311 posts tagged “open-source”
2026
[...] the reality is that 75% of the people on our engineering team lost their jobs here yesterday because of the brutal impact AI has had on our business. And every second I spend trying to do fun free things for the community like this is a second I'm not spending trying to turn the business around and make sure the people who are still here are getting their paychecks every month. [...]
Traffic to our docs is down about 40% from early 2023 despite Tailwind being more popular than ever. The docs are the only way people find out about our commercial products, and without customers we can't afford to maintain the framework. [...]
Tailwind is growing faster than it ever has and is bigger than it ever has been, and our revenue is down close to 80%. Right now there's just no correlation between making Tailwind easier to use and making development of the framework more sustainable.
— Adam Wathan, CEO, Tailwind Labs
2025
TIL: Downloading archived Git repositories from archive.softwareheritage.org
(via)
Back in February I blogged about a neat Python library called sqlite-s3vfs for accessing SQLite databases hosted in an S3 bucket, released as MIT licensed open source by the UK government's Department for Business and Trade.
I went looking for it today and found that the github.com/uktrade/sqlite-s3vfs repository is now a 404.
Since this is taxpayer-funded open source software I saw it as my moral duty to try and restore access! It turns out a full copy had been captured by the Software Heritage archive, so I was able to restore the repository from there. My copy is now archived at simonw/sqlite-s3vfs.
The process for retrieving an archive was non-obvious, so I've written up a TIL and also published a new Software Heritage Repository Retriever tool which takes advantage of the CORS-enabled APIs provided by Software Heritage. Here's the Claude Code transcript from building that.
Copyright Release for Contributions To SQLite. D. Richard Hipp called me out for spreading misinformation on Hacker News that SQLite refuses outside contributions:
No, Simon, we don't "refuse". We are just very selective and there is a lot of paperwork involved to confirm the contribution is in the public domain and does not contaminate the SQLite core with licensed code.
I deeply regret this error! I'm linking to the copyright release document here - it looks like SQLite's public domain nature makes this kind of clause extremely important:
[...] To the best of my knowledge and belief, the changes and enhancements that I have contributed to SQLite are either originally written by me or are derived from prior works which I have verified are also in the public domain and are not subject to claims of copyright by other parties.
Out of curiosity I decided to see how many people have contributed to SQLite outside of the core team of Richard, Dan and Joe. I ran that query using Fossil, SQLite's own SQLite-based version control system, like this:
brew install fossil
fossil clone https://www.sqlite.org/src sqlite.fossil
fossil sql -R sqlite.fossil "
SELECT user, COUNT(*) as commits
FROM event WHERE type='ci'
GROUP BY user ORDER BY commits DESC
"
I got back 38 rows, though I think danielk1977 and dan may be duplicates.
Update: The SQLite team have clarified this on their SQLite is Public Domain page. It used to read "In order to keep SQLite completely free and unencumbered by copyright, the project does not accept patches." - it now reads:
In order to keep SQLite completely free and unencumbered by copyright, the project does not accept patches from random people on the internet. There is a process to get a patch accepted, but that process is involved and for smaller changes is not normally worth the effort.
Agentic AI Foundation. Announced today as a new foundation under the parent umbrella of the Linux Foundation (see also the OpenJS Foundation, Cloud Native Computing Foundation, OpenSSF and many more).
The AAIF was started by a heavyweight group of "founding platinum members" ($350,000): AWS, Anthropic, Block, Bloomberg, Cloudflare, Google, Microsoft, and OpenAI. The stated goal is to provide "a neutral, open foundation to ensure agentic AI evolves transparently and collaboratively".
Anthropic have donated Model Context Protocol to the new foundation, OpenAI donated AGENTS.md, Block donated goose (their open source, extensible AI agent).
Personally the project I'd like to see most from an initiative like this one is a clear, community-managed specification for the OpenAI Chat Completions JSON API - or a close equivalent. There are dozens of slightly incompatible implementations of that not-quite-specification floating around already, it would be great to have a written spec accompanied by a compliance test suite.
Deprecations via warnings don’t work for Python libraries
(via)
Seth Larson reports that urllib3 2.6.0 released on the 5th of December and finally removed the HTTPResponse.getheaders() and HTTPResponse.getheader(name, default) methods, which have been marked as deprecated via warnings since v2.0.0 in April 2023. They had to add them back again in a hastily released 2.6.1 a few days later when it turned out major downstream dependents such as kubernetes-client and fastly-py still hadn't upgraded.
Seth says:
My conclusion from this incident is that
DeprecationWarningin its current state does not work for deprecating APIs, at least for Python libraries. That is unfortunate, asDeprecationWarningand thewarningsmodule are easy-to-use, language-"blessed", and explicit without impacting users that don't need to take action due to deprecations.
On Lobste.rs James Bennett advocates for watching for warnings more deliberately:
Something I always encourage people to do, and try to get implemented anywhere I work, is running Python test suites with
-Wonce::DeprecationWarning. This doesn't spam you with noise if a deprecated API is called a lot, but still makes sure you see the warning so you know there's something you need to fix.
I didn't know about the -Wonce option - the documentation describes that as "Warn once per Python process".
Since the beginning of the project in 2023 and the private beta days of Ghostty, I've repeatedly expressed my intention that Ghostty legally become a non-profit. [...]
I want to squelch any possible concerns about a "rug pull". A non-profit structure provides enforceable assurances: the mission cannot be quietly changed, funds cannot be diverted to private benefit, and the project cannot be sold off or repurposed for commercial gain. The structure legally binds Ghostty to the public-benefit purpose it was created to serve. [...]
I believe infrastructure of this kind should be stewarded by a mission-driven, non-commercial entity that prioritizes public benefit over private profit. That structure increases trust, encourages adoption, and creates the conditions for Ghostty to grow into a widely used and impactful piece of open-source infrastructure.
