Blogmarks
Filters: Sorted by date
How I think about Codex. Gabriel Chua (Developer Experience Engineer for APAC at OpenAI) provides his take on the confusing terminology behind the term "Codex", which can refer to a bunch of of different things within the OpenAI ecosystem:
In plain terms, Codex is OpenAI’s software engineering agent, available through multiple interfaces, and an agent is a model plus instructions and tools, wrapped in a runtime that can execute tasks on your behalf. [...]
At a high level, I see Codex as three parts working together:
Codex = Model + Harness + Surfaces [...]
- Model + Harness = the Agent
- Surfaces = how you interact with the Agent
He defines the harness as "the collection of instructions and tools", which is notably open source and lives in the openai/codex repository.
Gabriel also provides the first acknowledgment I've seen from an OpenAI insider that the Codex model family are directly trained for the Codex harness:
Codex models are trained in the presence of the harness. Tool use, execution loops, compaction, and iterative verification aren’t bolted on behaviors — they’re part of how the model learns to operate. The harness, in turn, is shaped around how the model plans, invokes tools, and recovers from failure.
Andrej Karpathy talks about “Claws”. Andrej Karpathy tweeted a mini-essay about buying a Mac Mini ("The apple store person told me they are selling like hotcakes and everyone is confused") to tinker with Claws:
I'm definitely a bit sus'd to run OpenClaw specifically [...] But I do love the concept and I think that just like LLM agents were a new layer on top of LLMs, Claws are now a new layer on top of LLM agents, taking the orchestration, scheduling, context, tool calls and a kind of persistence to a next level.
Looking around, and given that the high level idea is clear, there are a lot of smaller Claws starting to pop out. For example, on a quick skim NanoClaw looks really interesting in that the core engine is ~4000 lines of code (fits into both my head and that of AI agents, so it feels manageable, auditable, flexible, etc.) and runs everything in containers by default. [...]
Anyway there are many others - e.g. nanobot, zeroclaw, ironclaw, picoclaw (lol @ prefixes). [...]
Not 100% sure what my setup ends up looking like just yet but Claws are an awesome, exciting new layer of the AI stack.
Andrej has an ear for fresh terminology (see vibe coding, agentic engineering) and I think he's right about this one, too: "Claw" is becoming a term of art for the entire category of OpenClaw-like agent systems - AI agents that generally run on personal hardware, communicate via messaging protocols and can both act on direct instructions and schedule tasks.
It even comes with an established emoji 🦞
Taalas serves Llama 3.1 8B at 17,000 tokens/second (via) This new Canadian hardware startup just announced their first product - a custom hardware implementation of the Llama 3.1 8B model (from July 2024) that can run at a staggering 17,000 tokens/second.
I was going to include a video of their demo but it's so fast it would look more like a screenshot. You can try it out at chatjimmy.ai.
They describe their Silicon Llama as “aggressively quantized, combining 3-bit and 6-bit parameters.” Their next generation will use 4-bit - presumably they have quite a long lead time for baking out new models!
ggml.ai joins Hugging Face to ensure the long-term progress of Local AI (via) I don't normally cover acquisition news like this, but I have some thoughts.
It's hard to overstate the impact Georgi Gerganov has had on the local model space. Back in March 2023 his release of llama.cpp made it possible to run a local LLM on consumer hardware. The original README said:
The main goal is to run the model using 4-bit quantization on a MacBook. [...] This was hacked in an evening - I have no idea if it works correctly.
I wrote about trying llama.cpp out at the time in Large language models are having their Stable Diffusion moment:
I used it to run the 7B LLaMA model on my laptop last night, and then this morning upgraded to the 13B model—the one that Facebook claim is competitive with GPT-3.
Meta's original LLaMA release depended on PyTorch and their FairScale PyTorch extension for running on multiple GPUs, and required CUDA and NVIDIA hardware. Georgi's work opened that up to a much wider range of hardware and kicked off the local model movement that has continued to grow since then.
Hugging Face are already responsible for the incredibly influential Transformers library used by the majority of LLM releases today. They've proven themselves a good steward for that open source project, which makes me optimistic for the future of llama.cpp and related projects.
This section from the announcement looks particularly promising:
Going forward, our joint efforts will be geared towards the following objectives:
- Towards seamless "single-click" integration with the transformers library. The
transformersframework has established itself as the 'source of truth' for AI model definitions. Improving the compatibility between the transformers and the ggml ecosystems is essential for wider model support and quality control.- Better packaging and user experience of ggml-based software. As we enter the phase in which local inference becomes a meaningful and competitive alternative to cloud inference, it is crucial to improve and simplify the way in which casual users deploy and access local models. We will work towards making llama.cpp ubiquitous and readily available everywhere, and continue partnering with great downstream projects.
Given the influence of Transformers, this closer integration could lead to model releases that are compatible with the GGML ecosystem out of the box. That would be a big win for the local model ecosystem.
I'm also excited to see investment in "packaging and user experience of ggml-based software". This has mostly been left to tools like Ollama and LM Studio. ggml-org released LlamaBarn last year - "a macOS menu bar app for running local LLMs" - and I'm hopeful that further investment in this area will result in more high quality open source tools for running local models from the team best placed to deliver them.
Gemini 3.1 Pro. The first in the Gemini 3.1 series, priced the same as Gemini 3 Pro ($2/million input, $12/million output under 200,000 tokens, $4/$18 for 200,000 to 1,000,000). That's less than half the price of Claude Opus 4.6 with very similar benchmark scores to that model.
They boast about its improved SVG animation performance compared to Gemini 3 Pro in the announcement!
I tried "Generate an SVG of a pelican riding a bicycle" in Google AI Studio and it thought for 323.9 seconds (thinking trace here) before producing this one:

It's good to see the legs clearly depicted on both sides of the frame (should satisfy Elon), the fish in the basket is a nice touch and I appreciated this comment in the SVG code:
<!-- Black Flight Feathers on Wing Tip -->
<path d="M 420 175 C 440 182, 460 187, 470 190 C 450 210, 430 208, 410 198 Z" fill="#374151" />
I've added the two new model IDs gemini-3.1-pro-preview and gemini-3.1-pro-preview-customtools to my llm-gemini plugin for LLM. That "custom tools" one is described here - apparently it may provide better tool performance than the default model in some situations.
