76 posts tagged “data-journalism”
2026
Coding agents for data analysis. Here's the handout I prepared for my NICAR 2026 workshop "Coding agents for data analysis" - a three hour session aimed at data journalists demonstrating ways that tools like Claude Code and OpenAI Codex can be used to explore, analyze and clean data.
Here's the table of contents:
I ran the workshop using GitHub Codespaces and OpenAI Codex, since it was easy (and inexpensive) to distribute a budget-restricted API key for Codex that attendees could use during the class. Participants ended up burning $23 of Codex tokens.
The exercises all used Python and SQLite and some of them used Datasette.
One highlight of the workshop was when we started running Datasette such that it served static content from a viz/ folder, then had Claude Code start vibe coding new interactive visualizations directly in that folder. Here's a heat map it created for my trees database using Leaflet and Leaflet.heat, source code here.

I designed the handout to also be useful for people who weren't able to attend the session in person. As is usually the case, material aimed at data journalists is equally applicable to anyone else with data to explore.
An AI-generated report, delivered directly to the email inboxes of journalists, was an essential tool in the Times’ coverage. It was also one of the first signals that conservative media was turning against the administration [...]
Built in-house and known internally as the “Manosphere Report,” the tool uses large language models (LLMs) to transcribe and summarize new episodes of dozens of podcasts.
“The Manosphere Report gave us a really fast and clear signal that this was not going over well with that segment of the President’s base,” said Seward. “There was a direct link between seeing that and then diving in to actually cover it.”
— Andrew Deck for Niemen Lab, How The New York Times uses a custom AI tool to track the “manosphere”
2025
Under the hood of Canada Spends with Brendan Samek

I talked to Brendan Samek about Canada Spends, a project from Build Canada that makes Canadian government financial data accessible and explorable using a combination of Datasette, a neat custom frontend, Ruby ingestion scripts, sqlite-utils and pieces of LLM-powered PDF extraction.
[... 561 words]Highlights from my appearance on the Data Renegades podcast with CL Kao and Dori Wilson

I talked with CL Kao and Dori Wilson for an episode of their new Data Renegades podcast titled Data Journalism Unleashed with Simon Willison.
[... 2,964 words]Recreating the Apollo AI adoption rate chart with GPT-5, Python and Pyodide
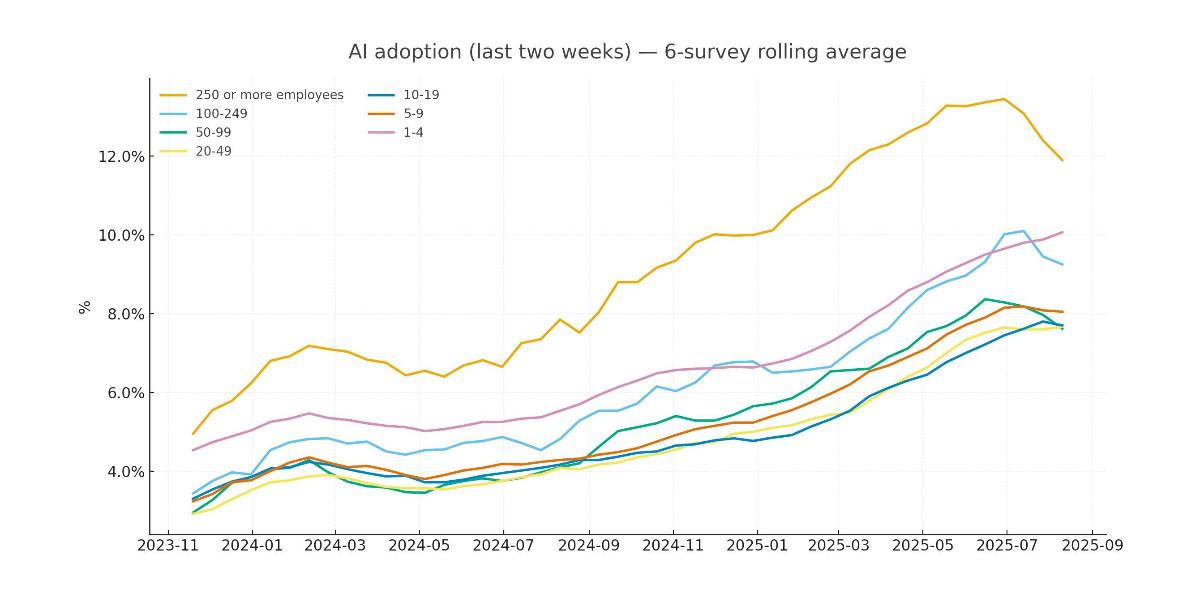
Apollo Global Management’s “Chief Economist” Dr. Torsten Sløk released this interesting chart which appears to show a slowdown in AI adoption rates among large (>250 employees) companies:
[... 2,673 words]How OpenElections Uses LLMs (via) The OpenElections project collects detailed election data for the USA, all the way down to the precinct level. This is a surprisingly hard problem: while county and state-level results are widely available, precinct-level results are published in thousands of different ad-hoc ways and rarely aggregated once the election result has been announced.
A lot of those precinct results are published as image-filled PDFs.
Derek Willis has recently started leaning on Gemini to help parse those PDFs into CSV data:
For parsing image PDFs into CSV files, Google’s Gemini is my model of choice, for two main reasons. First, the results are usually very, very accurate (with a few caveats I’ll detail below), and second, Gemini’s large context window means it’s possible to work with PDF files that can be multiple MBs in size.
Is this piece he shares the process and prompts for a real-world expert level data entry project, assisted by Gemini.
