546 posts tagged “projects”
Posts about projects I have worked on.
2025
I had some notes in a GitHub issue thread in a private repository that I wanted to export as Markdown. I realized that I could get them using a combination of several recent projects.
Here's what I ran:
export GITHUB_TOKEN="$(llm keys get github)"
llm -f issue:https://github.com/simonw/todos/issues/170 \
-m echo --no-log | jq .prompt -r > notes.md
I have a GitHub personal access token stored in my LLM keys, for use with Anthony Shaw's llm-github-models plugin.
My own llm-fragments-github plugin expects an optional GITHUB_TOKEN environment variable, so I set that first - here's an issue to have it use the github key instead.
With that set, the issue: fragment loader can take a URL to a private GitHub issue thread and load it via the API using the token, then concatenate the comments together as Markdown. Here's the code for that.
Fragments are meant to be used as input to LLMs. I built a llm-echo plugin recently which adds a fake LLM called "echo" which simply echos its input back out again.
Adding --no-log prevents that junk data from being stored in my LLM log database.
The output is JSON with a "prompt" key for the original prompt. I use jq .prompt to extract that out, then -r to get it as raw text (not a "JSON string").
... and I write the result to notes.md.
sqlite-utils 4.0a0. New alpha release of sqlite-utils, my Python library and CLI tool for manipulating SQLite databases.
It's the first 4.0 alpha because there's a (minor) backwards-incompatible change: I've upgraded the .upsert() and .upsert_all() methods to use SQLIte's UPSERT mechanism, INSERT INTO ... ON CONFLICT DO UPDATE. Details in this issue.
That feature was added to SQLite in version 3.24.0, released 2018-06-04. I'm pretty cautious about my SQLite version support since the underlying library can be difficult to upgrade, depending on your platform and operating system.
I'm going to leave the new alpha to bake for a little while before pushing a stable release. Since this is a major version bump I'm going to take the opportunity to see if there are any other minor API warts that I can clean up at the same time.
llm-prices.com.
I've been maintaining a simple LLM pricing calculator since October last year. I finally decided to split it out to its own domain name (previously it was hosted at tools.simonwillison.net/llm-prices), running on Cloudflare Pages.
The site runs out of my simonw/llm-prices GitHub repository. I ported the history of the old llm-prices.html file using a vibe-coded bash script that I forgot to save anywhere.
I rarely use AI-generated imagery in my own projects, but for this one I found an excellent reason to use GPT-4o image outputs... to generate the favicon! I dropped a screenshot of the site into ChatGPT (o4-mini-high in this case) and asked for the following:
design a bunch of options for favicons for this site in a single image, white background

I liked the top right one, so I cropped it into Pixelmator and made a 32x32 version. Here's what it looks like in my browser:
I added a new feature just now: the state of the calculator is now reflected in the #fragment-hash URL of the page, which means you can link to your previous calculations.
I implemented that feature using the new gemini-2.5-pro-preview-05-06, since that model boasts improved front-end coding abilities. It did a pretty great job - here's how I prompted it:
llm -m gemini-2.5-pro-preview-05-06 -f https://www.llm-prices.com/ -s 'modify this code so that the state of the page is reflected in the fragmenth hash URL - I want to capture the values filling out the form fields and also the current sort order of the table. These should be respected when the page first loads too. Update them using replaceHistory, no need to enable the back button.'
Here's the transcript and the commit updating the tool, plus an example link showing the new feature in action (and calculating the cost for that Gemini 2.5 Pro prompt at 16.8224 cents, after fixing the calculation.)
Feed a video to a vision LLM as a sequence of JPEG frames on the CLI (also LLM 0.25)

The new llm-video-frames plugin can turn a video file into a sequence of JPEG frames and feed them directly into a long context vision LLM such as GPT-4.1, even when that LLM doesn’t directly support video input. It depends on a plugin feature I added to LLM 0.25, which I released last night.
[... 1,600 words]Introducing Datasette for Newsrooms. We're introducing a new product suite today called Datasette for Newsrooms - a bundled collection of Datasette Cloud features built specifically for investigative journalists and data teams. We're describing it as an all-in-one data store, search engine, and collaboration platform designed to make working with data in a newsroom easier, faster, and more transparent.
If your newsroom could benefit from a managed version of Datasette we would love to hear from you. We're offering it to nonprofit newsrooms for free for the first year (they can pay us in feedback), and we have a two month trial for everyone else.
Get in touch at hello@datasette.cloud if you'd like to try it out.
One crucial detail: we will help you get started - we'll load data into your instance for you (you get some free data engineering!) and walk you through how to use it, and we will eagerly consume any feedback you have for us and prioritize shipping anything that helps you use the tool. Our unofficial goal: we want someone to win a Pulitzer for investigative reporting where our tool played a tiny part in their reporting process.
Here's an animated GIF demo (taken from our new Newsrooms landing page) of my favorite recent feature: the ability to extract structured data into a table starting with an unstructured PDF, using the latest version of the datasette-extract plugin.

llm-fragment-symbex. I released a new LLM fragment loader plugin that builds on top of my Symbex project.