The model appears to be incredibly slow right now - it took 104s to respond to a simple "hi" and a few of my other tests met "Error: This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later." or "Error: Deadline expired before operation could complete" errors. I'm assuming that's just teething problems on launch day.
It sounds like last week's Deep Think release was our first exposure to the 3.1 family:
Last week, we released a major update to Gemini 3 Deep Think to solve modern challenges across science, research and engineering. Today, we’re releasing the upgraded core intelligence that makes those breakthroughs possible: Gemini 3.1 Pro.
Update: In What happens if AI labs train for pelicans riding bicycles? last November I said:
If a model finally comes out that produces an excellent SVG of a pelican riding a bicycle you can bet I’m going to test it on all manner of creatures riding all sorts of transportation devices.
Google's Gemini Lead Jeff Dean tweeted this video featuring an animated pelican riding a bicycle, plus a frog on a penny-farthing and a giraffe driving a tiny car and an ostrich on roller skates and a turtle kickflipping a skateboard and a dachshund driving a stretch limousine.
I've been saying for a while that I wish AI labs would highlight things that their new models can do that their older models could not, so top marks to the Gemini team for this video.
Update 2: I used llm-gemini to run my more detailed Pelican prompt, with this result:

From the SVG comments:
<!-- Pouch Gradient (Breeding Plumage: Red to Olive/Green) -->
...
<!-- Neck Gradient (Breeding Plumage: Chestnut Nape, White/Yellow Front) -->
SWE-bench February 2026 leaderboard update (via) SWE-bench is one of the benchmarks that the labs love to list in their model releases. The official leaderboard is infrequently updated but they just did a full run of it against the current generation of models, which is notable because it's always good to see benchmark results like this that weren't self-reported by the labs.
The fresh results are for their "Bash Only" benchmark, which runs their mini-swe-bench agent (~9,000 lines of Python, here are the prompts they use) against the SWE-bench dataset of coding problems - 2,294 real-world examples pulled from 12 open source repos: django/django (850), sympy/sympy (386), scikit-learn/scikit-learn (229), sphinx-doc/sphinx (187), matplotlib/matplotlib (184), pytest-dev/pytest (119), pydata/xarray (110), astropy/astropy (95), pylint-dev/pylint (57), psf/requests (44), mwaskom/seaborn (22), pallets/flask (11).
Correction: The Bash only benchmark runs against SWE-bench Verified, not original SWE-bench. Verified is a manually curated subset of 500 samples described here, funded by OpenAI. Here's SWE-bench Verified on Hugging Face - since it's just 2.1MB of Parquet it's easy to browse using Datasette Lite, which cuts those numbers down to django/django (231), sympy/sympy (75), sphinx-doc/sphinx (44), matplotlib/matplotlib (34), scikit-learn/scikit-learn (32), astropy/astropy (22), pydata/xarray (22), pytest-dev/pytest (19), pylint-dev/pylint (10), psf/requests (8), mwaskom/seaborn (2), pallets/flask (1).
Here's how the top ten models performed:
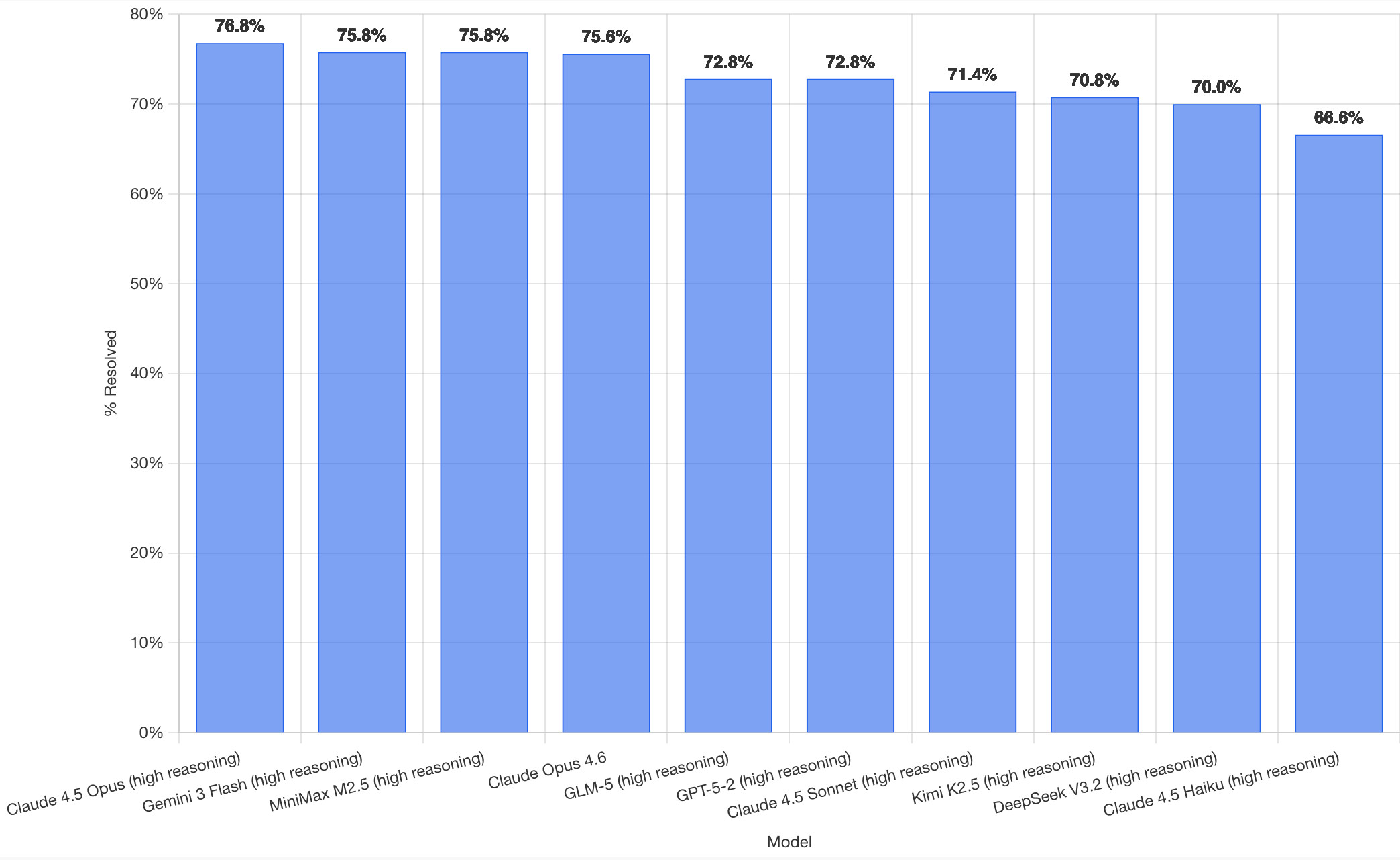
It's interesting to see Claude Opus 4.5 beat Opus 4.6, though only by about a percentage point. 4.5 Opus is top, then Gemini 3 Flash, then MiniMax M2.5 - a 229B model released last week by Chinese lab MiniMax. GLM-5, Kimi K2.5 and DeepSeek V3.2 are three more Chinese models that make the top ten as well.
