The AI trust crisis
14th December 2023
Dropbox added some new AI features. In the past couple of days these have attracted a firestorm of criticism. Benj Edwards rounds it up in Dropbox spooks users with new AI features that send data to OpenAI when used.
The key issue here is that people are worried that their private files on Dropbox are being passed to OpenAI to use as training data for their models—a claim that is strenuously denied by Dropbox.
As far as I can tell, Dropbox built some sensible features—summarize on demand, “chat with your data” via Retrieval Augmented Generation—and did a moderately OK job of communicating how they work... but when it comes to data privacy and AI, a “moderately OK job” is a failing grade. Especially if you hold as much of people’s private data as Dropbox does!
Two details in particular seem really important. Dropbox have an AI principles document which includes this:
Customer trust and the privacy of their data are our foundation. We will not use customer data to train AI models without consent.
They also have a checkbox in their settings that looks like this:
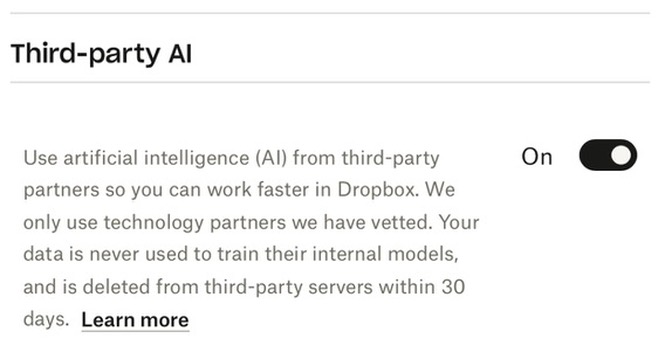
Update: Some time between me publishing this article and four hours later, that link stopped working.
I took that screenshot on my own account. It’s toggled “on”—but I never turned it on myself.
Does that mean I’m marked as “consenting” to having my data used to train AI models?
I don’t think so: I think this is a combination of confusing wording and the eternal vagueness of what the term “consent” means in a world where everyone agrees to the terms and conditions of everything without reading them.
But a LOT of people have come to the conclusion that this means their private data—which they pay Dropbox to protect—is now being funneled into the OpenAI training abyss.
People don’t believe OpenAI
Here’s copy from that Dropbox preference box, talking about their “third-party partners”—in this case OpenAI:
Your data is never used to train their internal models, and is deleted from third-party servers within 30 days.
It’s increasing clear to me like people simply don’t believe OpenAI when they’re told that data won’t be used for training.
What’s really going on here is something deeper then: AI is facing a crisis of trust.
I quipped on Twitter:
“OpenAI are training on every piece of data they see, even when they say they aren’t” is the new “Facebook are showing you ads based on overhearing everything you say through your phone’s microphone”
Here’s what I meant by that.
Facebook don’t spy on you through your microphone
Have you heard the one about Facebook spying on you through your phone’s microphone and showing you ads based on what you’re talking about?
This theory has been floating around for years. From a technical perspective it should be easy to disprove:
- Mobile phone operating systems don’t allow apps to invisibly access the microphone.
- Privacy researchers can audit communications between devices and Facebook to confirm if this is happening.
- Running high quality voice recognition like this at scale is extremely expensive—I had a conversation with a friend who works on server-based machine learning at Apple a few years ago who found the entire idea laughable.
The non-technical reasons are even stronger:
- Facebook say they aren’t doing this. The risk to their reputation if they are caught in a lie is astronomical.
- As with many conspiracy theories, too many people would have to be “in the loop” and not blow the whistle.
- Facebook don’t need to do this: there are much, much cheaper and more effective ways to target ads at you than spying through your microphone. These methods have been working incredibly well for years.
- Facebook gets to show us thousands of ads a year. 99% of those don’t correlate in the slightest to anything we have said out loud. If you keep rolling the dice long enough, eventually a coincidence will strike.
Here’s the thing though: none of these arguments matter.
If you’ve ever experienced Facebook showing you an ad for something that you were talking about out-loud about moments earlier, you’ve already dismissed everything I just said. You have personally experienced anecdotal evidence which overrides all of my arguments here.