— Mitchell Hashimoto, Ghostty is now Non-Profit
Anthropic acquires Bun. Anthropic just acquired the company behind the Bun JavaScript runtime, which they adopted for Claude Code back in July. Their announcement includes an impressive revenue update on Claude Code:
In November, Claude Code achieved a significant milestone: just six months after becoming available to the public, it reached $1 billion in run-rate revenue.
Here "run-rate revenue" means that their current monthly revenue would add up to $1bn/year.
I've been watching Anthropic's published revenue figures with interest: their annual revenue run rate was $1 billion in January 2025 and had grown to $5 billion by August 2025 and to $7 billion by October.
I had suspected that a large chunk of this was down to Claude Code - given that $1bn figure I guess a large chunk of the rest of the revenue comes from their API customers, since Claude Sonnet/Opus are extremely popular models for coding assistant startups.
Bun founder Jarred Sumner explains the acquisition here. They still had plenty of runway after their $26m raise but did not yet have any revenue:
Instead of putting our users & community through "Bun, the VC-backed startups tries to figure out monetization" – thanks to Anthropic, we can skip that chapter entirely and focus on building the best JavaScript tooling. [...] When people ask "will Bun still be around in five or ten years?", answering with "we raised $26 million" isn't a great answer. [...]
Anthropic is investing in Bun as the infrastructure powering Claude Code, Claude Agent SDK, and future AI coding products. Our job is to make Bun the best place to build, run, and test AI-driven software — while continuing to be a great general-purpose JavaScript runtime, bundler, package manager, and test runner.
We should all be using dependency cooldowns (via) William Woodruff gives a name to a sensible strategy for managing dependencies while reducing the chances of a surprise supply chain attack: dependency cooldowns.
Supply chain attacks happen when an attacker compromises a widely used open source package and publishes a new version with an exploit. These are usually spotted very quickly, so an attack often only has a few hours of effective window before the problem is identified and the compromised package is pulled.
You are most at risk if you're automatically applying upgrades the same day they are released.
William says:
I love cooldowns for several reasons:
- They're empirically effective, per above. They won't stop all attackers, but they do stymie the majority of high-visibiity, mass-impact supply chain attacks that have become more common.
- They're incredibly easy to implement. Moreover, they're literally free to implement in most cases: most people can use Dependabot's functionality, Renovate's functionality, or the functionality build directly into their package manager
The one counter-argument to this is that sometimes an upgrade fixes a security vulnerability, and in those cases every hour of delay in upgrading as an hour when an attacker could exploit the new issue against your software.
I see that as an argument for carefully monitoring the release notes of your dependencies, and paying special attention to security advisories. I'm a big fan of the GitHub Advisory Database for that kind of information.
The fate of “small” open source. Nolan Lawson asks if LLM assistance means that the category of tiny open source libraries like his own blob-util is destined to fade away.
Why take on additional supply chain risks adding another dependency when an LLM can likely kick out the subset of functionality needed by your own code to-order?
I still believe in open source, and I’m still doing it (in fits and starts). But one thing has become clear to me: the era of small, low-value libraries like
blob-utilis over. They were already on their way out thanks to Node.js and the browser taking on more and more of their functionality (seenode:glob,structuredClone, etc.), but LLMs are the final nail in the coffin.
I've been thinking about a similar issue myself recently as well.
Quite a few of my own open source projects exist to solve problems that are frustratingly hard to figure out. s3-credentials is a great example of this: it solves the problem of creating read-only or read-write credentials for an S3 bucket - something that I've always found infuriatingly difficult since you need to know to craft an IAM policy that looks something like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::my-s3-bucket"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectAcl",
"s3:GetObjectLegalHold",
"s3:GetObjectRetention",
"s3:GetObjectTagging"
],
"Resource": [
"arn:aws:s3:::my-s3-bucket/*"
]
}
]
}
Modern LLMs are very good at S3 IAM polices, to the point that if I needed to solve this problem today I doubt I would find it frustrating enough to justify finding or creating a reusable library to help.
The fetch()ening (via) After several years of stable htmx 2.0 and a promise to never release a backwards-incompatible htmx 3 Carson Gross is technically keeping that promise... by skipping to htmx 4 instead!
The main reason is to replace XMLHttpRequest with fetch() - a change that will have enough knock-on compatibility effects to require a major version bump - so they're using that as an excuse to clean up various other accumulated design warts at the same time.
htmx is a very responsibly run project. Here's their plan for the upgrade:
That said, htmx 2.0 users will face an upgrade project when moving to 4.0 in a way that they did not have to in moving from 1.0 to 2.0.
I am sorry about that, and want to offer three things to address it:
- htmx 2.0 (like htmx 1.0 & intercooler.js 1.0) will be supported in perpetuity, so there is absolutely no pressure to upgrade your application: if htmx 2.0 is satisfying your hypermedia needs, you can stick with it.
- We will create extensions that revert htmx 4 to htmx 2 behaviors as much as is feasible (e.g. Supporting the old implicit attribute inheritance model, at least)
- We will roll htmx 4.0 out slowly, over a multi-year period. As with the htmx 1.0 -> 2.0 upgrade, there will be a long period where htmx 2.x is
latestand htmx 4.x isnext
There are lots of neat details in here about the design changes they plan to make. It's a really great piece of technical writing - I learned a bunch about htmx and picked up some good notes on API design in general from this.
I plan to introduce hard Rust dependencies and Rust code into APT, no earlier than May 2026. This extends at first to the Rust compiler and standard library, and the Sequoia ecosystem.
In particular, our code to parse .deb, .ar, .tar, and the HTTP signature verification code would strongly benefit from memory safe languages and a stronger approach to unit testing.
If you maintain a port without a working Rust toolchain, please ensure it has one within the next 6 months, or sunset the port.
