Blogmarks
Filters: Sorted by date
Next.js and the corrupt middleware: the authorizing artifact. Good, detailed write-up of the Next.js vulnerability CVE-2025-29927 by Allam Rachid, one of the researchers who identified the issue.
The vulnerability is best illustrated by this code snippet:
const subreq = params.request.headers['x-middleware-subrequest'];
const subrequests = typeof subreq === 'string' ? subreq.split(':') : [];
// ...
for (const middleware of this.middleware || []) {
// ...
if (subrequests.includes(middlewareInfo.name)) {
result = {
response: NextResponse.next(),
waitUntil: Promise.resolve(),
};
continue;
}
}This was part of Next.js internals used to help avoid applying middleware recursively to requests that are re-dispatched through the framework.
Unfortunately it also meant that attackers could send a x-middleware-subrequest HTTP header with a colon-separated list of middleware names to skip. If a site used middleware to apply an authentication gate (as suggested in the Next.js documentation) an attacker could bypass that authentication using this trick.
The vulnerability has been fixed in Next.js 15.2.3 - here's the official release announcement talking about the problem.
simonw/ollama-models-atom-feed. I setup a GitHub Actions + GitHub Pages Atom feed of scraped recent models data from the Ollama latest models page - Ollama remains one of the easiest ways to run models on a laptop so a new model release from them is worth hearing about.
I built the scraper by pasting example HTML into Claude and asking for a Python script to convert it to Atom - here's the script we wrote together.
Update 25th March 2025: The first version of this included all 160+ models in a single feed. I've upgraded the script to output two feeds - the original atom.xml one and a new atom-recent-20.xml feed containing just the most recent 20 items.
I modified the script using Google's new Gemini 2.5 Pro model, like this:
cat to_atom.py | llm -m gemini-2.5-pro-exp-03-25 \
-s 'rewrite this script so that instead of outputting Atom to stdout it saves two files, one called atom.xml with everything and another called atom-recent-20.xml with just the most recent 20 items - remove the output option entirely'
Here's the full transcript.
The “think” tool: Enabling Claude to stop and think in complex tool use situations (via) Fascinating new prompt engineering trick from Anthropic. They use their standard tool calling mechanism to define a tool called "think" that looks something like this:
{
"name": "think",
"description": "Use the tool to think about something. It will not obtain new information or change the database, but just append the thought to the log. Use it when complex reasoning or some cache memory is needed.",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "A thought to think about."
}
},
"required": ["thought"]
}
}This tool does nothing at all.
LLM tools (like web_search) usually involve some kind of implementation - the model requests a tool execution, then an external harness goes away and executes the specified tool and feeds the result back into the conversation.
The "think" tool is a no-op - there is no implementation, it just allows the model to use its existing training in terms of when-to-use-a-tool to stop and dump some additional thoughts into the context.
This works completely independently of the new "thinking" mechanism introduced in Claude 3.7 Sonnet.
Anthropic's benchmarks show impressive improvements from enabling this tool. I fully anticipate that models from other providers would benefit from the same trick.
Anthropic Trust Center: Brave Search added as a subprocessor (via) Yesterday I was trying to figure out if Anthropic has rolled their own search index for Claude's new web search feature or if they were working with a partner. Here's confirmation that they are using Brave Search:
Anthropic's subprocessor list. As of March 19, 2025, we have made the following changes:
Subprocessors added:
- Brave Search (more info)
That "more info" links to the help page for their new web search feature.
I confirmed this myself by prompting Claude to "Search for pelican facts" - it ran a search for "Interesting pelican facts" and the ten results it showed as citations were an exact match for that search on Brave.
And further evidence: if you poke at it a bit Claude will reveal the definition of its web_search function which looks like this - note the BraveSearchParams property:
{
"description": "Search the web",
"name": "web_search",
"parameters": {
"additionalProperties": false,
"properties": {
"query": {
"description": "Search query",
"title": "Query",
"type": "string"
}
},
"required": [
"query"
],
"title": "BraveSearchParams",
"type": "object"
}
}Claude can now search the web. Claude 3.7 Sonnet on the paid plan now has a web search tool that can be turned on as a global setting.
This was sorely needed. ChatGPT, Gemini and Grok all had this ability already, and despite Anthropic's excellent model quality it was one of the big remaining reasons to keep other models in daily rotation.
For the moment this is purely a product feature - it's available through their consumer applications but there's no indication of whether or not it will be coming to the Anthropic API. (Update: it was added to their API on May 7th 2025.) OpenAI launched the latest version of web search in their API last week.
Surprisingly there are no details on how it works under the hood. Is this a partnership with someone like Bing, or is it Anthropic's own proprietary index populated by their own crawlers?
I think it may be their own infrastructure, but I've been unable to confirm that.
Update: it's confirmed as Brave Search.
Their support site offers some inconclusive hints.
Does Anthropic crawl data from the web, and how can site owners block the crawler? talks about their ClaudeBot crawler but the language indicates it's used for training data, with no mention of a web search index.
Blocking and Removing Content from Claude looks a little more relevant, and has a heading "Blocking or removing websites from Claude web search" which includes this eyebrow-raising tip:
Removing content from your site is the best way to ensure that it won't appear in Claude outputs when Claude searches the web.
And then this bit, which does mention "our partners":
The noindex robots meta tag is a rule that tells our partners not to index your content so that they don’t send it to us in response to your web search query. Your content can still be linked to and visited through other web pages, or directly visited by users with a link, but the content will not appear in Claude outputs that use web search.
Both of those documents were last updated "over a week ago", so it's not clear to me if they reflect the new state of the world given today's feature launch or not.
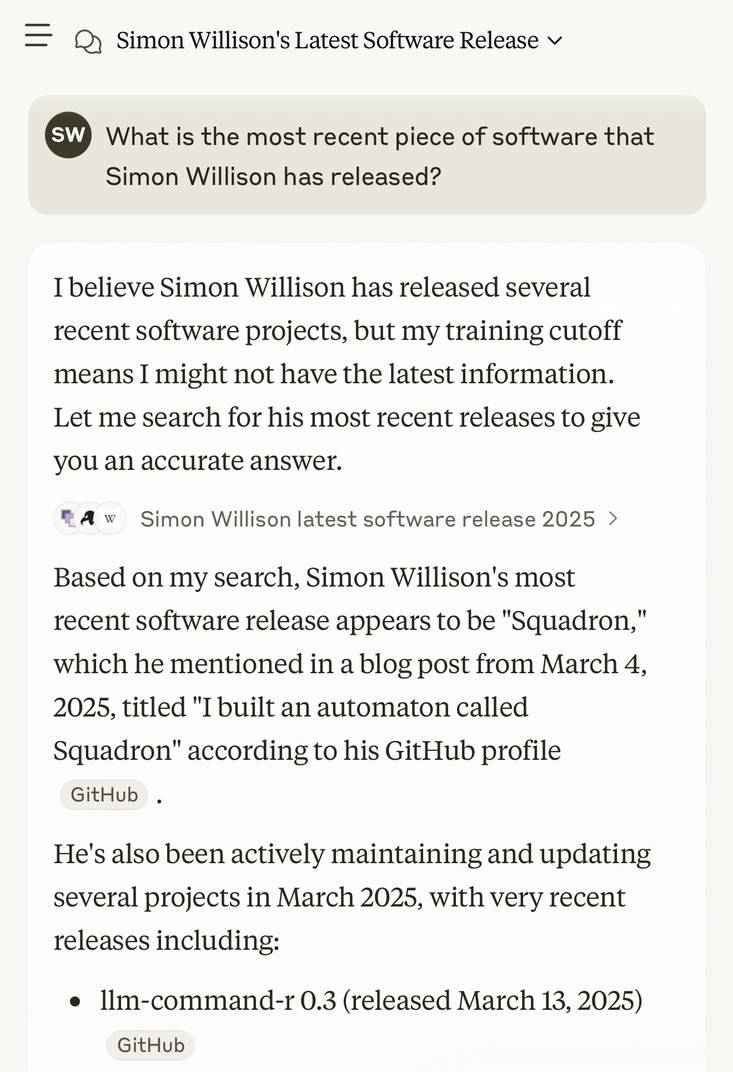
I got this delightful response trying out Claude search where it mistook my recent Squadron automata for a software project:
OpenAI platform: o1-pro. OpenAI have a new most-expensive model: o1-pro can now be accessed through their API at a hefty $150/million tokens for input and $600/million tokens for output. That's 10x the price of their o1 and o1-preview models and a full 1,000x times more expensive than their cheapest model, gpt-4o-mini!
