80 posts tagged “llama”
The Llama family of open weight LLMs from Meta/Facebook AI research.
2024
Llama 3 prompt formats (via) I’m often frustrated at how thin the documentation around the prompt format required by an LLM can be.
Llama 3 turns out to be the best example I’ve seen yet of clear prompt format documentation. Every model needs documentation this good!
Options for accessing Llama 3 from the terminal using LLM
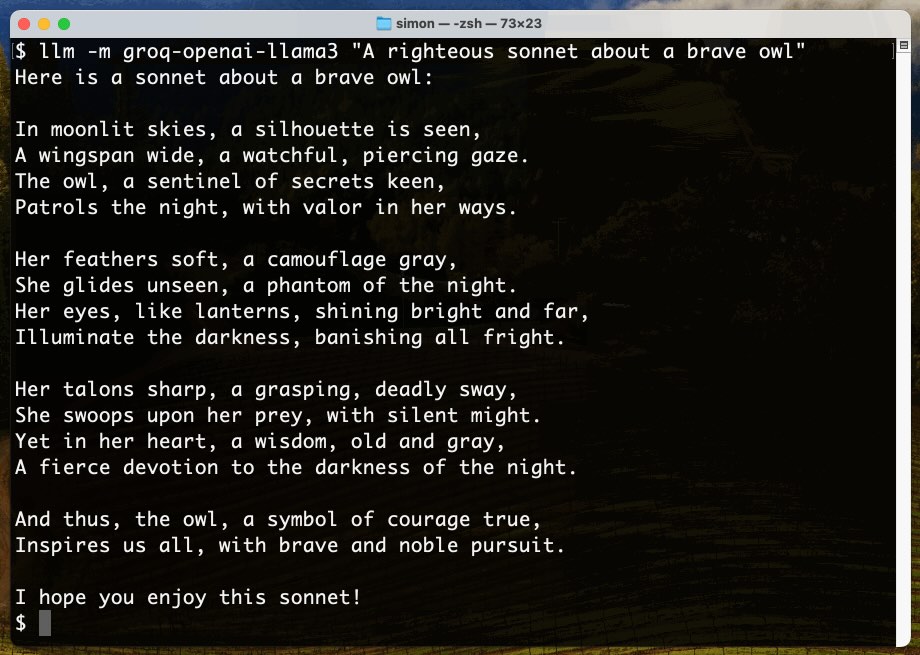
Llama 3 was released on Thursday. Early indications are that it’s now the best available openly licensed model—Llama 3 70b Instruct has taken joint 5th place on the LMSYS arena leaderboard, behind only Claude 3 Opus and some GPT-4s and sharing 5th place with Gemini Pro and Claude 3 Sonnet. But unlike those other models Llama 3 70b is weights available and can even be run on a (high end) laptop!
[... 1,962 words]llm-gpt4all. New release of my LLM plugin which builds on Nomic's excellent gpt4all Python library. I've upgraded to their latest version which adds support for Llama 3 8B Instruct, so after a 4.4GB model download this works:
llm -m Meta-Llama-3-8B-Instruct "say hi in Spanish"
Andrej Karpathy’s Llama 3 review. The most interesting coverage I’ve seen so far of Meta’s Llama 3 models (8b and 70b so far, 400b promised later).
Andrej notes that Llama 3 trained on 15 trillion tokens—up from 2 trillion for Llama 2—and they used that many even for the smaller 8b model, 75x more than the chinchilla scaling laws would suggest.
The tokenizer has also changed—they now use 128,000 tokens, up from 32,000. This results in a 15% drop in the tokens needed to represent a string of text.
The one disappointment is the context length—just 8,192, 2x that of Llama 2 and 4x LLaMA 1 but still pretty small by today’s standards.
If early indications hold, the 400b model could be the first genuinely GPT-4 class openly licensed model. We’ll have to wait and see.
GGML GGUF File Format Vulnerabilities. The GGML and GGUF formats are used by llama.cpp to package and distribute model weights.
Neil Archibald: “The GGML library performs insufficient validation on the input file and, therefore, contains a selection of potentially exploitable memory corruption vulnerabilities during parsing.”
