November 2024
137 posts: 9 entries, 65 links, 19 quotes, 1 note, 43 beats
Nov. 15, 2024
Recraft V3. Recraft are a generative AI design tool startup based out of London who released their v3 model a few weeks ago. It's currently sat at the top of the Artificial Analysis Image Arena Leaderboard, beating Midjourney and Flux 1.1 pro.
The thing that impressed me is that it can generate both raster and vector graphics... and the vector graphics can be exported as SVG!
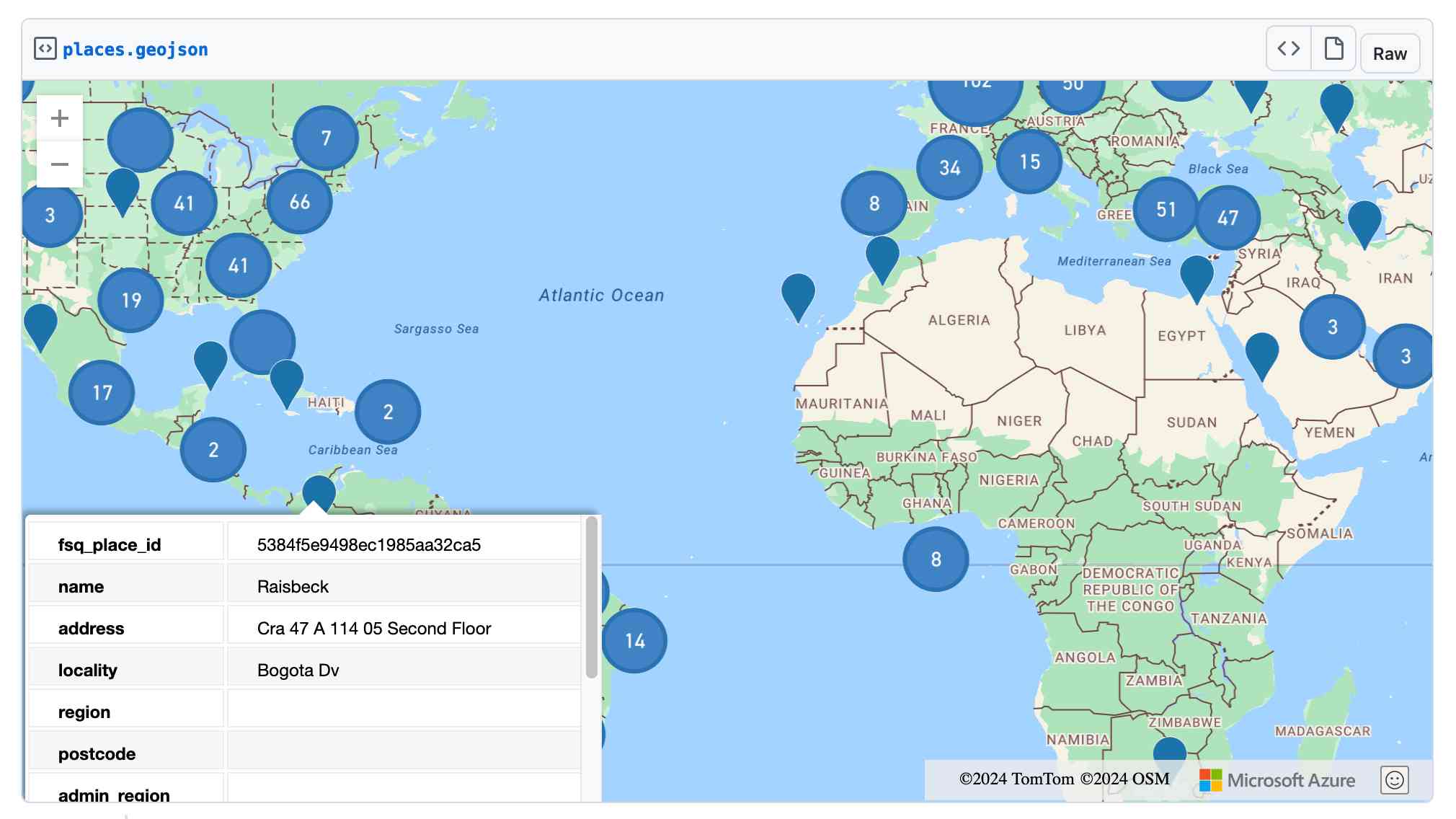
Here's what I got for raccoon with a sign that says "I love trash" - SVG here.