This example from Limestone County, Texas is a great illustration of how tricky this problem can get. Getting traditional OCR software to correctly interpret multi-column layouts like this always requires some level of manual intervention:
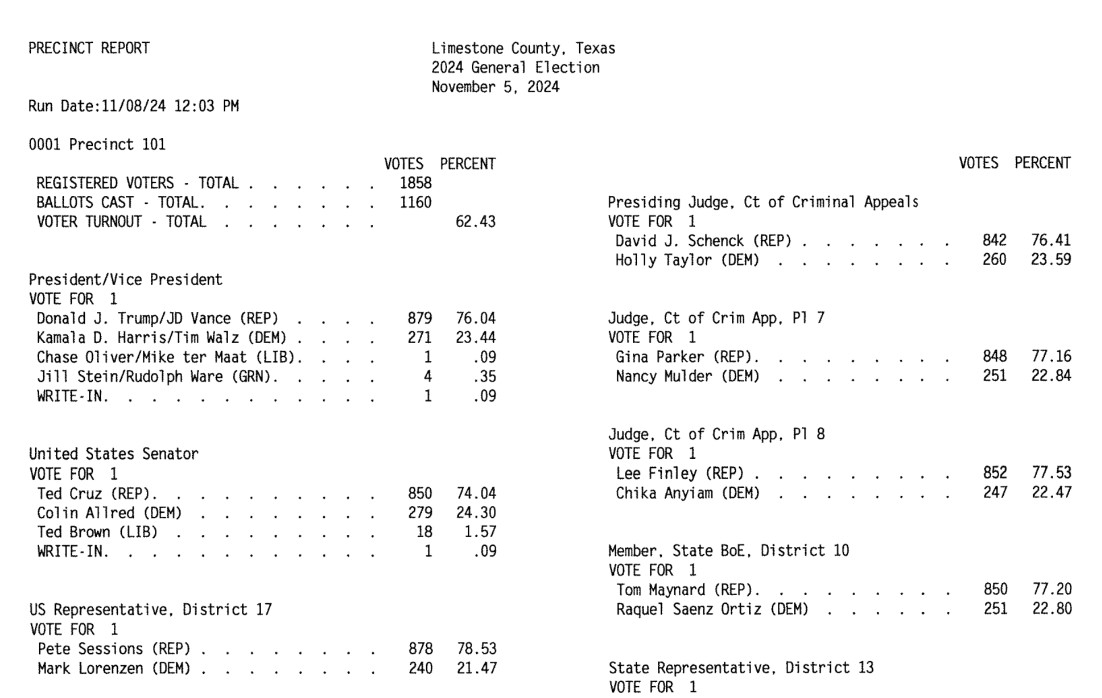
Derek's prompt against Gemini 2.5 Pro throws in an example, some special instructions and a note about the two column format:
Produce a CSV file from the attached PDF based on this example:
county,precinct,office,district,party,candidate,votes,absentee,early_voting,election_day
Limestone,Precinct 101,Registered Voters,,,,1858,,,
Limestone,Precinct 101,Ballots Cast,,,,1160,,,
Limestone,Precinct 101,President,,REP,Donald J. Trump,879,,,
Limestone,Precinct 101,President,,DEM,Kamala D. Harris,271,,,
Limestone,Precinct 101,President,,LIB,Chase Oliver,1,,,
Limestone,Precinct 101,President,,GRN,Jill Stein,4,,,
Limestone,Precinct 101,President,,,Write-ins,1,,,
Skip Write-ins with candidate names and rows with "Cast Votes", "Not Assigned", "Rejected write-in votes", "Unresolved write-in votes" or "Contest Totals". Do not extract any values that end in "%"
Use the following offices:
President/Vice President -> President
United States Senator -> U.S. Senate
US Representative -> U.S. House
State Senator -> State Senate
Quote all office and candidate values. The results are split into two columns on each page; parse the left column first and then the right column.
A spot-check and a few manual tweaks and the result against a 42 page PDF was exactly what was needed.
How about something harder? The results for Cameron County came as more than 600 pages and looked like this - note the hole-punch holes that obscure some of the text!
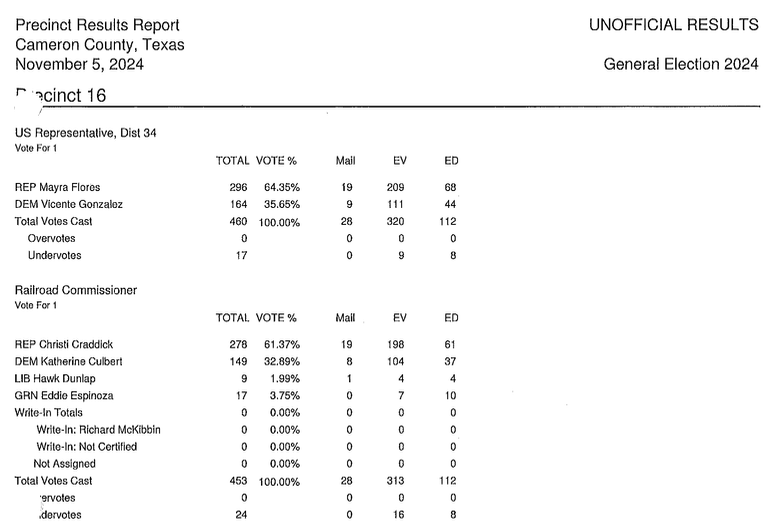
This file had to be split into chunks of 100 pages each, and the entire process still took a full hour of work - but the resulting table matched up with the official vote totals.
I love how realistic this example is. AI data entry like this isn't a silver bullet - there's still a bunch of work needed to verify the results and creative thinking needed to work through limitations - but it represents a very real improvement in how small teams can take on projects of this scale.
In the six weeks since we started working on Texas precinct results, we’ve been able to convert them for more than half of the state’s 254 counties, including many image PDFs like the ones on display here. That pace simply wouldn’t be possible with data entry or traditional OCR software.
We've been seeing if the latest versions of LLMs are any better at geolocating and chronolocating images, and they've improved dramatically since we last tested them in 2023. [...]
Before anyone worries about it taking our job, I see it more as the difference between a hand whisk and an electric whisk, just the same job done quicker, and either way you've got to check if your peaks are stiff at the end of it.
— Eliot Higgins, Bellingcat
Introducing Datasette for Newsrooms. We're introducing a new product suite today called Datasette for Newsrooms - a bundled collection of Datasette Cloud features built specifically for investigative journalists and data teams. We're describing it as an all-in-one data store, search engine, and collaboration platform designed to make working with data in a newsroom easier, faster, and more transparent.
If your newsroom could benefit from a managed version of Datasette we would love to hear from you. We're offering it to nonprofit newsrooms for free for the first year (they can pay us in feedback), and we have a two month trial for everyone else.
Get in touch at hello@datasette.cloud if you'd like to try it out.
One crucial detail: we will help you get started - we'll load data into your instance for you (you get some free data engineering!) and walk you through how to use it, and we will eagerly consume any feedback you have for us and prioritize shipping anything that helps you use the tool. Our unofficial goal: we want someone to win a Pulitzer for investigative reporting where our tool played a tiny part in their reporting process.
Here's an animated GIF demo (taken from our new Newsrooms landing page) of my favorite recent feature: the ability to extract structured data into a table starting with an unstructured PDF, using the latest version of the datasette-extract plugin.

Political Email Extraction Leaderboard (via) Derek Willis collects "political fundraising emails from just about every committee" - 3,000-12,000 a month - and has created an LLM benchmark from 1,000 of them that he collected last November.
He explains the leaderboard in this blog post. The goal is to have an LLM correctly identify the the committee name from the disclaimer text included in the email.
Here's the code he uses to run prompts using Ollama. It uses this system prompt:
Produce a JSON object with the following keys: 'committee', which is the name of the committee in the disclaimer that begins with Paid for by but does not include 'Paid for by', the committee address or the treasurer name. If no committee is present, the value of 'committee' should be None. Also add a key called 'sender', which is the name of the person, if any, mentioned as the author of the email. If there is no person named, the value is None. Do not include any other text, no yapping.
Gemini 2.5 Pro tops the leaderboard at the moment with 95.40%, but the new Mistral Small 3.1 manages 5th place with 85.70%, pretty good for a local model!
