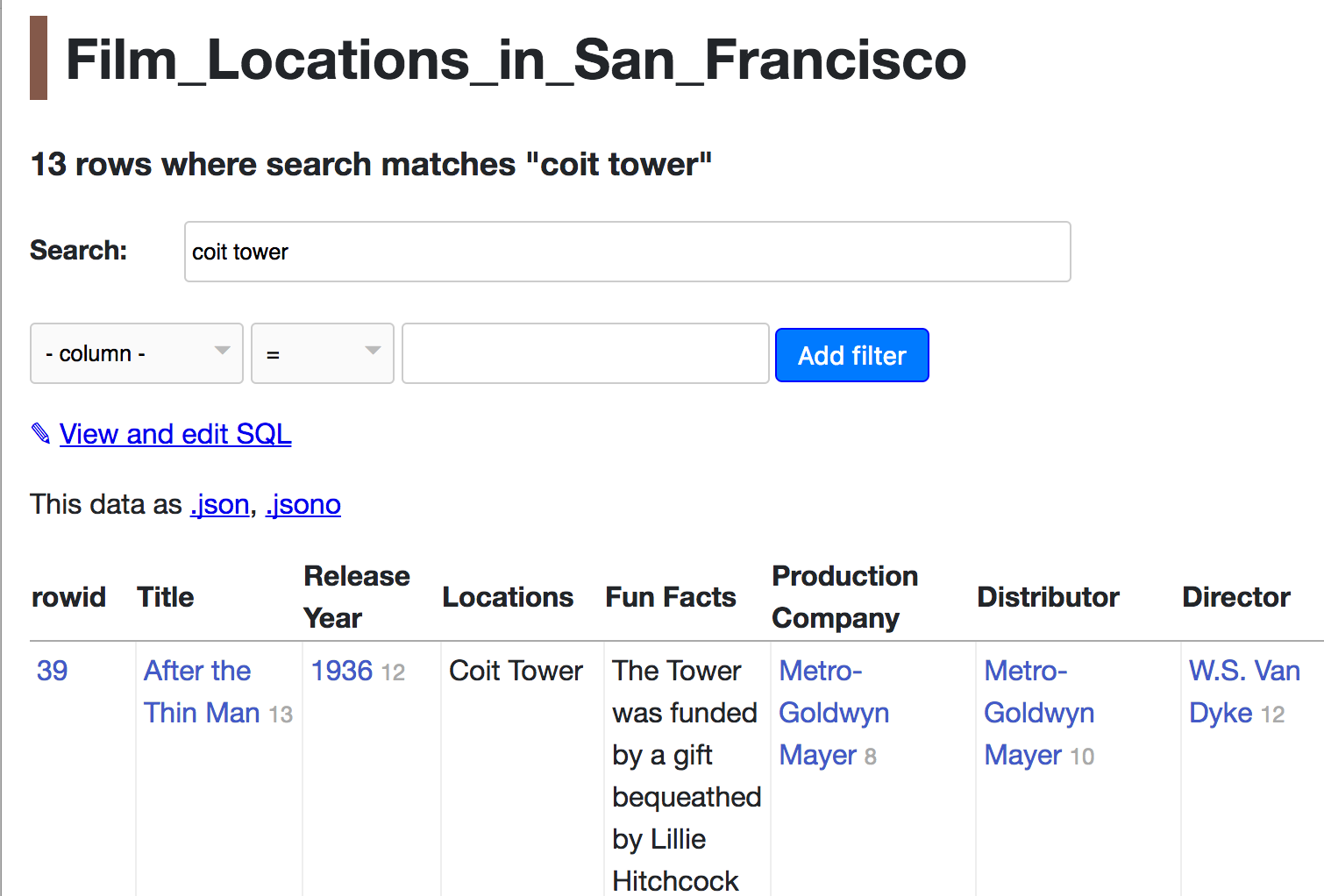
If you click on "View and edit SQL" you’ll see how the underlying query works:
select rowid, *
from Film_Locations_in_San_Francisco
where rowid in (
select rowid
from [Film_Locations_in_San_Francisco_fts]
where [Film_Locations_in_San_Francisco_fts] match :search
)
csvs-to-sqlite knows how to create the underlying FTS virtual tables from a specified list of columns. Here’s how to create the sf-film-locations database:
csvs-to-sqlite \
Film_Locations_in_San_Francisco.csv sf-film-locations.db \
-c Title \
-c "Release Year" \
-c "Production Company" \
-c "Distributor" \
-c "Director" \
-c "Writer" \
-c "Actor 1:Actors" \
-c "Actor 2:Actors" \
-c "Actor 3:Actors" \
-f Title \
-f "Production Company" \
-f Director \
-f Writer \
-f "Actor 1" \
-f "Actor 2" \
-f "Actor 3" \
-f Locations \
-f "Fun Facts"
The -f options are used to specify the columns which should be incorporated into the SQLite full-text search index. Note that the -f argument is compatible with the -c argument described above—if you extract a text column into a separate table, csvs-to-sqlite can still incorporate data from that column into the full-text index it creates.
