80 posts tagged “llama”
The Llama family of open weight LLMs from Meta/Facebook AI research.
2023
Thoughts on AI safety in this era of increasingly powerful open source LLMs
This morning, VentureBeat published a story by Sharon Goldman: With a wave of new LLMs, open source AI is having a moment — and a red-hot debate. It covers the explosion in activity around openly available Large Language Models such as LLaMA—a trend I’ve been tracking in my own series LLMs on personal devices—and talks about their implications with respect to AI safety.
[... 782 words]The Changelog podcast: LLMs break the internet

I’m the guest on the latest episode of The Changelog podcast: LLMs break the internet. It’s a follow-up to the episode we recorded six months ago about Stable Diffusion.
[... 454 words]Downloading and converting the original models (Cerebras-GPT) (via) Georgi Gerganov added support for the Apache 2 licensed Cerebras-GPT language model to his ggml C++ inference library, as used by llama.cpp.
gpt4all. Similar to Alpaca, here’s a project which takes the LLaMA base model and fine-tunes it on instruction examples generated by GPT-3—in this case, it’s 800,000 examples generated using the ChatGPT GPT 3.5 turbo model (Alpaca used 52,000 generated by regular GPT-3). This is currently the easiest way to get a LLaMA derived chatbot running on your own computer: the repo includes compiled binaries for running on M1/M2, Intel Mac, Windows and Linux and provides a link to download the 3.9GB 4-bit quantized model.
Announcing Open Flamingo (via) New from LAION: “OpenFlamingo is a framework that enables training and evaluation of large multimodal models (LMMs)”. Multimodal here means it can answer questions about images—their interactive demo includes tools for image captioning, animal recognition, counting objects and visual question answering. Theye’ve released the OpenFlamingo-9B model built on top of LLaMA 7B and CLIP ViT/L-14—the model checkpoint is a 5.24 GB download from Hugging Face, and is available under a non-commercial research license.
LLaMA voice chat, with Whisper and Siri TTS. llama.cpp author Georgi Gerganov has stitched together the LLaMA language model, the Whisper voice to text model (with his whisper.cpp library) and the macOS “say” command to create an entirely offline AI agent that he can talk to with his voice and that can speak replies straight back to him.
Hello Dolly: Democratizing the magic of ChatGPT with open models. A team at DataBricks applied the same fine-tuning data used by Stanford Alpaca against LLaMA to a much older model—EleutherAI’s GPT-J 6B, first released in May 2021. As with Alpaca, they found that instruction tuning took the raw model—which was extremely difficult to interact with—and turned it into something that felt a lot more like ChatGPT. It’s a shame they reused the license-encumbered 52,000 training samples from Alpaca, but I doubt it will be long before someone recreates a freely licensed alternative to that training set.
Was on a plane yesterday, studying some physics; got confused about something and I was able to solve my problem by just asking alpaca-13B—running locally on my machine—for an explanation. Felt straight-up spooky.
Fine-tune LLaMA to speak like Homer Simpson. Replicate spent 90 minutes fine-tuning LLaMA on 60,000 lines of dialog from the first 12 seasons of the Simpsons, and now it can do a good job of producing invented dialog from any of the characters from the series. This is a really interesting result: I’ve been skeptical about how much value can be had from fine-tuning large models on just a tiny amount of new data, assuming that the new data would be statistically irrelevant compared to the existing model. Clearly my mental model around this was incorrect.
Could you train a ChatGPT-beating model for $85,000 and run it in a browser?
