October 2024
165 posts: 12 entries, 82 links, 22 quotes, 49 beats
Oct. 8, 2024
Anthropic: Message Batches (beta) (via) Anthropic now have a batch mode, allowing you to send prompts to Claude in batches which will be processed within 24 hours (though probably much faster than that) and come at a 50% price discount.
This matches the batch models offered by OpenAI and by Google Gemini, both of which also provide a 50% discount.
Update 15th October 2024: Alex Albert confirms that Anthropic batching and prompt caching can be combined:
Don't know if folks have realized yet that you can get close to a 95% discount on Claude 3.5 Sonnet tokens when you combine prompt caching with the new Batches API
If we had $1,000,000…. Jacob Kaplan-Moss gave my favorite talk at DjangoCon this year, imagining what the Django Software Foundation could do if it quadrupled its annual income to $1 million and laying out a realistic path for getting there. Jacob suggests leaning more into large donors than increasing our small donor base:
It’s far easier for me to picture convincing eight or ten or fifteen large companies to make large donations than it is to picture increasing our small donor base tenfold. So I think a major donor strategy is probably the most realistic one for us.
So when I talk about major donors, who am I talking about? I’m talking about four major categories: large corporations, high net worth individuals (very wealthy people), grants from governments (e.g. the Sovereign Tech Fund run out of Germany), and private foundations (e.g. the Chan Zuckerberg Initiative, who’s given grants to the PSF in the past).
Also included: a TIL on Turning a conference talk into an annotated presentation. Jacob used my annotated presentation tool to OCR text from images of keynote slides, extracted a Whisper transcript from the YouTube livestream audio and then cleaned that up a little with LLM and Claude 3.5 Sonnet ("Split the content of this transcript up into paragraphs with logical breaks. Add newlines between each paragraph.") before editing and re-writing it all into the final post.
Oct. 9, 2024
openai/openai-realtime-console. I got this OpenAI demo repository working today - it's an extremely easy way to get started playing around with the new Realtime voice API they announced at DevDay last week:
cd /tmp
git clone https://github.com/openai/openai-realtime-console
cd openai-realtime-console
npm i
npm start
That starts a localhost:3000 server running the demo React application. It asks for an API key, you paste one in and you can start talking to the web page.
The demo handles voice input, voice output and basic tool support - it has a tool that can show you the weather anywhere in the world, including panning a map to that location. I tried adding a show_map() tool so I could pan to a location just by saying "Show me a map of the capital of Morocco" - all it took was editing the src/pages/ConsolePage.tsx file and hitting save, then refreshing the page in my browser to pick up the new function.
Be warned, it can be quite expensive to play around with. I was testing the application intermittently for only about 15 minutes and racked up $3.87 in API charges.

otterwiki (via) It's been a while since I've seen a new-ish Wiki implementation, and this one by Ralph Thesen is really nice. It's written in Python (Flask + SQLAlchemy + mistune for Markdown + GitPython) and keeps all of the actual wiki content as Markdown files in a local Git repository.
The installation instructions are a little in-depth as they assume a production installation with Docker or systemd - I figured out this recipe for trying it locally using uv:
git clone https://github.com/redimp/otterwiki.git
cd otterwiki
mkdir -p app-data/repository
git init app-data/repository
echo "REPOSITORY='${PWD}/app-data/repository'" >> settings.cfg
echo "SQLALCHEMY_DATABASE_URI='sqlite:///${PWD}/app-data/db.sqlite'" >> settings.cfg
echo "SECRET_KEY='$(echo $RANDOM | md5sum | head -c 16)'" >> settings.cfg
export OTTERWIKI_SETTINGS=$PWD/settings.cfg
uv run --with gunicorn gunicorn --bind 127.0.0.1:8080 otterwiki.server:app
The Fair Source Definition (via) Fair Source (fair.io) is the new-ish initiative from Chad Whitacre and Sentry aimed at providing an alternative licensing philosophy that provides additional protection for the business models of companies that release their code.
