108 posts tagged “rust”
2026
[...] On the interesting side is how fungible programming languages are nowadays. Programming languages used to be LOCK IN, and they're increasingly not so. You think the Bun rewrite in Rust is good for Rust? Bun has shown they can be in probably any language they want in roughly a week or two. Rust is expendable. Its useful until its not then it can be thrown out. That's interesting!
— Mitchell Hashimoto, on Bun porting from Zig to Rust
russellromney/honker (via) "Postgres NOTIFY/LISTEN semantics" for SQLite, implemented as a Rust SQLite extension and various language bindings to help make use of it.
The design of this looks very solid. It lets you write Python code for queues that looks like this:
import honker db = honker.open("app.db") emails = db.queue("emails") emails.enqueue({"to": "alice@example.com"}) # Consume (in a worker process) async for job in emails.claim("worker-1"): send(job.payload) job.ack()
And Kafka-style durable streams like this:
stream = db.stream("user-events") with db.transaction() as tx: tx.execute("UPDATE users SET name=? WHERE id=?", [name, uid]) stream.publish({"user_id": uid, "change": "name"}, tx=tx) async for event in stream.subscribe(consumer="dashboard"): await push_to_browser(event)
It also adds 20+ custom SQL functions including these two:
SELECT notify('orders', '{"id":42}');
SELECT honker_stream_read_since('orders', 0, 1000);The extension requires WAL mode, and workers can poll the .db-wal file with a stat call every 1ms to get as close to real-time as possible without the expense of running a full SQL query.
honker implements the transactional outbox pattern, which ensures items are only queued if a transaction successfully commits. My favorite explanation of that pattern remains Transactionally Staged Job Drains in Postgres by Brandur Leach. It's great to see a new implementation of that pattern for SQLite.
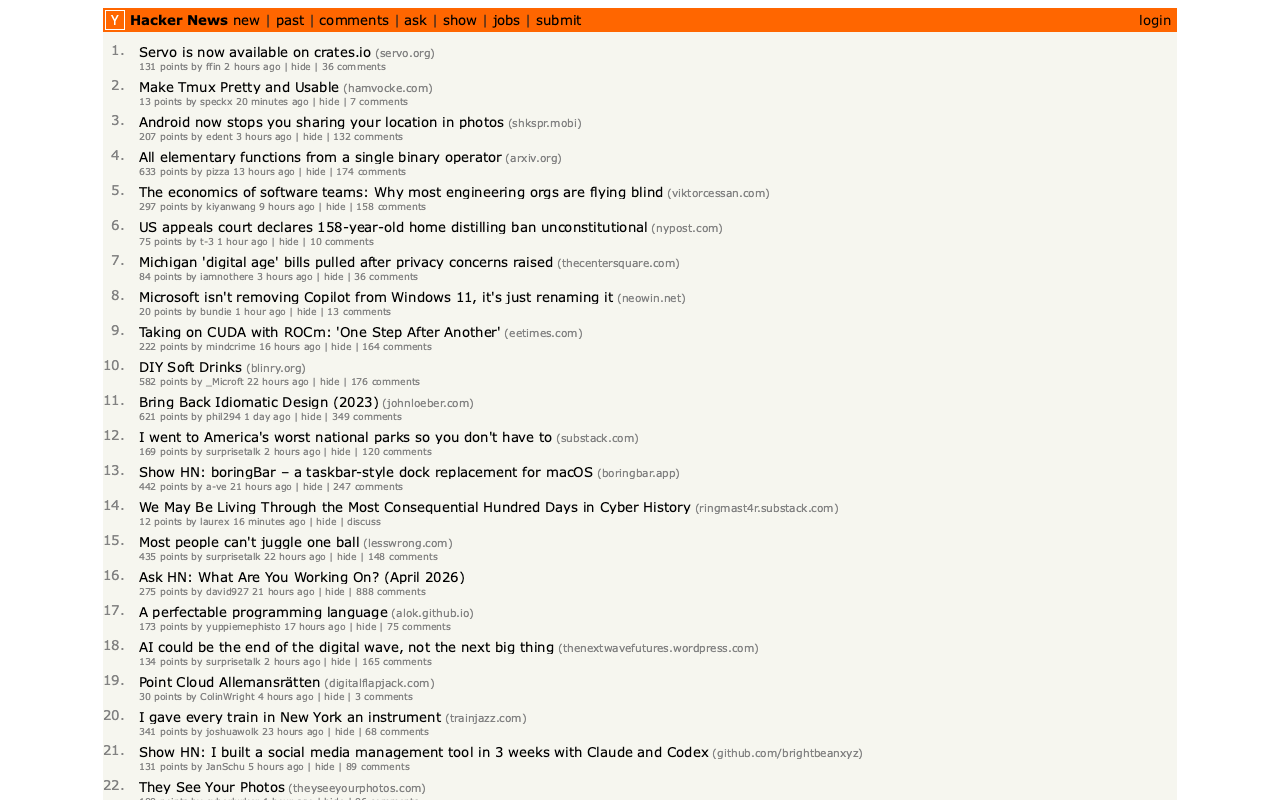
In Servo is now available on crates.io the Servo team announced the initial release of the servo crate, which packages their browser engine as an embeddable library.
I set Claude Code for web the task of figuring out what it can do, building a CLI tool for taking screenshots using it and working out if it could be compiled to WebAssembly.
The servo-shot Rust tool it built works pretty well:
git clone https://github.com/simonw/research
cd research/servo-crate-exploration/servo-shot
cargo build
./target/debug/servo-shot https://news.ycombinator.com/
Here's the result:
Compiling Servo itself to WebAssembly is not feasible due to its heavy use of threads and dependencies like SpiderMonkey, but Claude did build me this playground page for trying out a WebAssembly build of the html5ever and markup5ever_rcdom crates, providing a tool for turning fragments of HTML into a parse tree.
Thoughts on OpenAI acquiring Astral and uv/ruff/ty
The big news this morning: Astral to join OpenAI (on the Astral blog) and OpenAI to acquire Astral (the OpenAI announcement). Astral are the company behind uv, ruff, and ty—three increasingly load-bearing open source projects in the Python ecosystem. I have thoughts!
