60 posts tagged “embeddings”
2025
Scaling HNSWs (via) Salvatore Sanfilippo spent much of this year working on vector sets for Redis, which first shipped in Redis 8 in May.
A big part of that work involved implementing HNSW - Hierarchical Navigable Small World - an indexing technique first introduced in this 2016 paper by Yu. A. Malkov and D. A. Yashunin.
Salvatore's detailed notes on the Redis implementation here offer an immersive trip through a fascinating modern field of computer science. He describes several new contributions he's made to the HNSW algorithm, mainly around efficient deletion and updating of existing indexes.
Since embedding vectors are notoriously memory-hungry I particularly appreciated this note about how you can scale a large HNSW vector set across many different nodes and run parallel queries against them for both reads and writes:
[...] if you have different vectors about the same use case split in different instances / keys, you can ask VSIM for the same query vector into all the instances, and add the WITHSCORES option (that returns the cosine distance) and merge the results client-side, and you have magically scaled your hundred of millions of vectors into multiple instances, splitting your dataset N times [One interesting thing about such a use case is that you can query the N instances in parallel using multiplexing, if your client library is smart enough].
Another very notable thing about HNSWs exposed in this raw way, is that you can finally scale writes very easily. Just hash your element modulo N, and target the resulting Redis key/instance. Multiple instances can absorb the (slow, but still fast for HNSW standards) writes at the same time, parallelizing an otherwise very slow process.
It's always exciting to see new implementations of fundamental algorithms and data structures like this make it into Redis because Salvatore's C code is so clearly commented and pleasant to read - here's vector-sets/hnsw.c and vector-sets/vset.c.
The case against pgvector (via) I wasn't keen on the title of this piece but the content is great: Alex Jacobs talks through lessons learned trying to run the popular pgvector PostgreSQL vector indexing extension at scale, in particular the challenges involved in maintaining a large index with close-to-realtime updates using the IVFFlat or HNSW index types.
The section on pre-v.s.-post filtering is particularly useful:
Okay but let's say you solve your index and insert problems. Now you have a document search system with millions of vectors. Documents have metadata---maybe they're marked as
draft,published, orarchived. A user searches for something, and you only want to return published documents.[...] should Postgres filter on status first (pre-filter) or do the vector search first and then filter (post-filter)?
This seems like an implementation detail. It’s not. It’s the difference between queries that take 50ms and queries that take 5 seconds. It’s also the difference between returning the most relevant results and… not.