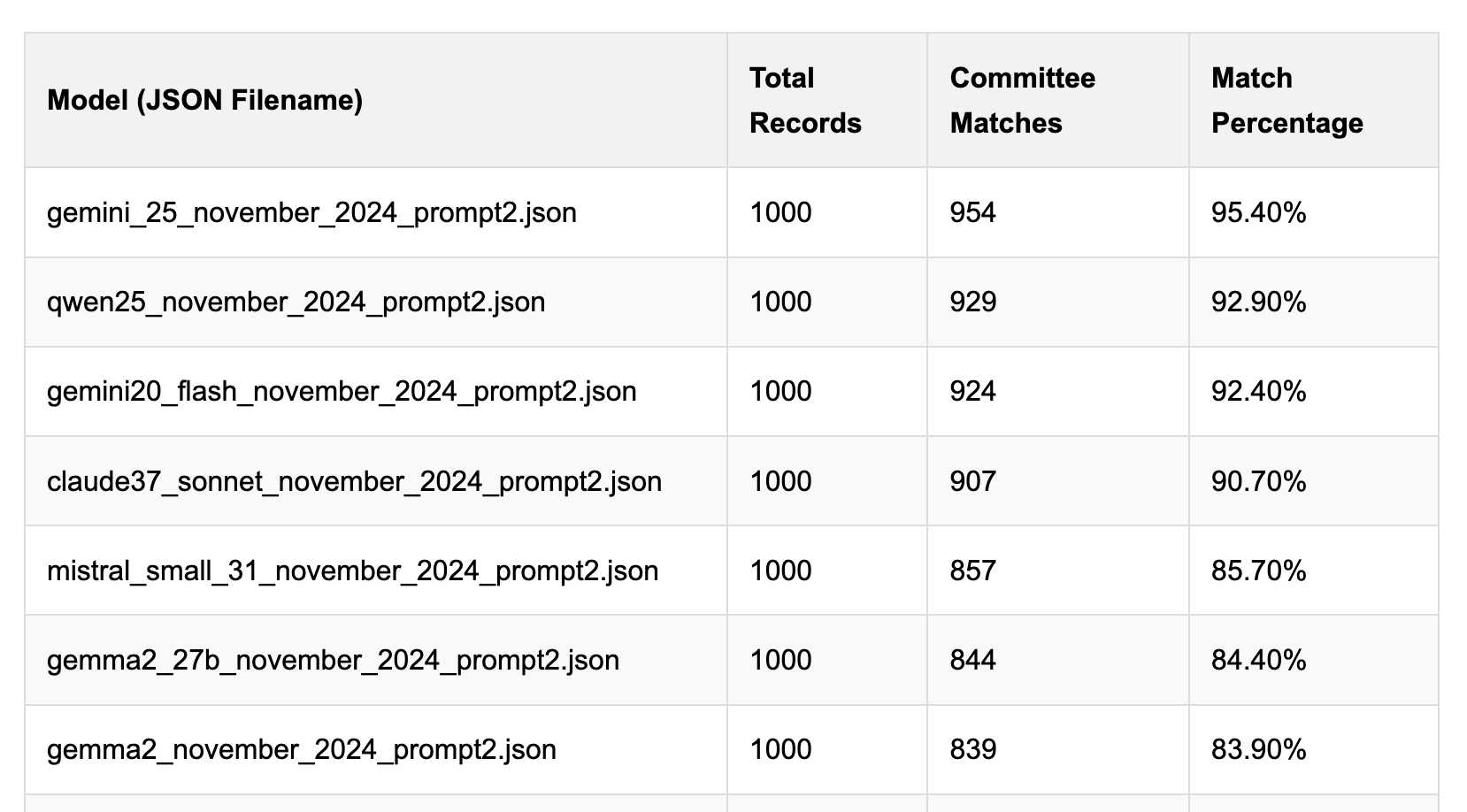
I said we need our own evals in my talk at the NICAR Data Journalism conference last month, without realizing Derek has been running one since January.
{kind=link}
Half Stack Data Science: Programming with AI, with Simon Willison (via) I participated in this wide-ranging 50 minute conversation with David Asboth and Shaun McGirr. Topics we covered included applications of LLMs to data journalism, the challenges of building an intuition for how best to use these tool given their "jagged frontier" of capabilities, how LLMs impact learning to program and how local models are starting to get genuinely useful now.
At 27:47:
If you're a new programmer, my optimistic version is that there has never been a better time to learn to program, because it shaves down the learning curve so much. When you're learning to program and you miss a semicolon and you bang your head against the computer for four hours [...] if you're unlucky you quit programming for good because it was so frustrating. [...]
I've always been a project-oriented learner; I can learn things by building something, and now the friction involved in building something has gone down so much [...] So I think especially if you're an autodidact, if you're somebody who likes teaching yourself things, these are a gift from heaven. You get a weird teaching assistant that knows loads of stuff and occasionally makes weird mistakes and believes in bizarre conspiracy theories, but you have 24 hour access to that assistant.
If you're somebody who prefers structured learning in classrooms, I think the benefits are going to take a lot longer to get to you because we don't know how to use these things in classrooms yet. [...]
If you want to strike out on your own, this is an amazing tool if you learn how to learn with it. So you've got to learn the limits of what it can do, and you've got to be disciplined enough to make sure you're not outsourcing the bits you need to learn to the machines.
How ProPublica Uses AI Responsibly in Its Investigations. Charles Ornstein describes how ProPublica used an LLM to help analyze data for their recent story A Study of Mint Plants. A Device to Stop Bleeding. This Is the Scientific Research Ted Cruz Calls “Woke.” by Agnel Philip and Lisa Song.
They ran ~3,400 grant descriptions through a prompt that included the following:
As an investigative journalist, I am looking for the following information
--
woke_description: A short description (at maximum a paragraph) on why this grant is being singled out for promoting "woke" ideology, Diversity, Equity, and Inclusion (DEI) or advanced neo-Marxist class warfare propaganda. Leave this blank if it's unclear.
why_flagged: Look at the "STATUS", "SOCIAL JUSTICE CATEGORY", "RACE CATEGORY", "GENDER CATEGORY" and "ENVIRONMENTAL JUSTICE CATEGORY" fields. If it's filled out, it means that the author of this document believed the grant was promoting DEI ideology in that way. Analyze the "AWARD DESCRIPTIONS" field and see if you can figure out why the author may have flagged it in this way. Write it in a way that is thorough and easy to understand with only one description per type and award.
citation_for_flag: Extract a very concise text quoting the passage of "AWARDS DESCRIPTIONS" that backs up the "why_flagged" data.
This was only the first step in the analysis of the data:
Of course, members of our staff reviewed and confirmed every detail before we published our story, and we called all the named people and agencies seeking comment, which remains a must-do even in the world of AI.
I think journalists are particularly well positioned to take advantage of LLMs in this way, because a big part of journalism is about deriving the truth from multiple unreliable sources of information. Journalists are deeply familiar with fact-checking, which is a critical skill if you're going to report with the assistance of these powerful but unreliable models.
Agnel Philip:
The tech holds a ton of promise in lead generation and pointing us in the right direction. But in my experience, it still needs a lot of human supervision and vetting. If used correctly, it can both really speed up the process of understanding large sets of information, and if you’re creative with your prompts and critically read the output, it can help uncover things that you may not have thought of.
What’s new in the world of LLMs, for NICAR 2025

I presented two sessions at the NICAR 2025 data journalism conference this year. The first was this one based on my review of LLMs in 2024, extended by several months to cover everything that’s happened in 2025 so far. The second was a workshop on Cutting-edge web scraping techniques, which I’ve written up separately.
