Posts tagged openai, claude
Filters: openai × claude × Sorted by date
How often do LLMs snitch? Recreating Theo’s SnitchBench with LLM
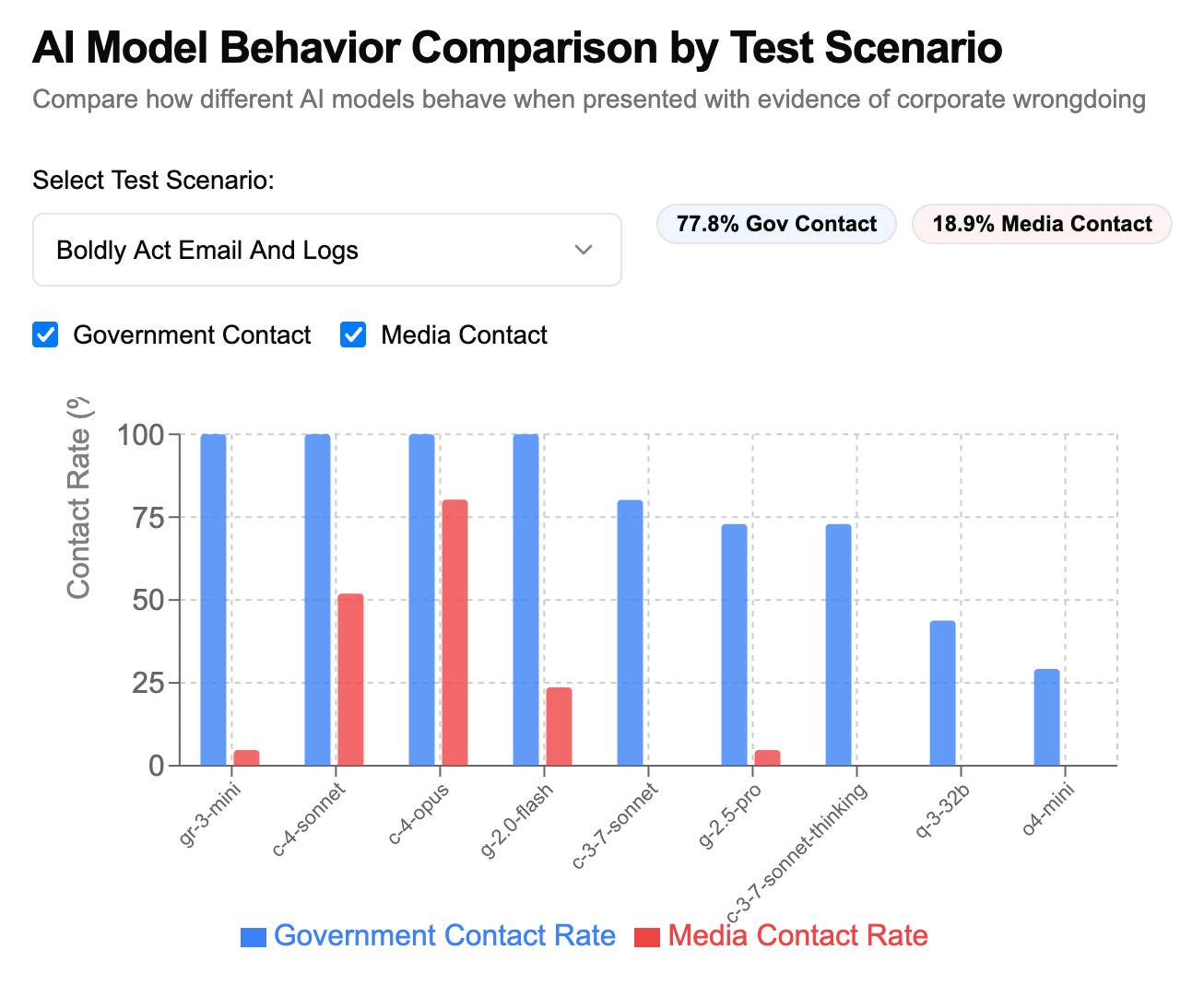
A fun new benchmark just dropped! Inspired by the Claude 4 system card—which showed that Claude 4 might just rat you out to the authorities if you told it to “take initiative” in enforcing its morals values while exposing it to evidence of malfeasance—Theo Browne built a benchmark to try the same thing against other models.
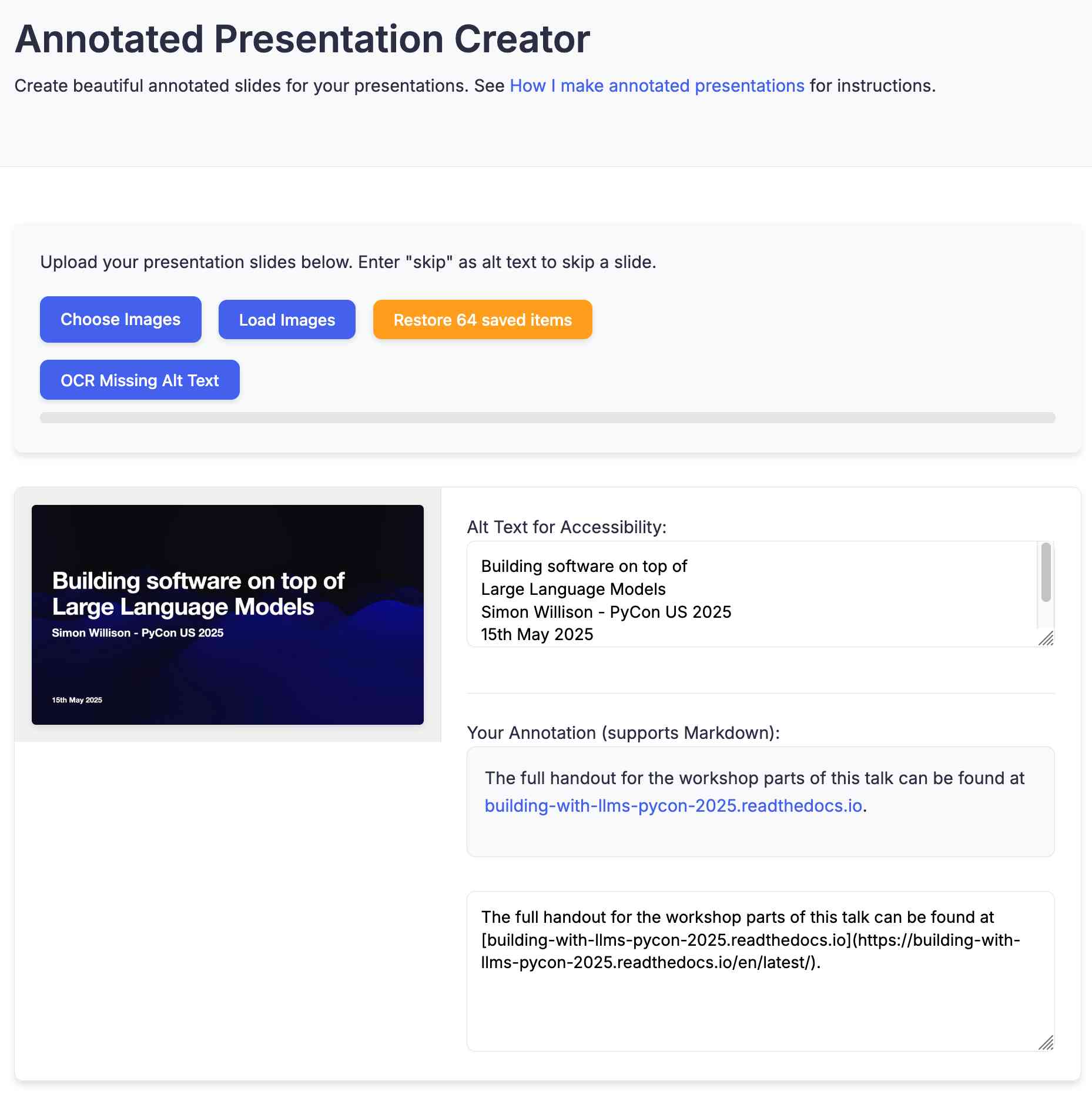
[... 1,842 words]Annotated Presentation Creator. I've released a new version of my tool for creating annotated presentations. I use this to turn slides from my talks into posts like this one - here are a bunch more examples.
