Weeknotes: Llama 3, AI for Data Journalism, llm-evals and datasette-secrets
23rd April 2024
Llama 3 landed on Thursday. I ended up updating a whole bunch of different plugins to work with it, described in Options for accessing Llama 3 from the terminal using LLM.
I also wrote up the talk I gave at Stanford a few weeks ago: AI for Data Journalism: demonstrating what we can do with this stuff right now.
That talk had 12 different live demos in it, and a bunch of those were software that I hadn’t released yet when I gave the talk—so I spent quite a bit of time cleaning those up for release. The most notable of those is datasette-query-assistant, a plugin built on top of Claude 3 that takes a question in English and converts that into a SQL query. Here’s the section of that video with the demo.
I’ve also spun up two new projects which are still very much in the draft stage.
llm-evals
Ony of my biggest frustrations in working with LLMs is that I still don’t have a great way to evaluate improvements to my prompts. Did capitalizing OUTPUT IN JSON really make a difference? I don’t have a great mechanism for figuring that out.
datasette-query-assistant really needs this: Which models are best at generating SQLite SQL? What prompts make it most likely I’ll get a SQL query that executes successfully against the schema?
llm-evals-plugin (llmevals was taken on PyPI already) is a very early prototype of an LLM plugin that I hope to use to address this problem.
The idea is to define “evals” as YAML files, which might look something like this (format still very much in flux):
name: Simple translate
system: |
Return just a single word in the specified language
prompt: |
Apple in Spanish
checks:
- iexact: manzana
- notcontains: appleThen, to run the eval against multiple models:
llm install llm-evals-plugin
llm evals simple-translate.yml -m gpt-4-turbo -m gpt-3.5-turboWhich currently outputs this:
('gpt-4-turbo-preview', [True, True])
('gpt-3.5-turbo', [True, True])
Those checks: are provided by a plugin hook, with the aim of having plugins that add new checks like sqlite_execute: [["1", "Apple"]] that run SQL queries returned by the model and assert against the results—or even checks like js: response_text == 'manzana' that evaluate using a programming language (in that case using quickjs to run code in a sandbox).
This is still a rough sketch of how the tool will work. The big missing feature at the moment is parameterization: I want to be able to try out different prompt/system prompt combinations and run a whole bunch of additional examples that are defined in a CSV or JSON or YAML file.
I also want to record the results of those runs to a SQLite database, and also make it easy to dump those results out in a format that’s suitable for storing in a GitHub repository in order to track differences to the results over time.