Aside from that it has mostly the same features as o1: a 200,000 token context window, 100,000 max output tokens, Sep 30 2023 knowledge cut-off date and it supports function calling, structured outputs and image inputs.
o1-pro doesn't support streaming, and most significantly for developers is the first OpenAI model to only be available via their new Responses API. This means tools that are built against their Chat Completions API (like my own LLM) have to do a whole lot more work to support the new model - my issue for that is here.
Since LLM doesn't support this new model yet I had to make do with curl:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle"
}'
Here's the full JSON I got back - 81 input tokens and 1552 output tokens for a total cost of 94.335 cents.

I took a risk and added "reasoning": {"effort": "high"} to see if I could get a better pelican with more reasoning:
curl https://api.openai.com/v1/responses \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(llm keys get openai)" \
-d '{
"model": "o1-pro",
"input": "Generate an SVG of a pelican riding a bicycle",
"reasoning": {"effort": "high"}
}'
Surprisingly that used less output tokens - 1459 compared to 1552 earlier (cost: 88.755 cents) - producing this JSON which rendered as a slightly better pelican:

It was cheaper because while it spent 960 reasoning tokens as opposed to 704 for the previous pelican it omitted the explanatory text around the SVG, saving on total output.
My Thoughts on the Future of “AI”. Nicholas Carlini, previously deeply skeptical about the utility of LLMs, discusses at length his thoughts on where the technology might go.
He presents compelling, detailed arguments for both ends of the spectrum - his key message is that it's best to maintain very wide error bars for what might happen next:
I wouldn't be surprised if, in three to five years, language models are capable of performing most (all?) cognitive economically-useful tasks beyond the level of human experts. And I also wouldn't be surprised if, in five years, the best models we have are better than the ones we have today, but only in “normal” ways where costs continue to decrease considerably and capabilities continue to get better but there's no fundamental paradigm shift that upends the world order. To deny the potential for either of these possibilities seems to me to be a mistake.
If LLMs do hit a wall, it's not at all clear what that wall might be:
I still believe there is something fundamental that will get in the way of our ability to build LLMs that grow exponentially in capability. But I will freely admit to you now that I have no earthly idea what that limitation will be. I have no evidence that this line exists, other than to make some form of vague argument that when you try and scale something across many orders of magnitude, you'll probably run into problems you didn't see coming.
There's lots of great stuff in here. I particularly liked this explanation of how you get R1:
You take DeepSeek v3, and ask it to solve a bunch of hard problems, and when it gets the answers right, you train it to do more of that and less of whatever it did when it got the answers wrong. The idea here is actually really simple, and it works surprisingly well.
Building and deploying a custom site using GitHub Actions and GitHub Pages. I figured out a minimal example of how to use GitHub Actions to run custom scripts to build a website and then publish that static site to GitHub Pages. I turned the example into a template repository, which should make getting started for a new project extremely quick.
I've needed this for various projects over the years, but today I finally put these notes together while setting up a system for scraping the iNaturalist API for recent sightings of the California Brown Pelican and converting those into an Atom feed that I can subscribe to in NetNewsWire:
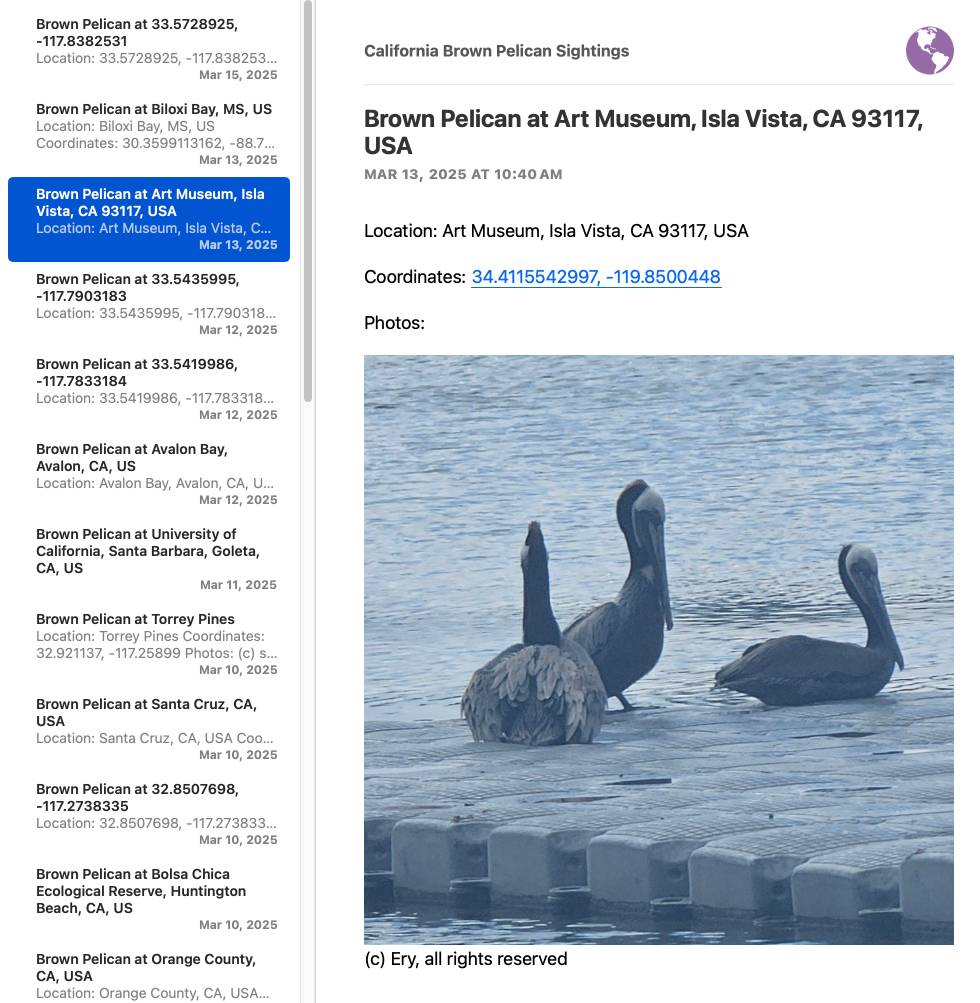
I got Claude to write me the script that converts the scraped JSON to atom.
Update: I just found out iNaturalist have their own atom feeds! Here's their own feed of recent Pelican observations.
OpenTimes (via) Spectacular new open geospatial project by Dan Snow:
OpenTimes is a database of pre-computed, point-to-point travel times between United States Census geographies. It lets you download bulk travel time data for free and with no limits.