{kind=link}
That's an editable SVG - when I open it up in Pixelmator I can select and modify the individual paths and shapes:
![]()
They also have an API. I spent $1 on 1000 credits and then spent 80 credits (8 cents) making this SVG of a pelican riding a bicycle, using my API key stored in 1Password:
export RECRAFT_API_TOKEN="$(
op item get recraft.ai --fields label=password \
--format json | jq .value -r)"
curl https://external.api.recraft.ai/v1/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $RECRAFT_API_TOKEN" \
-d '{
"prompt": "california brown pelican riding a bicycle",
"style": "vector_illustration",
"model": "recraftv3"
}'

Voting opens for Oxford Word of the Year 2024 (via) One of the options is slop!
slop (n.): Art, writing, or other content generated using artificial intelligence, shared and distributed online in an indiscriminate or intrusive way, and characterized as being of low quality, inauthentic, or inaccurate.
Update 1st December: Slop lost to Brain rot
Nov. 16, 2024
NuExtract 1.5. Structured extraction - where an LLM helps turn unstructured text (or image content) into structured data - remains one of the most directly useful applications of LLMs.
NuExtract is a family of small models directly trained for this purpose (though text only at the moment) and released under the MIT license.
It comes in a variety of shapes and sizes:
- NuExtract-v1.5 is a 3.8B parameter model fine-tuned on Phi-3.5-mini instruct. You can try this one out in this playground.
- NuExtract-tiny-v1.5 is 494M parameters, fine-tuned on Qwen2.5-0.5B.
- NuExtract-1.5-smol is 1.7B parameters, fine-tuned on SmolLM2-1.7B.
All three models were fine-tuned on NuMind's "private high-quality dataset". It's interesting to see a model family that uses one fine-tuning set against three completely different base models.
Useful tip from Steffen Röcker:
Make sure to use it with low temperature, I've uploaded NuExtract-tiny-v1.5 to Ollama and set it to 0. With the Ollama default of 0.7 it started repeating the input text. It works really well despite being so smol.
Project: Civic Band—scraping and searching PDF meeting minutes from hundreds of municipalities
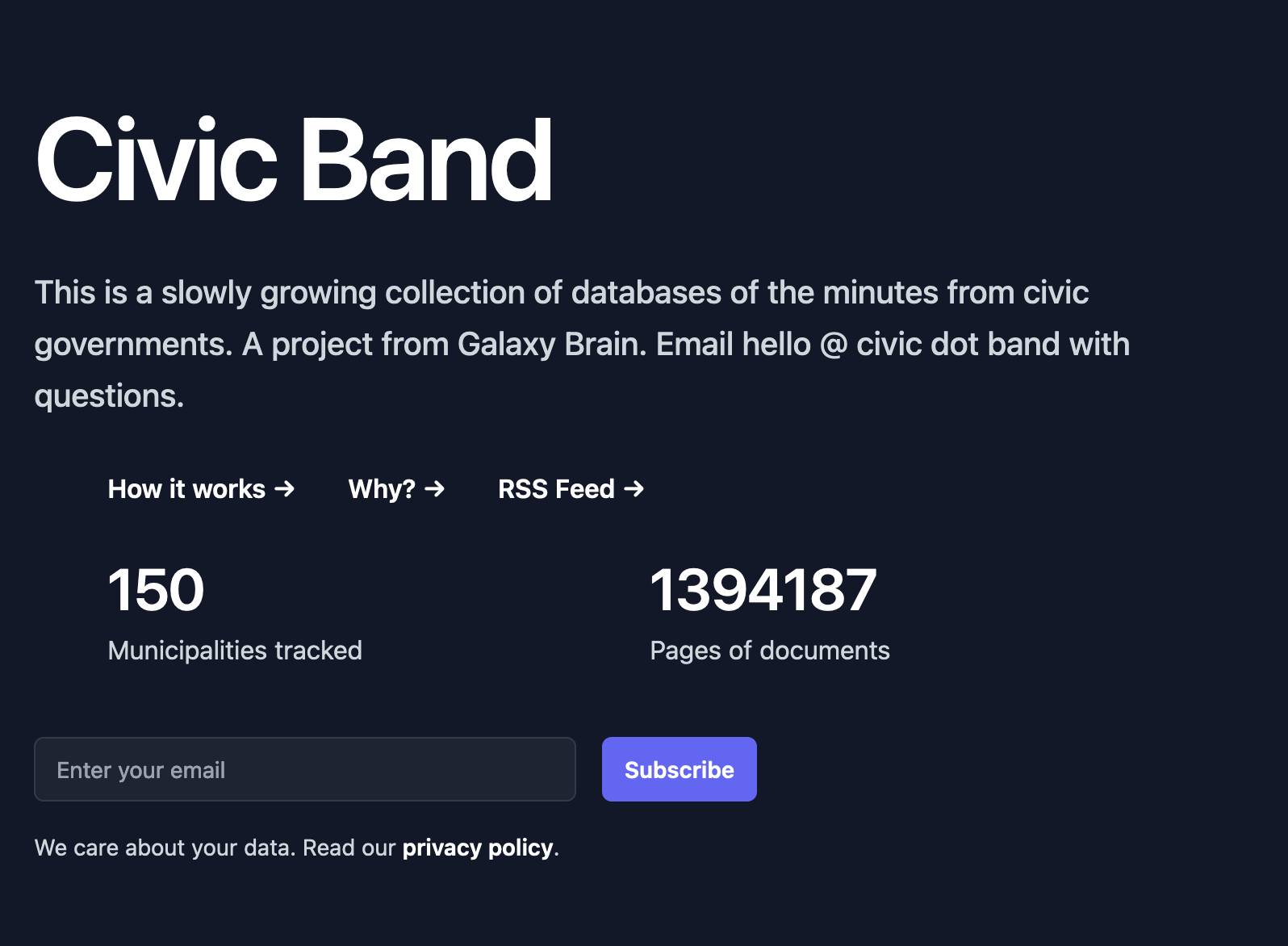
I interviewed Philip James about Civic Band, his “slowly growing collection of databases of the minutes from civic governments”. Philip demonstrated the site and talked through his pipeline for scraping and indexing meeting minutes from many different local government authorities around the USA.
[... 762 words]Nov. 17, 2024
LLM 0.18. New release of LLM. The big new feature is asynchronous model support - you can now use supported models in async Python code like this:
import llm
model = llm.get_async_model("gpt-4o")
async for chunk in model.prompt(
"Five surprising names for a pet pelican"
):
print(chunk, end="", flush=True)
Also new in this release: support for sending audio attachments to OpenAI's gpt-4o-audio-preview model.
Nov. 18, 2024
llm-gemini 0.4.
New release of my llm-gemini plugin, adding support for asynchronous models (see LLM 0.18), plus the new gemini-exp-1114 model (currently at the top of the Chatbot Arena) and a -o json_object 1 option to force JSON output.
I also released llm-claude-3 0.9 which adds asynchronous support for the Claude family of models.
The main innovation here is just using more data. Specifically, Qwen2.5 Coder is a continuation of an earlier Qwen 2.5 model. The original Qwen 2.5 model was trained on 18 trillion tokens spread across a variety of languages and tasks (e.g, writing, programming, question answering). Qwen 2.5-Coder sees them train this model on an additional 5.5 trillion tokens of data. This means Qwen has been trained on a total of ~23T tokens of data – for perspective, Facebook’s LLaMa3 models were trained on about 15T tokens. I think this means Qwen is the largest publicly disclosed number of tokens dumped into a single language model (so far).
