1,261 posts tagged “python”
The Python programming language.
2023
Python Sandbox in Web Assembly (via) Jim Kring responded to my questions on Mastodon about running Python in a WASM sandbox by building this repo, which demonstrates using wasmer-python to run a build of Python 3.6 compiled to WebAssembly, complete with protected access to a sandbox directory.
Mapping Python to LLVM (via) Codon is a fascinating new entry in the “compile Python code to something else” world—this time targeting LLVM. Ariya Shajii describes in great detail how it pulls this off, including tricks such as transforming Python generators to LLVM coroutines. Codon doesn’t promise that all Python code will work—it’s best thought of as a Python-like language which can be used to create compiled modules which can then be imported back into regular Python projects.
nanoGPT. “The simplest, fastest repository for training/finetuning medium-sized GPTs”—by Andrej Karpathy, in about 600 lines of Python.
2022
Boring Python: code quality. James Bennett provides an opinionated guide to setting up Python tools for linting, code formatting and and other code quality concerns. Of particular interest to me is his section on packaging checks, which introduces a whole bunch of new-to-me tools that can help avoid accidentally shipping broken packages to PyPI.
PyScript Updates: Bytecode Alliance, Pyodide, and MicroPython. Absolutely huge news about Python on the Web tucked into this announcement: Anaconda have managed to get a version of MicroPython compiled to WebAssembly running in the browser. Pyodide weighs in at around 6.5MB compressed, but the MicroPython build is just 303KB—the size of a large image. This makes Python in the web browser applicable to so many more potential areas.
Chris Amico’s Python setup for 2022 (via) Homebrew to install pyenv, then pyenv to install specific Python versions. pipx and pipenv for package management. I need to habitually start using pyenv for everything.
How to create a Python package in 2022 (via) Fantastic tutorial on modern Python packaging by Rodrigo Girão Serrão. I’ve been meaning to figure out Poetry for a while now and this gave me exactly the information I needed to start figuring it out. Great coverage of GitHub Actions, Tox and pre-commit as well.
py2rs. Extremely useful document providing resources for learning Rust followed by an extensive collection of common Python tasks (building a list, opening a file, spawning a thread, running a simple web server) and their Rust equivalents.
PEP 554 – Multiple Interpreters in the Stdlib: Shared data (via) Python 3.12 hopes to introduce multiple interpreters as part of the Python standard library, so Python code will be able to launch subinterpreters, each with their own independent GIL. This will allow Python code to execute on multiple CPU cores at the same time while ensuring existing code (and C modules) that rely on the GIL continue to work.
The obvious question here is how data will be shared between those interpreters. This PEP proposes a channels mechanism, where channels can be used to send just basic Python types between interpreters: None, bytes, str, int and channels themselves (I wonder why not floats?)
Deploying Python web apps as AWS Lambda functions. After literally years of failed half-hearted attempts, I finally managed to deploy an ASGI Python web application (Datasette) to an AWS Lambda function! Here are my extensive notes.
APSW is now available on PyPI. News I missed from June: the venerable (17+ years old) APSW SQLite library for Python is now officially available on PyPI as a set of wheels, built using cibuildwheel. This is a really big deal: APSW is an extremely well maintained library which exposes way more low-level SQLite functionality than the standard library’s sqlite3 module, and to-date one of the only disadvantages of using it was the need to install it independently of PyPI. Now you can just run “pip install apsw”.
TIL: You Can Build Portable Binaries of Python Applications (via) Hynek Schlawack on the brilliant PyOxidizer by Gregory Szorc.
Should You Use Upper Bound Version Constraints?
(via)
Should you pin your library's dependencies using "click>=7,<8" or "click~=7.0"? Henry Schreiner's short answer is no, and his long answer is an exhaustive essay covering every conceivable aspect of this thorny Python packaging problem.
storysniffer (via) Ben Welsh built a small Python library that guesses if a URL points to an article on a news website, or if it’s more likely to be a category page or /about page or similar. I really like this as an example of what you can do with a tiny machine learning model: the model is bundled as a ~3MB pickle file as part of the package, and the repository includes the Jupyter notebook that was used to train it.
Weeknotes: Joining the board of the Python Software Foundation
A few weeks ago I was elected to the board of directors for the Python Software Foundation.