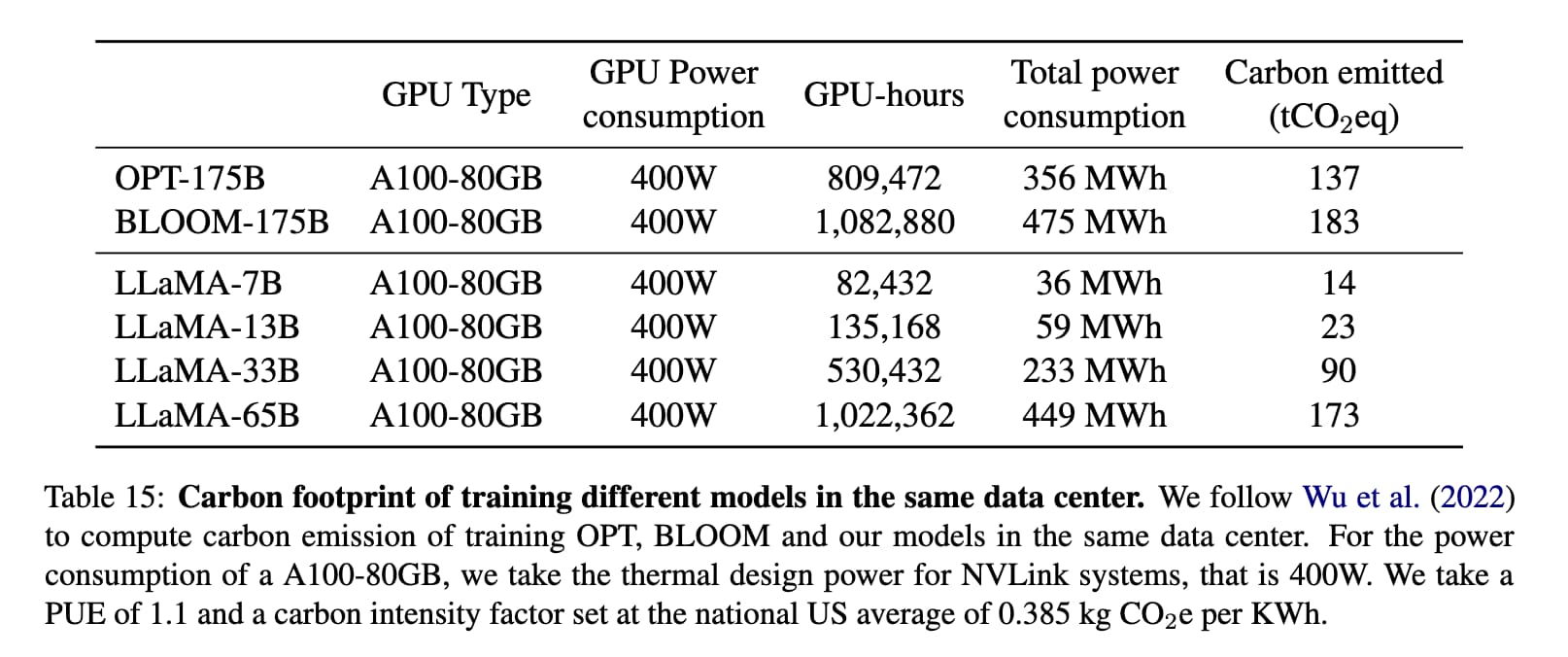
I think it’s now possible to train a large language model with similar functionality to GPT-3 for $85,000. And I think we might soon be able to run the resulting model entirely in the browser, and give it capabilities that leapfrog it ahead of ChatGPT.
[... 1,751 words]Train and run Stanford Alpaca on your own machine. The team at Replicate managed to train their own copy of Stanford’s Alpaca—a fine-tuned version of LLaMA that can follow instructions like ChatGPT. Here they provide step-by-step instructions for recreating Alpaca yourself—running the training needs one or more A100s for a few hours, which you can rent through various cloud providers.
bloomz.cpp (via) Nouamane Tazi Adapted the llama.cpp project to run against the BLOOM family of language models, which were released in July 2022 and trained in France on 45 natural languages and 12 programming languages using the Jean Zay Public Supercomputer, provided by the French government and powered using mostly nuclear energy.
It’s under the RAIL license which allows (limited) commercial use, unlike LLaMA.
Nouamane reports getting 16 tokens/second from BLOOMZ-7B1 running on an M1 Pro laptop.
Int-4 LLaMa is not enough—Int-3 and beyond (via) The Nolano team are experimenting with reducing the size of the LLaMA models even further than the 4bit quantization popularized by llama.cpp.