I’m using another new feature above as well: the CSV file has three columns for actors, Actor 1, Actor 2 and Actor 3. I can tell the -c column extractor to refer each of those columns to the same underlying lookup table like this:
-c "Actor 1:Actors" \
-c "Actor 2:Actors" \
-c "Actor 3:Actors" \
If you visit the Eddie Murphy page you can see that he’s listed as Actor 1 for 14 rows and in Actor 2 for 1.
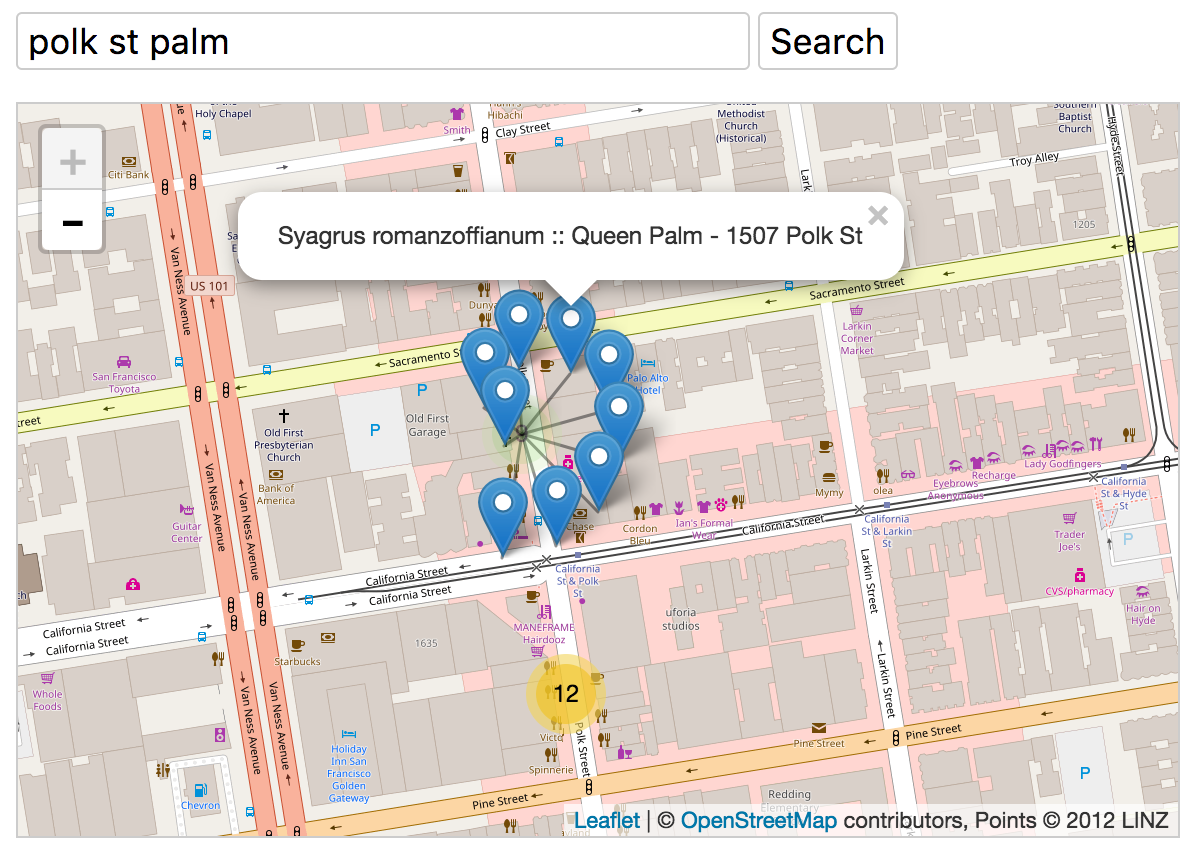
A search engine for trees!
One last demo, this time using my favourite CSV file from data.sfgov.org: the Street Tree List, published by the San Francisco Department of Public Works.
This time, in addition to publishing the database I also put together a custom UI for querying it, based on the Leaflet.markercluster library. You can try that out at https://sf-tree-search.now.sh/.
Here’s the command I used to create the database:
csvs-to-sqlite Street_Tree_List.csv sf-trees.db \
-c qLegalStatus \
-c qSpecies \
-c qSiteInfo \
-c PlantType \
-c qCaretaker \
-c qCareAssistant \
-f qLegalStatus \
-f qSpecies \
-f qAddress \
-f qSiteInfo \
-f PlantType \
-f qCaretaker \
-f qCareAssistant \
-f PermitNotes
Once again, I’m extracting out specified columns and pointing the SQLite full-text indexer at a subset of them.
Since the JavaScript search needs to pull back a subset of the overall data, I composed a custom SQL query to drive those searches.
The full source code for my tree search demo is available on GitHub.
More recent articles
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026
- sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25) - 5th July 2026