Qwen2.5-Coder-32B is an LLM that can code well that runs on my Mac
12th November 2024
There’s a whole lot of buzz around the new Qwen2.5-Coder Series of open source (Apache 2.0 licensed) LLM releases from Alibaba’s Qwen research team. On first impression it looks like the buzz is well deserved.
Qwen claim:
Qwen2.5-Coder-32B-Instruct has become the current SOTA open-source code model, matching the coding capabilities of GPT-4o.
That’s a big claim for a 32B model that’s small enough that it can run on my 64GB MacBook Pro M2. The Qwen published scores look impressive, comparing favorably with GPT-4o and Claude 3.5 Sonnet (October 2024) edition across various code-related benchmarks:
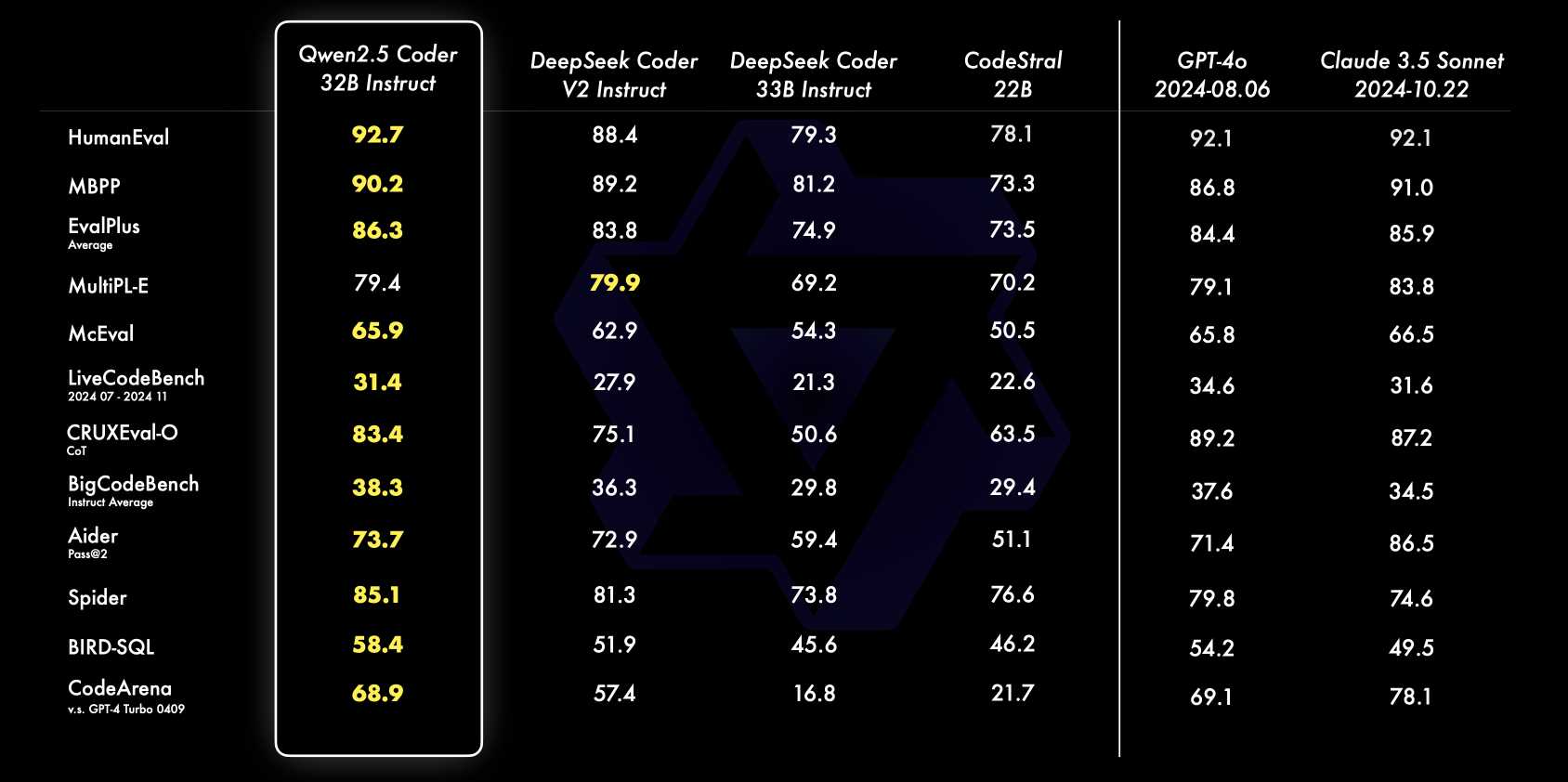
How about benchmarks from other researchers? Paul Gauthier’s Aider benchmarks have a great reputation and Paul reports:
The new Qwen 2.5 Coder models did very well on aider’s code editing benchmark. The 32B Instruct model scored in between GPT-4o and 3.5 Haiku.