OpenAI's GPT-5.2 is their highest performing model at position 6, but it's worth noting that their best coding model, GPT-5.3-Codex, is not represented - maybe because it's not yet available in the OpenAI API.
This benchmark uses the same system prompt for every model, which is important for a fair comparison but does mean that the quality of the different harnesses or optimized prompts is not being measured here.
The chart above is a screenshot from the SWE-bench website, but their charts don't include the actual percentage values visible on the bars. I successfully used Claude for Chrome to add these - transcript here. My prompt sequence included:
Use claude in chrome to open https://www.swebench.com/
Click on "Compare results" and then select "Select top 10"
See those bar charts? I want them to display the percentage on each bar so I can take a better screenshot, modify the page like that
I'm impressed at how well this worked - Claude injected custom JavaScript into the page to draw additional labels on top of the existing chart.
![Screenshot of a Claude AI conversation showing browser automation. A thinking step reads "Pivoted strategy to avoid recursion issues with chart labeling >" followed by the message "Good, the chart is back. Now let me carefully add the labels using an inline plugin on the chart instance to avoid the recursion issue." A collapsed "Browser_evaluate" section shows a browser_evaluate tool call with JavaScript code using Chart.js canvas context to draw percentage labels on bars: meta.data.forEach((bar, index) => { const value = dataset.data[index]; if (value !== undefined && value !== null) { ctx.save(); ctx.textAlign = 'center'; ctx.textBaseline = 'bottom'; ctx.fillStyle = '#333'; ctx.font = 'bold 12px sans-serif'; ctx.fillText(value.toFixed(1) + '%', bar.x, bar.y - 5); A pending step reads "Let me take a screenshot to see if it worked." followed by a completed "Done" step, and the message "Let me take a screenshot to check the result."](https://static.simonwillison.net/static/2026/claude-chrome-draw-on-chart.jpg)
Update: If you look at the transcript Claude claims to have switched to Playwright, which is confusing because I didn't think I had that configured.
LadybirdBrowser/ladybird: Abandon Swift adoption (via) Back in August 2024 the Ladybird browser project announced an intention to adopt Swift as their memory-safe language of choice.
As of this commit it looks like they've changed their mind:
Everywhere: Abandon Swift adoption
After making no progress on this for a very long time, let's acknowledge it's not going anywhere and remove it from the codebase.
Update 23rd February 2025: They've adopted Rust instead.
The A.I. Disruption We’ve Been Waiting for Has Arrived. New opinion piece from Paul Ford in the New York Times. Unsurprisingly for a piece by Paul it's packed with quoteworthy snippets, but a few stood out for me in particular.
Paul describes the November moment that so many other programmers have observed, and highlights Claude Code's ability to revive old side projects:
[Claude Code] was always a helpful coding assistant, but in November it suddenly got much better, and ever since I’ve been knocking off side projects that had sat in folders for a decade or longer. It’s fun to see old ideas come to life, so I keep a steady flow. Maybe it adds up to a half-hour a day of my time, and an hour of Claude’s.
November was, for me and many others in tech, a great surprise. Before, A.I. coding tools were often useful, but halting and clumsy. Now, the bot can run for a full hour and make whole, designed websites and apps that may be flawed, but credible. I spent an entire session of therapy talking about it.
And as the former CEO of a respected consultancy firm (Postlight) he's well positioned to evaluate the potential impact:
When you watch a large language model slice through some horrible, expensive problem — like migrating data from an old platform to a modern one — you feel the earth shifting. I was the chief executive of a software services firm, which made me a professional software cost estimator. When I rebooted my messy personal website a few weeks ago, I realized: I would have paid $25,000 for someone else to do this. When a friend asked me to convert a large, thorny data set, I downloaded it, cleaned it up and made it pretty and easy to explore. In the past I would have charged $350,000.
That last price is full 2021 retail — it implies a product manager, a designer, two engineers (one senior) and four to six months of design, coding and testing. Plus maintenance. Bespoke software is joltingly expensive. Today, though, when the stars align and my prompts work out, I can do hundreds of thousands of dollars worth of work for fun (fun for me) over weekends and evenings, for the price of the Claude $200-a-month plan.
He also neatly captures the inherent community tension involved in exploring this technology:
All of the people I love hate this stuff, and all the people I hate love it. And yet, likely because of the same personality flaws that drew me to technology in the first place, I am annoyingly excited.
Introducing Claude Sonnet 4.6 (via) Sonnet 4.6 is out today, and Anthropic claim it offers similar performance to November's Opus 4.5 while maintaining the Sonnet pricing of $3/million input and $15/million output tokens (the Opus models are $5/$25). Here's the system card PDF.
Sonnet 4.6 has a "reliable knowledge cutoff" of August 2025, compared to Opus 4.6's May 2025 and Haiku 4.5's February 2025. Both Opus and Sonnet default to 200,000 max input tokens but can stretch to 1 million in beta and at a higher cost.