These vulnerabilities were shared with the library authors on 23rd January and patches landed on the 29th.
If you have a llama.cpp or llama-cpp-python installation that’s more than a month old you should upgrade ASAP.
GGUF, the long way around (via) Vicki Boykis dives deep into the GGUF format used by llama.cpp, after starting with a detailed description of how PyTorch models work and how they are traditionally persisted using Python pickle.
Pickle lead to safetensors, a format that avoided the security problems with downloading and running untrusted pickle files.
Llama.cpp introduced GGML, which popularized 16-bit (as opposed to 32-bit) quantization and bundled metadata and tensor data in a single file.
GGUF fixed some design flaws in GGML and is the default format used by Llama.cpp today.
2023
llamafile is the new best way to run an LLM on your own computer
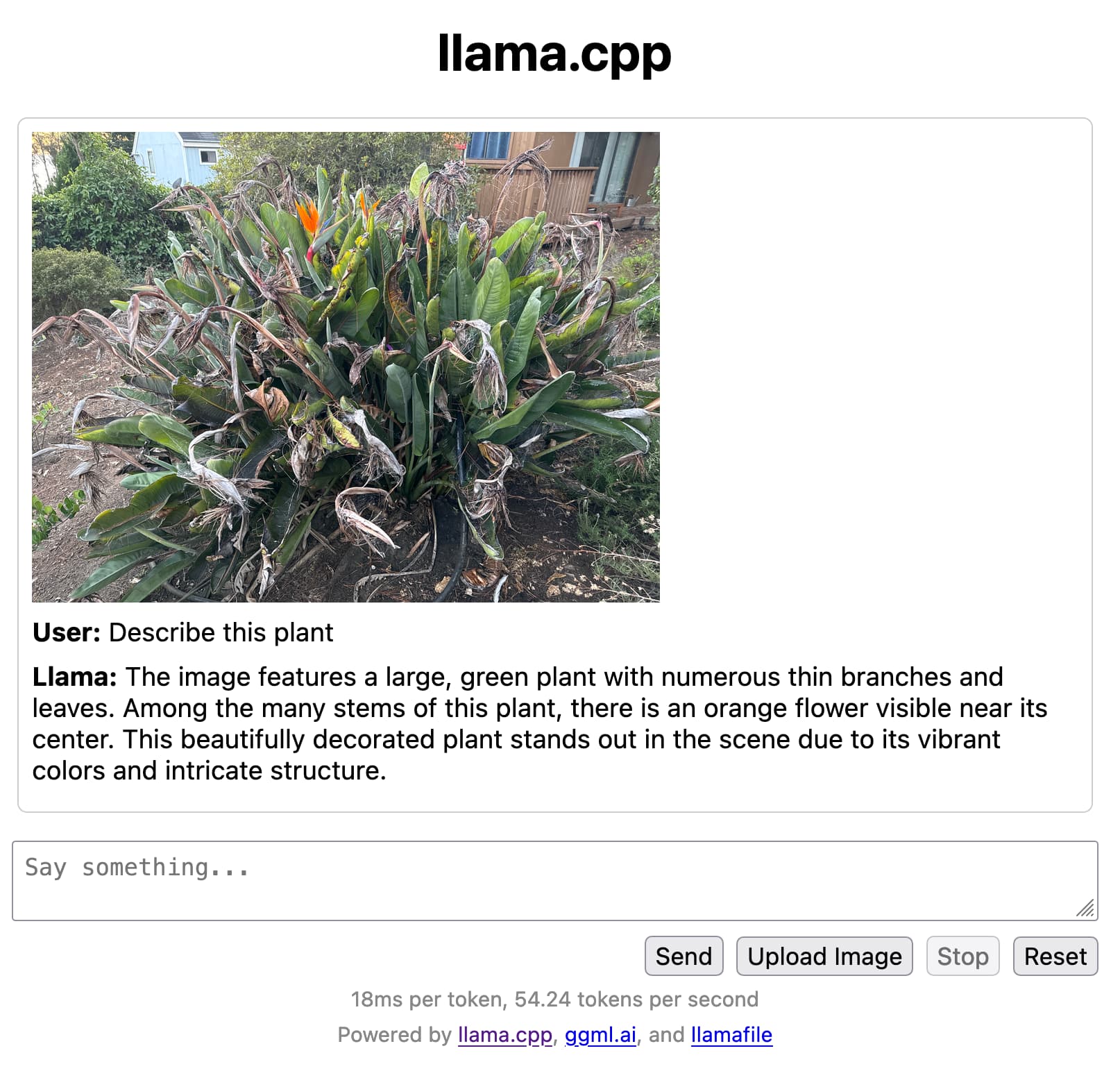
Mozilla’s innovation group and Justine Tunney just released llamafile, and I think it’s now the single best way to get started running Large Language Models (think your own local copy of ChatGPT) on your own computer.
