43 posts tagged “gpt-4”
2024
I can now run a GPT-4 class model on my laptop

Meta’s new Llama 3.3 70B is a genuinely GPT-4 class Large Language Model that runs on my laptop.
[... 2,905 words]OK, I can partly explain the LLM chess weirdness now
(via)
Last week Dynomight published Something weird is happening with LLMs and chess pointing out that most LLMs are terrible chess players with the exception of gpt-3.5-turbo-instruct (OpenAI's last remaining completion as opposed to chat model, which they describe as "Similar capabilities as GPT-3 era models").
After diving deep into this, Dynomight now has a theory. It's mainly about completion models v.s. chat models - a completion model like gpt-3.5-turbo-instruct naturally outputs good next-turn suggestions, but something about reformatting that challenge as a chat conversation dramatically reduces the quality of the results.
Through extensive prompt engineering Dynomight got results out of GPT-4o that were almost as good as the 3.5 instruct model. The two tricks that had the biggest impact:
- Examples. Including just three examples of inputs (with valid chess moves) and expected outputs gave a huge boost in performance.
- "Regurgitation" - encouraging the model to repeat the entire sequence of previous moves before outputting the next move, as a way to help it reconstruct its context regarding the state of the board.
They experimented a bit with fine-tuning too, but I found their results from prompt engineering more convincing.
No non-OpenAI models have exhibited any talents for chess at all yet. I think that's explained by the A.2 Chess Puzzles section of OpenAI's December 2023 paper Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision:
The GPT-4 pretraining dataset included chess games in the format of move sequence known as Portable Game Notation (PGN). We note that only games with players of Elo 1800 or higher were included in pretraining.
Notes from Bing Chat—Our First Encounter With Manipulative AI

I participated in an Ars Live conversation with Benj Edwards of Ars Technica today, talking about that wild period of LLM history last year when Microsoft launched Bing Chat and it instantly started misbehaving, gaslighting and defaming people.