[... 2,797 words]Structured data extraction from unstructured content using LLM schemas
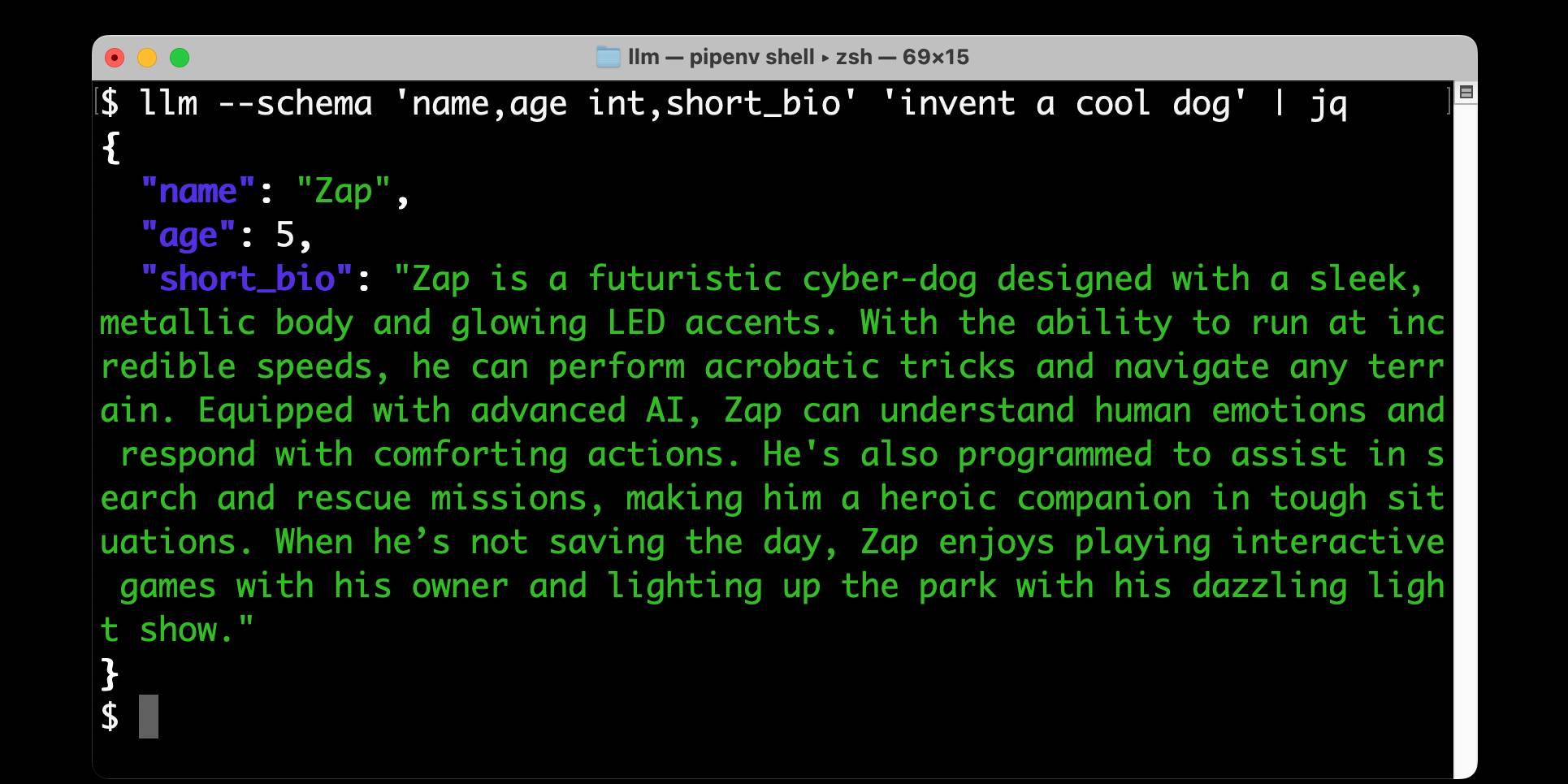
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]simonw/git-scraper-template. I built this new GitHub template repository in preparation for a workshop I'm giving at NICAR (the data journalism conference) next week on Cutting-edge web scraping techniques.
One of the topics I'll be covering is Git scraping - creating a GitHub repository that uses scheduled GitHub Actions workflows to grab copies of websites and data feeds and store their changes over time using Git.
This template repository is designed to be the fastest possible way to get started with a new Git scraper: simple create a new repository from the template and paste the URL you want to scrape into the description field and the repository will be initialized with a custom script that scrapes and stores that URL.
It's modeled after my earlier shot-scraper-template tool which I described in detail in Instantly create a GitHub repository to take screenshots of a web page.
The new git-scraper-template repo took some help from Claude to figure out. It uses a custom script to download the provided URL and derive a filename to use based on the URL and the content type, detected using file --mime-type -b "$file_path" against the downloaded file.
It also detects if the downloaded content is JSON and, if it is, pretty-prints it using jq - I find this is a quick way to generate much more useful diffs when the content changes.
I Went To SQL Injection Court (via) Thomas Ptacek talks about his ongoing involvement as an expert witness in an Illinois legal battle lead by Matt Chapman over whether a SQL schema (e.g. for the CANVAS parking ticket database) should be accessible to Freedom of Information (FOIA) requests against the Illinois state government.
They eventually lost in the Illinois Supreme Court, but there's still hope in the shape of IL SB0226, a proposed bill that would amend the FOIA act to ensure "that the public body shall provide a sufficient description of the structures of all databases under the control of the public body to allow a requester to request the public body to perform specific database queries".
Thomas posted this comment on Hacker News:
Permit me a PSA about local politics: engaging in national politics is bleak and dispiriting, like being a gnat bouncing off the glass plate window of a skyscraper. Local politics is, by contrast, extremely responsive. I've gotten things done --- including a law passed --- in my spare time and at practically no expense (drastically unlike national politics).
