April 2023
110 posts: 17 entries, 45 links, 19 quotes, 29 beats
April 7, 2023
Several libraries let you declare objects with type-hinted members and automatically derive validation rules and serialization/deserialization from the type hints – Pydantic is the most popular, but alternatives like msgspec are out there too. There’s also a whole new generation of web frameworks like FastAPI and Starlite which use type hints at runtime to do not just input validation and serialization/deserialization but also things like dependency injection.
Personally, I’ve seen more significant gains in productivity from those runtime usages of Python’s type hints than from any static ahead-of-time type checking, which mostly is only useful to me as documentation.
Why ChatGPT and Bing Chat are so good at making things up. I helped review this deep dive by Benj Edwards for Ars Technica into the hallucination/confabulation problem with ChatGPT and other LLMs, which is attracting increasing attention thanks to stories like the recent defamation complaints against ChatGPT. This article explains why this is happening and talks to various experts about potential solutions.
For example, if you prompt GPT-3 with "Mary had a," it usually completes the sentence with "little lamb." That's because there are probably thousands of examples of "Mary had a little lamb" in GPT-3's training data set, making it a sensible completion. But if you add more context in the prompt, such as "In the hospital, Mary had a," the result will change and return words like "baby" or "series of tests."
Database “sharding” came from UO? (via) Raph Koster coined the term “shard” back in 1996 in a design document proposing a way of scaling Ultima Online: “[...] we realized we would need to run multiple whole copies of Ultima Online for users to connect to, we needed to come up with a fiction for it. [...] the evil wizard Mondain had attempted to gain control over Sosaria by trapping its essence in a crystal. When the Stranger at the end of Ultima I defeated Mondain and shattered the crystal, the crystal shards each held a refracted copy of Sosaria.”
We need to tell people ChatGPT will lie to them, not debate linguistics
ChatGPT lies to people. This is a serious bug that has so far resisted all attempts at a fix. We need to prioritize helping people understand this, not debating the most precise terminology to use to describe it.
[... 1,174 words]The progress in AI has allowed things like taking down hate speech more efficiently - and this is due entirely to large language models. Because we have large language models [...] we can do a better job than we ever could in detecting hate speech in most languages in the world. That was impossible before.
April 8, 2023
Working in public

I participated in a panel discussion this week for path to Citus Con, a series of Discord audio events that are happening in the run up to the Citus Con 2023 later this month.
[... 546 words]The Changelog podcast: LLMs break the internet

I’m the guest on the latest episode of The Changelog podcast: LLMs break the internet. It’s a follow-up to the episode we recorded six months ago about Stable Diffusion.
[... 454 words]April 9, 2023