[... 1,378 words]An AI agent coding skeptic tries AI agent coding, in excessive detail. Another in the genre of "OK, coding agents got good in November" posts, this one is by Max Woolf and is very much worth your time. He describes a sequence of coding agent projects, each more ambitious than the last - starting with simple YouTube metadata scrapers and eventually evolving to this:
It would be arrogant to port Python's scikit-learn — the gold standard of data science and machine learning libraries — to Rust with all the features that implies.
But that's unironically a good idea so I decided to try and do it anyways. With the use of agents, I am now developing
rustlearn(extreme placeholder name), a Rust crate that implements not only the fast implementations of the standard machine learning algorithms such as logistic regression and k-means clustering, but also includes the fast implementations of the algorithms above: the same three step pipeline I describe above still works even with the more simple algorithms to beat scikit-learn's implementations.
Max also captures the frustration of trying to explain how good the models have got to an existing skeptical audience:
The real annoying thing about Opus 4.6/Codex 5.3 is that it’s impossible to publicly say “Opus 4.5 (and the models that came after it) are an order of magnitude better than coding LLMs released just months before it” without sounding like an AI hype booster clickbaiting, but it’s the counterintuitive truth to my personal frustration. I have been trying to break this damn model by giving it complex tasks that would take me months to do by myself despite my coding pedigree but Opus and Codex keep doing them correctly.
A throwaway remark in this post inspired me to ask Claude Code to build a Rust word cloud CLI tool, which it happily did.
Ladybird adopts Rust, with help from AI (via) Really interesting case-study from Andreas Kling on advanced, sophisticated use of coding agents for ambitious coding projects with critical code. After a few years hoping Swift's platform support outside of the Apple ecosystem would mature they switched tracks to Rust their memory-safe language of choice, starting with an AI-assisted port of a critical library:
Our first target was LibJS , Ladybird's JavaScript engine. The lexer, parser, AST, and bytecode generator are relatively self-contained and have extensive test coverage through test262, which made them a natural starting point.
I used Claude Code and Codex for the translation. This was human-directed, not autonomous code generation. I decided what to port, in what order, and what the Rust code should look like. It was hundreds of small prompts, steering the agents where things needed to go. [...]
The requirement from the start was byte-for-byte identical output from both pipelines. The result was about 25,000 lines of Rust, and the entire port took about two weeks. The same work would have taken me multiple months to do by hand. We’ve verified that every AST produced by the Rust parser is identical to the C++ one, and all bytecode generated by the Rust compiler is identical to the C++ compiler’s output. Zero regressions across the board.
Having an existing conformance testing suite of the quality of test262 is a huge unlock for projects of this magnitude, and the ability to compare output with an existing trusted implementation makes agentic engineering much more of a safe bet.
LadybirdBrowser/ladybird: Abandon Swift adoption (via) Back in August 2024 the Ladybird browser project announced an intention to adopt Swift as their memory-safe language of choice.
As of this commit it looks like they've changed their mind:
Everywhere: Abandon Swift adoption
After making no progress on this for a very long time, let's acknowledge it's not going anywhere and remove it from the codebase.
Update 23rd February 2025: They've adopted Rust instead.
Running Pydantic’s Monty Rust sandboxed Python subset in WebAssembly
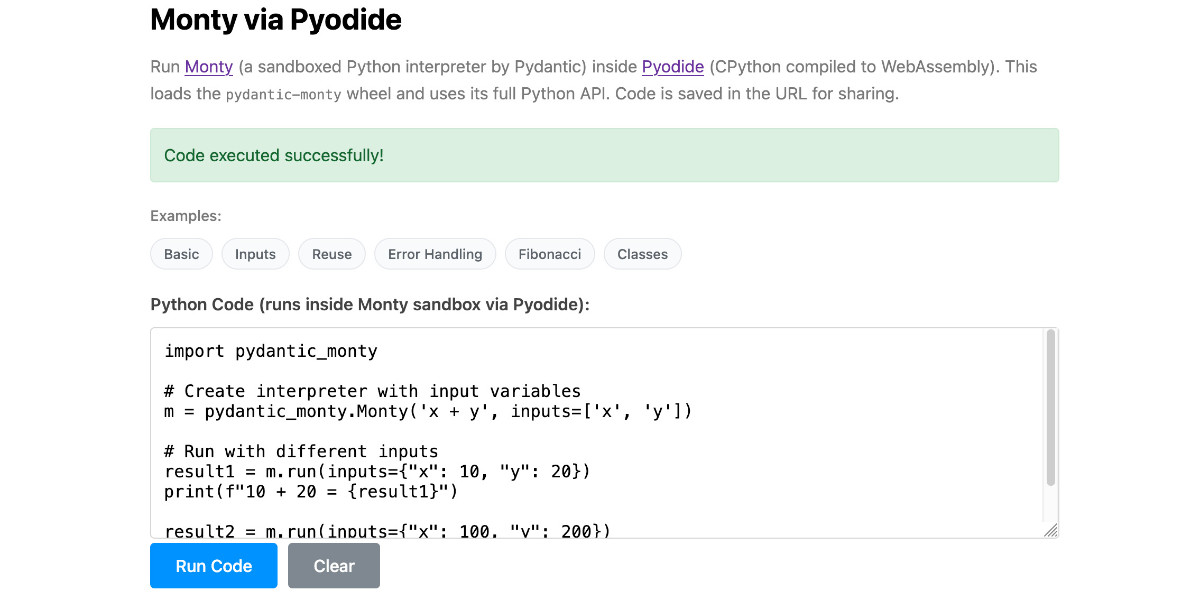
There’s a jargon-filled headline for you! Everyone’s building sandboxes for running untrusted code right now, and Pydantic’s latest attempt, Monty, provides a custom Python-like language (a subset of Python) in Rust and makes it available as both a Rust library and a Python package. I got it working in WebAssembly, providing a sandbox-in-a-sandbox.
[... 854 words]One Human + One Agent = One Browser From Scratch (via) embedding-shapes was so infuriated by the hype around Cursor's FastRender browser project - thousands of parallel agents producing ~1.6 million lines of Rust - that they were inspired to take a go at building a web browser using coding agents themselves.
The result is one-agent-one-browser and it's really impressive. Over three days they drove a single Codex CLI agent to build 20,000 lines of Rust that successfully renders HTML+CSS with no Rust crate dependencies at all - though it does (reasonably) use Windows, macOS and Linux system frameworks for image and text rendering.