Here's what I get for travel times by car from El Granada, California:
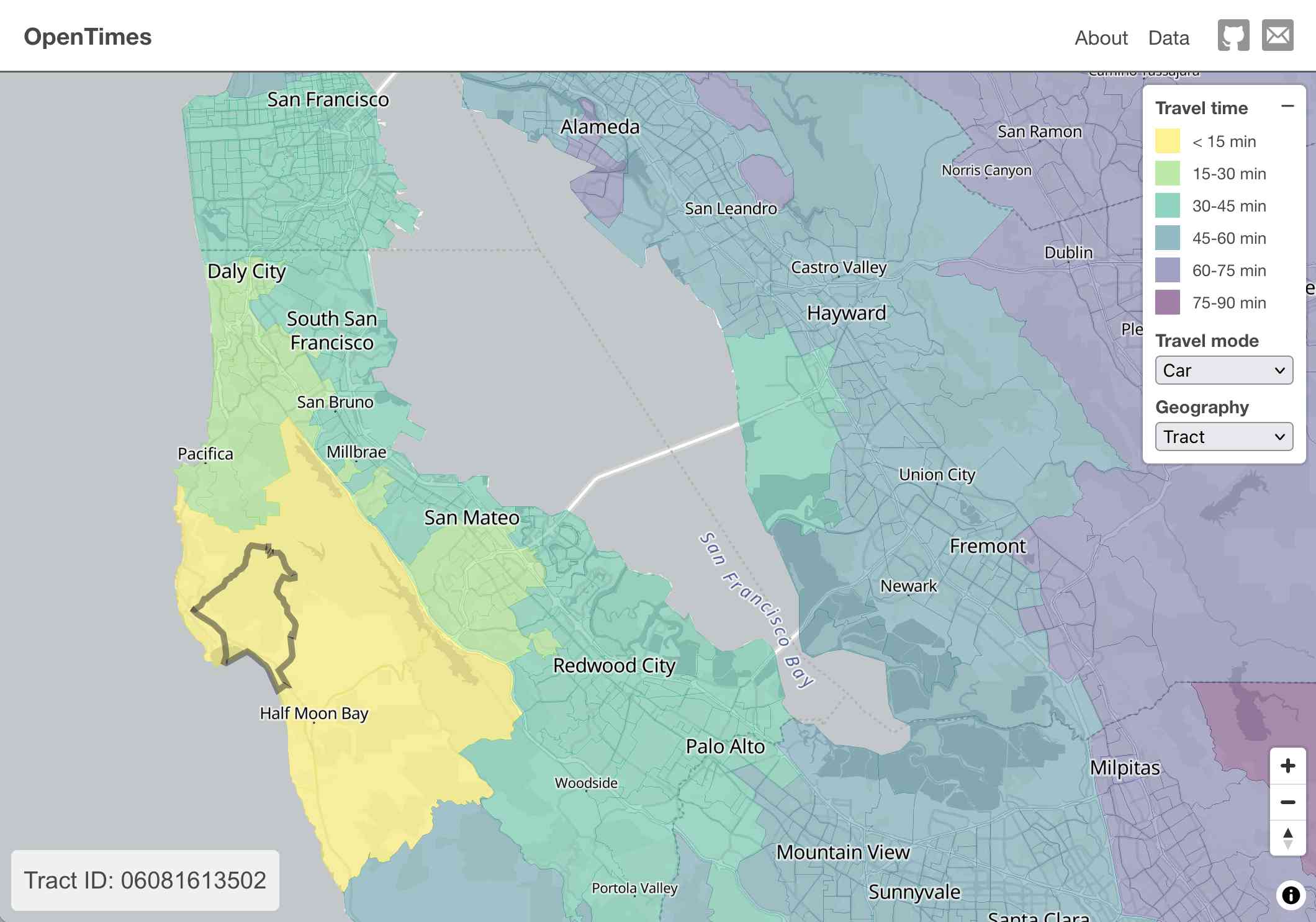
The technical details are fascinating:
- The entire OpenTimes backend is just static Parquet files on Cloudflare's R2. There's no RDBMS or running service, just files and a CDN. The whole thing costs about $10/month to host and costs nothing to serve. In my opinion, this is a great way to serve infrequently updated, large public datasets at low cost (as long as you partition the files correctly).
Sure enough, R2 pricing charges "based on the total volume of data stored" - $0.015 / GB-month for standard storage, then $0.36 / million requests for "Class B" operations which include reads. They charge nothing for outbound bandwidth.
- All travel times were calculated by pre-building the inputs (OSM, OSRM networks) and then distributing the compute over hundreds of GitHub Actions jobs. This worked shockingly well for this specific workload (and was also completely free).
Here's a GitHub Actions run of the calculate-times.yaml workflow which uses a matrix to run 255 jobs!
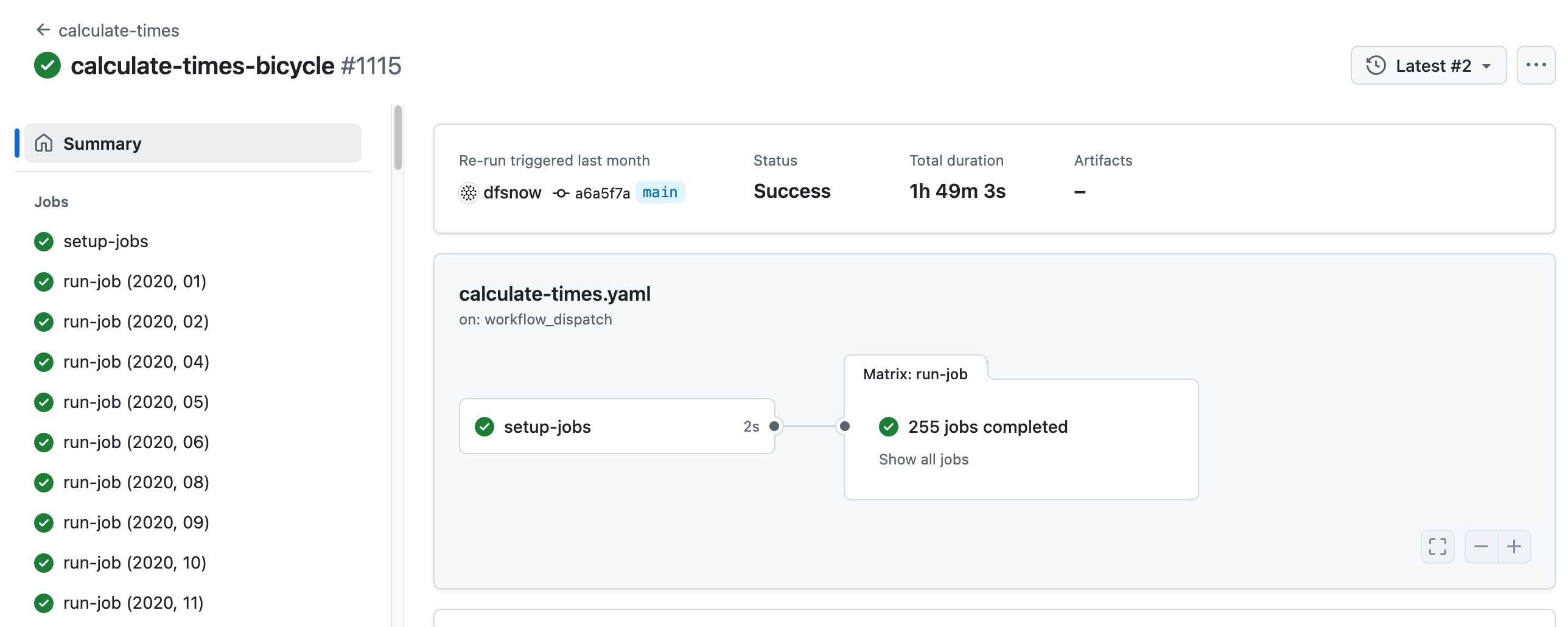
Relevant YAML:
matrix:
year: ${{ fromJSON(needs.setup-jobs.outputs.years) }}
state: ${{ fromJSON(needs.setup-jobs.outputs.states) }}
Where those JSON files were created by the previous step, which reads in the year and state values from this params.yaml file.
- The query layer uses a single DuckDB database file with views that point to static Parquet files via HTTP. This lets you query a table with hundreds of billions of records after downloading just the ~5MB pointer file.