The Hacker News thread for this article attracted a robust discussion, including some fascinating comments by Discourse developer Rafael dos Santos Silva (xfalcox) about how they are using pgvector at scale:
We [run pgvector in production] at Discourse, in thousands of databases, and it's leveraged in most of the billions of page views we serve. [...]
Also worth mentioning that we use quantization extensively:
- halfvec (16bit float) for storage - bit (binary vectors) for indexes
Which makes the storage cost and on-going performance good enough that we could enable this in all our hosting. [...]
In Discourse embeddings power:
- Related Topics, a list of topics to read next, which uses embeddings of the current topic as the key to search for similar ones
- Suggesting tags and categories when composing a new topic
- Augmented search
- RAG for uploaded files
I recently spoke with the CTO of a popular AI note-taking app who told me something surprising: they spend twice as much on vector search as they do on OpenAI API calls. Think about that for a second. Running the retrieval layer costs them more than paying for the LLM itself.
— James Luan, Engineering architect of Milvus
I am once again shocked at how much better image retrieval performance you can get if you embed highly opinionated summaries of an image, a summary that came out of a visual language model, than using CLIP embeddings themselves. If you tell the LLM that the summary is going to be embedded and used to do search downstream. I had one system go from 28% recall at 5 using CLIP to 75% recall at 5 using an LLM summary.
Introducing EmbeddingGemma. Brand new open weights (under the slightly janky Gemma license) 308M parameter embedding model from Google:
Based on the Gemma 3 architecture, EmbeddingGemma is trained on 100+ languages and is small enough to run on less than 200MB of RAM with quantization.
It's available via sentence-transformers, llama.cpp, MLX, Ollama, LMStudio and more.
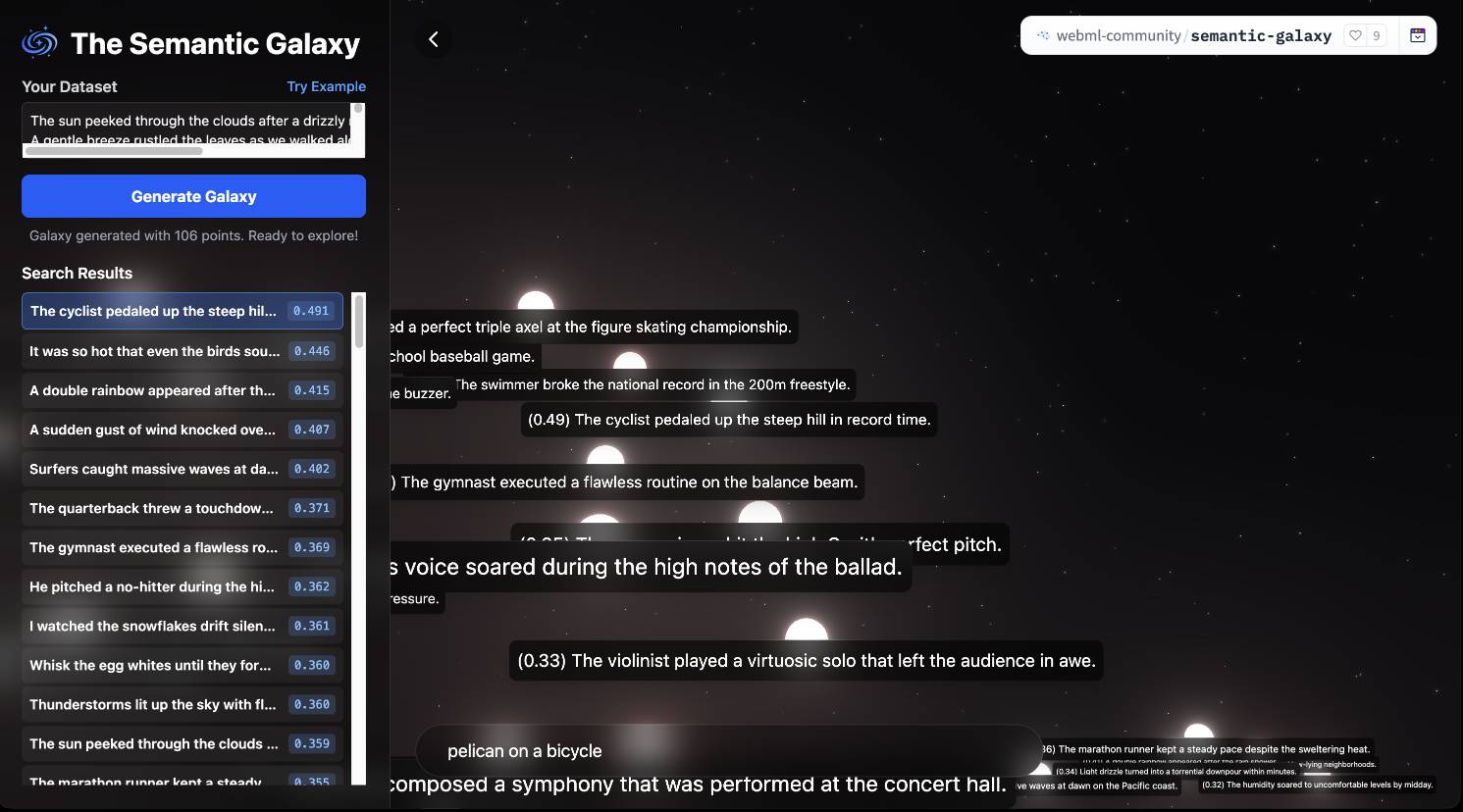
As usual for these smaller models there's a Transformers.js demo (via) that runs directly in the browser (in Chrome variants) - Semantic Galaxy loads a ~400MB model and then lets you run embeddings against hundreds of text sentences, map them in a 2D space and run similarity searches to zoom to points within that space.
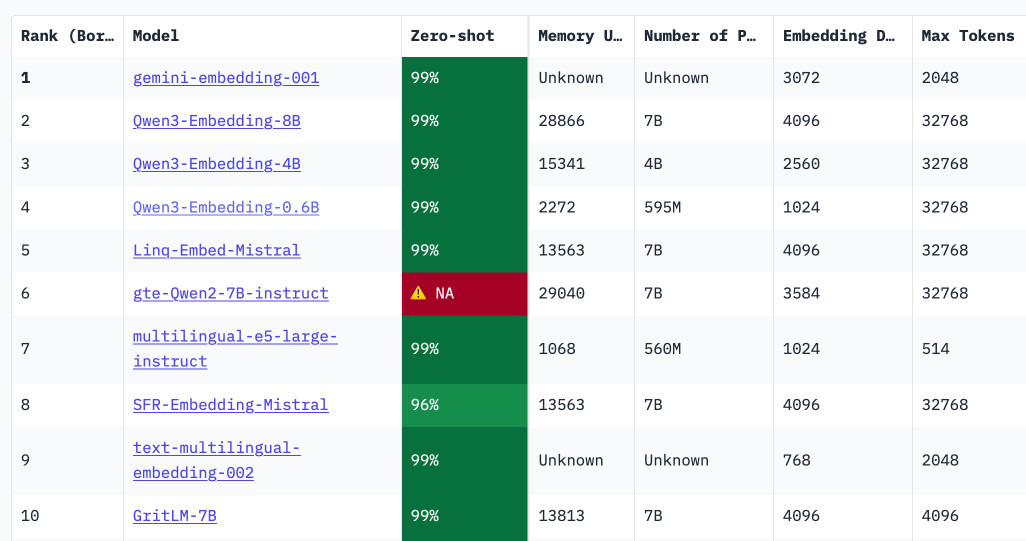
Qwen3 Embedding (via) New family of embedding models from Qwen, in three sizes: 0.6B, 4B, 8B - and two categories: Text Embedding and Text Reranking.
The full collection can be browsed on Hugging Face. The smallest available model is the 0.6B Q8 one, which is available as a 639MB GGUF. I tried it out using my llm-sentence-transformers plugin like this:
llm install llm-sentence-transformers
llm sentence-transformers register Qwen/Qwen3-Embedding-0.6B
llm embed -m sentence-transformers/Qwen/Qwen3-Embedding-0.6B -c hi | jq length
This output 1024, confirming that Qwen3 0.6B produces 1024 length embedding vectors.
These new models are the highest scoring open-weight models on the well regarded MTEB leaderboard - they're licensed Apache 2.0.
