76 posts tagged “data-journalism”
2024
Weeknotes: Getting ready for NICAR
Next week is NICAR 2024 in Baltimore—the annual data journalism conference hosted by Investigative Reporters and Editors. I’m running a workshop on Datasette, and I plan to spend most of my time in the hallway track talking to people about Datasette, Datasette Cloud and how the Datasette ecosystem can best help support their work.
[... 1,390 words]2023
Simon Willison (Part Two): How Datasette Helps With Investigative Reporting. The second part of my Newsroom Robots podcast conversation with Nikita Roy. This episode includes my best audio answer yet to the “what is Datasette?” question, plus notes on how to use LLMs in journalism despite their propensity to make things up.
Prompt injection explained, November 2023 edition

A neat thing about podcast appearances is that, thanks to Whisper transcriptions, I can often repurpose parts of them as written content for my blog.
[... 1,357 words]I’m on the Newsroom Robots podcast, with thoughts on the OpenAI board
Newsroom Robots is a weekly podcast exploring the intersection of AI and journalism, hosted by Nikita Roy.
[... 1,032 words]Example of OpenAI function calling API to extract data from LAPD newsroom articles (via) Fascinating code example from Kyle McDonald. The OpenAI functions mechanism is intended to drive custom function calls, but I hadn’t quite appreciated how useful it can be ignoring the function calls entirely. Kyle instead uses it to define a schema for data he wants to extract from a news article, then uses the gpt-3.5-turbo-0613 to get back that exact set of extracted data as JSON.