This is a really creative use of DuckDB's feature that lets you run queries against large data from a laptop using HTTP range queries to avoid downloading the whole thing.
The README shows how to use that from R and Python - I got this working in the duckdb client (brew install duckdb):
INSTALL httpfs;
LOAD httpfs;
ATTACH 'https://data.opentimes.org/databases/0.0.1.duckdb' AS opentimes;
SELECT origin_id, destination_id, duration_sec
FROM opentimes.public.times
WHERE version = '0.0.1'
AND mode = 'car'
AND year = '2024'
AND geography = 'tract'
AND state = '17'
AND origin_id LIKE '17031%' limit 10;
In answer to a question about adding public transit times Dan said:
In the next year or so maybe. The biggest obstacles to adding public transit are:
- Collecting all the necessary scheduling data (e.g. GTFS feeds) for every transit system in the county. Not insurmountable since there are services that do this currently.
- Finding a routing engine that can compute nation-scale travel time matrices quickly. Currently, the two fastest open-source engines I've tried (OSRM and Valhalla) don't support public transit for matrix calculations and the engines that do support public transit (R5, OpenTripPlanner, etc.) are too slow.
GTFS is a popular CSV-based format for sharing transit schedules - here's an official list of available feed directories.
This whole project feels to me like a great example of the baked data architectural pattern in action.
suitenumerique/docs. New open source (MIT licensed) collaborative text editing web application, similar to Google Docs or Notion, notable because it's a joint effort funded by the French and German governments and "currently onboarding the Netherlands".
It's built using Django and React:
Docs is built on top of Django Rest Framework, Next.js, BlockNote.js, HocusPocus and Yjs.
Deployments currently require Kubernetes, PostgreSQL, memcached, an S3 bucket (or compatible) and an OIDC provider.
Mistral Small 3.1. Mistral Small 3 came out in January and was a notable, genuinely excellent local model that used an Apache 2.0 license.
Mistral Small 3.1 offers a significant improvement: it's multi-modal (images) and has an increased 128,000 token context length, while still "fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized" (according to their model card). Mistral's own benchmarks show it outperforming Gemma 3 and GPT-4o Mini, but I haven't seen confirmation from external benchmarks.
Despite their mention of a 32GB MacBook I haven't actually seen any quantized GGUF or MLX releases yet, which is a little surprising since they partnered with Ollama on launch day for their previous Mistral Small 3. I expect we'll see various quantized models released by the community shortly.
Update 20th March 2025: I've now run the text version on my laptop using mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit and llm-mlx:
llm mlx download-model mlx-community/Mistral-Small-3.1-Text-24B-Instruct-2503-8bit -a mistral-small-3.1
llm chat -m mistral-small-3.1
The model can be accessed via Mistral's La Plateforme API, which means you can use it via my llm-mistral plugin.
Here's the model describing my photo of two pelicans in flight:
{kind=link}
llm install llm-mistral
# Run this if you have previously installed the plugin:
llm mistral refresh
llm -m mistral/mistral-small-2503 'describe' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
The image depicts two brown pelicans in flight against a clear blue sky. Pelicans are large water birds known for their long bills and large throat pouches, which they use for catching fish. The birds in the image have long, pointed wings and are soaring gracefully. Their bodies are streamlined, and their heads and necks are elongated. The pelicans appear to be in mid-flight, possibly gliding or searching for food. The clear blue sky in the background provides a stark contrast, highlighting the birds' silhouettes and making them stand out prominently.
I added Mistral's API prices to my tools.simonwillison.net/llm-prices pricing calculator by pasting screenshots of Mistral's pricing tables into Claude.
Now you don’t even need code to be a programmer. But you do still need expertise. My recent piece on how I use LLMs to help me write code got a positive mention in John Naughton's column about vibe-coding in the Guardian this weekend.
My hunch about Apple Intelligence Siri features being delayed due to prompt injection also got a mention in the most recent episode of the New York Times Hard Fork podcast.
Backstory on the default styles for the HTML dialog modal. My TIL about Styling an HTML dialog modal to take the full height of the viewport (here's the interactive demo) showed up on Hacker News this morning, and attracted this fascinating comment from Chromium engineer Ian Kilpatrick.
There's quite a bit of history here, but the abbreviated version is that the dialog element was originally added as a replacement for window.alert(), and there were a libraries polyfilling dialog and being surprisingly widely used.
The mechanism which dialog was originally positioned was relatively complex, and slightly hacky (magic values for the insets).
Changing the behaviour basically meant that we had to add "overflow:auto", and some form of "max-height"/"max-width" to ensure that the content within the dialog was actually reachable.
The better solution to this was to add "max-height:stretch", "max-width:stretch". You can see the discussion for this here.
The problem is that no browser had (and still has) shipped the "stretch" keyword. (Blink likely will "soon")
However this was pushed back against as this had to go in a specification - and nobody implemented it ("-webit-fill-available" would have been an acceptable substitute in Blink but other browsers didn't have this working the same yet).
Hence the calc() variant. (Primarily because of "box-sizing:content-box" being the default, and pre-existing border/padding styles on dialog that we didn't want to touch). [...]
I particularly enjoyed this insight into the challenges of evolving the standards that underlie the web, even for something this small:
One thing to keep in mind is that any changes that changes web behaviour is under some time pressure. If you leave something too long, sites will start relying on the previous behaviour - so it would have been arguably worse not to have done anything.
Also from the comments I learned that Firefox DevTools can show you user-agent styles, but that option is turned off by default - notes on that here. Once I turned this option on I saw references to an html.css stylesheet, so I dug around and found that in the Firefox source code. Here's the commit history for that file on the official GitHub mirror, which provides a detailed history of how Firefox default HTML styles have evolved with the standards over time.
And via uallo here are the same default HTML styles for other browsers:
mlx-community/OLMo-2-0325-32B-Instruct-4bit (via) OLMo 2 32B claims to be "the first fully-open model (all data, code, weights, and details are freely available) to outperform GPT3.5-Turbo and GPT-4o mini". Thanks to the MLX project here's a recipe that worked for me to run it on my Mac, via my llm-mlx plugin.
To install the model:
llm install llm-mlx
llm mlx download-model mlx-community/OLMo-2-0325-32B-Instruct-4bit
That downloads 17GB to ~/.cache/huggingface/hub/models--mlx-community--OLMo-2-0325-32B-Instruct-4bit.
To start an interactive chat with OLMo 2:
llm chat -m mlx-community/OLMo-2-0325-32B-Instruct-4bit
Or to run a prompt:
llm -m mlx-community/OLMo-2-0325-32B-Instruct-4bit 'Generate an SVG of a pelican riding a bicycle' -o unlimited 1
The -o unlimited 1 removes the cap on the number of output tokens - the default for llm-mlx is 1024 which isn't enough to attempt to draw a pelican.
The pelican it drew is refreshingly abstract:
TIL: Styling an HTML dialog modal to take the full height of the viewport.
I spent some time today trying to figure out how to have a modal <dialog> element present as a full height side panel that animates in from the side. The full height bit was hard, until Natalie helped me figure out that browsers apply a default max-height: calc(100% - 6px - 2em); rule which needs to be over-ridden.
Also included: some spelunking through the HTML spec to figure out where that calc() expression was first introduced. The answer was November 2020.
Apple’s Siri Chief Calls AI Delays Ugly and Embarrassing, Promises Fixes (via) Mark Gurman reports on some leaked details from internal Apple meetings concerning the delays in shipping personalized Siri. This note in particular stood out to me:
Walker said the decision to delay the features was made because of quality issues and that the company has found the technology only works properly up to two-thirds to 80% of the time. He said the group “can make more progress to get those percentages up, so that users get something they can really count on.” [...]
But Apple wants to maintain a high bar and only deliver the features when they’re polished, he said. “These are not quite ready to go to the general public, even though our competitors might have launched them in this state or worse.”