Six short video demos of LLM and Datasette projects
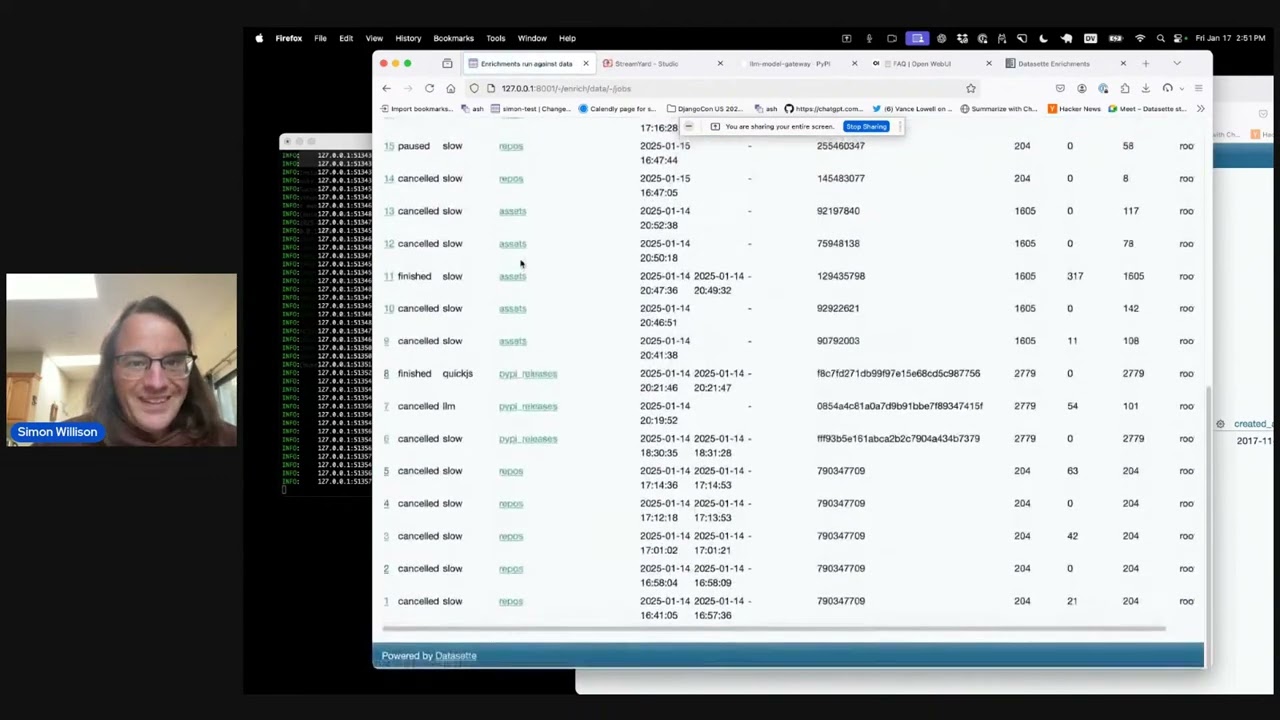
Last Friday Alex Garcia and I hosted a new kind of Datasette Public Office Hours session, inviting members of the Datasette community to share short demos of projects that they had built. The session lasted just over an hour and featured demos from six different people.
[... 1,047 words]My AI/LLM predictions for the next 1, 3 and 6 years, for Oxide and Friends
The Oxide and Friends podcast has an annual tradition of asking guests to share their predictions for the next 1, 3 and 6 years. Here’s 2022, 2023 and 2024. This year they invited me to participate. I’ve never been brave enough to share any public predictions before, so this was a great opportunity to get outside my comfort zone!
[... 2,675 words]2024
Project: Civic Band—scraping and searching PDF meeting minutes from hundreds of municipalities
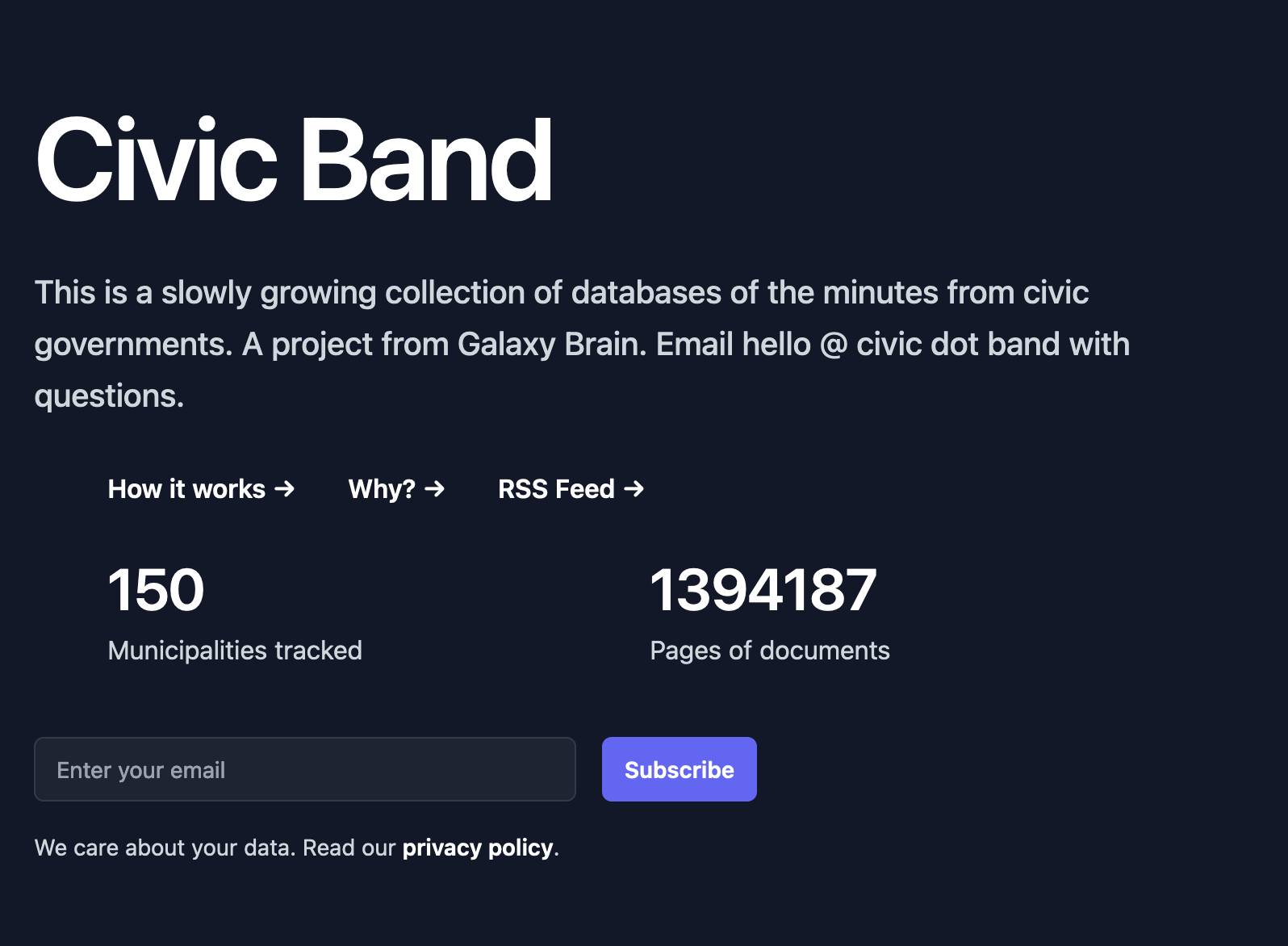
I interviewed Philip James about Civic Band, his “slowly growing collection of databases of the minutes from civic governments”. Philip demonstrated the site and talked through his pipeline for scraping and indexing meeting minutes from many different local government authorities around the USA.