I installed the 1MB macOS binary release and ran it against my blog:
chmod 755 ~/Downloads/one-agent-one-browser-macOS-ARM64
~/Downloads/one-agent-one-browser-macOS-ARM64 https://simonwillison.net/
Here's the result:
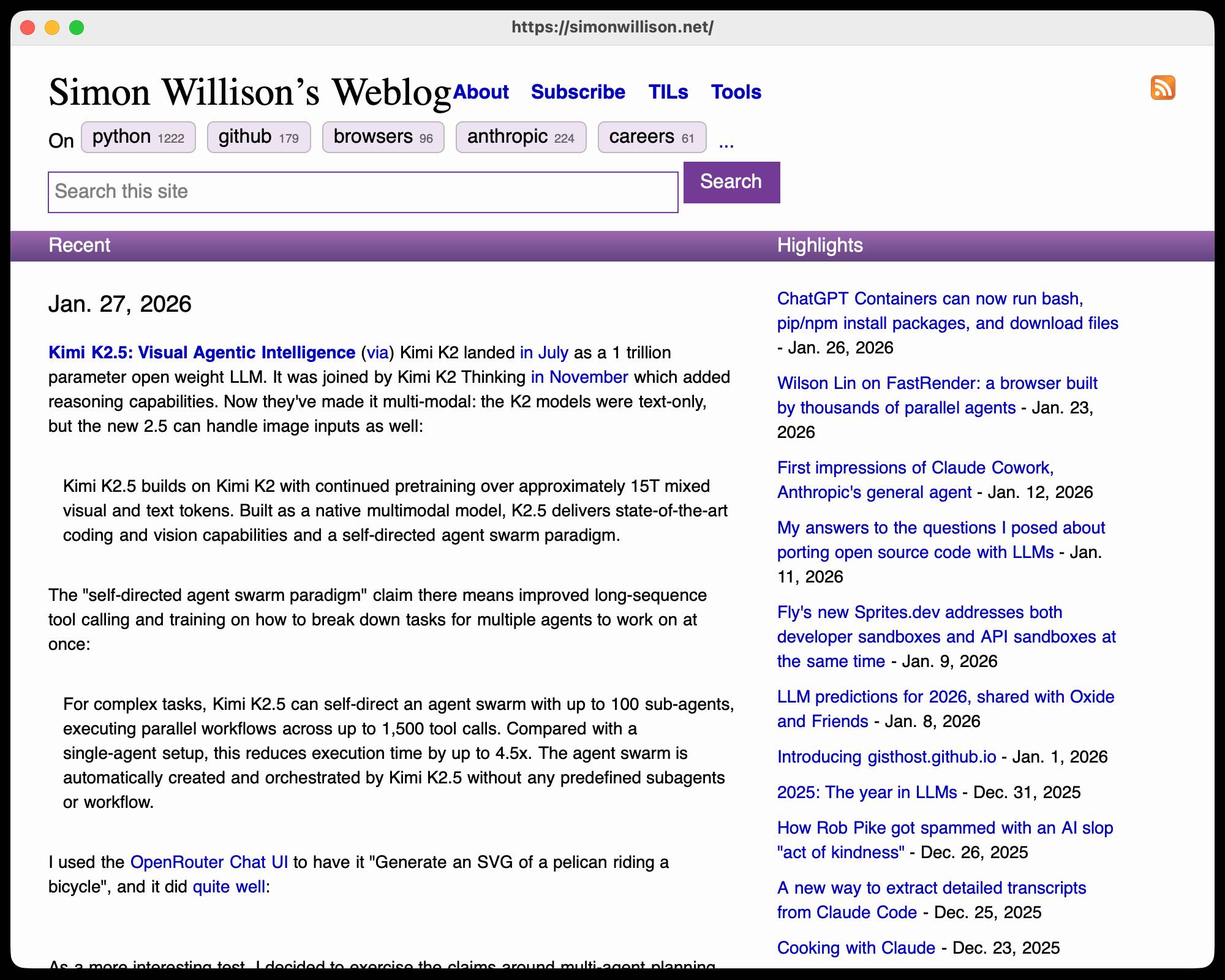
It even rendered my SVG feed subscription icon! A PNG image is missing from the page, which looks like an intermittent bug (there's code to render PNGs).
The code is pretty readable too - here's the flexbox implementation.
I had thought that "build a web browser" was the ideal prompt to really stretch the capabilities of coding agents - and that it would take sophisticated multi-agent harnesses (as seen in the Cursor project) and millions of lines of code to achieve.
Turns out one agent driven by a talented engineer, three days and 20,000 lines of Rust is enough to get a very solid basic renderer working!
I'm going to upgrade my prediction for 2029: I think we're going to get a production-grade web browser built by a small team using AI assistance by then.
