Posts tagged python, projects
Filters: python × projects × Sorted by date
llm-mistral 0.14. I added tool-support to my plugin for accessing the Mistral API from LLM today, plus support for Mistral's new Codestral Embed embedding model.
An interesting challenge here is that I'm not using an official client library for llm-mistral - I rolled my own client on top of their streaming HTTP API using Florimond Manca's httpx-sse library. It's a very pleasant way to interact with streaming APIs - here's my code that does most of the work.
The problem I faced is that Mistral's API documentation for function calling has examples in Python and TypeScript but doesn't include curl or direct documentation of their HTTP endpoints!
I needed documentation at the HTTP level. Could I maybe extract that directly from Mistral's official Python library?
It turns out I could. I started by cloning the repo:
git clone https://github.com/mistralai/client-python
cd client-python/src/mistralai
files-to-prompt . | ttokMy ttok tool gave me a token count of 212,410 (counted using OpenAI's tokenizer, but that's normally a close enough estimate) - Mistral's models tap out at 128,000 so I switched to Gemini 2.5 Flash which can easily handle that many.
I ran this:
files-to-prompt -c . > /tmp/mistral.txt
llm -f /tmp/mistral.txt \
-m gemini-2.5-flash-preview-05-20 \
-s 'Generate comprehensive HTTP API documentation showing
how function calling works, include example curl commands for each step'The results were pretty spectacular! Gemini 2.5 Flash produced a detailed description of the exact set of HTTP APIs I needed to interact with, and the JSON formats I should pass to them.
There are a bunch of steps needed to get tools working in a new model, as described in the LLM plugin authors documentation. I started working through them by hand... and then got lazy and decided to see if I could get a model to do the work for me.
This time I tried the new Claude Opus 4. I fed it three files: my existing, incomplete llm_mistral.py, a full copy of llm_gemini.py with its working tools implementation and a copy of the API docs Gemini had written for me earlier. I prompted:
I need to update this Mistral code to add tool support. I've included examples of that code for Gemini, and a detailed README explaining the Mistral format.
Claude churned away and wrote me code that was most of what I needed. I tested it in a bunch of different scenarios, pasted problems back into Claude to see what would happen, and eventually took over and finished the rest of the code myself. Here's the full transcript.
I'm a little sad I didn't use Mistral to write the code to support Mistral, but I'm pleased to add yet another model family to the list that's supported for tool usage in LLM.
files-to-prompt 0.5.
My files-to-prompt tool (originally built using Claude 3 Opus back in April) had been accumulating a bunch of issues and PRs - I finally got around to spending some time with it and pushed a fresh release:
- New
-n/--line-numbersflag for including line numbers in the output. Thanks, Dan Clayton. #38- Fix for utf-8 handling on Windows. Thanks, David Jarman. #36
--ignorepatterns are now matched against directory names as well as file names, unless you pass the new--ignore-files-onlyflag. Thanks, Nick Powell. #30
I use this tool myself on an almost daily basis - it's fantastic for quickly answering questions about code. Recently I've been plugging it into Gemini 2.0 with its 2 million token context length, running recipes like this one:
git clone https://github.com/bytecodealliance/componentize-py
cd componentize-py
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'How does this work? Does it include a python compiler or AST trick of some sort?'
I ran that question against the bytecodealliance/componentize-py repo - which provides a tool for turning Python code into compiled WASM - and got this really useful answer.
Here's another example. I decided to have o3-mini review how Datasette handles concurrent SQLite connections from async Python code - so I ran this:
git clone https://github.com/simonw/datasette
cd datasette/datasette
files-to-prompt database.py utils/__init__.py -c | \
llm -m o3-mini -o reasoning_effort high \
-s 'Output in markdown a detailed analysis of how this code handles the challenge of running SQLite queries from a Python asyncio application. Explain how it works in the first section, then explore the pros and cons of this design. In a final section propose alternative mechanisms that might work better.'
Here's the result. It did an extremely good job of explaining how my code works - despite being fed just the Python and none of the other documentation. Then it made some solid recommendations for potential alternatives.
I added a couple of follow-up questions (using llm -c) which resulted in a full working prototype of an alternative threadpool mechanism, plus some benchmarks.
One final example: I decided to see if there were any undocumented features in Litestream, so I checked out the repo and ran a prompt against just the .go files in that project:
git clone https://github.com/benbjohnson/litestream
cd litestream
files-to-prompt . -e go -c | llm -m o3-mini \
-s 'Write extensive user documentation for this project in markdown'
Once again, o3-mini provided a really impressively detailed set of unofficial documentation derived purely from reading the source.
shot-scraper 1.6 with support for HTTP Archives. New release of my shot-scraper CLI tool for taking screenshots and scraping web pages.
The big new feature is HTTP Archive (HAR) support. The new shot-scraper har command can now create an archive of a page and all of its dependents like this:
shot-scraper har https://datasette.io/
This produces a datasette-io.har file (currently 163KB) which is JSON representing the full set of requests used to render that page. Here's a copy of that file. You can visualize that here using ericduran.github.io/chromeHAR.