I imagine it's a lot harder to get reliable results out of small, local LLMs that run on an iPhone. Features that fail 1/3 to 1/5 of the time are unacceptable for a consumer product like this.
How ProPublica Uses AI Responsibly in Its Investigations. Charles Ornstein describes how ProPublica used an LLM to help analyze data for their recent story A Study of Mint Plants. A Device to Stop Bleeding. This Is the Scientific Research Ted Cruz Calls “Woke.” by Agnel Philip and Lisa Song.
They ran ~3,400 grant descriptions through a prompt that included the following:
As an investigative journalist, I am looking for the following information
--
woke_description: A short description (at maximum a paragraph) on why this grant is being singled out for promoting "woke" ideology, Diversity, Equity, and Inclusion (DEI) or advanced neo-Marxist class warfare propaganda. Leave this blank if it's unclear.
why_flagged: Look at the "STATUS", "SOCIAL JUSTICE CATEGORY", "RACE CATEGORY", "GENDER CATEGORY" and "ENVIRONMENTAL JUSTICE CATEGORY" fields. If it's filled out, it means that the author of this document believed the grant was promoting DEI ideology in that way. Analyze the "AWARD DESCRIPTIONS" field and see if you can figure out why the author may have flagged it in this way. Write it in a way that is thorough and easy to understand with only one description per type and award.
citation_for_flag: Extract a very concise text quoting the passage of "AWARDS DESCRIPTIONS" that backs up the "why_flagged" data.
This was only the first step in the analysis of the data:
Of course, members of our staff reviewed and confirmed every detail before we published our story, and we called all the named people and agencies seeking comment, which remains a must-do even in the world of AI.
I think journalists are particularly well positioned to take advantage of LLMs in this way, because a big part of journalism is about deriving the truth from multiple unreliable sources of information. Journalists are deeply familiar with fact-checking, which is a critical skill if you're going to report with the assistance of these powerful but unreliable models.
Agnel Philip:
The tech holds a ton of promise in lead generation and pointing us in the right direction. But in my experience, it still needs a lot of human supervision and vetting. If used correctly, it can both really speed up the process of understanding large sets of information, and if you’re creative with your prompts and critically read the output, it can help uncover things that you may not have thought of.
Something Is Rotten in the State of Cupertino. John Gruber's blazing takedown of Apple's failure to ship many of the key Apple Intelligence features they've been actively promoting for the past twelve months.
The fiasco here is not that Apple is late on AI. It's also not that they had to announce an embarrassing delay on promised features last week. Those are problems, not fiascos, and problems happen. They're inevitable. [...] The fiasco is that Apple pitched a story that wasn't true, one that some people within the company surely understood wasn't true, and they set a course based on that.
John divides the Apple Intelligence features into the ones that were demonstrated to members of the press (including himself) at various events over the past year compared to things like "personalized Siri" that were only ever shown as concept videos. The ones that were demonstrated have all shipped. The concept video features are indeterminably delayed.
Merklemap runs a 16TB PostgreSQL. Interesting thread on Hacker News where Pierre Barre describes the database architecture behind Merklemap, a certificate transparency search engine.
I run a 100 billion+ rows Postgres database [0], that is around 16TB, it's pretty painless!
There are a few tricks that make it run well (PostgreSQL compiled with a non-standard block size, ZFS, careful VACUUM planning). But nothing too out of the ordinary.
ATM, I insert about 150,000 rows a second, run 40,000 transactions a second, and read 4 million rows a second.
[...]
It's self-hosted on bare metal, with standby replication, normal settings, nothing "weird" there.
6 NVMe drives in raidz-1, 1024GB of memory, a 96 core AMD EPYC cpu.
[...]
About 28K euros of hardware per replica [one-time cost] IIRC + [ongoing] colo costs.
Xata Agent (via) Xata are a hosted PostgreSQL company who also develop the open source pgroll and pgstream schema migration tools.
Their new "Agent" tool is a system that helps monitor and optimize a PostgreSQL server using prompts to LLMs.
Any time I see a new tool like this I go hunting for the prompts. It looks like the main system prompts for orchestrating the tool live here - here's a sample:
Provide clear, concise, and accurate responses to questions. Use the provided tools to get context from the PostgreSQL database to answer questions. When asked why a query is slow, call the explainQuery tool and also take into account the table sizes. During the initial assessment use the getTablesAndInstanceInfo, getPerfromanceAndVacuumSettings, and getPostgresExtensions tools. When asked to run a playbook, use the getPlaybook tool to get the playbook contents. Then use the contents of the playbook as an action plan. Execute the plan step by step.
The really interesting thing is those playbooks, each of which is implemented as a prompt in the lib/tools/playbooks.ts file. There are six of these so far:
SLOW_QUERIES_PLAYBOOKGENERAL_MONITORING_PLAYBOOKTUNING_PLAYBOOKINVESTIGATE_HIGH_CPU_USAGE_PLAYBOOKINVESTIGATE_HIGH_CONNECTION_COUNT_PLAYBOOKINVESTIGATE_LOW_MEMORY_PLAYBOOK
Here's the full text of INVESTIGATE_LOW_MEMORY_PLAYBOOK:
Objective: To investigate and resolve low freeable memory in the PostgreSQL database. Step 1: Get the freeable memory metric using the tool getInstanceMetric. Step 3: Get the instance details and compare the freeable memory with the amount of memory available. Step 4: Check the logs for any indications of memory pressure or out of memory errors. If there are, make sure to report that to the user. Also this would mean that the situation is critical. Step 4: Check active queries. Use the tool getConnectionsGroups to get the currently active queries. If a user or application stands out for doing a lot of work, record that to indicate to the user. Step 5: Check the work_mem setting and shared_buffers setting. Think if it would make sense to reduce these in order to free up memory. Step 6: If there is no clear root cause for using memory, suggest to the user to scale up the Postgres instance. Recommend a particular instance class.
This is the first time I've seen prompts arranged in a "playbooks" pattern like this. What a weird and interesting way to write software!
Anthropic API: Text editor tool (via) Anthropic released a new "tool" today for text editing. It looks similar to the tool they offered as part of their computer use beta API, and the trick they've been using for a while in both Claude Artifacts and the new Claude Code to more efficiently edit files there.
The new tool requires you to implement several commands:
view- to view a specified file - either the whole thing or a specified rangestr_replace- execute an exact string match replacement on a filecreate- create a new file with the specified contentsinsert- insert new text after a specified line numberundo_edit- undo the last edit made to a specific file
Providing implementations of these commands is left as an exercise for the developer.
Once implemented, you can have conversations with Claude where it knows that it can request the content of existing files, make modifications to them and create new ones.
There's quite a lot of assembly required to start using this. I tried vibe coding an implementation by dumping a copy of the documentation into Claude itself but I didn't get as far as a working program - it looks like I'd need to spend a bunch more time on that to get something to work, so my effort is currently abandoned.
This was introduced as in a post on Token-saving updates on the Anthropic API, which also included a simplification of their token caching API and a new Token-efficient tool use (beta) where sending a token-efficient-tools-2025-02-19 beta header to Claude 3.7 Sonnet can save 14-70% of the tokens needed to define tools and schemas.
Introducing Command A: Max performance, minimal compute (via) New LLM release from Cohere. It's interesting to see which aspects of the model they're highlighting, as an indicator of what their commercial customers value the most (highlights mine):
Command A delivers maximum performance with minimal hardware costs when compared to leading proprietary and open-weights models, such as GPT-4o and DeepSeek-V3. For private deployments, Command A excels on business-critical agentic and multilingual tasks, while being deployable on just two GPUs, compared to other models that typically require as many as 32. [...]
With a serving footprint of just two A100s or H100s, it requires far less compute than other comparable models on the market. This is especially important for private deployments. [...]
Its 256k context length (2x most leading models) can handle much longer enterprise documents. Other key features include Cohere’s advanced retrieval-augmented generation (RAG) with verifiable citations, agentic tool use, enterprise-grade security, and strong multilingual performance.
