64 posts tagged “s3”
2026
A backend for datasette-files that adds the ability to store and retrieve files using an S3 bucket. This release added a mechanism for fetching S3 configuration periodically from a URL, which means we can use time limited IAM credentials that are restricted to a prefix within a bucket.
2025
s3-credentials 0.17. New release of my s3-credentials CLI tool for managing credentials needed to access just one S3 bucket. Here are the release notes in full:
That s3-credentials localserver command (documented here) is a little obscure, but I found myself wanting something like that to help me test out a new feature I'm building to help create temporary Litestream credentials using Amazon STS.
Most of that new feature was built by Claude Code from the following starting prompt:
Add a feature s3-credentials localserver which starts a localhost weberver running (using the Python standard library stuff) on port 8094 by default but -p/--port can set a different port and otherwise takes an option that names a bucket and then takes the same options for read--write/read-only etc as other commands. It also takes a required --refresh-interval option which can be set as 5m or 10h or 30s. All this thing does is reply on / to a GET request with the IAM expiring credentials that allow access to that bucket with that policy for that specified amount of time. It caches internally the credentials it generates and will return the exact same data up until they expire (it also tracks expected expiry time) after which it will generate new credentials (avoiding dog pile effects if multiple requests ask at the same time) and return and cache those instead.
An MVCC-like columnar table on S3 with constant-time deletes (via) s3's support for conditional writes (previously) makes it an interesting, scalable and often inexpensive platform for all kinds of database patterns.
Shayon Mukherjee presents an ingenious design for a Parquet-backed database in S3 which accepts concurrent writes, presents a single atomic view for readers and even supports reliable row deletion despite Parquet requiring a complete file rewrite in order to remove data.
The key to the design is a _latest_manifest JSON file at the top of the bucket, containing an integer version number. Clients use compare-and-swap to increment that version - only one client can succeed at this, so the incremented version they get back is guaranteed unique to them.
Having reserved a version number the client can write a unique manifest file for that version - manifest/v00000123.json - with a more complex data structure referencing the current versions of every persisted file, including the one they just uploaded.
Deleted rows are written to tombstone files as either a list of primary keys or a list of of ranges. Clients consult these when executing reads, filtering out deleted rows as part of resolving a query.
The pricing estimates are especially noteworthy:
For a workload ingesting 6 TB/day with 2 TB of deletes and 50K queries/day:
- PUT requests: ~380K/day (≈4 req/s) = $1.88/day
- GET requests: highly variable, depends on partitioning effectiveness
- Best case (good time-based partitioning): ~100K-200K/day = $0.04-$0.08/day
- Worst case (poor partitioning, scanning many files): ~2M/day = $0.80/day
~$3/day for ingesting 6TB of data is pretty fantastic!
Watch out for storage costs though - each new TB of data at $0.023/GB/month adds $23.55 to the ongoing monthly bill.
AWS in 2025: The Stuff You Think You Know That’s Now Wrong (via) Absurdly useful roundup from Corey Quinn of AWS changes you may have missed that can materially affect your architectural decisions about how you use their services.
A few that stood out to me:
- EC2 instances can now live-migrate between physical hosts, and can have their security groups, IAM roles and EBS volumes modified without a restart. They now charge by the second; they used to round up to the hour.
- S3 Glacier restore fees are now fast and predictably priced.
- AWS Lambdas can now run containers, execute for up to 15 minutes, use up to 10GB of RAM and request 10GB of /tmp storage.
Also this note on AWS's previously legendary resistance to shutting things down:
While deprecations remain rare, they’re definitely on the rise; if an AWS service sounds relatively niche or goofy, consider your exodus plan before building atop it.
I designed Dropbox's storage system and modeled its durability. Durability numbers (11 9's etc) are meaningless because competent providers don't lose data because of disk failures, they lose data because of bugs and operator error. [...]
The best thing you can do for your own durability is to choose a competent provider and then ensure you don't accidentally delete or corrupt own data on it:
- Ideally never mutate an object in S3, add a new version instead.
- Never live-delete any data. Mark it for deletion and then use a lifecycle policy to clean it up after a week.
This way you have time to react to a bug in your own stack.
suitenumerique/docs. New open source (MIT licensed) collaborative text editing web application, similar to Google Docs or Notion, notable because it's a joint effort funded by the French and German governments and "currently onboarding the Netherlands".
It's built using Django and React:
Docs is built on top of Django Rest Framework, Next.js, BlockNote.js, HocusPocus and Yjs.
Deployments currently require Kubernetes, PostgreSQL, memcached, an S3 bucket (or compatible) and an OIDC provider.
Using S3 triggers to maintain a list of files in DynamoDB. I built an experimental prototype this morning of a system for efficiently tracking files that have been added to a large S3 bucket by maintaining a parallel DynamoDB table using S3 triggers and AWS lambda.
I got 80% of the way there with this single prompt (complete with typos) to my custom Claude Project:
Python CLI app using boto3 with commands for creating a new S3 bucket which it also configures to have S3 lambada event triggers which moantian a dynamodb table containing metadata about all of the files in that bucket. Include these commands
create_bucket - create a bucket and sets up the associated triggers and dynamo tableslist_files - shows me a list of files based purely on querying dynamo
ChatGPT then took me to the 95% point. The code Claude produced included an obvious bug, so I pasted the code into o3-mini-high on the basis that "reasoning" is often a great way to fix those kinds of errors:
Identify, explain and then fix any bugs in this code:code from Claude pasted here
... and aside from adding a couple of time.sleep() calls to work around timing errors with IAM policy distribution, everything worked!