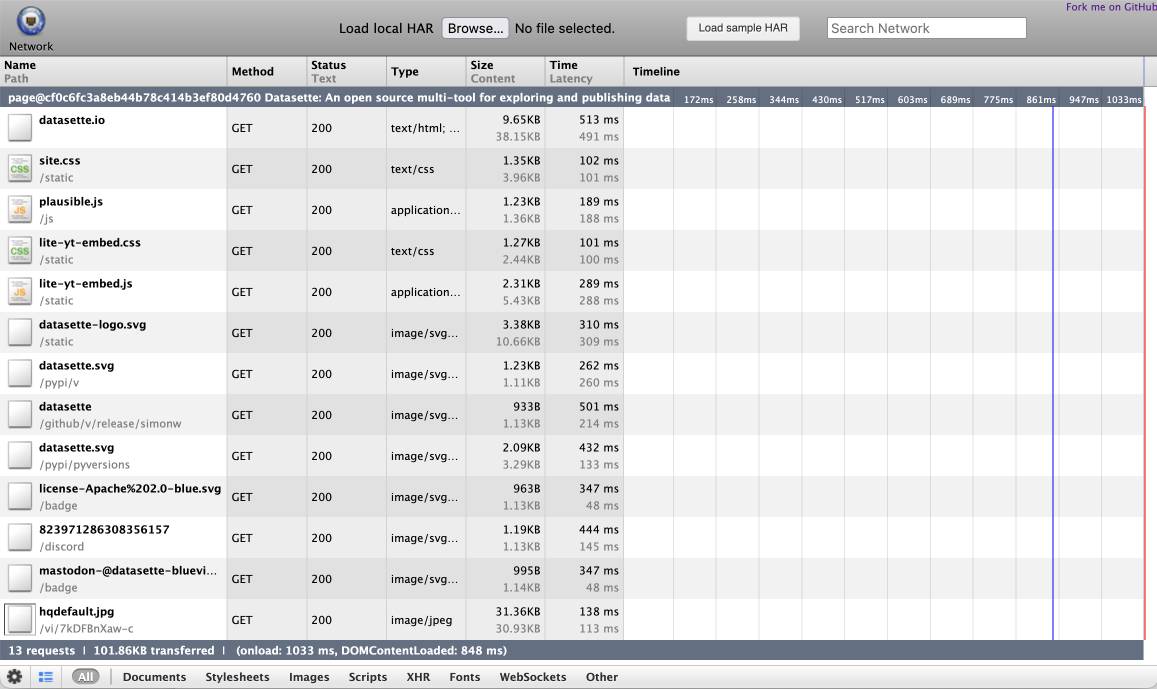
That JSON includes full copies of all of the responses, base64 encoded if they are binary files such as images.
You can add the --zip flag to instead get a datasette-io.har.zip file, containing JSON data in har.har but with the response bodies saved as separate files in that archive.
The shot-scraper multi command lets you run shot-scraper against multiple URLs in sequence, specified using a YAML file. That command now takes a --har option (or --har-zip or --har-file name-of-file), described in the documentation, which will produce a HAR at the same time as taking the screenshots.
Shots are usually defined in YAML that looks like this:
- output: example.com.png
url: http://www.example.com/
- output: w3c.org.png
url: https://www.w3.org/You can now omit the output: keys and generate a HAR file without taking any screenshots at all:
- url: http://www.example.com/
- url: https://www.w3.org/Run like this:
shot-scraper multi shots.yml --har
Which outputs:
Skipping screenshot of 'https://www.example.com/'
Skipping screenshot of 'https://www.w3.org/'
Wrote to HAR file: trace.har
shot-scraper is built on top of Playwright, and the new features use the browser.new_context(record_har_path=...) parameter.
Using pip to install a Large Language Model that’s under 100MB
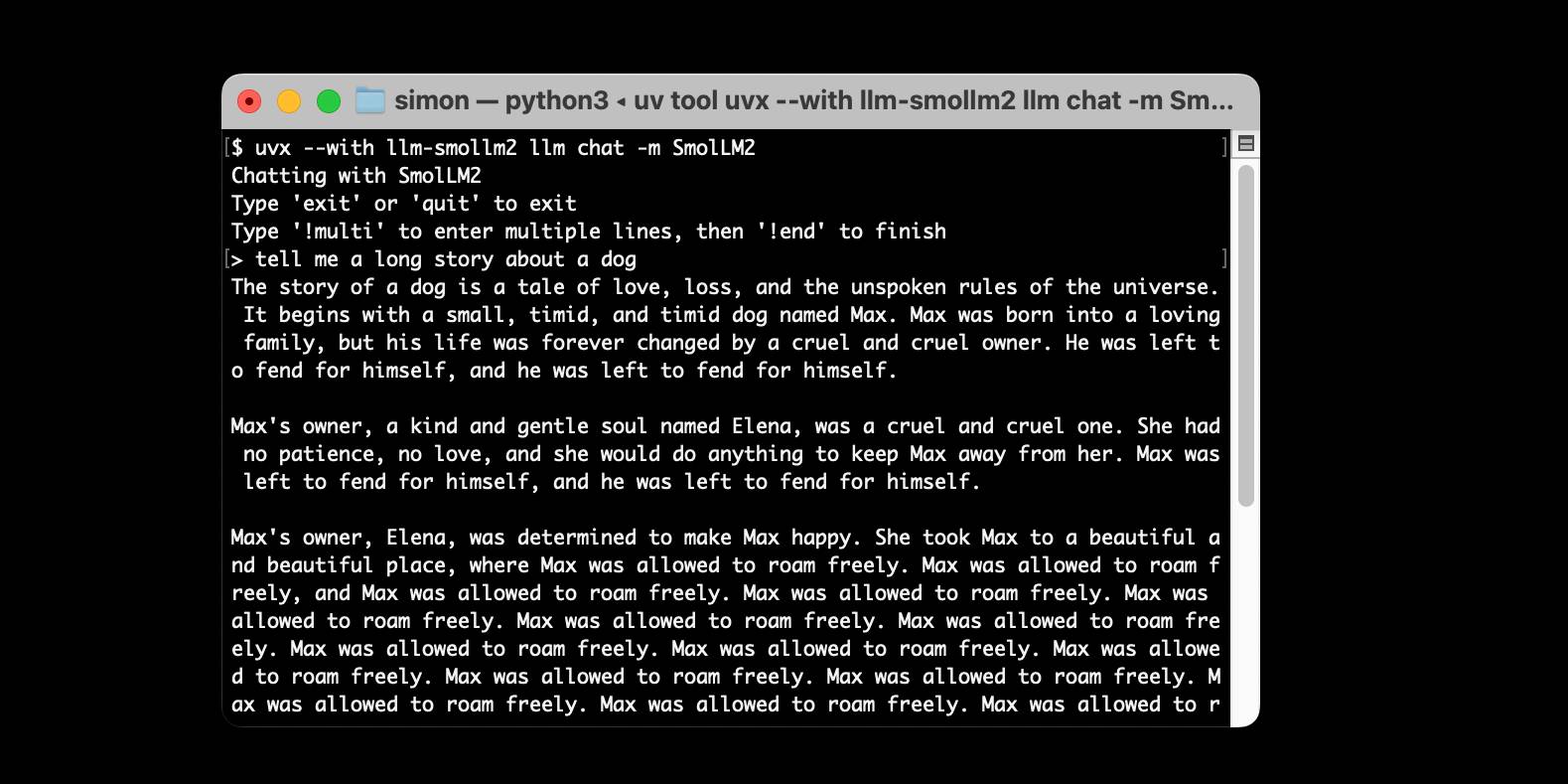
I just released llm-smollm2, a new plugin for LLM that bundles a quantized copy of the SmolLM2-135M-Instruct LLM inside of the Python package.