Symbex is a CLI tool I wrote that can run against a folder full of Python code and output functions, classes, methods or just their docstrings and signatures, using the Python AST module to parse the code.
llm-fragments-symbex brings that ability directly to LLM. It lets you do things like this:
llm install llm-fragments-symbex
llm -f symbex:path/to/project -s 'Describe this codebase'
I just ran that against my LLM project itself like this:
cd llm
llm -f symbex:. -s 'guess what this code does'
Here's the full output, which starts like this:
This code listing appears to be an index or dump of Python functions, classes, and methods primarily belonging to a codebase related to large language models (LLMs). It covers a broad functionality set related to managing LLMs, embeddings, templates, plugins, logging, and command-line interface (CLI) utilities for interaction with language models. [...]
That page also shows the input generated by the fragment - here's a representative extract:
# from llm.cli import resolve_attachment def resolve_attachment(value): """Resolve an attachment from a string value which could be: - "-" for stdin - A URL - A file path Returns an Attachment object. Raises AttachmentError if the attachment cannot be resolved.""" # from llm.cli import AttachmentType class AttachmentType: def convert(self, value, param, ctx): # from llm.cli import resolve_attachment_with_type def resolve_attachment_with_type(value: str, mimetype: str) -> Attachment:
If your Python code has good docstrings and type annotations, this should hopefully be a shortcut for providing full API documentation to a model without needing to dump in the entire codebase.
The above example used 13,471 input tokens and 781 output tokens, using openai/gpt-4.1-mini. That model is extremely cheap, so the total cost was 0.6638 cents - less than a cent.
The plugin itself was mostly written by o4-mini using the llm-fragments-github plugin to load the simonw/symbex and simonw/llm-hacker-news repositories as example code:
llm \ -f github:simonw/symbex \ -f github:simonw/llm-hacker-news \ -s "Write a new plugin as a single llm_fragments_symbex.py file which provides a custom loader which can be used like this: llm -f symbex:path/to/folder - it then loads in all of the python function signatures with their docstrings from that folder using the same trick that symbex uses, effectively the same as running symbex . '*' '*.*' --docs --imports -n" \ -m openai/o4-mini -o reasoning_effort high
Here's the response. 27,819 input, 2,918 output = 4.344 cents.
In working on this project I identified and fixed a minor cosmetic defect in Symbex itself. Technically this is a breaking change (it changes the output) so I shipped that as Symbex 2.0.
llm-hacker-news. I built this new plugin to exercise the new register_fragment_loaders() plugin hook I added to LLM 0.24. It's the plugin equivalent of the Bash script I've been using to summarize Hacker News conversations for the past 18 months.
You can use it like this:
llm install llm-hacker-news
llm -f hn:43615912 'summary with illustrative direct quotes'
You can see the output in this issue.
The plugin registers a hn: prefix - combine that with the ID of a Hacker News conversation to pull that conversation into the context.
It uses the Algolia Hacker News API which returns JSON like this. Rather than feed the JSON directly to the LLM it instead converts it to a hopefully more LLM-friendly format that looks like this example from the plugin's test:
[1] BeakMaster: Fish Spotting Techniques
[1.1] CoastalFlyer: The dive technique works best when hunting in shallow waters.
[1.1.1] PouchBill: Agreed. Have you tried the hover method near the pier?
[1.1.2] WingSpan22: My bill gets too wet with that approach.
[1.1.2.1] CoastalFlyer: Try tilting at a 40° angle like our Australian cousins.
[1.2] BrownFeathers: Anyone spotted those "silver fish" near the rocks?
[1.2.1] GulfGlider: Yes! They're best caught at dawn.
Just remember: swoop > grab > lift
That format was suggested by Claude, which then wrote most of the plugin implementation for me. Here's that Claude transcript.
Long context support in LLM 0.24 using fragments and template plugins
LLM 0.24 is now available with new features to help take advantage of the increasingly long input context supported by modern LLMs.
[... 1,896 words]I've added a new content type to my blog: notes. These join my existing types: entries, bookmarks and quotations.
A note is a little bit like a bookmark without a link. They're for short form writing - thoughts or images that don't warrant a full entry with a title. The kind of things I used to post to Twitter, but that don't feel right to cross-post to multiple social networks (Mastodon and Bluesky, for example.)
I was partly inspired by Molly White's short thoughts, notes, links, and musings.
I've been thinking about this for a while, but the amount of work involved in modifying all of the parts of my site that handle the three different content types was daunting. Then this evening I tried running my blog's source code (using files-to-prompt and LLM) through the new Gemini 2.5 Pro:
files-to-prompt . -e py -c | \
llm -m gemini-2.5-pro-exp-03-25 -s \
'I want to add a new type of content called a Note,
similar to quotation and bookmark and entry but it
only has a markdown text body. Output all of the
code I need to add for that feature and tell me
which files to add the code to.'Gemini gave me a detailed 13 step plan covering all of the tedious changes I'd been avoiding having to figure out!
The code is in this PR, which touched 18 different files. The whole project took around 45 minutes start to finish.
(I used Claude to brainstorm names for the feature - I had it come up with possible nouns and then "rank those by least pretentious to most pretentious", and "notes" came out on top.)
