64 posts tagged “training-data”
Data used to train LLMs and other machine learning models.
2024
SAM 2: The next generation of Meta Segment Anything Model for videos and images (via) Segment Anything is Meta AI's model for image segmentation: for any image or frame of video it can identify which shapes on the image represent different "objects" - things like vehicles, people, animals, tools and more.
SAM 2 "outperforms SAM on its 23 dataset zero-shot benchmark suite, while being six times faster". Notably, SAM 2 works with video where the original SAM only worked with still images. It's released under the Apache 2 license.
The best way to understand SAM 2 is to try it out. Meta have a web demo which worked for me in Chrome but not in Firefox. I uploaded a recent video of my brand new cactus tweezers (for removing detritus from my cacti without getting spiked) and selected the succulent and the tweezers as two different objects:
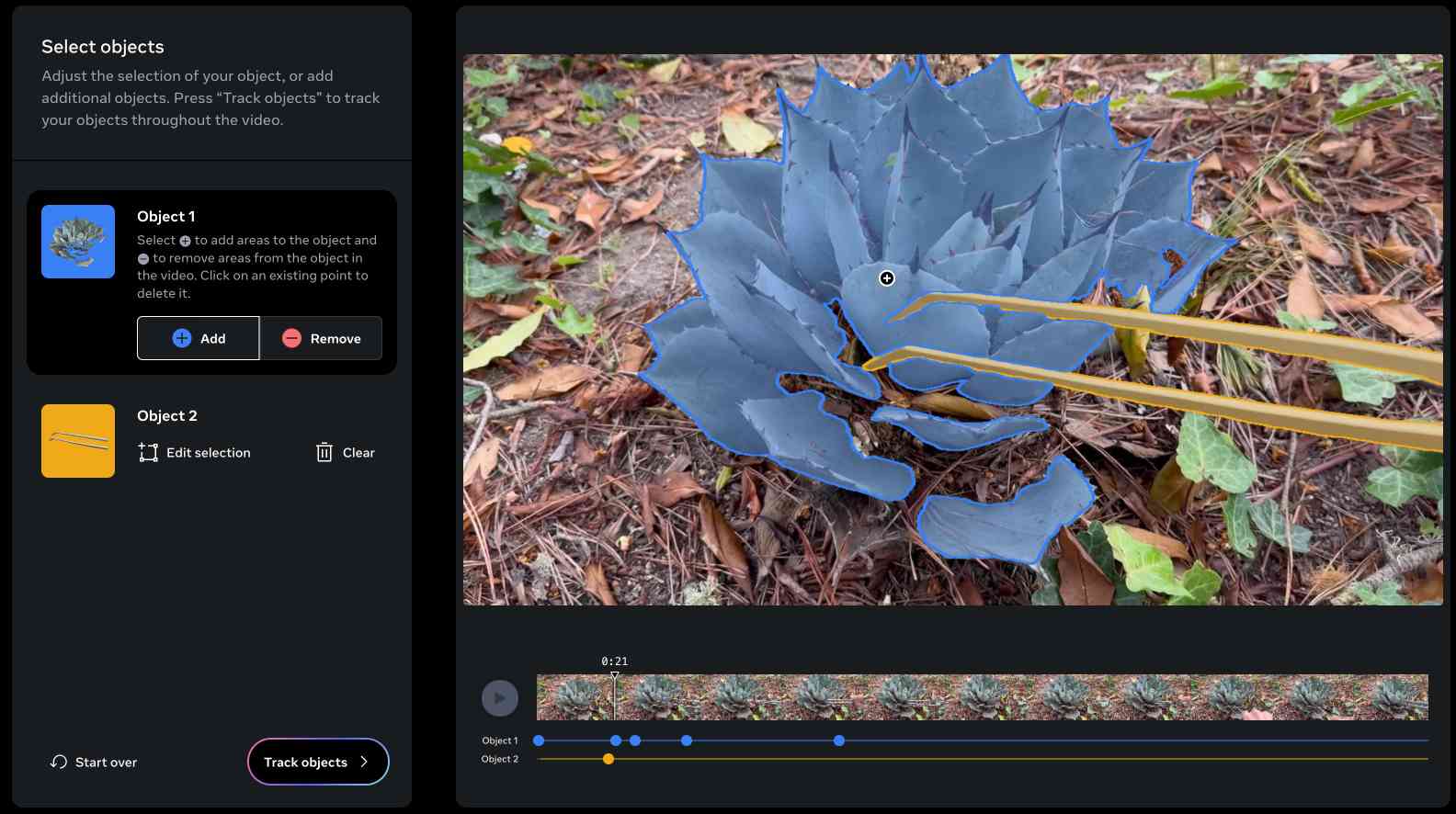
Then I applied a "desaturate" filter to the background and exported this resulting video, with the background converted to black and white while the succulent and tweezers remained in full colour:
Also released today: the full SAM 2 paper, the SA-V dataset of "51K diverse videos and 643K spatio-temporal segmentation masks" and a Dataset explorer tool (again, not supported by Firefox) for poking around in that collection.
