Posts tagged projects, datasette
Filters: projects × datasette × Sorted by date
Introducing Datasette for Newsrooms. We're introducing a new product suite today called Datasette for Newsrooms - a bundled collection of Datasette Cloud features built specifically for investigative journalists and data teams. We're describing it as an all-in-one data store, search engine, and collaboration platform designed to make working with data in a newsroom easier, faster, and more transparent.
If your newsroom could benefit from a managed version of Datasette we would love to hear from you. We're offering it to nonprofit newsrooms for free for the first year (they can pay us in feedback), and we have a two month trial for everyone else.
Get in touch at hello@datasette.cloud if you'd like to try it out.
One crucial detail: we will help you get started - we'll load data into your instance for you (you get some free data engineering!) and walk you through how to use it, and we will eagerly consume any feedback you have for us and prioritize shipping anything that helps you use the tool. Our unofficial goal: we want someone to win a Pulitzer for investigative reporting where our tool played a tiny part in their reporting process.
Here's an animated GIF demo (taken from our new Newsrooms landing page) of my favorite recent feature: the ability to extract structured data into a table starting with an unstructured PDF, using the latest version of the datasette-extract plugin.

files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
Datasette 1.0a17. New Datasette alpha, with a bunch of small changes and bug fixes accumulated over the past few months. Some (minor) highlights:
- The register_magic_parameters(datasette) plugin hook can now register async functions. (#2441)
- Breadcrumbs on database and table pages now include a consistent self-link for resetting query string parameters. (#2454)
- New internal methods
datasette.set_actor_cookie()anddatasette.delete_actor_cookie(), described here. (#1690)/-/permissionspage now shows a list of all permissions registered by plugins. (#1943)- If a table has a single unique text column Datasette now detects that as the foreign key label for that table. (#2458)
- The
/-/permissionspage now includes options for filtering or exclude permission checks recorded against the current user. (#2460)
I was incentivized to push this release by an issue I ran into in my new datasette-load plugin, which resulted in this fix:
- Fixed a bug where replacing a database with a new one with the same name did not pick up the new database correctly. (#2465)