[... 1,553 words]llm-gemini 0.4.
New release of my llm-gemini plugin, adding support for asynchronous models (see LLM 0.18), plus the new gemini-exp-1114 model (currently at the top of the Chatbot Arena) and a -o json_object 1 option to force JSON output.
I also released llm-claude-3 0.9 which adds asynchronous support for the Claude family of models.
LLM 0.18. New release of LLM. The big new feature is asynchronous model support - you can now use supported models in async Python code like this:
import llm
model = llm.get_async_model("gpt-4o")
async for chunk in model.prompt(
"Five surprising names for a pet pelican"
):
print(chunk, end="", flush=True)
Also new in this release: support for sending audio attachments to OpenAI's gpt-4o-audio-preview model.
files-to-prompt 0.4. New release of my files-to-prompt tool adding an option for filtering just for files with a specific extension.
The following command will output Claude XML-style markup for all Python and Markdown files in the current directory, and copy that to the macOS clipboard ready to be pasted into an LLM:
files-to-prompt . -e py -e md -c | pbcopy
Datasette 0.65. Python 3.13 was released today, which broke compatibility with the Datasette 0.x series due to an issue with an underlying dependency. I've fixed that problem by vendoring and fixing the dependency and the new 0.65 release works on Python 3.13 (but drops support for Python 3.8, which is EOL this month). Datasette 1.0a16 added support for Python 3.13 last month.
simonw/docs cookiecutter template. Over the last few years I’ve settled on the combination of Sphinx, the Furo theme and the myst-parser extension (enabling Markdown in place of reStructuredText) as my documentation toolkit of choice, maintained in GitHub and hosted using ReadTheDocs.
My LLM and shot-scraper projects are two examples of that stack in action.
Today I wanted to spin up a new documentation site so I finally took the time to construct a cookiecutter template for my preferred configuration. You can use it like this:
pipx install cookiecutter
cookiecutter gh:simonw/docs
Or with uv:
uv tool run cookiecutter gh:simonw/docs
Answer a few questions:
[1/3] project (): shot-scraper
[2/3] author (): Simon Willison
[3/3] docs_directory (docs):
And it creates a docs/ directory ready for you to start editing docs:
cd docs
pip install -r requirements.txt
make livehtml
Upgrading my cookiecutter templates to use python -m pytest.
Every now and then I get caught out by weird test failures when I run pytest and it turns out I'm running the wrong installation of that tool, so my tests fail because that pytest is executing in a different virtual environment from the one needed by the tests.
The fix for this is easy: run python -m pytest instead, which guarantees that you will run pytest in the same environment as your currently active Python.
Yesterday I went through and updated every one of my cookiecutter templates (python-lib, click-app, datasette-plugin, sqlite-utils-plugin, llm-plugin) to use this pattern in their READMEs and generated repositories instead, to help spread that better recipe a little bit further.