April 10, 2023
On Endings: Why & How We Retired Elm at Culture Amp (via) Culture Amp made extensive use of Elm—a ML-like functional language that compiles to JavaScript—between 2016 and 2020 while building their company’s frontend. They eventually decided to move away from it, for reasons described at length in this post primarily relating to its integration with React. This piece is worth reading mainly as a thoughtful approach to engineering management challenge of deprecating a well-loved piece of technology from the recommended stack at a company.
Floor796 (via) “An ever-expanding animation scene showing the life of the 796th floor of the huge space station” by Russian artist 0x00, who built their own custom browser-based pixel animation tool with which they are constructing this project. Absolutely crammed with pop culture references and easter eggs. The “Changes” link at the top shows almost daily updates, with links to jump to the latest content.
Thoughts on AI safety in this era of increasingly powerful open source LLMs
This morning, VentureBeat published a story by Sharon Goldman: With a wave of new LLMs, open source AI is having a moment — and a red-hot debate. It covers the explosion in activity around openly available Large Language Models such as LLaMA—a trend I’ve been tracking in my own series LLMs on personal devices—and talks about their implications with respect to AI safety.
[... 782 words]AI is flooding the workplace, and workers love it. The microwave kiln pottery project I helped Natalie with gets a mention in this story about people who are putting AI tools to use.
The AI singularity is here. Can’t say I’m a fan of the headline, but the subhead “The time to figure out how to use generative AI and large language models in your code is now” is much more illustrative of the story. I’m referred to in this one as “One of the most outspoken advocates for LLM-enhanced development” which is a bit of a surprise!
April 11, 2023
How we’re building a browser when it’s supposed to be impossible (via) Andreas Kling: “The ECMAScript, HTML, and CSS specifications today are (for the most part) stellar technical documents whose algorithms can be implemented with considerably less effort and guesswork than in the past.” The Ladybird project is such an inspiration, and really demonstrates the enormous value of the work put in by web standards spec authors over the last twenty years.
My strong hunch is that the GIL does not need removing, if a) subinterpreters have their own GILs and b) an efficient way is provided to pass (some) data between subinterpreters lock free and c) we find good patterns to make working with subinterpreters work.
Sheepy-T—an LLM running on an iPhone. Kevin Kwok has a video on Twitter demonstrating Sheepy-T—his iPhone app which runs a full instruction-tuned large language model, based on EleutherAI’s GPT-J, entirely on an iPhone 14. I applied for the TestFlight beta and I have this running on my phone now: it works!
I literally lost my biggest and best client to ChatGPT today. This client is my main source of income, he’s a marketer who outsources the majority of his copy and content writing to me. Today he emailed saying that although he knows AI’s work isn’t nearly as good as mine, he can’t ignore the profit margin. [...] Please do not think you are immune to this unless you are the top 1% of writers. I just signed up for Doordash as a driver. I really wish I was kidding.
April 12, 2023
Running Python micro-benchmarks using the ChatGPT Code Interpreter alpha
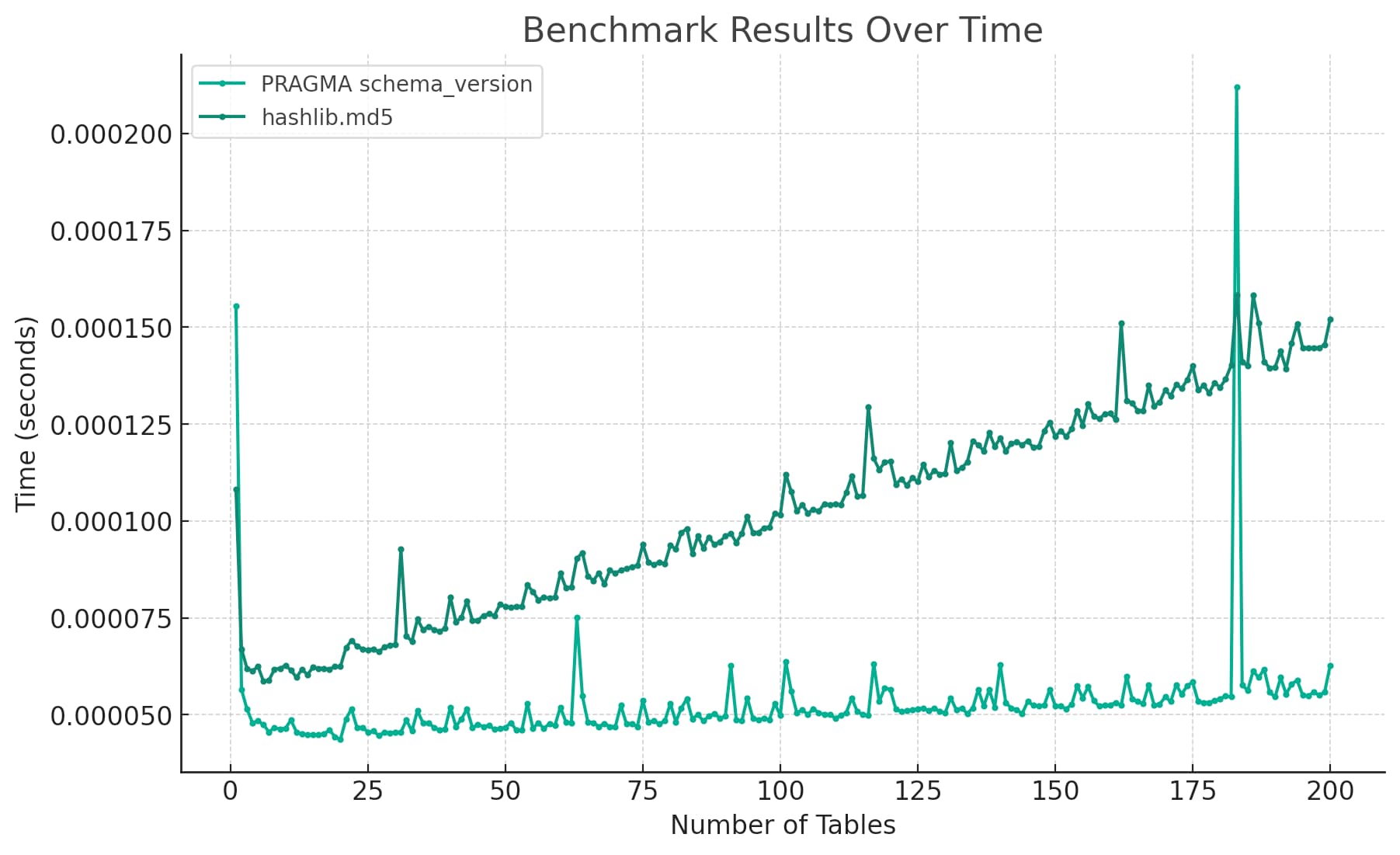
Today I wanted to understand the performance difference between two Python implementations of a mechanism to detect changes to a SQLite database schema. I rendered the difference between the two as this chart:
[... 2,939 words]Graphic designers had a similar sea change ~20-25 years ago.
Flyers, restaurant menus, wedding invitations, price lists... That sort of thing was bread and butter work for most designers. Then desktop publishing happened and a large fraction of designers lost their main source of income as the work shifted to computer assisted unskilled labor.
The field still thrives today, but that simple work is gone forever.


Replacing my best friends with an LLM trained on 500,000 group chat messages (via) Izzy Miller used a 7 year long group text conversation with five friends from college to fine-tune LLaMA, such that it could simulate ongoing conversations. They started by extracting the messages from the iMessage SQLite database on their Mac, then generated a new training set from those messages and ran it using code from the Stanford Alpaca repository. This is genuinely one of the clearest explanations of the process of fine-tuning a model like this I’ve seen anywhere.
April 13, 2023
Free Dolly: Introducing the World’s First Truly Open Instruction-Tuned LLM (via) Databricks released a large language model called Dolly a few weeks ago. They just released Dolly 2.0 and it is MUCH more interesting—it’s an instruction tuned 12B parameter upgrade of EleutherAI’s Pythia model. Unlike other recent instruction tuned models Databricks didn’t use a training set derived from GPT-3—instead, they recruited 5,000 employees to help put together 15,000 human-generated request/response pairs, which they have released under a Creative Commons Attribution-ShareAlike license. The model itself is a 24GB download from Hugging Face—I’ve run it slowly on a small GPU-enabled Paperspace instance, but hopefully optimized ways to run it will emerge in short order.
GitHub Accelerator: our first cohort. I’m participating in the first cohort of GitHub’s new open source accelerator program, with Datasette (and related projects). It’s a 10 week program with 20 projects working together “with an end goal of building durable streams of funding for their work”.