84% 3.5 Sonnet, 75% 3.5 Haiku, 74% Qwen2.5 Coder 32B, 71% GPT-4o, 69% Qwen2.5 Coder 14B, 58% Qwen2.5 Coder 7B
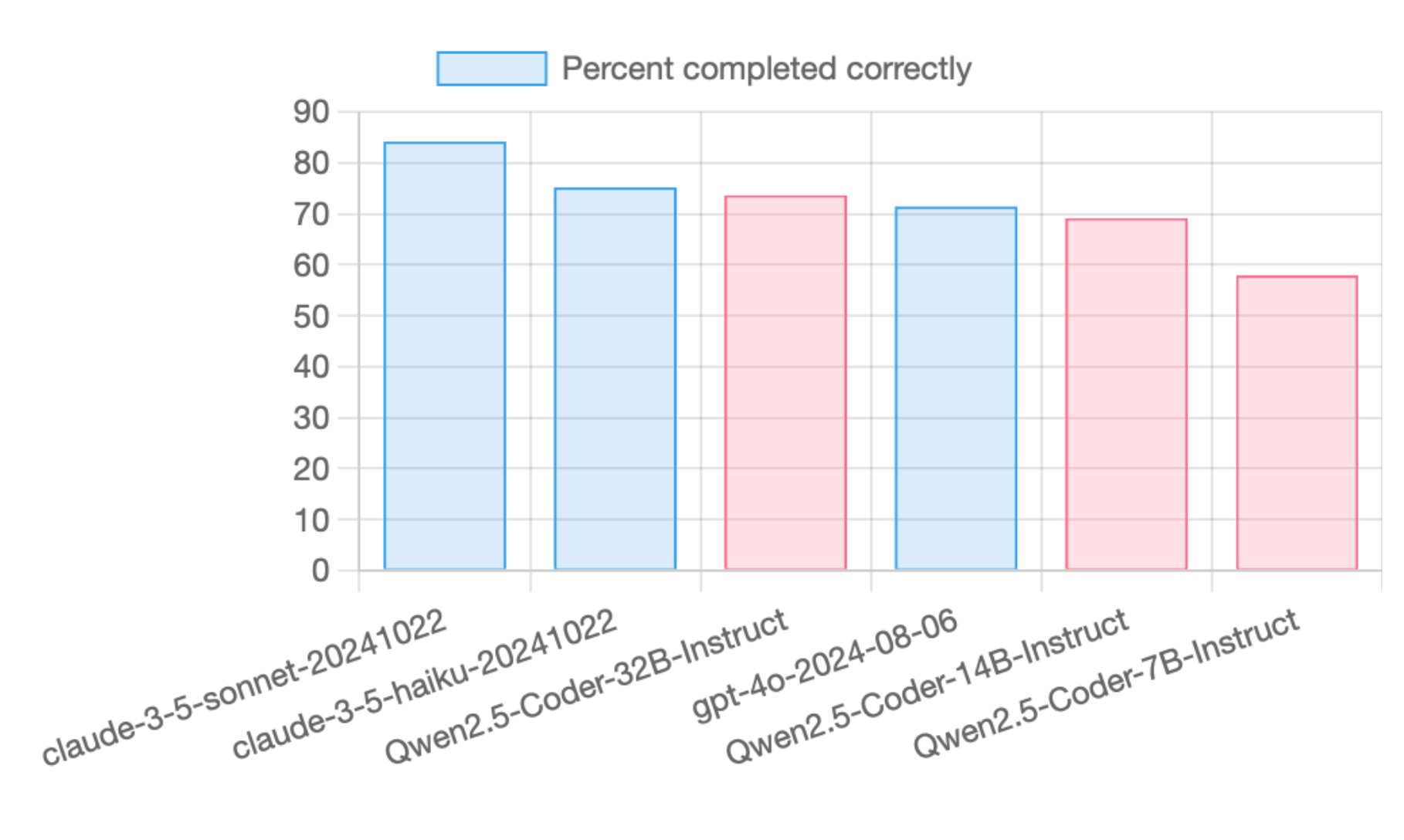
That was for the Aider “whole edit” benchmark. The “diff” benchmark scores well too, with Qwen2.5 Coder 32B tying with GPT-4o (but a little behind Claude 3.5 Haiku).