[... 2,081 words]Packaging Python Projects with pyproject.toml. I decided to finally figure out how packaging with pyproject.toml works—all of my existing projects use setup.py. The official tutorial from the Python Packaging Authority (PyPA) had everything I needed.
Fastest way to turn HTML into text in Python (via) A light benchmark of the new-to-me selectolax Python library shows it performing extremely well for tasks such as extracting just the text from an HTML string, after first manipulating the DOM. selectolax is a Python binding over the Modest and Lexbor HTML parsing engines, which are written in no-outside-dependency C.
Cosmopolitan: Compiling Python. Cosmopolitan is Justine Tunney’s “build-once run-anywhere C library”—part of the αcτµαlly pδrταblε εxεcµταblε effort, which produces wildly clever binary executable files that work on multiple different platforms, and is the secret sauce behind redbean. I hadn’t realized this was happening but there’s an active project to get Python to work as this format, producing a new way of running Python applications as standalone executables, only these ones have the potential to run unmodified on Windows, Linux and macOS.
Announcing Pyston-lite: our Python JIT as an extension module (via) The Pyston JIT can now be installed in any Python 3.8 virtual environment by running “pip install pyston_lite_autoload”—which includes a hook to automatically inject the JIT. I just tried a very rough benchmark against Datasette (ab -n 1000 -c 10) and got 391.20 requests/second without the JIT compared to 404.10 request/second with it.
Compiling Black with mypyc (via) Richard Si is a Black contributor who recently obtained a 2x performance boost by compiling Black using the mypyc tool from the mypy project, which uses Python type annotations to generate a compiled C version of the Python logic. He wrote up this fantastic three-part series describing in detail how he achieved this, including plenty of tips on Python profiling and clever optimization tricks.
Benjamin “Zags” Zagorsky: Handling Timezones in Python. The talks from PyCon US have started appearing on YouTube. I found this one really useful for shoring up my Python timezone knowledge: It reminds that if your code calls datetime.now(), datetime.utcnow() or date.today(), you have timezone bugs—you’ve been working with ambiguous representations of instances in time that could span a 26 hour interval from UTC-12 to UTC+14. date.today() represents a 24 hour period and hence is prone to timezone surprises as well. My code has a lot of timezone bugs!
