Options for accessing Llama 3 from the terminal using LLM
22nd April 2024
Llama 3 was released on Thursday. Early indications are that it’s now the best available openly licensed model—Llama 3 70b Instruct has taken joint 5th place on the LMSYS arena leaderboard, behind only Claude 3 Opus and some GPT-4s and sharing 5th place with Gemini Pro and Claude 3 Sonnet. But unlike those other models Llama 3 70b is weights available and can even be run on a (high end) laptop!
My LLM command-line tool and Python library provides access to dozens of models via plugins. Here are several ways you can use it to access Llama 3, both hosted versions and running locally on your own hardware.
- Llama-3-8B-Instruct locally with llm-gpt4all
- Fast API access via Groq
- Local Llama 3 70b Instruct with llamafile
- Paid access via other API providers
Llama-3-8B-Instruct locally with llm-gpt4all
If you want to run Llama 3 locally, the easiest way to do that with LLM is using the llm-gpt4all plugin. This plugin builds on the excellent gpt4all project by Nomic AI, providing a quantized (q4) Llama 3 8B instruct model that needs 8GB of RAM and requires a 4.34GB download.
If you don’t have LLM installed yet, install it like this:
brew install llmOr like this:
pipx install llmInstall the plugin:
llm install llm-gpt4allThe first time you run a prompt it will download the model:
llm -m Meta-Llama-3-8B-Instruct "Three great names for a pet emu"What an interesting question! Here are three name suggestions for your pet emu:
- Emmet: A playful take on the word “emu” that suits a friendly and curious bird.
- Gizmo: Emus are known for their quirky behavior, so Gizmo is a fitting name to capture their unique personality.
- Aussie: As an Australian native species, naming your emu Aussie would be a nod to its heritage.
Remember to choose a name that suits your pet’s temperament and characteristics!
Each time you run a command like this the model will be loaded into memory from scratch. To keep it resident in memory, use the llm chat command:
llm chat -m Meta-Llama-3-8B-InstructHere’s an example session:
Chatting with Meta-Llama-3-8B-Instruct
Type 'exit' or 'quit' to exit
Type '!multi' to enter multiple lines, then '!end' to finish
> javascript function to reverse a string
%
Here is the JavaScript code that reverses a given string:
```
function reverseString(str) {
return str.split("").reverse().join("");
}
```
You can use this function by passing your desired input string as an argument, like so:
```javascript
let reversedStr = reverseString("Hello World");
console.log(reversedStr); // Output: "dlroW olleH"
```
In the code above:
- `str.split("")` splits the original string into individual characters.
- `.reverse()` reverses the order of those characters.
- `.join("")` combines them back together as a single string.
This function works for any input string, not just "Hello World". Try it out with different strings to see how it handles punctuation and spaces!
> capitalize it too
%
Here's an updated JavaScript function that not only reverses the input string but also capitalizes each character:
```javascript
function reverseAndCapitalize(str) {
return str.split("").reverse().map(function(char) {
if (char.match(/[a-z]/i)) {
return char.toUpperCase();
} else {
return char;
}
}).join("");
}
```
(I’m not sure I’d write reverseAndCapitalize() quite like that, but still a fun example!)
Consult the LLM documentation for more details on how to use the command-line tool.
Fast API access via Groq
Groq serve openly licensed LLMs at ludicrous speeds using their own custom LPU (Language Processing Unit) Inference Engine. They currently offer a free preview of their API: you can sign up and obtain an API key to start using it.
You can run prompts against Groq using their OpenAI compatible API endpoint.
Edit the file ~/Library/Application Support/io.datasette.llm/extra-openai-models.yaml—creating it if it doesn’t exist—and add the following lines to it:
- model_id: groq-openai-llama3
model_name: llama3-70b-8192
api_base: https://api.groq.com/openai/v1
api_key_name: groq
- model_id: groq-openai-llama3-8b
model_name: llama3-8b-8192
api_base: https://api.groq.com/openai/v1
api_key_name: groqThis tells LLM about those models, and makes them accessible via those configured model_id values.