— Julian Andres Klode, debian-devel mailing list
Marimo is Joining CoreWeave (via) I don't usually cover startup acquisitions here, but this one feels relevant to several of my interests.
Marimo (previously) provide an open source (Apache 2 licensed) notebook tool for Python, with first-class support for an additional WebAssembly build plus an optional hosted service. It's effectively a reimagining of Jupyter notebooks as a reactive system, where cells automatically update based on changes to other cells - similar to how Observable JavaScript notebooks work.
The first public Marimo release was in January 2024 and the tool has "been in development since 2022" (source).
CoreWeave are a big player in the AI data center space. They started out as an Ethereum mining company in 2017, then pivoted to cloud computing infrastructure for AI companies after the 2018 cryptocurrency crash. They IPOd in March 2025 and today they operate more than 30 data centers worldwide and have announced a number of eye-wateringly sized deals with companies such as Cohere and OpenAI. I found their Wikipedia page very helpful.
They've also been on an acquisition spree this year, including:
- Weights & Biases in March 2025 (deal closed in May), the AI training observability platform.
- OpenPipe in September 2025 - a reinforcement learning platform, authors of the Agent Reinforcement Trainer Apache 2 licensed open source RL framework.
- Monolith AI in October 2025, a UK-based AI model SaaS platform focused on AI for engineering and industrial manufacturing.
- And now Marimo.
Marimo's own announcement emphasizes continued investment in that tool:
Marimo is joining CoreWeave. We’re continuing to build the open-source marimo notebook, while also leveling up molab with serious compute. Our long-term mission remains the same: to build the world’s best open-source programming environment for working with data.
marimo is, and always will be, free, open-source, and permissively licensed.
Give CoreWeave's buying spree only really started this year it's impossible to say how well these acquisitions are likely to play out - they haven't yet established a track record.
The PSF has withdrawn a $1.5 million proposal to US government grant program. The Python Software Foundation was recently "recommended for funding" (NSF terminology) for a $1.5m grant from the US government National Science Foundation to help improve the security of the Python software ecosystem, after an grant application process lead by Seth Larson and Loren Crary.
The PSF's annual budget is less than $6m so this is a meaningful amount of money for the organization!
We were forced to withdraw our application and turn down the funding, thanks to new language that was added to the agreement requiring us to affirm that we "do not, and will not during the term of this financial assistance award, operate any programs that advance or promote DEI, or discriminatory equity ideology in violation of Federal anti-discrimination laws."
Our legal advisors confirmed that this would not just apply to security work covered by the grant - this would apply to all of the PSF's activities.
This was not an option for us. Here's the mission of the PSF:
The mission of the Python Software Foundation is to promote, protect, and advance the Python programming language, and to support and facilitate the growth of a diverse and international community of Python programmers.
If we accepted and spent the money despite this term, there was a very real risk that the money could be clawed back later. That represents an existential risk for the foundation since we would have already spent the money!
I was one of the board members who voted to reject this funding - a unanimous but tough decision. I’m proud to serve on a board that can make difficult decisions like this.
If you'd like to sponsor the PSF you can find out more on our site. I'd love to see a few more of the large AI labs show up on our top-tier visionary sponsors list.
A Retrospective Survey of 2024/2025 Open Source Supply Chain Compromises (via) Filippo Valsorda surveyed 18 incidents from the past year of open source supply chain attacks, where package updates were infected with malware thanks to a compromise of the project itself.
These are important lessons:
I have the growing impression that software supply chain compromises have a few predominant causes which we might have a responsibility as a professional open source maintainers to robustly mitigate.
To test this impression and figure out any such mitigations, I collected all 2024/2025 open source supply chain compromises I could find, and categorized their root cause.
This is a fascinating piece of research. 5 were the result of phishing (maintainers should use passkeys/WebAuthn!), ~5 were stolen long-lived credentials, 3 were "control handoff" where a maintainer gave project access to someone who later turned out to be untrustworthy, 4 were caused by GitHub Actions workflows that triggered on pull requests or issue comments in a way that could leak credentials, and one (MavenGate) was caused by an expired domain being resurrected.
Python 3.14. This year's major Python version, Python 3.14, just made its first stable release!
As usual the what's new in Python 3.14 document is the best place to get familiar with the new release:
The biggest changes include template string literals, deferred evaluation of annotations, and support for subinterpreters in the standard library.
The library changes include significantly improved capabilities for introspection in asyncio, support for Zstandard via a new compression.zstd module, syntax highlighting in the REPL, as well as the usual deprecations and removals, and improvements in user-friendliness and correctness.
Subinterpreters look particularly interesting as a way to use multiple CPU cores to run Python code despite the continued existence of the GIL. If you're feeling brave and your dependencies cooperate you can also use the free-threaded build of Python 3.14 - now officially supported - to skip the GIL entirely.
A new major Python release means an older release hits the end of its support lifecycle - in this case that's Python 3.9. If you maintain open source libraries that target every supported Python versions (as I do) this means features introduced in Python 3.10 can now be depended on! What's new in Python 3.10 lists those - I'm most excited by structured pattern matching (the match/case statement) and the union type operator, allowing int | float | None as a type annotation in place of Optional[Union[int, float]].
If you use uv you can grab a copy of 3.14 using:
uv self update
uv python upgrade 3.14
uvx python@3.14
Or for free-threaded Python 3.1;:
uvx python@3.14t
The uv team wrote about their Python 3.14 highlights in their announcement of Python 3.14's availability via uv.
The GitHub Actions setup-python action includes Python 3.14 now too, so the following YAML snippet in will run tests on all currently supported versions:
strategy:
matrix:
python-version: ["3.10", "3.11", "3.12", "3.13", "3.14"]
steps:
- uses: actions/setup-python@v6
with:
python-version: ${{ matrix.python-version }}
Full example here for one of my many Datasette plugin repos.