datasette-enrichments-llm. Today's new alpha release is datasette-enrichments-llm, a plugin for Datasette 1.0a+ that provides an enrichment that lets you run prompts against data from one or more column and store the result in another column.
So far it's a light re-implementation of the existing datasette-enrichments-gpt plugin, now using the new llm.get_async_models() method to allow users to select any async-enabled model that has been registered by a plugin - so currently any of the models from OpenAI, Anthropic, Gemini or Mistral via their respective plugins.
Still plenty to do on this one. Next step is to integrate it with datasette-llm-usage and use it to drive a design-complete stable version of that.
datasette-queries. I released the first alpha of a new plugin to replace the crusty old datasette-saved-queries. This one adds a new UI element to the top of the query results page with an expandable form for saving the query as a new canned query:
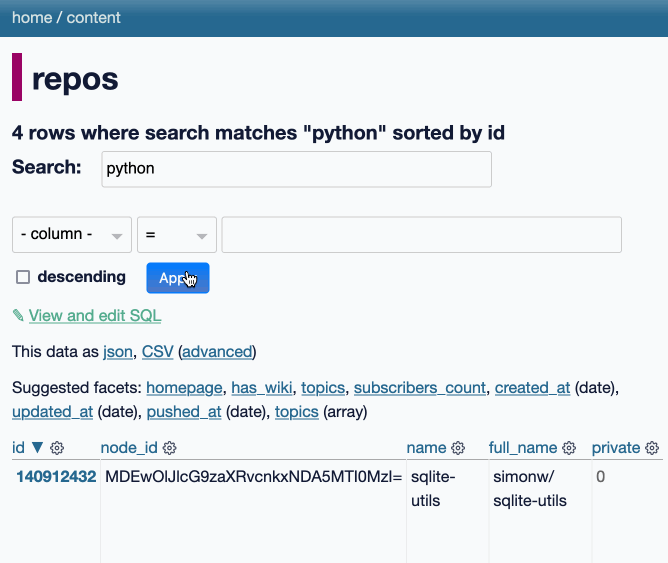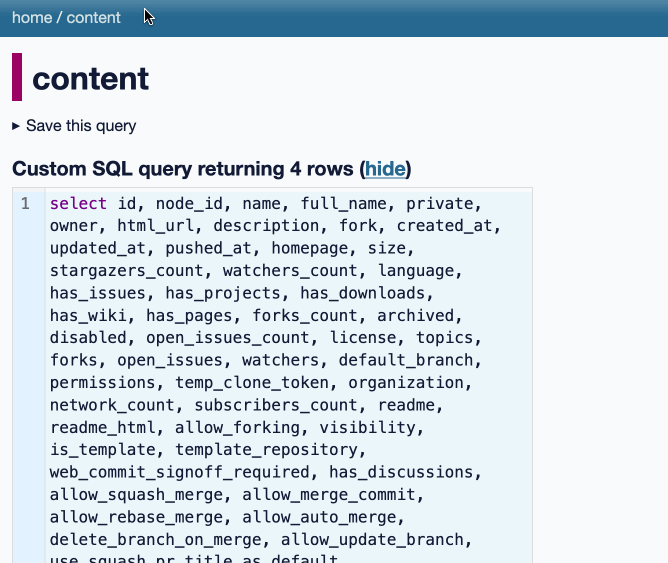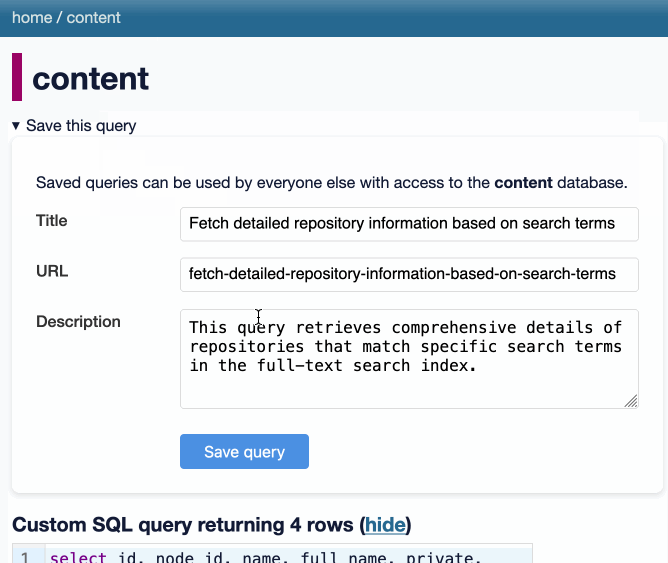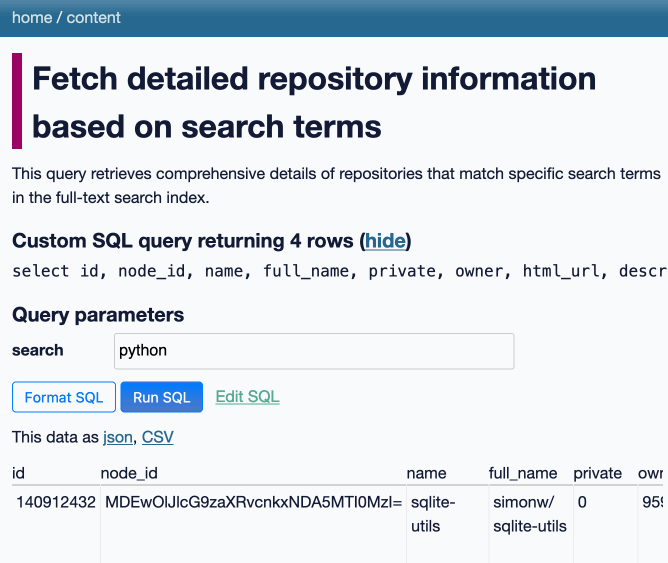
It's my first plugin to depend on LLM and datasette-llm-usage - it uses GPT-4o mini to power an optional "Suggest title and description" button, labeled with the becoming-standard ✨ sparkles emoji to indicate an LLM-powered feature.
I intend to expand this to work across multiple models as I continue to iterate on llm-datasette-usage to better support those kinds of patterns.
For the moment though each suggested title and description call costs about 250 input tokens and 50 output tokens, which against GPT-4o mini adds up to 0.0067 cents.
datasette-llm-usage. I released the first alpha of a Datasette plugin to help track LLM usage by other plugins, with the goal of supporting token allowances - both for things like free public apps that stop working after a daily allowance, plus free previews of AI features for paid-account-based projects such as Datasette Cloud.
It's using the usage features I added in LLM 0.19.
The alpha doesn't do much yet - it will start getting interesting once I upgrade other plugins to depend on it.
Design notes so far in issue #1.
Weeknotes: asynchronous LLMs, synchronous embeddings, and I kind of started a podcast
These past few weeks I’ve been bringing Datasette and LLM together and distracting myself with a new sort-of-podcast crossed with a live streaming experiment.
[... 896 words]Visualizing local election results with Datasette, Observable and MapLibre GL
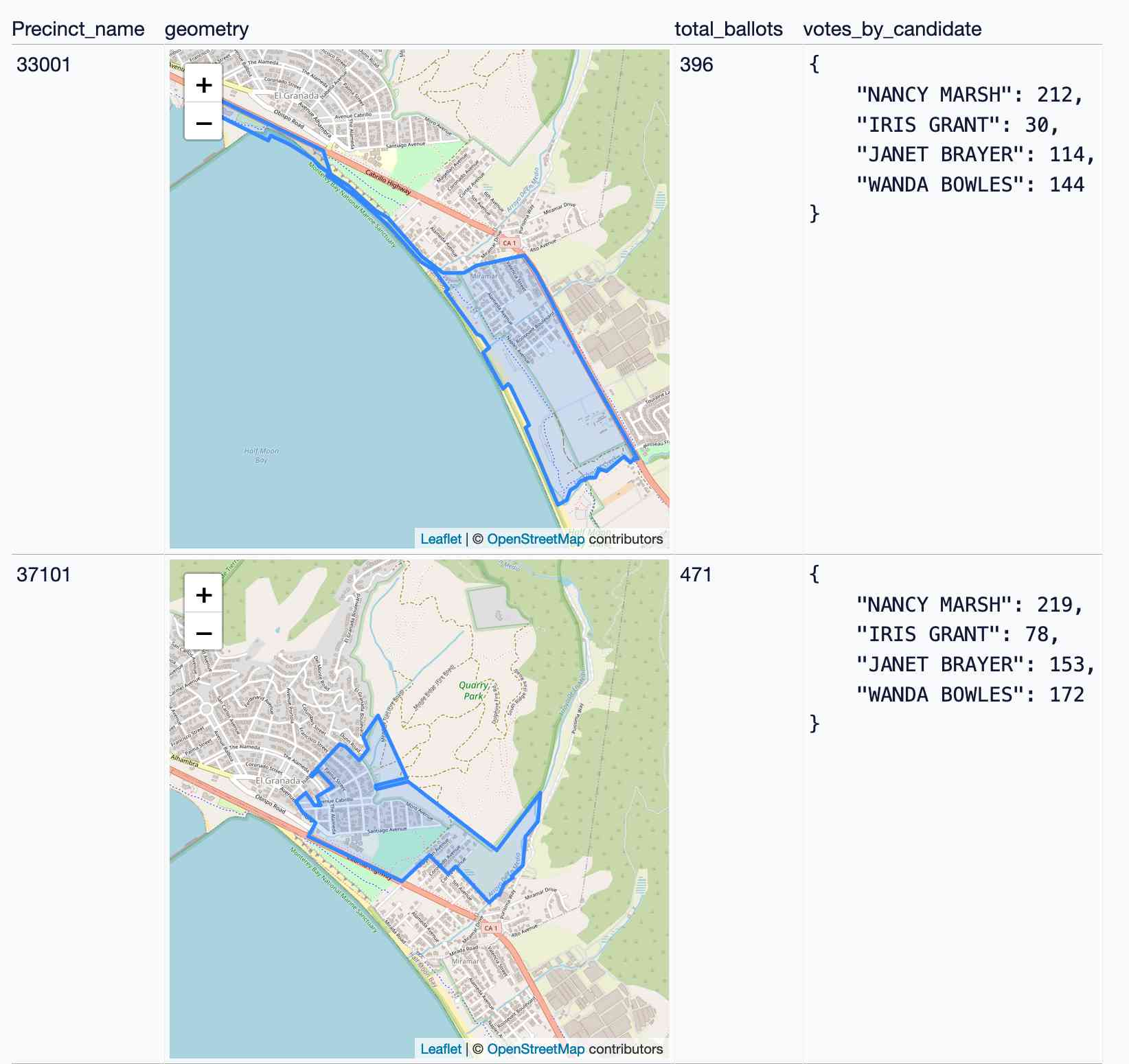
Alex Garcia and myself hosted the first Datasette Open Office Hours on Friday—a live-streamed video session where we hacked on a project together and took questions and tips from community members on Discord.