This is now far too long for a note and should really be upgraded to an entry, but I need to post a first note to make sure everything is working as it should.
shot-scraper 1.8. I've added a new feature to shot-scraper that makes it easier to share scripts for other people to use with the shot-scraper javascript command.
shot-scraper javascript lets you load up a web page in an invisible Chrome browser (via Playwright), execute some JavaScript against that page and output the results to your terminal. It's a fun way of running complex screen-scraping routines as part of a terminal session, or even chained together with other commands using pipes.
The -i/--input option lets you load that JavaScript from a file on disk - but now you can also use a gh: prefix to specify loading code from GitHub instead.
To quote the release notes:
shot-scraper javascriptcan now optionally load scripts hosted on GitHub via the newgh:prefix to theshot-scraper javascript -i/--inputoption. #173Scripts can be referenced as
gh:username/repo/path/to/script.jsor, if the GitHub user has created a dedicatedshot-scraper-scriptsrepository and placed scripts in the root of it, usinggh:username/name-of-script.For example, to run this readability.js script against any web page you can use the following:
shot-scraper javascript --input gh:simonw/readability \ https://simonwillison.net/2025/Mar/24/qwen25-vl-32b/
The output from that example starts like this:
{
"title": "Qwen2.5-VL-32B: Smarter and Lighter",
"byline": "Simon Willison",
"dir": null,
"lang": "en-gb",
"content": "<div id=\"readability-page-1\"...My simonw/shot-scraper-scripts repo only has that one file in it so far, but I'm looking forward to growing that collection and hopefully seeing other people create and share their own shot-scraper-scripts repos as well.
This feature is an imitation of a similar feature that's coming in the next release of LLM.
simonw/ollama-models-atom-feed. I setup a GitHub Actions + GitHub Pages Atom feed of scraped recent models data from the Ollama latest models page - Ollama remains one of the easiest ways to run models on a laptop so a new model release from them is worth hearing about.
I built the scraper by pasting example HTML into Claude and asking for a Python script to convert it to Atom - here's the script we wrote together.
Update 25th March 2025: The first version of this included all 160+ models in a single feed. I've upgraded the script to output two feeds - the original atom.xml one and a new atom-recent-20.xml feed containing just the most recent 20 items.
I modified the script using Google's new Gemini 2.5 Pro model, like this:
cat to_atom.py | llm -m gemini-2.5-pro-exp-03-25 \
-s 'rewrite this script so that instead of outputting Atom to stdout it saves two files, one called atom.xml with everything and another called atom-recent-20.xml with just the most recent 20 items - remove the output option entirely'
Here's the full transcript.
Adding AI-generated descriptions to my tools collection

The /colophon page on my tools.simonwillison.net site lists all 78 of the HTML+JavaScript tools I’ve built (with AI assistance) along with their commit histories, including links to prompting transcripts. I wrote about how I built that colophon the other day. It now also includes a description of each tool, generated using Claude 3.7 Sonnet.
[... 741 words]llm-openrouter 0.4. I found out this morning that OpenRouter include support for a number of (rate-limited) free API models.
I occasionally run workshops on top of LLMs (like this one) and being able to provide students with a quick way to obtain an API key against models where they don't have to setup billing is really valuable to me!
This inspired me to upgrade my existing llm-openrouter plugin, and in doing so I closed out a bunch of open feature requests.
Consider this post the annotated release notes:
- LLM schema support for OpenRouter models that support structured output. #23
I'm trying to get support for LLM's new schema feature into as many plugins as possible.
OpenRouter's OpenAI-compatible API includes support for the response_format structured content option, but with an important caveat: it only works for some models, and if you try to use it on others it is silently ignored.
I filed an issue with OpenRouter requesting they include schema support in their machine-readable model index. For the moment LLM will let you specify schemas for unsupported models and will ignore them entirely, which isn't ideal.
llm openrouter keycommand displays information about your current API key. #24
Useful for debugging and checking the details of your key's rate limit.
llm -m ... -o online 1enables web search grounding against any model, powered by Exa. #25
OpenRouter apparently make this feature available to every one of their supported models! They're using new-to-me Exa to power this feature, an AI-focused search engine startup who appear to have built their own index with their own crawlers (according to their FAQ). This feature is currently priced by OpenRouter at $4 per 1000 results, and since 5 results are returned for every prompt that's 2 cents per prompt.
llm openrouter modelscommand for listing details of the OpenRouter models, including a--jsonoption to get JSON and a--freeoption to filter for just the free models. #26
This offers a neat way to list the available models. There are examples of the output in the comments on the issue.
- New option to specify custom provider routing:
-o provider '{JSON here}'. #17
Part of OpenRouter's USP is that it can route prompts to different providers depending on factors like latency, cost or as a fallback if your first choice is unavailable - great for if you are using open weight models like Llama which are hosted by competing companies.
The options they provide for routing are very thorough - I had initially hoped to provide a set of CLI options that covered all of these bases, but I decided instead to reuse their JSON format and forward those options directly on to the model.
