Posts tagged python in Aug
Filters: Month: Aug × python × Sorted by date
Anthropic’s Prompt Engineering Interactive Tutorial (via) Anthropic continue their trend of offering the best documentation of any of the leading LLM vendors. This tutorial is delivered as a set of Jupyter notebooks - I used it as an excuse to try uvx like this:
git clone https://github.com/anthropics/courses
uvx --from jupyter-core jupyter notebook coursesThis installed a working Jupyter system, started the server and launched my browser within a few seconds.
The first few chapters are pretty basic, demonstrating simple prompts run through the Anthropic API. I used %pip install anthropic instead of !pip install anthropic to make sure the package was installed in the correct virtual environment, then filed an issue and a PR.
One new-to-me trick: in the first chapter the tutorial suggests running this:
API_KEY = "your_api_key_here" %store API_KEY
This stashes your Anthropic API key in the IPython store. In subsequent notebooks you can restore the API_KEY variable like this:
%store -r API_KEY
I poked around and on macOS those variables are stored in files of the same name in ~/.ipython/profile_default/db/autorestore.
Chapter 4: Separating Data and Instructions included some interesting notes on Claude's support for content wrapped in XML-tag-style delimiters:
Note: While Claude can recognize and work with a wide range of separators and delimeters, we recommend that you use specifically XML tags as separators for Claude, as Claude was trained specifically to recognize XML tags as a prompt organizing mechanism. Outside of function calling, there are no special sauce XML tags that Claude has been trained on that you should use to maximally boost your performance. We have purposefully made Claude very malleable and customizable this way.
Plus this note on the importance of avoiding typos, with a nod back to the problem of sandbagging where models match their intelligence and tone to that of their prompts:
This is an important lesson about prompting: small details matter! It's always worth it to scrub your prompts for typos and grammatical errors. Claude is sensitive to patterns (in its early years, before finetuning, it was a raw text-prediction tool), and it's more likely to make mistakes when you make mistakes, smarter when you sound smart, sillier when you sound silly, and so on.
Chapter 5: Formatting Output and Speaking for Claude includes notes on one of Claude's most interesting features: prefill, where you can tell it how to start its response:
client.messages.create( model="claude-3-haiku-20240307", max_tokens=100, messages=[ {"role": "user", "content": "JSON facts about cats"}, {"role": "assistant", "content": "{"} ] )
Things start to get really interesting in Chapter 6: Precognition (Thinking Step by Step), which suggests using XML tags to help the model consider different arguments prior to generating a final answer:
Is this review sentiment positive or negative? First, write the best arguments for each side in <positive-argument> and <negative-argument> XML tags, then answer.
The tags make it easy to strip out the "thinking out loud" portions of the response.
It also warns about Claude's sensitivity to ordering. If you give Claude two options (e.g. for sentiment analysis):
In most situations (but not all, confusingly enough), Claude is more likely to choose the second of two options, possibly because in its training data from the web, second options were more likely to be correct.
This effect can be reduced using the thinking out loud / brainstorming prompting techniques.
A related tip is proposed in Chapter 8: Avoiding Hallucinations:
How do we fix this? Well, a great way to reduce hallucinations on long documents is to make Claude gather evidence first.
In this case, we tell Claude to first extract relevant quotes, then base its answer on those quotes. Telling Claude to do so here makes it correctly notice that the quote does not answer the question.
I really like the example prompt they provide here, for answering complex questions against a long document:
<question>What was Matterport's subscriber base on the precise date of May 31, 2020?</question>
Please read the below document. Then, in <scratchpad> tags, pull the most relevant quote from the document and consider whether it answers the user's question or whether it lacks sufficient detail. Then write a brief numerical answer in <answer> tags.
light-the-torchis a small utility that wrapspipto ease the installation process for PyTorch distributions liketorch,torchvision,torchaudio, and so on as well as third-party packages that depend on them. It auto-detects compatible CUDA versions from the local setup and installs the correct PyTorch binaries without user interference.
Use it like this:
pip install light-the-torch
ltt install torchIt works by wrapping and patching pip.
There is an elephant in the room which is that Astral is a VC funded company. What does that mean for the future of these tools? Here is my take on this: for the community having someone pour money into it can create some challenges. For the PSF and the core Python project this is something that should be considered. However having seen the code and what uv is doing, even in the worst possible future this is a very forkable and maintainable thing. I believe that even in case Astral shuts down or were to do something incredibly dodgy licensing wise, the community would be better off than before uv existed.