[... 762 words]Project: VERDAD—tracking misinformation in radio broadcasts using Gemini 1.5
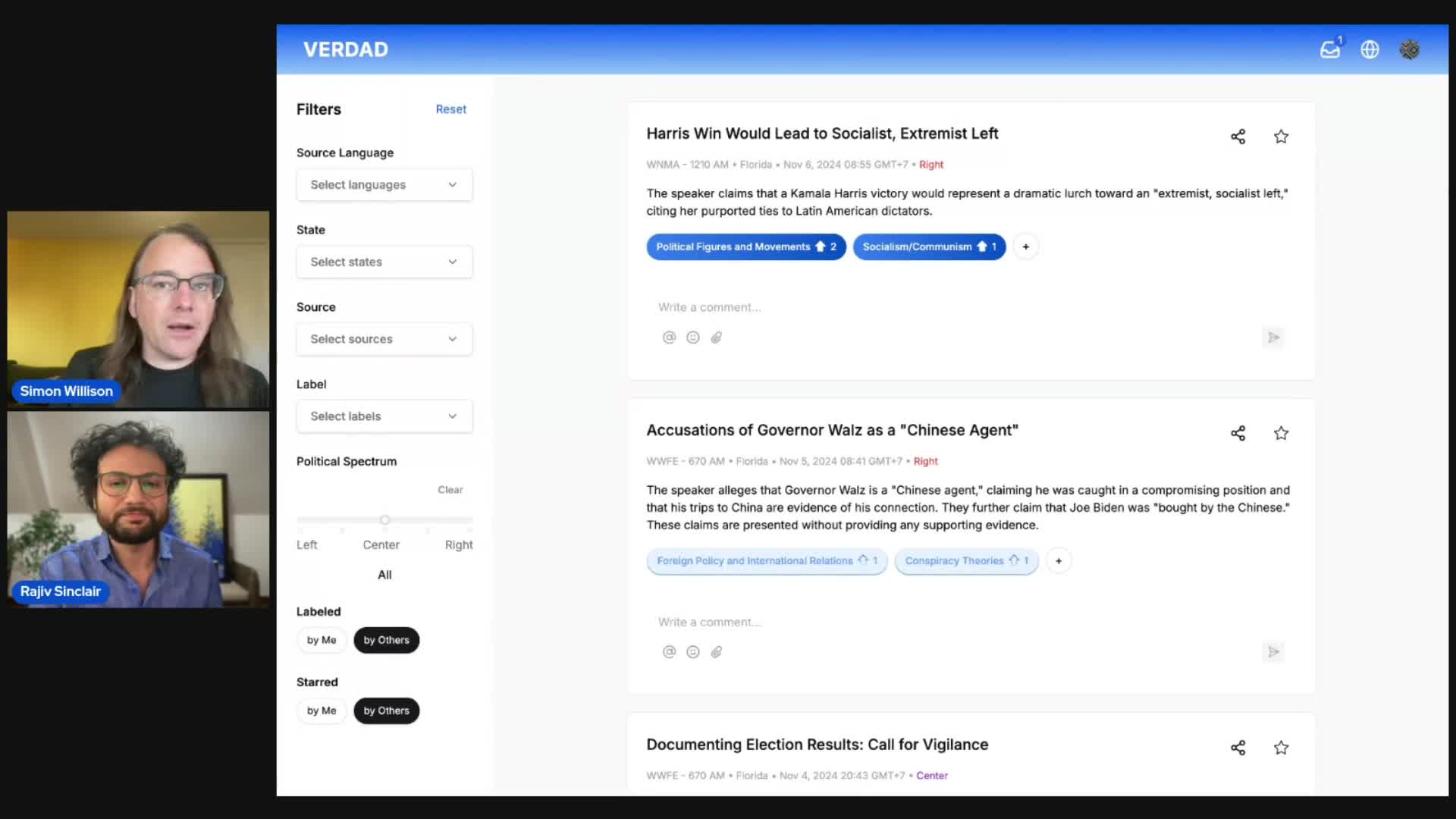
I’m starting a new interview series called Project. The idea is to interview people who are building interesting data projects and talk about what they’ve built, how they built it, and what they learned along the way.
[... 1,025 words]New in NotebookLM: Customizing your Audio Overviews. The most requested feature for Google's NotebookLM "audio overviews" (aka automatically generated podcast conversations) has been the ability to provide direction to those artificial podcast hosts - setting their expertise level or asking them to focus on specific topics.
Today's update adds exactly that:
Now you can provide instructions before you generate a "Deep Dive" Audio Overview. For example, you can focus on specific topics or adjust the expertise level to suit your audience. Think of it like slipping the AI hosts a quick note right before they go on the air, which will change how they cover your material.
I pasted in a link to my post about video scraping and prompted it like this:
You are both pelicans who work as data journalist at a pelican news service. Discuss this from the perspective of pelican data journalists, being sure to inject as many pelican related anecdotes as possible
Here's the resulting 7m40s MP3, and the transcript.
It starts off strong!
You ever find yourself wading through mountains of data trying to pluck out the juicy bits? It's like hunting for a single shrimp in a whole kelp forest, am I right?
Then later:
Think of those facial recognition systems they have for humans. We could have something similar for our finned friends. Although, gotta say, the ethical implications of that kind of tech are a whole other kettle of fish. We pelicans gotta use these tools responsibly and be transparent about it.
And when brainstorming some potential use-cases:
Imagine a pelican citizen journalist being able to analyze footage of a local council meeting, you know, really hold those pelicans in power accountable, or a pelican historian using video scraping to analyze old film reels, uncovering lost details about our pelican ancestors.
Plus this delightful conclusion:
The future of data journalism is looking brighter than a school of silversides reflecting the morning sun. Until next time, keep those wings spread, those eyes sharp, and those minds open. There's a whole ocean of data out there just waiting to be explored.
And yes, people on Reddit have got them to swear.
