62 posts tagged “redis”
2012
Can you recommend a few video lectures on web application design with Redis?
We have a collection of 27 videos of conference talks that cover Redis on Lanyrd, gathered by our community: Redis Videos | Lanyrd
[... 74 words]2011
How we use Redis at Bump. A couple of neat tricks I hadn’t seen before: using Redis to aggregate log files from multiple servers (they all push in to a Redis queue, then one process pulls from the queue and writes to disk), and using Redis blocking queues for RPC by specifying a different temporary queue to return the result.
We can deploy new versions of our software, make database schema changes, or even rotate our primary database server, all without failing to respond to a single request. We can accomplish this because we gave ourselves the ability suspend our traffic, which gives us a window of a few seconds to make some changes before letting the requests through. To make this happen, we built a custom HTTP server and application dispatching infrastructure around Python’s Tornado and Redis.
— Dan Manges, Braintree
2010
HotQueue. A super-simple Python work queue using Redis. The API is neat, and makes clever use of generators for blocking consumption of queue items.
What are the advantages and disadvantages of using MongoDB vs CouchDB vs Cassandra vs Redis?
I see Redis as a different category from the other three—kind of like you wouldn’t say “what are the advantages of MySQL v.s. Memcached”. Redis makes an excellent complement to pretty much any other persistent storage mechanism. I expanded on this here: http://simonwillison.net/2009/Oc...
[... 67 words]Will Redis support per-database persistence configuration?
I don’t know if that’s on the roadmap (you’d need to ask antirez on the mailing list or Twitter), but it should be easy enough to run multiple Redis instances with different settings—especially on a multi core machine.
[... 52 words]How we deploy new features. GitHub are experimenting with using Redis for configuration management. I’ve been thinking about this recently too—managing feature flags feels like an ideal use-case for Redis, since it lets you read multiple values on every page access without adding a bunch of extra read traffic on your regular database.
Zero-downtime Redis upgrade discussion. GitHub have a short window of scheduled downtime in order to upgrade their Redis server. I asked in their comments if they’d considered trying to run the upgrade with no downtime at all using Redis replication, and Ryan Tomayko has posted some interesting replies.
A fast, fuzzy, full-text index using Redis. Interesting twist on building a reverse-index using Redis sets: this one indexes only the metaphones of the words, resulting in a phonetic fuzzy search.
Comprehensive notes from my three hour Redis tutorial

Last week I presented two talks at the inaugural NoSQL Europe conference in London. The first was presented with Matthew Wall and covered the ways in which we have been exploring NoSQL at the Guardian. The second was a three hour workshop on Redis, my favourite piece of software to have the NoSQL label applied to it.
[... 263 words]tempalias.com development diary (via) tempalias.com is a e-mail forwarding service that lets you create an address that will only work for a few days (or a limited number of messages) and will forward messages on to your real account. It’s implemented using Node.js and Redis and the code is released under an MIT license. Philip Hofstetter, the developer, maintained a detailed development diary throughout which is worth reading if you’re interested in Node.js.
Redis weekly update #3—Pub/Sub and more. Redis is now a publish/subscribe server—and it ended up only taking 150 lines of C code since Redis internals were already based on that paradigm.
VMware: the new Redis home. Redis creator Salvatore Sanfilippo is joining VMWare to work on Redis full time. Sounds like a good match.
Redis weekly update #1—Hashes and... many more! Hashes were the big missing data type in Redis—support is only partial at the moment (no ability to list all keys in a hash or delete a specific key) but at the rate Redis is developed I expect that to be fixed within a week or two.
Cache Machine: Automatic caching for your Django models. This is the third new ORM caching layer for Django I’ve seen in the past month! Cache Machine was developed for zamboni, the port of addons.mozilla.org to Django. Caching is enabled using a model mixin class (to hook up some post_delete hooks) and a custom caching manager. Invalidation works by maintaining a “flush list” of dependent cache entries for each object—this is currently stored in memcached and hence has potential race conditions, but a comment in the source code suggests that this could be solved by moving to redis.
Node.js, redis, and resque (via) Paul Gross has been experimenting with Node.js proxies for allowing web applications to be upgraded without missing any requests. Here he places all incoming HTTP requests in a redis queue, then has his backend Rails servers consume requests from the queue and push the responses back on to a queue for Node to deliver. When the backend application is upgraded, requests remain in the queue and users see a few seconds of delay before their request is handled. It’s not production ready yet (POST requests aren’t handled, for example) but it’s a very interesting approach.