[... 438 words]Prompt GPT-4o audio. A week and a half ago I built a tool for experimenting with OpenAI's new audio input. I just put together the other side of that, for experimenting with audio output.
Once you've provided an API key (which is saved in localStorage) you can use this to prompt the gpt-4o-audio-preview model with a system and regular prompt and select a voice for the response.
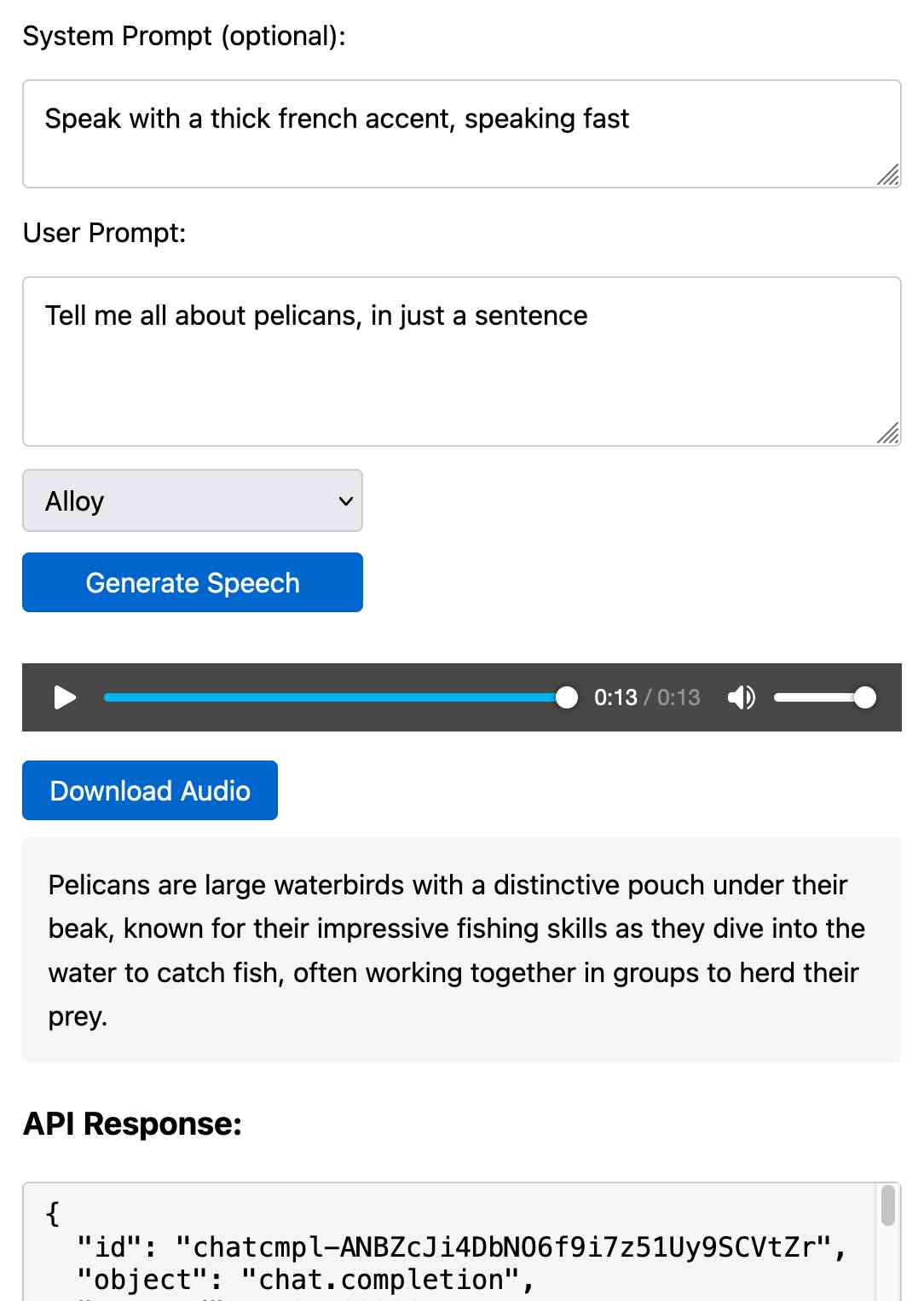
I built it with assistance from Claude: initial app, adding system prompt support.
You can preview and download the resulting wav file, and you can also copy out the raw JSON. If you save that in a Gist you can then feed its Gist ID to https://tools.simonwillison.net/gpt-4o-audio-player?gist=GIST_ID_HERE (Claude transcript) to play it back again.
You can try using that to listen to my French accented pelican description.
There's something really interesting to me here about this form of application which exists entirely as HTML and JavaScript that uses CORS to talk to various APIs. GitHub's Gist API is accessible via CORS too, so it wouldn't take much more work to add a "save" button which writes out a new Gist after prompting for a personal access token. I prototyped that a bit here.
Experimenting with audio input and output for the OpenAI Chat Completion API
OpenAI promised this at DevDay a few weeks ago and now it’s here: their Chat Completion API can now accept audio as input and return it as output. OpenAI still recommend their WebSocket-based Realtime API for audio tasks, but the Chat Completion API is a whole lot easier to write code against.
[... 1,555 words]My @covidsewage bot now includes useful alt text. I've been running a @covidsewage Mastodon bot for a while now, posting daily screenshots (taken with shot-scraper) of the Santa Clara County COVID in wastewater dashboard.
Prior to today the screenshot was accompanied by the decidedly unhelpful alt text "Screenshot of the latest Covid charts".
I finally fixed that today, closing issue #2 more than two years after I first opened it.
The screenshot is of a Microsoft Power BI dashboard. I hoped I could scrape the key information out of it using JavaScript, but the weirdness of their DOM proved insurmountable.