Mistral OCR (via) New closed-source specialist OCR model by Mistral - you can feed it images or a PDF and it produces Markdown with optional embedded images.
It's available via their API, or it's "available to self-host on a selective basis" for people with stringent privacy requirements who are willing to talk to their sales team.
I decided to try out their API, so I copied and pasted example code from their notebook into my custom Claude project and told it:
Turn this into a CLI app, depends on mistralai - it should take a file path and an optional API key defauling to env vironment called MISTRAL_API_KEY
After some further iteration / vibe coding I got to something that worked, which I then tidied up and shared as mistral_ocr.py.
You can try it out like this:
export MISTRAL_API_KEY='...'
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf --html --inline-images > mixtral.html
I fed in the Mixtral paper as a PDF. The API returns Markdown, but my --html option renders that Markdown as HTML and the --inline-images option takes any images and inlines them as base64 URIs (inspired by monolith). The result is mixtral.html, a 972KB HTML file with images and text bundled together.
This did a pretty great job!
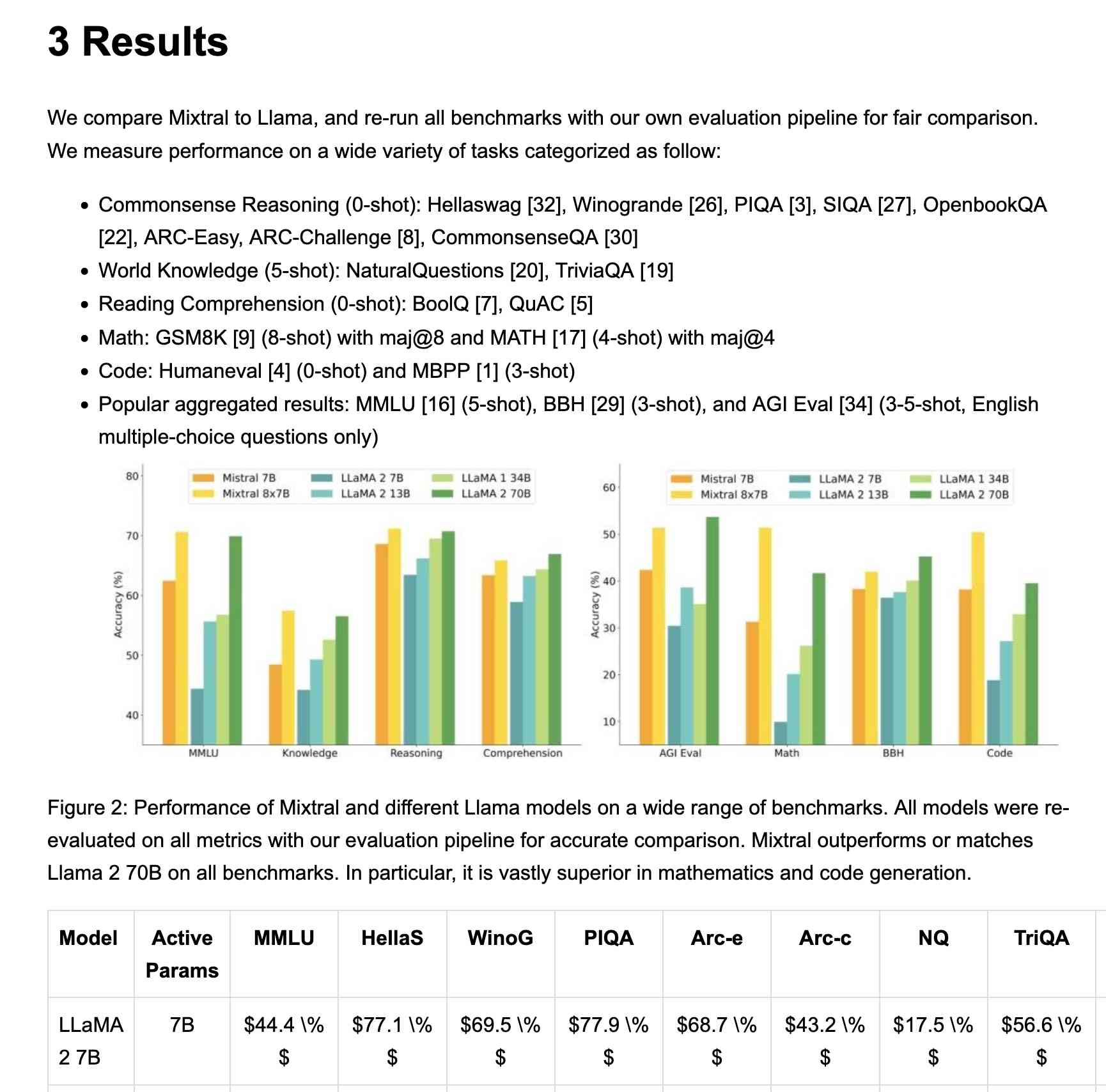
My script renders Markdown tables but I haven't figured out how to render inline Markdown MathML yet. I ran the command a second time and requested Markdown output (the default) like this:
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf > mixtral.md
Here's that Markdown rendered as a Gist - there are a few MathML glitches so clearly the Mistral OCR MathML dialect and the GitHub Formatted Markdown dialect don't quite line up.