Getting from a rough idea to a working proof of concept of something like this with less than 15 minutes of prompting is extraordinarily valuable.
This is exactly the kind of project I've avoided in the past because of my almost irrational intolerance of the frustration involved in figuring out the individual details of each call to S3, IAM, AWS Lambda and DynamoDB.
(Update: I just found out about the new S3 Metadata system which launched a few weeks ago and might solve this exact problem!)
sqlite-s3vfs (via) Neat open source project on the GitHub organisation for the UK government's Department for Business and Trade: a "Python virtual filesystem for SQLite to read from and write to S3."
I tried out their usage example by running it in a Python REPL with all of the dependencies
uv run --python 3.13 --with apsw --with sqlite-s3vfs --with boto3 python
It worked as advertised. When I listed my S3 bucket I found it had created two files - one called demo.sqlite/0000000000 and another called demo.sqlite/0000000001, both 4096 bytes because each one represented a SQLite page.
The implementation is just 200 lines of Python, implementing a new SQLite Virtual Filesystem on top of apsw.VFS.
The README includes this warning:
No locking is performed, so client code must ensure that writes do not overlap with other writes or reads. If multiple writes happen at the same time, the database will probably become corrupt and data be lost.
I wonder if the conditional writes feature added to S3 back in November could be used to protect against that happening. Tricky as there are multiple files involved, but maybe it (or a trick like this one) could be used to implement some kind of exclusive lock between multiple processes?
2024
Building Python tools with a one-shot prompt using uv run and Claude Projects
I’ve written a lot about how I’ve been using Claude to build one-shot HTML+JavaScript applications via Claude Artifacts. I recently started using a similar pattern to create one-shot Python utilities, using a custom Claude Project combined with the dependency management capabilities of uv.
[... 899 words]DSQL Vignette: Reads and Compute. Marc Brooker is one of the engineers behind AWS's new Aurora DSQL horizontally scalable database. Here he shares all sorts of interesting details about how it works under the hood.
The system is built around the principle of separating storage from compute: storage uses S3, while compute runs in Firecracker:
Each transaction inside DSQL runs in a customized Postgres engine inside a Firecracker MicroVM, dedicated to your database. When you connect to DSQL, we make sure there are enough of these MicroVMs to serve your load, and scale up dynamically if needed. We add MicroVMs in the AZs and regions your connections are coming from, keeping your SQL query processor engine as close to your client as possible to optimize for latency.
We opted to use PostgreSQL here because of its pedigree, modularity, extensibility, and performance. We’re not using any of the storage or transaction processing parts of PostgreSQL, but are using the SQL engine, an adapted version of the planner and optimizer, and the client protocol implementation.
The system then provides strong repeatable-read transaction isolation using MVCC and EC2's high precision clocks, enabling reads "as of time X" including against nearby read replicas.
The storage layer supports index scans, which means the compute layer can push down some operations allowing it to load a subset of the rows it needs, reducing round-trips that are affected by speed-of-light latency.
The overall approach here is disaggregation: we’ve taken each of the critical components of an OLTP database and made it a dedicated service. Each of those services is independently horizontally scalable, most of them are shared-nothing, and each can make the design choices that is most optimal in its domain.
Amazon S3 adds new functionality for conditional writes (via)
Amazon S3 can now perform conditional writes that evaluate if an object is unmodified before updating it. This helps you coordinate simultaneous writes to the same object and prevents multiple concurrent writers from unintentionally overwriting the object without knowing the state of its content. You can use this capability by providing the ETag of an object [...]
This new conditional header can help improve the efficiency of your large-scale analytics, distributed machine learning, and other highly parallelized workloads by reliably offloading compare and swap operations to S3.
(Both Azure Blob Storage and Google Cloud have this feature already.)
When AWS added conditional write support just for if an object with that key exists or not back in August I wrote about Gunnar Morling's trick for Leader Election With S3 Conditional Writes. This new capability opens up a whole set of new patterns for implementing distributed locking systems along those lines.
Here's a useful illustrative example by lxgr on Hacker News:
As a (horribly inefficient, in case of non-trivial write contention) toy example, you could use S3 as a lock-free concurrent SQLite storage backend: Reads work as expected by fetching the entire database and satisfying the operation locally; writes work like this:
- Download the current database copy
- Perform your write locally
- Upload it back using "Put-If-Match" and the pre-edit copy as the matched object.
- If you get success, consider the transaction successful.
- If you get failure, go back to step 1 and try again.
AWS also just added the ability to enforce conditional writes in bucket policies:
To enforce conditional write operations, you can now use s3:if-none-match or s3:if-match condition keys to write a bucket policy that mandates the use of HTTP if-none-match or HTTP if-match conditional headers in S3 PutObject and CompleteMultipartUpload API requests. With this bucket policy in place, any attempt to write an object to your bucket without the required conditional header will be rejected.
Amazon S3 Express One Zone now supports the ability to append data to an object. This is a first for Amazon S3: it is now possible to append data to an existing object in a bucket, where previously the only supported operation was to atomically replace the object with an updated version.
This is only available for S3 Express One Zone, a bucket class introduced a year ago which provides storage in just a single availability zone, providing significantly lower latency at the cost of reduced redundancy and a much higher price (16c/GB/month compared to 2.3c for S3 standard tier).
The fact that appends have never been supported for multi-availability zone S3 provides an interesting clue as to the underlying architecture. Guaranteeing that every copy of an object has received and applied an append is significantly harder than doing a distributed atomic swap to a new version.