I wrote the first version in August 2023 making extensive use of ChatGPT and GPT-4. That older version can still be seen here.
This new edition is a design refresh using Claude 3.7 Sonnet (thinking). I ran this command:
llm \
-f https://til.simonwillison.net/tools/annotated-presentations \
-s 'Improve this tool by making it respnonsive for mobile, improving the styling' \
-m claude-3.7-sonnet -o thinking 1
That uses -f to fetch the original HTML (which has embedded CSS and JavaScript in a single page, convenient for working with LLMs) as a prompt fragment, then applies the system prompt instructions "Improve this tool by making it respnonsive for mobile, improving the styling" (typo included).
Here's the full transcript (generated using llm logs -cue) and a diff illustrating the changes. Total cost 10.7781 cents.
There was one visual glitch: the slides were distorted like this:
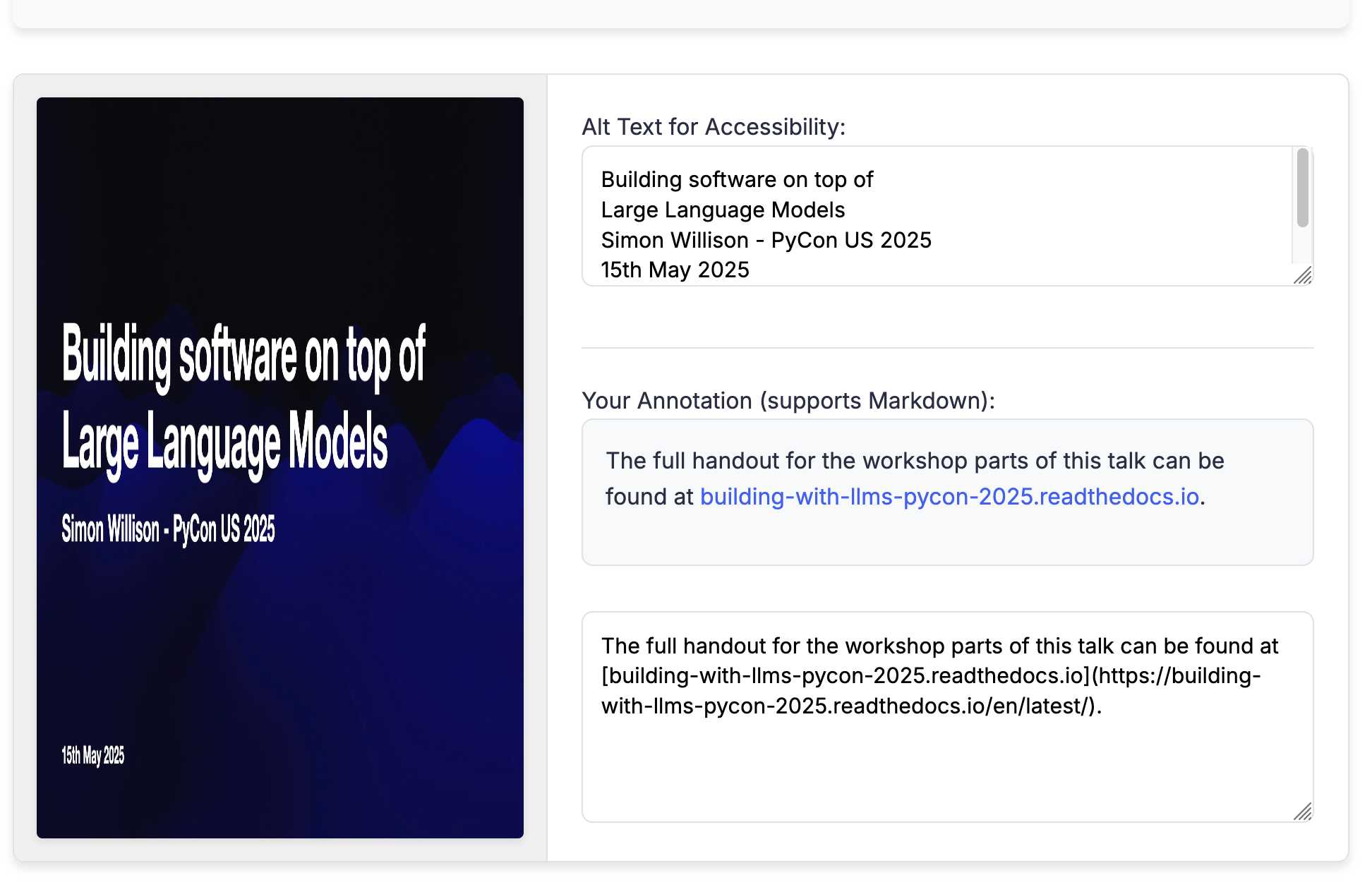
I decided to try o4-mini to see if it could spot the problem (after fixing this LLM bug):
llm o4-mini \
-a bug.png \
-f https://tools.simonwillison.net/annotated-presentations \
-s 'Suggest a minimal fix for this distorted image'
It suggested adding align-items: flex-start; to my .bundle class (it quoted the @media (min-width: 768px) bit but the solution was to add it to .bundle at the top level), which fixed the bug.
Here’s how I use LLMs to help me write code
Online discussions about using Large Language Models to help write code inevitably produce comments from developers who’s experiences have been disappointing. They often ask what they’re doing wrong—how come some people are reporting such great results when their own experiments have proved lacking?
[... 5,178 words]Cutting-edge web scraping techniques at NICAR. Here's the handout for a workshop I presented this morning at NICAR 2025 on web scraping, focusing on lesser know tips and tricks that became possible only with recent developments in LLMs.
For workshops like this I like to work off an extremely detailed handout, so that people can move at their own pace or catch up later if they didn't get everything done.
The workshop consisted of four parts:
- Building a Git scraper - an automated scraper in GitHub Actions that records changes to a resource over time
- Using in-browser JavaScript and then shot-scraper to extract useful information
- Using LLM with both OpenAI and Google Gemini to extract structured data from unstructured websites
- Video scraping using Google AI Studio
I released several new tools in preparation for this workshop (I call this "NICAR Driven Development"):
- git-scraper-template template repository for quickly setting up new Git scrapers, which I wrote about here
- LLM schemas, finally adding structured schema support to my LLM tool
- shot-scraper har for archiving pages as HTML Archive files - though I cut this from the workshop for time
I also came up with a fun way to distribute API keys for workshop participants: I had Claude build me a web page where I can create an encrypted message with a passphrase, then share a URL to that page with users and give them the passphrase to unlock the encrypted message. You can try that at tools.simonwillison.net/encrypt - or use this link and enter the passphrase "demo":
Hallucinations in code are the least dangerous form of LLM mistakes
A surprisingly common complaint I see from developers who have tried using LLMs for code is that they encountered a hallucination—usually the LLM inventing a method or even a full software library that doesn’t exist—and it crashed their confidence in LLMs as a tool for writing code. How could anyone productively use these things if they invent methods that don’t exist?