Qwen: Extending the Context Length to 1M Tokens (via) The new Qwen2.5-Turbo boasts a million token context window (up from 128,000 for Qwen 2.5) and faster performance:
Using sparse attention mechanisms, we successfully reduced the time to first token for processing a context of 1M tokens from 4.9 minutes to 68 seconds, achieving a 4.3x speedup.
The benchmarks they've published look impressive, including a 100% score on the 1M-token passkey retrieval task (not the first model to achieve this).
There's a catch: unlike previous models in the Qwen 2.5 series it looks like this one hasn't been released as open weights: it's available exclusively via their (inexpensive) paid API - for which it looks like you may need a +86 Chinese phone number.
Pixtral Large (via) New today from Mistral:
Today we announce Pixtral Large, a 124B open-weights multimodal model built on top of Mistral Large 2. Pixtral Large is the second model in our multimodal family and demonstrates frontier-level image understanding.
The weights are out on Hugging Face (over 200GB to download, and you'll need a hefty GPU rig to run them). The license is free for academic research but you'll need to pay for commercial usage.
The new Pixtral Large model is available through their API, as models called pixtral-large-2411 and pixtral-large-latest.
Here's how to run it using LLM and the llm-mistral plugin:
llm install -U llm-mistral
llm keys set mistral
# paste in API key
llm mistral refresh
llm -m mistral/pixtral-large-latest describe -a https://static.simonwillison.net/static/2024/pelicans.jpg
The image shows a large group of birds, specifically pelicans, congregated together on a rocky area near a body of water. These pelicans are densely packed together, some looking directly at the camera while others are engaging in various activities such as preening or resting. Pelicans are known for their large bills with a distinctive pouch, which they use for catching fish. The rocky terrain and the proximity to water suggest this could be a coastal area or an island where pelicans commonly gather in large numbers. The scene reflects a common natural behavior of these birds, often seen in their nesting or feeding grounds.

Update: I released llm-mistral 0.8 which adds async model support for the full Mistral line, plus a new llm -m mistral-large shortcut alias for the Mistral Large model.
Nov. 19, 2024
Security means securing people where they are (via) William Woodruff is an Engineering Director at Trail of Bits who worked on the recent PyPI digital attestations project.
That feature is based around open standards but launched with an implementation against GitHub, which resulted in push back (and even some conspiracy theories) that PyPI were deliberately favoring GitHub over other platforms.
William argues here for pragmatism over ideology:
Being serious about security at scale means meeting users where they are. In practice, this means deciding how to divide a limited pool of engineering resources such that the largest demographic of users benefits from a security initiative. This results in a fundamental bias towards institutional and pre-existing services, since the average user belongs to these institutional services and does not personally particularly care about security. Participants in open source can and should work to counteract this institutional bias, but doing so as a matter of ideological purity undermines our shared security interests.
Preview: Gemini API Additional Terms of Service. Google sent out an email last week linking to this preview of upcoming changes to the Gemini API terms. Key paragraph from that email:
To maintain a safe and responsible environment for all users, we're enhancing our abuse monitoring practices for Google AI Studio and Gemini API. Starting December 13, 2024, Gemini API will log prompts and responses for Paid Services, as described in the terms. These logs are only retained for a limited time (55 days) and are used solely to detect abuse and for required legal or regulatory disclosures. These logs are not used for model training. Logging for abuse monitoring is standard practice across the global AI industry. You can preview the updated Gemini API Additional Terms of Service, effective December 13, 2024.
That "for required legal or regulatory disclosures" piece makes it sound like somebody could subpoena Google to gain access to your logged Gemini API calls.
It's not clear to me if this is a change from their current policy though, other than the number of days of log retention increasing from 30 to 55 (and I'm having trouble finding that 30 day number written down anywhere.)
That same email also announced the deprecation of the older Gemini 1.0 Pro model:
Gemini 1.0 Pro will be discontinued on February 15, 2025.
Notes from Bing Chat—Our First Encounter With Manipulative AI

I participated in an Ars Live conversation with Benj Edwards of Ars Technica today, talking about that wild period of LLM history last year when Microsoft launched Bing Chat and it instantly started misbehaving, gaslighting and defaming people.