I like that they're establishing a new brand for this and making it clear that it's a separate concept from Open Source. Here's their definition:
Fair Source is an alternative to closed source, allowing you to safely share access to your core products. Fair Source Software (FSS):
- is publicly available to read;
- allows use, modification, and redistribution with minimal restrictions to protect the producer’s business model; and
- undergoes delayed Open Source publication (DOSP).
They link to the Delayed Open Source Publication research paper published by OSI in January. (I was frustrated that this is only available as a PDF, so I converted it to Markdown using Gemini 1.5 Pro so I could read it on my phone.)
The most interesting background I could find on Fair Source was this GitHub issues thread, started in May, where Chad and other contributors fleshed out the initial launch plan over the course of several months.
Free Threaded Python With Asyncio.
Jamie Chang expanded my free-threaded Python experiment from a few months ago to explore the interaction between Python's asyncio and the new GIL-free build of Python 3.13.
The results look really promising. Jamie says:
Generally when it comes to Asyncio, the discussion around it is always about the performance or lack there of. Whilst peroformance is certain important, the ability to reason about concurrency is the biggest benefit. [...]
Depending on your familiarity with AsyncIO, it might actually be the simplest way to start a thread.
This code for running a Python function in a thread really is very pleasant to look at:
result = await asyncio.to_thread(some_function, *args, **kwargs)
Jamie also demonstrates asyncio.TaskGroup, which makes it easy to execute a whole bunch of threads and wait for them all to finish:
async with TaskGroup() as tg:
for _ in range(args.tasks):
tg.create_task(to_thread(cpu_bound_task, args.size))
Forums are still alive, active, and a treasure trove of information (via) Chris Person:
When I want information, like the real stuff, I go to forums. Over the years, forums did not really get smaller, so much as the rest of the internet just got bigger. Reddit, Discord and Facebook groups have filled a lot of that space, but there is just certain information that requires the dedication of adults who have specifically signed up to be in one kind of community.
This is a very comprehensive directory of active forums.
RISD BFA Industrial Design: AI Software Design Studio. Fascinating syllabus for a course on digital product design taught at the Rhode Island School of Design by Kelin Carolyn Zhang.
Designers must adapt and shape the frontier of AI-driven computing — while navigating the opportunities, risks, and ethical responsibilities of working with this new technology.
In this new world, creation is cheap, craft is automatable, and everyone is a beginner. The ultimate differentiator will be the creator’s perspective, taste, and judgment. The software design education for our current moment must prioritize this above all else.
By course's end, students will have hands-on experience with an end-to-end digital product design process, culminating in a physical or digital product that takes advantage of the unique properties of generative AI models. Prior coding experience is not required, but students will learn using AI coding assistants like ChatGPT and Claude.
From Kelin's Twitter thread about the course so far:
these are juniors in industrial design. about half of them don't have past experience even designing software or using figma [...]
to me, they're doing great because they're moving super quickly
what my 4th yr interaction design students in 2019 could make in half a semester, these 3rd year industrial design students are doing in a few days with no past experience [...]
they very quickly realized the limits of LLM code in week 1, especially in styling & creating unconventional behavior
AI can help them make a functional prototype with js in minutes, but it doesn't look good
Oct. 10, 2024
Announcing Deno 2. The big focus of Deno 2 is compatibility with the existing Node.js and npm ecosystem:
Deno 2 takes all of the features developers love about Deno 1.x — zero-config, all-in-one toolchain for JavaScript and TypeScript development, web standard API support, secure by default — and makes it fully backwards compatible with Node and npm (in ESM).
The npm support is documented here. You can write a script like this:
import * as emoji from "npm:node-emoji";
console.log(emoji.emojify(`:sauropod: :heart: npm`));And when you run it Deno will automatically fetch and cache the required dependencies:
deno run main.js
Another new feature that caught my eye was this:
deno jupyternow supports outputting images, graphs, and HTML
Deno has apparently shipped with a Jupyter notebook kernel for a while, and it's had a major upgrade in this release.
Here's Ryan Dahl's demo of the new notebook support in his Deno 2 release video.