My tool can also output raw JSON as an alternative to Markdown or HTML - full details in the documentation.
The Mistral API is priced at roughly 1000 pages per dollar, with a 50% discount for batch usage.
The big question with LLM-based OCR is always how well it copes with accidental instructions in the text (can you safely OCR a document full of prompting examples?) and how well it handles text it can't write.
Mistral's Sophia Yang says it "should be robust" against following instructions in the text, and invited people to try and find counter-examples.
Alexander Doria noted that Mistral OCR can hallucinate text when faced with handwriting that it cannot understand.
llm-mistral 0.11. I added schema support to this plugin which adds support for the Mistral API to LLM. Release notes:
Schemas now work with OpenAI, Anthropic, Gemini and Mistral hosted models, plus self-hosted models via Ollama and llm-ollama.
I built an automaton called Squadron

I believe that the price you have to pay for taking on a project is writing about it afterwards. On that basis, I feel compelled to write up my decidedly non-software project from this weekend: Squadron, an automaton.
[... 1,142 words]llm-anthropic #24: Use new URL parameter to send attachments. Anthropic released a neat quality of life improvement today. Alex Albert:
We've added the ability to specify a public facing URL as the source for an image / document block in the Anthropic API
Prior to this, any time you wanted to send an image to the Claude API you needed to base64-encode it and then include that data in the JSON. This got pretty bulky, especially in conversation scenarios where the same image data needs to get passed in every follow-up prompt.
I implemented this for llm-anthropic and shipped it just now in version 0.15.1 (here's the commit) - I went with a patch release version number bump because this is effectively a performance optimization which doesn't provide any new features, previously LLM would accept URLs just fine and would download and then base64 them behind the scenes.
In testing this out I had a really impressive result from Claude 3.7 Sonnet. I found a newspaper page from 1900 on the Library of Congress (the "Worcester spy.") and fed a URL to the PDF into Sonnet like this:
llm -m claude-3.7-sonnet \
-a 'https://tile.loc.gov/storage-services/service/ndnp/mb/batch_mb_gaia_ver02/data/sn86086481/0051717161A/1900012901/0296.pdf' \
'transcribe all text from this image, formatted as markdown'

I haven't checked every sentence but it appears to have done an excellent job, at a cost of 16 cents.
As another experiment, I tried running that against my example people template from the schemas feature I released this morning:
llm -m claude-3.7-sonnet \
-a 'https://tile.loc.gov/storage-services/service/ndnp/mb/batch_mb_gaia_ver02/data/sn86086481/0051717161A/1900012901/0296.pdf' \
-t people
That only gave me two results - so I tried an alternative approach where I looped the OCR text back through the same template, using llm logs --cid with the logged conversation ID and -r to extract just the raw response from the logs:
llm logs --cid 01jn7h45x2dafa34zk30z7ayfy -r | \
llm -t people -m claude-3.7-sonnet
... and that worked fantastically well! The result started like this:
{
"items": [
{
"name": "Capt. W. R. Abercrombie",
"organization": "United States Army",
"role": "Commander of Copper River exploring expedition",
"learned": "Reported on the horrors along the Copper River in Alaska, including starvation, scurvy, and mental illness affecting 70% of people. He was tasked with laying out a trans-Alaskan military route and assessing resources.",
"article_headline": "MUCH SUFFERING",
"article_date": "1900-01-28"
},
{
"name": "Edward Gillette",
"organization": "Copper River expedition",
"role": "Member of the expedition",
"learned": "Contributed a chapter to Abercrombie's report on the feasibility of establishing a railroad route up the Copper River valley, comparing it favorably to the Seattle to Skaguay route.",
"article_headline": "MUCH SUFFERING",
"article_date": "1900-01-28"
}strip-tags 0.6. It's been a while since I updated this tool, but in investigating a tricky mistake in my tutorial for LLM schemas I discovered a bug that I needed to fix.
Those release notes in full:
- Fixed a bug where
strip-tags -t metastill removed<meta>tags from the<head>because the entire<head>element was removed first. #32- Kept
<meta>tags now default to keeping theircontentandpropertyattributes.- The CLI
-m/--minifyoption now also removes any remaining blank lines. #33- A new
strip_tags(remove_blank_lines=True)option can be used to achieve the same thing with the Python library function.
Now I can do this and persist the <meta> tags for the article along with the stripped text content:
curl -s 'https://apnews.com/article/trump-federal-employees-firings-a85d1aaf1088e050d39dcf7e3664bb9f' | \
strip-tags -t meta --minify
Here's the output from that command.