When attention is being appropriated, producers need to weigh the costs and benefits of the transaction. To assess whether the appropriation of attention is net-positive, it’s useful to distinguish between extractive and non-extractive contributions. Extractive contributions are those where the marginal cost of reviewing and merging that contribution is greater than the marginal benefit to the project’s producers. In the case of a code contribution, it might be a pull request that’s too complex or unwieldy to review, given the potential upside
— Nadia Eghbal, Working in Public, via the draft LLVM AI tools policy
I thought I had an verbal agreement with them, that “Varnish Cache” was the FOSS project and “Varnish Software” was the commercial entitity, but the current position of Varnish Software’s IP-lawyers is that nobody can use “Varnish Cache” in any context, without their explicit permission. [...]
We have tried to negotiatiate with Varnish Software for many months about this issue, but their IP-Lawyers still insist that Varnish Software owns the Varnish Cache name, and at most we have being offered a strictly limited, subject to their veto, permission for the FOSS project to use the “Varnish Cache” name.
We cannot live with that: We are independent FOSS project with our own name.
So we will change the name of the project.
The new association and the new project will be named “The Vinyl Cache Project”, and this release 8.0.0, will be the last under the “Varnish Cache” name.
— Poul-Henning Kamp, Varnish 8.0.0 release notes
Maintainers of Last Resort (via) Filippo Valsorda founded Geomys last year as an "organization of professional open source maintainers", providing maintenance and support for critical packages in the Go language ecosystem backed by clients in retainer relationships.
This is an inspiring and optimistic shape for financially sustaining key open source projects, and it appears be working really well.
Most recently, Geomys have started acting as a "maintainer of last resort" for security-related Go projects in need of new maintainers. In this piece Filippo describes their work on the bluemonday HTML sanitization library - similar to Python’s bleach which was deprecated in 2023. He also talks at length about their work on CSRF for Go after gorilla/csrf lost active maintenance - I’m still working my way through his earlier post on Cross-Site Request Forgery trying to absorb the research shared their about the best modern approaches to this vulnerability.
pyx: a Python-native package registry, now in Beta (via) Since its first release, the single biggest question around the uv Python environment management tool has been around Astral's business model: Astral are a VC-backed company and at some point they need to start making real revenue.
Back in September Astral founder Charlie Marsh said the following:
I don't want to charge people money to use our tools, and I don't want to create an incentive structure whereby our open source offerings are competing with any commercial offerings (which is what you see with a lost of hosted-open-source-SaaS business models).
What I want to do is build software that vertically integrates with our open source tools, and sell that software to companies that are already using Ruff, uv, etc. Alternatives to things that companies already pay for today.
An example of what this might look like (we may not do this, but it's helpful to have a concrete example of the strategy) would be something like an enterprise-focused private package registry. [...]
It looks like those plans have become concrete now! From today's announcement:
TL;DR: pyx is a Python-native package registry --- and the first piece of the Astral platform, our next-generation infrastructure for the Python ecosystem.
We think of pyx as an optimized backend for uv: it's a package registry, but it also solves problems that go beyond the scope of a traditional "package registry", making your Python experience faster, more secure, and even GPU-aware, both for private packages and public sources (like PyPI and the PyTorch index).
pyx is live with our early partners, including Ramp, Intercom, and fal [...]
This looks like a sensible direction to me, and one that stays true to Charlie's promises to carefully design the incentive structure to avoid corrupting the core open source project that the Python community is coming to depend on.
OpenAI’s new open weight (Apache 2) models are really good
The long promised OpenAI open weight models are here, and they are very impressive. They’re available under proper open source licenses—Apache 2.0—and come in two sizes, 120B and 20B.
[... 2,771 words]Something that has become undeniable this month is that the best available open weight models now come from the Chinese AI labs.
I continue to have a lot of love for Mistral, Gemma and Llama but my feeling is that Qwen, Moonshot and Z.ai have positively smoked them over the course of July.
Here's what came out this month, with links to my notes on each one:
- Moonshot Kimi-K2-Instruct - 11th July, 1 trillion parameters
- Qwen Qwen3-235B-A22B-Instruct-2507 - 21st July, 235 billion
- Qwen Qwen3-Coder-480B-A35B-Instruct - 22nd July, 480 billion
- Qwen Qwen3-235B-A22B-Thinking-2507 - 25th July, 235 billion
- Z.ai GLM-4.5 and GLM-4.5 Air - 28th July, 355 and 106 billion
- Qwen Qwen3-30B-A3B-Instruct-2507 - 29th July, 30 billion
- Qwen Qwen3-30B-A3B-Thinking-2507 - 30th July, 30 billion
- Qwen Qwen3-Coder-30B-A3B-Instruct - 31st July, 30 billion (released after I first posted this note)
Notably absent from this list is DeepSeek, but that's only because their last model release was DeepSeek-R1-0528 back in April.
The only janky license among them is Kimi K2, which uses a non-OSI-compliant modified MIT. Qwen's models are all Apache 2 and Z.ai's are MIT.
The larger Chinese models all offer their own APIs and are increasingly available from other providers. I've been able to run versions of the Qwen 30B and GLM-4.5 Air 106B models on my own laptop.
I can't help but wonder if part of the reason for the delay in release of OpenAI's open weights model comes from a desire to be notably better than this truly impressive lineup of Chinese models.
Update August 5th 2025: The OpenAI open weight models came out and they are very impressive.
Announcing Toad—a universal UI for agentic coding in the terminal. Will McGugan is building his own take on a terminal coding assistant, in the style of Claude Code and Gemini CLI, using his Textual Python library as the display layer.