The [Apple Foundation Model] pre-training dataset consists of a diverse and high quality data mixture. This includes data we have licensed from publishers, curated publicly-available or open-sourced datasets, and publicly available information crawled by our web-crawler, Applebot. We respect the right of webpages to opt out of being crawled by Applebot, using standard robots.txt directives.
Given our focus on protecting user privacy, we note that no private Apple user data is included in the data mixture. Additionally, extensive efforts have been made to exclude profanity, unsafe material, and personally identifiable information from publicly available data (see Section 7 for more details). Rigorous decontamination is also performed against many common evaluation benchmarks.
We find that data quality, much more so than quantity, is the key determining factor of downstream model performance.
The reason current models are so large is because we're still being very wasteful during training - we're asking them to memorize the internet and, remarkably, they do and can e.g. recite SHA hashes of common numbers, or recall really esoteric facts. (Actually LLMs are really good at memorization, qualitatively a lot better than humans, sometimes needing just a single update to remember a lot of detail for a long time). But imagine if you were going to be tested, closed book, on reciting arbitrary passages of the internet given the first few words. This is the standard (pre)training objective for models today. The reason doing better is hard is because demonstrations of thinking are "entangled" with knowledge, in the training data.
Therefore, the models have to first get larger before they can get smaller, because we need their (automated) help to refactor and mold the training data into ideal, synthetic formats.
It's a staircase of improvement - of one model helping to generate the training data for next, until we're left with "perfect training set". When you train GPT-2 on it, it will be a really strong / smart model by today's standards. Maybe the MMLU will be a bit lower because it won't remember all of its chemistry perfectly.
Apple, Nvidia, Anthropic Used Thousands of Swiped YouTube Videos to Train AI. This article has been getting a lot of attention over the past couple of days.
The story itself is nothing new: the Pile is four years old now, and has been widely used for training LLMs since before anyone even cared what an LLM was. It turns out one of the components of the Pile is a set of ~170,000 YouTube video captions (just the captions, not the actual video) and this story by Annie Gilbertson and Alex Reisner highlights that and interviews some of the creators who were included in the data, as well as providing a search tool for seeing if a specific creator has content that was included.
What's notable is the response. Marques Brownlee (19m subscribers) posted a video about it. Abigail Thorn (Philosophy Tube, 1.57m subscribers) tweeted this:
Very sad to have to say this - an AI company called EleutherAI stole tens of thousands of YouTube videos - including many of mine. I’m one of the creators Proof News spoke to. The stolen data was sold to Apple, Nvidia, and other companies to build AI
When I was told about this I lay on the floor and cried, it’s so violating, it made me want to quit writing forever. The reason I got back up was because I know my audience come to my show for real connection and ideas, not cheapfake AI garbage, and I know they’ll stay with me
Framing the data as "sold to Apple..." is a slight misrepresentation here - EleutherAI have been giving the Pile away for free since 2020. It's a good illustration of the emotional impact here though: many creative people do not want their work used in this way, especially without their permission.
It's interesting seeing how attitudes to this stuff change over time. Four years ago the fact that a bunch of academic researchers were sharing and training models using 170,000 YouTube subtitles would likely not have caught any attention at all. Today, people care!
Why The Atlantic signed a deal with OpenAI. Interesting conversation between Nilay Patel and The Atlantic CEO (and former journalist/editor) Nicholas Thompson about the relationship between media organizations and LLM companies like OpenAI.
On the impact of these deals on the ongoing New York Times lawsuit:
One of the ways that we [The Atlantic] can help the industry is by making deals and setting a market. I believe that us doing a deal with OpenAI makes it easier for us to make deals with the other large language model companies if those come about, I think it makes it easier for other journalistic companies to make deals with OpenAI and others, and I think it makes it more likely that The Times wins their lawsuit.