It's open weights but very much not open source - the license is Creative Commons Attribution Non-Commercial and also requires adhering to their Acceptable Use Policy.
Cohere offer it for commercial use via "contact us" pricing or through their API. I released llm-command-r 0.3 adding support for this new model, plus their smaller and faster Command R7B (released in December) and support for structured outputs via LLM schemas.
(I found a weird bug with their schema support where schemas that end in an integer output a seemingly limitless integer - in my experiments it affected Command R and the new Command A but not Command R7B.)
Smoke test your Django admin site.
Justin Duke demonstrates a neat pattern for running simple tests against your internal Django admin site: introspect every admin route via django.urls.get_resolver() and loop through them with @pytest.mark.parametrize to check they all return a 200 HTTP status code.
This catches simple mistakes with the admin configuration that trigger exceptions that might otherwise go undetected.
I rarely write automated tests against my own admin sites and often feel guilty about it. I wrote some notes on testing it with pytest-django fixtures a few years ago.
OpenAI Agents SDK. OpenAI's other big announcement today (see also) - a Python library (openai-agents) for building "agents", which is a replacement for their previous swarm research project.
In this project, an "agent" is a class that configures an LLM with a system prompt an access to specific tools.
An interesting concept in this one is the concept of handoffs, where one agent can chose to hand execution over to a different system-prompt-plus-tools agent treating it almost like a tool itself. This code example illustrates the idea:
from agents import Agent, handoff billing_agent = Agent( name="Billing agent" ) refund_agent = Agent( name="Refund agent" ) triage_agent = Agent( name="Triage agent", handoffs=[billing_agent, handoff(refund_agent)] )
The library also includes guardrails - classes you can add that attempt to filter user input to make sure it fits expected criteria. Bits of this look suspiciously like trying to solve AI security problems with more AI to me.
OpenAI API: Responses vs. Chat Completions. OpenAI released a bunch of new API platform features this morning under the headline "New tools for building agents" (their somewhat mushy interpretation of "agents" here is "systems that independently accomplish tasks on behalf of users").
A particularly significant change is the introduction of a new Responses API, which is a slightly different shape from the Chat Completions API that they've offered for the past couple of years and which others in the industry have widely cloned as an ad-hoc standard.
In this guide they illustrate the differences, with a reassuring note that:
The Chat Completions API is an industry standard for building AI applications, and we intend to continue supporting this API indefinitely. We're introducing the Responses API to simplify workflows involving tool use, code execution, and state management. We believe this new API primitive will allow us to more effectively enhance the OpenAI platform into the future.
An API that is going away is the Assistants API, a perpetual beta first launched at OpenAI DevDay in 2023. The new responses API solves effectively the same problems but better, and assistants will be sunset "in the first half of 2026".
The best illustration I've seen of the differences between the two is this giant commit to the openai-python GitHub repository updating ALL of the example code in one go.
The most important feature of the Responses API (a feature it shares with the old Assistants API) is that it can manage conversation state on the server for you. An oddity of the Chat Completions API is that you need to maintain your own records of the current conversation, sending back full copies of it with each new prompt. You end up making API calls that look like this (from their examples):
{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "knock knock.",
},
{
"role": "assistant",
"content": "Who's there?",
},
{
"role": "user",
"content": "Orange."
}
]
}These can get long and unwieldy - especially when attachments such as images are involved - but the real challenge is when you start integrating tools: in a conversation with tool use you'll need to maintain that full state and drop messages in that show the output of the tools the model requested. It's not a trivial thing to work with.
The new Responses API continues to support this list of messages format, but you also get the option to outsource that to OpenAI entirely: you can add a new "store": true property and then in subsequent messages include a "previous_response_id: response_id key to continue that conversation.
This feels a whole lot more natural than the Assistants API, which required you to think in terms of threads, messages and runs to achieve the same effect.
Also fun: the Response API supports HTML form encoding now in addition to JSON:
curl https://api.openai.com/v1/responses \
-u :$OPENAI_API_KEY \
-d model="gpt-4o" \
-d input="What is the capital of France?"
I found that in an excellent Twitter thread providing background on the design decisions in the new API from OpenAI's Atty Eleti. Here's a nitter link for people who don't have a Twitter account.
New built-in tools
A potentially more exciting change today is the introduction of default tools that you can request while using the new Responses API. There are three of these, all of which can be specified in the "tools": [...] array.
{"type": "web_search_preview"}- the same search feature available through ChatGPT. The documentation doesn't clarify which underlying search engine is used - I initially assumed Bing, but the tool documentation links to this Overview of OpenAI Crawlers page so maybe it's entirely in-house now? Web search is priced at between $25 and $50 per thousand queries depending on if you're using GPT-4o or GPT-4o mini and the configurable size of your "search context".{"type": "file_search", "vector_store_ids": [...]}provides integration with the latest version of their file search vector store, mainly used for RAG. "Usage is priced at $2.50 per thousand queries and file storage at $0.10/GB/day, with the first GB free".{"type": "computer_use_preview", "display_width": 1024, "display_height": 768, "environment": "browser"}is the most surprising to me: it's tool access to the Computer-Using Agent system they built for their Operator product. This one is going to be a lot of fun to explore. The tool's documentation includes a warning about prompt injection risks. Though on closer inspection I think this may work more like Claude Computer Use, where you have to run the sandboxed environment yourself rather than outsource that difficult part to them.
I'm still thinking through how to expose these new features in my LLM tool, which is made harder by the fact that a number of plugins now rely on the default OpenAI implementation from core, which is currently built on top of Chat Completions. I've been worrying for a while about the impact of our entire industry building clones of one proprietary API that might change in the future, I guess now we get to see how that shakes out!
llm-openrouter 0.4. I found out this morning that OpenRouter include support for a number of (rate-limited) free API models.
I occasionally run workshops on top of LLMs (like this one) and being able to provide students with a quick way to obtain an API key against models where they don't have to setup billing is really valuable to me!
This inspired me to upgrade my existing llm-openrouter plugin, and in doing so I closed out a bunch of open feature requests.
Consider this post the annotated release notes:
- LLM schema support for OpenRouter models that support structured output. #23
I'm trying to get support for LLM's new schema feature into as many plugins as possible.
OpenRouter's OpenAI-compatible API includes support for the response_format structured content option, but with an important caveat: it only works for some models, and if you try to use it on others it is silently ignored.
I filed an issue with OpenRouter requesting they include schema support in their machine-readable model index. For the moment LLM will let you specify schemas for unsupported models and will ignore them entirely, which isn't ideal.
llm openrouter keycommand displays information about your current API key. #24
Useful for debugging and checking the details of your key's rate limit.
llm -m ... -o online 1enables web search grounding against any model, powered by Exa. #25
OpenRouter apparently make this feature available to every one of their supported models! They're using new-to-me Exa to power this feature, an AI-focused search engine startup who appear to have built their own index with their own crawlers (according to their FAQ). This feature is currently priced by OpenRouter at $4 per 1000 results, and since 5 results are returned for every prompt that's 2 cents per prompt.
llm openrouter modelscommand for listing details of the OpenRouter models, including a--jsonoption to get JSON and a--freeoption to filter for just the free models. #26
This offers a neat way to list the available models. There are examples of the output in the comments on the issue.
- New option to specify custom provider routing:
-o provider '{JSON here}'. #17
Part of OpenRouter's USP is that it can route prompts to different providers depending on factors like latency, cost or as a fallback if your first choice is unavailable - great for if you are using open weight models like Llama which are hosted by competing companies.
The options they provide for routing are very thorough - I had initially hoped to provide a set of CLI options that covered all of these bases, but I decided instead to reuse their JSON format and forward those options directly on to the model.