[... 3,390 words]Datasette 0.65. Python 3.13 was released today, which broke compatibility with the Datasette 0.x series due to an issue with an underlying dependency. I've fixed that problem by vendoring and fixing the dependency and the new 0.65 release works on Python 3.13 (but drops support for Python 3.8, which is EOL this month). Datasette 1.0a16 added support for Python 3.13 last month.
django-plugin-datasette. I did some more work on my DJP plugin mechanism for Django at the DjangoCon US sprints today. I added a new plugin hook, asgi_wrapper(), released in DJP 0.3 and inspired by the similar hook in Datasette.
The hook only works for Django apps that are served using ASGI. It allows plugins to add their own wrapping ASGI middleware around the Django app itself, which means they can do things like attach entirely separate ASGI-compatible applications outside of the regular Django request/response cycle.
Datasette is one of those ASGI-compatible applications!
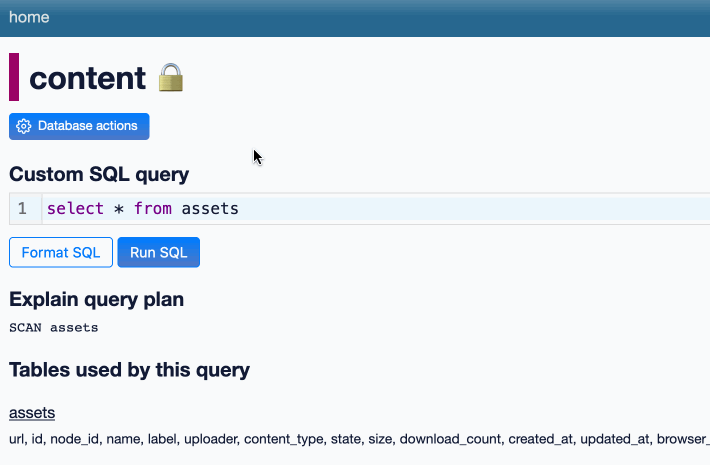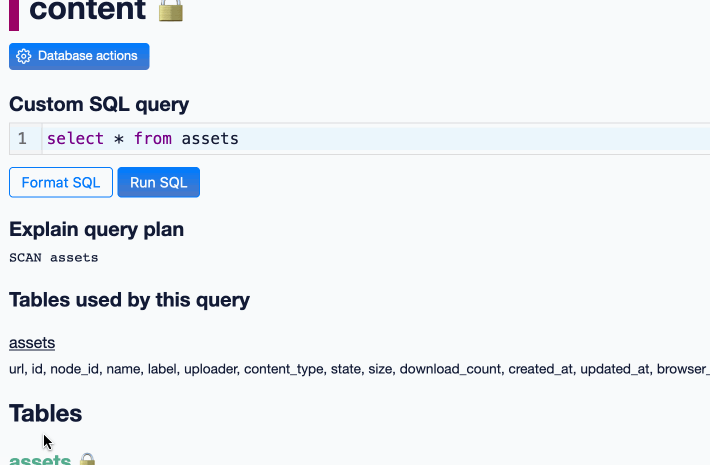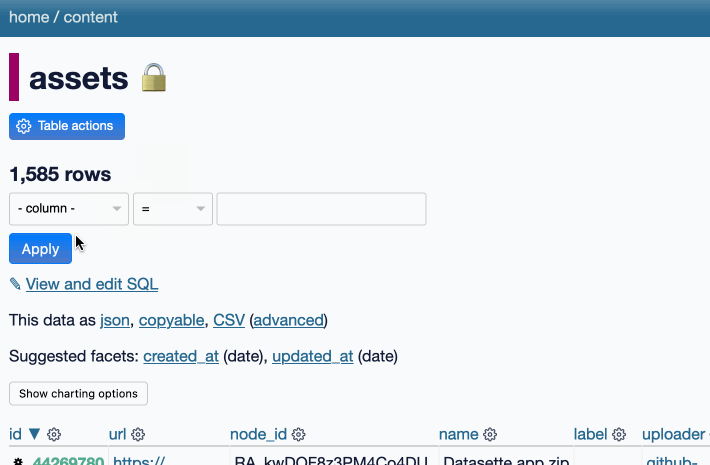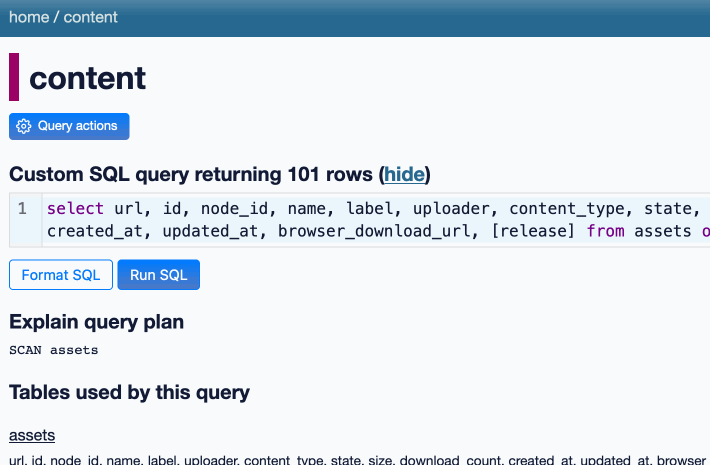
django-plugin-datasette uses that new hook to configure a new URL, /-/datasette/, which serves a full Datasette instance that scans through Django’s settings.DATABASES dictionary and serves an explore interface on top of any SQLite databases it finds there.
It doesn’t support authentication yet, so this will expose your entire database contents - probably best used as a local debugging tool only.
I did borrow some code from the datasette-mask-columns plugin to ensure that the password column in the auth_user column is reliably redacted. That column contains a heavily salted hashed password so exposing it isn’t necessarily a disaster, but I like to default to keeping hashes safe.
Datasette 1.0a16. This latest release focuses mainly on performance, as discussed here in Optimizing Datasette a couple of weeks ago.
It also includes some minor CSS changes that could affect plugins, and hence need to be included before the final 1.0 release. Those are outlined in detail in issues #2415 and #2420.
Calling LLMs from client-side JavaScript, converting PDFs to HTML + weeknotes
I’ve been having a bunch of fun taking advantage of CORS-enabled LLM APIs to build client-side JavaScript applications that access LLMs directly. I also span up a new Datasette plugin for advanced permission management.
[... 2,050 words]datasette-checkbox. I built this fun little Datasette plugin today, inspired by a conversation I had in Datasette Office Hours.