I tried this out myself, and it's really neat. First you need to install the kernel:
deno juptyer --install
I was curious to find out what this actually did, so I dug around in the code and then further in the Rust runtimed dependency. It turns out installing Jupyter kernels, at least on macOS, involves creating a directory in ~/Library/Jupyter/kernels/deno and writing a kernel.json file containing the following:
{
"argv": [
"/opt/homebrew/bin/deno",
"jupyter",
"--kernel",
"--conn",
"{connection_file}"
],
"display_name": "Deno",
"language": "typescript"
}That file is picked up by any Jupyter servers running on your machine, and tells them to run deno jupyter --kernel ... to start a kernel.
I started Jupyter like this:
jupyter-notebook /tmp
Then started a new notebook, selected the Deno kernel and it worked as advertised:
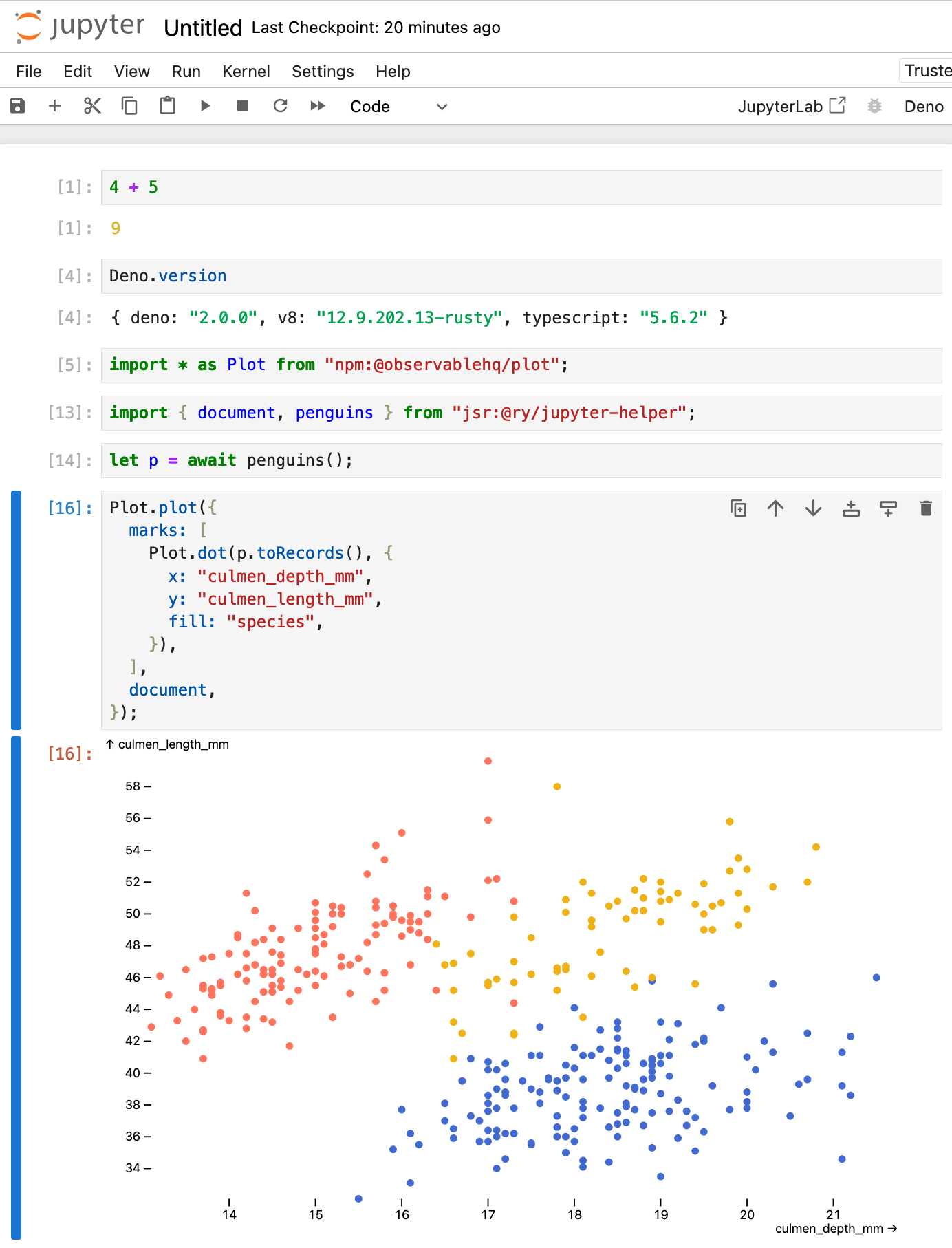
import * as Plot from "npm:@observablehq/plot";
import { document, penguins } from "jsr:@ry/jupyter-helper";
let p = await penguins();
Plot.plot({
marks: [
Plot.dot(p.toRecords(), {
x: "culmen_depth_mm",
y: "culmen_length_mm",
fill: "species",
}),
],
document,
});
Bridging Language Gaps in Multilingual Embeddings via Contrastive Learning (via) Most text embeddings models suffer from a "language gap", where phrases in different languages with the same semantic meaning end up with embedding vectors that aren't clustered together.