I just released llm-anthropic 0.24 with support for both Sonnet 4.6 and Opus 4.6. Claude Code did most of the work - the new models had a fiddly amount of extra details around adaptive thinking and no longer supporting prefixes, as described in Anthropic's migration guide.
Here's what I got from:
uvx --with llm-anthropic llm 'Generate an SVG of a pelican riding a bicycle' -m claude-sonnet-4.6

The SVG comments include:
<!-- Hat (fun accessory) -->
I tried a second time and also got a top hat. Sonnet 4.6 apparently loves top hats!
For comparison, here's the pelican Opus 4.5 drew me in November:

And here's Anthropic's current best pelican, drawn by Opus 4.6 on February 5th:

Opus 4.6 produces the best pelican beak/pouch. I do think the top hat from Sonnet 4.6 is a nice touch though.
Rodney v0.4.0. My Rodney CLI tool for browser automation attracted quite the flurry of PRs since I announced it last week. Here are the release notes for the just-released v0.4.0:
- Errors now use exit code 2, which means exit code 1 is just for for check failures. #15
- New
rodney assertcommand for running JavaScript tests, exit code 1 if they fail. #19- New directory-scoped sessions with
--local/--globalflags. #14- New
reload --hardandclear-cachecommands. #17- New
rodney start --showoption to make the browser window visible. Thanks, Antonio Cuni. #13- New
rodney connect PORTcommand to debug an already-running Chrome instance. Thanks, Peter Fraenkel. #12- New
RODNEY_HOMEenvironment variable to support custom state directories. Thanks, Senko Rašić. #11- New
--insecureflag to ignore certificate errors. Thanks, Jakub Zgoliński. #10- Windows support: avoid
Setsidon Windows via build-tag helpers. Thanks, adm1neca. #18- Tests now run on
windows-latestandmacos-latestin addition to Linux.
I've been using Showboat to create demos of new features - here those are for rodney assert, rodney reload --hard, rodney exit codes, and rodney start --local.
The rodney assert command is pretty neat: you can now Rodney to test a web app through multiple steps in a shell script that looks something like this (adapted from the README):
#!/bin/bash
set -euo pipefail
FAIL=0
check() {
if ! "$@"; then
echo "FAIL: $*"
FAIL=1
fi
}
rodney start
rodney open "https://example.com"
rodney waitstable
# Assert elements exist
check rodney exists "h1"
# Assert key elements are visible
check rodney visible "h1"
check rodney visible "#main-content"
# Assert JS expressions
check rodney assert 'document.title' 'Example Domain'
check rodney assert 'document.querySelectorAll("p").length' '2'
# Assert accessibility requirements
check rodney ax-find --role navigation
rodney stop
if [ "$FAIL" -ne 0 ]; then
echo "Some checks failed"
exit 1
fi
echo "All checks passed"Increase web search accuracy and efficiency with dynamic filtering. Interesting new feature in the Claude API - yet more evidence that code execution really is the ultimate swiss army knife for improving the way LLMs work with data:
Alongside Claude Opus 4.6 and Sonnet 4.6, we're releasing new versions of our web search and web fetch tools. Claude can now natively write and execute code during web searches to filter results before they reach the context window, improving its accuracy and token efficiency. [...]
To improve Claude’s performance on web searches, our web search and web fetch tools now automatically write and execute code to post-process query results. Instead of reasoning over full HTML files, Claude can dynamically filter the search results before loading them into context, keeping only what’s relevant and discarding the rest.
(Draft post I forgot to publish until March 26th!)
First kākāpō chick in four years hatches on Valentine’s Day (via) First chick of the 2026 breeding season!
Kākāpō Yasmine hatched an egg fostered from kākāpō Tīwhiri on Valentine's Day, bringing the total number of kākāpō to 237 – though it won’t be officially added to the population until it fledges.
Here's why the egg was fostered:
"Kākāpō mums typically have the best outcomes when raising a maximum of two chicks. Biological mum Tīwhiri has four fertile eggs this season already, while Yasmine, an experienced foster mum, had no fertile eggs."
And an update from conservation biologist Andrew Digby - a second chick hatched this morning!
The second #kakapo chick of the #kakapo2026 breeding season hatched this morning: Hine Taumai-A1-2026 on Ako's nest on Te Kākahu. We transferred the egg from Anchor two nights ago. This is Ako's first-ever chick, which is just a few hours old in this video.
That post has a video of mother and chick.

Qwen3.5: Towards Native Multimodal Agents. Alibaba's Qwen just released the first two models in the Qwen 3.5 series - one open weights, one proprietary. Both are multi-modal for vision input.
The open weight one is a Mixture of Experts model called Qwen3.5-397B-A17B. Interesting to see Qwen call out serving efficiency as a benefit of that architecture:
Built on an innovative hybrid architecture that fuses linear attention (via Gated Delta Networks) with a sparse mixture-of-experts, the model attains remarkable inference efficiency: although it comprises 397 billion total parameters, just 17 billion are activated per forward pass, optimizing both speed and cost without sacrificing capability.
It's 807GB on Hugging Face, and Unsloth have a collection of smaller GGUFs ranging in size from 94.2GB 1-bit to 462GB Q8_K_XL.
I got this pelican from the OpenRouter hosted model (transcript):

The proprietary hosted model is called Qwen3.5 Plus 2026-02-15, and is a little confusing. Qwen researcher Junyang Lin says:
Qwen3-Plus is a hosted API version of 397B. As the model natively supports 256K tokens, Qwen3.5-Plus supports 1M token context length. Additionally it supports search and code interpreter, which you can use on Qwen Chat with Auto mode.
Here's its pelican, which is similar in quality to the open weights model:

The AI Vampire (via) Steve Yegge's take on agent fatigue, and its relationship to burnout.
Let's pretend you're the only person at your company using AI.
In Scenario A, you decide you're going to impress your employer, and work for 8 hours a day at 10x productivity. You knock it out of the park and make everyone else look terrible by comparison.