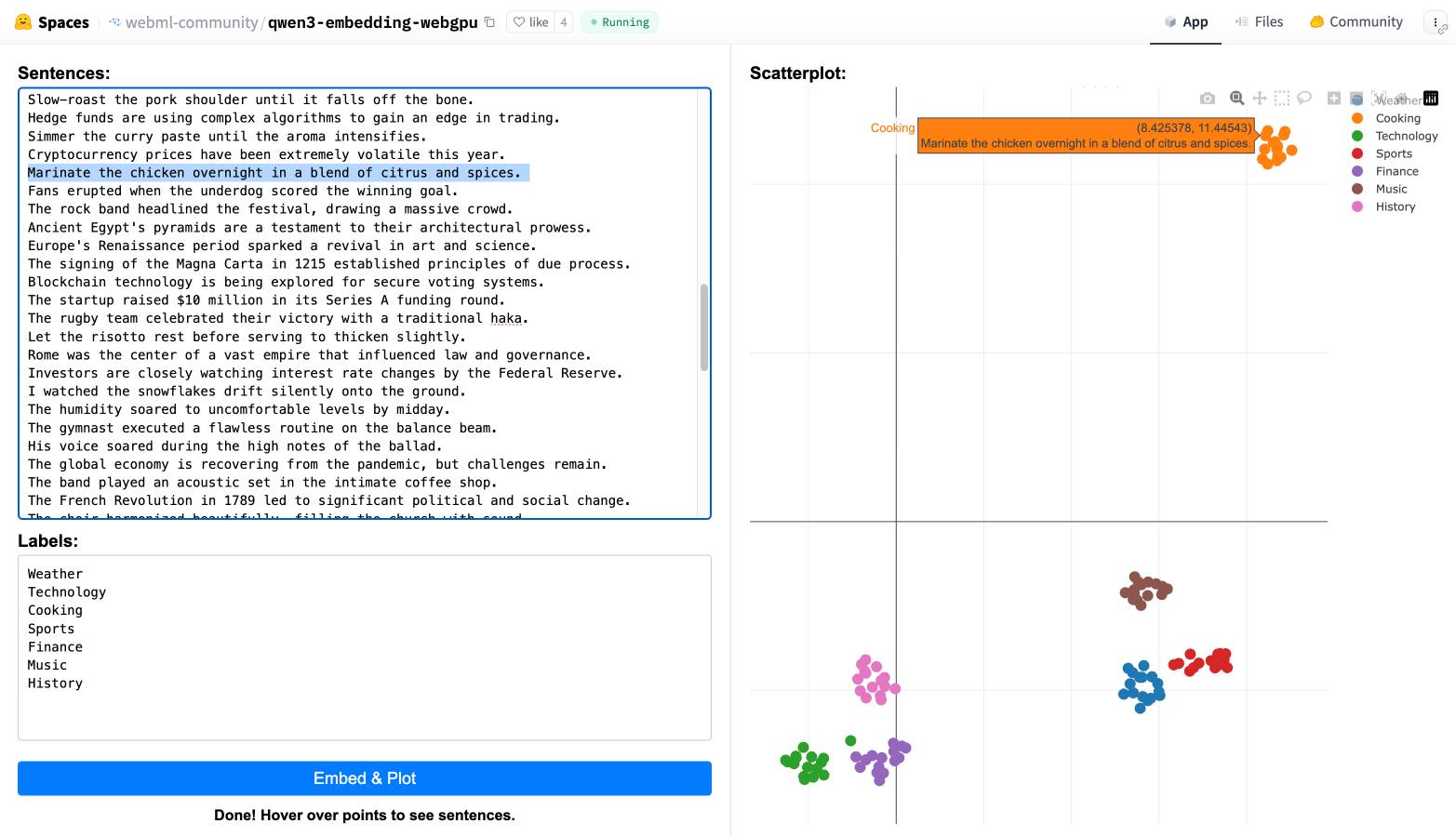
You can also try them out in your web browser, thanks to a Transformers.js port of the models. I loaded this page in Chrome (source code here) and it fetched 560MB of model files and gave me an interactive interface for visualizing clusters of embeddings like this:
Codestral Embed. Brand new embedding model from Mistral, specifically trained for code. Mistral claim that:
Codestral Embed significantly outperforms leading code embedders in the market today: Voyage Code 3, Cohere Embed v4.0 and OpenAI’s large embedding model.
The model is designed to work at different sizes. They show performance numbers for 256, 512, 1024 and 1546 sized vectors in binary (256 bits = 32 bytes of storage per record), int8 and float32 representations. The API documentation says you can request up to 3072.
The dimensions of our embeddings are ordered by relevance. For any integer target dimension n, you can choose to keep the first n dimensions for a smooth trade-off between quality and cost.
I think that means they're using Matryoshka embeddings.
Here's the problem: the benchmarks look great, but the model is only available via their API (or for on-prem deployments at "contact us" prices).
I'm perfectly happy to pay for API access to an embedding model like this, but I only want to do that if the model itself is also open weights so I can maintain the option to run it myself in the future if I ever need to.
The reason is that the embeddings I retrieve from this API only maintain their value if I can continue to calculate more of them in the future. If I'm going to spend money on calculating and storing embeddings I want to know that value is guaranteed far into the future.
If the only way to get new embeddings is via an API, and Mistral shut down that API (or go out of business), that investment I've made in the embeddings I've stored collapses in an instant.
I don't actually want to run the model myself. Paying Mistral $0.15 per million tokens (50% off for batch discounts) to not have to waste my own server's RAM and GPU holding that model in memory is great deal!
In this case, open weights is a feature I want purely because it gives me complete confidence in the future of my investment.
Building software on top of Large Language Models

I presented a three hour workshop at PyCon US yesterday titled Building software on top of Large Language Models. The goal of the workshop was to give participants everything they needed to get started writing code that makes use of LLMs.
[... 3,726 words]Cursor: Security (via) Cursor's security documentation page includes a surprising amount of detail about how the Cursor text editor's backend systems work.
I've recently learned that checking an organization's list of documented subprocessors is a great way to get a feel for how everything works under the hood - it's a loose "view source" for their infrastructure! That was how I confirmed that Anthropic's search features used Brave search back in March.
Cursor's list includes AWS, Azure and GCP (AWS for primary infrastructure, Azure and GCP for "some secondary infrastructure"). They host their own custom models on Fireworks and make API calls out to OpenAI, Anthropic, Gemini and xAI depending on user preferences. They're using turbopuffer as a hosted vector store.
The most interesting section is about codebase indexing:
Cursor allows you to semantically index your codebase, which allows it to answer questions with the context of all of your code as well as write better code by referencing existing implementations. […]
At our server, we chunk and embed the files, and store the embeddings in Turbopuffer. To allow filtering vector search results by file path, we store with every vector an obfuscated relative file path, as well as the line range the chunk corresponds to. We also store the embedding in a cache in AWS, indexed by the hash of the chunk, to ensure that indexing the same codebase a second time is much faster (which is particularly useful for teams).