This is a very early idea. I may find a good existing solution and use that instead, but for the moment I’m enjoying using running code as a way to explore a new problem space.
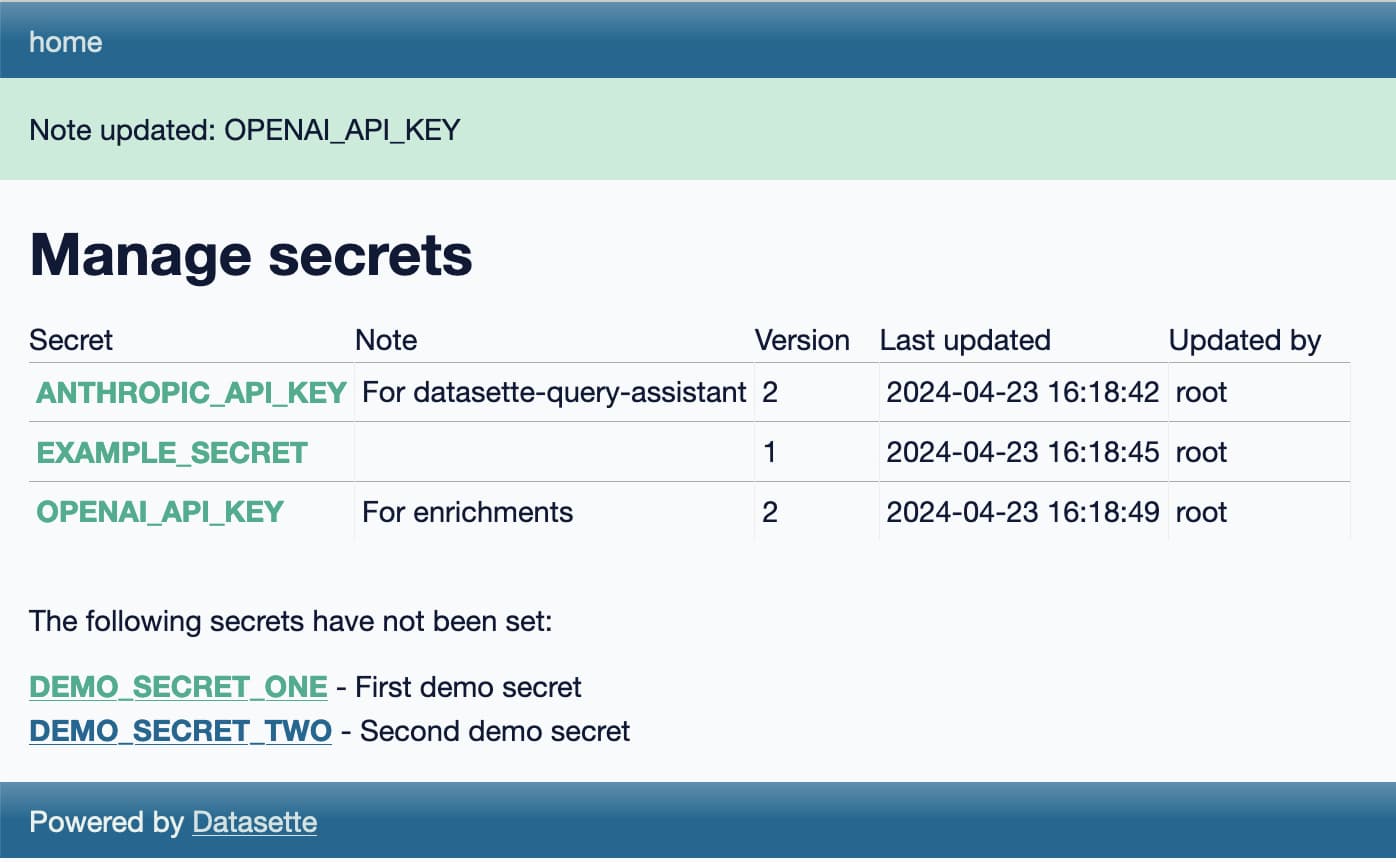
datasette-secrets
datasette-secrets is another draft project, this time a Datasette plugin.
I’m increasingly finding a need for Datasette plugins to access secrets—things like API keys. datasette-extract and datasette-enrichments-gpt both need an OpenAI API key, datasette-enrichments-opencage needs OpenCage Geocoder and datasette-query-assistant needs a key for Anthropic’s Claude.
Currently those keys are set using environment variables, but for both Datasette Cloud and Datasette Desktop I’d like users to be able to bring their own keys, without messing around with their environment.
datasette-secrets adds a UI for entering registered secrets, available to administrator level users with the manage-secrets permission. Those secrets are stored encrypted in the SQLite database, using symmetric encryption powered by the Python cryptography library.
The goal of the encryption is to ensure that if someone somehow obtains the SQLite database itself they won’t be able to access the secrets contained within, unless they also have access to the encryption key which is stored separately.
The next step with datasette-secrets is to ship some other plugins that use it. Once it’s proved itself there (and in an alpha release to Datasette Cloud) I’ll remove the alpha designation and start recommending it for use in other plugins.
Releases
-
datasette-secrets 0.1a1—2024-04-23
Manage secrets such as API keys for use with other Datasette plugins -
llm-llamafile 0.1—2024-04-22
Access llamafile localhost models via LLM -
llm-anyscale-endpoints 0.6—2024-04-21
LLM plugin for models hosted by Anyscale Endpoints -
llm-evals-plugin 0.1a0—2024-04-21
Run evals using LLM -
llm-gpt4all 0.4—2024-04-20
Plugin for LLM adding support for the GPT4All collection of models -
llm-fireworks 0.1a0—2024-04-18
Access fireworks.ai models via API -
llm-replicate 0.3.1—2024-04-18
LLM plugin for models hosted on Replicate -
llm-mistral 0.3.1—2024-04-18
LLM plugin providing access to Mistral models using the Mistral API -
llm-reka 0.1a0—2024-04-18
Access Reka models via the Reka API -
openai-to-sqlite 0.4.2—2024-04-17
Save OpenAI API results to a SQLite database -
datasette-query-assistant 0.1a2—2024-04-16
Query databases and tables with AI assistance -
datasette-cors 1.0.1—2024-04-12
Datasette plugin for configuring CORS headers -
asgi-cors 1.0.1—2024-04-12
ASGI middleware for applying CORS headers to an ASGI application -
llm-gemini 0.1a3—2024-04-10
LLM plugin to access Google’s Gemini family of models
TILs
More recent articles
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026
- sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25) - 5th July 2026