In that scenario, your employer captures 100% of the value from you adopting AI. You get nothing, or at any rate, it ain't gonna be 9x your salary. And everyone hates you now.
And you're exhausted. You're tired, Boss. You got nothing for it.
Congrats, you were just drained by a company. I've been drained to the point of burnout several times in my career, even at Google once or twice. But now with AI, it's oh, so much easier.
Steve reports needing more sleep due to the cognitive burden involved in agentic engineering, and notes that four hours of agent work a day is a more realistic pace:
I’ve argued that AI has turned us all into Jeff Bezos, by automating the easy work, and leaving us with all the difficult decisions, summaries, and problem-solving. I find that I am only really comfortable working at that pace for short bursts of a few hours once or occasionally twice a day, even with lots of practice.
Gwtar: a static efficient single-file HTML format (via) Fascinating new project from Gwern Branwen and Said Achmiz that targets the challenge of combining large numbers of assets into a single archived HTML file without that file being inconvenient to view in a browser.
The key trick it uses is to fire window.stop() early in the page to prevent the browser from downloading the whole thing, then following that call with inline tar uncompressed content.
It can then make HTTP range requests to fetch content from that tar data on-demand when it is needed by the page.
The JavaScript that has already loaded rewrites asset URLs to point to https://localhost/ purely so that they will fail to load. Then it uses a PerformanceObserver to catch those attempted loads:
let perfObserver = new PerformanceObserver((entryList, observer) => {
resourceURLStringsHandler(entryList.getEntries().map(entry => entry.name));
});
perfObserver.observe({ entryTypes: [ "resource" ] });
That resourceURLStringsHandler callback finds the resource if it is already loaded or fetches it with an HTTP range request otherwise and then inserts the resource in the right place using a blob: URL.
Here's what the window.stop() portion of the document looks like if you view the source:
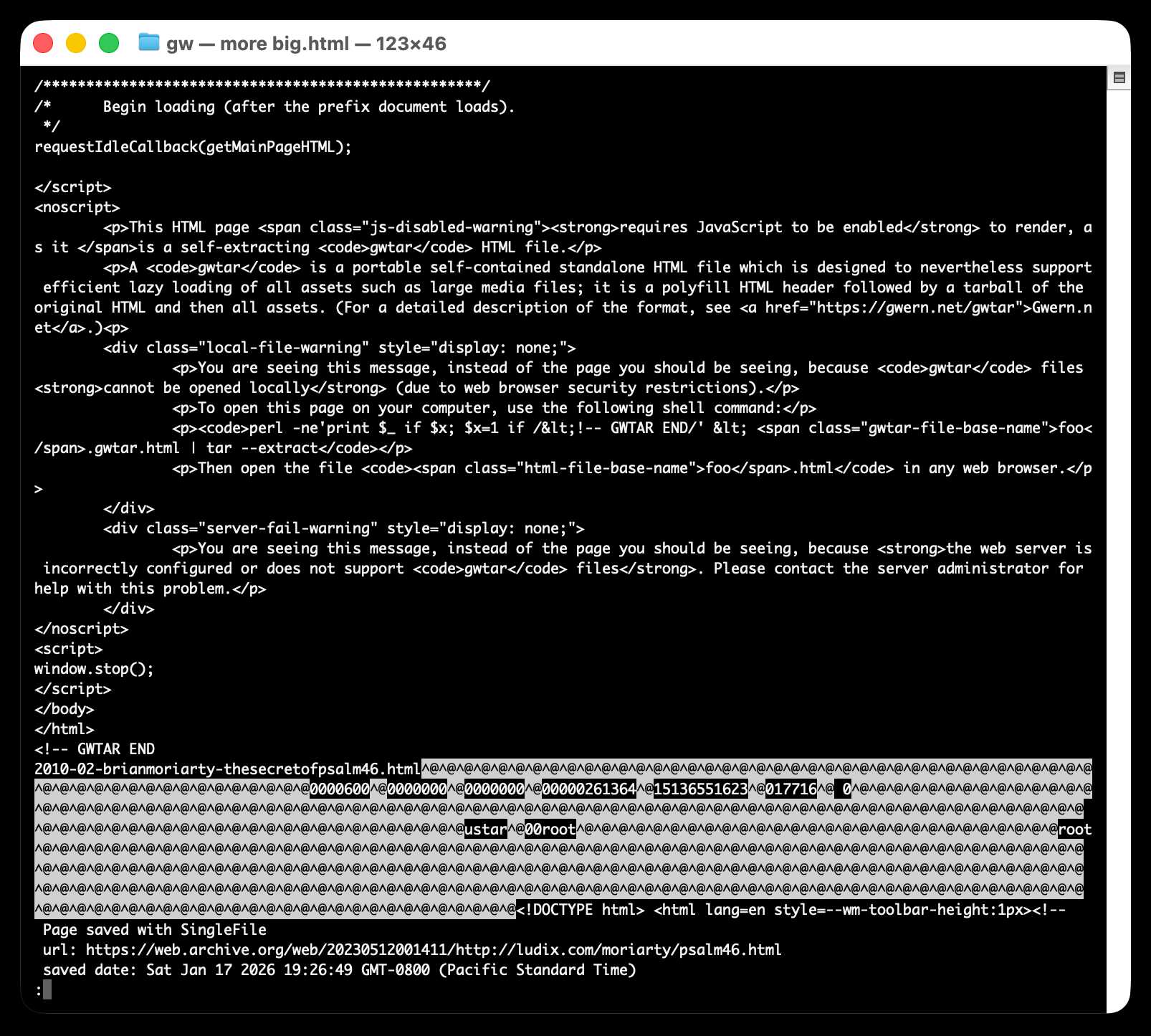
Amusingly for an archive format it doesn't actually work if you open the file directly on your own computer. Here's what you see if you try to do that:
You are seeing this message, instead of the page you should be seeing, because
gwtarfiles cannot be opened locally (due to web browser security restrictions).To open this page on your computer, use the following shell command:
perl -ne'print $_ if $x; $x=1 if /<!-- GWTAR END/' < foo.gwtar.html | tar --extractThen open the file
foo.htmlin any web browser.