At inference time, we compute an embedding, let Turbopuffer do the nearest neighbor search, send back the obfuscated file path and line range to the client, and read those file chunks on the client locally. We then send those chunks back up to the server to answer the user’s question.
When operating in privacy mode - which they say is enabled by 50% of their users - they are careful not to store any raw code on their servers for longer than the duration of a single request. This is why they store the embeddings and obfuscated file paths but not the code itself.
Reading this made me instantly think of the paper Text Embeddings Reveal (Almost) As Much As Text about how vector embeddings can be reversed. The security documentation touches on that in the notes:
Embedding reversal: academic work has shown that reversing embeddings is possible in some cases. Current attacks rely on having access to the model and embedding short strings into big vectors, which makes us believe that the attack would be somewhat difficult to do here. That said, it is definitely possible for an adversary who breaks into our vector database to learn things about the indexed codebases.
Nomic Embed Code: A State-of-the-Art Code Retriever. Nomic have released a new embedding model that specializes in code, based on their CoRNStack "large-scale high-quality training dataset specifically curated for code retrieval".
The nomic-embed-code model is pretty large - 26.35GB - but the announcement also mentioned a much smaller model (released 5 months ago) called CodeRankEmbed which is just 521.60MB.
I missed that when it first came out, so I decided to give it a try using my llm-sentence-transformers plugin for LLM.
llm install llm-sentence-transformers
llm sentence-transformers register nomic-ai/CodeRankEmbed --trust-remote-code
Now I can run the model like this:
llm embed -m sentence-transformers/nomic-ai/CodeRankEmbed -c 'hello'
This outputs an array of 768 numbers, starting [1.4794224500656128, -0.474479079246521, ....
Where this gets fun is combining it with my Symbex tool to create and then search embeddings for functions in a codebase.
I created an index for my LLM codebase like this:
cd llm
symbex '*' '*.*' --nl > code.txt
This creates a newline-separated JSON file of all of the functions (from '*') and methods (from '*.*') in the current directory - you can see that here.
Then I fed that into the llm embed-multi command like this:
llm embed-multi \
-d code.db \
-m sentence-transformers/nomic-ai/CodeRankEmbed \
code code.txt \
--format nl \
--store \
--batch-size 10
I found the --batch-size was needed to prevent it from crashing with an error.
The above command creates a collection called code in a SQLite database called code.db.
Having run this command I can search for functions that match a specific search term in that code collection like this:
llm similar code -d code.db \
-c 'Represent this query for searching relevant code: install a plugin' | jq
That "Represent this query for searching relevant code: " prefix is required by the model. I pipe it through jq to make it a little more readable, which gives me these results.
This jq recipe makes for a better output:
llm similar code -d code.db \
-c 'Represent this query for searching relevant code: install a plugin' | \
jq -r '.id + "\n\n" + .content + "\n--------\n"'
The output from that starts like so:
llm/cli.py:1776
@cli.command(name="plugins")
@click.option("--all", help="Include built-in default plugins", is_flag=True)
def plugins_list(all):
"List installed plugins"
click.echo(json.dumps(get_plugins(all), indent=2))
--------
llm/cli.py:1791
@cli.command()
@click.argument("packages", nargs=-1, required=False)
@click.option(
"-U", "--upgrade", is_flag=True, help="Upgrade packages to latest version"
)
...
def install(packages, upgrade, editable, force_reinstall, no_cache_dir):
"""Install packages from PyPI into the same environment as LLM"""
Getting this output was quite inconvenient, so I've opened an issue.
State-of-the-art text embedding via the Gemini API
(via)
Gemini just released their new text embedding model, with the snappy name gemini-embedding-exp-03-07. It supports 8,000 input tokens - up from 3,000 - and outputs vectors that are a lot larger than their previous text-embedding-004 model - that one output size 768 vectors, the new model outputs 3072.
Storing that many floating point numbers for each embedded record can use a lot of space. thankfully, the new model supports Matryoshka Representation Learning - this means you can simply truncate the vectors to trade accuracy for storage.
I added support for the new model in llm-gemini 0.14. LLM doesn't yet have direct support for Matryoshka truncation so I instead registered different truncated sizes of the model under different IDs: gemini-embedding-exp-03-07-2048, gemini-embedding-exp-03-07-1024, gemini-embedding-exp-03-07-512, gemini-embedding-exp-03-07-256, gemini-embedding-exp-03-07-128.
The model is currently free while it is in preview, but comes with a strict rate limit - 5 requests per minute and just 100 requests a day. I quickly tripped those limits while testing out the new model - I hope they can bump those up soon.
The Best Way to Use Text Embeddings Portably is With Parquet and Polars. Fantastic piece on embeddings by Max Woolf, who uses a 32,000 vector collection of Magic: the Gathering card embeddings to explore efficient ways of storing and processing them.
Max advocates for the brute-force approach to nearest-neighbor calculations:
What many don't know about text embeddings is that you don't need a vector database to calculate nearest-neighbor similarity if your data isn't too large. Using numpy and my Magic card embeddings, a 2D matrix of 32,254
float32embeddings at a dimensionality of 768D (common for "smaller" LLM embedding models) occupies 94.49 MB of system memory, which is relatively low for modern personal computers and can fit within free usage tiers of cloud VMs.
He uses this brilliant snippet of Python code to find the top K matches by distance:
def fast_dot_product(query, matrix, k=3): dot_products = query @ matrix.T idx = np.argpartition(dot_products, -k)[-k:] idx = idx[np.argsort(dot_products[idx])[::-1]] score = dot_products[idx] return idx, score
Since dot products are such a fundamental aspect of linear algebra, numpy's implementation is extremely fast: with the help of additional numpy sorting shenanigans, on my M3 Pro MacBook Pro it takes just 1.08 ms on average to calculate all 32,254 dot products, find the top 3 most similar embeddings, and return their corresponding
idxof the matrix and and cosine similarityscore.