How could it help? Because deals like this establish a market value for training content, important for the fair use component of the legal argument.
Listen to the AI-generated ripoff songs that got Udio and Suno sued. Jason Koebler reports on the lawsuit filed today by the RIAA against Udio and Suno, the two leading generative music startups.
The lawsuit includes examples of prompts that the record labels used to recreate famous songs that were almost certainly included in the (undisclosed) training data. Jason collected some of these together into a three minute video, and the result in pretty damning. Arguing "fair use" isn't going to be easy here.
It is in the public good to have AI produce quality and credible (if ‘hallucinations’ can be overcome) output. It is in the public good that there be the creation of original quality, credible, and artistic content. It is not in the public good if quality, credible content is excluded from AI training and output OR if quality, credible content is not created.
One of the core constitutional principles that guides our AI model development is privacy. We do not train our generative models on user-submitted data unless a user gives us explicit permission to do so. To date we have not used any customer or user-submitted data to train our generative models.
Extracting Concepts from GPT-4. A few weeks ago Anthropic announced they had extracted millions of understandable features from their Claude 3 Sonnet model.
Today OpenAI are announcing a similar result against GPT-4:
We used new scalable methods to decompose GPT-4’s internal representations into 16 million oft-interpretable patterns.
These features are "patterns of activity that we hope are human interpretable". The release includes code and a paper, Scaling and evaluating sparse autoencoders paper (PDF) which credits nine authors, two of whom - Ilya Sutskever and Jan Leike - are high profile figures that left OpenAI within the past month.
The most fun part of this release is the interactive tool for exploring features. This highlights some interesting features on the homepage, or you can hit the "I'm feeling lucky" button to bounce to a random feature. The most interesting I've found so far is feature 5140 which seems to combine God's approval, telling your doctor about your prescriptions and information passed to the Admiralty.
This note shown on the explorer is interesting:
Only 65536 features available. Activations shown on The Pile (uncopyrighted) instead of our internal training dataset.
Here's the full Pile Uncopyrighted, which I hadn't seen before. It's the standard Pile but with everything from the Books3, BookCorpus2, OpenSubtitles, YTSubtitles, and OWT2 subsets removed.
Turns out that LLMs learn a lot better and faster from educational content as well. This is partly because the average Common Crawl article (internet pages) is not of very high value and distracts the training, packing in too much irrelevant information. The average webpage on the internet is so random and terrible it's not even clear how prior LLMs learn anything at all.
Training is not the same as chatting: ChatGPT and other LLMs don’t remember everything you say
I’m beginning to suspect that one of the most common misconceptions about LLMs such as ChatGPT involves how “training” works.
[... 1,543 words]I’ve been at OpenAI for almost a year now. In that time, I’ve trained a lot of generative models. [...] It’s becoming awfully clear to me that these models are truly approximating their datasets to an incredible degree. [...] What this manifests as is – trained on the same dataset for long enough, pretty much every model with enough weights and training time converges to the same point. [...] This is a surprising observation! It implies that model behavior is not determined by architecture, hyperparameters, or optimizer choices. It’s determined by your dataset, nothing else. Everything else is a means to an end in efficiently delivery compute to approximating that dataset.
openelm/README-pretraining.md. Apple released something big three hours ago, and I’m still trying to get my head around exactly what it is.
The parent project is called CoreNet, described as “A library for training deep neural networks”. Part of the release is a new LLM called OpenELM, which includes completely open source training code and a large number of published training checkpoint.
I’m linking here to the best documentation I’ve found of that training data: it looks like the bulk of it comes from RefinedWeb, RedPajama, The Pile and Dolma.
Releasing Common Corpus: the largest public domain dataset for training LLMs (via) Released today. 500 billion words from "a wide diversity of cultural heritage initiatives". 180 billion words of English, 110 billion of French, 30 billion of German, then Dutch, Spanish and Italian.
Includes quite a lot of US public domain data - 21 million digitized out-of-copyright newspapers (or do they mean newspaper articles?)
This is only an initial part of what we have collected so far, in part due to the lengthy process of copyright duration verification. In the following weeks and months, we’ll continue to publish many additional datasets also coming from other open sources, such as open data or open science.
Coordinated by French AI startup Pleias and supported by the French Ministry of Culture, among others.
I can't wait to try a model that's been trained on this.