Run this command to confirm that the models were registered correctly:
llm models | grep groqYou should see this:
OpenAI Chat: groq-openai-llama3
OpenAI Chat: groq-openai-llama3-8b
Set your Groq API key like this:
llm keys set groq
# <Paste your API key here>Now you should be able to run prompts through the models like this:
llm -m groq-openai-llama3 "A righteous sonnet about a brave owl"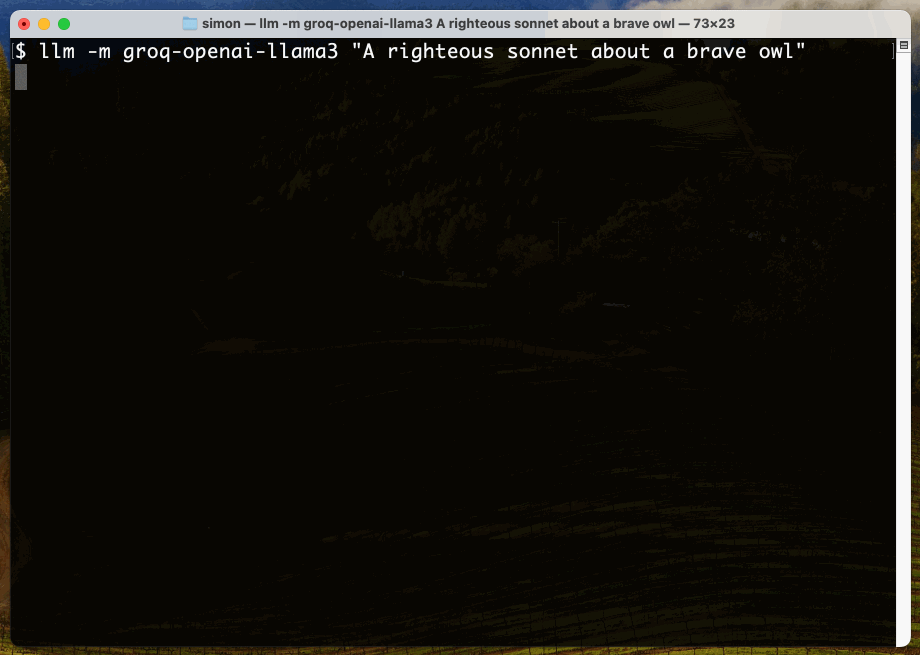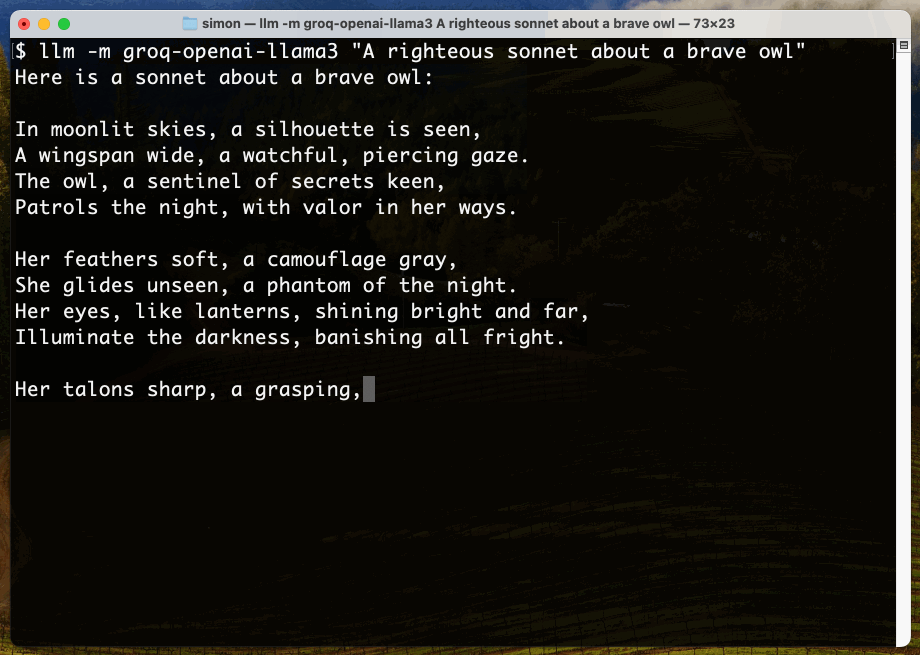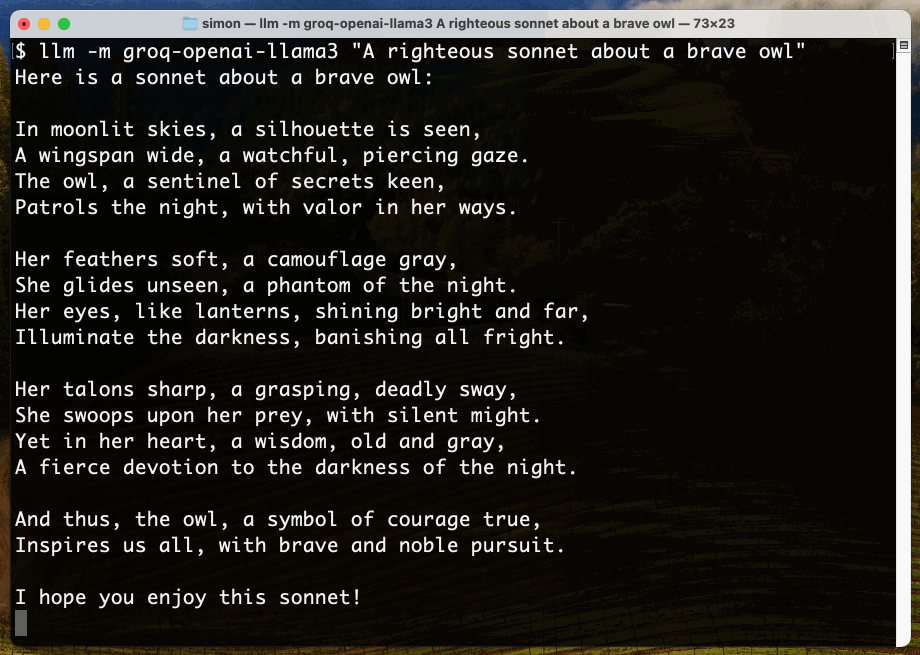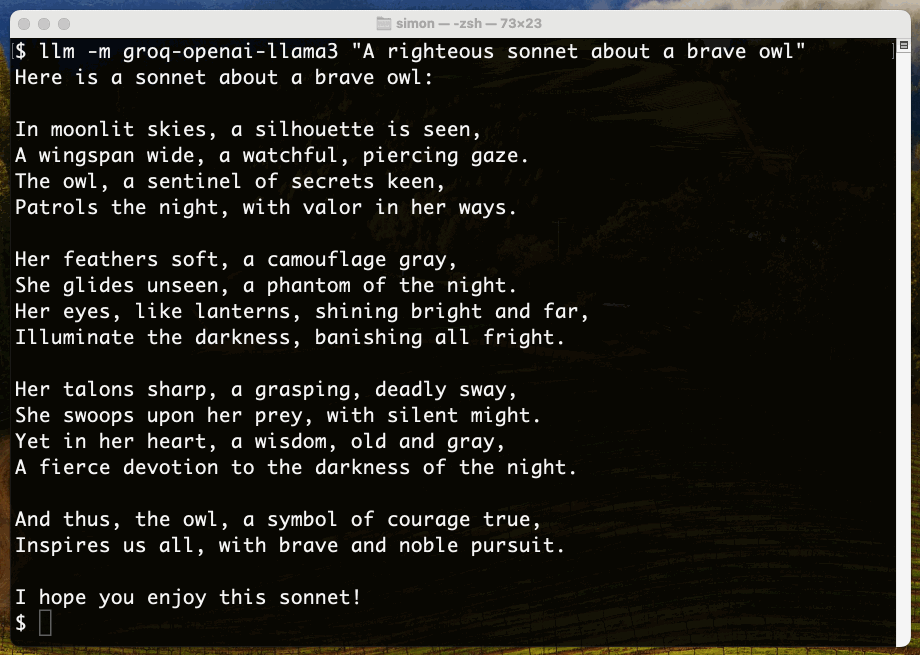
Groq is fast.
There’s also a llm-groq plugin but it hasn’t shipped support for the new models just yet—though there’s a PR for that by Lex Herbert here and you can install the plugin directly from that PR like this:
llm install https://github.com/lexh/llm-groq/archive/ba9d7de74b3057b074a85fe99fe873b75519bd78.zip
llm keys set groq
# paste API key here
llm -m groq-llama3-70b 'say hi in spanish five ways'Local Llama 3 70b Instruct with llamafile
The Llama 3 8b model is easy to run on a laptop, but it’s pretty limited in capability. The 70b model is the one that’s starting to get competitive with GPT-4. Can we run that on a laptop?
I managed to run the 70b model on my 64GB MacBook Pro M2 using llamafile (previously on this blog)—after quitting most other applications to make sure the 37GB of RAM it needed was available.
I used the Meta-Llama-3-70B-Instruct.Q4_0.llamafile Q4 version from jartine/Meta-Llama-3-70B-Instruct-llamafile—a 37GB download. I have a dedicated external hard disk (a Samsung T7 Shield) for this kind of thing.