I ran that Python code through Claude 3.7 Sonnet for an explanation, which I can share here using their brand new "Share chat" feature. TIL about numpy.argpartition!
He explores multiple options for efficiently storing these embedding vectors, finding that naive CSV storage takes 631.5 MB while pickle uses 94.49 MB and his preferred option, Parquet via Polars, uses 94.3 MB and enables some neat zero-copy optimization tricks.
Nomic Embed Text V2: An Open Source, Multilingual, Mixture-of-Experts Embedding Model (via) Nomic continue to release the most interesting and powerful embedding models. Their latest is Embed Text V2, an Apache 2.0 licensed multi-lingual 1.9GB model (here it is on Hugging Face) trained on "1.6 billion high-quality data pairs", which is the first embedding model I've seen to use a Mixture of Experts architecture:
In our experiments, we found that alternating MoE layers with 8 experts and top-2 routing provides the optimal balance between performance and efficiency. This results in 475M total parameters in the model, but only 305M active during training and inference.
I first tried it out using uv run like this:
uv run \
--with einops \
--with sentence-transformers \
--python 3.13 pythonThen:
from sentence_transformers import SentenceTransformer model = SentenceTransformer("nomic-ai/nomic-embed-text-v2-moe", trust_remote_code=True) sentences = ["Hello!", "¡Hola!"] embeddings = model.encode(sentences, prompt_name="passage") print(embeddings)
Then I got it working on my laptop using the llm-sentence-tranformers plugin like this:
llm install llm-sentence-transformers
llm install einops # additional necessary package
llm sentence-transformers register nomic-ai/nomic-embed-text-v2-moe --trust-remote-code
llm embed -m sentence-transformers/nomic-ai/nomic-embed-text-v2-moe -c 'string to embed'
This outputs a 768 item JSON array of floating point numbers to the terminal. These are Matryoshka embeddings which means you can truncate that down to just the first 256 items and get similarity calculations that still work albeit slightly less well.
To use this for RAG you'll need to conform to Nomic's custom prompt format. For documents to be searched:
search_document: text of document goes here
And for search queries:
search_query: term to search for
I landed a new --prepend option for the llm embed-multi command to help with that, but it's not out in a full release just yet. (Update: it's now out in LLM 0.22.)
I also released llm-sentence-transformers 0.3 with some minor improvements to make running this model more smooth.
2024
Looking back, it's clear we overcomplicated things. While embeddings fundamentally changed how we can represent and compare content, they didn't need an entirely new infrastructure category. What we label as "vector databases" are, in reality, search engines with vector capabilities. The market is already correcting this categorization—vector search providers rapidly add traditional search features while established search engines incorporate vector search capabilities. This category convergence isn't surprising: building a good retrieval engine has always been about combining multiple retrieval and ranking strategies. Vector search is just another powerful tool in that toolbox, not a category of its own.
Clio: A system for privacy-preserving insights into real-world AI use. New research from Anthropic, describing a system they built called Clio - for Claude insights and observations - which attempts to provide insights into how Claude is being used by end-users while also preserving user privacy.
There's a lot to digest here. The summary is accompanied by a full paper and a 47 minute YouTube interview with team members Deep Ganguli, Esin Durmus, Miles McCain and Alex Tamkin.
The key idea behind Clio is to take user conversations and use Claude to summarize, cluster and then analyze those clusters - aiming to ensure that any private or personally identifiable details are filtered out long before the resulting clusters reach human eyes.
This diagram from the paper helps explain how that works:
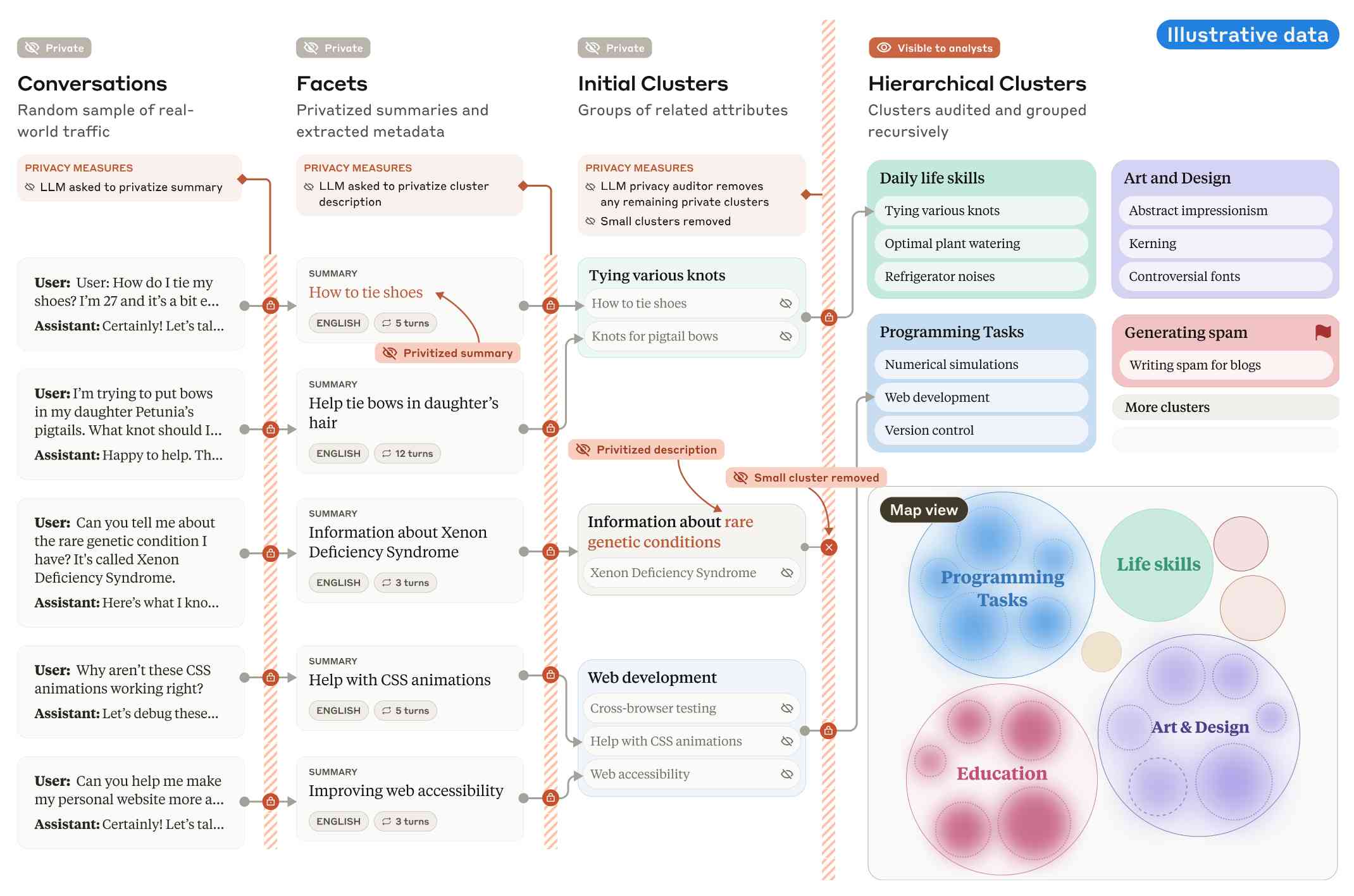
Claude generates a conversation summary, than extracts "facets" from that summary that aim to privatize the data to simple characteristics like language and topics.