If a user has the update-row permission and the table they are viewing has any integer columns with names that start with is_ or should_ or has_, the plugin adds interactive checkboxes to that table which can be toggled to update the underlying rows.
This makes it easy to quickly spin up an interface that allows users to review and update boolean flags in a table.

I have ambitions for a much more advanced version of this, where users can do things like add or remove tags from rows directly in that table interface - but for the moment this is a neat starting point, and it only took an hour to build (thanks to help from Claude to build an initial prototype, chat transcript here).
Datasette 1.0a15. Mainly bug fixes, but a couple of minor new features:
- Datasette now defaults to hiding SQLite "shadow" tables, as seen in extensions such as SQLite FTS and sqlite-vec. Virtual tables that it makes sense to display, such as FTS core tables, are no longer hidden. Thanks, Alex Garcia. (#2296)
- The Datasette homepage is now duplicated at
/-/, using the defaultindex.htmltemplate. This ensures that the information on that page is still accessible even if the Datasette homepage has been customized using a customindex.htmltemplate, for example on sites like datasette.io. (#2393)
Datasette also now serves more user-friendly CSRF pages, an improvement which required me to ship asgi-csrf 0.10.
Datasette 1.0a14: The annotated release notes

Released today: Datasette 1.0a14. This alpha includes significant contributions from Alex Garcia, including some backwards-incompatible changes in the run-up to the 1.0 release.
[... 1,424 words]datasette-python.
I just released a small new plugin for Datasette to assist with debugging. It adds a python subcommand which runs a Python process in the same virtual environment as Datasette itself.
I built it initially to help debug some issues in Datasette installed via Homebrew. The Homebrew installation has its own virtual environment, and sometimes it can be useful to run commands like pip list in the same environment as Datasette itself.
Now you can do this:
brew install datasette
datasette install datasette-python
datasette python -m pip list
I built a similar plugin for LLM last year, called llm-python - it's proved useful enough that I duplicated the design for Datasette.
Datasette 0.64.8. A very small Datasette release, fixing a minor potential security issue where the name of missing databases or tables was reflected on the 404 page in a way that could allow an attacker to present arbitrary text to a user who followed a link. Not an XSS attack (no code could be executed) but still a potential vector for confusing messages.