Jina claim their new jina-embeddings-v3 (CC BY-NC 4.0, which means you need to license it for commercial use if you're not using their API) is much better on this front, thanks to a training technique called "contrastive learning".
There are 30 languages represented in our contrastive learning dataset, but 97% of pairs and triplets are in just one language, with only 3% involving cross-language pairs or triplets. But this 3% is enough to produce a dramatic result: Embeddings show very little language clustering and semantically similar texts produce close embeddings regardless of their language

Oct. 11, 2024
Providing validation, strength, and stability to people who feel gaslit and dismissed and forgotten can help them feel stronger and surer in their decisions. These pieces made me understand that journalism can be a caretaking profession, even if it is never really thought about in those terms. It is often framed in terms of antagonism. Speaking truth to power turns into being hard-nosed and removed from our subject matter, which so easily turns into be an asshole and do whatever you like.
This is a viewpoint that I reject. My pillars are empathy, curiosity, and kindness. And much else flows from that. For people who feel lost and alone, we get to say through our work, you are not. For people who feel like society has abandoned them and their lives do not matter, we get to say, actually, they fucking do. We are one of the only professions that can do that through our work and that can do that at scale.
HTML for People (via) Blake Watson's brand new HTML tutorial, presented as a free online book (CC BY-NC-SA 4.0, on GitHub). This seems very modern and well thought-out to me. It focuses exclusively on HTML, skipping JavaScript entirely and teaching with Simple.css to avoid needing to dig into CSS while still producing sites that are pleasing to look at. It even touches on Web Components (described as Custom HTML tags) towards the end.
The primary use of “misinformation” is not to change the beliefs of other people at all. Instead, the vast majority of misinformation is offered as a service for people to maintain their beliefs in face of overwhelming evidence to the contrary.
— Mike Caulfield, via Charlie Warzel
$2 H100s: How the GPU Bubble Burst. Fascinating analysis from Eugene Cheah, founder of LLM hosting provider Featherless, discussing GPU economics over the past 12 months.
TLDR: Don’t buy H100s. The market has flipped from shortage ($8/hr) to oversupplied ($2/hr), because of reserved compute resales, open model finetuning, and decline in new foundation model co’s. Rent instead.
lm.rs: run inference on Language Models locally on the CPU with Rust (via) Impressive new LLM inference implementation in Rust by Samuel Vitorino. I tried it just now on an M2 Mac with 64GB of RAM and got very snappy performance for this Q8 Llama 3.2 1B, with Activity Monitor reporting 980% CPU usage over 13 threads.
Here's how I compiled the library and ran the model:
cd /tmp
git clone https://github.com/samuel-vitorino/lm.rs
cd lm.rs
RUSTFLAGS="-C target-cpu=native" cargo build --release --bin chat
curl -LO 'https://huggingface.co/samuel-vitorino/Llama-3.2-1B-Instruct-Q8_0-LMRS/resolve/main/tokenizer.bin?download=true'
curl -LO 'https://huggingface.co/samuel-vitorino/Llama-3.2-1B-Instruct-Q8_0-LMRS/resolve/main/llama3.2-1b-it-q80.lmrs?download=true'
./target/release/chat --model llama3.2-1b-it-q80.lmrs --show-metrics
That --show-metrics option added this at the end of a response:
Speed: 26.41 tok/s
It looks like the performance is helped by two key dependencies: wide, which provides data types optimized for SIMD operations and rayon for running parallel iterators across multiple cores (used for matrix multiplication).