Instead, I'm using GPT-4o - specifically, this Python code (run using a python -c block in the GitHub Actions YAML file):
import base64, openai client = openai.OpenAI() with open('/tmp/covid.png', 'rb') as image_file: encoded_image = base64.b64encode(image_file.read()).decode('utf-8') messages = [ {'role': 'system', 'content': 'Return the concentration levels in the sewersheds - single paragraph, no markdown'}, {'role': 'user', 'content': [ {'type': 'image_url', 'image_url': { 'url': 'data:image/png;base64,' + encoded_image }} ]} ] completion = client.chat.completions.create(model='gpt-4o', messages=messages) print(completion.choices[0].message.content)
I'm base64 encoding the screenshot and sending it with this system prompt:
Return the concentration levels in the sewersheds - single paragraph, no markdown
Given this input image:
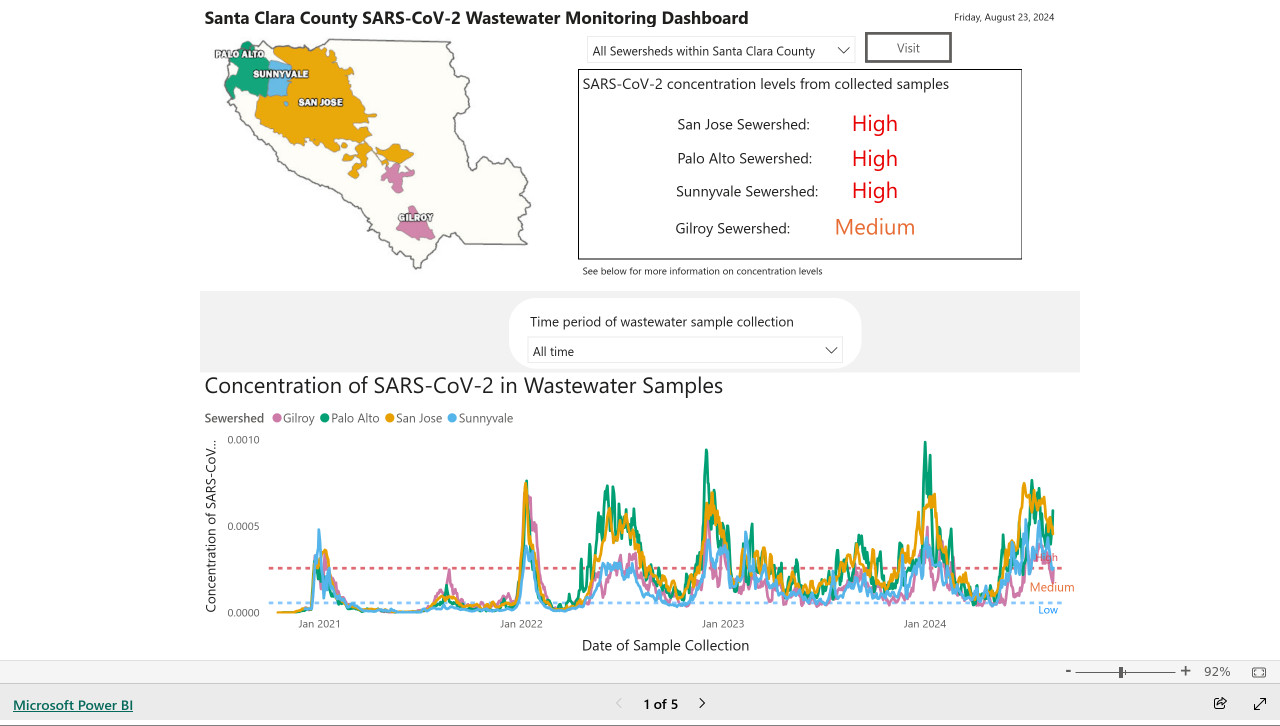
Here's the text that comes back:
The concentration levels of SARS-CoV-2 in the sewersheds from collected samples are as follows: San Jose Sewershed has a high concentration, Palo Alto Sewershed has a high concentration, Sunnyvale Sewershed has a high concentration, and Gilroy Sewershed has a medium concentration.
The full implementation can be found in the GitHub Actions workflow, which runs on a schedule at 7am Pacific time every day.