For the last few years, Meta has had a team of attorneys dedicated to policing unauthorized forms of scraping and data collection on Meta platforms. The decision not to further pursue these claims seems as close to waving the white flag as you can get against these kinds of companies. But why? [...]
In short, I think Meta cares more about access to large volumes of data and AI than it does about outsiders scraping their public data now. My hunch is that they know that any success in anti-scraping cases can be thrown back at them in their own attempts to build AI training databases and LLMs. And they care more about the latter than the former.
Aya (via) “A global initiative led by Cohere For AI involving over 3,000 independent researchers across 119 countries. Aya is a state-of-art model and dataset, pushing the boundaries of multilingual AI for 101 languages through open science.”
Both the model and the training data are released under Apache 2. The training data looks particularly interesting: “513 million instances through templating and translating existing datasets across 114 languages”—suggesting the data is mostly automatically generated.
Open Language Models (OLMos) and the LLM landscape (via) OLMo is a newly released LLM from the Allen Institute for AI (AI2) currently available in 7b and 1b parameters (OLMo-65b is on the way) and trained on a fully openly published dataset called Dolma.
The model and code are Apache 2, while the data is under the “AI2 ImpACT license”.
From the benchmark scores shared here by Nathan Lambert it looks like this may be the highest performing model currently available that was built using a fully documented training set.
What’s in Dolma? It’s mainly Common Crawl, Wikipedia, Project Gutenberg and the Stack.
We believe that AI tools are at their best when they incorporate and represent the full diversity and breadth of human intelligence and experience. [...] Because copyright today covers virtually every sort of human expression– including blog posts, photographs, forum posts, scraps of software code, and government documents–it would be impossible to train today’s leading AI models without using copyrighted materials. Limiting training data to public domain books and drawings created more than a century ago might yield an interesting experiment, but would not provide AI systems that meet the needs of today’s citizens.
2023
The AI trust crisis
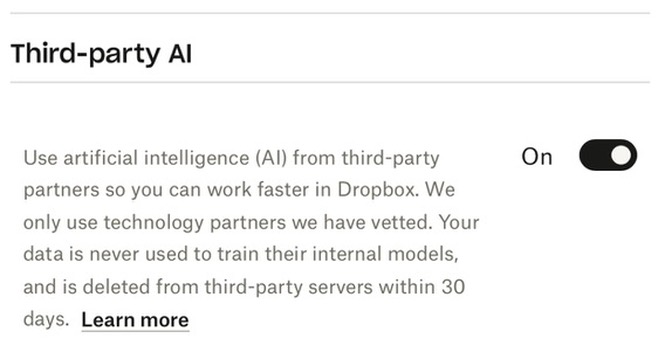
Dropbox added some new AI features. In the past couple of days these have attracted a firestorm of criticism. Benj Edwards rounds it up in Dropbox spooks users with new AI features that send data to OpenAI when used.
[... 1,733 words]I’ve resigned from my role leading the Audio team at Stability AI, because I don’t agree with the company’s opinion that training generative AI models on copyrighted works is ‘fair use’.
[...] I disagree because one of the factors affecting whether the act of copying is fair use, according to Congress, is “the effect of the use upon the potential market for or value of the copyrighted work”. Today’s generative AI models can clearly be used to create works that compete with the copyrighted works they are trained on. So I don’t see how using copyrighted works to train generative AI models of this nature can be considered fair use.
But setting aside the fair use argument for a moment — since ‘fair use’ wasn’t designed with generative AI in mind — training generative AI models in this way is, to me, wrong. Companies worth billions of dollars are, without permission, training generative AI models on creators’ works, which are then being used to create new content that in many cases can compete with the original works.
It’s infuriatingly hard to understand how closed models train on their input
One of the most common concerns I see about large language models regards their training data. People are worried that anything they say to ChatGPT could be memorized by it and spat out to other users. People are concerned that anything they store in a private repository on GitHub might be used as training data for future versions of Copilot.
[... 1,465 words]Introducing speech-to-text, text-to-speech, and more for 1,100+ languages (via) New from Meta AI: Massively Multilingual Speech. “MMS supports speech-to-text and text-to-speech for 1,107 languages and language identification for over 4,000 languages. [...] Some of these, such as the Tatuyo language, have only a few hundred speakers, and for most of these languages, no prior speech technology exists.”
It’s licensed CC-BY-NC 4.0 though, so it’s not available for commercial use.