Stanford Alpaca, and the acceleration of on-device large language model development
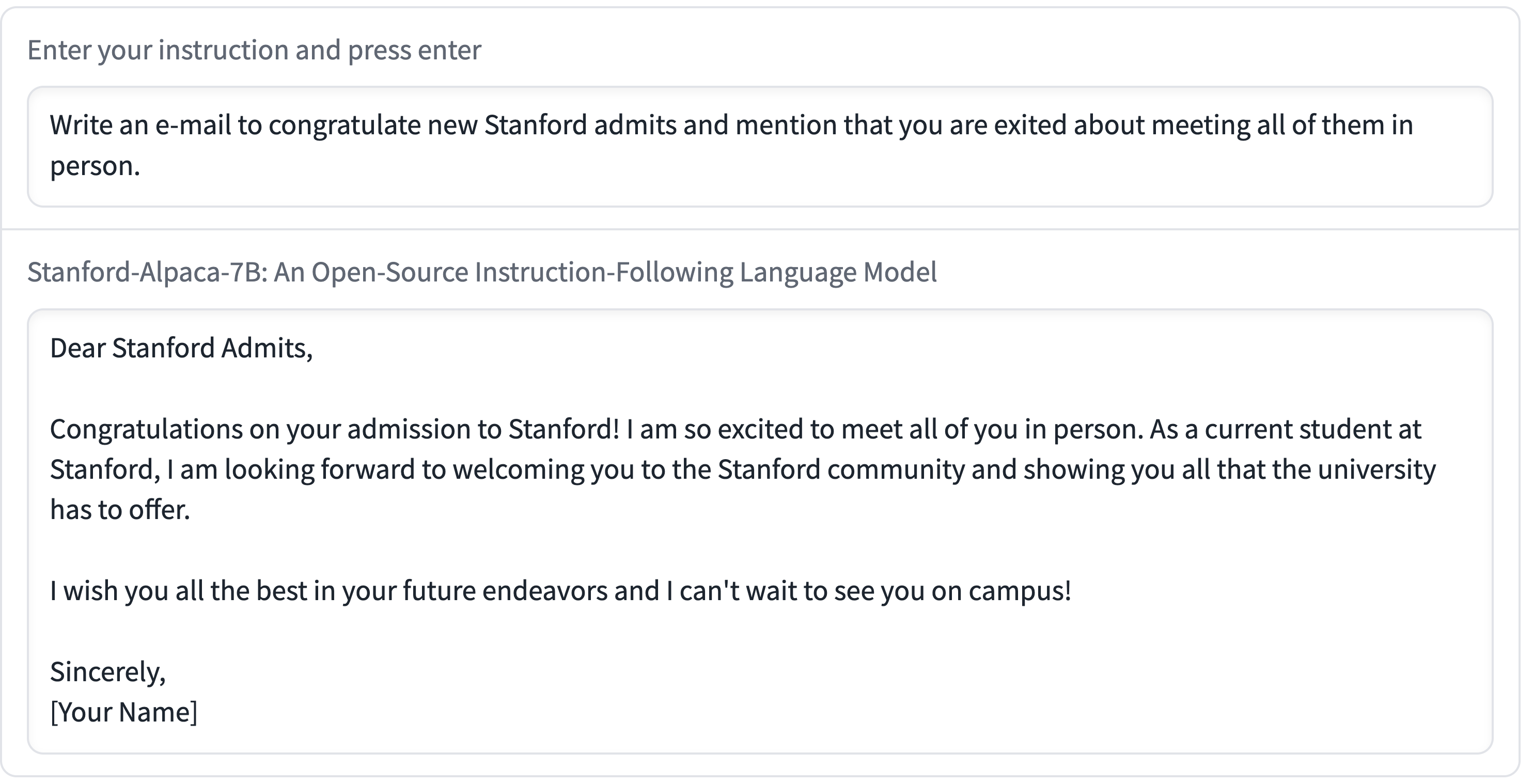
On Saturday 11th March I wrote about how Large language models are having their Stable Diffusion moment. Today is Monday. Let’s look at what’s happened in the past three days.
[... 2,055 words]We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. Alpaca behaves similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).
I've successfully run LLaMA 7B model on my 4GB RAM Raspberry Pi 4. It's super slow about 10sec/token. But it looks we can run powerful cognitive pipelines on a cheap hardware.
Large language models are having their Stable Diffusion moment
The open release of the Stable Diffusion image generation model back in August 2022 was a key moment. I wrote how Stable Diffusion is a really big deal at the time.