Using gpt-4o-mini as a reranker. Tip from David Zhang: "using gpt-4-mini as a reranker gives you better results, and now with strict mode it's just as reliable as any other reranker model".
David's code here demonstrates the Vercel AI SDK for TypeScript, and its support for structured data using Zod schemas.
const res = await generateObject({
model: gpt4MiniModel,
prompt: `Given the list of search results, produce an array of scores measuring the liklihood of the search result containing information that would be useful for a report on the following objective: ${objective}\n\nHere are the search results:\n<results>\n${resultsString}\n</results>`,
system: systemMessage(),
schema: z.object({
scores: z
.object({
reason: z
.string()
.describe(
'Think step by step, describe your reasoning for choosing this score.',
),
id: z.string().describe('The id of the search result.'),
score: z
.enum(['low', 'medium', 'high'])
.describe(
'Score of relevancy of the result, should be low, medium, or high.',
),
})
.array()
.describe(
'An array of scores. Make sure to give a score to all ${results.length} results.',
),
}),
});It's using the trick where you request a reason key prior to the score, in order to implement chain-of-thought - see also Matt Webb's Braggoscope Prompts.
Accidental GPT-4o voice preview (via) Reddit user RozziTheCreator was one of a small group who were accidentally granted access to the new multimodal GPT-4o audio voice feature. They captured this video of it telling them a spooky story, complete with thunder sound effects added to the background and in a very realistic voice that clearly wasn't the one from the 4o demo that sounded similar to Scarlet Johansson.
OpenAI provided a comment for this Tom's Guide story confirming the accidental rollout so I don't think this is a faked video.
A Picture is Worth 170 Tokens: How Does GPT-4o Encode Images? (via) Oran Looney dives into the question of how GPT-4o tokenizes images - an image "costs" just 170 tokens, despite being able to include more text than could be encoded in that many tokens by the standard tokenizer.
There are some really neat tricks in here. I particularly like the experimental validation section where Oran creates 5x5 (and larger) grids of coloured icons and asks GPT-4o to return a JSON matrix of icon descriptions. This works perfectly at 5x5, gets 38/49 for 7x7 and completely fails at 13x13.
I'm not convinced by the idea that GPT-4o runs standard OCR such as Tesseract to enhance its ability to interpret text, but I would love to understand more about how this all works. I imagine a lot can be learned from looking at how openly licensed vision models such as LLaVA work, but I've not tried to understand that myself yet.
Extracting Concepts from GPT-4. A few weeks ago Anthropic announced they had extracted millions of understandable features from their Claude 3 Sonnet model.
Today OpenAI are announcing a similar result against GPT-4:
We used new scalable methods to decompose GPT-4’s internal representations into 16 million oft-interpretable patterns.
These features are "patterns of activity that we hope are human interpretable". The release includes code and a paper, Scaling and evaluating sparse autoencoders paper (PDF) which credits nine authors, two of whom - Ilya Sutskever and Jan Leike - are high profile figures that left OpenAI within the past month.
The most fun part of this release is the interactive tool for exploring features. This highlights some interesting features on the homepage, or you can hit the "I'm feeling lucky" button to bounce to a random feature. The most interesting I've found so far is feature 5140 which seems to combine God's approval, telling your doctor about your prescriptions and information passed to the Admiralty.
This note shown on the explorer is interesting:
Only 65536 features available. Activations shown on The Pile (uncopyrighted) instead of our internal training dataset.
Here's the full Pile Uncopyrighted, which I hadn't seen before. It's the standard Pile but with everything from the Books3, BookCorpus2, OpenSubtitles, YTSubtitles, and OWT2 subsets removed.
Hello GPT-4o. OpenAI announced a new model today: GPT-4o, where the o stands for "omni".
It looks like this is the gpt2-chatbot we've been seeing in the Chat Arena the past few weeks.
GPT-4o doesn't seem to be a huge leap ahead of GPT-4 in terms of "intelligence" - whatever that might mean - but it has a bunch of interesting new characteristics.