More details from the documentation:
There is no minimum size requirement for the data you can append to an object. However, the maximum size of the data that you can append to an object in a single request is 5GB. This is the same limit as the largest request size when uploading data using any Amazon S3 API.
With each successful append operation, you create a part of the object and each object can have up to 10,000 parts. This means you can append data to an object up to 10,000 times. If an object is created using S3 multipart upload, each uploaded part is counted towards the total maximum of 10,000 parts. For example, you can append up to 9,000 times to an object created by multipart upload comprising of 1,000 parts.
That 10,000 limit means this won't quite work for constantly appending to a log file in a bucket.
Presumably it will be possible to "tail" an object that is receiving appended updates using the HTTP Range header.
Leader Election With S3 Conditional Writes (via) Amazon S3 added support for conditional writes last week, so you can now write a key to S3 with a reliable failure if someone else has has already created it.
This is a big deal. It reminds me of the time in 2020 when S3 added read-after-write consistency, an astonishing piece of distributed systems engineering.
Gunnar Morling demonstrates how this can be used to implement a distributed leader election system. The core flow looks like this:
- Scan an S3 bucket for files matching
lock_*- likelock_0000000001.json. If the highest number contains{"expired": false}then that is the leader - If the highest lock has expired, attempt to become the leader yourself: increment that lock ID and then attempt to create
lock_0000000002.jsonwith a PUT request that includes the newIf-None-Match: *header - set the file content to{"expired": false} - If that succeeds, you are the leader! If not then someone else beat you to it.
- To resign from leadership, update the file with
{"expired": true}
There's a bit more to it than that - Gunnar also describes how to implement lock validity timeouts such that a crashed leader doesn't leave the system leaderless.
After giving it a lot of thought, we made the decision to discontinue new access to a small number of services, including AWS CodeCommit.
While we are no longer onboarding new customers to these services, there are no plans to change the features or experience you get today, including keeping them secure and reliable. [...]
The services I'm referring to are: S3 Select, CloudSearch, Cloud9, SimpleDB, Forecast, Data Pipeline, and CodeCommit.
How an empty S3 bucket can make your AWS bill explode (via) Maciej Pocwierz accidentally created an S3 bucket with a name that was already used as a placeholder value in a widely used piece of software. They saw 100 million PUT requests to their new bucket in a single day, racking up a big bill since AWS charges $5/million PUTs.
It turns out AWS charge that same amount for PUTs that result in a 403 authentication error, a policy that extends even to "requester pays" buckets!
So, if you know someone's S3 bucket name you can DDoS their AWS bill just by flooding them with meaningless unauthenticated PUT requests.
AWS support refunded Maciej's bill as an exception here, but I'd like to see them reconsider this broken policy entirely.
Update from Jeff Barr:
We agree that customers should not have to pay for unauthorized requests that they did not initiate. We’ll have more to share on exactly how we’ll help prevent these charges shortly.
s3-credentials 0.16.
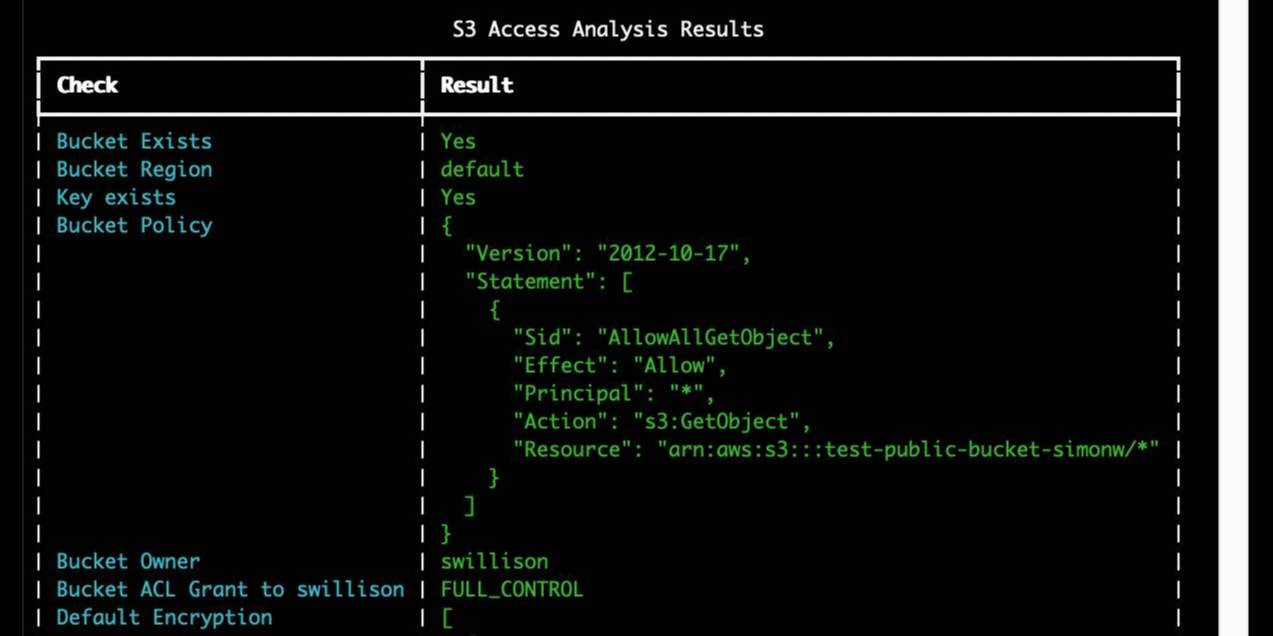
I spent entirely too long this evening trying to figure out why files in my new supposedly public S3 bucket were unavailable to view. It turns out these days you need to set a PublicAccessBlockConfiguration of {"BlockPublicAcls": false, "IgnorePublicAcls": false, "BlockPublicPolicy": false, "RestrictPublicBuckets": false}.