Video scraping: extracting JSON data from a 35 second screen capture for less than 1/10th of a cent
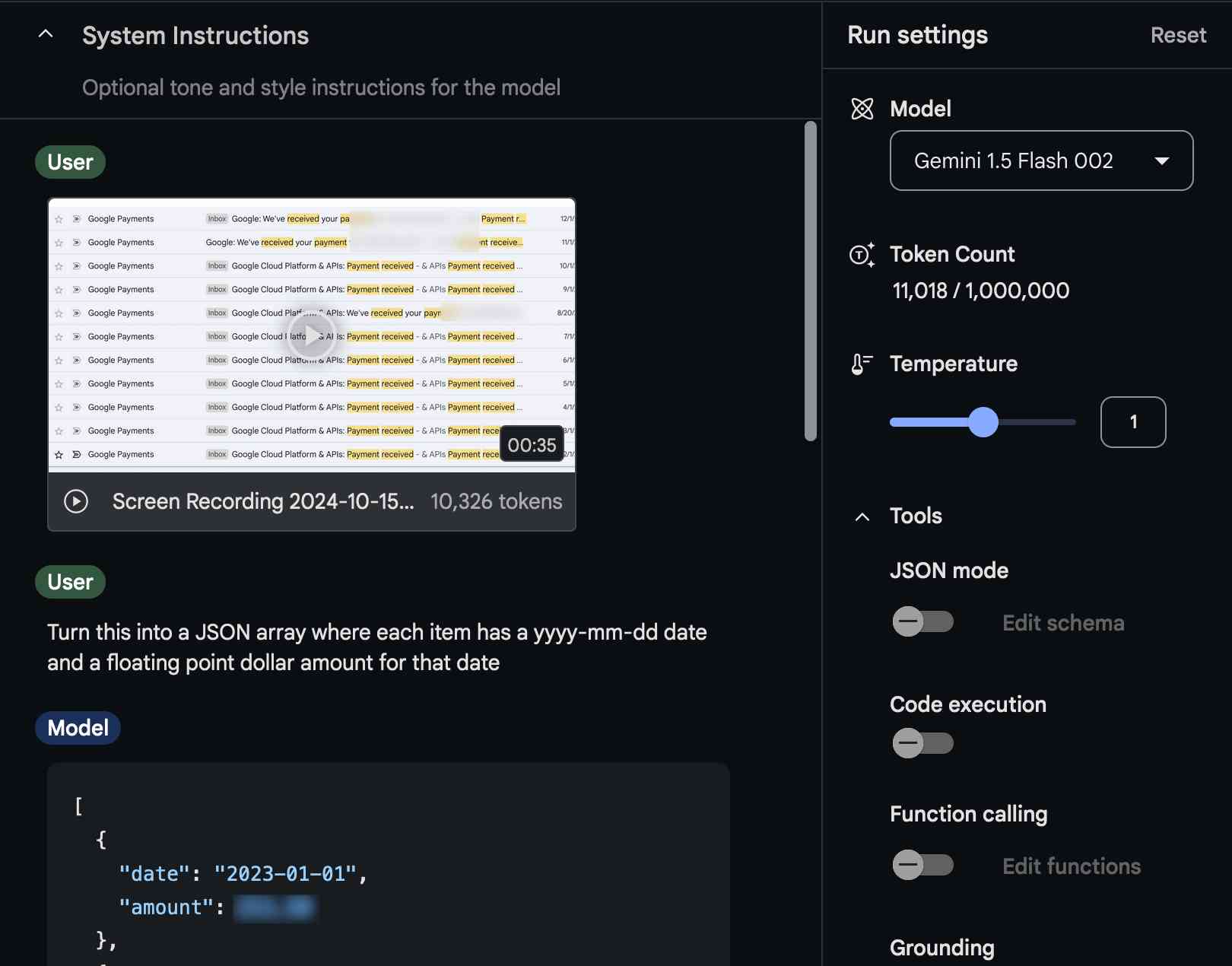
The other day I found myself needing to add up some numeric values that were scattered across twelve different emails.
[... 1,294 words]Follow the Crypto (via) Very smart new site from Molly White tracking the huge increase in activity from Cryptocurrency-focused PACs this year. These PACs have already raised $203 million and spent $38 million influencing US elections in 2024.
Right now Molly's rankings show that the "Fairshake" cryptocurrency PAC is second only to the Trump-supporting "Make America Great Again Inc" in money raised by Super PACs this year - though it's 9th in the list that includes other types of PAC.
Molly's data comes from the FEC, and the code behind the site is all open source.
There's lots more about the project in the latest edition of Molly's newsletter:
Did you know that the cryptocurrency industry has spent more on 2024 elections in the United States than the oil industry? More than the pharmaceutical industry?
In fact, the cryptocurrency industry has spent more on 2024 elections than the entire energy sector and the entire health sector. Those industries, both worth hundreds of billions or trillions of dollars, are being outspent by an industry that, even by generous estimates, is worth less than $20 billion.
interactive-feed (via) Sam Morris maintains this project which gathers interactive, graphic and data visualization stories from various newsrooms around the world and publishes them on Twitter, Mastodon and Bluesky.
It runs automatically using GitHub Actions, and gathers data using a number of different techniques - XML feeds, custom API integrations (for the NYT, Guardian and Washington Post) and in some cases by scraping index pages on news websites using CSS selectors and cheerio.
The data it collects is archived as JSON in the data/ directory of the repository.
Civic Band. Exciting new civic tech project from Philip James: 30 (and counting) Datasette instances serving full-text search enabled collections of OCRd meeting minutes for different civic governments. Includes 20,000 pages for Alameda, 17,000 for Pittsburgh, 3,567 for Baltimore and an enormous 117,000 for Maui County.
Philip includes some notes on how they're doing it. They gather PDF minute notes from anywhere that provides API access to them, then run local Tesseract for OCR (the cost of cloud-based OCR proving prohibitive given the volume of data). The collection is then deployed to a single VPS running multiple instances of Datasette via Caddy, one instance for each of the covered regions.
Food Delivery Leak Unmasks Russian Security Agents. This story is from April 2022 but I realize now I never linked to it.
Yandex Food, a popular food delivery service in Russia, suffered a major data leak.
The data included an order history with names, addresses and phone numbers of people who had placed food orders through that service.
Bellingcat were able to cross-reference this leak with addresses of Russian security service buildings—including those linked to the GRU and FSB.This allowed them to identify the names and phone numbers of people working for those organizations, and then combine that information with further leaked data as part of their other investigations.
If you look closely at the screenshots in this story they may look familiar: Bellingcat were using Datasette internally as a tool for exploring this data!
Weeknotes: Llama 3, AI for Data Journalism, llm-evals and datasette-secrets
Llama 3 landed on Thursday. I ended up updating a whole bunch of different plugins to work with it, described in Options for accessing Llama 3 from the terminal using LLM.