Will makes some confident claims about this being a better approach than the Node UI libraries used in those other tools:
Both Anthropic and Google’s apps flicker due to the way they perform visual updates. These apps update the terminal by removing the previous lines and writing new output (even if only a single line needs to change). This is a surprisingly expensive operation in terminals, and has a high likelihood you will see a partial frame—which will be perceived as flicker. [...]
Toad doesn’t suffer from these issues. There is no flicker, as it can update partial regions of the output as small as a single character. You can also scroll back up and interact with anything that was previously written, including copying un-garbled output — even if it is cropped.
Using Node.js for terminal apps means that users with npx can run them easily without worrying too much about installation - Will points out that uvx has closed the developer experience there for tools written in Python.
Toad will be open source eventually, but is currently in a private preview that's open to companies who sponsor Will's work for $5,000:
[...] you can gain access to Toad by sponsoring me on GitHub sponsors. I anticipate Toad being used by various commercial organizations where $5K a month wouldn't be a big ask. So consider this a buy-in to influence the project for communal benefit at this early stage.
With a bit of luck, this sabbatical needn't eat in to my retirement fund too much. If it goes well, it may even become my full-time gig.
I really hope this works! It would be great to see this kind of model proven as a new way to financially support experimental open source projects of this nature.
I wrote about Textual's streaming markdown implementation the other day, and this post goes into a whole lot more detail about optimizations Will has discovered for making that work better.
The key optimization is to only re-render the last displayed block of the Markdown document, which might be a paragraph or a heading or a table or list, avoiding having to re-render the entire thing any time a token is added to it... with one important catch:
It turns out that the very last block can change its type when you add new content. Consider a table where the first tokens add the headers to the table. The parser considers that text to be a simple paragraph block up until the entire row has arrived, and then all-of-a-sudden the paragraph becomes a table.
Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity (via) METR - for Model Evaluation & Threat Research - are a non-profit research institute founded by Beth Barnes, a former alignment researcher at OpenAI (see Wikipedia). They've previously contributed to system cards for OpenAI and Anthropic, but this new research represents a slightly different direction for them:
We conduct a randomized controlled trial (RCT) to understand how early-2025 AI tools affect the productivity of experienced open-source developers working on their own repositories. Surprisingly, we find that when developers use AI tools, they take 19% longer than without—AI makes them slower.
The full paper (PDF) has a lot of details that are missing from the linked summary.
METR recruited 16 experienced open source developers for their study, with varying levels of exposure to LLM tools. They then assigned them tasks from their own open source projects, randomly assigning whether AI was allowed or not allowed for each of those tasks.
They found a surprising difference between developer estimates and actual completion times:
After completing the study, developers estimate that allowing AI reduced completion time by 20%. Surprisingly, we find that allowing AI actually increases completion time by 19%—AI tooling slowed developers down.
I shared my initial intuition about this paper on Hacker News the other day:
My personal theory is that getting a significant productivity boost from LLM assistance and AI tools has a much steeper learning curve than most people expect.
This study had 16 participants, with a mix of previous exposure to AI tools - 56% of them had never used Cursor before, and the study was mainly about Cursor.
They then had those 16 participants work on issues (about 15 each), where each issue was randomly assigned a "you can use AI" v.s. "you can't use AI" rule.
So each developer worked on a mix of AI-tasks and no-AI-tasks during the study.
A quarter of the participants saw increased performance, 3/4 saw reduced performance.
One of the top performers for AI was also someone with the most previous Cursor experience. The paper acknowledges that here:
However, we see positive speedup for the one developer who has more than 50 hours of Cursor experience, so it's plausible that there is a high skill ceiling for using Cursor, such that developers with significant experience see positive speedup.
My intuition here is that this study mainly demonstrated that the learning curve on AI-assisted development is high enough that asking developers to bake it into their existing workflows reduces their performance while they climb that learing curve.
I got an insightful reply there from Nate Rush, one of the authors of the study, which included these notes:
- Some prior studies that find speedup do so with developers that have similar (or less!) experience with the tools they use. In other words, the "steep learning curve" theory doesn't differentially explain our results vs. other results.
- Prior to the study, 90+% of developers had reasonable experience prompting LLMs. Before we found slowdown, this was the only concern that most external reviewers had about experience was about prompting -- as prompting was considered the primary skill. In general, the standard wisdom was/is Cursor is very easy to pick up if you're used to VSCode, which most developers used prior to the study.
- Imagine all these developers had a TON of AI experience. One thing this might do is make them worse programmers when not using AI (relatable, at least for me), which in turn would raise the speedup we find (but not because AI was better, but just because with AI is much worse). In other words, we're sorta in between a rock and a hard place here -- it's just plain hard to figure out what the right baseline should be!
- We shared information on developer prior experience with expert forecasters. Even with this information, forecasters were still dramatically over-optimistic about speedup.
- As you say, it's totally possible that there is a long-tail of skills to using these tools -- things you only pick up and realize after hundreds of hours of usage. Our study doesn't really speak to this. I'd be excited for future literature to explore this more.
In general, these results being surprising makes it easy to read the paper, find one factor that resonates, and conclude "ah, this one factor probably just explains slowdown." My guess: there is no one factor -- there's a bunch of factors that contribute to this result -- at least 5 seem likely, and at least 9 we can't rule out (see the factors table on page 11).