django-http-debug, a new Django app mostly written by Claude
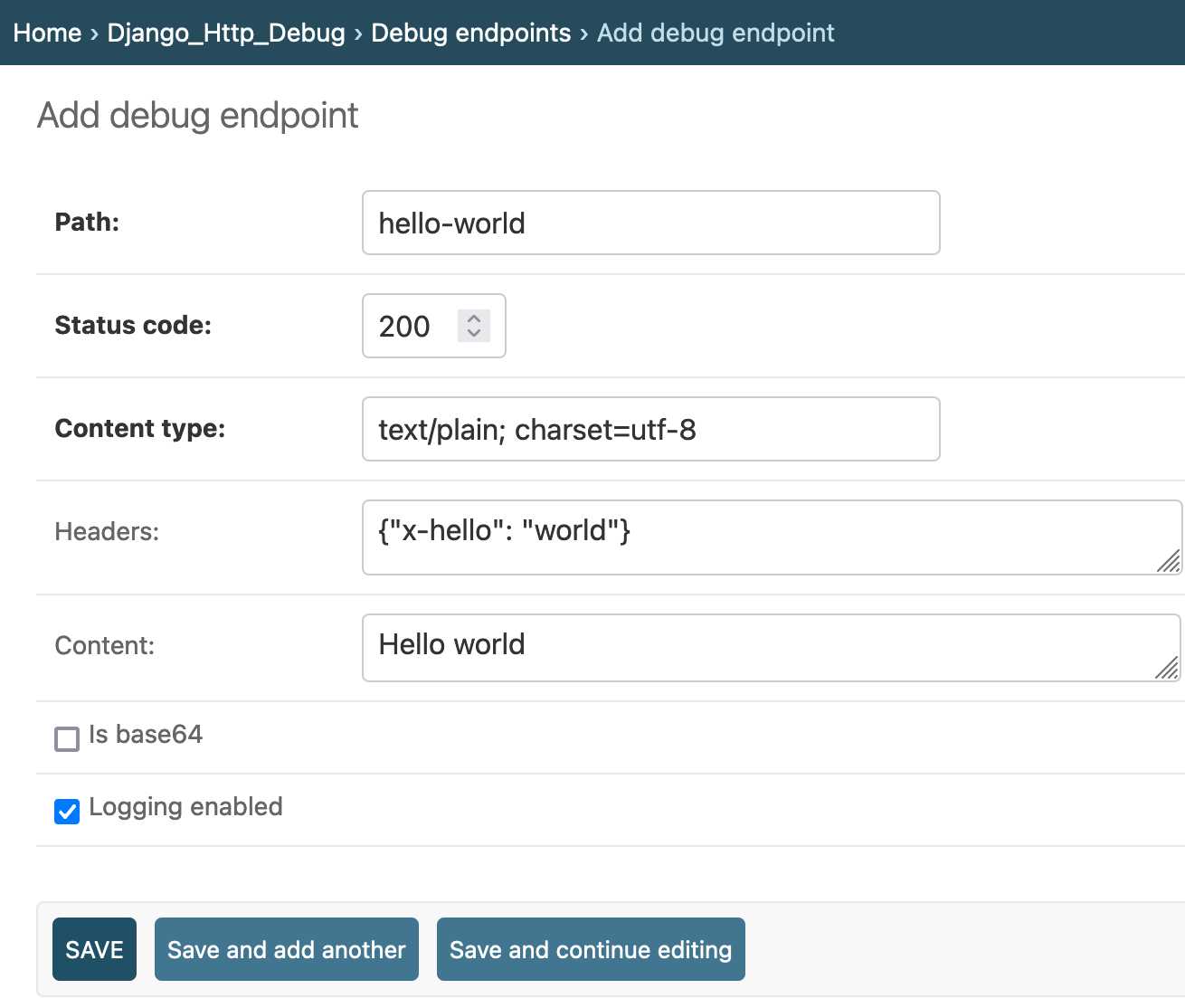
Yesterday I finally developed something I’ve been casually thinking about building for a long time: django-http-debug. It’s a reusable Django app—something you can pip install into any Django project—which provides tools for quickly setting up a URL that returns a canned HTTP response and logs the full details of any incoming request to a database table.
datasette-python.
I just released a small new plugin for Datasette to assist with debugging. It adds a python subcommand which runs a Python process in the same virtual environment as Datasette itself.
I built it initially to help debug some issues in Datasette installed via Homebrew. The Homebrew installation has its own virtual environment, and sometimes it can be useful to run commands like pip list in the same environment as Datasette itself.
Now you can do this:
brew install datasette
datasette install datasette-python
datasette python -m pip list
I built a similar plugin for LLM last year, called llm-python - it's proved useful enough that I duplicated the design for Datasette.
llm-claude-3. I built a new plugin for LLM—my command-line tool and Python library for interacting with Large Language Models—which adds support for the new Claude 3 models from Anthropic.
datasette-studio. I've been thinking for a while that it might be interesting to have a version of Datasette that comes bundled with a set of useful plugins, aimed at expanding Datasette's default functionality to cover things like importing data and editing schemas.
This morning I built the very first experimental preview of what that could look like. Install it using pipx:
pipx install datasette-studio