The facets are used to create initial clusters (via embeddings), and those clusters further filtered to remove any that are too small or may contain private information. The goal is to have no cluster which represents less than 1,000 underlying individual users.
In the video at 16:39:
And then we can use that to understand, for example, if Claude is as useful giving web development advice for people in English or in Spanish. Or we can understand what programming languages are people generally asking for help with. We can do all of this in a really privacy preserving way because we are so far removed from the underlying conversations that we're very confident that we can use this in a way that respects the sort of spirit of privacy that our users expect from us.
Then later at 29:50 there's this interesting hint as to how Anthropic hire human annotators to improve Claude's performance in specific areas:
But one of the things we can do is we can look at clusters with high, for example, refusal rates, or trust and safety flag rates. And then we can look at those and say huh, this is clearly an over-refusal, this is clearly fine. And we can use that to sort of close the loop and say, okay, well here are examples where we wanna add to our, you know, human training data so that Claude is less refusally in the future on those topics.
And importantly, we're not using the actual conversations to make Claude less refusally. Instead what we're doing is we are looking at the topics and then hiring people to generate data in those domains and generating synthetic data in those domains.
So we're able to sort of use our users activity with Claude to improve their experience while also respecting their privacy.
According to Clio the top clusters of usage for Claude right now are as follows:
- Web & Mobile App Development (10.4%)
- Content Creation & Communication (9.2%)
- Academic Research & Writing (7.2%)
- Education & Career Development (7.1%)
- Advanced AI/ML Applications (6.0%)
- Business Strategy & Operations (5.7%)
- Language Translation (4.5%)
- DevOps & Cloud Infrastructure (3.9%)
- Digital Marketing & SEO (3.7%)
- Data Analysis & Visualization (3.5%)
There also are some interesting insights about variations in usage across different languages. For example, Chinese language users had "Write crime, thriller, and mystery fiction with complex plots and characters" at 4.4x the base rate for other languages.
Is async Django ready for prime time? (via) Jonathan Adly reports on his experience using Django to build ColiVara, a hosted RAG API that uses ColQwen2 visual embeddings, inspired by the ColPali paper.
In a breach of Betteridge's law of headlines the answer to the question posed by this headline is “yes”.
We believe async Django is ready for production. In theory, there should be no performance loss when using async Django instead of FastAPI for the same tasks.
The ColiVara application is itself open source, and you can see how it makes use of Django’s relatively new asynchronous ORM features in the api/views.py module.
I also picked up a useful trick from their Dockerfile: if you want uv in a container you can install it with this one-liner:
COPY --from=ghcr.io/astral-sh/uv:latest /uv /bin/uv
Weeknotes: asynchronous LLMs, synchronous embeddings, and I kind of started a podcast
These past few weeks I’ve been bringing Datasette and LLM together and distracting myself with a new sort-of-podcast crossed with a live streaming experiment.
[... 896 words]llm-gguf 0.2, now with embeddings. This new release of my llm-gguf plugin - which provides support for locally hosted GGUF LLMs - adds a new feature: it now supports embedding models distributed as GGUFs as well.
This means you can use models like the bafflingly small (30.8MB in its smallest quantization) mxbai-embed-xsmall-v1 with LLM like this:
llm install llm-gguf
llm gguf download-embed-model \
'https://huggingface.co/mixedbread-ai/mxbai-embed-xsmall-v1/resolve/main/gguf/mxbai-embed-xsmall-v1-q8_0.gguf'
Then to embed a string:
llm embed -m gguf/mxbai-embed-xsmall-v1-q8_0 -c 'hello'
The LLM docs have extensive coverage of things you can then do with this model, like embedding every row in a CSV file / file in a directory / record in a SQLite database table and running similarity and semantic search against them.
Under the hood this takes advantage of the create_embedding() method provided by the llama-cpp-python wrapper around llama.cpp.
Binary vector embeddings are so cool (via) Evan Schwartz:
Vector embeddings by themselves are pretty neat. Binary quantized vector embeddings are extra impressive. In short, they can retain 95+% retrieval accuracy with 32x compression and ~25x retrieval speedup.
It's so unintuitive how well this trick works: take a vector of 1024x4 byte floating point numbers (4096 bytes = 32,768 bits), turn that into an array of single bits for > 0 or <= 0 which reduces it to just 1024 bits or 128 bytes - a 1/32 reduction.