Given these scores (and the positive buzz on Reddit) I had to try it for myself.
My attempts to run the Qwen/Qwen2.5-Coder-32B-Instruct-GGUF Q8 using llm-gguf were a bit too slow, because I don’t have that compiled to use my Mac’s GPU at the moment.
But both the Ollama version and the MLX version worked great!
I installed the Ollama version using:
ollama pull qwen2.5-coder:32b
That fetched a 20GB quantized file. I ran a prompt through that using my LLM tool and Sergey Alexandrov’s llm-ollama plugin like this:
llm install llm-ollama
llm models # Confirming the new model is present
llm -m qwen2.5-coder:32b 'python function that takes URL to a CSV file and path to a SQLite database, fetches the CSV with the standard library, creates a table with the right columns and inserts the data'
Here’s the result. The code worked, but I had to work around a frustrating ssl bug first (which wouldn’t have been an issue if I’d allowed the model to use requests or httpx instead of the standard library).
I also tried running it using the Apple Silicon fast array framework MLX using the mlx-llm library directly, run via uv like this:
uv run --with mlx-lm \
mlx_lm.generate \
--model mlx-community/Qwen2.5-Coder-32B-Instruct-8bit \
--max-tokens 4000 \
--prompt 'write me a python function that renders a mandelbrot fractal as wide as the current terminal'
That gave me a very satisfying result—when I ran the code it generated in a terminal I got this:
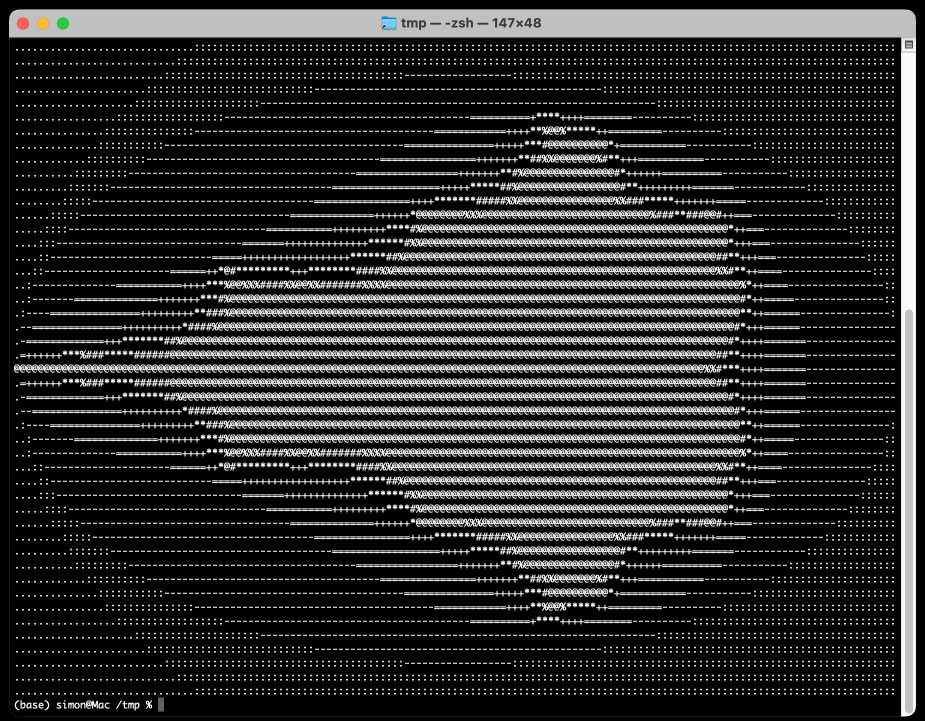
MLX reported the following performance metrics:
Prompt: 49 tokens, 95.691 tokens-per-sec Generation: 723 tokens, 10.016 tokens-per-sec Peak memory: 32.685 GB
Let’s see how it does on the Pelican on a bicycle benchmark.
llm -m qwen2.5-coder:32b 'Generate an SVG of a pelican riding a bicycle'Here’s what I got:

Questionable Pelican SVG drawings aside, this is a really promising development. 32GB is just small enough that I can run the model on my Mac without having to quit every other application I’m running, and both the speed and the quality of the results feel genuinely competitive with the current best of the hosted models.
Given that code assistance is probably around 80% of my LLM usage at the moment this is a meaningfully useful release for how I engage with this class of technology.
More recent articles
- OpenAI’s accidental cyberattack against Hugging Face is science fiction that happened - 22nd July 2026
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026