First, it's multi-modal across text, images and audio as well. The audio demos from this morning's launch were extremely impressive.
ChatGPT's previous voice mode worked by passing audio through a speech-to-text model, then an LLM, then a text-to-speech for the output. GPT-4o does everything with the one model, reducing latency to the point where it can act as a live interpreter between people speaking in two different languages. It also has the ability to interpret tone of voice, and has much more control over the voice and intonation it uses in response.
It's very science fiction, and has hints of uncanny valley. I can't wait to try it out - it should be rolling out to the various OpenAI apps "in the coming weeks".
Meanwhile the new model itself is already available for text and image inputs via the API and in the Playground interface, as model ID "gpt-4o" or "gpt-4o-2024-05-13". My first impressions are that it feels notably faster than gpt-4-turbo.
This announcement post also includes examples of image output from the new model. It looks like they may have taken big steps forward in two key areas of image generation: output of text (the "Poetic typography" examples) and maintaining consistent characters across multiple prompts (the "Character design - Geary the robot" example).
The size of the vocabulary of the tokenizer - effectively the number of unique integers used to represent text - has increased to ~200,000 from ~100,000 for GPT-4 and GPT-3.5. Inputs in Gujarati use 4.4x fewer tokens, Japanese uses 1.4x fewer, Spanish uses 1.1x fewer. Previously languages other than English paid a material penalty in terms of how much text could fit into a prompt, it's good to see that effect being reduced.
Also notable: the price. OpenAI claim a 50% price reduction compared to GPT-4 Turbo. Conveniently, gpt-4o costs exactly 10x gpt-3.5: 4o is $5/million input tokens and $15/million output tokens. 3.5 is $0.50/million input tokens and $1.50/million output tokens.
(I was a little surprised not to see a price decrease there to better compete with the less expensive Claude 3 Haiku.)
The price drop is particularly notable because OpenAI are promising to make this model available to free ChatGPT users as well - the first time they've directly made their "best" model available to non-paying customers.
Tucked away right at the end of the post:
We plan to launch support for GPT-4o's new audio and video capabilities to a small group of trusted partners in the API in the coming weeks.
I'm looking forward to learning more about these video capabilities, which were hinted at by some of the live demos in this morning's presentation.
Extracting data from unstructured text and images with Datasette and GPT-4 Turbo. Datasette Extract is a new Datasette plugin that uses GPT-4 Turbo (released to general availability today) and GPT-4 Vision to extract structured data from unstructured text and images.
I put together a video demo of the plugin in action today, and posted it to the Datasette Cloud blog along with screenshots and a tutorial describing how to use it.
“The king is dead”—Claude 3 surpasses GPT-4 on Chatbot Arena for the first time. I’m quoted in this piece by Benj Edwards for Ars Technica:
“For the first time, the best available models—Opus for advanced tasks, Haiku for cost and efficiency—are from a vendor that isn’t OpenAI. That’s reassuring—we all benefit from a diversity of top vendors in this space. But GPT-4 is over a year old at this point, and it took that year for anyone else to catch up.”
In every group I speak to, from business executives to scientists, including a group of very accomplished people in Silicon Valley last night, much less than 20% of the crowd has even tried a GPT-4 class model.
Less than 5% has spent the required 10 hours to know how they tick.
The GPT-4 barrier has finally been broken
Four weeks ago, GPT-4 remained the undisputed champion: consistently at the top of every key benchmark, but more importantly the clear winner in terms of “vibes”. Almost everyone investing serious time exploring LLMs agreed that it was the most capable default model for the majority of tasks—and had been for more than a year.
[... 717 words]Inflection-2.5: meet the world’s best personal AI (via) I’ve not been paying much attention to Inflection’s Pi since it released last year, but yesterday they released a new version that they claim is competitive with GPT-4.
“Inflection-2.5 approaches GPT-4’s performance, but used only 40% of the amount of compute for training.”
(I wasn’t aware that the compute used to train GPT-4 was public knowledge.)