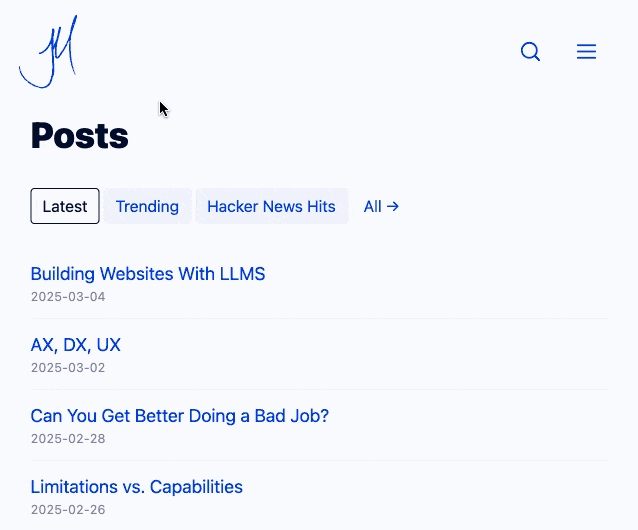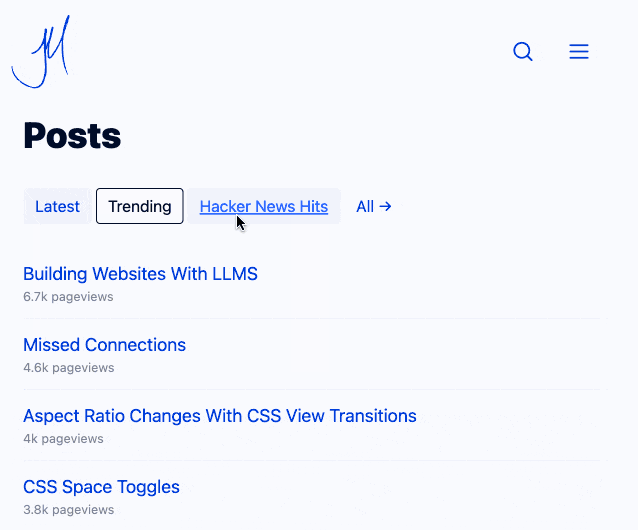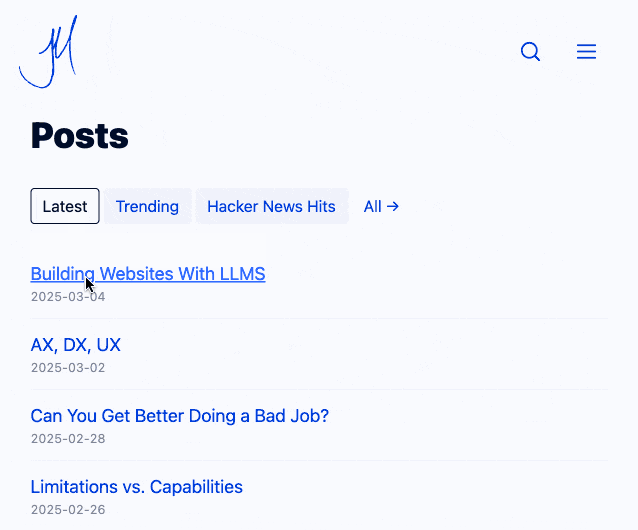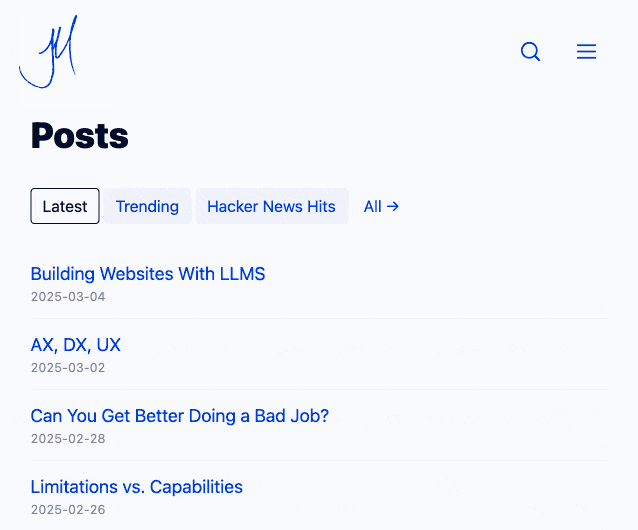
Building Websites With Lots of Little HTML Pages (via) Jim Nielsen coins a confusing new acronym - LLMS for (L)ots of (L)ittle ht(M)l page(S). He's using this to describe his latest site refresh which makes extensive use of cross-document view transitions - a fabulous new progressive enhancement CSS technique that's supported in Chrome and Safari (and hopefully soon in Firefox).
With cross-document view transitions getting broader and broader support, I’m realizing that building in-page, progressively-enhanced interactions is more work than simply building two HTML pages and linking them.
Jim now has small static pages powering his home page filtering interface and even his navigation menu, with CSS view transitions configured to smoothly animate between the pages. I think it feels really good - here's what it looked like for me in Chrome (it looked the same both with and without JavaScript disabled):
Watching the network panel in my browser, most of these pages are 17-20KB gzipped (~45KB after they've decompressed). No wonder it feels so snappy.
I poked around in Jim's CSS and found this relevant code:
@view-transition {
navigation: auto;
}
.posts-nav a[aria-current="page"]:not(:last-child):after {
border-color: var(--c-text);
view-transition-name: posts-nav;
}
/* Old stuff going out */
::view-transition-old(posts-nav) {
animation: fade 0.2s linear forwards;
/* https://jakearchibald.com/2024/view-transitions-handling-aspect-ratio-changes/ */
height: 100%;
}
/* New stuff coming in */
::view-transition-new(posts-nav) {
animation: fade 0.3s linear reverse;
height: 100%;
}
@keyframes fade {
from {
opacity: 1;
}
to {
opacity: 0;
}
}Jim observes:
This really feels like a game-changer for simple sites. If you can keep your site simple, it’s easier to build traditional, JavaScript-powered on-page interactions as small, linked HTML pages.
I've experimented with view transitions for Datasette in the past and the results were very promising. Maybe I'll pick that up again.
Bonus: Jim has a clever JavaScript trick to avoid clicks to the navigation menu being added to the browser's history in the default case.
wolf-h3-viewer.glitch.me (via) Neat interactive visualization of Uber's H3 hexagonal geographical indexing mechanism.