Teaching News Apps with Codespaces (via) Derek Willis used GitHub Codespaces for the latest data journalism class he taught, and it eliminated the painful process of trying to get students on an assortment of Mac, Windows and Chromebook laptops all to a point where they could start working and learning together.
Weeknotes: NICAR, and an appearance on KQED Forum
I spent most of this week at NICAR 2023, the data journalism conference hosted this year in Nashville, Tennessee.
[... 1,941 words]Datasette is my data hammer (via) Jeremia Kimelman—a data journalist at CalMatters in Sacramento—enthuses about how he uses Datasette as his default hammer for all kinds of data projects—in particular how much he appreciates Datasette’s focus on URLs. So nice to see this!
2022
Measuring traffic during the Half Moon Bay Pumpkin Festival
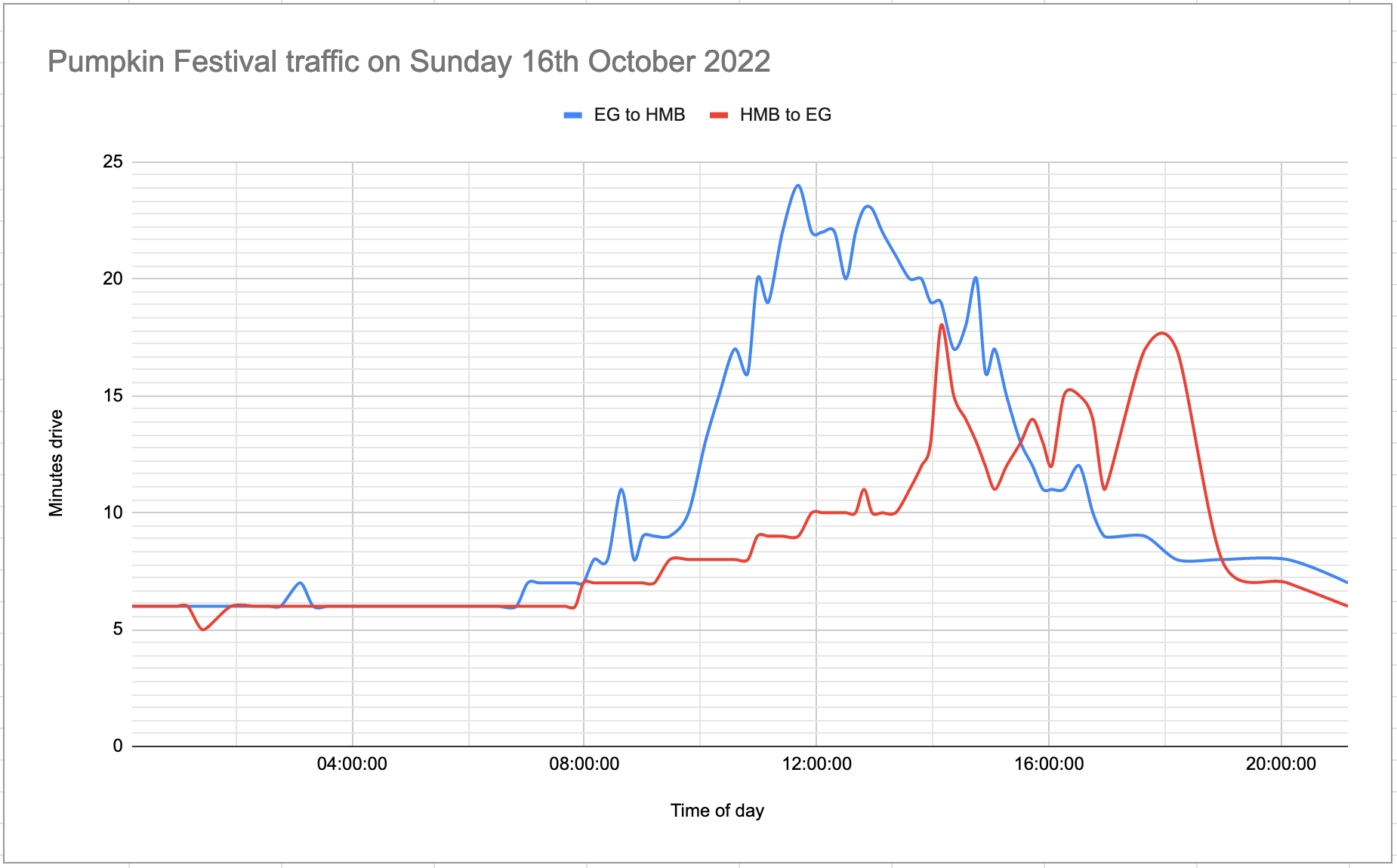
This weekend was the 50th annual Half Moon Bay Pumpkin Festival.
[... 2,693 words]Getting tabular data from unstructured text with GPT-3: an ongoing experiment (via) Roberto Rocha shows how to use a carefully designed prompt (with plenty of examples) to get GPT-3 to convert unstructured textual data into a structured table.
2021
git-history: a tool for analyzing scraped data collected using Git and SQLite
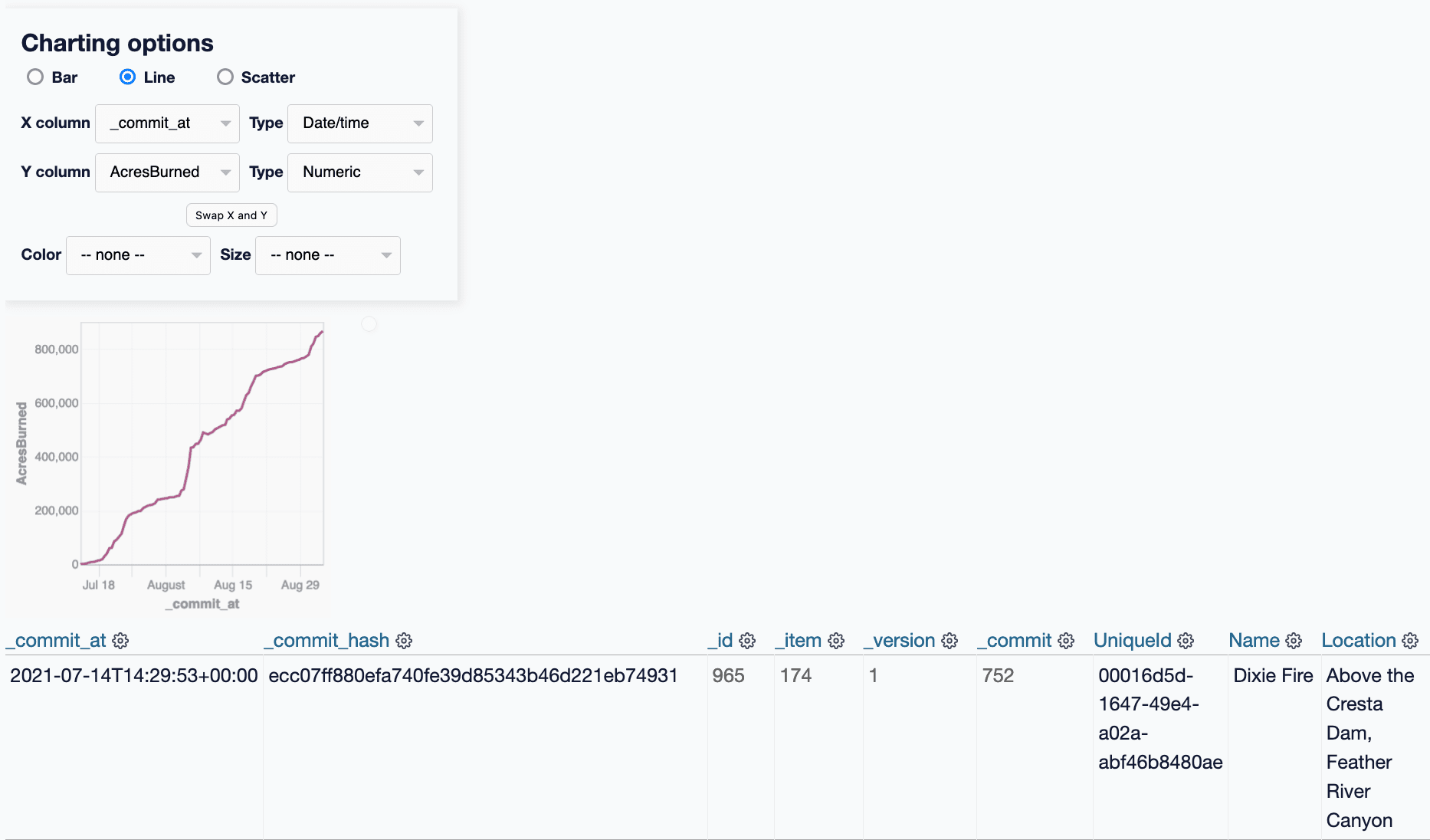
I described Git scraping last year: a technique for writing scrapers where you periodically snapshot a source of data to a Git repository in order to record changes to that source over time.
