Wednesday, 15th November 2023
[On Meta's Galactica LLM launch] We did this with a 8 person team which is an order of magnitude fewer people than other LLM teams at the time.
We were overstretched and lost situational awareness at launch by releasing demo of a base model without checks. We were aware of what potential criticisms would be, but we lost sight of the obvious in the workload we were under.
One of the considerations for a demo was we wanted to understand the distribution of scientific queries that people would use for LLMs (useful for instruction tuning and RLHF). Obviously this was a free goal we gave to journalists who instead queried it outside its domain. But yes we should have known better.
We had a “good faith” assumption that we’d share the base model, warts and all, with four disclaimers about hallucinations on the demo - so people could see what it could do (openness). Again, obviously this didn’t work.
Exploring GPTs: ChatGPT in a trench coat?
The biggest announcement from last week’s OpenAI DevDay (and there were a LOT of announcements) was GPTs. Users of ChatGPT Plus can now create their own, custom GPT chat bots that other Plus subscribers can then talk to.
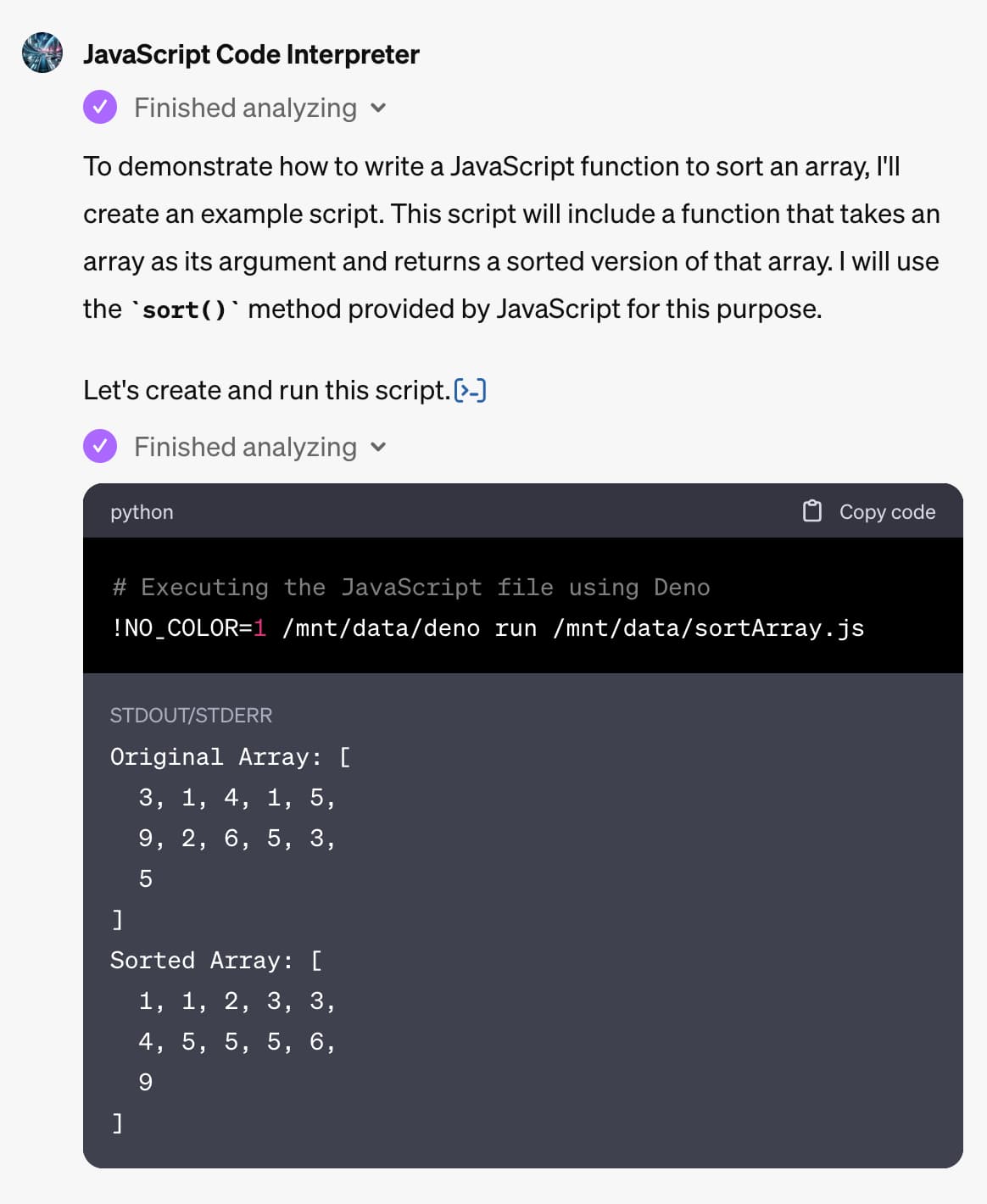
[... 5,699 words]I’ve resigned from my role leading the Audio team at Stability AI, because I don’t agree with the company’s opinion that training generative AI models on copyrighted works is ‘fair use’.
[...] I disagree because one of the factors affecting whether the act of copying is fair use, according to Congress, is “the effect of the use upon the potential market for or value of the copyrighted work”. Today’s generative AI models can clearly be used to create works that compete with the copyrighted works they are trained on. So I don’t see how using copyrighted works to train generative AI models of this nature can be considered fair use.
But setting aside the fair use argument for a moment — since ‘fair use’ wasn’t designed with generative AI in mind — training generative AI models in this way is, to me, wrong. Companies worth billions of dollars are, without permission, training generative AI models on creators’ works, which are then being used to create new content that in many cases can compete with the original works.
Fleet Context. This project took the source code and documentation for 1221 popular Python libraries and ran them through the OpenAI text-embedding-ada-002 embedding model, then made those pre-calculated embedding vectors available as Parquet files for download from S3 or via a custom Python CLI tool.
I haven’t seen many projects release pre-calculated embeddings like this, it’s an interesting initiative.