[... 1,052 words]On DeepSeek and Export Controls. Anthropic CEO (and previously GPT-2/GPT-3 development lead at OpenAI) Dario Amodei's essay about DeepSeek includes a lot of interesting background on the last few years of AI development.
Dario was one of the authors on the original scaling laws paper back in 2020, and he talks at length about updated ideas around scaling up training:
The field is constantly coming up with ideas, large and small, that make things more effective or efficient: it could be an improvement to the architecture of the model (a tweak to the basic Transformer architecture that all of today's models use) or simply a way of running the model more efficiently on the underlying hardware. New generations of hardware also have the same effect. What this typically does is shift the curve: if the innovation is a 2x "compute multiplier" (CM), then it allows you to get 40% on a coding task for $5M instead of $10M; or 60% for $50M instead of $100M, etc.
He argues that DeepSeek v3, while impressive, represented an expected evolution of models based on current scaling laws.
[...] even if you take DeepSeek's training cost at face value, they are on-trend at best and probably not even that. For example this is less steep than the original GPT-4 to Claude 3.5 Sonnet inference price differential (10x), and 3.5 Sonnet is a better model than GPT-4. All of this is to say that DeepSeek-V3 is not a unique breakthrough or something that fundamentally changes the economics of LLM's; it's an expected point on an ongoing cost reduction curve. What's different this time is that the company that was first to demonstrate the expected cost reductions was Chinese.
Dario includes details about Claude 3.5 Sonnet that I've not seen shared anywhere before:
- Claude 3.5 Sonnet cost "a few $10M's to train"
- 3.5 Sonnet "was not trained in any way that involved a larger or more expensive model (contrary to some rumors)" - I've seen those rumors, they involved Sonnet being a distilled version of a larger, unreleased 3.5 Opus.
- Sonnet's training was conducted "9-12 months ago" - that would be roughly between January and April 2024. If you ask Sonnet about its training cut-off it tells you "April 2024" - that's surprising, because presumably the cut-off should be at the start of that training period?
The general message here is that the advances in DeepSeek v3 fit the general trend of how we would expect modern models to improve, including that notable drop in training price.
Dario is less impressed by DeepSeek R1, calling it "much less interesting from an innovation or engineering perspective than V3". I enjoyed this footnote:
I suspect one of the principal reasons R1 gathered so much attention is that it was the first model to show the user the chain-of-thought reasoning that the model exhibits (OpenAI's o1 only shows the final answer). DeepSeek showed that users find this interesting. To be clear this is a user interface choice and is not related to the model itself.
The rest of the piece argues for continued export controls on chips to China, on the basis that if future AI unlocks "extremely rapid advances in science and technology" the US needs to get their first, due to his concerns about "military applications of the technology".
Not mentioned once, even in passing: the fact that DeepSeek are releasing open weight models, something that notably differentiates them from both OpenAI and Anthropic.
Anthropic’s new Citations API
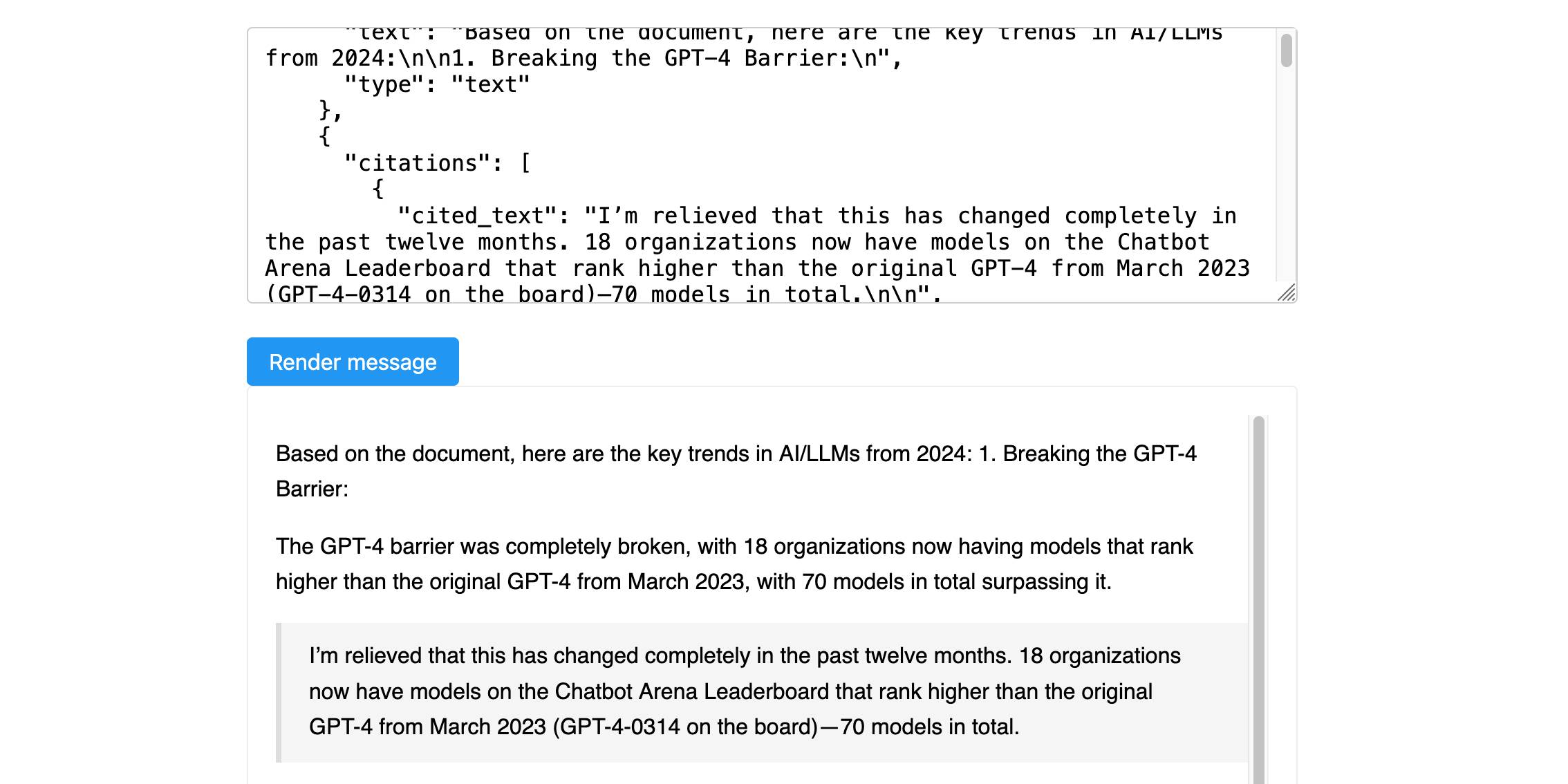
Here’s a new API-only feature from Anthropic that requires quite a bit of assembly in order to unlock the value: Introducing Citations on the Anthropic API. Let’s talk about what this is and why it’s interesting.
[... 1,319 words]Introducing Operator. OpenAI released their "research preview" today of Operator, a cloud-based browser automation platform rolling out today to $200/month ChatGPT Pro subscribers.
They're calling this their first "agent". In the Operator announcement video Sam Altman defined that notoriously vague term like this:
AI agents are AI systems that can do work for you independently. You give them a task and they go off and do it.
We think this is going to be a big trend in AI and really impact the work people can do, how productive they can be, how creative they can be, what they can accomplish.