A Collection Of Redis Use Cases. Lots of interesting case studies here, collated by Mathias Meyer. Redis clearly shines for anything involving statistics or high volumes of small writes.
Redis in Practice: Who’s Online? Using Redis to implement a “which of your friends are online now” feature, by maintaining a set of active user IDs for every minute, then intersecting the past five minutes of user IDs with a set containing the IDs of your friends.
Redis Virtual Memory: the story and the code. Fascinating overview of the virtual memory feature coming to Redis 2.0, which will remove the requirement that all Redis data fit in RAM. Keys still stay in RAM, but rarely accessed values will be swapped to disk. 16 GB of RAM will be enough to hold 100 million keys, each with a value as large as you like.
Distributed lock on top of memcached. A simple Python context manager (taking advantage of the with statement) that implements a distributed lock using memcached to store lock state: “memcached_lock can be used to ensure that some global data is only updated by one server”. Redis would work well for this kind of thing as well.
Help pick the best photos, but watch out, it’s addictive! My favourite WildlifeNearYou feature yet—our new tool asks you to pick the best from two photos, then uses the results to rank all of the photos for each species. It’s surprisingly addictive—we had over 5,000 votes in the first two hours, peaking at 4 or 5 votes a second. The feature seems to be staying nice and speedy thanks to Redis under the hood. Photos in the top three for any given species display a medal on their photo page.
BLPOP and BRPOP in Redis. Added over Christmas—Redis now has blocking list pop operations. This means you can use Redis to drive a queue server without the need for polling—simply BLPOP against a key and, if it’s empty, your client will block until another client pushes an item on to the list. Multiple clients can block against the same key and only the first client will return when an item becomes available.
2009
New Redis ZINCRBY command (via) Just added to Redis, a command which increments the “score” for an item in a sorted set and reorders the set to reflect the new scores. Looks ideally suited to real time stats, and I’m sure there are plenty of other exciting uses for it.
Crowdsourced document analysis and MP expenses
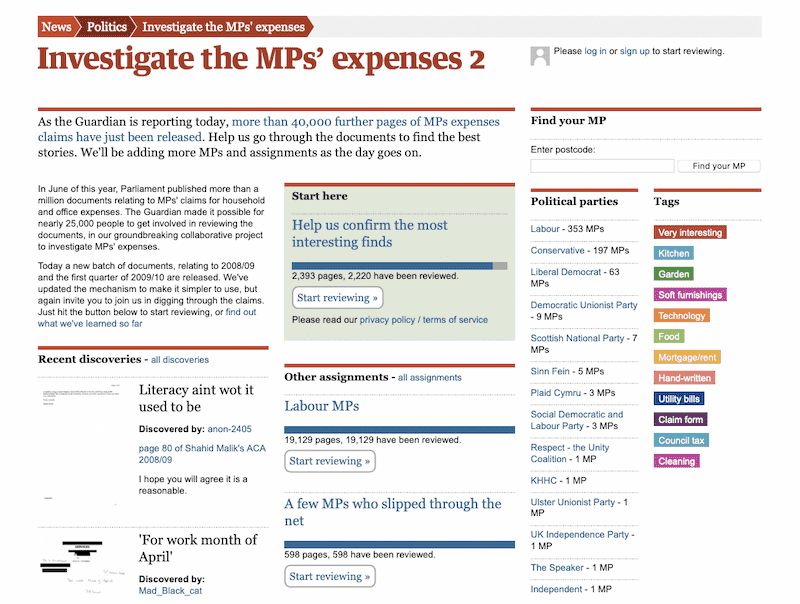
As you may have heard, the UK government released a fresh batch of MP expenses documents a week ago on Thursday. I spent that week working with a small team at Guardian HQ to prepare for the release. Here’s what we built:
[... 2,081 words]I think that what's particularly hard with C is not the details about pointers, automatic memory management, and so forth, but the fact that C is at the same time so low level and so flexible. So basically if you want to create a large project in C you have to build a number of intermediate layers (otherwise the code will be a complete mess full of bugs and 10 times bigger than required). This continue design exercise of creating additional layers is the hard part about C. You have to get very good at understanding when to write a function or not, when to create a layer of abstraction, and when it's worth to generalize or when it is an overkill.