The s3-credentials --create-bucket --public option now does that for you. I also added a s3-credentials debug-bucket name-of-bucket command to help figure out why a bucket isn't working as expected.
S3 is files, but not a filesystem (via) Cal Paterson helps some concepts click into place for me: S3 imitates a file system but has a number of critical missing features, the most important of which is the lack of partial updates. Any time you want to modify even a few bytes in a file you have to upload and overwrite the entire thing. Almost every database system is dependent on partial updates to function, which is why there are so few databases that can use S3 directly as a backend storage mechanism.
Slashing Data Transfer Costs in AWS by 99% (via) Brilliant trick by Daniel Kleinstein. If you have data in two availability zones in the same AWS region, transferring a TB will cost you $10 in ingress and $10 in egress at the inter-zone rates charged by AWS.
But... transferring data to an S3 bucket in that same region is free (aside from S3 storage costs). And buckets are available with free transfer to all availability zones in their region, which means that TB of data can be transferred between availability zones for mere cents of S3 storage costs provided you delete the data as soon as it’s transferred.
2023
How ima.ge.cx works (via) ima.ge.cx is Aidan Steele’s web tool for browsing the contents of Docker images hosted on Docker Hub. The architecture is really interesting: it’s a set of AWS Lambda functions, written in Go, that fetch metadata about the images using Step Functions and then cache it in DynamoDB and S3. It uses S3 Select to serve directory listings from newline-delimited JSON in S3 without retrieving the whole file.
2022
Litestream backups for Datasette Cloud (and weeknotes)
My main focus this week has been adding robust backups to the forthcoming Datasette Cloud.
[... 1,604 words]s3-ocr: Extract text from PDF files stored in an S3 bucket
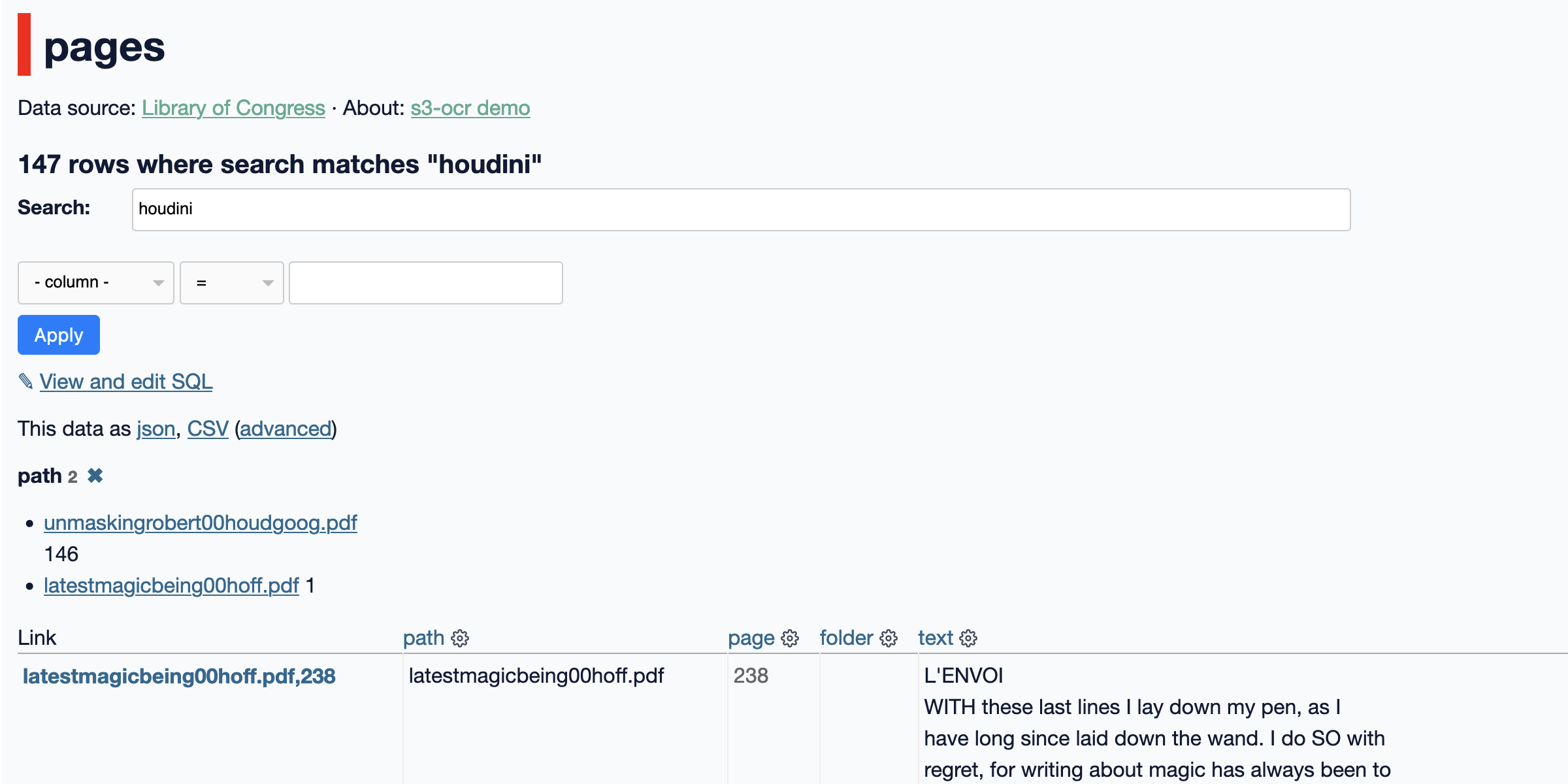
I’ve released s3-ocr, a new tool that runs Amazon’s Textract OCR text extraction against PDF files in an S3 bucket, then writes the resulting text out to a SQLite database with full-text search configured so you can run searches against the extracted data.