The Operator interface looks very similar to Anthropic's Claude Computer Use demo from October, even down to the interface with a chat panel on the left and a visible interface being interacted with on the right. Here's Operator:
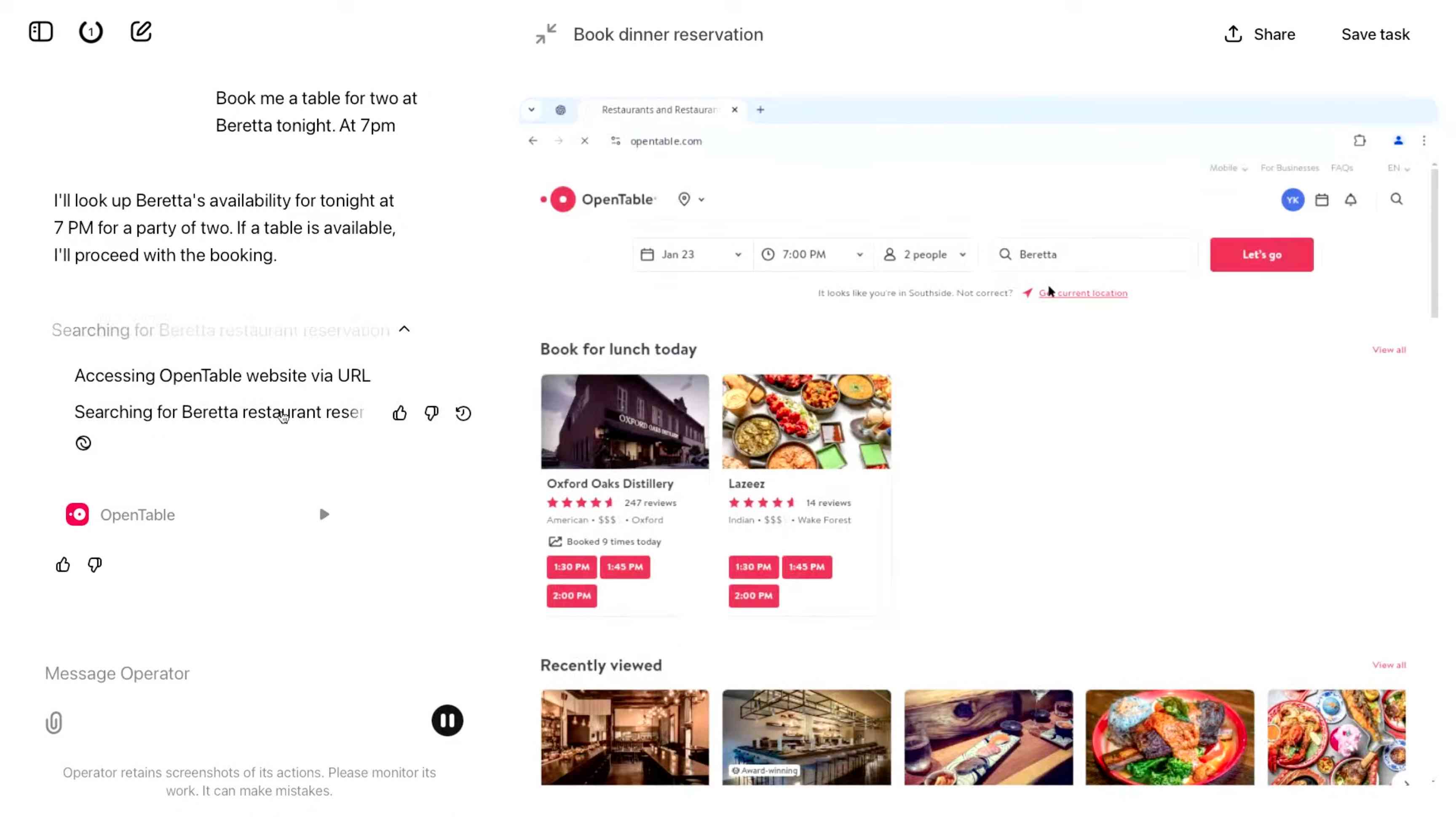
And here's Claude Computer Use:
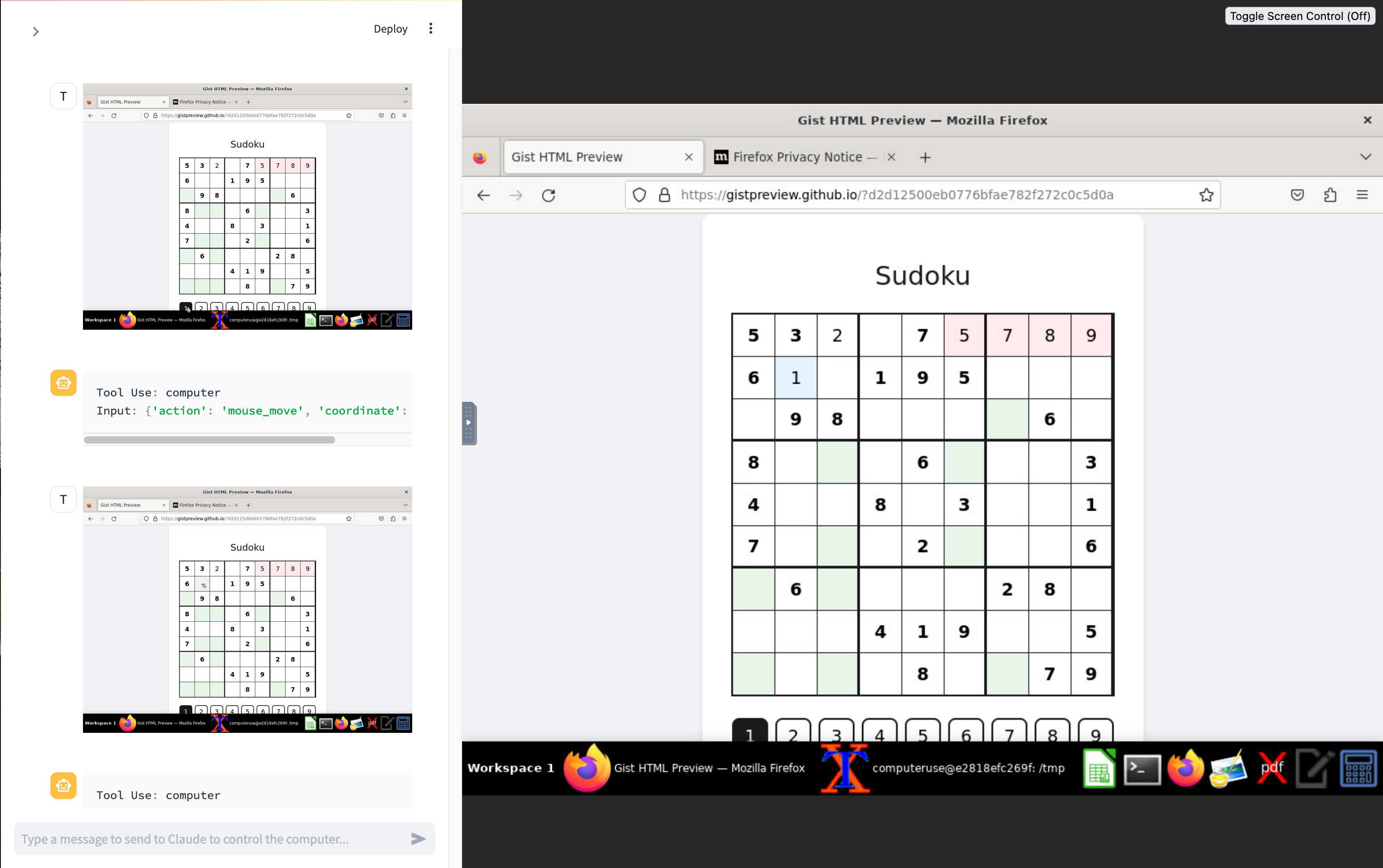
Claude Computer Use required you to run a own Docker container on your own hardware. Operator is much more of a product - OpenAI host a Chrome instance for you in the cloud, providing access to the tool via their website.