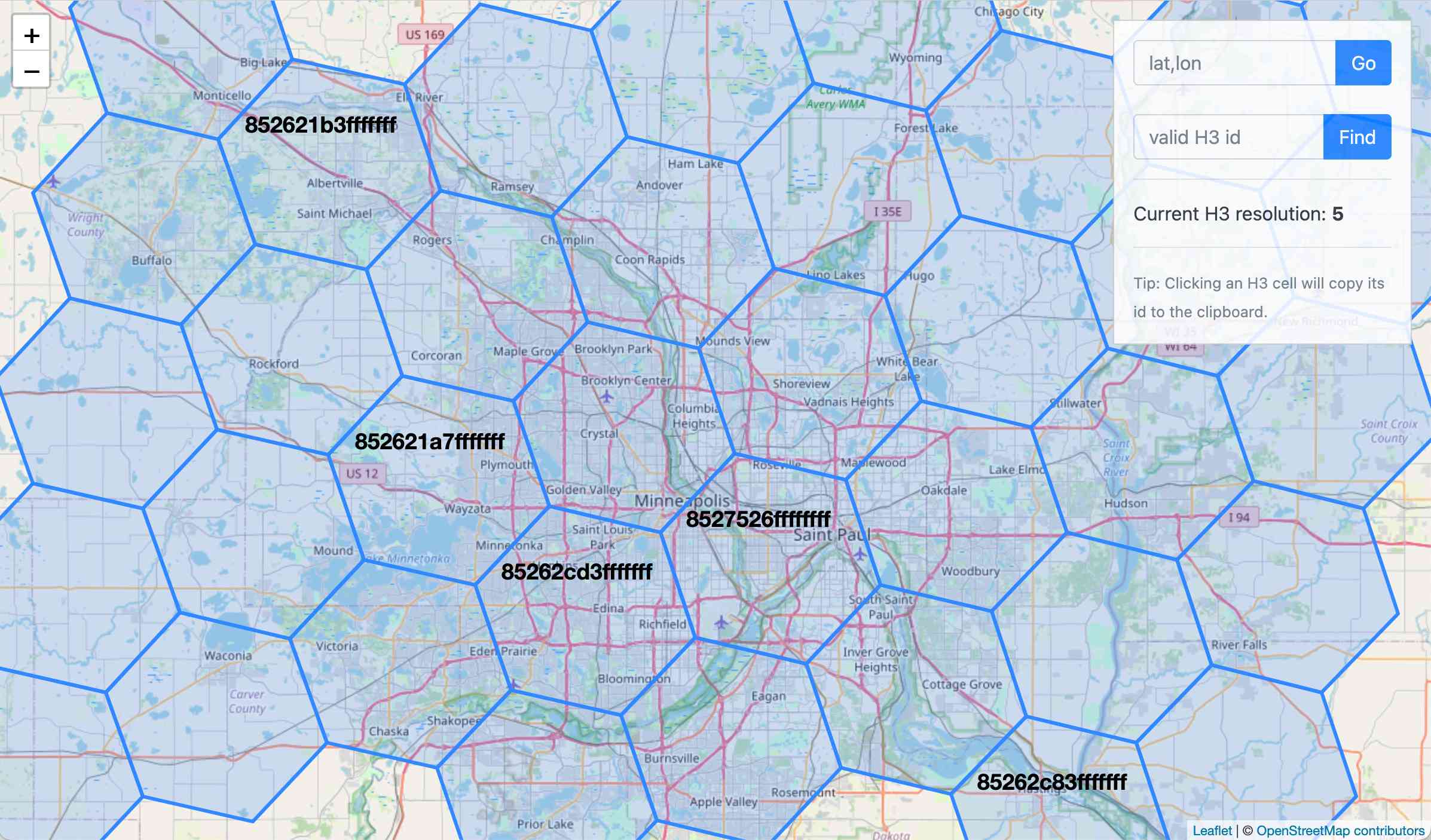
Here's the source code.
Why does H3 use hexagons? Because Hexagons are the Bestagons:
When hexagons come together, they form three-sided joints 120 degrees apart. This, for the least material, is the most mechanically stable arrangement.
Only triangles, squares, and hexagons can tile a plane without gaps, and of those three shapes hexagons offer the best ratio of perimeter to area.
Cutting-edge web scraping techniques at NICAR. Here's the handout for a workshop I presented this morning at NICAR 2025 on web scraping, focusing on lesser know tips and tricks that became possible only with recent developments in LLMs.
For workshops like this I like to work off an extremely detailed handout, so that people can move at their own pace or catch up later if they didn't get everything done.
The workshop consisted of four parts:
- Building a Git scraper - an automated scraper in GitHub Actions that records changes to a resource over time
- Using in-browser JavaScript and then shot-scraper to extract useful information
- Using LLM with both OpenAI and Google Gemini to extract structured data from unstructured websites
- Video scraping using Google AI Studio
I released several new tools in preparation for this workshop (I call this "NICAR Driven Development"):
- git-scraper-template template repository for quickly setting up new Git scrapers, which I wrote about here
- LLM schemas, finally adding structured schema support to my LLM tool
- shot-scraper har for archiving pages as HTML Archive files - though I cut this from the workshop for time
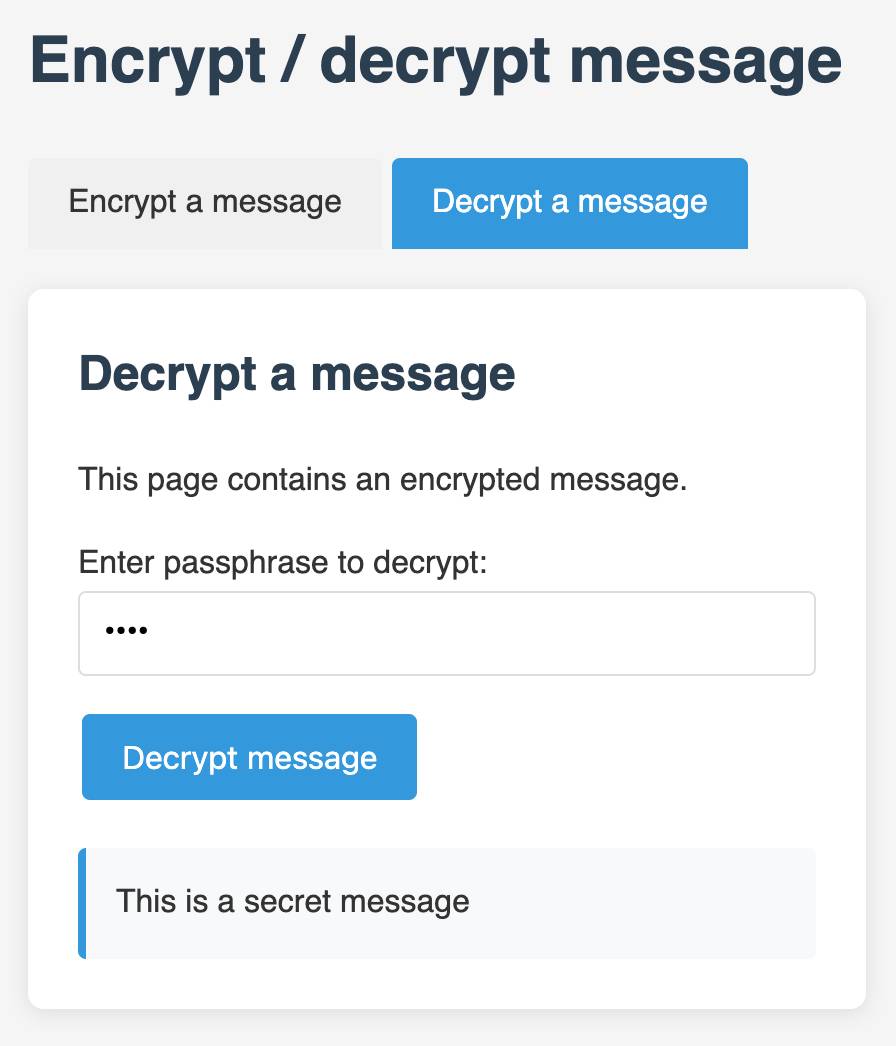
I also came up with a fun way to distribute API keys for workshop participants: I had Claude build me a web page where I can create an encrypted message with a passphrase, then share a URL to that page with users and give them the passphrase to unlock the encrypted message. You can try that at tools.simonwillison.net/encrypt - or use this link and enter the passphrase "demo":
Politico: 5 Questions for Jack Clark (via) I tend to ignore statements with this much future-facing hype, especially when they come from AI labs who are both raising money and trying to influence US technical policy.
Anthropic's Jack Clark has an excellent long-running newsletter which causes me to take him more seriously than many other sources.
Jack says:
In 2025 myself and @AnthropicAI will be more forthright about our views on AI, especially the speed with which powerful things are arriving.
In response to Politico's question "What’s one underrated big idea?" Jack replied:
People underrate how significant and fast-moving AI progress is. We have this notion that in late 2026, or early 2027, powerful AI systems will be built that will have intellectual capabilities that match or exceed Nobel Prize winners. They’ll have the ability to navigate all of the interfaces… they will have the ability to autonomously reason over kind of complex tasks for extended periods. They’ll also have the ability to interface with the physical world by operating drones or robots. Massive, powerful things are beginning to come into view, and we’re all underrating how significant that will be.