Here’s a Reply All podcast episode from Novemember 2017 that explores this issue: 109 Is Facebook Spying on You?. Their conclusion: Facebook are not spying through your microphone. But if someone already believes that there is no argument that can possibly convince them otherwise.
I’ve experienced this effect myself—over the past few years I’ve tried talking people out of this, as part of my own personal fascination with how sticky this conspiracy theory is.
The key issue here is the same as the OpenAI training issue: people don’t believe these companies when they say that they aren’t doing something.
One interesting difference here is that in the Facebook example people have personal evidence that makes them believe they understand what’s going on.
With AI we have almost the complete opposite: AI models are weird black boxes, built in secret and with no way of understanding what the training data was or how it influences the model.
As with so much in AI, people are left with nothing more than “vibes” to go on. And the vibes are bad.
This really matters
Trust is really important. Companies lying about what they do with your privacy is a very serious allegation.
A society where big companies tell blatant lies about how they are handling our data—and get away with it without consequences—is a very unhealthy society.
A key role of government is to prevent this from happening. If OpenAI are training on data that they said they wouldn’t train on, or if Facebook are spying on us through our phone’s microphones, they should be hauled in front of regulators and/or sued into the ground.
If we believe that they are doing this without consequence, and have been getting away with it for years, our intolerance for corporate misbehavior becomes a victim as well. We risk letting companies get away with real misconduct because we incorrectly believed in conspiracy theories.
Privacy is important, and very easily misunderstood. People both overestimate and underestimate what companies are doing, and what’s possible. This isn’t helped by the fact that AI technology means the scope of what’s possible is changing at a rate that’s hard to appreciate even if you’re deeply aware of the space.
If we want to protect our privacy, we need to understand what’s going on. More importantly, we need to be able to trust companies to honestly and clearly explain what they are doing with our data.
On a personal level we risk losing out on useful tools. How many people cancelled their Dropbox accounts in the last 48 hours? How many more turned off that AI toggle, ruling out ever evaluating if those features were useful for them or not?
What can we do about it?
There is something that the big AI labs could be doing to help here: tell us how you are training!
The fundamental question here is about training data: what are OpenAI using to train their models?
And the answer is: we have no idea! The entire process could not be more opaque.
Given that, is it any wonder that when OpenAI say “we don’t train on data submitted via our API” people have trouble believing them?
The situation with ChatGPT itself is even more messy. OpenAI say that they DO use ChatGPT interactions to improve their models—even those from paying customers, with the exception of the “call us” priced ChatGPT Enterprise.
If I paste a private document into ChatGPT to ask for a summary, will snippets of that document be leaked to future users after the next model update? Without more details on HOW they are using ChatGPT to improve their models I can’t come close to answering that question.
Clear explanations of how this stuff works could go a long way to improving the trust relationship OpenAI have with their users, and the world at large.
Maybe take a leaf from large scale platform companies. They publish public post-mortem incident reports on outages, to regain trust with their customers through transparency about exactly what happened and the steps they are taking to prevent it from happening again. Dan Luu has collected a great list of examples.
An opportunity for local models
One consistent theme I’ve seen in conversations about this issue is that people are much more comfortable trusting their data to local models that run on their own devices than models hosted in the cloud.
The good news is that local models are consistently both increasing in quality and shrinking in size.
I figured out how to run Mixtral-8x7b-Instruct on my laptop last night—the first local model I’ve tried which really does seem to be equivalent in quality to ChatGPT 3.5.
Microsoft’s Phi-2 is a fascinating new model in that it’s only 2.7 billion parameters (most useful local models start at 7 billion) but claims state-of-the-art performance against some of those larger models. And it looks like they trained it for around $35,000.
While I’m excited about the potential of local models, I’d hate to see us lose out on the power and convenience of the larger hosted models over privacy concerns which turn out to be incorrect.
The intersection of AI and privacy is a critical issue. We need to be able to have the highest quality conversations about it, with maximum transparency and understanding of what’s actually going on.
This is hard already, and it’s made even harder if we straight up disbelieve anything that companies tell us. Those companies need to earn our trust. How can we help them understand how to do that?
More recent articles
- A Fireside Chat with Cat and Thariq from the Claude Code team - 21st July 2026
- Kimi K3, and what we can still learn from the pelican benchmark - 16th July 2026
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026