I recommend pipx because it will ensure datasette-studio gets its own isolated environment, independent of any other Datasette installations you might have.
Now running datasette-studio instead of datasette will get you the version with the bundled plugins.
The implementation of this is fun - it's a single pyproject.toml file defining the dependencies and setting up the datasette-studio CLI hook, which is enough to provide the full set of functionality.
Is this a good idea? I don't know yet, but it's certainly an interesting initial experiment.
Publish Python packages to PyPI with a python-lib cookiecutter template and GitHub Actions
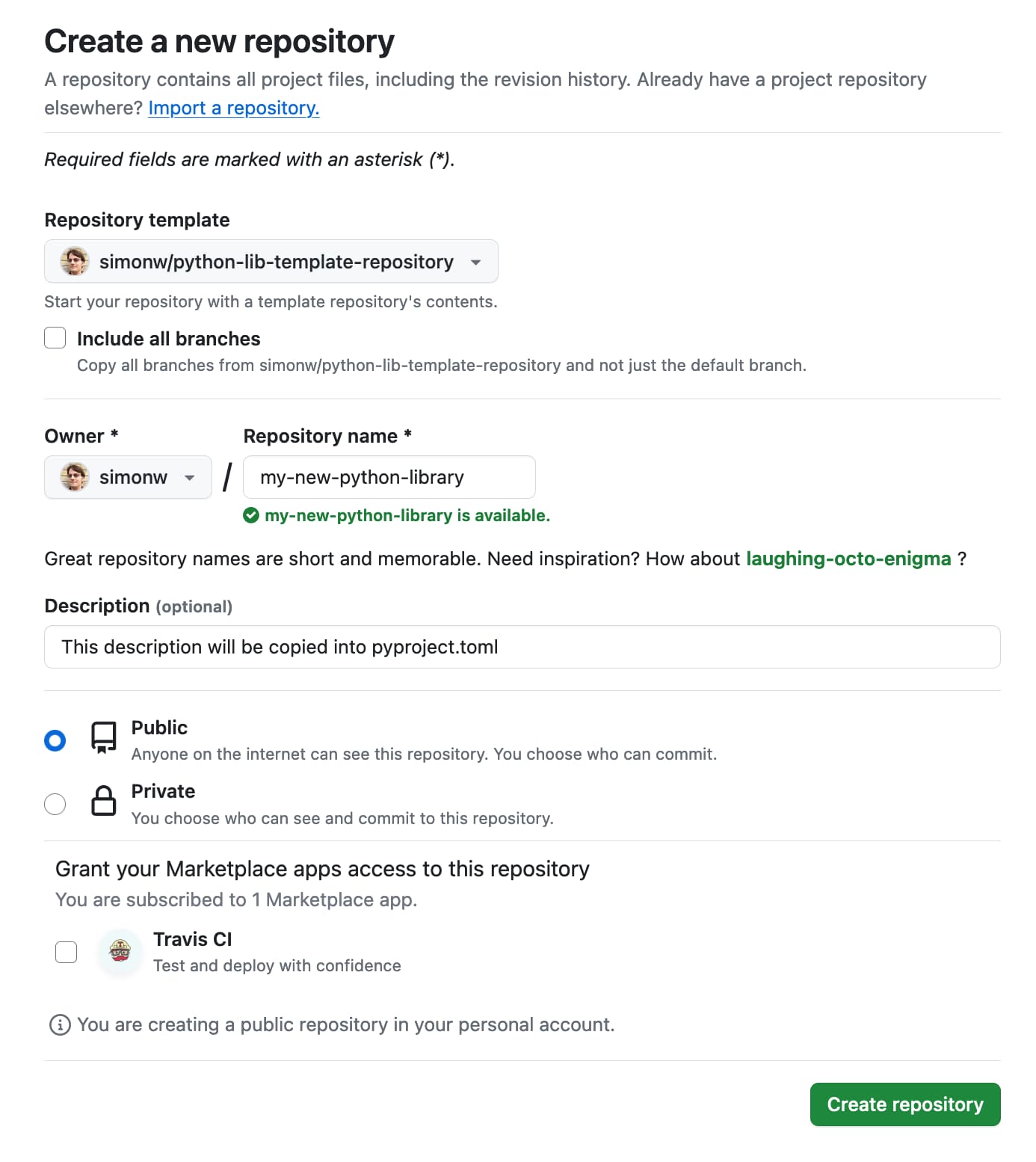
I use cookiecutter to start almost all of my Python projects. It helps me quickly generate a skeleton of a project with my preferred directory structure and configured tools.
[... 686 words]Symbex: search Python code for functions and classes, then pipe them into a LLM
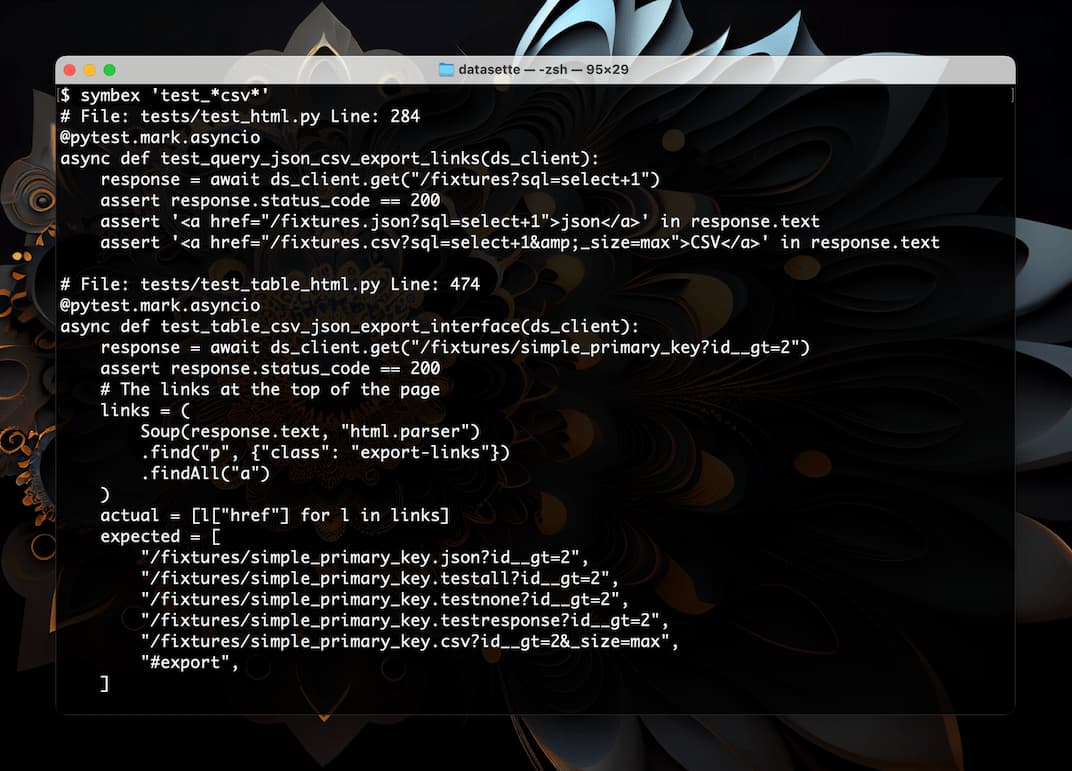
I just released a new Python CLI tool called Symbex. It’s a search tool, loosely inspired by ripgrep, which lets you search Python code for functions and classes by name or wildcard, then see just the source code of those matching entities.
[... 1,183 words]Trogon (via) The latest project from the Textualize/Rich crew, Trogon provides a Python decorator—@tui—which, when applied to a Click CLI application, adds a new interactive TUI mode which introspects the available subcommands and their options and creates a full Text User Interface—with keyboard and mouse support—for assembling invocations of those various commands.
I just shipped sqlite-utils 3.32 with support for this—it uses an optional dependency, so you’ll need to run “sqlite-utils install trogon” and then “sqlite-utils tui” to try it out.