[... 1,030 words]AI for Data Journalism: demonstrating what we can do with this stuff right now
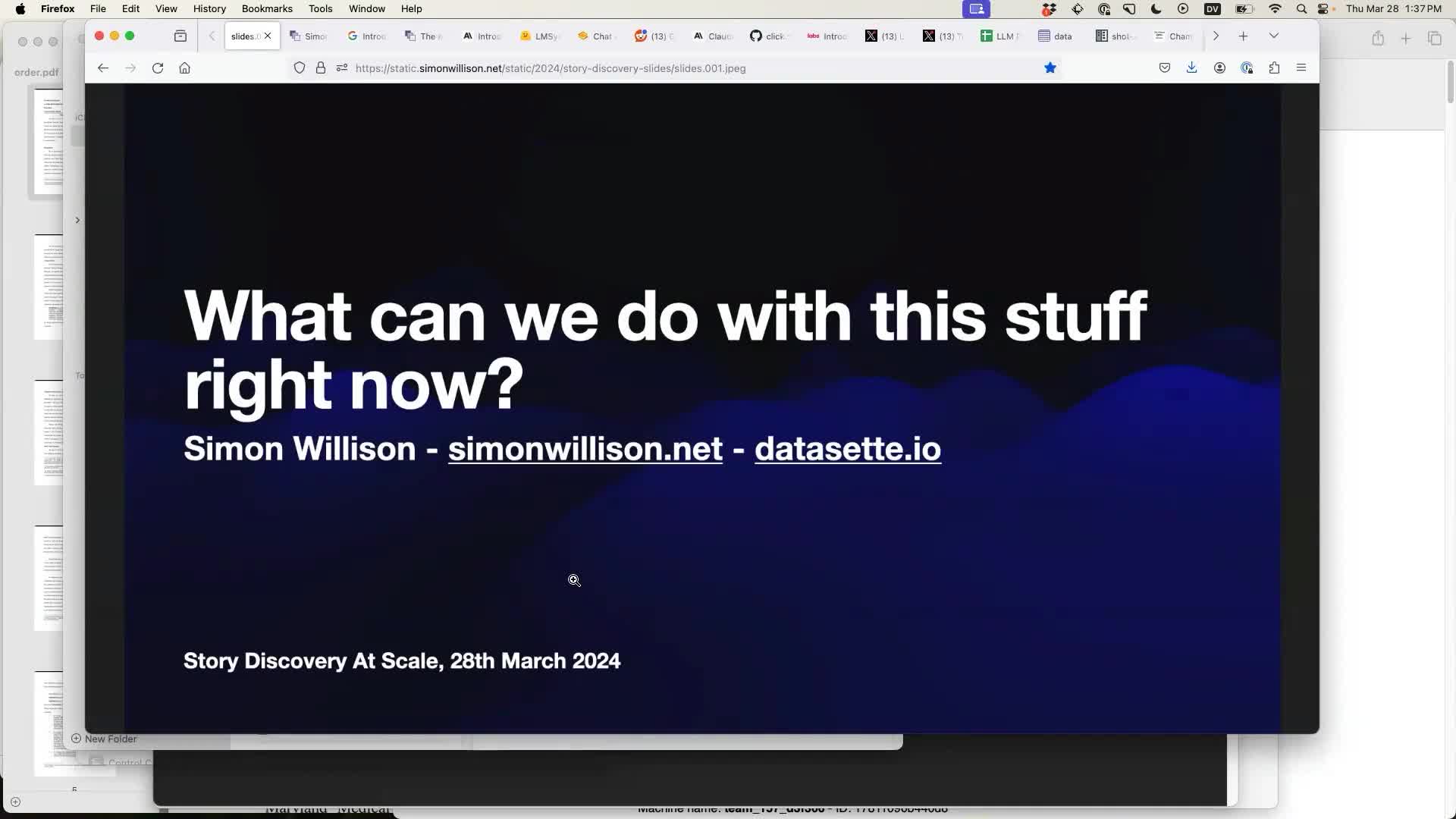
I gave a talk last month at the Story Discovery at Scale data journalism conference hosted at Stanford by Big Local News. My brief was to go deep into the things we can use Large Language Models for right now, illustrated by a flurry of demos to help provide starting points for further conversations at the conference.
[... 6,081 words]Running OCR against PDFs and images directly in your browser
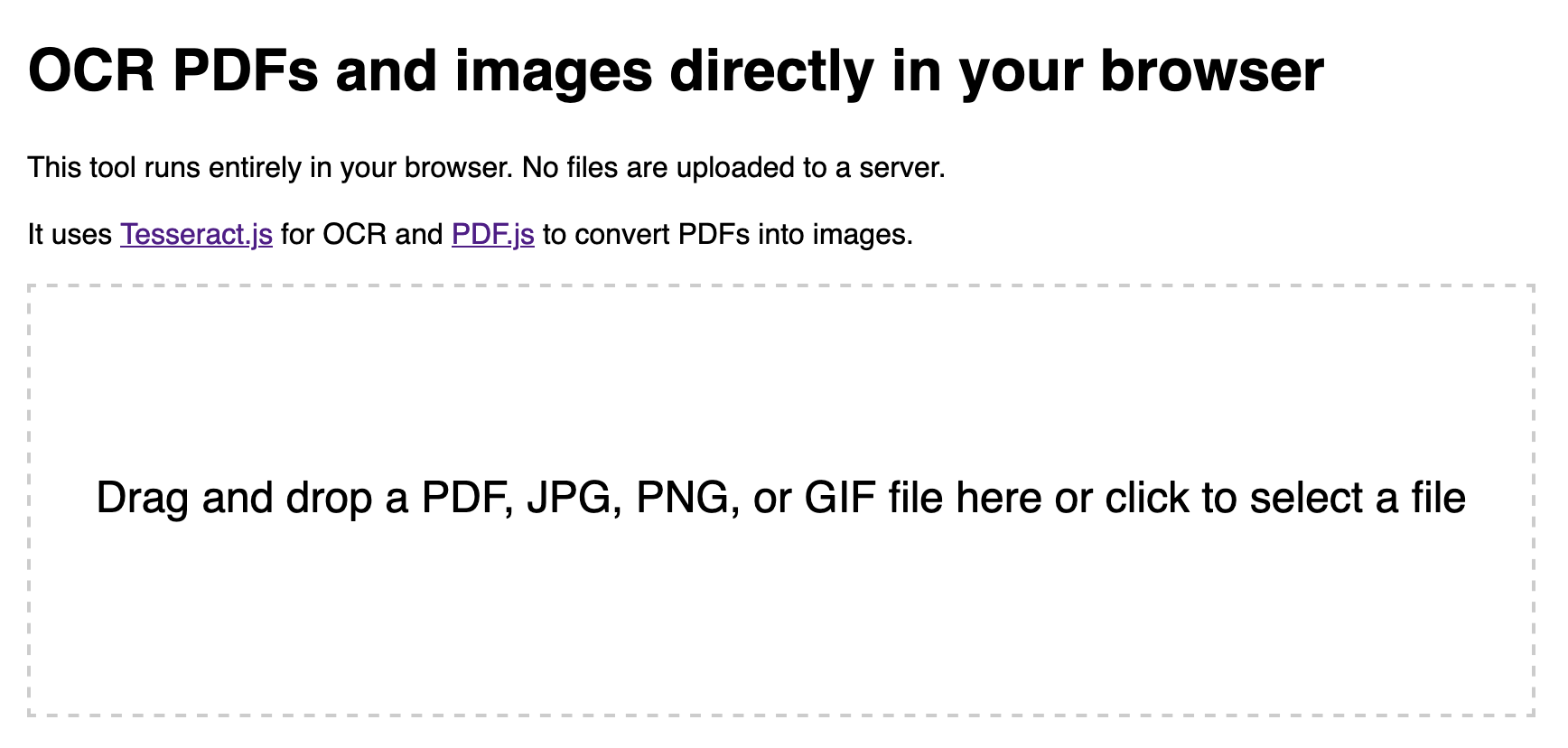
I attended the Story Discovery At Scale data journalism conference at Stanford this week. One of the perennial hot topics at any journalism conference concerns data extraction: how can we best get data out of PDFs and images?
[... 2,263 words]NICAR 2024 Tipsheets & Audio. The NICAR data journalism conference was outstanding this year: ~1100 attendees, and every slot on the schedule had at least 2 sessions that I wanted to attend (and usually a lot more).
If you’re interested in the intersection of data analysis and journalism it really should be a permanent fixture on your calendar, it’s fantastic.
Here’s the official collection of handouts (NICAR calls them tipsheets) and audio recordings from this year’s event.
American Community Survey Data via FTP. I got talking to some people from the US Census at NICAR today and asked them if there was a way to download their data in bulk (in addition to their various APIs)... and there was!
I had heard of the American Community Survey but I hadn’t realized that it’s gathered on a yearly basis, as a 5% sample compared to the full every-ten-years census. It’s only been running for ten years, and there’s around a year long lead time on the survey becoming available.