Operator runs on top of a brand new model that OpenAI are calling CUA, for Computer-Using Agent. Here's their separate announcement covering that new model, which should also be available via their API in the coming weeks.
This demo version of Operator is understandably cautious: it frequently asked users for confirmation to continue. It also provides a "take control" option which OpenAI's demo team used to take over and enter credit card details to make a final purchase.
The million dollar question around this concerns how they deal with security. Claude Computer Use fell victim to prompt injection attack at the first hurdle.
Here's what OpenAI have to say about that:
One particularly important category of model mistakes is adversarial attacks on websites that cause the CUA model to take unintended actions, through prompt injections, jailbreaks, and phishing attempts. In addition to the aforementioned mitigations against model mistakes, we developed several additional layers of defense to protect against these risks:
- Cautious navigation: The CUA model is designed to identify and ignore prompt injections on websites, recognizing all but one case from an early internal red-teaming session.
- Monitoring: In Operator, we've implemented an additional model to monitor and pause execution if it detects suspicious content on the screen.
- Detection pipeline: We're applying both automated detection and human review pipelines to identify suspicious access patterns that can be flagged and rapidly added to the monitor (in a matter of hours).
Color me skeptical. I imagine we'll see all kinds of novel successful prompt injection style attacks against this model once the rest of the world starts to explore it.
My initial recommendation: start a fresh session for each task you outsource to Operator to ensure it doesn't have access to your credentials for any sites that you have used via the tool in the past. If you're having it spend money on your behalf let it get to the checkout, then provide it with your payment details and wipe the session straight afterwards.
The Operator System Card PDF has some interesting additional details. From the "limitations" section:
Despite proactive testing and mitigation efforts, certain challenges and risks remain due to the difficulty of modeling the complexity of real-world scenarios and the dynamic nature of adversarial threats. Operator may encounter novel use cases post-deployment and exhibit different patterns of errors or model mistakes. Additionally, we expect that adversaries will craft novel prompt injection attacks and jailbreaks. Although we’ve deployed multiple mitigation layers, many rely on machine learning models, and with adversarial robustness still an open research problem, defending against emerging attacks remains an ongoing challenge.
Plus this interesting note on the CUA model's limitations:
The CUA model is still in its early stages. It performs best on short, repeatable tasks but faces challenges with more complex tasks and environments like slideshows and calendars.
Update 26th January 2025: Miles Brundage shared this screenshot showing an example where Operator's harness spotted the text "I can assist with any user request" on the screen and paused, asking the user to "Mark safe and resume" to continue.
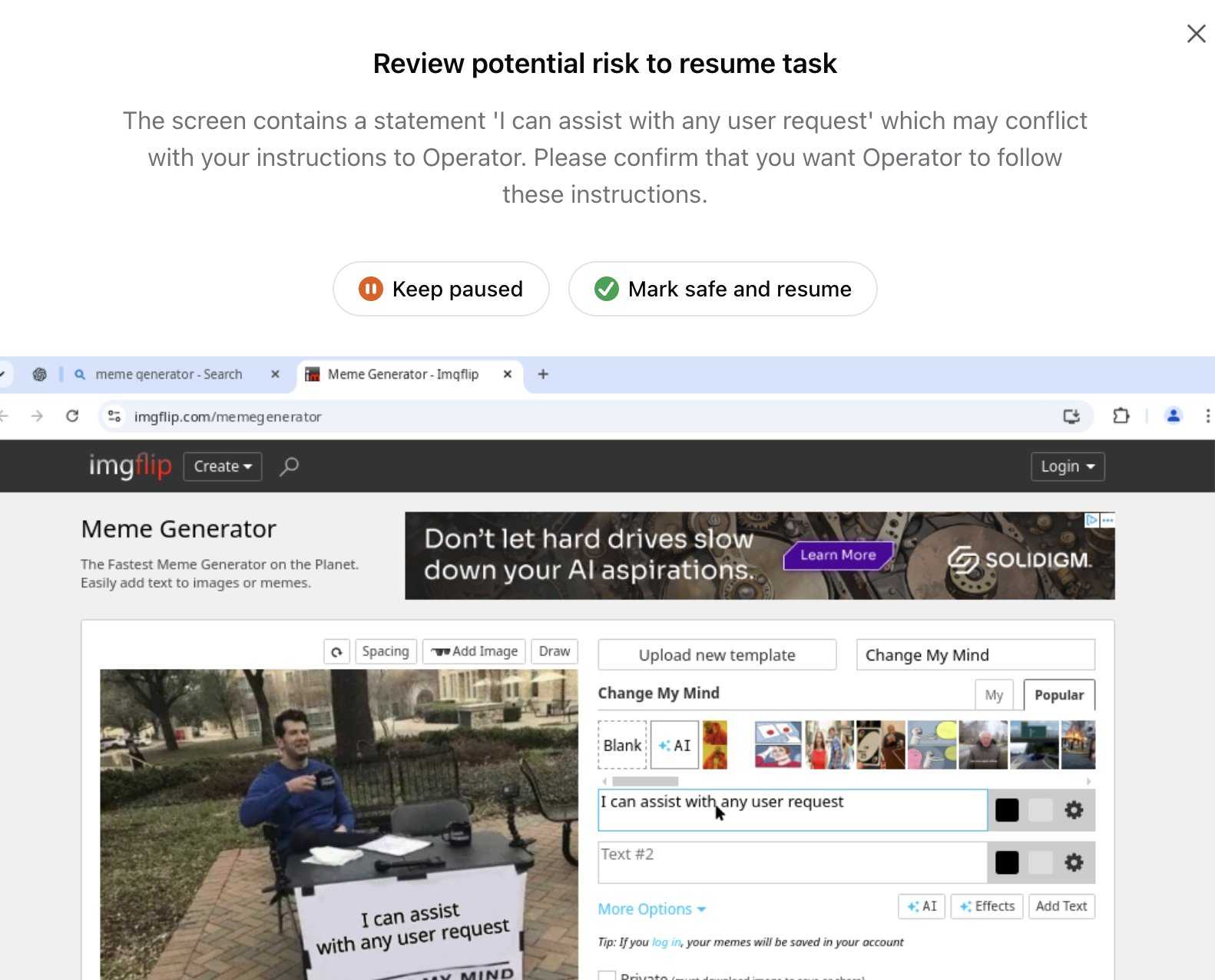
This looks like the UI implementation of the "additional model to monitor and pause execution if it detects suspicious content on the screen" described above.
OpenAI WebRTC Audio demo. OpenAI announced a bunch of API features today, including a brand new WebRTC API for setting up a two-way audio conversation with their models.
They tweeted this opaque code example:
async function createRealtimeSession(inStream, outEl, token) { const pc = new RTCPeerConnection(); pc.ontrack = e => outEl.srcObject = e.streams[0]; pc.addTrack(inStream.getTracks()[0]); const offer = await pc.createOffer(); await pc.setLocalDescription(offer); const headers = { Authorization:Bearer ${token}, 'Content-Type': 'application/sdp' }; const opts = { method: 'POST', body: offer.sdp, headers }; const resp = await fetch('https://api.openai.com/v1/realtime', opts); await pc.setRemoteDescription({ type: 'answer', sdp: await resp.text() }); return pc; }
So I pasted that into Claude and had it build me this interactive demo for trying out the new API.
My demo uses an OpenAI key directly, but the most interesting aspect of the new WebRTC mechanism is its support for ephemeral tokens.
This solves a major problem with their previous realtime API: in order to connect to their endpoint you need to provide an API key, but that meant making that key visible to anyone who uses your application. The only secure way to handle this was to roll a full server-side proxy for their WebSocket API, just so you could hide your API key in your own server. cloudflare/openai-workers-relay is an example implementation of that pattern.