Weeknotes: sqlite-utils 3.31, download-esm, Python in a sandbox
A couple of speaking appearances last week—one planned, one unplanned. Plus sqlite-utils 3.31, download-esm and a new TIL.
A simple Python implementation of the ReAct pattern for LLMs. I implemented the ReAct pattern (for Reason+Act) described in this paper. It's a pattern where you implement additional actions that an LLM can take - searching Wikipedia or running calculations for example - and then teach it how to request that those actions are run, then feed their results back into the LLM.
Weeknotes: Datasette Lite, nogil Python, HYTRADBOI
My big project this week was Datasette Lite, a new way to run Datasette directly in a browser, powered by WebAssembly and Pyodide. I also continued my research into running SQL queries in parallel, described last week. Plus I spoke at HYTRADBOI.
[... 1,434 words]Datasette Lite: a server-side Python web application running in a browser
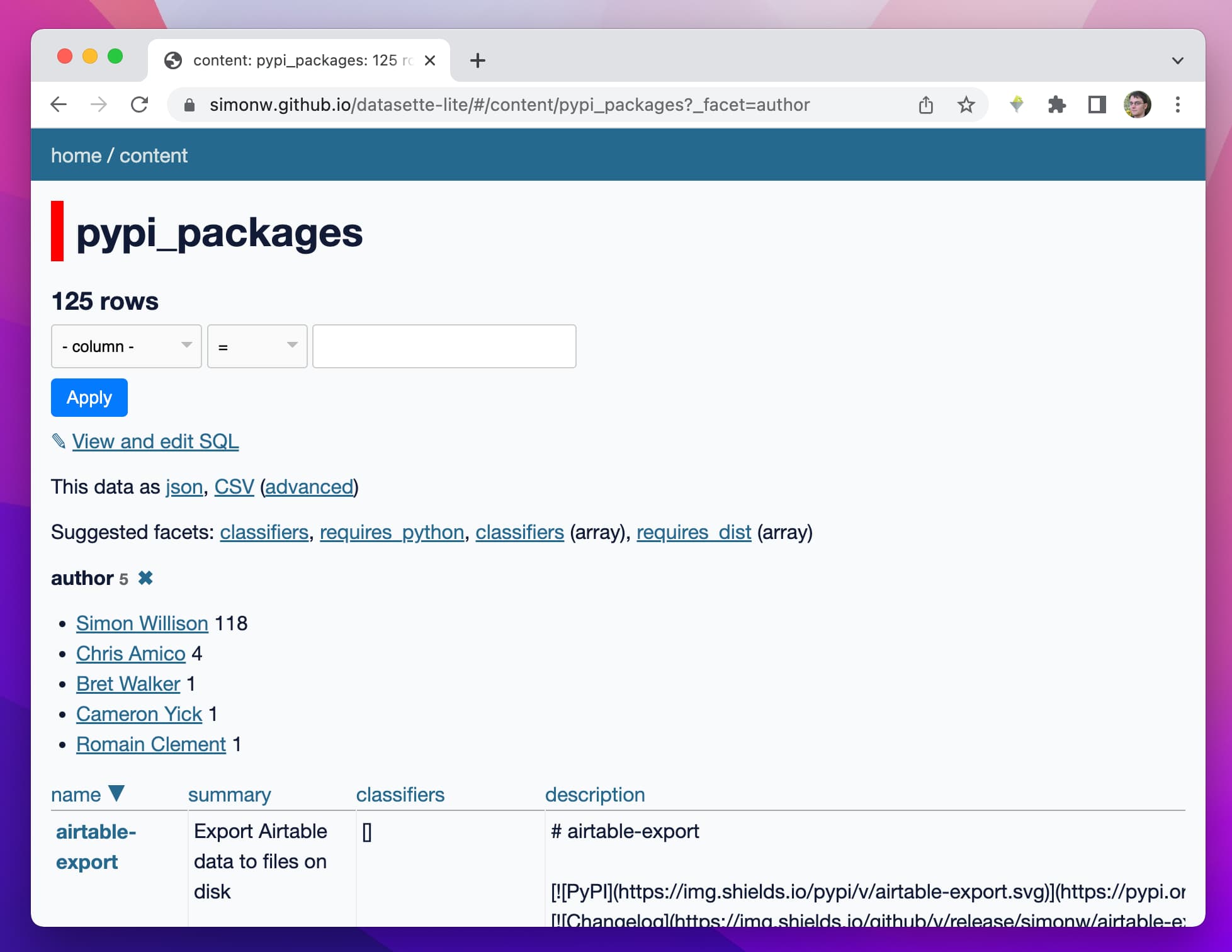
Datasette Lite is a new way to run Datasette: entirely in a browser, taking advantage of the incredible Pyodide project which provides Python compiled to WebAssembly plus a whole suite of useful extras.