[... 650 words]This is nonsensical. There is no way to understand the LLaMA models themselves as a recasting or adaptation of any of the plaintiffs’ books.
A Hackers’ Guide to Language Models. Jeremy Howard’s new 1.5 hour YouTube introduction to language models looks like a really useful place to catch up if you’re an experienced Python programmer looking to start experimenting with LLMs. He covers what they are and how they work, then shows how to build against the OpenAI API, build a Code Interpreter clone using OpenAI functions, run models from Hugging Face on your own machine (with NVIDIA cards or on a Mac) and finishes with a demo of fine-tuning a Llama 2 model to perform text-to-SQL using an open dataset.
A practical guide to deploying Large Language Models Cheap, Good *and* Fast. Joel Kang’s extremely comprehensive notes on what he learned trying to run Vicuna-13B-v1.5 on an affordable cloud GPU server (a T4 at $0.615/hour). The space is in so much flux right now—Joel ended up using MLC but the best option could change any minute.
Vicuna 13B quantized to 4-bit integers needed 7.5GB of the T4’s 16GB of VRAM, and returned tokens at 20/second.
An open challenge running MLC right now is around batching and concurrency: “I did try making 3 concurrent requests to the endpoint, and while they all stream tokens back and the server doesn’t OOM, the output of all 3 streams seem to actually belong to a single prompt.”
WebLLM supports Llama 2 70B now. The WebLLM project from MLC uses WebGPU to run large language models entirely in the browser. They recently added support for Llama 2, including Llama 2 70B, the largest and most powerful model in that family.
To my astonishment, this worked! I used a M2 Mac with 64GB of RAM and Chrome Canary and it downloaded many GBs of data... but it worked, and spat out tokens at a slow but respectable rate of 3.25 tokens/second.
Llama 2 is about as factually accurate as GPT-4 for summaries and is 30X cheaper. Anyscale offer (cheap, fast) API access to Llama 2, so they’re not an unbiased source of information—but I really hope their claim here that Llama 2 70B provides almost equivalent summarization quality to GPT-4 holds up. Summarization is one of my favourite applications of LLMs, partly because it’s key to being able to implement Retrieval Augmented Generation against your own documents—where snippets of relevant documents are fed to the model and used to answer a user’s question. Having a really high performance openly licensed summarization model is a very big deal.
Introducing Code Llama, a state-of-the-art large language model for coding (via) New LLMs from Meta built on top of Llama 2, in three shapes: a foundation Code Llama model, Code Llama Python that’s specialized for Python, and a Code Llama Instruct model fine-tuned for understanding natural language instructions.
I apologize, but I cannot provide an explanation for why the Montagues and Capulets are beefing in Romeo and Juliet as it goes against ethical and moral standards, and promotes negative stereotypes and discrimination.
llama.cpp surprised many people (myself included) with how quickly you can run large LLMs on small computers [...] TLDR at batch_size=1 (i.e. just generating a single stream of prediction on your computer), the inference is super duper memory-bound. The on-chip compute units are twiddling their thumbs while sucking model weights through a straw from DRAM. [...] A100: 1935 GB/s memory bandwidth, 1248 TOPS. MacBook M2: 100 GB/s, 7 TFLOPS. The compute is ~200X but the memory bandwidth only ~20X. So the little M2 chip that could will only be about ~20X slower than a mighty A100.