[... 2,002 words]Stanford School Enrollment Project (via) This is Project Pelican: I’ve been working with the Big Local News team at Stanford helping bundle up and release the data they’ve been collecting on school enrollment statistics around the USA. This Datasette instance has data from 33 states for every year since 2015—3.3m rows total. Be sure to check out the accompanying documentation!
Weeknotes: sqlite-transform 1.1, Datasette 0.58.1, datasette-graphql 1.5
Work on Project Pelican inspires new features and improvements across a number of different projects.
[... 1,419 words]The Accountability Project Datasettes. The Accountability Project “curates, standardizes and indexes public data to give journalists, researchers and others a simple way to search across otherwise siloed records”—they have a wide range of useful data, and they’ve started experimenting with Datasette to provide SQL access to a subset of the information that they have collected.
Weeknotes: Datasette and Git scraping at NICAR, VaccinateCA
This week I virtually attended the NICAR data journalism conference and made a ton of progress on the Django backend for VaccinateCA (see last week).
[... 773 words]Git scraping, the five minute lightning talk
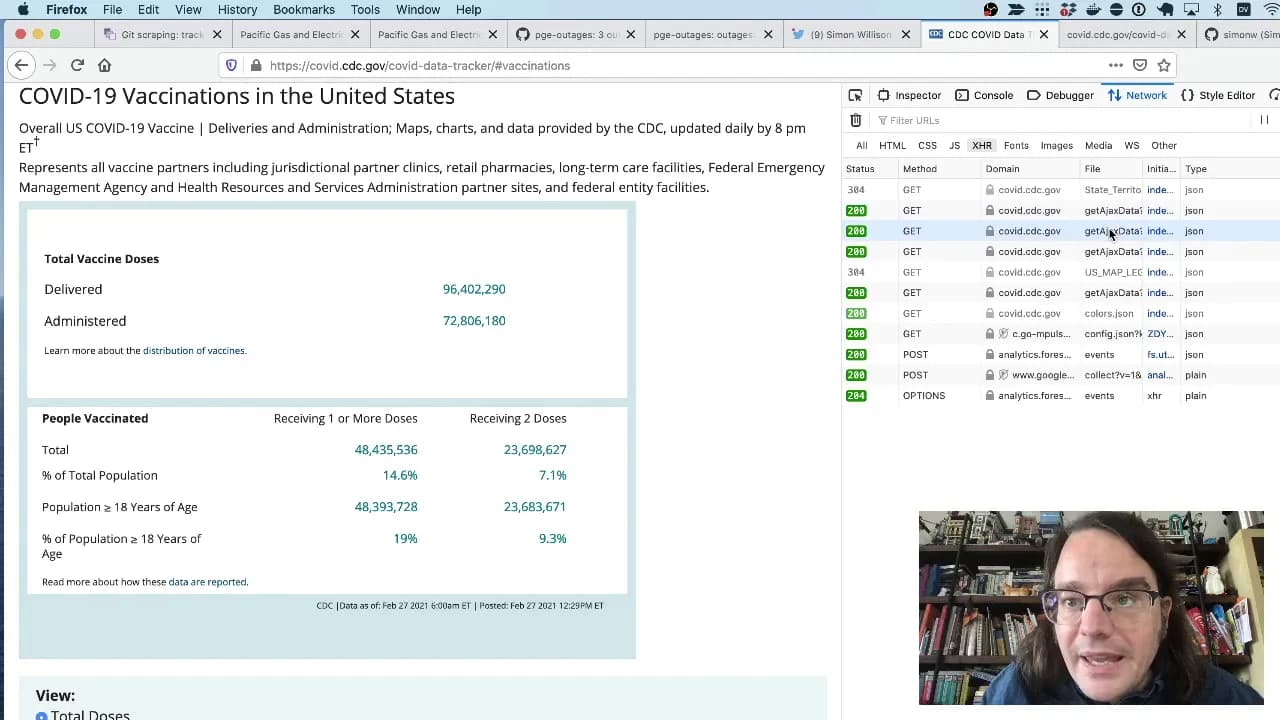
I prepared a lightning talk about Git scraping for the NICAR 2021 data journalism conference. In the talk I explain the idea of running scheduled scrapers in GitHub Actions, show some examples and then live code a new scraper for the CDC’s vaccination data using the GitHub web interface. Here’s the video.