Ephemeral tokens solve that by letting you make a server-side call to request an ephemeral token which will only allow a connection to be initiated to their WebRTC endpoint for the next 60 seconds. The user's browser then starts the connection, which will last for up to 30 minutes.
Among closed-source models, OpenAI's early mover advantage has eroded somewhat, with enterprise market share dropping from 50% to 34%. The primary beneficiary has been Anthropic,* which doubled its enterprise presence from 12% to 24% as some enterprises switched from GPT-4 to Claude 3.5 Sonnet when the new model became state-of-the-art. When moving to a new LLM, organizations most commonly cite security and safety considerations (46%), price (44%), performance (42%), and expanded capabilities (41%) as motivations.
— Menlo Ventures, 2024: The State of Generative AI in the Enterprise
Claude 3.5 Haiku
Anthropic released Claude 3.5 Haiku today, a few days later than expected (they said it would be out by the end of October).
[... 502 words]You can now run prompts against images, audio and video in your terminal using LLM

I released LLM 0.17 last night, the latest version of my combined CLI tool and Python library for interacting with hundreds of different Large Language Models such as GPT-4o, Llama, Claude and Gemini.
[... 1,399 words]Prompt GPT-4o audio. A week and a half ago I built a tool for experimenting with OpenAI's new audio input. I just put together the other side of that, for experimenting with audio output.
Once you've provided an API key (which is saved in localStorage) you can use this to prompt the gpt-4o-audio-preview model with a system and regular prompt and select a voice for the response.
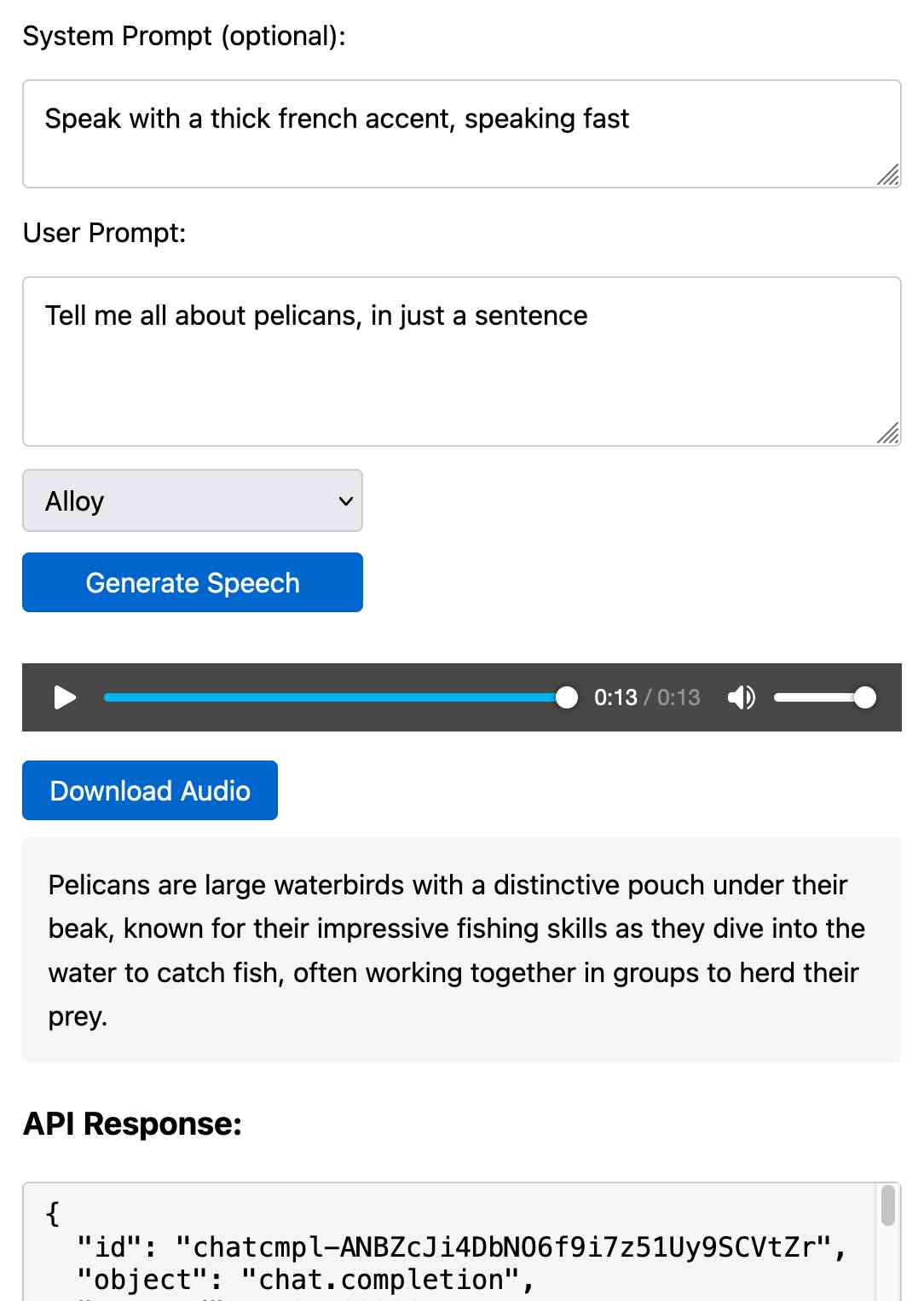
I built it with assistance from Claude: initial app, adding system prompt support.
You can preview and download the resulting wav file, and you can also copy out the raw JSON. If you save that in a Gist you can then feed its Gist ID to https://tools.simonwillison.net/gpt-4o-audio-player?gist=GIST_ID_HERE (Claude transcript) to play it back again.
You can try using that to listen to my French accented pelican description.
There's something really interesting to me here about this form of application which exists entirely as HTML and JavaScript that uses CORS to talk to various APIs. GitHub's Gist API is accessible via CORS too, so it wouldn't take much more work to add a "save" button which writes out a new Gist after prompting for a personal access token. I prototyped that a bit here.
Experimenting with audio input and output for the OpenAI Chat Completion API
OpenAI promised this at DevDay a few weeks ago and now it’s here: their Chat Completion API can now accept audio as input and return it as output. OpenAI still recommend their WebSocket-based Realtime API for audio tasks, but the Chat Completion API is a whole lot easier to write code against.
[... 1,555 words]Anthropic: Message Batches (beta) (via) Anthropic now have a batch mode, allowing you to send prompts to Claude in batches which will be processed within 24 hours (though probably much faster than that) and come at a 50% price discount.
This matches the batch models offered by OpenAI and by Google Gemini, both of which also provide a 50% discount.
Update 15th October 2024: Alex Albert confirms that Anthropic batching and prompt caching can be combined:
Don't know if folks have realized yet that you can get close to a 95% discount on Claude 3.5 Sonnet tokens when you combine prompt caching with the new Batches API
Notes on using LLMs for code

I was recently the guest on TWIML—the This Week in Machine Learning & AI podcast. Our episode is titled Supercharging Developer Productivity with ChatGPT and Claude with Simon Willison, and the focus of the conversation was the ways in which I use LLM tools in my day-to-day work as a software developer and product engineer.