#!/usr/bin/env -S uv run (via) This is a really neat pattern. Start your Python script like this:
#!/usr/bin/env -S uv run
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flask==3.*",
# ]
# ///
import flask
# ...
And now if you chmod 755 it you can run it on any machine with the uv binary installed like this: ./app.py - and it will automatically create its own isolated environment and run itself with the correct installed dependencies and even the correctly installed Python version.
All of that from putting uv run in the shebang line!
Code from this PR by David Laban.
uv: Unified Python packaging (via) Huge new release from the Astral team today. uv 0.3.0 adds a bewildering array of new features, as part of their attempt to build "Cargo, for Python".
It's going to take a while to fully absorb all of this. Some of the key new features are:
uv tool run cowsay, aliased touvx cowsay- a pipx alternative that runs a tool in its own dedicated virtual environment (tucked away in~/Library/Caches/uv), installing it if it's not present. It has a neat--withoption for installing extras - I tried that just now withuvx --with datasette-cluster-map datasetteand it ran Datasette with thedatasette-cluster-mapplugin installed.- Project management, as an alternative to tools like Poetry and PDM.
uv initcreates apyproject.tomlfile in the current directory,uv add sqlite-utilsthen creates and activates a.venvvirtual environment, adds the package to thatpyproject.tomland adds all of its dependencies to a newuv.lockfile (like this one). Thatuv.lockis described as a universal or cross-platform lockfile that can support locking dependencies for multiple platforms. - Single-file script execution using
uv run myscript.py, where those scripts can define their own dependencies using PEP 723 inline metadata. These dependencies are listed in a specially formatted comment and will be installed into a virtual environment before the script is executed. - Python version management similar to pyenv. The new
uv python listcommand lists all Python versions available on your system (including detecting various system and Homebrew installations), anduv python install 3.13can then install a uv-managed Python using Gregory Szorc's invaluable python-build-standalone releases.
It's all accompanied by new and very thorough documentation.
The paint isn't even dry on this stuff - it's only been out for a few hours - but this feels very promising to me. The idea that you can install uv (a single Rust binary) and then start running all of these commands to manage Python installations and their dependencies is very appealing.
If you’re wondering about the relationship between this and Rye - another project that Astral adopted solving a subset of these problems - this forum thread clarifies that they intend to continue maintaining Rye but are eager for uv to work as a full replacement.
Writing your pyproject.toml (via) When I started exploring pyproject.toml a year ago I had trouble finding comprehensive documentation about what should go in that file.
Since then the Python Packaging Guide split out this page, which is exactly what I was looking for back then.
Upgrading my cookiecutter templates to use python -m pytest.
Every now and then I get caught out by weird test failures when I run pytest and it turns out I'm running the wrong installation of that tool, so my tests fail because that pytest is executing in a different virtual environment from the one needed by the tests.
The fix for this is easy: run python -m pytest instead, which guarantees that you will run pytest in the same environment as your currently active Python.
Yesterday I went through and updated every one of my cookiecutter templates (python-lib, click-app, datasette-plugin, sqlite-utils-plugin, llm-plugin) to use this pattern in their READMEs and generated repositories instead, to help spread that better recipe a little bit further.
mlx-whisper
(via)
Apple's MLX framework for running GPU-accelerated machine learning models on Apple Silicon keeps growing new examples. mlx-whisper is a Python package for running OpenAI's Whisper speech-to-text model. It's really easy to use:
pip install mlx-whisper
Then in a Python console:
>>> import mlx_whisper
>>> result = mlx_whisper.transcribe(
... "/tmp/recording.mp3",
... path_or_hf_repo="mlx-community/distil-whisper-large-v3")
.gitattributes: 100%|███████████| 1.52k/1.52k [00:00<00:00, 4.46MB/s]
config.json: 100%|██████████████| 268/268 [00:00<00:00, 843kB/s]
README.md: 100%|████████████████| 332/332 [00:00<00:00, 1.95MB/s]
Fetching 4 files: 50%|████▌ | 2/4 [00:01<00:01, 1.26it/s]
weights.npz: 63%|██████████ ▎ | 944M/1.51G [02:41<02:15, 4.17MB/s]
>>> result.keys()
dict_keys(['text', 'segments', 'language'])
>>> result['language']
'en'
>>> len(result['text'])
100105
>>> print(result['text'][:3000])
This is so exciting. I have to tell you, first of all ...Here's Activity Monitor confirming that the Python process is using the GPU for the transcription:

This example downloaded a 1.5GB model from Hugging Face and stashed it in my ~/.cache/huggingface/hub/models--mlx-community--distil-whisper-large-v3 folder.