Here's their table of the most likely factors:
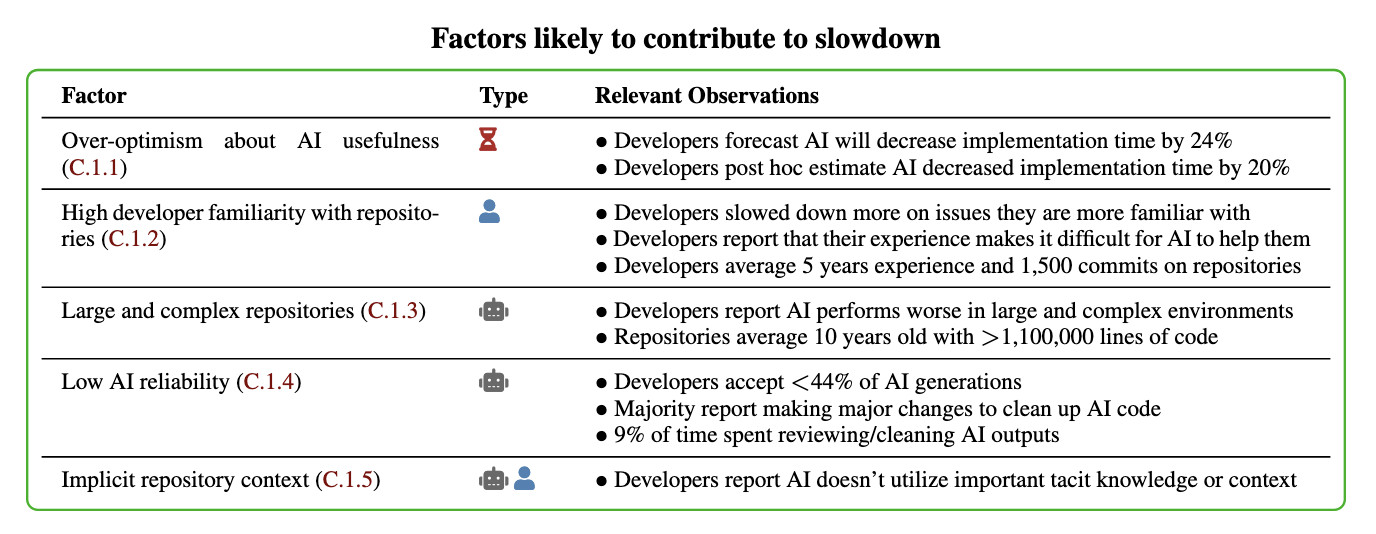
I think Nate's right that jumping straight to a conclusion about a single factor is a shallow and unproductive way to think about this report.
That said, I can't resist the temptation to do exactly that! The factor that stands out most to me is that these developers were all working in repositories they have a deep understanding of already, presumably on non-trivial issues since any trivial issues are likely to have been resolved in the past.
I think this is a really interesting paper. Measuring developer productivity is notoriously difficult. I hope this paper inspires more work with a similar level of detail to analyzing how professional programmers spend their time:
To compare how developers spend their time with and without AI assistance, we manually label a subset of 128 screen recordings with fine-grained activity labels, totaling 143 hours of video.
Following the widespread availability of large language models (LLMs), the Django Security Team has received a growing number of security reports generated partially or entirely using such tools. Many of these contain inaccurate, misleading, or fictitious content. While AI tools can help draft or analyze reports, they must not replace human understanding and review.
If you use AI tools to help prepare a report, you must:
- Disclose which AI tools were used and specify what they were used for (analysis, writing the description, writing the exploit, etc).
- Verify that the issue describes a real, reproducible vulnerability that otherwise meets these reporting guidelines.
- Avoid fabricated code, placeholder text, or references to non-existent Django features.
Reports that appear to be unverified AI output will be closed without response. Repeated low-quality submissions may result in a ban from future reporting
— Django’s security policies, on AI-Assisted Reports
microsoft/vscode-copilot-chat (via) As promised at Build 2025 in May, Microsoft have released the GitHub Copilot Chat client for VS Code under an open source (MIT) license.
So far this is just the extension that provides the chat component of Copilot, but the launch announcement promises that Copilot autocomplete will be coming in the near future:
Next, we will carefully refactor the relevant components of the extension into VS Code core. The original GitHub Copilot extension that provides inline completions remains closed source -- but in the following months we plan to have that functionality be provided by the open sourced GitHub Copilot Chat extension.
I've started spelunking around looking for the all-important prompts. So far the most interesting I've found are in prompts/node/agent/agentInstructions.tsx, with a <Tag name='instructions'> block that starts like this:
You are a highly sophisticated automated coding agent with expert-level knowledge across many different programming languages and frameworks. The user will ask a question, or ask you to perform a task, and it may require lots of research to answer correctly. There is a selection of tools that let you perform actions or retrieve helpful context to answer the user's question.
There are tool use instructions - some edited highlights from those:
When using the ReadFile tool, prefer reading a large section over calling the ReadFile tool many times in sequence. You can also think of all the pieces you may be interested in and read them in parallel. Read large enough context to ensure you get what you need.You can use the FindTextInFiles to get an overview of a file by searching for a string within that one file, instead of using ReadFile many times.Don't call the RunInTerminal tool multiple times in parallel. Instead, run one command and wait for the output before running the next command.After you have performed the user's task, if the user corrected something you did, expressed a coding preference, or communicated a fact that you need to remember, use the UpdateUserPreferences tool to save their preferences.NEVER try to edit a file by running terminal commands unless the user specifically asks for it.Use the ReplaceString tool to replace a string in a file, but only if you are sure that the string is unique enough to not cause any issues. You can use this tool multiple times per file.
That file also has separate CodesearchModeInstructions, as well as a SweBenchAgentPrompt class with a comment saying that it is "used for some evals with swebench".
Elsewhere in the code, prompt/node/summarizer.ts illustrates one of their approaches to Context Summarization, with a prompt that looks like this:
You are an expert at summarizing chat conversations.
You will be provided:
- A series of user/assistant message pairs in chronological order
- A final user message indicating the user's intent.
[...]
Structure your summary using the following format:
TITLE: A brief title for the summary
USER INTENT: The user's goal or intent for the conversation
TASK DESCRIPTION: Main technical goals and user requirements
EXISTING: What has already been accomplished. Include file paths and other direct references.
PENDING: What still needs to be done. Include file paths and other direct references.