Building search-based RAG using Claude, Datasette and Val Town
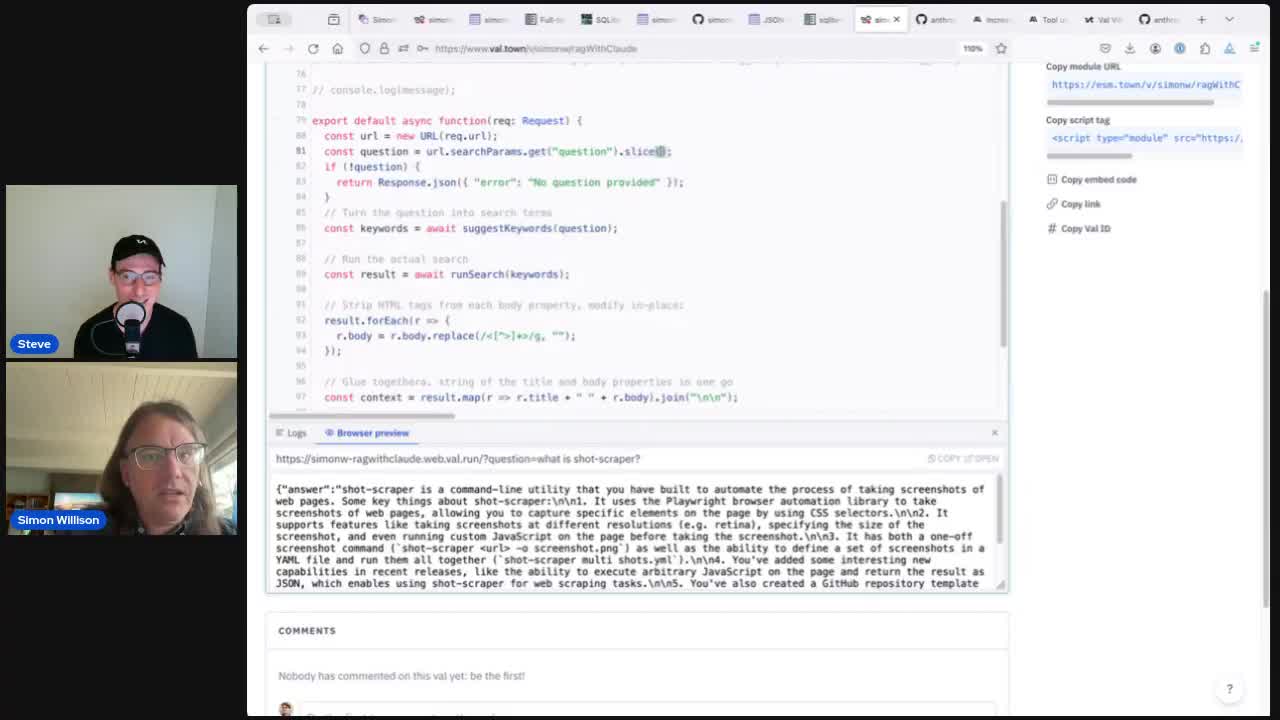
Retrieval Augmented Generation (RAG) is a technique for adding extra “knowledge” to systems built on LLMs, allowing them to answer questions against custom information not included in their training data. A common way to implement this is to take a question from a user, translate that into a set of search queries, run those against a search engine and then feed the results back into the LLM to generate an answer.
[... 3,372 words]Weeknotes: Datasette Studio and a whole lot of blogging
I’m still spinning back up after my trip back to the UK, so actual time spent building things has been less than I’d like. I presented an hour long workshop on command-line LLM usage, wrote five full blog entries (since my last weeknotes) and I’ve also been leaning more into short-form link blogging—a lot more prominent on this site now since my homepage redesign last week.
[... 736 words]Language models on the command-line
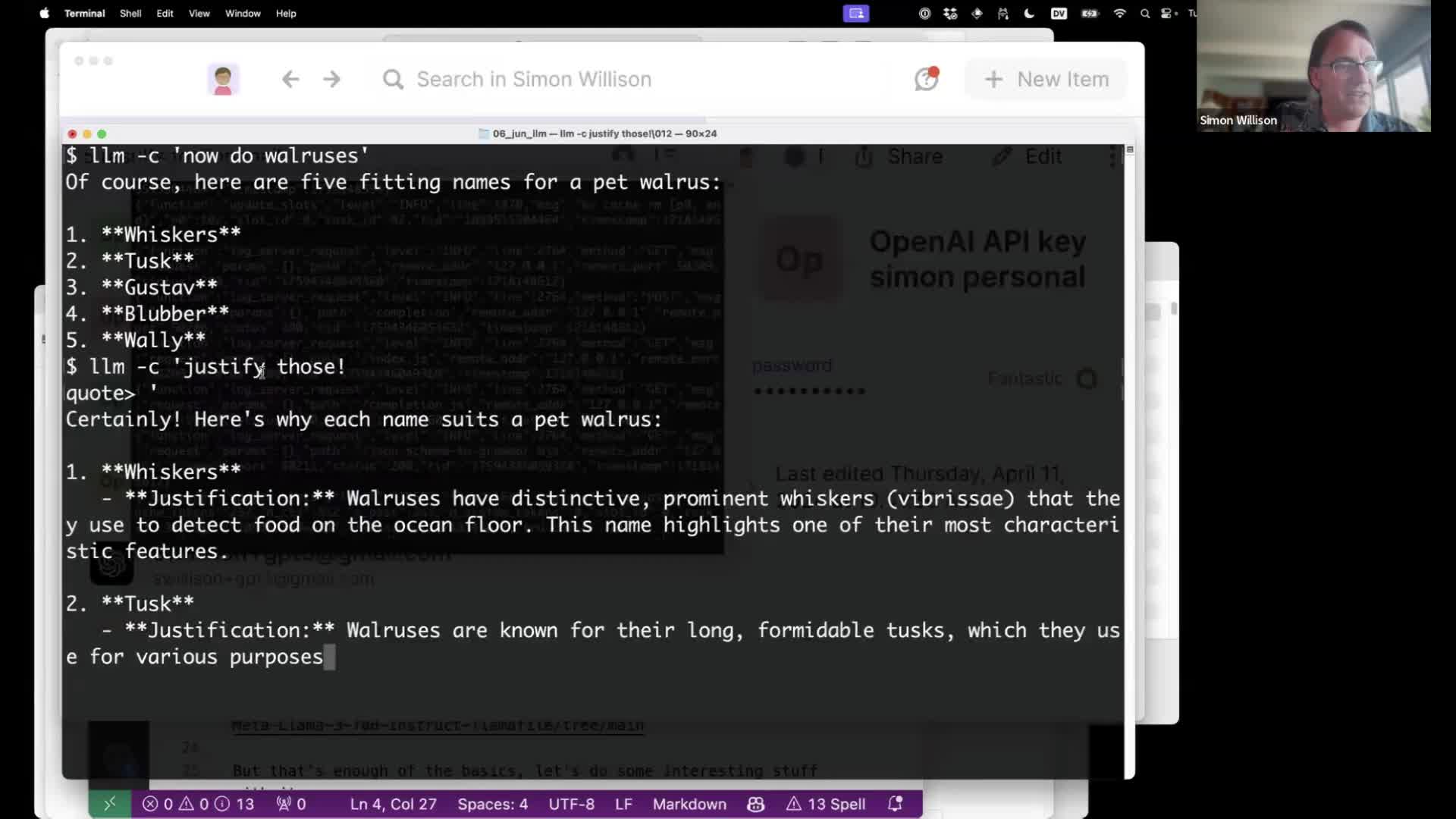
I gave a talk about accessing Large Language Models from the command-line last week as part of the Mastering LLMs: A Conference For Developers & Data Scientists six week long online conference. The talk focused on my LLM Python command-line utility and ways you can use it (and its plugins) to explore LLMs and use them for useful tasks.