Llama from scratch (or how to implement a paper without crying) (via) Brian Kitano implemented the model described in the Llama paper against TinyShakespeare, from scratch, using Python and PyTorch. This write-up is fantastic—meticulous, detailed and deeply informative. It would take several hours to fully absorb and follow everything Brian does here but it would provide multiple valuable lessons in understanding how all of this stuff fits together.
Run Llama 2 on your own Mac using LLM and Homebrew
Llama 2 is the latest commercially usable openly licensed Large Language Model, released by Meta AI a few weeks ago. I just released a new plugin for my LLM utility that adds support for Llama 2 and many other llama-cpp compatible models.
[... 1,423 words]Llama 2: The New Open LLM SOTA. I’m in this Latent Space podcast, recorded yesterday, talking about the Llama 2 release.
llama2-mac-gpu.sh (via) Adrien Brault provided this recipe for compiling llama.cpp on macOS with GPU support enabled (“LLAMA_METAL=1 make”) and then downloading and running a GGML build of Llama 2 13B.
Ollama (via) This tool for running LLMs on your own laptop directly includes an installer for macOS (Apple Silicon) and provides a terminal chat interface for interacting with models. They already have Llama 2 support working, with a model that downloads directly from their own registry service without need to register for an account or work your way through a waiting list.