Node.js is genuinely exciting
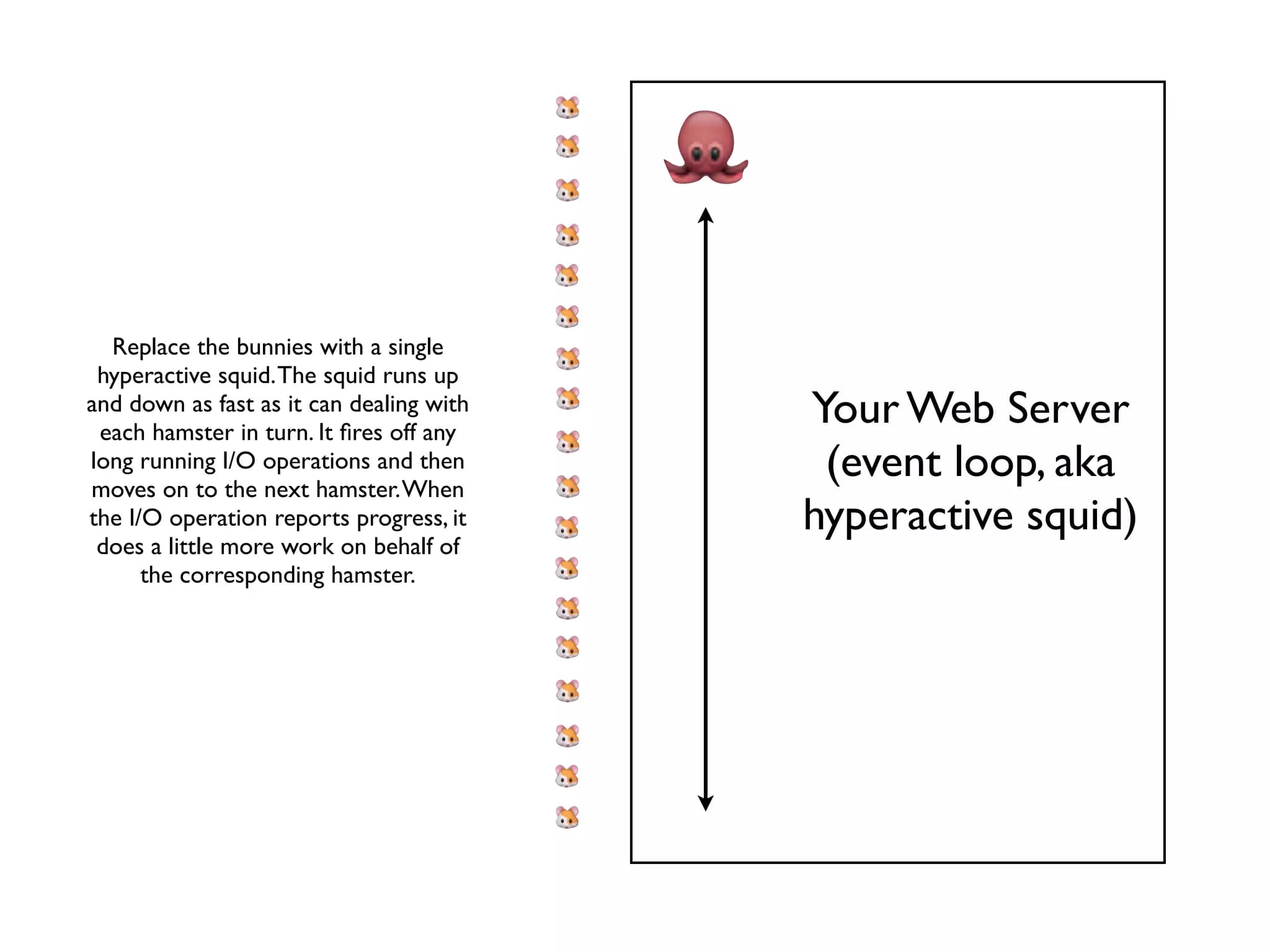
I gave a talk on Friday at Full Frontal, a new one day JavaScript conference in my home town of Brighton. I ended up throwing away my intended topic (JSONP, APIs and cross-domain security) three days before the event in favour of a technology which first crossed my radar less than two weeks ago.
[... 2,025 words]Introducing Resque. A new background worker management queue developed at GitHub, using Redis for the persistence layer. The blog post explains both the design and the shortcomings of previous solutions at length. Within 24 hours of the release code an external developer, Adam Cooke, has completely reskinned the UI.
How We Made GitHub Fast. Detailed overview of the new GitHub architecture. It’s a lot more complicated than I would have expected—lots of moving parts are involved in ensuring they can scale horizontally when they need to. Interesting components include nginx, Unicorn, Rails, DRBD, HAProxy, Redis, Erlang, memcached, SSH, git and a bunch of interesting new open source projects produced by the GitHub team such as BERT/Ernie and ProxyMachine.