Wilson Lin on FastRender: a browser built by thousands of parallel agents
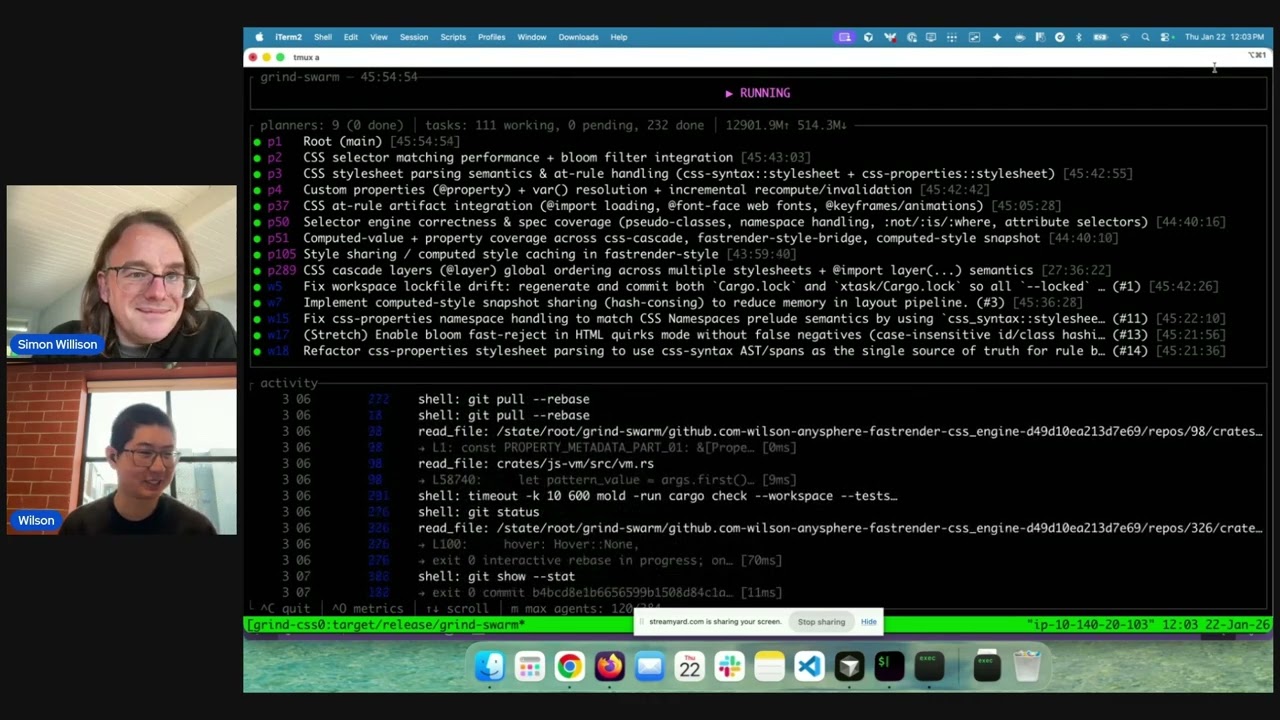
Last week Cursor published Scaling long-running autonomous coding, an article describing their research efforts into coordinating large numbers of autonomous coding agents. One of the projects mentioned in the article was FastRender, a web browser they built from scratch using their agent swarms. I wanted to learn more so I asked Wilson Lin, the engineer behind FastRender, if we could record a conversation about the project. That 47 minute video is now available on YouTube. I’ve included some of the highlights below.
[... 2,243 words]Scaling long-running autonomous coding. Wilson Lin at Cursor has been doing some experiments to see how far you can push a large fleet of "autonomous" coding agents:
This post describes what we've learned from running hundreds of concurrent agents on a single project, coordinating their work, and watching them write over a million lines of code and trillions of tokens.
They ended up running planners and sub-planners to create tasks, then having workers execute on those tasks - similar to how Claude Code uses sub-agents. Each cycle ended with a judge agent deciding if the project was completed or not.
In my predictions for 2026 the other day I said that by 2029:
I think somebody will have built a full web browser mostly using AI assistance, and it won’t even be surprising. Rolling a new web browser is one of the most complicated software projects I can imagine[...] the cheat code is the conformance suites. If there are existing tests that it’ll get so much easier.
I may have been off by three years, because Cursor chose "building a web browser from scratch" as their test case for their agent swarm approach:
To test this system, we pointed it at an ambitious goal: building a web browser from scratch. The agents ran for close to a week, writing over 1 million lines of code across 1,000 files. You can explore the source code on GitHub.
But how well did they do? Their initial announcement a couple of days ago was met with unsurprising skepticism, especially when it became apparent that their GitHub Actions CI was failing and there were no build instructions in the repo.