[... 1,493 words]2021
s3-credentials 0.8. The latest release of my s3-credentials CLI tool for creating S3 buckets with credentials to access them (with read-write, read-only or write-only policies) adds a new --public option for creating buckets that allow public access, such that anyone who knows a filename can download a file. The s3-credentials put-object command also now sets the appropriate Content-Type heading on the uploaded object.
Weeknotes: git-history, created for a Git scraping workshop
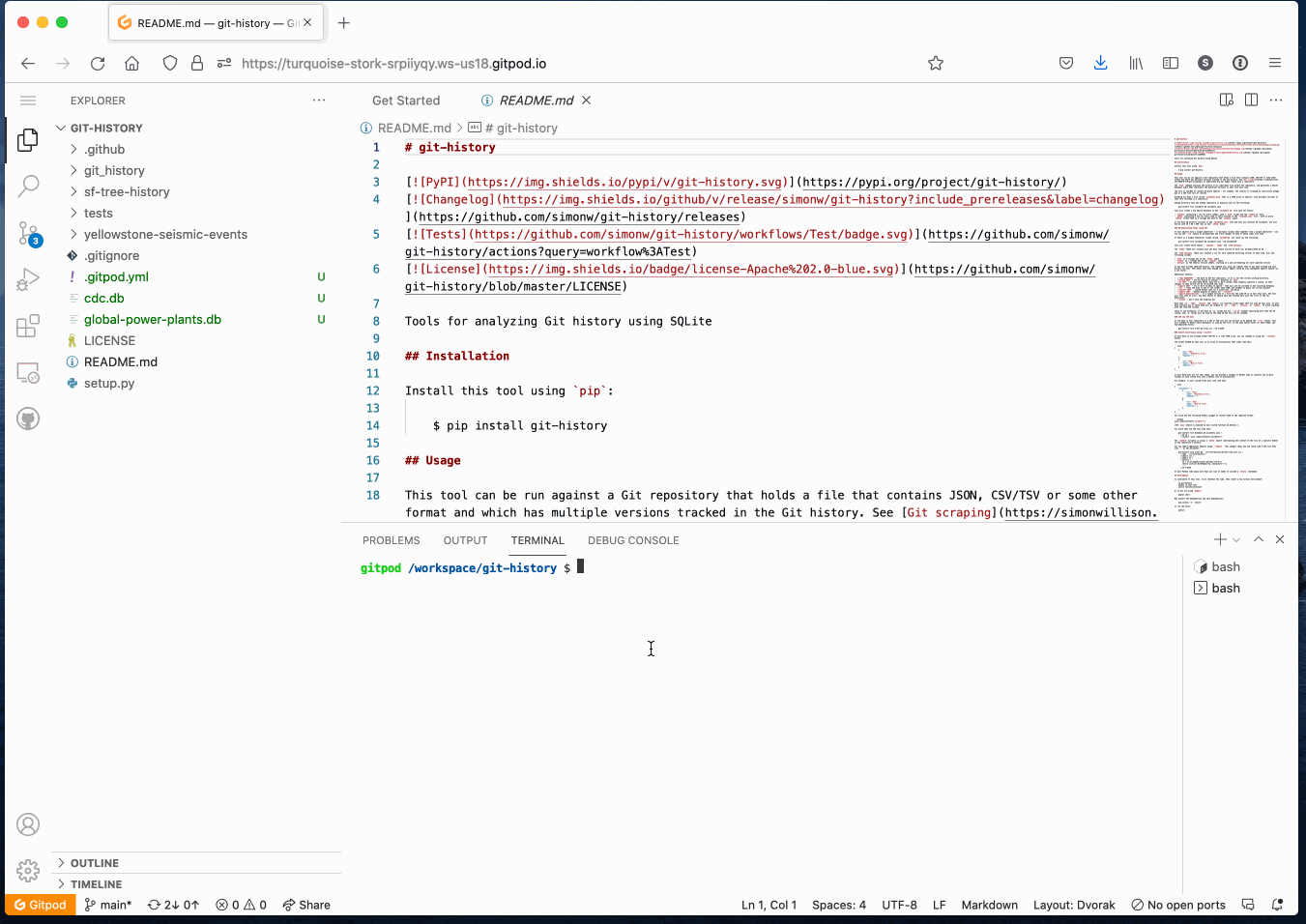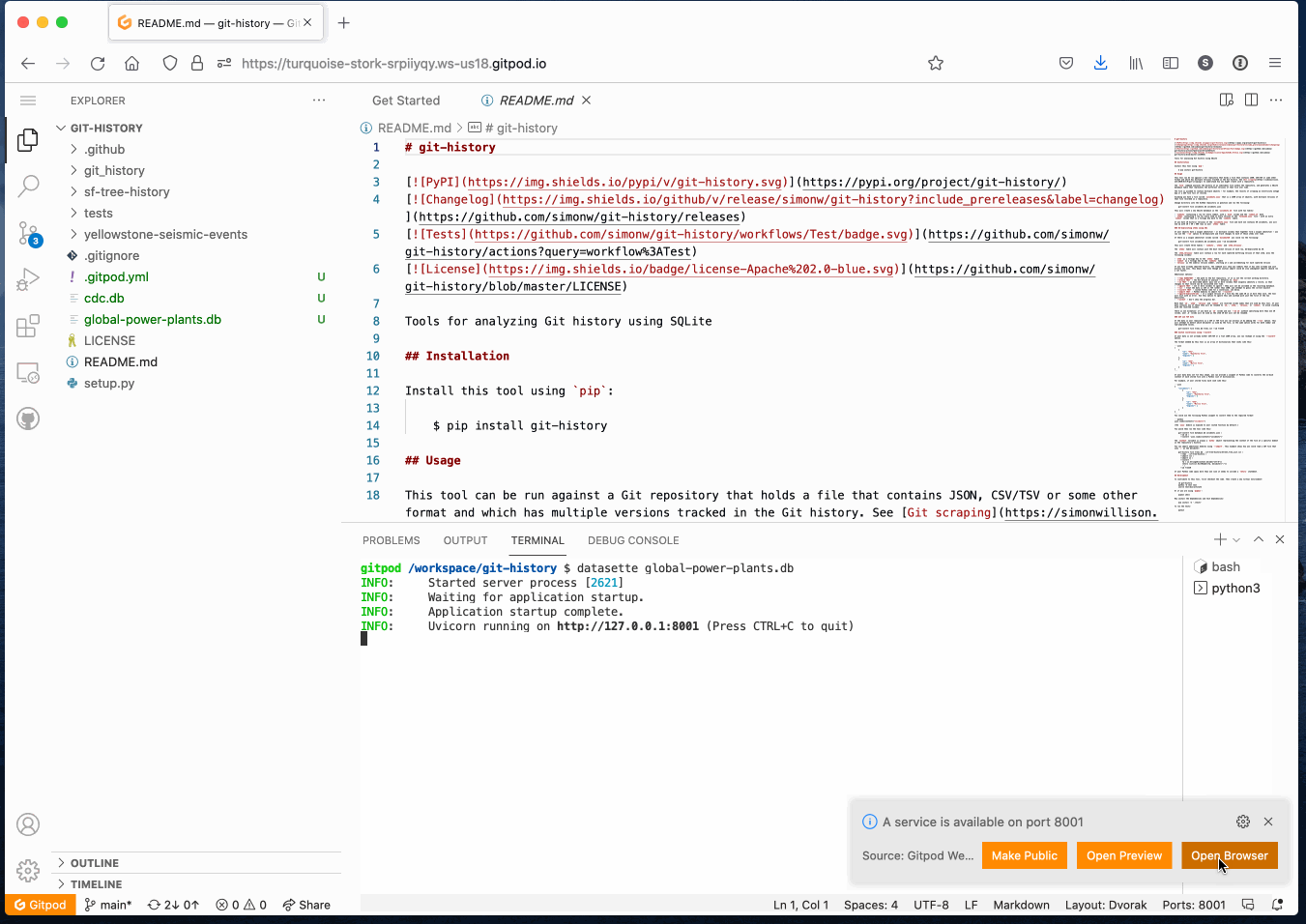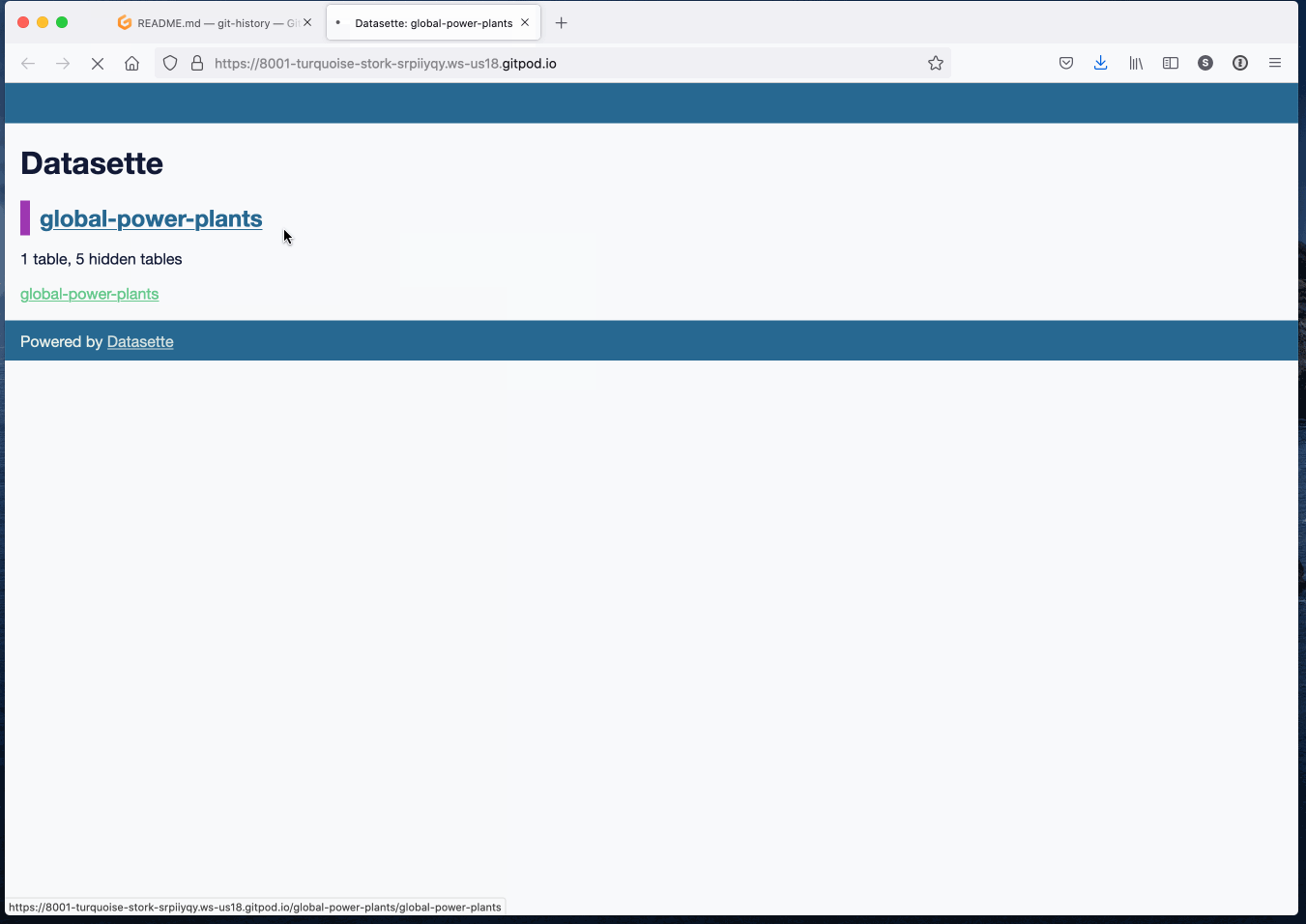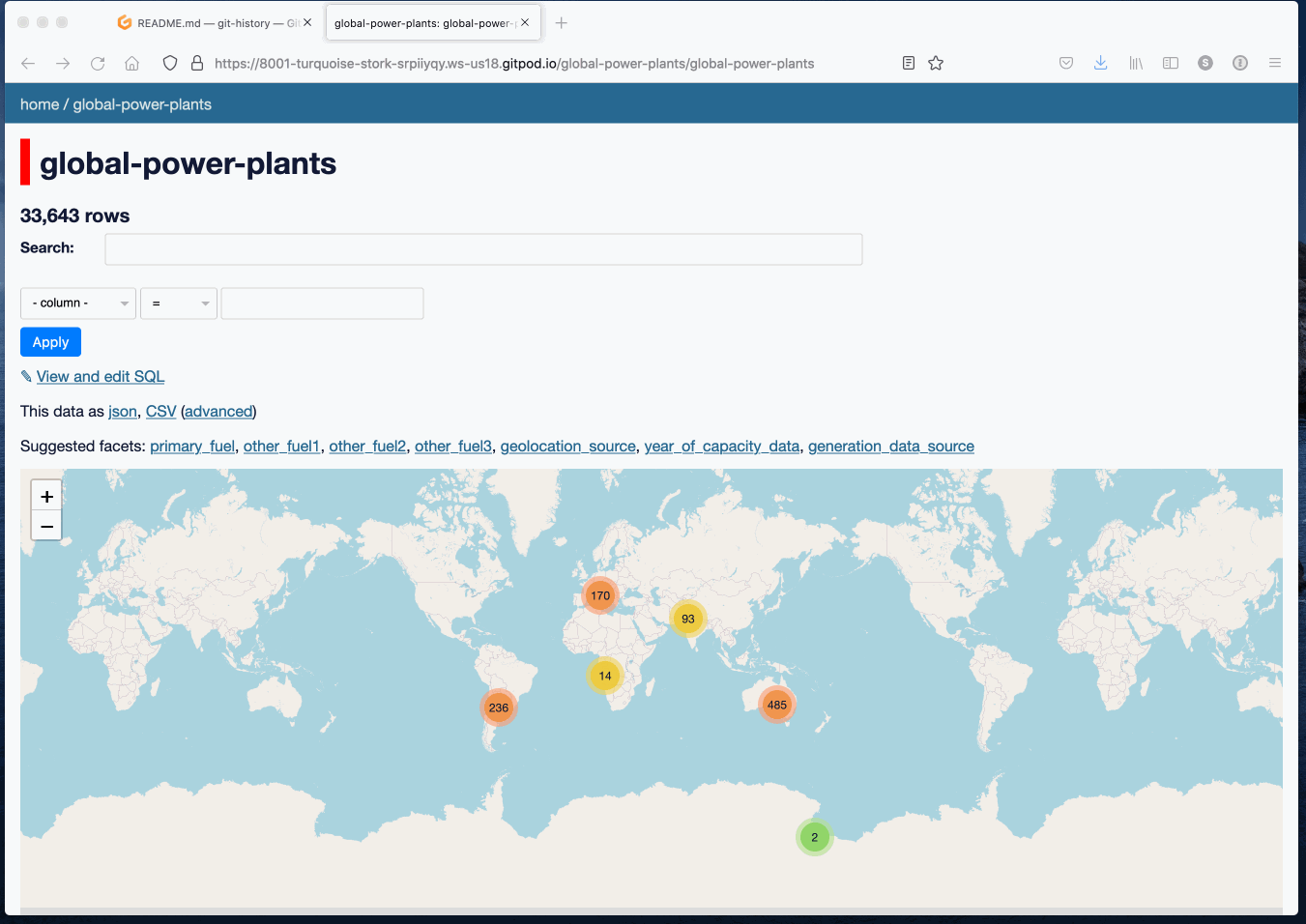
My main project this week was a 90 minute workshop I delivered about Git scraping at Coda.Br 2021, a Brazilian data journalism conference, on Friday. This inspired the creation of a brand new tool, git-history, plus smaller improvements to a range of other projects.