Calling .transcribe(filepath) without the path_or_hf_repo argument uses the much smaller (74.4 MB) whisper-tiny-mlx model.
A few people asked how this compares to whisper.cpp. Bill Mill compared the two and found mlx-whisper to be about 3x faster on an M1 Max.
Update: this note from Josh Marshall:
That '3x' comparison isn't fair; completely different models. I ran a test (14" M1 Pro) with the full (non-distilled) large-v2 model quantised to 8 bit (which is my pick), and whisper.cpp was 1m vs 1m36 for mlx-whisper.
I've now done a better test, using the MLK audio, multiple runs and 2 models (distil-large-v3, large-v2-8bit)... and mlx-whisper is indeed 30-40% faster
PEP 750 – Tag Strings For Writing Domain-Specific Languages. A new PEP by Jim Baker, Guido van Rossum and Paul Everitt that proposes introducing a feature to Python inspired by JavaScript's tagged template literals.
F strings in Python already use a f"f prefix", this proposes allowing any Python symbol in the current scope to be used as a string prefix as well.
I'm excited about this. Imagine being able to compose SQL queries like this:
query = sql"select * from articles where id = {id}"
Where the sql tag ensures that the {id} value there is correctly quoted and escaped.
Currently under active discussion on the official Python discussion forum.
django-http-debug, a new Django app mostly written by Claude
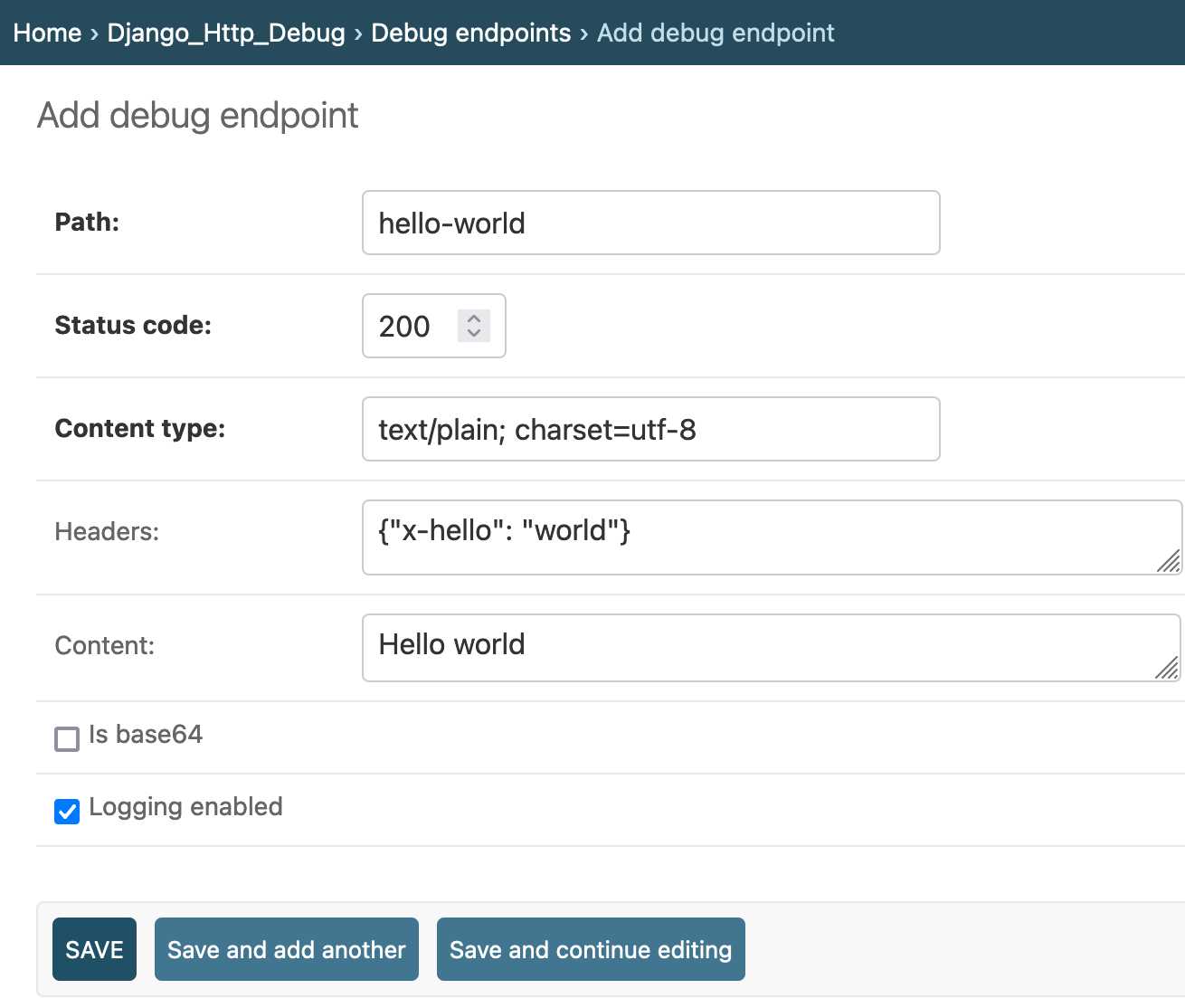
Yesterday I finally developed something I’ve been casually thinking about building for a long time: django-http-debug. It’s a reusable Django app—something you can pip install into any Django project—which provides tools for quickly setting up a URL that returns a canned HTTP response and logs the full details of any incoming request to a database table.