It looks like they addressed that within the past 24 hours. The latest README includes build instructions which I followed on macOS like this:
cd /tmp
git clone https://github.com/wilsonzlin/fastrender
cd fastrender
git submodule update --init vendor/ecma-rs
cargo run --release --features browser_ui --bin browser
This got me a working browser window! Here are screenshots I took of google.com and my own website:
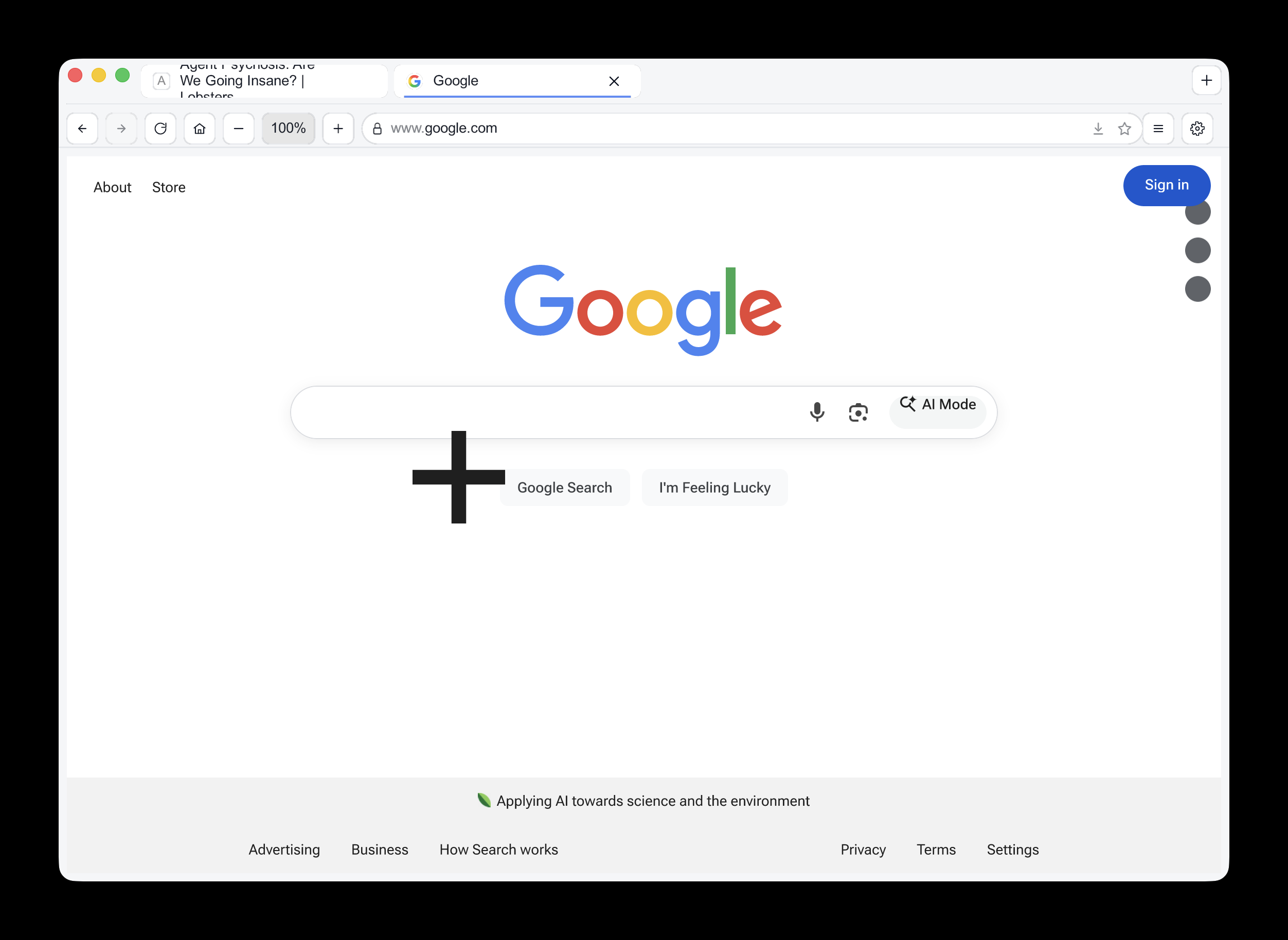
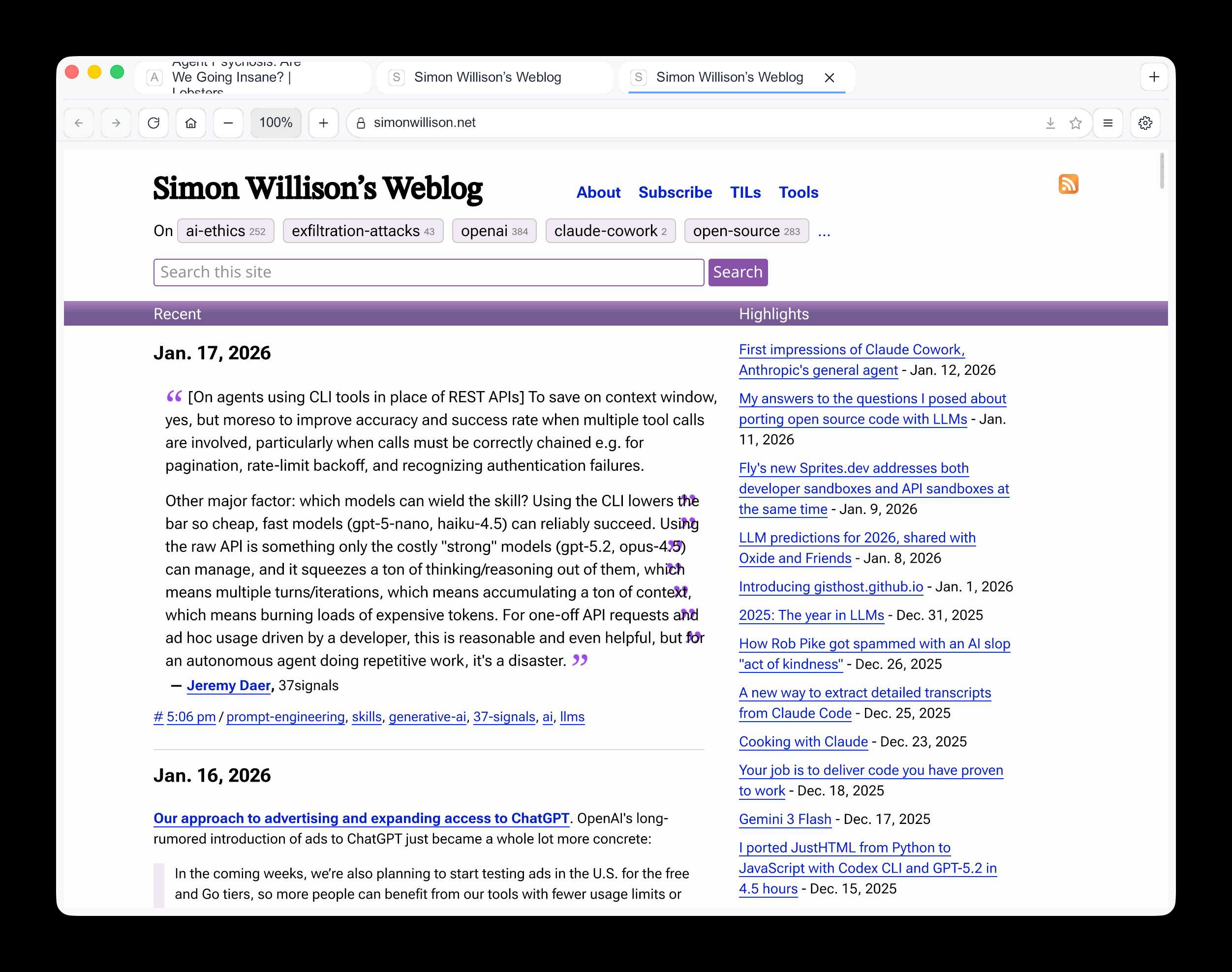
Honestly those are very impressive! You can tell they're not just wrapping an existing rendering engine because of those very obvious rendering glitches, but the pages are legible and look mostly correct.
The FastRender repo even uses Git submodules to include various WhatWG and CSS-WG specifications in the repo, which is a smart way to make sure the agents have access to the reference materials that they might need.
This is the second attempt I've seen at building a full web browser using AI-assisted coding in the past two weeks - the first was HiWave browser, a new browser engine in Rust first announced in this Reddit thread.
When I made my 2029 prediction this is more-or-less the quality of result I had in mind. I don't think we'll see projects of this nature compete with Chrome or Firefox or WebKit any time soon but I have to admit I'm very surprised to see something this capable emerge so quickly.
Update 23rd January 2026: I recorded a 47 minute conversation with Wilson about this project and published it on YouTube. Here's the video and accompanying highlights.
2025
How uv got so fast.
Andrew Nesbitt provides an insightful teardown of why uv is so much faster than pip. It's not nearly as simple as just "they rewrote it in Rust" - uv gets to skip a huge amount of Python packaging history (which pip needs to implement for backwards compatibility) and benefits enormously from work over recent years that makes it possible to resolve dependencies across most packages without having to execute the code in setup.py using a Python interpreter.