[... 4,992 words]Datasette 0.64.7.
A very minor dot-fix release for Datasette stable, addressing this bug where Datasette running against the latest version of SQLite - 3.46.0 - threw an error on canned queries that included :named parameters in their SQL.
The root cause was Datasette using a now invalid clever trick I came up with against the undocumented and unstable opcodes returned by a SQLite EXPLAIN query.
I asked on the SQLite forum and learned that the feature I was using was removed in this commit to SQLite. D. Richard Hipp explains:
The P4 parameter to OP_Variable was not being used for anything. By omitting it, we make the prepared statement slightly smaller, reduce the size of the SQLite library by a few bytes, and help sqlite3_prepare() and similar run slightly faster.
Ham radio general exam question pool as JSON. I scraped a pass of my Ham radio general exam this morning. One of the tools I used to help me pass was a Datasette instance with all 429 questions from the official question pool. I've published that raw data as JSON on GitHub, which I converted from the official question pool document using an Observable notebook.
Relevant TIL: How I studied for my Ham radio general exam.
Weeknotes: more datasette-secrets, plus a mystery video project

I introduced datasette-secrets two weeks ago. The core idea is to provide a way for end-users to store secrets such as API keys in Datasette, allowing other plugins to access them.
Weeknotes: Llama 3, AI for Data Journalism, llm-evals and datasette-secrets
Llama 3 landed on Thursday. I ended up updating a whole bunch of different plugins to work with it, described in Options for accessing Llama 3 from the terminal using LLM.
[... 1,030 words]AI for Data Journalism: demonstrating what we can do with this stuff right now
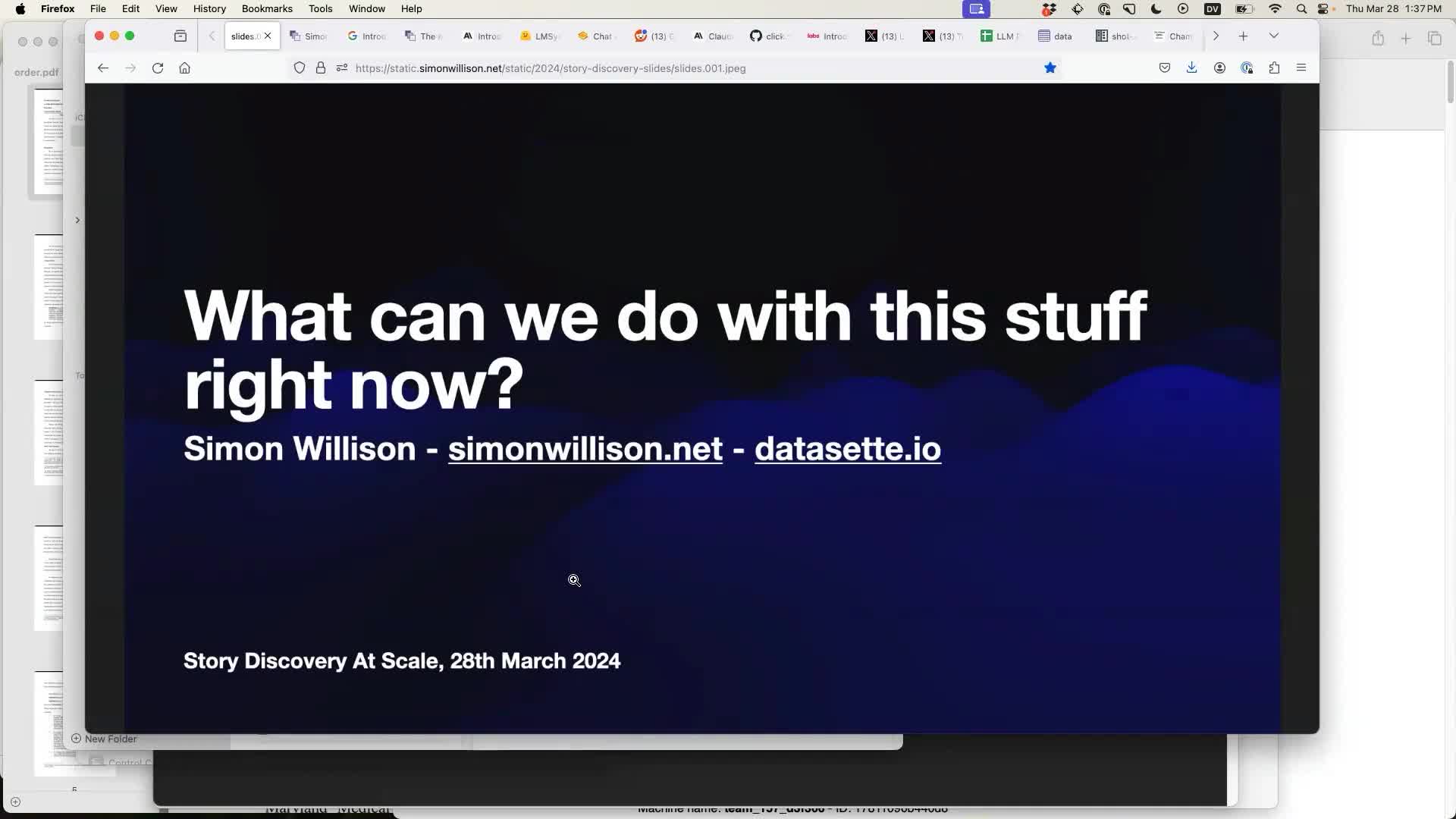
I gave a talk last month at the Story Discovery at Scale data journalism conference hosted at Stanford by Big Local News. My brief was to go deep into the things we can use Large Language Models for right now, illustrated by a flurry of demos to help provide starting points for further conversations at the conference.
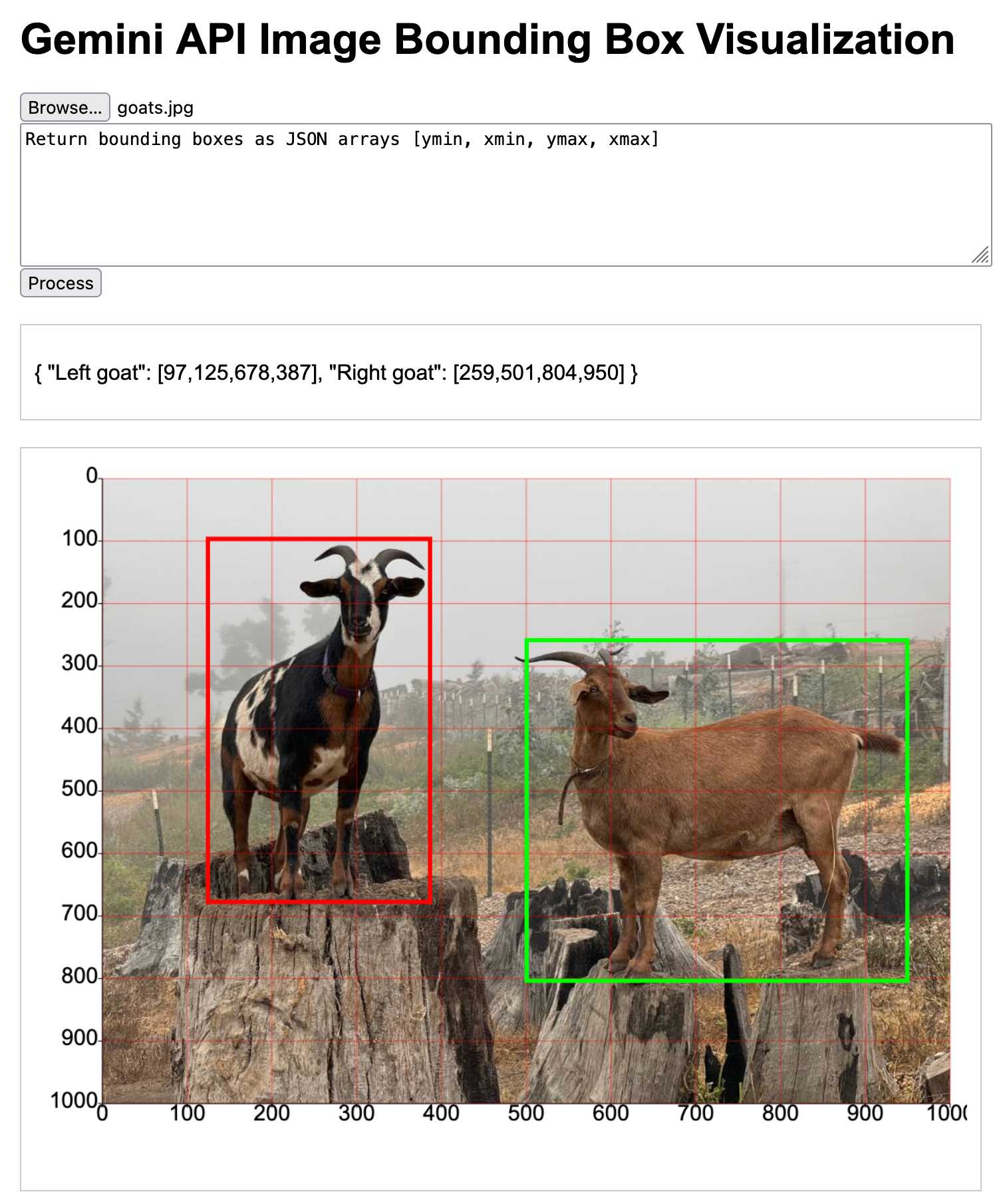
[... 6,081 words]Extracting data from unstructured text and images with Datasette and GPT-4 Turbo. Datasette Extract is a new Datasette plugin that uses GPT-4 Turbo (released to general availability today) and GPT-4 Vision to extract structured data from unstructured text and images.