cibuildwheel 2.20.0 now builds Python 3.13 wheels by default (via)
CPython 3.13 wheels are now built by default […] This release includes CPython 3.13.0rc1, which is guaranteed to be ABI compatible with the final release.
cibuildwheel is an underrated but crucial piece of the overall Python ecosystem.
Python wheel packages that include binary compiled components - packages with C extensions for example - need to be built multiple times, once for each combination of Python version, operating system and architecture.
A package like Adam Johnson’s time-machine - which bundles a 500 line C extension - can end up with 55 different wheel files with names like time_machine-2.15.0-cp313-cp313-win_arm64.whl and time_machine-2.15.0-cp38-cp38-musllinux_1_2_x86_64.whl.
Without these wheels, anyone who runs pip install time-machine will need to have a working C compiler toolchain on their machine for the command to work.
cibuildwheel solves the problem of building all of those wheels for all of those different platforms on the CI provider of your choice. Adam is using it in GitHub Actions for time-machine, and his .github/workflows/build.yml file neatly demonstrates how concise the configuration can be once you figure out how to use it.
The first release candidate of Python 3.13 hit its target release date of August 1st, and the final version looks on schedule for release on the 1st of October. Since this rc should be binary compatible with the final build now is the time to start shipping those wheels to PyPI.
Understanding Immortal Objects in Python 3.12. Abhinav Upadhyay provides a clear and detailed explanation of immortal objects coming in Python 3.12, which ensure Python no longer updates reference counts for immutable objects such as True, False, None and low-values integers. The trick (which maintains ABI compatibility) is pretty simple: a reference count value of 4294967295 now means an object is immortal, and the existing Py_INCREF and Py_DECREF macros have been updated to take that into account.
Lark parsing library JSON tutorial (via) A very convincing tutorial for a new-to-me parsing library for Python called Lark.
The tutorial covers building a full JSON parser from scratch, which ends up being just 19 lines of grammar definition code and 15 lines for the transformer to turn that tree into the final JSON.
It then gets into the details of optimization—the default Earley algorithm is quite slow, but swapping that out for a LALR parser (a one-line change) provides a 5x speedup for this particular example.
deno_python (via) A wildly impressive hack: deno_python uses Deno’s FFI interface to load your system’s Python framework (.dll/.dylib/.so) and sets up JavaScript proxy objects for imported Python objects—so you can run JavaScript code that instantiates objects from Python libraries and uses them to process data in different ways.
The latest release added pip support, so things like ’const np = await pip.import(“numpy”)’ now work.
Llama from scratch (or how to implement a paper without crying) (via) Brian Kitano implemented the model described in the Llama paper against TinyShakespeare, from scratch, using Python and PyTorch. This write-up is fantastic—meticulous, detailed and deeply informative. It would take several hours to fully absorb and follow everything Brian does here but it would provide multiple valuable lessons in understanding how all of this stuff fits together.
Python cocktail: mix a context manager and an iterator in equal parts (via) Explanation of a neat trick used by the Tenacity Python library, which provides a mechanism for retrying a chunk of code automatically on errors up to three times using a mixture of an iterator and a context manager to work around Python’s lack of multi-line lambda functions.
Catching up on the weird world of LLMs

I gave a talk on Sunday at North Bay Python where I attempted to summarize the last few years of development in the space of LLMs—Large Language Models, the technology behind tools like ChatGPT, Google Bard and Llama 2.