Bundling binary tools in Python wheels
I spotted a new (to me) pattern which I think is pretty interesting: projects are bundling compiled binary applications as part of their Python packaging wheels. I think it’s really neat.
[... 903 words]Weeknotes: Datasette Lite, nogil Python, HYTRADBOI
My big project this week was Datasette Lite, a new way to run Datasette directly in a browser, powered by WebAssembly and Pyodide. I also continued my research into running SQL queries in parallel, described last week. Plus I spoke at HYTRADBOI.
[... 1,434 words]Datasette Lite: a server-side Python web application running in a browser
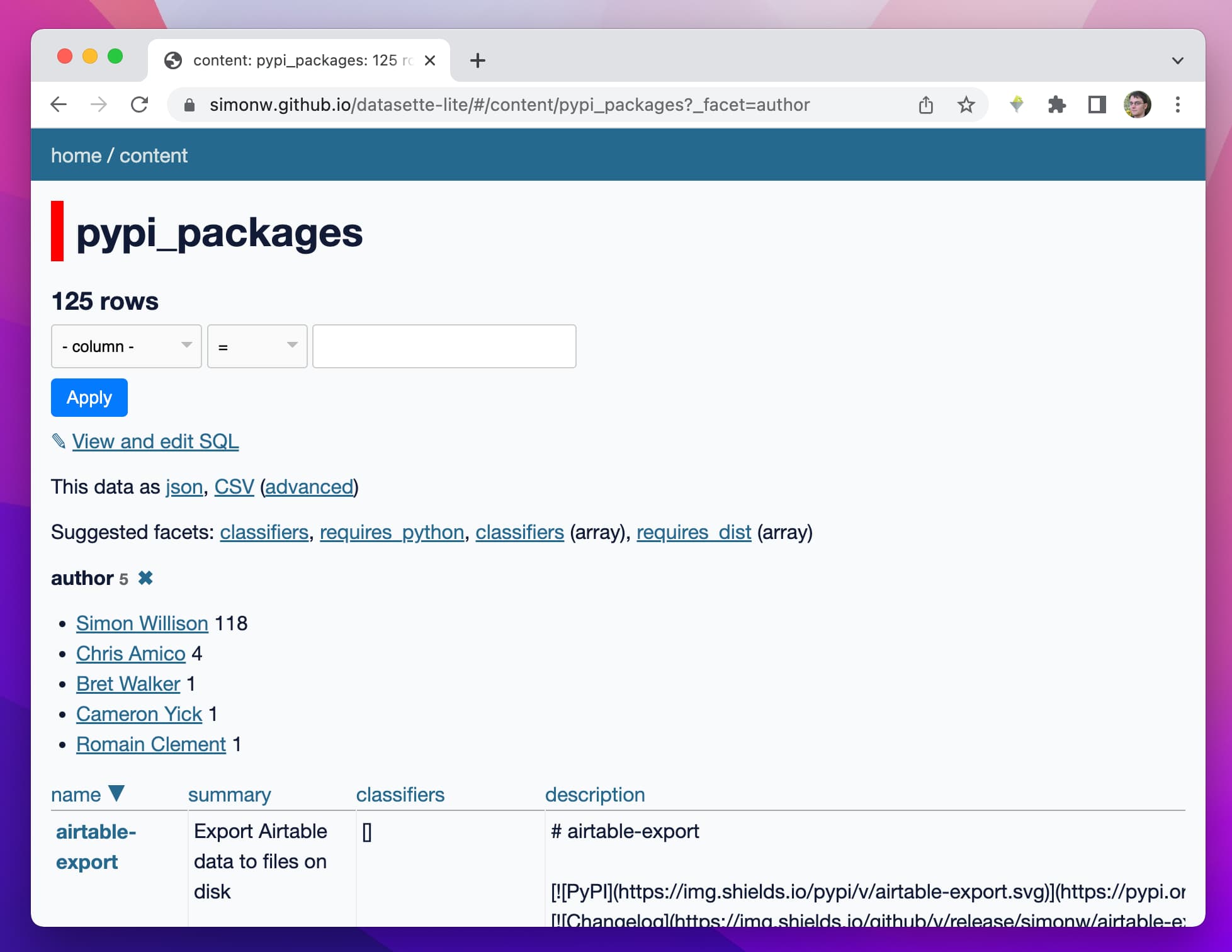
Datasette Lite is a new way to run Datasette: entirely in a browser, taking advantage of the incredible Pyodide project which provides Python compiled to WebAssembly plus a whole suite of useful extras.
[... 4,800 words]sqlite-utils 3.26.1 (via) I released sqlite-utils 3.36.1 with one tiny but exciting feature: I fixed its one dependency that wasn’t published as a pure Python wheel, which means it can now be used with Pyodide—Python compiled to WebAssembly running in your browser!
PyScript demos (via) PyScript was announced at PyCon this morning. It’s a new open source project that provides Web Components built on top of Pyodide, allowing you to use Python directly within your HTML pages in a way that is executed using a WebAssembly copy of Python running in your browser. These demos really help illustrate what it can do—it’s a fascinating new piece of the Python web ecosystem.
Testing Datasette parallel SQL queries in the nogil/python fork. As part of my ongoing research into whether Datasette can be sped up by running SQL queries in parallel I’ve been growing increasingly suspicious that the GIL is holding me back. I know the sqlite3 module releases the GIL and was hoping that would give me parallel queries, but it looks like there’s still a ton of work going on in Python GIL land creating Python objects representing the results of the query.
Sam Gross has been working on a nogil fork of Python and I decided to give it a go. It’s published as a Docker image and it turns out trying it out really did just take a few commands... and it produced the desired results, my parallel code started beating my serial code where previously the two had produced effectively the same performance numbers.
I’m pretty stunned by this. I had no idea how far along the nogil fork was. It’s amazing to see it in action.