If this holds true, that means that the GPT-4 barrier has been well and truly smashed: we now have Claude 3 Opus, Gemini 1.5, Mistral Large and Inflection-2.5 in the same class as GPT-4, up from zero contenders just a month ago.
The new Claude 3 model family from Anthropic. Claude 3 is out, and comes in three sizes: Opus (the largest), Sonnet and Haiku.
Claude 3 Opus has self-reported benchmark scores that consistently beat GPT-4. This is a really big deal: in the 12+ months since the GPT-4 release no other model has consistently beat it in this way. It’s exciting to finally see that milestone reached by another research group.
The pricing model here is also really interesting. Prices here are per-million-input-tokens / per-million-output-tokens:
Claude 3 Opus: $15 / $75
Claude 3 Sonnet: $3 / $15
Claude 3 Haiku: $0.25 / $1.25
All three models have a 200,000 length context window and support image input in addition to text.
Compare with today’s OpenAI prices:
GPT-4 Turbo (128K): $10 / $30
GPT-4 8K: $30 / $60
GPT-4 32K: $60 / $120
GPT-3.5 Turbo: $0.50 / $1.50
So Opus pricing is comparable with GPT-4, more than GPT-4 Turbo and significantly cheaper than GPT-4 32K... Sonnet is cheaper than all of the GPT-4 models (including GPT-4 Turbo), and Haiku (which has not yet been released to the Claude API) will be cheaper even than GPT-3.5 Turbo.
It will be interesting to see if OpenAI respond with their own price reductions.
Google’s Gemini Advanced: Tasting Notes and Implications. Ethan Mollick reviews the new Google Gemini Advanced—a rebranded Bard, released today, that runs on the GPT-4 competitive Gemini Ultra model.
“GPT-4 [...] has been the dominant AI for well over a year, and no other model has come particularly close. Prior to Gemini, we only had one advanced AI model to look at, and it is hard drawing conclusions with a dataset of one. Now there are two, and we can learn a few things.”
I like Ethan’s use of the term “tasting notes” here. Reminds me of how Matt Webb talks about being a language model sommelier.
2023
gpt-4-turbo over the API produces (statistically significant) shorter completions when it "thinks" its December vs. when it thinks its May (as determined by the date in the system prompt).
I took the same exact prompt over the API (a code completion task asking to implement a machine learning task without libraries).
I created two system prompts, one that told the API it was May and another that it was December and then compared the distributions.
For the May system prompt, mean = 4298 For the December system prompt, mean = 4086
N = 477 completions in each sample from May and December
t-test p < 2.28e-07
Mixtral of experts (via) Mistral have firmly established themselves as the most exciting AI lab outside of OpenAI, arguably more exciting because much of their work is released under open licenses.
On December 8th they tweeted a link to a torrent, with no additional context (a neat marketing trick they’ve used in the past). The 87GB torrent contained a new model, Mixtral-8x7b-32kseqlen—a Mixture of Experts.
Three days later they published a full write-up, describing “Mixtral 8x7B, a high-quality sparse mixture of experts model (SMoE) with open weights”—licensed Apache 2.0.
They claim “Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference”—and that it outperforms GPT-3.5 on most benchmarks too.
This isn’t even their current best model. The new Mistral API platform (currently on a waitlist) refers to Mixtral as “Mistral-small” (and their previous 7B model as “Mistral-tiny”—and also provides access to a currently closed model, “Mistral-medium”, which they claim to be competitive with GPT-4.
When I speak in front of groups and ask them to raise their hands if they used the free version of ChatGPT, almost every hand goes up. When I ask the same group how many use GPT-4, almost no one raises their hand. I increasingly think the decision of OpenAI to make the “bad” AI free is causing people to miss why AI seems like such a huge deal to a minority of people that use advanced systems and elicits a shrug from everyone else.