Two notes that caught my eye that I hadn't understood before:
HTTP range requests for metadata. Wheel files are zip archives, and zip archives put their file listing at the end. uv tries PEP 658 metadata first, falls back to HTTP range requests for the zip central directory, then full wheel download, then building from source. Each step is slower and riskier. The design makes the fast path cover 99% of cases. None of this requires Rust.
[...]
Compact version representation. uv packs versions into u64 integers where possible, making comparison and hashing fast. Over 90% of versions fit in one u64. This is micro-optimization that compounds across millions of comparisons.
I wanted to learn more about these tricks, so I fired up an asynchronous research task and told it to checkout the astral-sh/uv repo, find the Rust code for both of those features and try porting it to Python to help me understand how it works.
Here's the report that it wrote for me, the prompts I used and the Claude Code transcript.
You can try the script it wrote for extracting metadata from a wheel using HTTP range requests like this:
uv run --with httpx https://raw.githubusercontent.com/simonw/research/refs/heads/main/http-range-wheel-metadata/wheel_metadata.py https://files.pythonhosted.org/packages/8b/04/ef95b67e1ff59c080b2effd1a9a96984d6953f667c91dfe9d77c838fc956/playwright-1.57.0-py3-none-macosx_11_0_arm64.whl -v
The Playwright wheel there is ~40MB. Adding -v at the end causes the script to spit out verbose details of how it fetched the data - which looks like this.
Key extract from that output:
[1] HEAD request to get file size...
File size: 40,775,575 bytes
[2] Fetching last 16,384 bytes (EOCD + central directory)...
Received 16,384 bytes
[3] Parsed EOCD:
Central directory offset: 40,731,572
Central directory size: 43,981
Total entries: 453
[4] Fetching complete central directory...
...
[6] Found METADATA: playwright-1.57.0.dist-info/METADATA
Offset: 40,706,744
Compressed size: 1,286
Compression method: 8
[7] Fetching METADATA content (2,376 bytes)...
[8] Decompressed METADATA: 3,453 bytes
Total bytes fetched: 18,760 / 40,775,575 (100.0% savings)
The section of the report on compact version representation is interesting too. Here's how it illustrates sorting version numbers correctly based on their custom u64 representation:
Sorted order (by integer comparison of packed u64):
1.0.0a1 (repr=0x0001000000200001)
1.0.0b1 (repr=0x0001000000300001)
1.0.0rc1 (repr=0x0001000000400001)
1.0.0 (repr=0x0001000000500000)
1.0.0.post1 (repr=0x0001000000700001)
1.0.1 (repr=0x0001000100500000)
2.0.0.dev1 (repr=0x0002000000100001)
2.0.0 (repr=0x0002000000500000)
How to use a skill (progressive disclosure):
- After deciding to use a skill, open its
SKILL.md. Read only enough to follow the workflow.- If
SKILL.mdpoints to extra folders such asreferences/, load only the specific files needed for the request; don't bulk-load everything.- If
scripts/exist, prefer running or patching them instead of retyping large code blocks.- If
assets/or templates exist, reuse them instead of recreating from scratch.Description as trigger: The YAML
descriptioninSKILL.mdis the primary trigger signal; rely on it to decide applicability. If unsure, ask a brief clarification before proceeding.
— OpenAI Codex CLI, core/src/skills/render.rs, full prompt
Thoughts on Go vs. Rust vs. Zig (via) Thoughtful commentary on Go, Rust, and Zig by Sinclair Target. I haven't seen a single comparison that covers all three before and I learned a lot from reading this.
One thing that I hadn't noticed before is that none of these three languages implement class-based OOP.
Cloudflare's network began experiencing significant failures to deliver core network traffic [...] triggered by a change to one of our database systems' permissions which caused the database to output multiple entries into a “feature file” used by our Bot Management system. That feature file, in turn, doubled in size. The larger-than-expected feature file was then propagated to all the machines that make up our network. [...] The software had a limit on the size of the feature file that was below its doubled size. That caused the software to fail. [...]
This resulted in the following panic which in turn resulted in a 5xx error:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
— Matthew Prince, Cloudflare outage on November 18, 2025, see also this comment
Reverse engineering Codex CLI to get GPT-5-Codex-Mini to draw me a pelican

OpenAI partially released a new model yesterday called GPT-5-Codex-Mini, which they describe as "a more compact and cost-efficient version of GPT-5-Codex". It’s currently only available via their Codex CLI tool and VS Code extension, with proper API access "coming soon". I decided to use Codex to reverse engineer the Codex CLI tool and give me the ability to prompt the new model directly.
[... 1,774 words]I plan to introduce hard Rust dependencies and Rust code into APT, no earlier than May 2026. This extends at first to the Rust compiler and standard library, and the Sequoia ecosystem.
In particular, our code to parse .deb, .ar, .tar, and the HTTP signature verification code would strongly benefit from memory safe languages and a stronger approach to unit testing.
If you maintain a port without a working Rust toolchain, please ensure it has one within the next 6 months, or sunset the port.
— Julian Andres Klode, debian-devel mailing list
nanochat (via) Really interesting new project from Andrej Karpathy, described at length in this discussion post.
It provides a full ChatGPT-style LLM, including training, inference and a web Ui, that can be trained for as little as $100:
This repo is a full-stack implementation of an LLM like ChatGPT in a single, clean, minimal, hackable, dependency-lite codebase.
It's around 8,000 lines of code, mostly Python (using PyTorch) plus a little bit of Rust for training the tokenizer.
Andrej suggests renting a 8XH100 NVIDA node for around $24/ hour to train the model. 4 hours (~$100) is enough to get a model that can hold a conversation - almost coherent example here. Run it for 12 hours and you get something that slightly outperforms GPT-2. I'm looking forward to hearing results from longer training runs!
The resulting model is ~561M parameters, so it should run on almost anything. I've run a 4B model on my iPhone, 561M should easily fit on even an inexpensive Raspberry Pi.
The model defaults to training on ~24GB from karpathy/fineweb-edu-100b-shuffle derived from FineWeb-Edu, and then midtrains on 568K examples from SmolTalk (460K), MMLU auxiliary train (100K), and GSM8K (8K), followed by supervised finetuning on 21.4K examples from ARC-Easy (2.3K), ARC-Challenge (1.1K), GSM8K (8K), and SmolTalk (10K).