Here’s how I got it working:
curl -L -o Meta-Llama-3-70B-Instruct.Q4_0.llamafile 'https://huggingface.co/jartine/Meta-Llama-3-70B-Instruct-llamafile/resolve/main/Meta-Llama-3-70B-Instruct.Q4_0.llamafile?download=true'
# That downloads 37GB - now make it executable
chmod 755 Meta-Llama-3-70B-Instruct.Q4_0.llamafile
# And start it running:
./Meta-Llama-3-70B-Instruct.Q4_0.llamafileA llamafile is an executable that runs on virtually any platform—see my previous notes on Cosmopolitan and Actually Portable Executable for more on how that works.
This will take quite a while to start, because it needs to load that full 37GB of binary content into memory. Once it’s finished loading a local web server becomes available at http://127.0.0.1:8080/—this serves a web UI you can use to interact with the model, and also serves another OpenAI-compatible API endpoint.
The easiest way to access this from LLM is to install the llm-llamafile plugin:
llm install llm-llamafileAll this plugin does is configure a model called llamafile that attempts to access the model hosted on port 8080. You can run prompts like this:
llm -m llamafile "3 neat characteristics of a pelican"Here are three neat characteristics of a pelican:
Unique Beak: Pelicans have a distinctive beak that is shaped like a scoop or a basket. This beak is specially designed to catch fish, and it can hold up to 3 gallons of water! The beak is also very sensitive, which helps pelicans detect the presence of fish in the water.
Waterproof Feathers: Pelicans have a special coating on their feathers that makes them waterproof. This is essential for their fishing lifestyle, as they need to be able to dive into the water without getting weighed down by wet feathers. The coating is made up of a waxy substance that helps to repel water.
Pouch-Like Throat: Pelicans have a unique throat pouch that allows them to catch and store fish. When they dive into the water, they use their beak to scoop up fish, and then they store them in their throat pouch. The pouch can expand to hold multiple fish, and the pelican can then swallow the fish whole or regurgitate them to feed their young. This pouch is a key adaptation that helps pelicans thrive in their aquatic environment.
If you don’t want to install another plugin, you can instead configure the model by adding this to your openai-extra-models.yaml file:
- model_id: llamafile
model_name: llamafile
api_base: http://localhost:8080/v1
api_key: xOne warning about this approach: if you use LLM like this then every prompt you run through llamafile will be stored under the same model name in your SQLite logs, even if you try out different llamafile models at different times. You could work around this by registering them with different model_id values in the YAML file.
Paid access via other API providers
A neat thing about open weight models is that multiple API providers can offer them, encouraging them to aggressively compete on price.
Groq is currently free, but that’s with a limited number of free requests.
A number of other providers are now hosting Llama 3, and many of them have plugins available for LLM. Here are a few examples:
-
Perplexity Labs are offering
llama-3-8b-instructandllama-3-70b-instruct. The llm-perplexity plugin provides access—llm install llm-perplexityto install,llm keys set perplexityto set an API key and then run prompts against those two model IDs. Current price for 8b is $0.20 per million tokens, for 80b is $1.00. -
Anyscale Endpoints have
meta-llama/Llama-3-8b-chat-hf($0.15/million tokens) andmeta-llama/Llama-3-70b-chat-hf($1.0/million tokens) (pricing).llm install llm-anyscale-endpoints, thenllm keys set anyscale-endpointsto set the API key. -
Fireworks AI have
fireworks/models/llama-v3-8b-instructfor $0.20/million andfireworks/models/llama-v3-70b-instructfor $0.90/million (pricing).llm install llm-fireworks, thenllm keys set fireworksto set the API key. - OpenRouter provide proxied accessed to Llama 3 from a number of different providers at different prices, documented on their meta-llama/llama-3-70b-instruct and meta-llama/llama-3-8b-instruct pages (and more). Use the llm-openrouter plugin for those.
-
Together AI has both models as well. The llm-together plugin provides access to
meta-llama/Llama-3-8b-chat-hfandmeta-llama/Llama-3-70b-chat-hf.
I’m sure there are more—these are just the ones I’ve tried out myself. Check the LLM plugin directory for other providers, or if a provider emulates the OpenAI API you can configure with the YAML file as shown above or described in the LLM documentation.
That’s a lot of options
One key idea behind LLM is to use plugins to provide access to as many different models as possible. Above I’ve listed two ways to run Llama 3 locally and six different API vendors that LLM can access as well.
If you’re inspired to write your own plugin it’s pretty simple: each of the above plugins is open source, and there’s a detailed tutorial on Writing a plugin to support a new model on the LLM website.
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026