“In a like-for-like comparison with OpenAI’s Whisper, we found that models trained on the Massively Multilingual Speech data achieve half the word error rate, but Massively Multilingual Speech covers 11 times more languages.”
The training data was mostly sourced from audio Bible translations.
Inside the secret list of websites that make AI chatbots sound smart. Washington Post story digging into the C4 dataset—Colossal Clean Crawled Corpus, a filtered version of Common Crawl that’s often used for training large language models. They include a neat interactive tool for searching a domain to see if it’s included—TIL that simonwillison.net is the 106,649th ranked site in C4 by number of tokens, 189,767 total—0.0001% of the total token volume in C4.
What’s in the RedPajama-Data-1T LLM training set
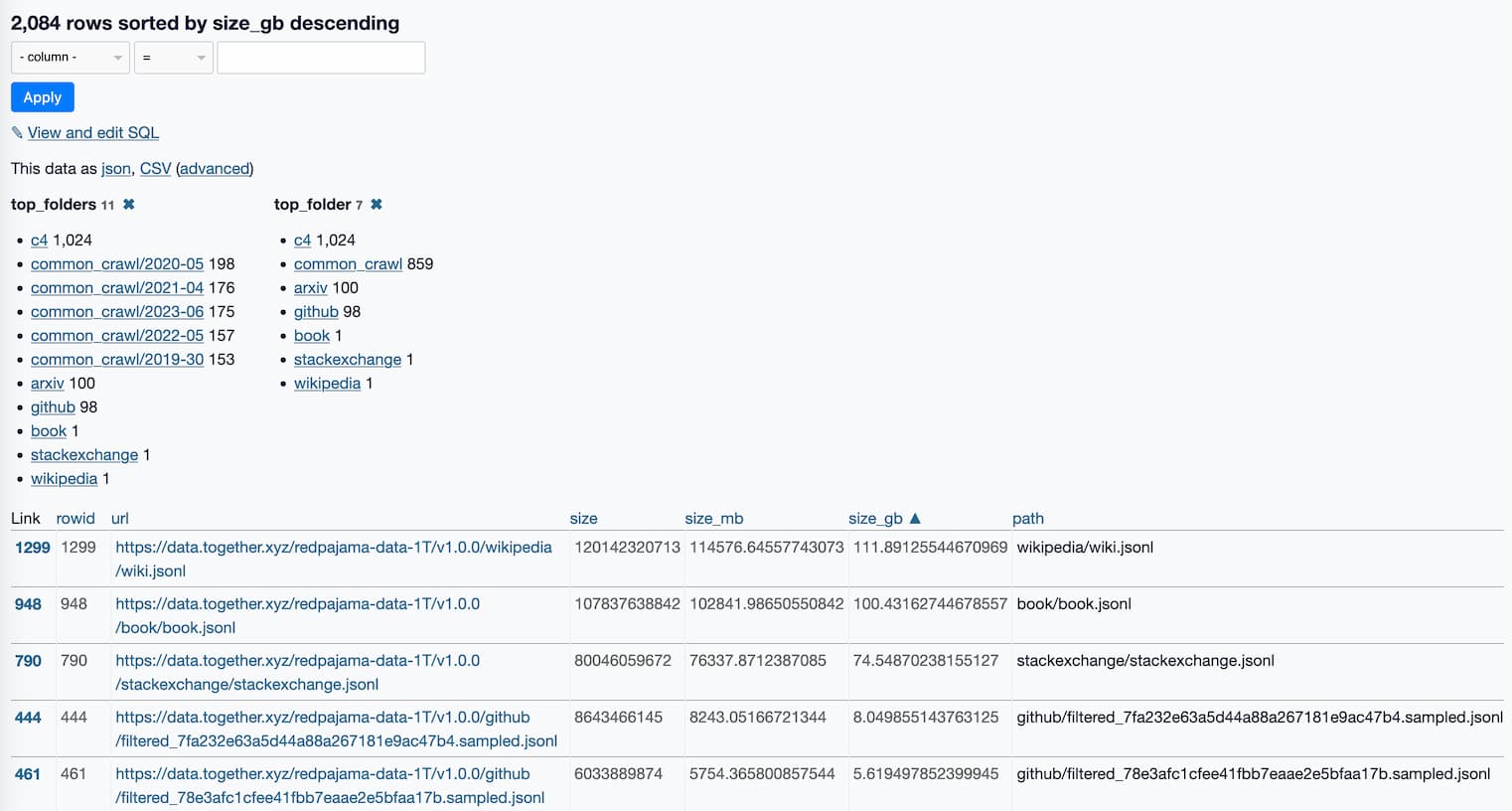
RedPajama is “a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens”. It’s a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute.