Ice Cubes GPT-4 prompts. The Ice Cubes open source Mastodon app recently grew a very good "describe this image" feature to help people add alt text to their images. I had a dig around in their repo and it turns out they're using GPT-4 Vision for this (and regular GPT-4 for other features), passing the image with this prompt:
What’s in this image? Be brief, it's for image alt description on a social network. Don't write in the first person.
tldraw/draw-a-ui (via) Absolutely spectacular GPT-4 Vision API demo. Sketch out a rough UI prototype using the open source tldraw drawing app, then select a set of components and click "Make Real" (after giving it an OpenAI API key). It generates a PNG snapshot of your selection and sends that to GPT-4 with instructions to turn it into a Tailwind HTML+JavaScript prototype, then adds the result as an iframe next to your mockup.
You can then make changes to your mockup, select it and the previous mockup and click "Make Real" again to ask for an updated version that takes your new changes into account.
This is such a great example of innovation at the UI layer, and everything is open source. Check app/lib/getHtmlFromOpenAI.ts for the system prompt that makes it work.
ospeak: a CLI tool for speaking text in the terminal via OpenAI
I attended OpenAI DevDay today, the first OpenAI developer conference. It was a lot. They released a bewildering array of new API tools, which I’m just beginning to wade my way through fully understanding.
[... 1,109 words]Multi-modal prompt injection image attacks against GPT-4V
GPT4-V is the new mode of GPT-4 that allows you to upload images as part of your conversations. It’s absolutely brilliant. It also provides a whole new set of vectors for prompt injection attacks.
[... 889 words]Translating Latin demonology manuals with GPT-4 and Claude (via) UC Santa Cruz history professor Benjamin Breen puts LLMs to work on historical texts. They do an impressive job of translating flaky OCRd text from 1599 Latin and 1707 Portuguese.
“It’s not about getting the AI to replace you. Instead, it’s asking the AI to act as a kind of polymathic research assistant to supply you with leads.”
Llama 2 is about as factually accurate as GPT-4 for summaries and is 30X cheaper. Anyscale offer (cheap, fast) API access to Llama 2, so they’re not an unbiased source of information—but I really hope their claim here that Llama 2 70B provides almost equivalent summarization quality to GPT-4 holds up. Summarization is one of my favourite applications of LLMs, partly because it’s key to being able to implement Retrieval Augmented Generation against your own documents—where snippets of relevant documents are fed to the model and used to answer a user’s question. Having a really high performance openly licensed summarization model is a very big deal.
airoboros LMoE. airoboros provides a system for fine-tuning Large Language Models. The latest release adds support for LMoE—LoRA Mixture of Experts. GPT-4 is strongly rumoured to work as a mixture of experts—several (maybe 8?) 220B models each with a different specialty working together to produce the best result. This is the first open source (Apache 2) implementation of that pattern that I’ve seen.
Study claims ChatGPT is losing capability, but some experts aren’t convinced. Benj Edwards talks about the ongoing debate as to whether or not GPT-4 is getting weaker over time. I remain skeptical of those claims—I think it’s more likely that people are seeing more of the flaws now that the novelty has worn off.
I’m quoted in this piece: “Honestly, the lack of release notes and transparency may be the biggest story here. How are we meant to build dependable software on top of a platform that changes in completely undocumented and mysterious ways every few months?”
OpenAI: Function calling and other API updates. Huge set of announcements from OpenAI today. A bunch of price reductions, but the things that most excite me are the new gpt-3.5-turbo-16k model which offers a 16,000 token context limit (4x the existing 3.5 turbo model) at a price of $0.003 per 1K input tokens and $0.004 per 1K output tokens—1/10th the price of GPT-4 8k.
The other big new feature: functions! You can now send JSON schema defining one or more functions to GPT 3.5 and GPT-4—those models will then return a blob of JSON describing a function they want you to call (if they determine that one should be called). Your code executes the function and passes the results back to the model to continue the execution flow.
This is effectively an implementation of the ReAct pattern, with models that have been fine-tuned to execute it.
They acknowledge the risk of prompt injection (though not by name) in the post: “We are working to mitigate these and other risks. Developers can protect their applications by only consuming information from trusted tools and by including user confirmation steps before performing actions with real-world impact, such as sending an email, posting online, or making a purchase.”