[... 289 words]2020
nyt-2020-election-scraper. Brilliant application of git scraping by Alex Gaynor and a growing team of contributors. Takes a JSON snapshot of the NYT’s latest election poll figures every five minutes, then runs a Python script to iterate through the history and build an HTML page showing the trends, including what percentage of the remaining votes each candidate needs to win each state. This is the perfect case study in why it can be useful to take a “snapshot if the world right now” data source and turn it into a git revision history over time.
selenium-wire. Really useful scraping tool: enhances the Python Selenium bindings to run against a proxy which then allows Python scraping code to look at captured requests—great for if a site you are working with triggers Ajax requests and you want to extract data from the raw JSON that came back.
Develomentor podcast: Simon Willison – Data Journalism, The Importance of Side Projects (via) Grant Ingersoll interviewed me for the Develomentor podcast. We talked about my career so far, and how much of it was driven by side-projects that I've worked on individually or with Natalie.
Here's the mp3, or access it through Buzzsprout.
sba-loans-covid-19-datasette (via) The treasury department released a bunch of data on the Covid-19 SBA Paycheck Protection Program Loan recipients today—I’ve loaded the most interesting data (the $150,000+ loans) into a Datasette instance.
Data Journalism Academy (via) MaryJo Webster is the data editor for the Star Tribune in Minneapolis, and a 2019 Pulitzer nominee. She’s has a huge amount of experience teaching data journalism and has just released her accumulated teaching materials in the form of the Data Journalism Academy.
Weeknotes: Covid-19, First Python Notebook, more Dogsheep, Tailscale
My covid-19.datasettes.com project publishes information on COVID-19 cases around the world. The project started out using data from Johns Hopkins CSSE, but last week the New York Times started publishing high quality USA county- and state-level daily numbers to their own repository. Here’s the change that added the NY Times data.
[... 993 words]Weeknotes: datasette-ics, datasette-upload-csvs, datasette-configure-fts, asgi-csrf
I’ve been preparing for the NICAR 2020 Data Journalism conference this week which has lead me into a flurry of activity across a plethora of different projects and plugins.
[... 834 words]Tracking FARA by deploying a data API using GitHub Actions and Cloud Run
I’m using the combination of GitHub Actions and Google Cloud Run to retrieve data from the U.S. Department of Justice FARA website and deploy it as a queryable API using Datasette.
[... 1,599 words]2019
Building tools to bring data-driven reporting to more newsrooms. I wrote about my fellowship project so far and my goals for the next few months for the JSK Medium publication. My next priority: an invite-only hosted version for newsrooms so that figuring out how to install and manage the software isn’t the biggest barrier to entry.