Structured data extraction from unstructured content using LLM schemas
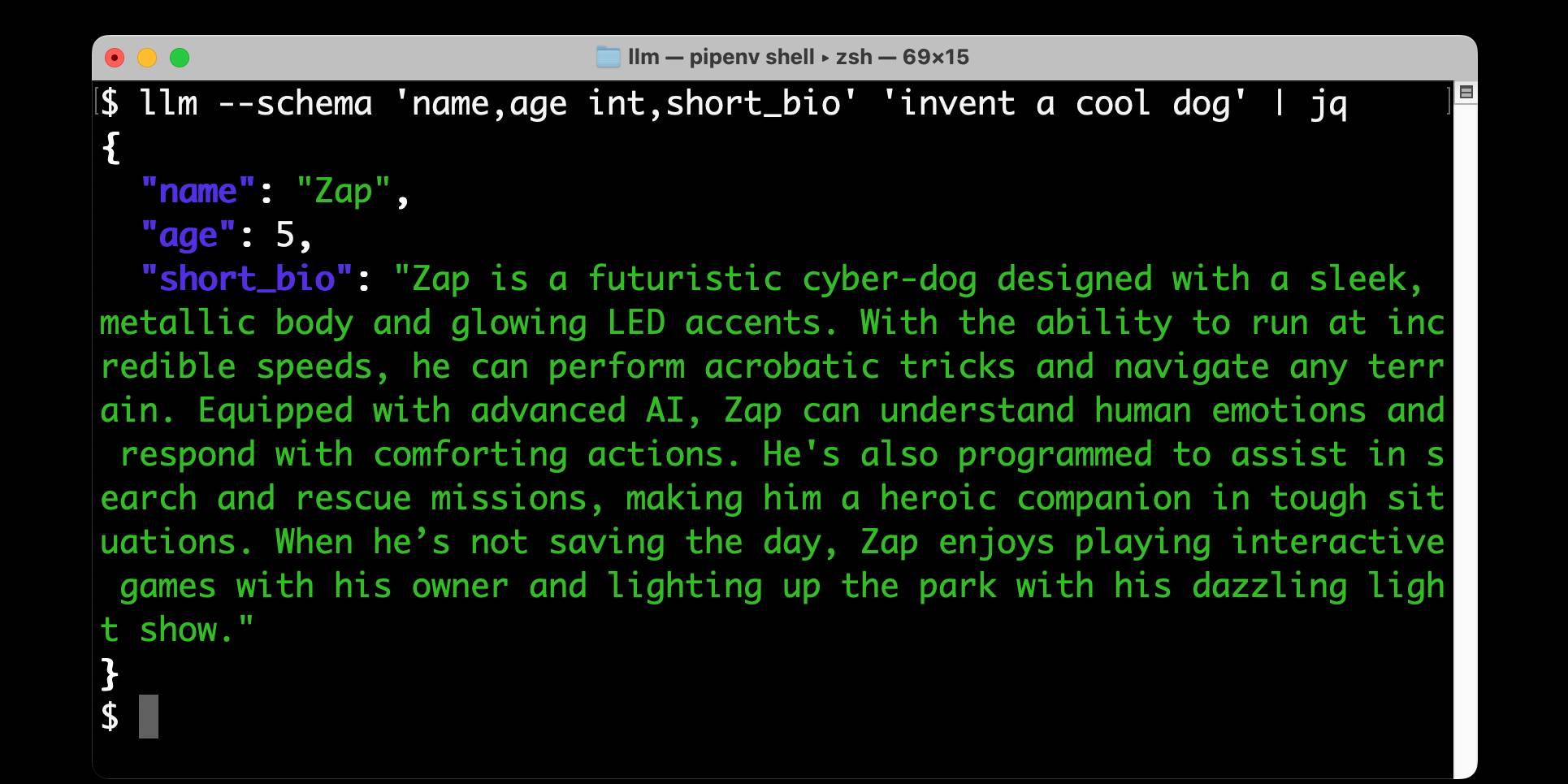
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]simonw/git-scraper-template. I built this new GitHub template repository in preparation for a workshop I'm giving at NICAR (the data journalism conference) next week on Cutting-edge web scraping techniques.
One of the topics I'll be covering is Git scraping - creating a GitHub repository that uses scheduled GitHub Actions workflows to grab copies of websites and data feeds and store their changes over time using Git.
This template repository is designed to be the fastest possible way to get started with a new Git scraper: simple create a new repository from the template and paste the URL you want to scrape into the description field and the repository will be initialized with a custom script that scrapes and stores that URL.
It's modeled after my earlier shot-scraper-template tool which I described in detail in Instantly create a GitHub repository to take screenshots of a web page.
The new git-scraper-template repo took some help from Claude to figure out. It uses a custom script to download the provided URL and derive a filename to use based on the URL and the content type, detected using file --mime-type -b "$file_path" against the downloaded file.
It also detects if the downloaded content is JSON and, if it is, pretty-prints it using jq - I find this is a quick way to generate much more useful diffs when the content changes.
Gemini 2.0 Flash and Flash-Lite (via) Gemini 2.0 Flash-Lite is now generally available - previously it was available just as a preview - and has announced pricing. The model is $0.075/million input tokens and $0.030/million output - the same price as Gemini 1.5 Flash.
Google call this "simplified pricing" because 1.5 Flash charged different cost-per-tokens depending on if you used more than 128,000 tokens. 2.0 Flash-Lite (and 2.0 Flash) are both priced the same no matter how many tokens you use.
I released llm-gemini 0.12 with support for the new gemini-2.0-flash-lite model ID. I've also updated my LLM pricing calculator with the new prices.