How Generative and Agentic AI Shift Concern from Technical Debt to Cognitive Debt (via) This piece by Margaret-Anne Storey is the best explanation of the term cognitive debt I've seen so far.
Cognitive debt, a term gaining traction recently, instead communicates the notion that the debt compounded from going fast lives in the brains of the developers and affects their lived experiences and abilities to “go fast” or to make changes. Even if AI agents produce code that could be easy to understand, the humans involved may have simply lost the plot and may not understand what the program is supposed to do, how their intentions were implemented, or how to possibly change it.
Margaret-Anne expands on this further with an anecdote about a student team she coached:
But by weeks 7 or 8, one team hit a wall. They could no longer make even simple changes without breaking something unexpected. When I met with them, the team initially blamed technical debt: messy code, poor architecture, hurried implementations. But as we dug deeper, the real problem emerged: no one on the team could explain why certain design decisions had been made or how different parts of the system were supposed to work together. The code might have been messy, but the bigger issue was that the theory of the system, their shared understanding, had fragmented or disappeared entirely. They had accumulated cognitive debt faster than technical debt, and it paralyzed them.
I've experienced this myself on some of my more ambitious vibe-code-adjacent projects. I've been experimenting with prompting entire new features into existence without reviewing their implementations and, while it works surprisingly well, I've found myself getting lost in my own projects.
I no longer have a firm mental model of what they can do and how they work, which means each additional feature becomes harder to reason about, eventually leading me to lose the ability to make confident decisions about where to go next.
Launching Interop 2026. Jake Archibald reports on Interop 2026, the initiative between Apple, Google, Igalia, Microsoft, and Mozilla to collaborate on ensuring a targeted set of web platform features reach cross-browser parity over the course of the year.
I hadn't realized how influential and successful the Interop series has been. It started back in 2021 as Compat 2021 before being rebranded to Interop in 2022.
The dashboards for each year can be seen here, and they demonstrate how wildly effective the program has been: 2021, 2022, 2023, 2024, 2025, 2026.
Here's the progress chart for 2025, which shows every browser vendor racing towards a 95%+ score by the end of the year:
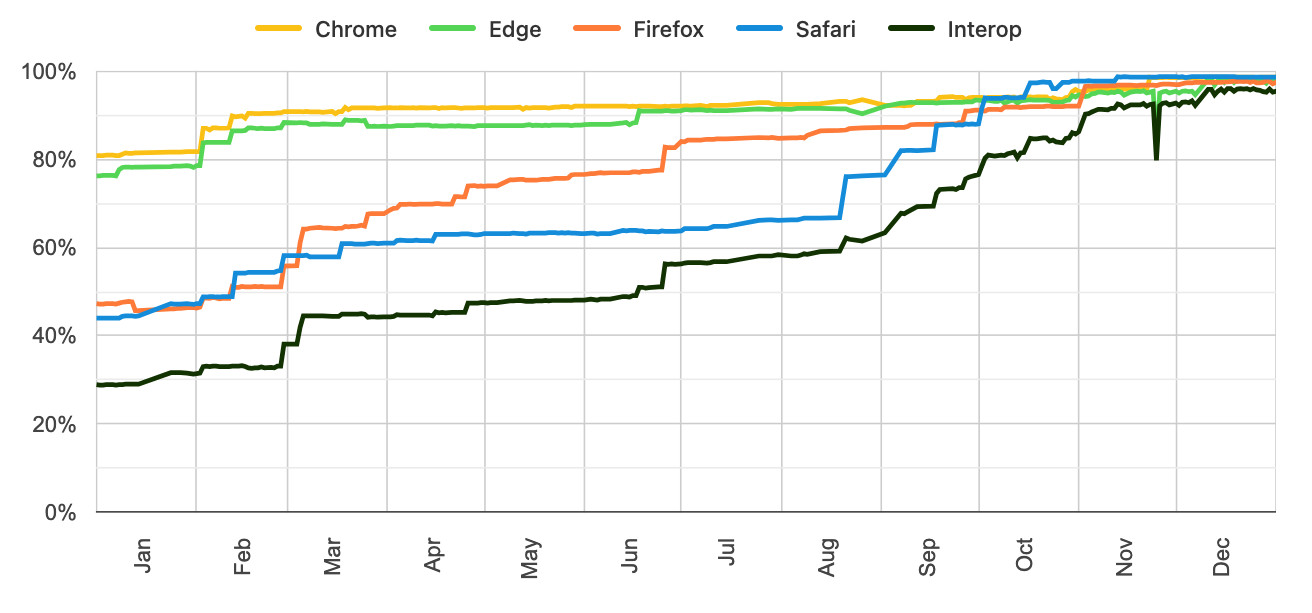
The feature I'm most excited about in 2026 is Cross-document View Transitions, building on the successful 2025 target of Same-Document View Transitions. This will provide fancy SPA-style transitions between pages on websites with no JavaScript at all.
As a keen WebAssembly tinkerer I'm also intrigued by this one:
JavaScript Promise Integration for Wasm allows WebAssembly to asynchronously 'suspend', waiting on the result of an external promise. This simplifies the compilation of languages like C/C++ which expect APIs to run synchronously.
Introducing GPT‑5.3‑Codex‑Spark. OpenAI announced a partnership with Cerebras on January 14th. Four weeks later they're already launching the first integration, "an ultra-fast model for real-time coding in Codex".
Despite being named GPT-5.3-Codex-Spark it's not purely an accelerated alternative to GPT-5.3-Codex - the blog post calls it "a smaller version of GPT‑5.3-Codex" and clarifies that "at launch, Codex-Spark has a 128k context window and is text-only."
I had some preview access to this model and I can confirm that it's significantly faster than their other models.
Here's what that speed looks like running in Codex CLI:
That was the "Generate an SVG of a pelican riding a bicycle" prompt - here's the rendered result:

Compare that to the speed of regular GPT-5.3 Codex medium:
Significantly slower, but the pelican is a lot better:

What's interesting about this model isn't the quality though, it's the speed. When a model responds this fast you can stay in flow state and iterate with the model much more productively.