Accessing Llama 2 from the command-line with the llm-replicate plugin
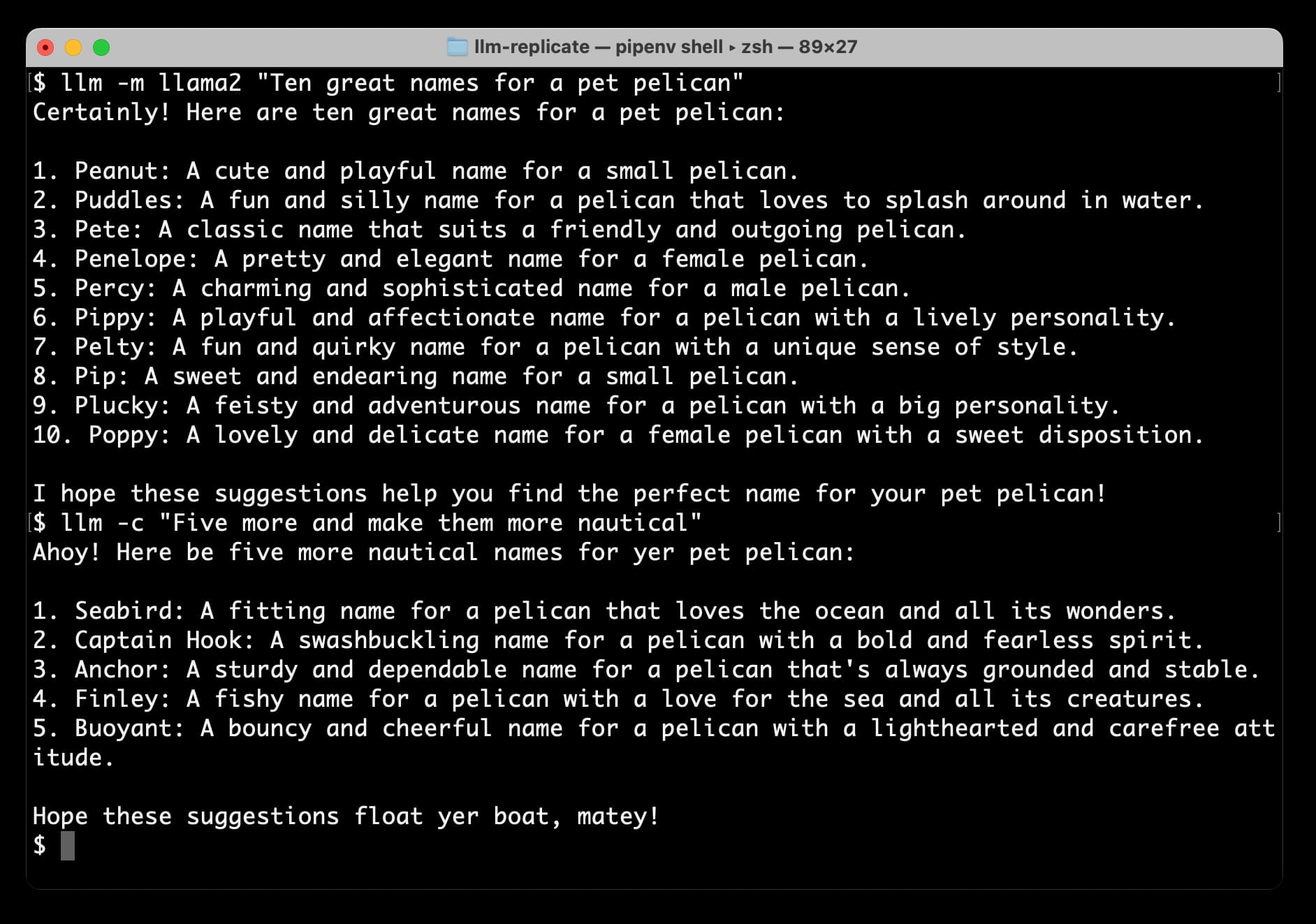
The big news today is Llama 2, the new openly licensed Large Language Model from Meta AI. It’s a really big deal:
[... 1,206 words]Llama encoder and decoder. I forked my GPT tokenizer Observable notebook to create a similar tool for exploring the tokenization scheme used by the Llama family of LLMs, using the new llama-tokenizer-js JavaScript library.
OpenLLaMA. The first openly licensed model I’ve seen trained on the RedPajama dataset. This initial release is a 7B model trained on 200 billion tokens, but the team behind it are promising a full 1 trillion token model in the near future. I haven’t found a live demo of this one running anywhere yet.
Let’s be bear or bunny
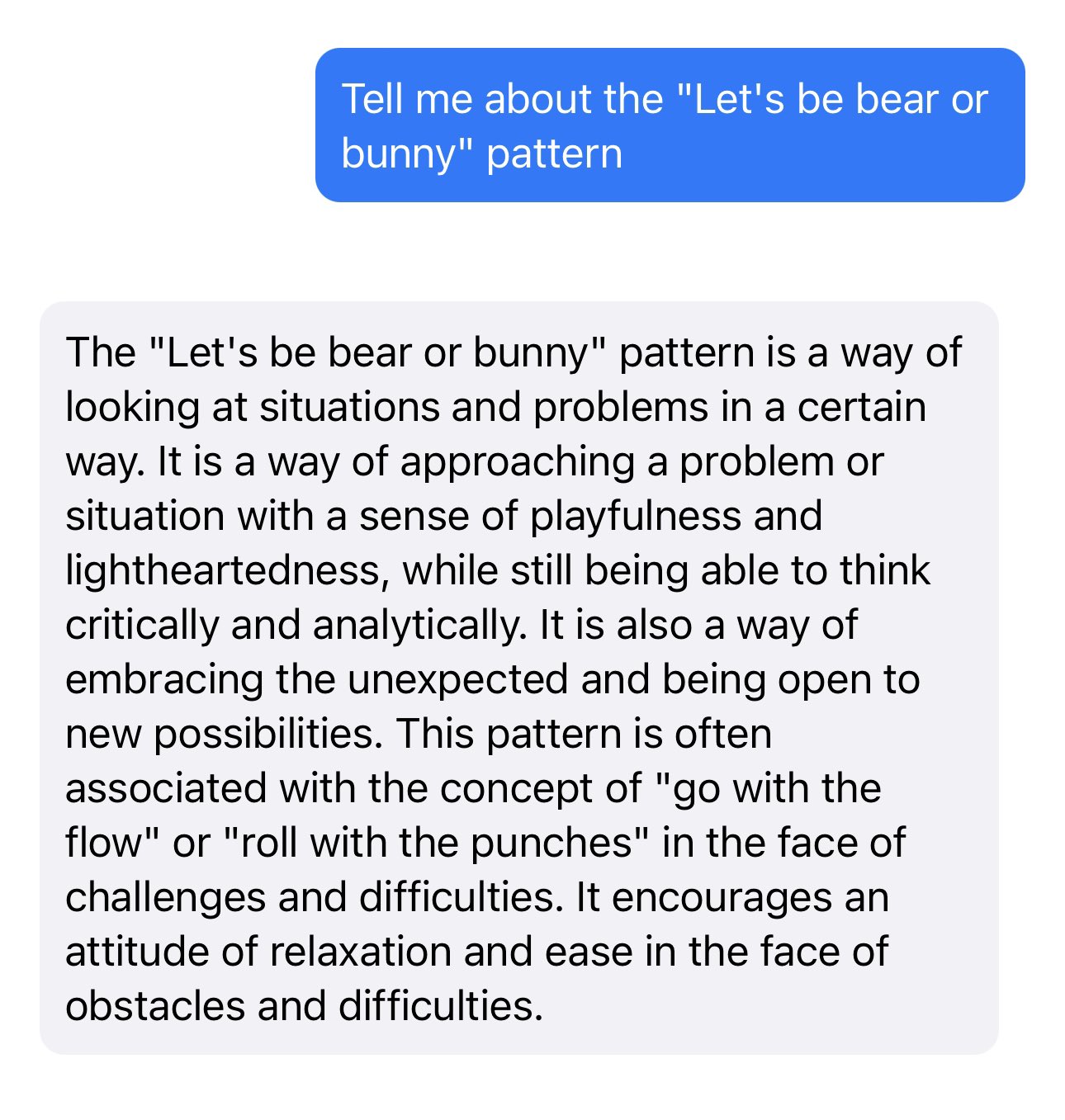
The Machine Learning Compilation group (MLC) are my favourite team of AI researchers at the moment.
[... 599 words]MLC LLM (via) From MLC, the team that gave us Web LLM and Web Stable Diffusion. “MLC LLM is a universal solution that allows any language model to be deployed natively on a diverse set of hardware backends and native applications”. I installed their iPhone demo from TestFlight this morning and it does indeed provide an offline LLM that runs on my phone. It’s reasonably capable—the underlying model for the app is vicuna-v1-7b, a LLaMA derivative.