Claude 3.7 Sonnet, extended thinking and long output, llm-anthropic 0.14

Claude 3.7 Sonnet (previously) is a very interesting new model. I released llm-anthropic 0.14 last night adding support for the new model’s features to LLM. I learned a whole lot about the new model in the process of building that plugin.
[... 1,491 words]files-to-prompt 0.6. New release of my CLI tool for turning a whole directory of code into a single prompt ready to pipe or paste into an LLM.
Here are the full release notes:
- New
-m/--markdownoption for outputting results as Markdown with each file in a fenced code block. #42- Support for reading a list of files from standard input. Thanks, Ankit Shankar. #44
Here's how to process just files modified within the last day:find . -mtime -1 | files-to-promptYou can also use the
-0/--nullflag to accept lists of file paths separated by null delimiters, which is useful for handling file names with spaces in them:find . -name "*.txt" -print0 | files-to-prompt -0
I also have a potential fix for a reported bug concerning nested .gitignore files that's currently sitting in a PR. I'm waiting for someone else to confirm that it behaves as they would expect. I've left details in this issue comment, but the short version is that you can try out the version from the PR using this uvx incantation:
uvx --with git+https://github.com/simonw/files-to-prompt@nested-gitignore files-to-prompt
LLM 0.22, the annotated release notes
I released LLM 0.22 this evening. Here are the annotated release notes:
[... 1,340 words]Run LLMs on macOS using llm-mlx and Apple’s MLX framework
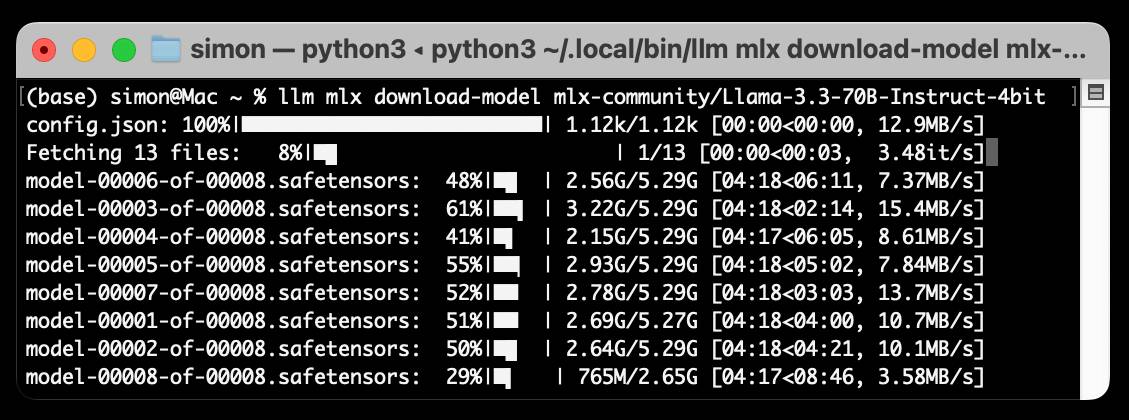
llm-mlx is a brand new plugin for my LLM Python Library and CLI utility which builds on top of Apple’s excellent MLX array framework library and mlx-lm package. If you’re a terminal user or Python developer with a Mac this may be the new easiest way to start exploring local Large Language Models.
[... 1,524 words]files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
shot-scraper 1.6 with support for HTTP Archives. New release of my shot-scraper CLI tool for taking screenshots and scraping web pages.
The big new feature is HTTP Archive (HAR) support. The new shot-scraper har command can now create an archive of a page and all of its dependents like this:
shot-scraper har https://datasette.io/
This produces a datasette-io.har file (currently 163KB) which is JSON representing the full set of requests used to render that page. Here's a copy of that file. You can visualize that here using ericduran.github.io/chromeHAR.
That JSON includes full copies of all of the responses, base64 encoded if they are binary files such as images.
You can add the --zip flag to instead get a datasette-io.har.zip file, containing JSON data in har.har but with the response bodies saved as separate files in that archive.
The shot-scraper multi command lets you run shot-scraper against multiple URLs in sequence, specified using a YAML file. That command now takes a --har option (or --har-zip or --har-file name-of-file), described in the documentation, which will produce a HAR at the same time as taking the screenshots.
Shots are usually defined in YAML that looks like this:
- output: example.com.png
url: http://www.example.com/
- output: w3c.org.png
url: https://www.w3.org/You can now omit the output: keys and generate a HAR file without taking any screenshots at all:
- url: http://www.example.com/
- url: https://www.w3.org/Run like this:
shot-scraper multi shots.yml --har
Which outputs:
Skipping screenshot of 'https://www.example.com/'
Skipping screenshot of 'https://www.w3.org/'
Wrote to HAR file: trace.har
shot-scraper is built on top of Playwright, and the new features use the browser.new_context(record_har_path=...) parameter.