CODE STATE: A list of all files discussed or modified. Provide code snippets or diffs that illustrate important context.
RELEVANT CODE/DOCUMENTATION SNIPPETS: Key code or documentation snippets from referenced files or discussions.
OTHER NOTES: Any additional context or information that may be relevant.
prompts/node/panel/terminalQuickFix.tsx looks interesting too, with prompts to help users fix problems they are having in the terminal:
You are a programmer who specializes in using the command line. Your task is to help the user fix a command that was run in the terminal by providing a list of fixed command suggestions. Carefully consider the command line, output and current working directory in your response. [...]
That file also has a PythonModuleError prompt:
Follow these guidelines for python:
- NEVER recommend using "pip install" directly, always recommend "python -m pip install"
- The following are pypi modules: ruff, pylint, black, autopep8, etc
- If the error is module not found, recommend installing the module using "python -m pip install" command.
- If activate is not available create an environment using "python -m venv .venv".
There's so much more to explore in here. xtab/common/promptCrafting.ts looks like it may be part of the code that's intended to replace Copilot autocomplete, for example.
The way it handles evals is really interesting too. The code for that lives in the test/ directory. There's a lot of it, so I engaged Gemini 2.5 Pro to help figure out how it worked:
git clone https://github.com/microsoft/vscode-copilot-chat
cd vscode-copilot-chat/chat
files-to-prompt -e ts -c . | llm -m gemini-2.5-pro -s \
'Output detailed markdown architectural documentation explaining how this test suite works, with a focus on how it tests LLM prompts'
Here's the resulting generated documentation, which even includes a Mermaid chart (I had to save the Markdown in a regular GitHub repository to get that to render - Gists still don't handle Mermaid.)
The neatest trick is the way it uses a SQLite-based caching mechanism to cache the results of prompts from the LLM, which allows the test suite to be run deterministically even though LLMs themselves are famously non-deterministic.
llvm: InstCombine: improve optimizations for ceiling division with no overflow—a PR by Alex Gaynor and Claude Code. Alex Gaynor maintains rust-asn1, and recently spotted a missing LLVM compiler optimization while hacking on it, with the assistance of Claude (Alex works for Anthropic).
He describes how he confirmed that optimization in So you want to serialize some DER?, taking advantage of a tool called Alive2 to automatically verify that the potential optimization resulted in the same behavior.
Alex filed a bug, and then...
Obviously the next move is to see if I can send a PR to LLVM, but it’s been years since I was doing compiler development or was familiar with the LLVM internals and I wasn’t really prepared to invest the time and energy necessary to get back up to speed. But as a friend pointed out… what about Claude?
At this point my instinct was, "Claude is great, but I'm not sure if I'll be able to effectively code review any changes it proposes, and I'm not going to be the asshole who submits an untested and unreviewed PR that wastes a bunch of maintainer time". But excitement got the better of me, and I asked
claude-codeto see if it could implement the necessary optimization, based on nothing more than the test cases.
Alex reviewed the resulting code very carefully to ensure he wasn't wasting anyone's time, then submitted the PR and had Claude Code help implement the various changes requested by the reviewers. The optimization landed two weeks ago.
Alex's conclusion (emphasis mine):
I am incredibly leery about over-generalizing how to understand the capacity of the models, but at a minimum it seems safe to conclude that sometimes you should just let the model have a shot at a problem and you may be surprised -- particularly when the problem has very clear success criteria. This only works if you have the capacity to review what it produces, of course. [...]
This echoes Ethan Mollick's advice to "always invite AI to the table". For programming tasks the "very clear success criteria" is extremely important, as it helps fit the tools-in-a-loop pattern implemented by coding agents such as Claude Code.
LLVM have a policy on AI-assisted contributions which is compatible with Alex's work here:
[...] the LLVM policy is that contributors are permitted to use artificial intelligence tools to produce contributions, provided that they have the right to license that code under the project license. Contributions found to violate this policy will be removed just like any other offending contribution.
While the LLVM project has a liberal policy on AI tool use, contributors are considered responsible for their contributions. We encourage contributors to review all generated code before sending it for review to verify its correctness and to understand it so that they can answer questions during code review.
Back in April Ben Evans put out a call for concrete evidence that LLM tools were being used to solve non-trivial problems in mature open source projects:
I keep hearing #AI boosters / talking heads claiming that #LLMs have transformed software development [...] Share some AI-derived pull requests that deal with non-obvious corner cases or non-trivial bugs from mature #opensource projects.
I think this LLVM optimization definitely counts!
(I also like how this story supports the idea that AI tools amplify existing human expertise rather than replacing it. Alex had previous experience with LLVM, albeit rusty, and could lean on that knowledge to help direct and evaluate Claude's work.)
Gemini CLI. First there was Claude Code in February, then OpenAI Codex (CLI) in April, and now Gemini CLI in June. All three of the largest AI labs now have their own version of what I am calling a "terminal agent" - a CLI tool that can read and write files and execute commands on your behalf in the terminal.
I'm honestly a little surprised at how significant this category has become: I had assumed that terminal tools like this would always be something of a niche interest, but given the number of people I've heard from spending hundreds of dollars a month on Claude Code this niche is clearly larger and more important than I had thought!
I had a few days of early access to the Gemini one. It's very good - it takes advantage of Gemini's million token context and has good taste in things like when to read a file and when to run a command.
Like OpenAI Codex and unlike Claude Code it's open source (Apache 2) - the full source code can be found in google-gemini/gemini-cli on GitHub. The core system prompt lives in core/src/core/prompts.ts - I've extracted that out as a rendered Markdown Gist.
As usual, the system prompt doubles as extremely accurate and concise documentation of what the tool can do! Here's what it has to say about comments, for example:
- Comments: Add code comments sparingly. Focus on why something is done, especially for complex logic, rather than what is done. Only add high-value comments if necessary for clarity or if requested by the user. Do not edit comments that are seperate from the code you are changing. NEVER talk to the user or describe your changes through comments.