Tracking PG&E outages by scraping to a git repo
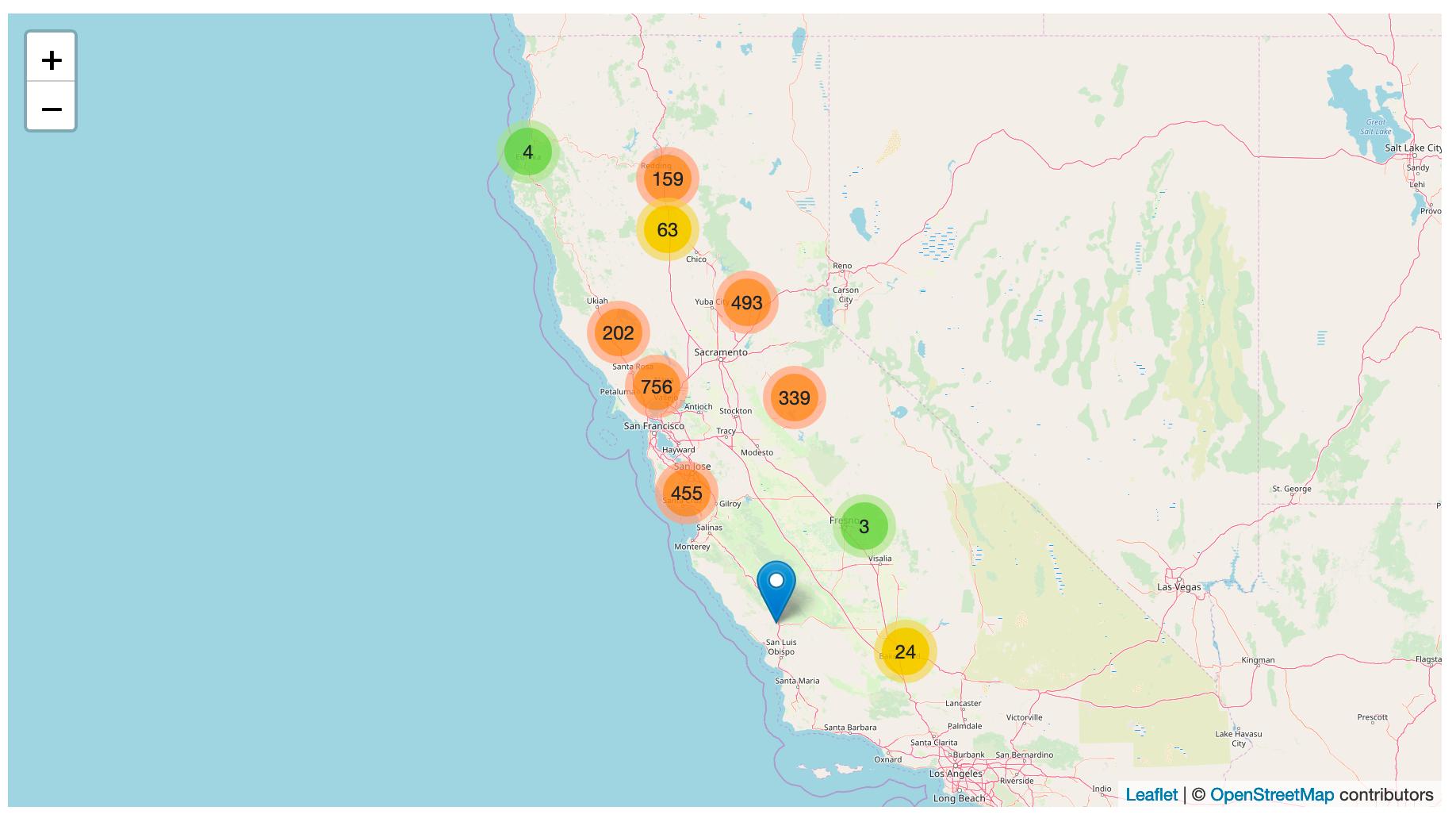
PG&E have cut off power to several million people in northern California, supposedly as a precaution against wildfires.
[... 868 words]My JSK Fellowship: Building an open source ecosystem of tools for data journalism
I started a new chapter of my career last week: I began a year long fellowship with the John S. Knight Journalism Fellowships program at Stanford.
[... 876 words]Los Angeles Weedmaps analysis (via) Ben Welsh at the LA Times published this Jupyter notebook showing the full working behind a story they published about LA’s black market weed dispensaries. I picked up several useful tricks from it—including how to load points into a geopandas GeoDataFrame (in epsg:4326 aka WGS 84) and how to then join that against the LA Times neighborhoods GeoJSON boundaries file.
JSK Journalism Fellowships names Class of 2019-2020 (and I’m in it!) (via) In personal news... I’ve been accepted for a ten month journalism fellowship at Stanford (starting September)! My work there will involve “Improving the impact of investigative stories by expanding the open-source ecosystem of tools that allows journalists to share the underlying data”.
VisiData
(via)
Intriguing tool by Saul Pwanson: VisiData is a command-line "textpunk utility" for browsing and manipulating tabular data. pip3 install visidata and then vd myfile.csv (or .json or .xls or SQLite or others) and get an interactive terminal UI for quickly searching through the data, conducting frequency analysis of columns, manipulating it and much more besides. Two tips for if you start playing with it: hit gq to exit, and hit Ctrl+H to view the help screen.