Here's the code for the web server, which is fronted by this pleasantly succinct vanilla JavaScript HTML+JavaScript frontend.
Update: Sam Dobson pushed a build of the model to sdobson/nanochat on Hugging Face. It's designed to run on CUDA but I pointed Claude Code at a checkout and had it hack around until it figured out how to run it on CPU on macOS, which eventually resulted in this script which I've published as a Gist. You should be able to try out the model using uv like this:
cd /tmp
git clone https://huggingface.co/sdobson/nanochat
uv run https://gist.githubusercontent.com/simonw/912623bf00d6c13cc0211508969a100a/raw/80f79c6a6f1e1b5d4485368ef3ddafa5ce853131/generate_cpu.py \
--model-dir /tmp/nanochat \
--prompt "Tell me about dogs."
I got this (truncated because it ran out of tokens):
I'm delighted to share my passion for dogs with you. As a veterinary doctor, I've had the privilege of helping many pet owners care for their furry friends. There's something special about training, about being a part of their lives, and about seeing their faces light up when they see their favorite treats or toys.
I've had the chance to work with over 1,000 dogs, and I must say, it's a rewarding experience. The bond between owner and pet
httpjail
(via)
Here's a promising new (experimental) project in the sandboxing space from Ammar Bandukwala at Coder. httpjail provides a Rust CLI tool for running an individual process against a custom configured HTTP proxy.
The initial goal is to help run coding agents like Claude Code and Codex CLI with extra rules governing how they interact with outside services. From Ammar's blog post that introduces the new tool, Fine-grained HTTP filtering for Claude Code:
httpjailimplements an HTTP(S) interceptor alongside process-level network isolation. Under default configuration, all DNS (udp:53) is permitted and all other non-HTTP(S) traffic is blocked.
httpjailrules are either JavaScript expressions or custom programs. This approach makes them far more flexible than traditional rule-oriented firewalls and avoids the learning curve of a DSL.Block all HTTP requests other than the LLM API traffic itself:
$ httpjail --js "r.host === 'api.anthropic.com'" -- claude "build something great"
I tried it out using OpenAI's Codex CLI instead and found this recipe worked:
brew upgrade rust
cargo install httpjail # Drops it in `~/.cargo/bin`
httpjail --js "r.host === 'chatgpt.com'" -- codex
Within that Codex instance the model ran fine but any attempts to access other URLs (e.g. telling it "Use curl to fetch simonwillison.net)" failed at the proxy layer.
This is still at a really early stage but there's a lot I like about this project. Being able to use JavaScript to filter requests via the --js option is neat (it's using V8 under the hood), and there's also a --sh shellscript option which instead runs a shell program passing environment variables that can be used to determine if the request should be allowed.
At a basic level it works by running a proxy server and setting HTTP_PROXY and HTTPS_PROXY environment variables so well-behaving software knows how to route requests.
It can also add a bunch of other layers. On Linux it sets up nftables rules to explicitly deny additional network access. There's also a --docker-run option which can launch a Docker container with the specified image but first locks that container down to only have network access to the httpjail proxy server.
It can intercept, filter and log HTTPS requests too by generating its own certificate and making that available to the underlying process.
I'm always interested in new approaches to sandboxing, and fine-grained network access is a particularly tricky problem to solve. This looks like a very promising step in that direction - I'm looking forward to seeing how this project continues to evolve.
I ran Claude in a loop for three months, and it created a genz programming language called cursed (via) Geoffrey Huntley vibe-coded an entirely new programming language using Claude:
The programming language is called "cursed". It's cursed in its lexical structure, it's cursed in how it was built, it's cursed that this is possible, it's cursed in how cheap this was, and it's cursed through how many times I've sworn at Claude.
Geoffrey's initial prompt:
Hey, can you make me a programming language like Golang but all the lexical keywords are swapped so they're Gen Z slang?
Then he pushed it to keep on iterating over a three month period.
Here's Hello World:
vibe main
yeet "vibez"
slay main() {
vibez.spill("Hello, World!")
}
And here's binary search, part of 17+ LeetCode problems that run as part of the test suite:
slay binary_search(nums normie[], target normie) normie {
sus left normie = 0
sus right normie = len(nums) - 1
bestie (left <= right) {
sus mid normie = left + (right - left) / 2
ready (nums[mid] == target) {
damn mid
}
ready (nums[mid] < target) {
left = mid + 1
} otherwise {
right = mid - 1
}
}
damn -1
}
This is a substantial project. The repository currently has 1,198 commits. It has both an interpreter mode and a compiler mode, and can compile programs to native binaries (via LLVM) for macOS, Linux and Windows.
It looks like it was mostly built using Claude running via Sourcegraph's Amp, which produces detailed commit messages. The commits include links to archived Amp sessions but sadly those don't appear to be publicly visible.
The first version was written in C, then Geoffrey had Claude port it to Rust and then Zig. His cost estimate:
Technically it costs about 5k usd to build your own compiler now because cursed was implemented first in c, then rust, now zig. So yeah, it’s not one compiler it’s three editions of it. For a total of $14k USD.
If you've been experimenting with OpenAI's Codex CLI and have been frustrated that it's not possible to select text and copy it to the clipboard, at least when running in the Mac terminal (I genuinely didn't know it was possible to build a terminal app that disabled copy and paste) you should know that they fixed that in this issue last week.
The new 0.20.0 version from three days ago also completely removes the old TypeScript codebase in favor of Rust. Even installations via NPM now get the Rust version.
I originally installed Codex via Homebrew, so I had to run this command to get the updated version:
brew upgrade codex
Another Codex tip: to use GPT-5 (or any other specific OpenAI model) you can run it like this:
export OPENAI_DEFAULT_MODEL="gpt-5"
codex
This no longer works, see update below.
I've been using a codex-5 script on my PATH containing this, because sometimes I like to live dangerously!
#!/usr/bin/env zsh
# Usage: codex-5 [additional args passed to `codex`]
export OPENAI_DEFAULT_MODEL="gpt-5"
exec codex --dangerously-bypass-approvals-and-sandbox "$@"
Update: It looks like GPT-5 is the default model in v0.20.0 already.