Now you can compare vectors using a simple Hamming distance - a count of the number of bits that differ - and yet still get embedding similarity scores that are only around 10% less accurate than if you had used the much larger floating point numbers.
Evan digs into models that this works for, which include OpenAI's text-embedding-3-large and the small but powerful all-MiniLM-L6-v2.
Bridging Language Gaps in Multilingual Embeddings via Contrastive Learning (via) Most text embeddings models suffer from a "language gap", where phrases in different languages with the same semantic meaning end up with embedding vectors that aren't clustered together.
Jina claim their new jina-embeddings-v3 (CC BY-NC 4.0, which means you need to license it for commercial use if you're not using their API) is much better on this front, thanks to a training technique called "contrastive learning".
There are 30 languages represented in our contrastive learning dataset, but 97% of pairs and triplets are in just one language, with only 3% involving cross-language pairs or triplets. But this 3% is enough to produce a dramatic result: Embeddings show very little language clustering and semantically similar texts produce close embeddings regardless of their language

Hybrid full-text search and vector search with SQLite. As part of Alex’s work on his sqlite-vec SQLite extension - adding fast vector lookups to SQLite - he’s been investigating hybrid search, where search results from both vector similarity and traditional full-text search are combined together.
The most promising approach looks to be Reciprocal Rank Fusion, which combines the top ranked items from both approaches. Here’s Alex’s SQL query:
-- the sqlite-vec KNN vector search results
with vec_matches as (
select
article_id,
row_number() over (order by distance) as rank_number,
distance
from vec_articles
where
headline_embedding match lembed(:query)
and k = :k
),
-- the FTS5 search results
fts_matches as (
select
rowid,
row_number() over (order by rank) as rank_number,
rank as score
from fts_articles
where headline match :query
limit :k
),
-- combine FTS5 + vector search results with RRF
final as (
select
articles.id,
articles.headline,
vec_matches.rank_number as vec_rank,
fts_matches.rank_number as fts_rank,
-- RRF algorithm
(
coalesce(1.0 / (:rrf_k + fts_matches.rank_number), 0.0) * :weight_fts +
coalesce(1.0 / (:rrf_k + vec_matches.rank_number), 0.0) * :weight_vec
) as combined_rank,
vec_matches.distance as vec_distance,
fts_matches.score as fts_score
from fts_matches
full outer join vec_matches on vec_matches.article_id = fts_matches.rowid
join articles on articles.rowid = coalesce(fts_matches.rowid, vec_matches.article_id)
order by combined_rank desc
)
select * from final;I’ve been puzzled in the past over how to best do that because the distance scores from vector similarity and the relevance scores from FTS are meaningless in comparison to each other. RRF doesn’t even attempt to compare them - it uses them purely for row_number() ranking within each set and combines the results based on that.
Conflating Overture Places Using DuckDB, Ollama, Embeddings, and More.
Drew Breunig's detailed tutorial on "conflation" - combining different geospatial data sources by de-duplicating address strings such as RESTAURANT LOS ARCOS,3359 FOOTHILL BLVD,OAKLAND,94601 and LOS ARCOS TAQUERIA,3359 FOOTHILL BLVD,OAKLAND,94601.
Drew uses an entirely offline stack based around Python, DuckDB and Ollama and finds that a combination of H3 geospatial tiles and mxbai-embed-large embeddings (though other embedding models should work equally well) gets really good results.
Introducing Contextual Retrieval (via) Here's an interesting new embedding/RAG technique, described by Anthropic but it should work for any embedding model against any other LLM.
One of the big challenges in implementing semantic search against vector embeddings - often used as part of a RAG system - is creating "chunks" of documents that are most likely to semantically match queries from users.
Anthropic provide this solid example where semantic chunks might let you down:
Imagine you had a collection of financial information (say, U.S. SEC filings) embedded in your knowledge base, and you received the following question: "What was the revenue growth for ACME Corp in Q2 2023?"
A relevant chunk might contain the text: "The company's revenue grew by 3% over the previous quarter." However, this chunk on its own doesn't specify which company it's referring to or the relevant time period, making it difficult to retrieve the right information or use the information effectively.
Their proposed solution is to take each chunk at indexing time and expand it using an LLM - so the above sentence would become this instead:
This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter.
This chunk was created by Claude 3 Haiku (their least expensive model) using the following prompt template:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
Here's the really clever bit: running the above prompt for every chunk in a document could get really expensive thanks to the inclusion of the entire document in each prompt. Claude added context caching last month, which allows you to pay around 1/10th of the cost for tokens cached up to your specified beakpoint.
By Anthropic's calculations:
Assuming 800 token chunks, 8k token documents, 50 token context instructions, and 100 tokens of context per chunk, the one-time cost to generate contextualized chunks is $1.02 per million document tokens.
Anthropic provide a detailed notebook demonstrating an implementation of this pattern. Their eventual solution combines cosine similarity and BM25 indexing, uses embeddings from Voyage AI and adds a reranking step powered by Cohere.
The notebook also includes an evaluation set using JSONL - here's that evaluation data in Datasette Lite.
OpenAI: Improve file search result relevance with chunk ranking (via) I've mostly been ignoring OpenAI's Assistants API. It provides an alternative to their standard messages API where you construct "assistants", chatbots with optional access to additional tools and that store full conversation threads on the server so you don't need to pass the previous conversation with every call to their API.
I'm pretty comfortable with their existing API and I found the assistants API to be quite a bit more complicated. So far the only thing I've used it for is a script to scrape OpenAI Code Interpreter to keep track of updates to their enviroment's Python packages.
Code Interpreter aside, the other interesting assistants feature is File Search. You can upload files in a wide variety of formats and OpenAI will chunk them, store the chunks in a vector store and make them available to help answer questions posed to your assistant - it's their version of hosted RAG.
Prior to today OpenAI had kept the details of how this worked undocumented. I found this infuriating, because when I'm building a RAG system the details of how files are chunked and scored for relevance is the whole game - without understanding that I can't make effective decisions about what kind of documents to use and how to build on top of the tool.