(I used LLM and files-to-prompt to help figure this out.)
Oct. 12, 2024
Cabel Sasser at XOXO (via) I cannot recommend this talk highly enough for the way it ends. After watching the video dive into this new site that accompanies the talk - an online archive of the works of commercial artist Wes Cook. I too would very much love to see a full scan of The Lost McDonalds Satire Triptych.
Frankenstein is a terrific book partly based on how concerned people were about electricity. It captures our fears about the nature of being human but didn’t help anyone really come up with better policies for dealing with electricity. I worry that a lot of AI critics are doing the same thing.
Carl Hewitt recently remarked that the question what is an agent? is embarrassing for the agent-based computing community in just the same way that the question what is intelligence? is embarrassing for the mainstream AI community. The problem is that although the term is widely used, by many people working in closely related areas, it defies attempts to produce a single universally accepted definition. This need not necessarily be a problem: after all, if many people are successfully developing interesting and useful applications, then it hardly matters that they do not agree on potentially trivial terminological details. However, there is also the danger that unless the issue is discussed, 'agent' might become a 'noise' term, subject to both abuse and misuse, to the potential confusion of the research community.
— Michael Wooldridge, in 1994, Intelligent Agents: Theory and Practice
Python 3.13’s best new features (via) Trey Hunner highlights some Python 3.13 usability improvements I had missed, mainly around the new REPL.
Pasting a block of code like a class or function that includes blank lines no longer breaks in the REPL - particularly useful if you frequently have LLMs write code for you to try out.
Hitting F2 in the REPL toggles "history mode" which gives you your Python code without the REPL's >>> and ... prefixes - great for copying code back out again.
Creating a virtual environment with python3.13 -m venv .venv now adds a .venv/.gitignore file containing * so you don't need to explicitly ignore that directory. I just checked and it looks like uv venv implements the same trick.
And my favourite:
Historically, any line in the Python debugger prompt that started with a PDB command would usually trigger the PDB command, instead of PDB interpreting the line as Python code. [...]
But now, if the command looks like Python code,
pdbwill run it as Python code!
Which means I can finally call list(iterable) in my pdb seesions, where previously I've had to use [i for i in iterable] instead.
(Tip from Trey: !list(iterable) and [*iterable] are good alternatives for pre-Python 3.13.)
Trey's post is also available as a YouTube video.
Perks of Being a Python Core Developer
(via)
Mariatta Wijaya provides a detailed breakdown of the exact capabilities and privileges that are granted to Python core developers - including commit access to the Python main, the ability to write or sponsor PEPs, the ability to vote on new core developers and for the steering council election and financial support from the PSF for travel expenses related to PyCon and core development sprints.
Not to be under-estimated is that you also gain respect:
Everyone’s always looking for ways to stand out in resumes, right? So do I. I’ve been an engineer for longer than I’ve been a core developer, and I do notice that having the extra title like open source maintainer and public speaker really make a difference. As a woman, as someone with foreign last name that nobody knows how to pronounce, as someone who looks foreign, and speaks in a foreign accent, having these extra “credentials” helped me be seen as more or less equal compared to other people.
jefftriplett/django-startproject
(via)
Django's django-admin startproject and startapp commands include a --template option which can be used to specify an alternative template for generating the initial code.
Jeff Triplett actively maintains his own template for new projects, which includes the pattern that I personally prefer of keeping settings and URLs in a config/ folder. It also configures the development environment to run using Docker Compose.
The latest update adds support for Python 3.13, Django 5.1 and uv. It's neat how you can get started without even installing Django using uv run like this:
uv run --with=django django-admin startproject \
--extension=ini,py,toml,yaml,yml \
--template=https://github.com/jefftriplett/django-startproject/archive/main.zip \
example_project
Oct. 13, 2024
PostgreSQL 17: SQL/JSON is here! (via) Hubert Lubaczewski dives into the new JSON features added in PostgreSQL 17, released a few weeks ago on the 26th of September. This is the latest in his long series of similar posts about new PostgreSQL features.