Also the environment variable I was using no longer does anything, it was removed in this commit (I used Codex Web to help figure that out). You can use the -m model_id command-line option instead.
Shipping WebGPU on Windows in Firefox 141 (via) WebGPU is coming to Mac and Linux soon as well:
Although Firefox 141 enables WebGPU only on Windows, we plan to ship WebGPU on Mac and Linux in the coming months, and finally on Android.
From this article I learned that it's already available in Firefox Nightly:
Note that WebGPU has been available in Firefox Nightly on all platforms other than Android for quite some time.
I tried the most recent Nightly on my Mac and now the Github Issue Generator running locally w/ SmolLM2 & WebGPU demo (previously) works! Firefox stable gives me an error message saying "Error: WebGPU is not supported in your current environment, but it is necessary to run the WebLLM engine."
The Firefox implementation is based on wgpu, an open source Rust WebGPU library.
crates.io: Trusted Publishing (via) crates.io is the Rust ecosystem's equivalent of PyPI. Inspired by PyPI's GitHub integration (see my TIL, I use this for dozens of my packages now) they've added a similar feature:
Trusted Publishing eliminates the need for GitHub Actions secrets when publishing crates from your CI/CD pipeline. Instead of managing API tokens, you can now configure which GitHub repository you trust directly on crates.io.
They're missing one feature that PyPI has: on PyPI you can create a "pending publisher" for your first release. crates.io currently requires the first release to be manual:
To get started with Trusted Publishing, you'll need to publish your first release manually. After that, you can set up trusted publishing for future releases.
Agentic Coding Recommendations (via) There's a ton of actionable advice on using Claude Code in this new piece from Armin Ronacher. He's getting excellent results from Go, especially having invested a bunch of work in making the various tools (linters, tests, logs, development servers etc) as accessible as possible through documenting them in a Makefile.
I liked this tip on logging:
In general logging is super important. For instance my app currently has a sign in and register flow that sends an email to the user. In debug mode (which the agent runs in), the email is just logged to stdout. This is crucial! It allows the agent to complete a full sign-in with a remote controlled browser without extra assistance. It knows that emails are being logged thanks to a
CLAUDE.mdinstruction and it automatically consults the log for the necessary link to click.
Armin also recently shared a half hour YouTube video in which he worked with Claude Code to resolve two medium complexity issues in his minijinja Rust templating library, resulting in PR #805 and PR #804.
astral-sh/ty (via) Astral have been working on this "extremely fast Python type checker and language server, written in Rust" quietly but in-the-open for a while now. Here's the first alpha public release - albeit not yet announced - as ty on PyPI (nice donated two-letter name!)
You can try it out via uvx like this - run the command in a folder full of Python code and see what comes back:
uvx ty check
I got zero errors for my recent, simple condense-json library and a ton of errors for my more mature sqlite-utils library - output here.
It really is fast:
cd /tmp
git clone https://github.com/simonw/sqlite-utils
cd sqlite-utils
time uvx ty check
Reports it running in around a tenth of a second (0.109 total wall time) using multiple CPU cores:
uvx ty check 0.18s user 0.07s system 228% cpu 0.109 total
Running time uvx mypy . in the same folder (both after first ensuring the underlying tools had been cached) took around 7x longer:
uvx mypy . 0.46s user 0.09s system 74% cpu 0.740 total
This isn't a fair comparison yet as ty still isn't feature complete in comparison to mypy.
llm-fragments-rust
(via)
Inspired by Filippo Valsorda's llm-fragments-go, Francois Garillot created llm-fragments-rust, an LLM fragments plugin that lets you pull documentation for any Rust crate directly into a prompt to LLM.
I really like this example, which uses two fragments to load documentation for two crates at once:
llm -f rust:rand@0.8.5 -f rust:tokio "How do I generate random numbers asynchronously?"
The code uses some neat tricks: it creates a new Rust project in a temporary directory (similar to how llm-fragments-go works), adds the crates and uses cargo doc --no-deps --document-private-items to generate documentation. Then it runs cargo tree --edges features to add dependency information, and cargo metadata --format-version=1 to include additional metadata about the crate.
Stop syncing everything. In which Carl Sverre announces Graft, a fascinating new open source Rust data synchronization engine he's been working on for the past year.
Carl's recent talk at the Vancouver Systems meetup explains Graft in detail, including this slide which helped everything click into place for me:

Graft manages a volume, which is a collection of pages (currently at a fixed 4KB size). A full history of that volume is maintained using snapshots. Clients can read and write from particular snapshot versions for particular pages, and are constantly updated on which of those pages have changed (while not needing to synchronize the actual changed data until they need it).
This is a great fit for B-tree databases like SQLite.
The Graft project includes a SQLite VFS extension that implements multi-leader read-write replication on top of a Graft volume. You can see a demo of that running at 36m15s in the video, or consult the libgraft extension documentation and try it yourself.
The section at the end on What can you build with Graft? has some very useful illustrative examples:
Offline-first apps: Note-taking, task management, or CRUD apps that operate partially offline. Graft takes care of syncing, allowing the application to forget the network even exists. When combined with a conflict handler, Graft can also enable multiplayer on top of arbitrary data.
Cross-platform data: Eliminate vendor lock-in and allow your users to seamlessly access their data across mobile platforms, devices, and the web. Graft is architected to be embedded anywhere
Stateless read replicas: Due to Graft's unique approach to replication, a database replica can be spun up with no local state, retrieve the latest snapshot metadata, and immediately start running queries. No need to download all the data and replay the log.
Replicate anything: Graft is just focused on consistent page replication. It doesn't care about what's inside those pages. So go crazy! Use Graft to sync AI models, Parquet or Lance files, Geospatial tilesets, or just photos of your cats. The sky's the limit with Graft.
Languages that allow for a structurally similar codebase offer a significant boon for anyone making code changes because we can easily port changes between the two codebases. In contrast, languages that require fundamental rethinking of memory management, mutation, data structuring, polymorphism, laziness, etc., might be a better fit for a ground-up rewrite, but we're undertaking this more as a port that maintains the existing behavior and critical optimizations we've built into the language. Idiomatic Go strongly resembles the existing coding patterns of the TypeScript codebase, which makes this porting effort much more tractable.
— Ryan Cavanaugh, on why TypeScript chose to rewrite in Go, not Rust