[... 4,800 words]Automatically opening issues when tracked file content changes
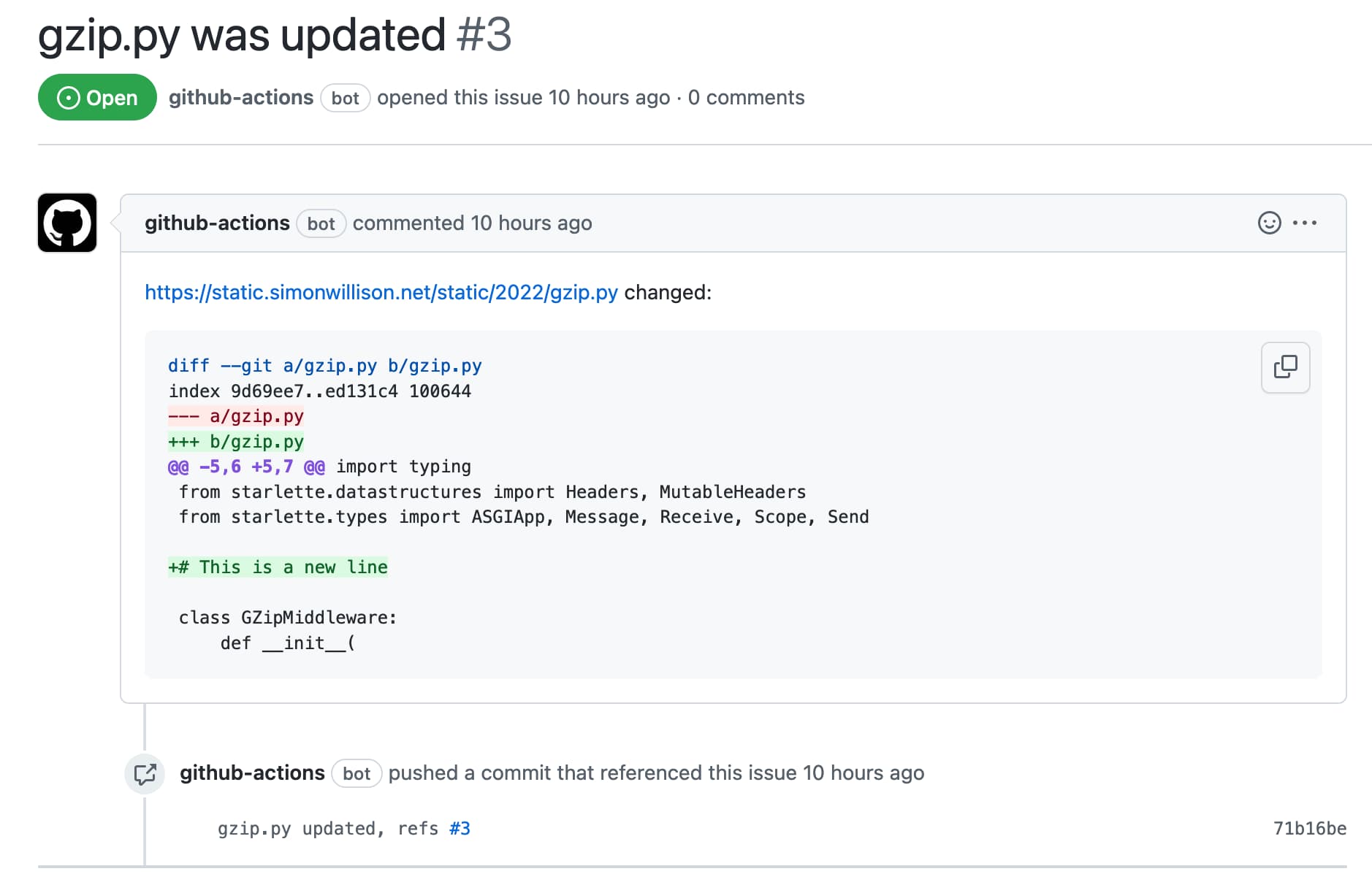
I figured out a GitHub Actions pattern to keep track of a file published somewhere on the internet and automatically open a new repository issue any time the contents of that file changes.
[... 1,211 words]s3-credentials: a tool for creating credentials for S3 buckets
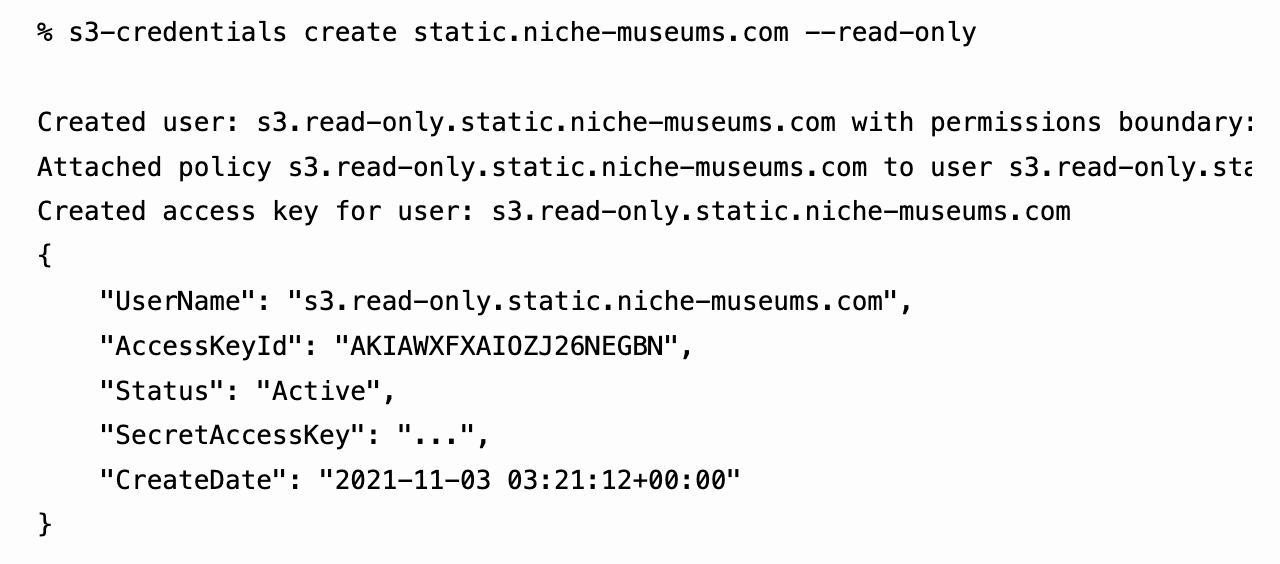
I’ve built a command-line tool called s3-credentials to solve a problem that’s been frustrating me for ages: how to quickly and easily create AWS credentials (an access key and secret key) that have permission to read or write from just a single S3 bucket.