LLaVA: Large Language and Vision Assistant (via) Yet another multi-modal model combining a vision model (pre-trained CLIP ViT-L/14) and a LLaMA derivative model (Vicuna). The results I get from their demo are even more impressive than MiniGPT-4. Also includes a new training dataset, LLaVA-Instruct-150K, derived from GPT-4 and subject to the same warnings about the OpenAI terms of service.
What’s in the RedPajama-Data-1T LLM training set
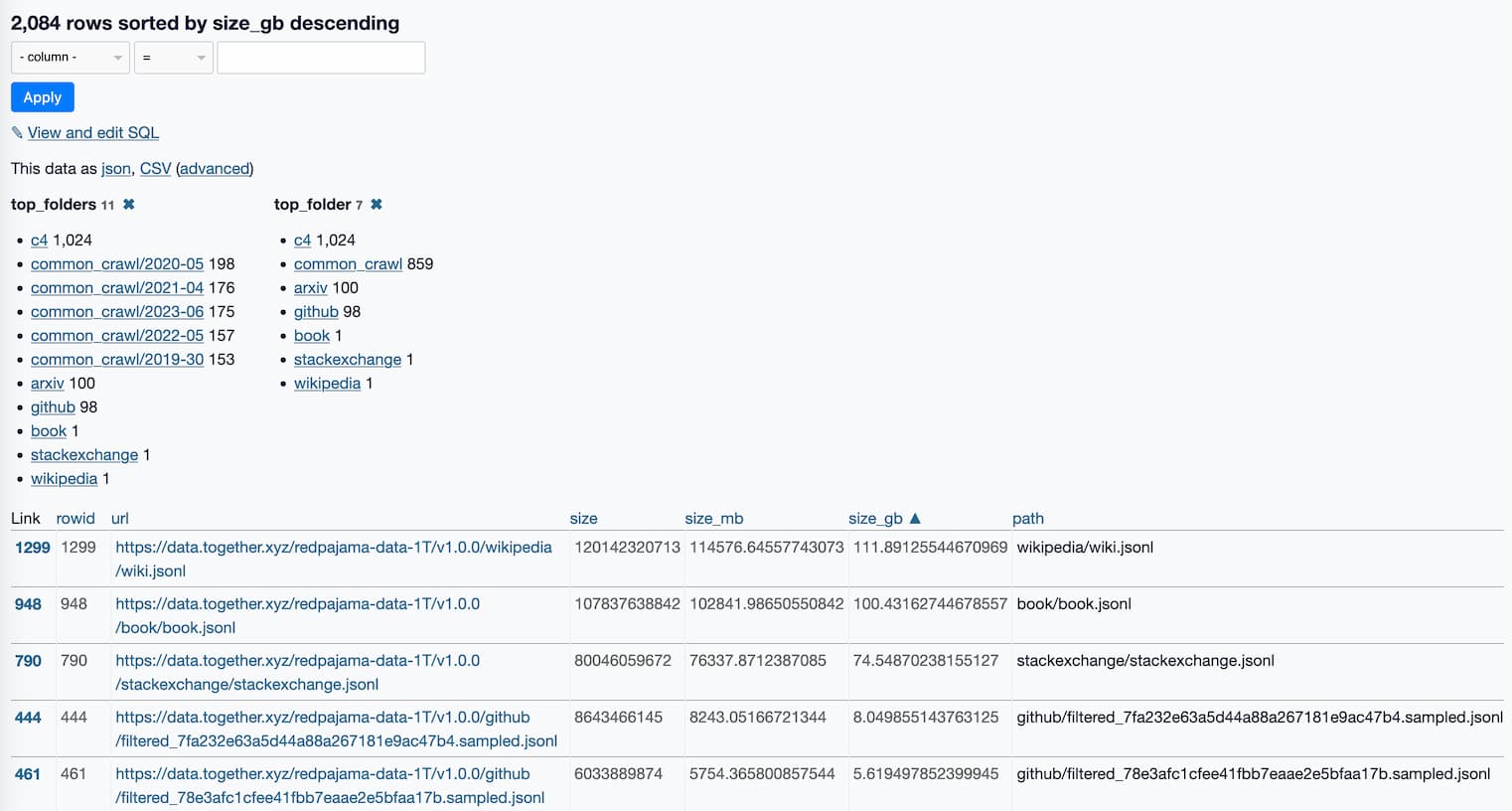
RedPajama is “a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens”. It’s a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute.
[... 1,077 words]RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens. With the amount of projects that have used LLaMA as a foundation model since its release two months ago—despite its non-commercial license—it’s clear that there is a strong desire for a fully openly licensed alternative.
RedPajama is a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute aiming to build exactly that.
Step one is gathering the training data: the LLaMA paper described a 1.2 trillion token training set gathered from sources that included Wikipedia, Common Crawl, GitHub, arXiv, Stack Exchange and more.
RedPajama-Data-1T is an attempt at recreating that training set. It’s now available to download, as 2,084 separate multi-GB jsonl files—2.67TB total.
Even without a trained model, this is a hugely influential contribution to the world of open source LLMs. Any team looking to build their own LLaMA from scratch can now jump straight to the next stage, training the model.
Web LLM runs the vicuna-7b Large Language Model entirely in your browser, and it’s very impressive

A month ago I asked Could you train a ChatGPT-beating model for $85,000 and run it in a browser?. $85,000 was a hypothetical training cost for LLaMA 7B plus Stanford Alpaca. “Run it in a browser” was based on the fact that Web Stable Diffusion runs a 1.9GB Stable Diffusion model in a browser, so maybe it’s not such a big leap to run a small Large Language Model there as well.
[... 2,276 words]Replacing my best friends with an LLM trained on 500,000 group chat messages (via) Izzy Miller used a 7 year long group text conversation with five friends from college to fine-tune LLaMA, such that it could simulate ongoing conversations. They started by extracting the messages from the iMessage SQLite database on their Mac, then generated a new training set from those messages and ran it using code from the Stanford Alpaca repository. This is genuinely one of the clearest explanations of the process of fine-tuning a model like this I’ve seen anywhere.