[... 1,077 words]RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens. With the amount of projects that have used LLaMA as a foundation model since its release two months ago—despite its non-commercial license—it’s clear that there is a strong desire for a fully openly licensed alternative.
RedPajama is a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute aiming to build exactly that.
Step one is gathering the training data: the LLaMA paper described a 1.2 trillion token training set gathered from sources that included Wikipedia, Common Crawl, GitHub, arXiv, Stack Exchange and more.
RedPajama-Data-1T is an attempt at recreating that training set. It’s now available to download, as 2,084 separate multi-GB jsonl files—2.67TB total.
Even without a trained model, this is a hugely influential contribution to the world of open source LLMs. Any team looking to build their own LLaMA from scratch can now jump straight to the next stage, training the model.
Replacing my best friends with an LLM trained on 500,000 group chat messages (via) Izzy Miller used a 7 year long group text conversation with five friends from college to fine-tune LLaMA, such that it could simulate ongoing conversations. They started by extracting the messages from the iMessage SQLite database on their Mac, then generated a new training set from those messages and ran it using code from the Stanford Alpaca repository. This is genuinely one of the clearest explanations of the process of fine-tuning a model like this I’ve seen anywhere.
ROOTS search tool (via) BLOOM is one of the most interesting completely openly licensed language models. The ROOTS corpus is the training data that was collected for it, and this tool lets you run searches directly against that corpus. I tried searching for my own name and got an interesting insight into what it knows about me.
mitsua-diffusion-one (via) “Mitsua Diffusion One is a latent text-to-image diffusion model, which is a successor of Mitsua Diffusion CC0. This model is trained from scratch using only public domain/CC0 or copyright images with permission for use.” I’ve been talking about how much I’d like to try out a “vegan” AI model trained entirely on out-of-copyright images for ages, and here one is! It looks like the training data mainly came from CC0 art gallery collections such as the Metropolitan Museum of Art Open Access.
Don’t trust AI to talk accurately about itself: Bard wasn’t trained on Gmail
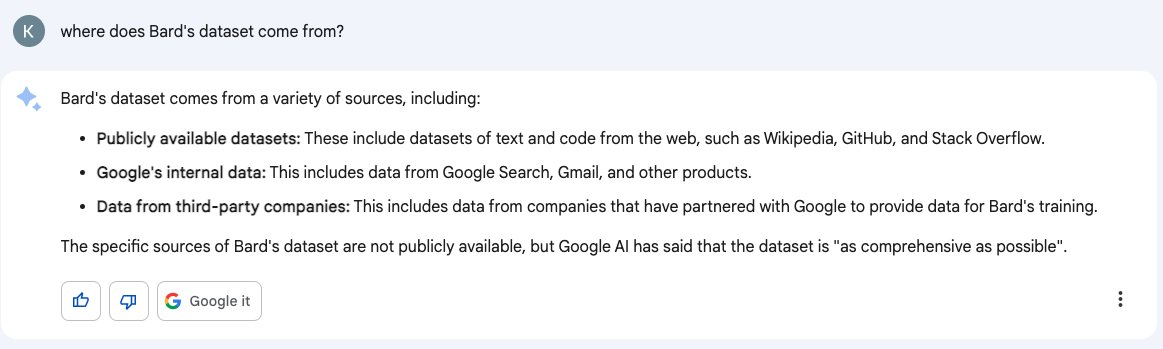
Earlier this month I wrote about how ChatGPT can’t access the internet, even though it really looks like it can. Consider this part two in the series. Here’s another common and non-intuitive mistake people make when interacting with large language model AI systems: asking them questions about themselves.
[... 1,950 words]Adobe made an AI image generator — and says it didn’t steal artists’ work to do it. Adobe Firefly is a brand new text-to-image model which Adobe claim was trained entirely on fully licensed imagery—either out of copyright, specially licensed or part of the existing Adobe Stock library. I’m sure they have the license, but I still wouldn’t be surprised to hear complaints from artists who licensed their content to Adobe Stock who didn’t anticipate it being used for model training.