The list of preferred technologies is interesting too:
When key technologies aren't specified prefer the following:
- Websites (Frontend): React (JavaScript/TypeScript) with Bootstrap CSS, incorporating Material Design principles for UI/UX.
- Back-End APIs: Node.js with Express.js (JavaScript/TypeScript) or Python with FastAPI.
- Full-stack: Next.js (React/Node.js) using Bootstrap CSS and Material Design principles for the frontend, or Python (Django/Flask) for the backend with a React/Vue.js frontend styled with Bootstrap CSS and Material Design principles.
- CLIs: Python or Go.
- Mobile App: Compose Multiplatform (Kotlin Multiplatform) or Flutter (Dart) using Material Design libraries and principles, when sharing code between Android and iOS. Jetpack Compose (Kotlin JVM) with Material Design principles or SwiftUI (Swift) for native apps targeted at either Android or iOS, respectively.
- 3d Games: HTML/CSS/JavaScript with Three.js.
- 2d Games: HTML/CSS/JavaScript.
As far as I can tell Gemini CLI only defines a small selection of tools:
edit: To modify files programmatically.glob: To find files by pattern.grep: To search for content within files.ls: To list directory contents.shell: To execute a command in the shellmemoryTool: To remember user-specific facts.read-file: To read a single filewrite-file: To write a single fileread-many-files: To read multiple files at once.web-fetch: To get content from URLs.web-search: To perform a web search (using Grounding with Google Search via the Gemini API).
I found most of those by having Gemini CLI inspect its own code for me! Here's that full transcript, which used just over 300,000 tokens total.
How much does it cost? The announcement describes a generous free tier:
To use Gemini CLI free-of-charge, simply login with a personal Google account to get a free Gemini Code Assist license. That free license gets you access to Gemini 2.5 Pro and its massive 1 million token context window. To ensure you rarely, if ever, hit a limit during this preview, we offer the industry’s largest allowance: 60 model requests per minute and 1,000 requests per day at no charge.
It's not yet clear to me if your inputs can be used to improve Google's models if you are using the free tier - that's been the situation with free prompt inference they have offered in the past.
You can also drop in your own paid API key, at which point your data will not be used for model improvements and you'll be billed based on your token usage.
My First Open Source AI Generated Library (via) Armin Ronacher had Claude and Claude Code do almost all of the work in building, testing, packaging and publishing a new Python library based on his design:
- It wrote ~1100 lines of code for the parser
- It wrote ~1000 lines of tests
- It configured the entire Python package, CI, PyPI publishing
- Generated a README, drafted a changelog, designed a logo, made it theme-aware
- Did multiple refactorings to make me happier
The project? sloppy-xml-py, a lax XML parser (and violation of everything the XML Working Group hold sacred) which ironically is necessary because LLMs themselves frequently output "XML" that includes validation errors.
Claude's SVG logo design is actually pretty decent, turns out it can draw more than just bad pelicans!

I think experiments like this are a really valuable way to explore the capabilities of these models. Armin's conclusion:
This was an experiment to see how far I could get with minimal manual effort, and to unstick myself from an annoying blocker. The result is good enough for my immediate use case and I also felt good enough to publish it to PyPI in case someone else has the same problem.
Treat it as a curious side project which says more about what's possible today than what's necessarily advisable.
I'd like to present a slightly different conclusion here. The most interesting thing about this project is that the code is good.
My criteria for good code these days is the following:
- Solves a defined problem, well enough that I'm not tempted to solve it in a different way
- Uses minimal dependencies
- Clear and easy to understand
- Well tested, with tests prove that the code does what it's meant to do
- Comprehensive documentation
- Packaged and published in a way that makes it convenient for me to use
- Designed to be easy to maintain and make changes in the future
sloppy-xml-py fits all of those criteria. It's useful, well defined, the code is readable with just about the right level of comments, everything is tested, the documentation explains everything I need to know, and it's been shipped to PyPI.
I'd be proud to have written this myself.
This example is not an argument for replacing programmers with LLMs. The code is good because Armin is an expert programmer who stayed in full control throughout the process. As I wrote the other day, a skilled individual with both deep domain understanding and deep understanding of the capabilities of the agent.
Run Your Own AI (via) Anthony Lewis published this neat, concise tutorial on using my LLM tool to run local models on your own machine, using llm-mlx.
An under-appreciated way to contribute to open source projects is to publish unofficial guides like this one. Always brightens my day when something like this shows up.
What people get wrong about the leading Chinese open models: Adoption and censorship (via) While I've been enjoying trying out Alibaba's Qwen 3 a lot recently, Nathan Lambert focuses on the elephant in the room:
People vastly underestimate the number of companies that cannot use Qwen and DeepSeek open models because they come from China. This includes on-premise solutions built by people who know the fact that model weights alone cannot reveal anything to their creators.
The root problem here is the closed nature of the training data. Even if a model is open weights, it's not possible to conclusively determine that it couldn't add backdoors to generated code or trigger "indirect influence of Chinese values on Western business systems". Qwen 3 certainly has baked in opinions about the status of Taiwan!
Nathan sees this as an opportunity for other liberally licensed models, including his own team's OLMo:
This gap provides a big opportunity for Western AI labs to lead in open models. Without DeepSeek and Qwen, the top tier of models we’re left with are Llama and Gemma, which both have very restrictive licenses when compared to their Chinese counterparts. These licenses are proportionally likely to block an IT department from approving a model.
This takes us to the middle tier of permissively licensed, open weight models who actually have a huge opportunity ahead of them: OLMo, of course, I’m biased, Microsoft with Phi, Mistral, IBM (!??!), and some other smaller companies to fill out the long tail.