I put together a video demo of the plugin in action today, and posted it to the Datasette Cloud blog along with screenshots and a tutorial describing how to use it.
datasette-import. A new plugin for importing data into Datasette. This is a replacement for datasette-paste, duplicating and extending its functionality. datasette-paste had grown beyond just dealing with pasted CSV/TSV/JSON data—it handles file uploads as well now—which inspired the new name.
Weeknotes: the aftermath of NICAR
NICAR was fantastic this year. Alex and I ran a successful workshop on Datasette and Datasette Cloud, and I gave a lightning talk demonstrating two new GPT-4 powered Datasette plugins—datasette-enrichments-gpt and datasette-extract. I need to write more about the latter one: it enables populating tables from unstructured content (using a variant of this technique) and it’s really effective. I got it working just in time for the conference.
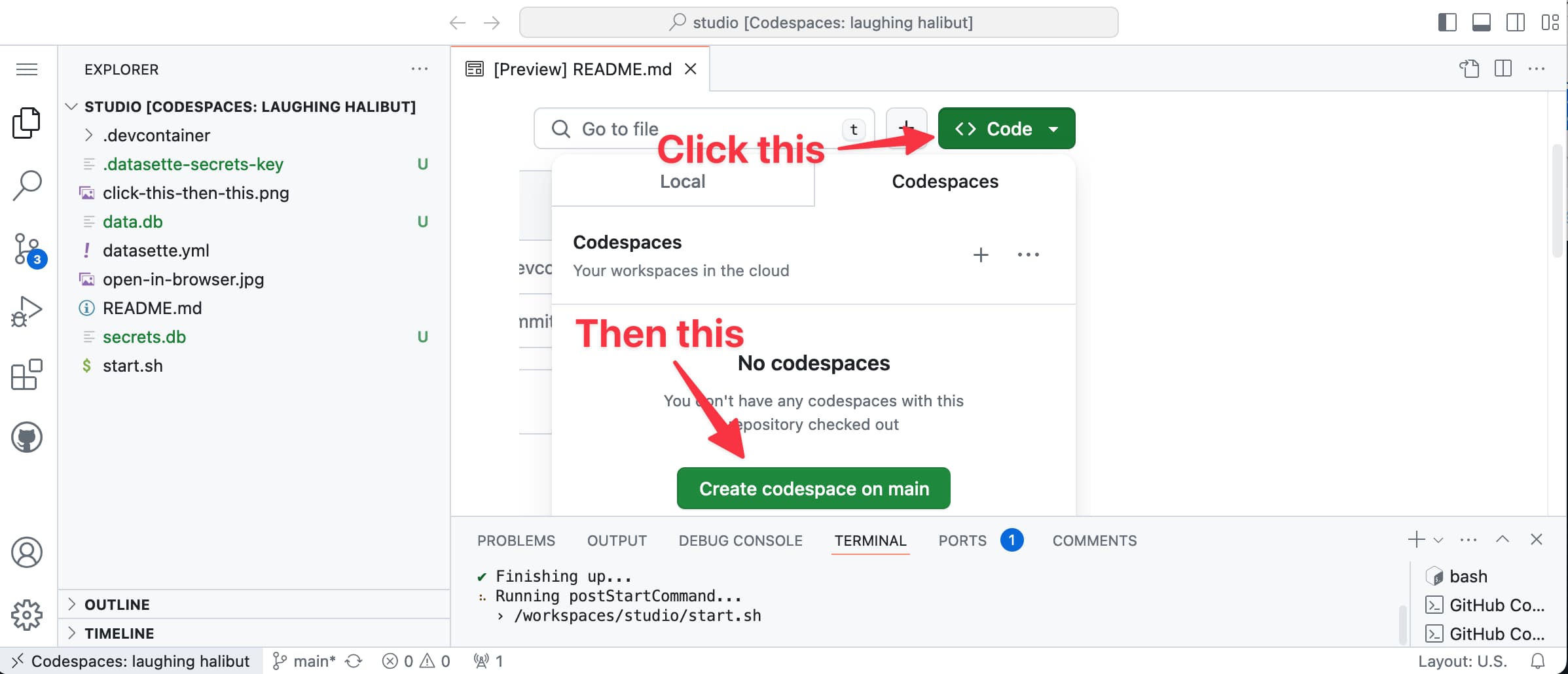
[... 1,430 words]datasette/studio. I’m trying a new way to make Datasette available for small personal data manipulation projects, using GitHub Codespaces.
This repository is designed to be opened directly in Codespaces—detailed instructions in the README.
When the container starts it installs the datasette-studio family of plugins—including CSV upload, some enrichments and a few other useful feature—then starts the server running and provides a big green button to click to access the server via GitHub’s port forwarding mechanism.
Datasette 1.0a12. Another alpha release, this time with a new query_actions() plugin hook, a new design for the table, database and query actions menus, a “does not contain” table filter and a fix for a minor bug with the JavaScript makeColumnActions() plugin mechanism.