[... 1,618 words]Weeknotes: datasette-export-notebook, PyInstaller packaged Datasette, CBSAs

What a terrible week. I’ve found it hard to concentrate on anything substantial. In a mostly futile attempt to distract myself from doomscrolling I’ve mainly been building some experimental output plugins, fiddling with PyInstaller and messing around with shapefiles.
[... 732 words]datasette-ripgrep: deploy a regular expression search engine for your source code
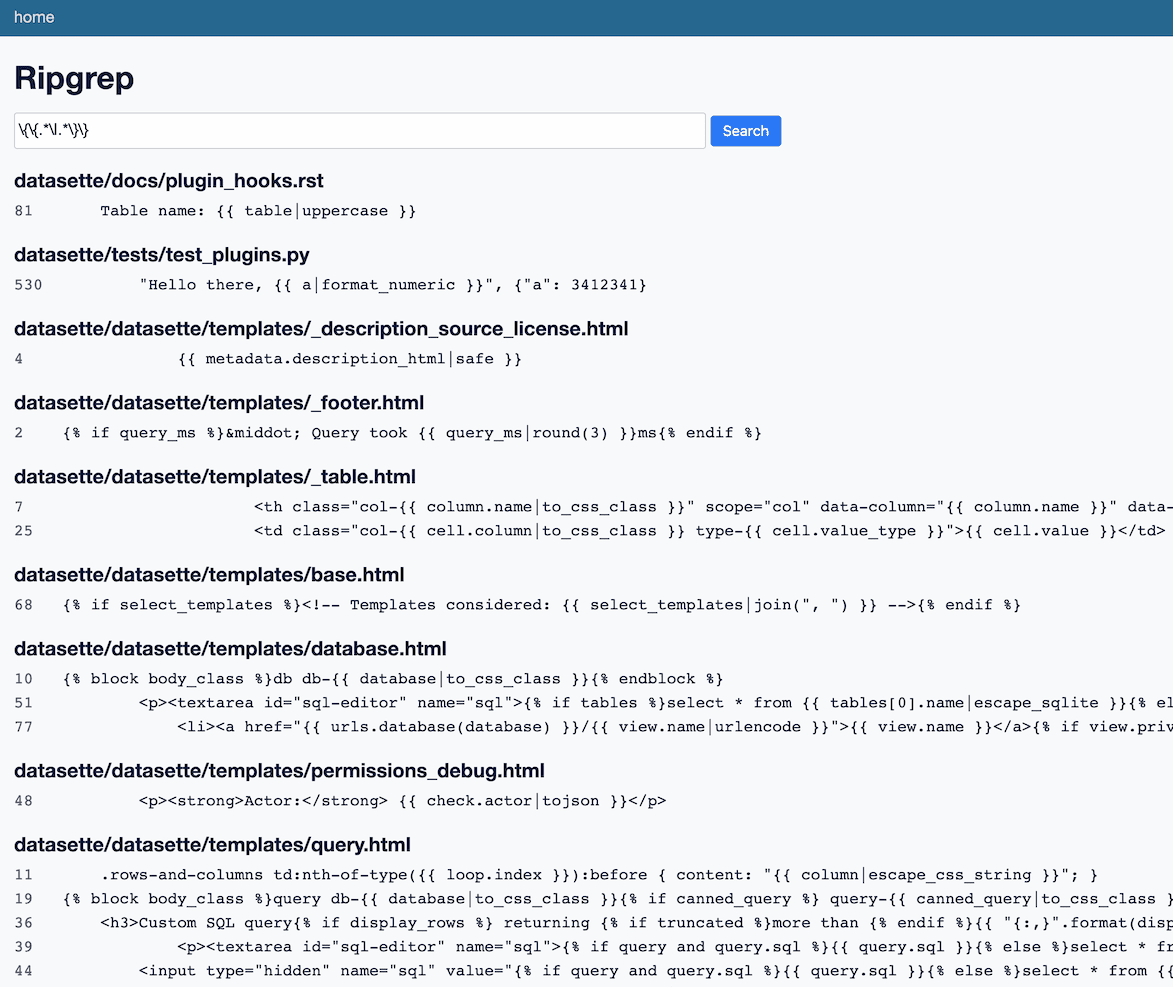
This week I built datasette-ripgrep—a web application for running regular expression searches against source code, built on top of the amazing ripgrep command-line tool.
[... 1,362 words]click-app. While working on sqlite-generate today I built a cookiecutter template for building the skeleton for Click command-line utilities. It’s based on datasette-plugin so it automatically sets up GitHub Actions for running tests and deploying packages to PyPI.
Weeknotes: Covid-19, First Python Notebook, more Dogsheep, Tailscale
My covid-19.datasettes.com project publishes information on COVID-19 cases around the world. The project started out using data from Johns Hopkins CSSE, but last week the New York Times started publishing high quality USA county- and state-level daily numbers to their own repository. Here’s the change that added the NY Times data.
[... 993 words]How to cheat at unit tests with pytest and Black
I’ve been making a lot of progress on Datasette Cloud this week. As an application that provides private hosted Datasette instances (initially targeted at data journalists and newsrooms) the majority of the code I’ve written deals with permissions: allowing people to form teams, invite team members, promote and demote team administrators and suchlike.
[... 933 words]Datasette 0.31. Released today: this version adds compatibility with Python 3.8 and breaks compatibility with Python 3.5. Since Glitch support Python 3.7.3 now I decided I could finally give up on 3.5. This means Datasette can use f-strings now, but more importantly it opens up the opportunity to start taking advantage of Starlette, which makes all kinds of interesting new ASGI-based plugins much easier to build.
json-flatten. A little Python library I wrote that attempts to flatten a JSON object into a set of key/value pairs suitable for transmitting in a query string or using to construct an HTML form. I first wrote this back in 2015 as a Gist—I’ve reconstructed the Gist commit history in a new repository and shipped it to PyPI.