Automatically opening issues when tracked file content changes
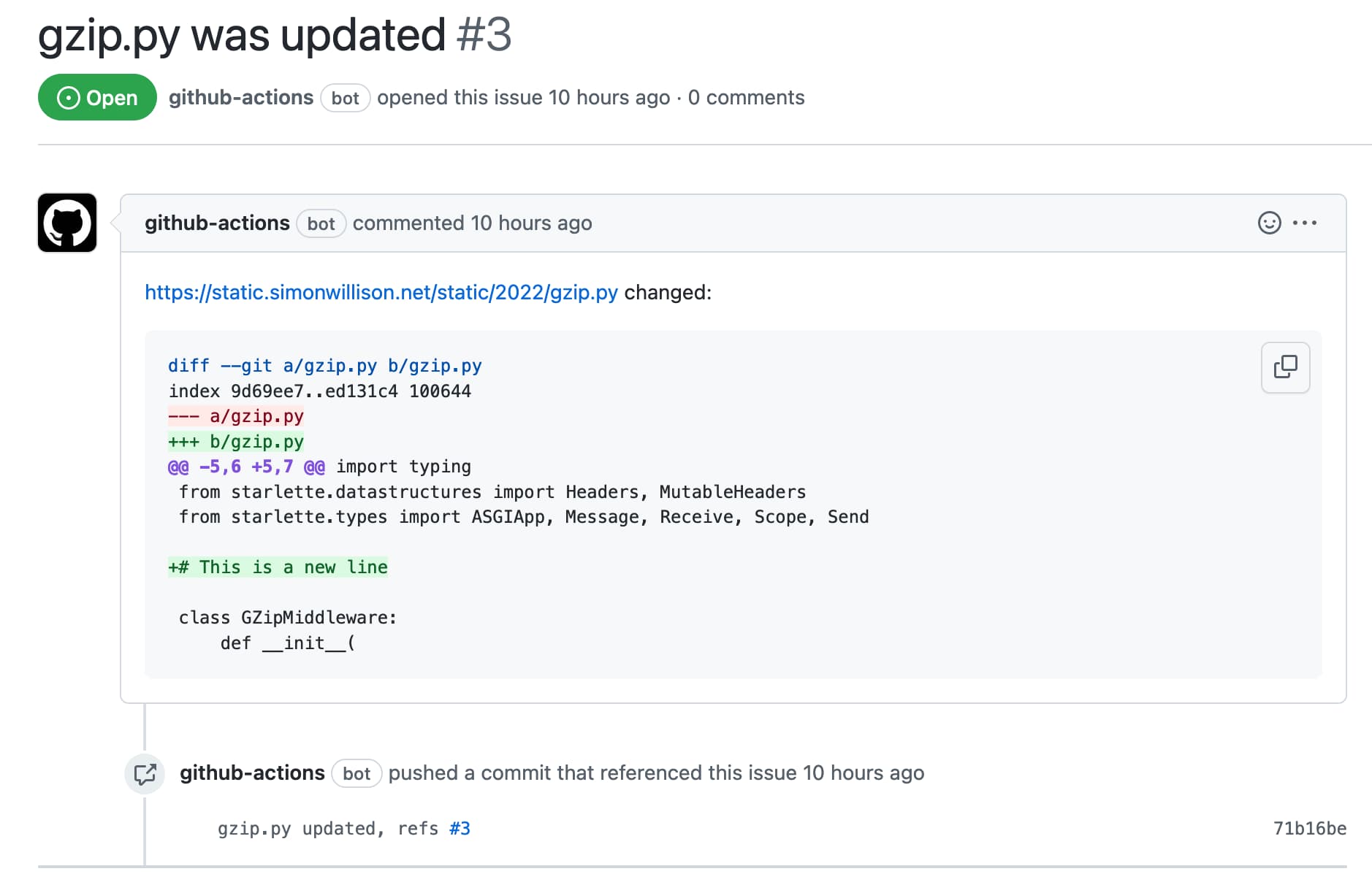
I figured out a GitHub Actions pattern to keep track of a file published somewhere on the internet and automatically open a new repository issue any time the contents of that file changes.
[... 1,211 words]Weeknotes: Parallel SQL queries for Datasette, plus some middleware tricks
A promising new performance optimization for Datasette, plus new datasette-gzip and datasette-total-page-time plugins.
Useful tricks with pip install URL and GitHub
The pip install command can accept a URL to a zip file or tarball. GitHub provides URLs that can create a zip file of any branch, tag or commit in any repository. Combining these is a really useful trick for maintaining Python packages.