[... 438 words]Understanding the BM25 full text search algorithm (via) Evan Schwartz provides a deep dive explanation of how the classic BM25 search relevance scoring function works, including a very useful breakdown of the mathematics it uses.
Using uv with PyTorch (via) PyTorch is a notoriously tricky piece of Python software to install, due to the need to provide separate wheels for different combinations of Python version and GPU accelerator (e.g. different CUDA versions).
uv now has dedicated documentation for PyTorch which I'm finding really useful - it clearly explains the challenge and then shows exactly how to configure a pyproject.toml such that uv knows which version of each package it should install from where.
OpenStreetMap vector tiles demo
(via)
Long-time OpenStreetMap developer Paul Norman has been working on adding vector tile support to OpenStreetMap for quite a while. Paul recently announced that vector.openstreetmap.org is now serving vector tiles (in Mapbox Vector Tiles (MVT) format) - here's his interactive demo for seeing what they look like.
Nov. 20, 2024
Bluesky WebSocket Firehose. Very quick (10 seconds of Claude hacking) prototype of a web page that attaches to the public Bluesky WebSocket firehose and displays the results directly in your browser.
Here's the code - there's very little to it, it's basically opening a connection to wss://jetstream2.us-east.bsky.network/subscribe?wantedCollections=app.bsky.feed.post and logging out the results to a <textarea readonly> element.

Bluesky's Jetstream isn't their main atproto firehose - that's a more complicated protocol involving CBOR data and CAR files. Jetstream is a new Go proxy (source code here) that provides a subset of that firehose over WebSocket.
Jetstream was built by Bluesky developer Jaz, initially as a side-project, in response to the surge of traffic they received back in September when Brazil banned Twitter. See Jetstream: Shrinking the AT Proto Firehose by >99% for their description of the project when it first launched.
The API scene growing around Bluesky is really exciting right now. Twitter's API is so expensive it may as well not exist, and Mastodon's community have pushed back against many potential uses of the Mastodon API as incompatible with that community's value system.
Hacking on Bluesky feels reminiscent of the massive diversity of innovation we saw around Twitter back in the late 2000s and early 2010s.
Here's a much more fun Bluesky demo by Theo Sanderson: firehose3d.theo.io (source code here) which displays the firehose from that same WebSocket endpoint in the style of a Windows XP screensaver.
Foursquare Open Source Places: A new foundational dataset for the geospatial community (via) I did not expect this!
[...] we are announcing today the general availability of a foundational open data set, Foursquare Open Source Places ("FSQ OS Places"). This base layer of 100mm+ global places of interest ("POI") includes 22 core attributes (see schema here) that will be updated monthly and available for commercial use under the Apache 2.0 license framework.
The data is available as Parquet files hosted on Amazon S3.
Here's how to list the available files:
aws s3 ls s3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/
I got back places-00000.snappy.parquet through places-00024.snappy.parquet, each file around 455MB for a total of 10.6GB of data.
I ran duckdb and then used DuckDB's ability to remotely query Parquet on S3 to explore the data a bit more without downloading it to my laptop first:
select count(*) from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-00000.snappy.parquet';
This got back 4,180,424 - that number is similar for each file, suggesting around 104,000,000 records total.
Update: DuckDB can use wildcards in S3 paths (thanks, Paul) so this query provides an exact count:
select count(*) from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-*.snappy.parquet';
That returned 104,511,073 - and Activity Monitor on my Mac confirmed that DuckDB only needed to fetch 1.2MB of data to answer that query.
I ran this query to retrieve 1,000 places from that first file as newline-delimited JSON:
copy (
select * from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-00000.snappy.parquet'
limit 1000
) to '/tmp/places.json';
Here's that places.json file, and here it is imported into Datasette Lite.
Finally, I got ChatGPT Code Interpreter to convert that file to GeoJSON and pasted the result into this Gist, giving me a map of those thousand places (because Gists automatically render GeoJSON):