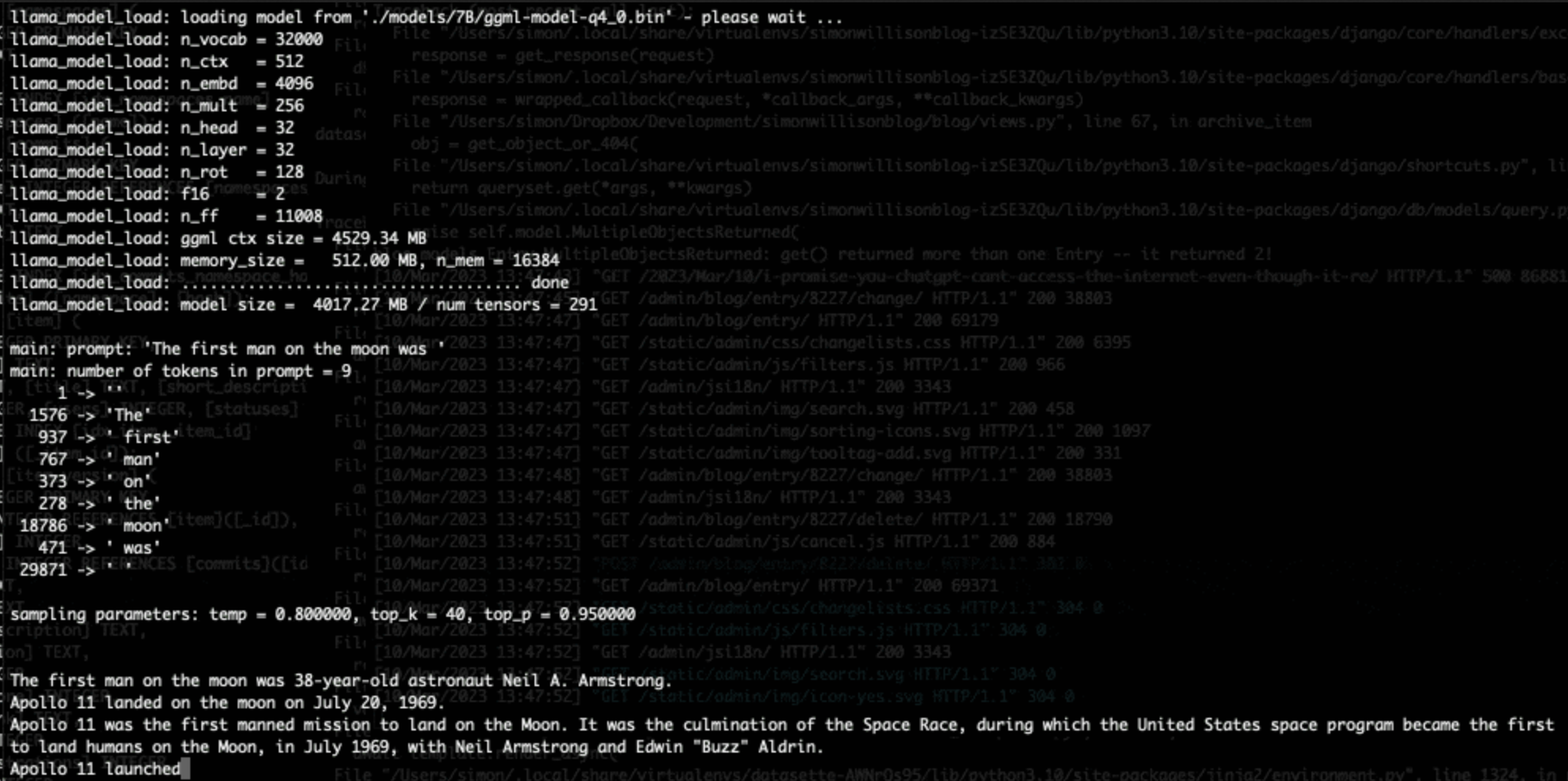
[... 1,815 words]Running LLaMA 7B on a 64GB M2 MacBook Pro with llama.cpp. I got Facebook’s LLaMA 7B to run on my MacBook Pro using llama.cpp (a “port of Facebook’s LLaMA model in C/C++”) by Georgi Gerganov. It works! I’ve been hoping to run a GPT-3 class language model on my own hardware for ages, and now it’s possible to do exactly that. The model itself ends up being just 4GB after applying Georgi’s script to “quantize the model to 4-bits”.
Introducing LLaMA: A foundational, 65-billion-parameter large language model (via) From the paper: “For instance, LLaMA-13B outperforms GPT-3 on most benchmarks, despite being 10× smaller. We believe that this model will help democratize the access and study of LLMs, since it can be run on a single GPU.”