Using pip to install a Large Language Model that’s under 100MB
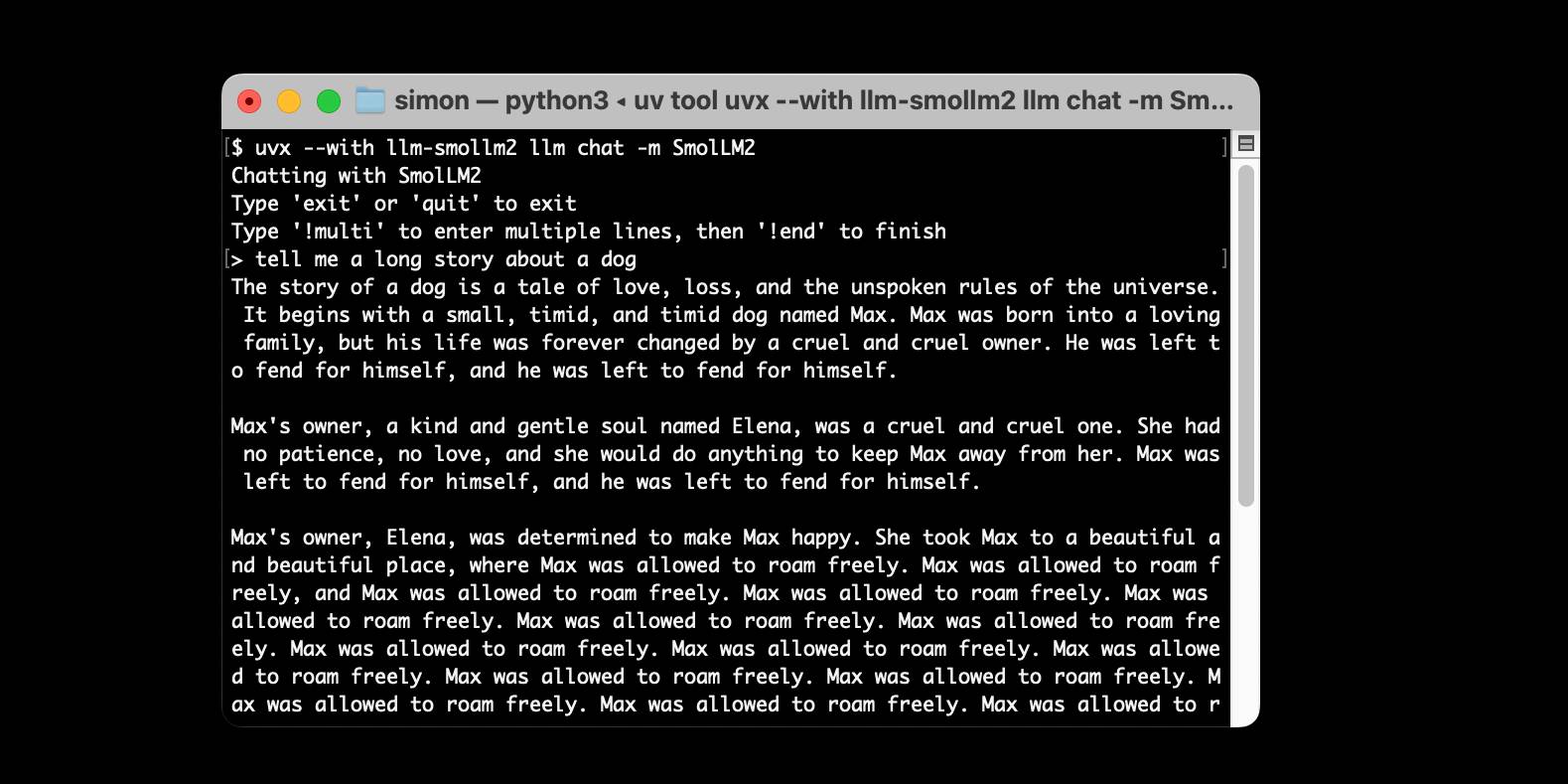
I just released llm-smollm2, a new plugin for LLM that bundles a quantized copy of the SmolLM2-135M-Instruct LLM inside of the Python package.
[... 1,553 words]Datasette 1.0a17. New Datasette alpha, with a bunch of small changes and bug fixes accumulated over the past few months. Some (minor) highlights:
- The register_magic_parameters(datasette) plugin hook can now register async functions. (#2441)
- Breadcrumbs on database and table pages now include a consistent self-link for resetting query string parameters. (#2454)
- New internal methods
datasette.set_actor_cookie()anddatasette.delete_actor_cookie(), described here. (#1690)/-/permissionspage now shows a list of all permissions registered by plugins. (#1943)- If a table has a single unique text column Datasette now detects that as the foreign key label for that table. (#2458)
- The
/-/permissionspage now includes options for filtering or exclude permission checks recorded against the current user. (#2460)
I was incentivized to push this release by an issue I ran into in my new datasette-load plugin, which resulted in this fix:
- Fixed a bug where replacing a database with a new one with the same name did not pick up the new database correctly. (#2465)
OpenAI o3-mini, now available in LLM
OpenAI’s o3-mini is out today. As with other o-series models it’s a slightly difficult one to evaluate—we now need to decide if a prompt is best run using GPT-4o, o1, o3-mini or (if we have access) o1 Pro.
[... 748 words]