[... 10,489 words]storysniffer (via) Ben Welsh built a small Python library that guesses if a URL points to an article on a news website, or if it’s more likely to be a category page or /about page or similar. I really like this as an example of what you can do with a tiny machine learning model: the model is bundled as a ~3MB pickle file as part of the package, and the repository includes the Jupyter notebook that was used to train it.
SQLModel. A new project by FastAPI creator Sebastián Ramírez: SQLModel builds on top of both SQLAlchemy and Sebastián’s Pydantic validation library to provide a new ORM that’s designed around Python 3’s optional typing. The real brilliance here is that a SQLModel subclass is simultaneously a valid SQLAlchemy ORM model AND a valid Pydantic validation model, saving on duplicate code by allowing the same class to be used both for form/API validation and for interacting with the database.
sqlite-utils API reference (via) I released sqlite-utils 3.15.1 today with just one change, but it’s a big one: I’ve added docstrings and type annotations to nearly every method in the library, and I’ve started using sphinx-autodoc to generate an API reference page in the documentation directly from those docstrings. I’ve deliberately avoided building this kind of documentation in the past because I so often see projects where the class reference is the ONLY documentation, which I find makes it really hard to figure out how to actually use it. sqlite-utils already has extensive narrative prose documentation so in this case I think it’s a useful enhancement—especially since the docstrings and type hints can help improve the usability of the library in IDEs and Jupyter notebooks.
Announcing the Consortium for Python Data API Standards (via) Interesting effort to unify the fragmented DataFrame API ecosystem, where increasing numbers of libraries offer APIs inspired by Pandas that imitate each other but aren’t 100% compatible. The announcement includes some very clever code to support the effort: custom tooling to compare the existing APIs, and an ingenious GitHub Actions setup to run traces (via sys.settrace), derive type signatures and commit those generated signatures back to a repository.
Pysa: An open source static analysis tool to detect and prevent security issues in Python code (via) Interesting new static analysis tool for auditing Python for security vulnerabilities—things like SQL injection and os.execute() calls. Built by Facebook and tested extensively on Instagram, a multi-million line Django application.
PyPI now supports uploading via API token (via) All of my open source Python libraries are set up to automatically deploy new tagged releases as PyPI packages using Circle CI or Travis, but I’ve always get a bit uncomfortable about sharing my PyPI password with those CI platforms to get this to work. PyPI just added scopes authentication tokens, which means I can issue a token that’s only allowed to upload a specific project and see an audit log of when that token was last used.
The subset of reStructuredText worth committing to memory
reStructuredText is the standard for documentation in the Python world.
[... 1,186 words]Compiling SQLite for use with Python Applications (via) Charles Leifer’s recent tutorial on how to compile and build the latest SQLite (with window function support) for use from Python via his pysqlite3 library.
coleifer/pysqlite3. Now that the pysqlite package is bundled as part of the Python standard library the original open source project is no longer actively maintained, and has not been upgraded for Python 3. Charles Leifer has been working on pysqlite3, a stand-alone package of the module. Crucially, this should enable compiling the latest version of SQLite (via the amalgamation package) without needing to upgrade the version that ships with the operating system.
Faust: Python Stream Processing (via) A new open source stream processing system released by Robinhood, created by Vineet Goel and Celery creator Ask Solem. The API looks delightful, making very smart use of Python decorators and async/await. The initial release requires Kafka but they plan to support multiple backends, hopefully including Redis Streams.
Datasette unit tests: monkeytype_call_traces (via) Faceted browse against every function call that occurs during the execution of Datasette’s test suite. I used Instagram’s MonkeyType tool to generate this, which can run Python code and generates a SQLite database of all of the traced calls. It’s intended to be used to automatically add mypy annotations to your code, but since it produces a SQLite database as a by-product I’ve started exploring the intermediary format using Datasette. Generating this was as easy as running “monkeytype run `which pytest`” in the Datasette root directory.
Web app: what programming knowledge do I need to create a goings on app?
For this kind of application a much more important question than "how can I build it? is "where will I get the data from?"—If you don’t have a good answer for that building the app is a waste of your time. The world is littered with local events listings apps that no one uses because they don’t have good data.
[... 82 words]Does SQLAlchemy depend on MySQLdb?
No. SQLAlchemy can talk to all sorts of different DB-API compliant backends, including MySQL Connector/J (Jython only), MySQL Connector/Python, mysql-python (the MySQLdb module) and OurSQL—plus backends for many other databases. See the full list here:
[... 50 words]