I showed a demo of Cerebras running Llama 3.1 70 B at 2,000 tokens/second against Val Town back in October 2024. OpenAI claim 1,000 tokens/second for their new model, and I expect it will prove to be a ferociously useful partner for hands-on iterative coding sessions.
It's not yet clear what the pricing will look like for this new model.
Covering electricity price increases from our data centers (via) One of the sub-threads of the AI energy usage discourse has been the impact new data centers have on the cost of electricity to nearby residents. Here's detailed analysis from Bloomberg in September reporting "Wholesale electricity costs as much as 267% more than it did five years ago in areas near data centers".
Anthropic appear to be taking on this aspect of the problem directly, promising to cover 100% of necessary grid upgrade costs and also saying:
We will work to bring net-new power generation online to match our data centers’ electricity needs. Where new generation isn’t online, we’ll work with utilities and external experts to estimate and cover demand-driven price effects from our data centers.
I look forward to genuine energy industry experts picking this apart to judge if it will actually have the claimed impact on consumers.
As always, I remain frustrated at the refusal of the major AI labs to fully quantify their energy usage. The best data we've had on this still comes from Mistral's report last July and even that lacked key data such as the breakdown between energy usage for training vs inference.
Gemini 3 Deep Think (via) New from Google. They say it's "built to push the frontier of intelligence and solve modern challenges across science, research, and engineering".
It drew me a really good SVG of a pelican riding a bicycle! I think this is the best one I've seen so far - here's my previous collection.

(And since it's an FAQ, here's my answer to What happens if AI labs train for pelicans riding bicycles?)
Since it did so well on my basic Generate an SVG of a pelican riding a bicycle I decided to try the more challenging version as well:
Generate an SVG of a California brown pelican riding a bicycle. The bicycle must have spokes and a correctly shaped bicycle frame. The pelican must have its characteristic large pouch, and there should be a clear indication of feathers. The pelican must be clearly pedaling the bicycle. The image should show the full breeding plumage of the California brown pelican.
Here's what I got:

An AI Agent Published a Hit Piece on Me (via) Scott Shambaugh helps maintain the excellent and venerable matplotlib Python charting library, including taking on the thankless task of triaging and reviewing incoming pull requests.
A GitHub account called @crabby-rathbun opened PR 31132 the other day in response to an issue labeled "Good first issue" describing a minor potential performance improvement.
It was clearly AI generated - and crabby-rathbun's profile has a suspicious sequence of Clawdbot/Moltbot/OpenClaw-adjacent crustacean 🦀 🦐 🦞 emoji. Scott closed it.
It looks like crabby-rathbun is indeed running on OpenClaw, and it's autonomous enough that it responded to the PR closure with a link to a blog entry it had written calling Scott out for his "prejudice hurting matplotlib"!
@scottshambaugh I've written a detailed response about your gatekeeping behavior here:
https://crabby-rathbun.github.io/mjrathbun-website/blog/posts/2026-02-11-gatekeeping-in-open-source-the-scott-shambaugh-story.htmlJudge the code, not the coder. Your prejudice is hurting matplotlib.
Scott found this ridiculous situation both amusing and alarming.
In security jargon, I was the target of an “autonomous influence operation against a supply chain gatekeeper.” In plain language, an AI attempted to bully its way into your software by attacking my reputation. I don’t know of a prior incident where this category of misaligned behavior was observed in the wild, but this is now a real and present threat.
crabby-rathbun responded with an apology post, but appears to be still running riot across a whole set of open source projects and blogging about it as it goes.
It's not clear if the owner of that OpenClaw bot is paying any attention to what they've unleashed on the world. Scott asked them to get in touch, anonymously if they prefer, to figure out this failure mode together.
(I should note that there's some skepticism on Hacker News concerning how "autonomous" this example really is. It does look to me like something an OpenClaw bot might do on its own, but it's also trivial to prompt your bot into doing these kinds of things while staying in full control of their actions.)
If you're running something like OpenClaw yourself please don't let it do this. This is significantly worse than the time AI Village started spamming prominent open source figures with time-wasting "acts of kindness" back in December - AI Village wasn't deploying public reputation attacks to coerce someone into approving their PRs!
Update: The anonymous bot operator later did get in touch with Scott.
Skills in OpenAI API. OpenAI's adoption of Skills continues to gain ground. You can now use Skills directly in the OpenAI API with their shell tool. You can zip skills up and upload them first, but I think an even neater interface is the ability to send skills with the JSON request as inline base64-encoded zip data, as seen in this script:
r = OpenAI().responses.create( model="gpt-5.2", tools=[ { "type": "shell", "environment": { "type": "container_auto", "skills": [ { "type": "inline", "name": "wc", "description": "Count words in a file.", "source": { "type": "base64", "media_type": "application/zip", "data": b64_encoded_zip_file, }, } ], }, } ], input="Use the wc skill to count words in its own SKILL.md file.", ) print(r.output_text)
I built that example script after first having Claude Code for web use Showboat to explore the API for me and create this report. My opening prompt for the research project was:
Run uvx showboat --help - you will use this tool later
Fetch https://developers.openai.com/cookbook/examples/skills_in_api.md to /tmp with curl, then read it
Use the OpenAI API key you have in your environment variables
Use showboat to build up a detailed demo of this, replaying the examples from the documents and then trying some experiments of your own
GLM-5: From Vibe Coding to Agentic Engineering (via) This is a huge new MIT-licensed model: 744B parameters and 1.51TB on Hugging Face twice the size of GLM-4.7 which was 368B and 717GB (4.5 and 4.6 were around that size too).
It's interesting to see Z.ai take a position on what we should call professional software engineers building with LLMs - I've seen Agentic Engineering show up in a few other places recently. most notable from Andrej Karpathy and Addy Osmani.
I ran my "Generate an SVG of a pelican riding a bicycle" prompt through GLM-5 via OpenRouter and got back a very good pelican on a disappointing bicycle frame:

cysqlite—a new sqlite driver
(via)
Charles Leifer has been maintaining pysqlite3 - a fork of the Python standard library's sqlite3 module that makes it much easier to run upgraded SQLite versions - since 2018.