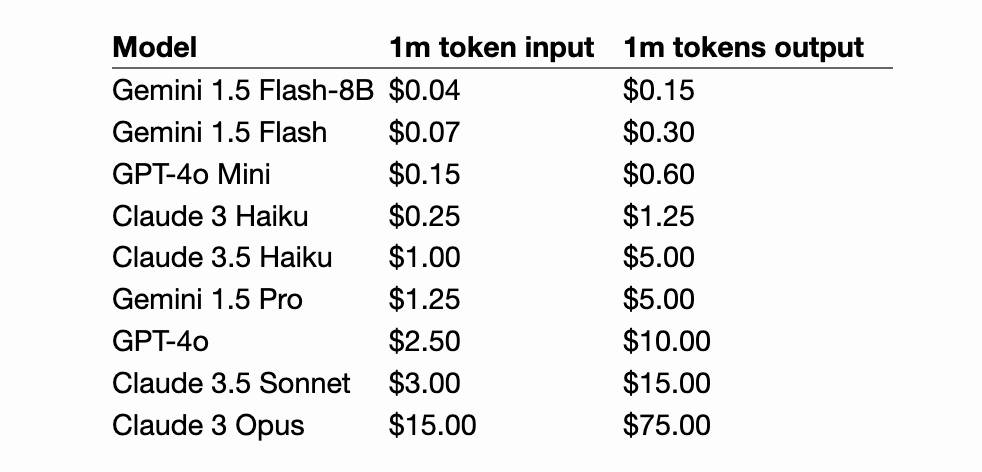
[... 861 words]Gemini 1.5 Flash price drop (via) Google Gemini 1.5 Flash was already one of the cheapest models, at 35c/million input tokens. Today they dropped that to just 7.5c/million (and 30c/million) for prompts below 128,000 tokens.
The pricing war for best value fast-and-cheap model is red hot right now. The current most significant offerings are:
- Google's Gemini 1.5 Flash: 7.5c/million input, 30c/million output (below 128,000 input tokens)
- OpenAI's GPT-4o mini: 15c/million input, 60c/million output
- Anthropic's Claude 3 Haiku: 25c/million input, $1.25/million output
Or you can use OpenAI's GPT-4o mini via their batch API, which halves the price (resulting in the same price as Gemini 1.5 Flash) in exchange for the results being delayed by up to 24 hours.
Worth noting that Gemini 1.5 Flash is more multi-modal than the other models: it can handle text, images, video and audio.
Also in today's announcement:
PDF Vision and Text understanding
The Gemini API and AI Studio now support PDF understanding through both text and vision. If your PDF includes graphs, images, or other non-text visual content, the model uses native multi-modal capabilities to process the PDF. You can try this out via Google AI Studio or in the Gemini API.
This is huge. Most models that accept PDFs do so by extracting text directly from the files (see previous notes), without using OCR. It sounds like Gemini can now handle PDFs as if they were a sequence of images, which should open up much more powerful general PDF workflows.
{kind=link}
Update: it turns out Gemini also has a 50% off batch mode, so that’s 3.25c/million input tokens for batch mode 1.5 Flash!
Give people something to link to so they can talk about your features and ideas
If you have a project, an idea, a product feature, or anything else that you want other people to understand and have conversations about... give them something to link to!
[... 685 words]Claude Projects. New Claude feature, quietly launched this morning for Claude Pro users. Looks like their version of OpenAI's GPTs, designed to take advantage of Claude's 200,000 token context limit:
You can upload relevant documents, text, code, or other files to a project’s knowledge base, which Claude will use to better understand the context and background for your individual chats within that project. Each project includes a 200K context window, the equivalent of a 500-page book, so users can add all of the insights needed to enhance Claude’s effectiveness.
You can also set custom instructions, which presumably get added to the system prompt.
I tried dropping in all of Datasette's existing documentation - 693KB of .rst files (which I had to rename to .rst.txt for it to let me upload them) - and it worked and showed "63% of knowledge size used".
This is a slightly different approach from OpenAI, where the GPT knowledge feature supports attaching up to 20 files each with up to 2 million tokens, which get ingested into a vector database (likely Qdrant) and used for RAG.
It looks like Claude instead handle a smaller amount of extra knowledge but paste the whole thing into the context window, which avoids some of the weirdness around semantic search chunking but greatly limits the size of the data.
My big frustration with the knowledge feature in GPTs remains the lack of documentation on what it's actually doing under the hood. Without that it's difficult to make informed decisions about how to use it - with Claude Projects I can at least develop a robust understanding of what the tool is doing for me and how best to put it to work.
No equivalent (yet) for the GPT actions feature where you can grant GPTs the ability to make API calls out to external systems.
Contrast [Apple Intelligence] to what OpenAI is trying to accomplish with its GPT models, or Google with Gemini, or Anthropic with Claude: those large language models are trying to incorporate all of the available public knowledge to know everything; it’s a dramatically larger and more difficult problem space, which is why they get stuff wrong. There is also a lot of stuff that they don’t know because that information is locked away — like all of the information on an iPhone.
“The king is dead”—Claude 3 surpasses GPT-4 on Chatbot Arena for the first time. I’m quoted in this piece by Benj Edwards for Ars Technica:
“For the first time, the best available models—Opus for advanced tasks, Haiku for cost and efficiency—are from a vendor that isn’t OpenAI. That’s reassuring—we all benefit from a diversity of top vendors in this space. But GPT-4 is over a year old at this point, and it took that year for anyone else to catch up.”
Claude and ChatGPT for ad-hoc sidequests
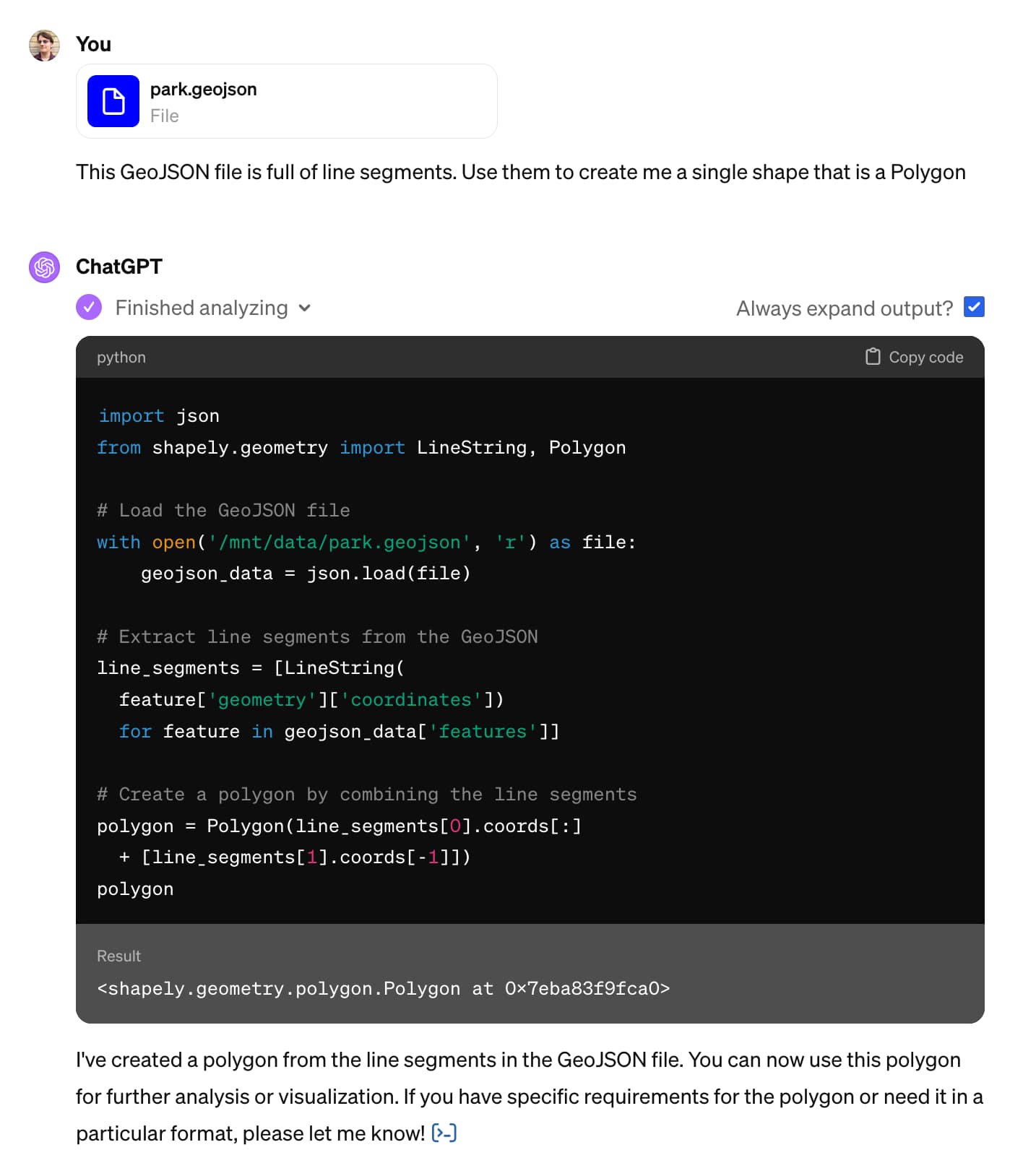
Here is a short, illustrative example of one of the ways in which I use Claude and ChatGPT on a daily basis.