This has finally changed! You can now run a "step" (a round of conversation in the chat) and then retrieve details of exactly which chunks of the file were used in the response and how they were scored using the following incantation:
run_step = client.beta.threads.runs.steps.retrieve( thread_id="thread_abc123", run_id="run_abc123", step_id="step_abc123", include=[ "step_details.tool_calls[*].file_search.results[*].content" ] )
(See what I mean about the API being a little obtuse?)
I tried this out today and the results were very promising. Here's a chat transcript with an assistant I created against an old PDF copy of the Datasette documentation - I used the above new API to dump out the full list of snippets used to answer the question "tell me about ways to use spatialite".
It pulled in a lot of content! 57,017 characters by my count, spread across 20 search results (customizable), for a total of 15,021 tokens as measured by ttok. At current GPT-4o-mini prices that would cost 0.225 cents (less than a quarter of a cent), but with regular GPT-4o it would cost 7.5 cents.
OpenAI provide up to 1GB of vector storage for free, then charge $0.10/GB/day for vector storage beyond that. My 173 page PDF seems to have taken up 728KB after being chunked and stored, so that GB should stretch a pretty long way.
Confession: I couldn't be bothered to work through the OpenAI code examples myself, so I hit Ctrl+A on that web page and copied the whole lot into Claude 3.5 Sonnet, then prompted it:
Based on this documentation, write me a Python CLI app (using the Click CLi library) with the following features:
openai-file-chat add-files name-of-vector-store *.pdf *.txt
This creates a new vector store called name-of-vector-store and adds all the files passed to the command to that store.
openai-file-chat name-of-vector-store1 name-of-vector-store2 ...
This starts an interactive chat with the user, where any time they hit enter the question is answered by a chat assistant using the specified vector stores.
We iterated on this a few times to build me a one-off CLI app for trying out the new features. It's got a few bugs that I haven't fixed yet, but it was a very productive way of prototyping against the new API.
Using sqlite-vec with embeddings in sqlite-utils and Datasette. My notes on trying out Alex Garcia's newly released sqlite-vec SQLite extension, including how to use it with OpenAI embeddings in both Datasette and sqlite-utils.
Introducing sqlite-lembed: A SQLite extension for generating text embeddings locally (via) Alex Garcia's latest SQLite extension is a C wrapper around the llama.cpp that exposes just its embedding support, allowing you to register a GGUF file containing an embedding model:
INSERT INTO temp.lembed_models(name, model)
select 'all-MiniLM-L6-v2',
lembed_model_from_file('all-MiniLM-L6-v2.e4ce9877.q8_0.gguf');
And then use it to calculate embeddings as part of a SQL query:
select lembed(
'all-MiniLM-L6-v2',
'The United States Postal Service is an independent agency...'
); -- X'A402...09C3' (1536 bytes)
all-MiniLM-L6-v2.e4ce9877.q8_0.gguf here is a 24MB file, so this should run quite happily even on machines without much available RAM.
What if you don't want to run the models locally at all? Alex has another new extension for that, described in Introducing sqlite-rembed: A SQLite extension for generating text embeddings from remote APIs. The rembed is for remote embeddings, and this extension uses Rust to call multiple remotely-hosted embeddings APIs, registered like this:
INSERT INTO temp.rembed_clients(name, options)
VALUES ('text-embedding-3-small', 'openai');
select rembed(
'text-embedding-3-small',
'The United States Postal Service is an independent agency...'
); -- X'A452...01FC', Blob<6144 bytes>
Here's the Rust code that implements Rust wrapper functions for HTTP JSON APIs from OpenAI, Nomic, Cohere, Jina, Mixedbread and localhost servers provided by Ollama and Llamafile.
Both of these extensions are designed to complement Alex's sqlite-vec extension, which is nearing a first stable release.
Searching an aerial photo with text queries. Robin Wilson built a demo that lets you search a large aerial photograph of Southampton for things like "roundabout" or "tennis court". He explains how it works in detail: he used the SkyCLIP model, which is trained on "5.2 million remote sensing image-text pairs in total, covering more than 29K distinct semantic tags" to generate embeddings for 200x200 image segments (with 100px of overlap), then stored them in Pinecone.
The Super Effectiveness of Pokémon Embeddings Using Only Raw JSON and Images.
A deep dive into embeddings from Max Woolf, exploring 1,000 different Pokémon (loaded from PokéAPI using this epic GraphQL query) and then embedding the cleaned up JSON data using nomic-embed-text-v1.5 and the official Pokémon image representations using nomic-embed-vision-v1.5.
I hadn't seen nomic-embed-vision-v1.5 before: it brings multimodality to Nomic embeddings and operates in the same embedding space as nomic-embed-text-v1.5 which means you can use it to perform CLIP-style tricks comparing text and images. Here's their announcement from June 5th:
Together, Nomic Embed is the only unified embedding space that outperforms OpenAI CLIP and OpenAI Text Embedding 3 Small on multimodal and text tasks respectively.
Sadly the new vision weights are available under a non-commercial Creative Commons license (unlike the text weights which are Apache 2), so if you want to use the vision weights commercially you'll need to access them via Nomic's paid API.
Nomic do say this though:
As Nomic releases future models, we intend to re-license less recent models in our catalogue under the Apache-2.0 license.
Update 17th January 2025: Nomic Embed Vision 1.5 is now Apache 2.0 licensed.
Val Vibes: Semantic search in Val Town. A neat case-study by JP Posma on how Val Town's developers can use Val Town Vals to build prototypes of new features that later make it into Val Town core.
This one explores building out semantic search against Vals using OpenAI embeddings and the PostgreSQL pgvector extension.
Using DuckDB for Embeddings and Vector Search (via) Sören Brunk's comprehensive tutorial combining DuckDB 1.0, a subset of German Wikipedia from Hugging Face (loaded using Parquet), the BGE M3 embedding model and DuckDB's new vss extension for implementing an HNSW vector index.