The features are based on the new SQL:2023 standard from June 2023. If you want to actually read the specification for SQL:2023 it looks like you have to buy a PDF from ISO for 194 Swiss Francs (currently $226). Here's a handy summary by Peter Eisentraut: SQL:2023 is finished: Here is what's new.
There's a lot of neat stuff in here. I'm particularly interested in the json_table() table-valued function, which can convert a JSON string into a table with quite a lot of flexibility. You can even specify a full table schema as part of the function call:
SELECT * FROM json_table(
'[{"a":10,"b":20},{"a":30,"b":40}]'::jsonb,
'$[*]'
COLUMNS (
id FOR ORDINALITY,
column_a int4 path '$.a',
column_b int4 path '$.b',
a int4,
b int4,
c text
)
);SQLite has solid JSON support already and often imitates PostgreSQL features, so I wonder if we'll see an update to SQLite that reflects some aspects of this new syntax.
An LLM TDD loop (via) Super neat demo by David Winterbottom, who wrapped my LLM and files-to-prompt tools in a short Bash script that can be fed a file full of Python unit tests and an empty implementation file and will then iterate on that file in a loop until the tests pass.
Zero-latency SQLite storage in every Durable Object (via) Kenton Varda introduces the next iteration of Cloudflare's Durable Object platform, which recently upgraded from a key/value store to a full relational system based on SQLite.
For useful background on the first version of Durable Objects take a look at Cloudflare's durable multiplayer moat by Paul Butler, who digs into its popularity for building WebSocket-based realtime collaborative applications.
The new SQLite-backed Durable Objects is a fascinating piece of distributed system design, which advocates for a really interesting way to architect a large scale application.
The key idea behind Durable Objects is to colocate application logic with the data it operates on. A Durable Object comprises code that executes on the same physical host as the SQLite database that it uses, resulting in blazingly fast read and write performance.
How could this work at scale?
A single object is inherently limited in throughput since it runs on a single thread of a single machine. To handle more traffic, you create more objects. This is easiest when different objects can handle different logical units of state (like different documents, different users, or different "shards" of a database), where each unit of state has low enough traffic to be handled by a single object
Kenton presents the example of a flight booking system, where each flight can map to a dedicated Durable Object with its own SQLite database - thousands of fresh databases per airline per day.
Each DO has a unique name, and Cloudflare's network then handles routing requests to that object wherever it might live on their global network.
The technical details are fascinating. Inspired by Litestream, each DO constantly streams a sequence of WAL entries to object storage - batched every 16MB or every ten seconds. This also enables point-in-time recovery for up to 30 days through replaying those logged transactions.
To ensure durability within that ten second window, writes are also forwarded to five replicas in separate nearby data centers as soon as they commit, and the write is only acknowledged once three of them have confirmed it.
The JavaScript API design is interesting too: it's blocking rather than async, because the whole point of the design is to provide fast single threaded persistence operations:
let docs = sql.exec(`
SELECT title, authorId FROM documents
ORDER BY lastModified DESC
LIMIT 100
`).toArray();
for (let doc of docs) {
doc.authorName = sql.exec(
"SELECT name FROM users WHERE id = ?",
doc.authorId).one().name;
}This one of their examples deliberately exhibits the N+1 query pattern, because that's something SQLite is uniquely well suited to handling.
The system underlying Durable Objects is called Storage Relay Service, and it's been powering Cloudflare's existing-but-different D1 SQLite system for over a year.
I was curious as to where the objects are created. According to this (via Hacker News):
Durable Objects do not currently change locations after they are created. By default, a Durable Object is instantiated in a data center close to where the initial
get()request is made. [...] To manually create Durable Objects in another location, provide an optionallocationHintparameter toget().
And in a footnote:
Dynamic relocation of existing Durable Objects is planned for the future.
where.durableobjects.live is a neat site that tracks where in the Cloudflare network DOs are created - I just visited it and it said:
This page tracks where new Durable Objects are created; for example, when you loaded this page from Half Moon Bay, a worker in San Jose, California, United States (SJC) created a durable object in San Jose, California, United States (SJC).