[... 1,239 words]s3-credentials: a tool for creating credentials for S3 buckets
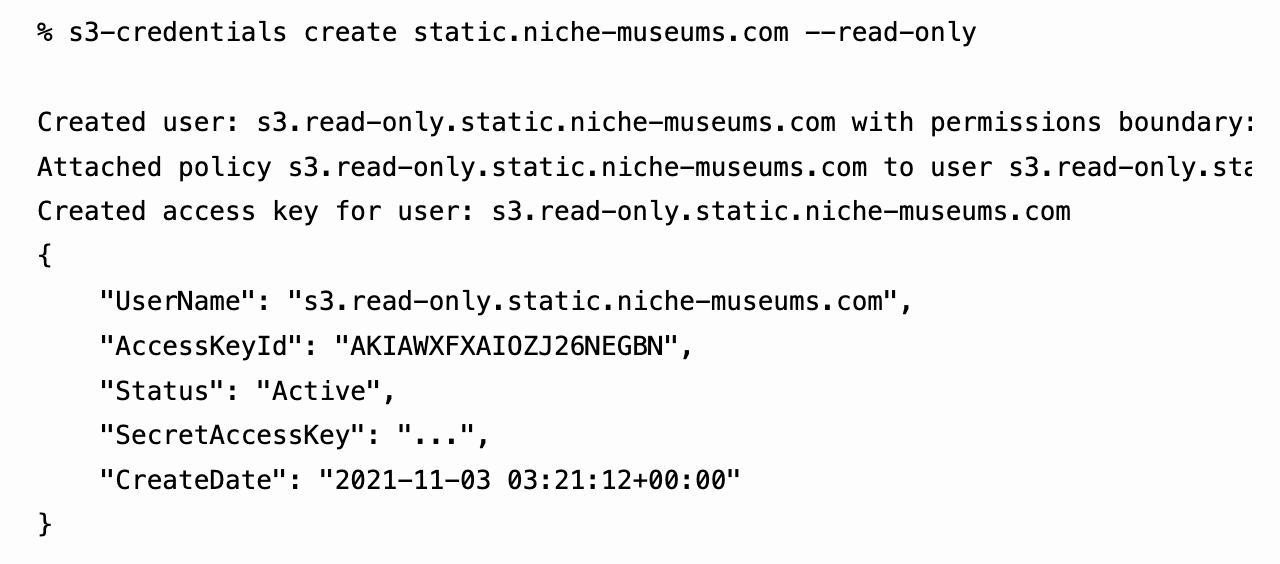
I’ve built a command-line tool called s3-credentials to solve a problem that’s been frustrating me for ages: how to quickly and easily create AWS credentials (an access key and secret key) that have permission to read or write from just a single S3 bucket.
[... 1,618 words]Abusing Terraform to Upload Static Websites to S3 (via) I found this really interesting. Terraform is infrastructure as code software which mostly handles creating and updating infrastructure resources, so it’s a poor fit for uploading files to S3 and setting the correct Content-Type headers for them. But... in figuring out how to do that, this article taught me a ton about how Terraform works. I wonder if that’s a useful general pattern? Get a tool to do something that it’s poorly designed to handle and see how much you learn about that tool along the way.
Folks think s3 is static assets hosting but really it's a consistent and highly available key value store with first class blob support
logpaste (via) Useful example of how to use the Litestream SQLite replication tool in a Dockerized application: S3 credentials are passed to the container on startup, it then attempts to restore the SQLite database from S3 and starts a Litestream process in the same container to periodically synchronize changes back up to the S3 bucket.
2019
athena-sqlite (via) Amazon Athena is the AWS tool for querying data stored in S3—as CSV, JSON or Apache Parquet files—using SQL. It’s an interesting way of buliding a very cheap data warehouse on top of S3 without having to run any additional services. Athena recently added a query federation SDK which lets you define additional custom data sources using Lambda functions. Damon Cortesi used this to write a custom connector for SQLite, which lets you run queries against data stored in SQLite files that you have uploaded to S3. You can then run joins between that data and other Athena sources.
Client-side instrumentation for under $1 per month. No servers necessary. (via) Rolling your own analytics used to be too complex and expensive to be worth the effort. Thanks to cloud technologies like Cloudfront, Athena, S3 and Lambda you can now inexpensively implement client-side analytics (via requests to a tracking pixel) that stores detailed logs on S3, then use Amazon Athena to run queries against those logs ($5/TB scanned) to get detailed reporting. This post also introduced me to Snowplow, an open source JavaScript analytics script (released by a commercial analytics platform) which looks very neat—it’s based on piwik.js, the tracker from the open-source Piwik analytics tool.
2018
Django Bakery (via) “A set of helpers for baking your Django site out as flat files”. Released by the LA Times Data Desk, who use it for a large number of projects from election results to data journalism interactives. Statically publishing these projects to S3 lets them handle huge traffic spikes at a very low cost.