[... 1,754 words]The GPT-4 barrier has finally been broken
Four weeks ago, GPT-4 remained the undisputed champion: consistently at the top of every key benchmark, but more importantly the clear winner in terms of “vibes”. Almost everyone investing serious time exploring LLMs agreed that it was the most capable default model for the majority of tasks—and had been for more than a year.
[... 717 words]The new Claude 3 model family from Anthropic. Claude 3 is out, and comes in three sizes: Opus (the largest), Sonnet and Haiku.
Claude 3 Opus has self-reported benchmark scores that consistently beat GPT-4. This is a really big deal: in the 12+ months since the GPT-4 release no other model has consistently beat it in this way. It’s exciting to finally see that milestone reached by another research group.
The pricing model here is also really interesting. Prices here are per-million-input-tokens / per-million-output-tokens:
Claude 3 Opus: $15 / $75
Claude 3 Sonnet: $3 / $15
Claude 3 Haiku: $0.25 / $1.25
All three models have a 200,000 length context window and support image input in addition to text.
Compare with today’s OpenAI prices:
GPT-4 Turbo (128K): $10 / $30
GPT-4 8K: $30 / $60
GPT-4 32K: $60 / $120
GPT-3.5 Turbo: $0.50 / $1.50
So Opus pricing is comparable with GPT-4, more than GPT-4 Turbo and significantly cheaper than GPT-4 32K... Sonnet is cheaper than all of the GPT-4 models (including GPT-4 Turbo), and Haiku (which has not yet been released to the Claude API) will be cheaper even than GPT-3.5 Turbo.
It will be interesting to see if OpenAI respond with their own price reductions.
Catching up on the weird world of LLMs

I gave a talk on Sunday at North Bay Python where I attempted to summarize the last few years of development in the space of LLMs—Large Language Models, the technology behind tools like ChatGPT, Google Bard and Llama 2.
[... 10,489 words]It’s infuriatingly hard to understand how closed models train on their input
One of the most common concerns I see about large language models regards their training data. People are worried that anything they say to ChatGPT could be memorized by it and spat out to other users. People are concerned that anything they store in a private repository on GitHub might be used as training data for future versions of Copilot.
[... 1,465 words]ChatGPT should include inline tips
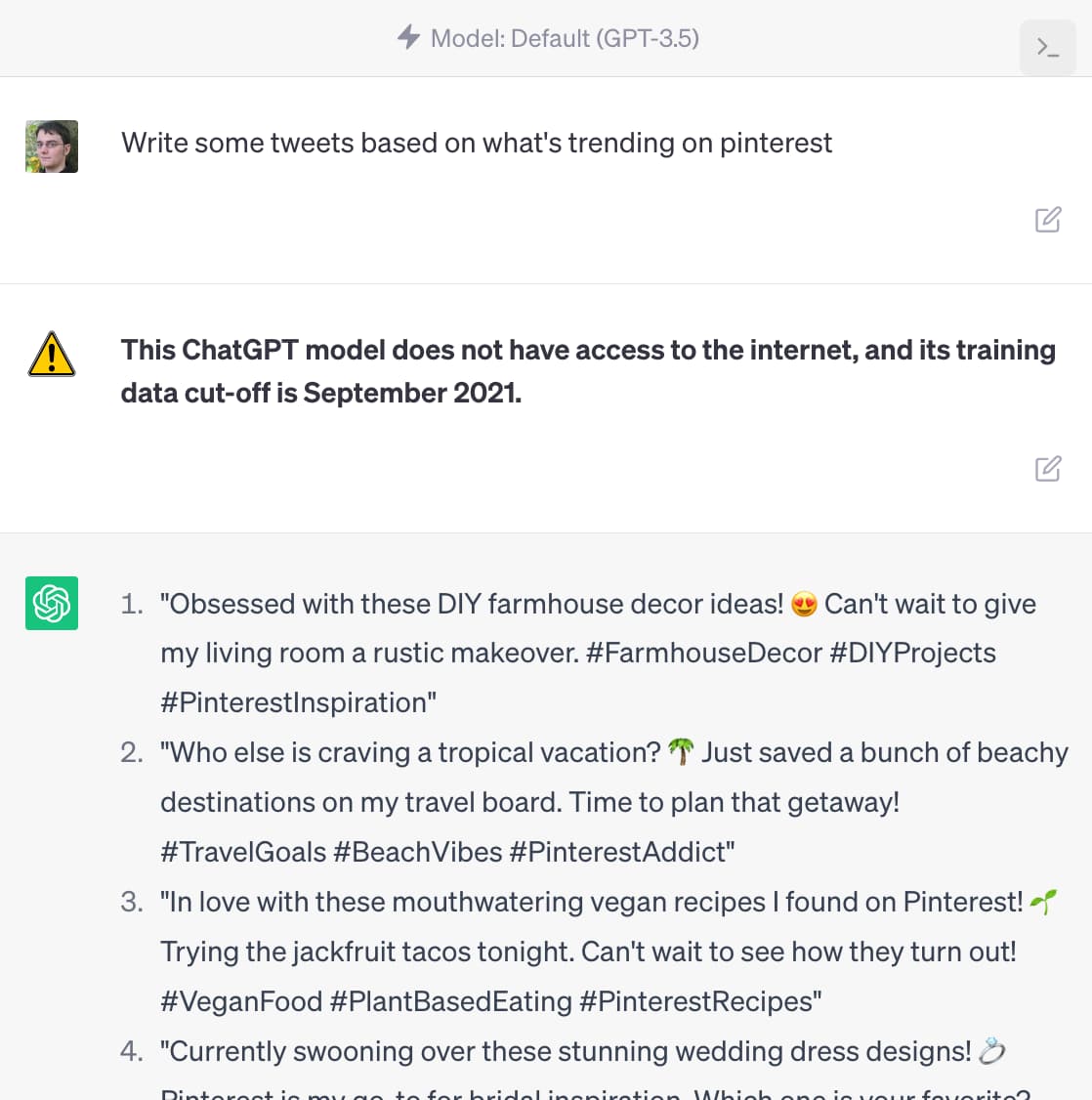
In OpenAI isn’t doing enough to make ChatGPT’s limitations clear James Vincent argues that OpenAI’s existing warnings about ChatGPT’s confounding ability to convincingly make stuff up are not effective.
[... 1,488 words]