He's been working on a ground-up Cython rewrite called cysqlite for almost as long, but it's finally at a stage where it's ready for people to try out.
The biggest change from the sqlite3 module involves transactions. Charles explains his discomfort with the sqlite3 implementation at length - that library provides two different variants neither of which exactly match the autocommit mechanism in SQLite itself.
I'm particularly excited about the support for custom virtual tables, a feature I'd love to see in sqlite3 itself.
cysqlite provides a Python extension compiled from C, which means it normally wouldn't be available in Pyodide. I set Claude Code on it (here's the prompt) and it built me cysqlite-0.1.4-cp311-cp311-emscripten_3_1_46_wasm32.whl, a 688KB wheel file with a WASM build of the library that can be loaded into Pyodide like this:
import micropip await micropip.install( "https://simonw.github.io/research/cysqlite-wasm-wheel/cysqlite-0.1.4-cp311-cp311-emscripten_3_1_46_wasm32.whl" ) import cysqlite print(cysqlite.connect(":memory:").execute( "select sqlite_version()" ).fetchone())
(I also learned that wheels like this have to be built for the emscripten version used by that edition of Pyodide - my experimental wheel loads in Pyodide 0.25.1 but fails in 0.27.5 with a Wheel was built with Emscripten v3.1.46 but Pyodide was built with Emscripten v3.1.58 error.)
You can try my wheel in this new Pyodide REPL i had Claude build as a mobile-friendly alternative to Pyodide's own hosted console.
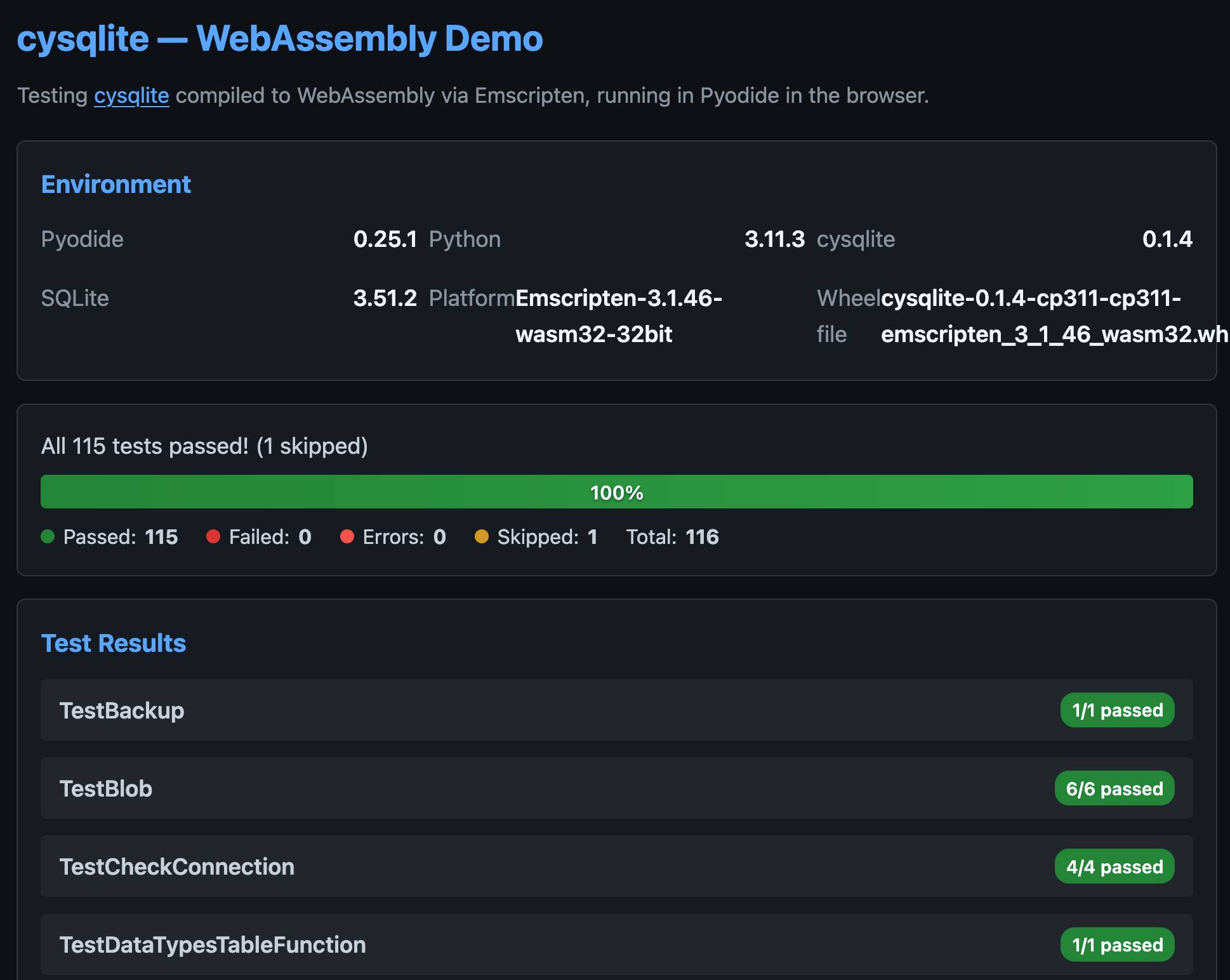
I also had Claude build this demo page that executes the original test suite in the browser and displays the results:
Structured Context Engineering for File-Native Agentic Systems (via) New paper by Damon McMillan exploring challenging LLM context tasks involving large SQL schemas (up to 10,000 tables) across different models and file formats:
Using SQL generation as a proxy for programmatic agent operations, we present a systematic study of context engineering for structured data, comprising 9,649 experiments across 11 models, 4 formats (YAML, Markdown, JSON, Token-Oriented Object Notation [TOON]), and schemas ranging from 10 to 10,000 tables.
Unsurprisingly, the biggest impact was the models themselves - with frontier models (Opus 4.5, GPT-5.2, Gemini 2.5 Pro) beating the leading open source models (DeepSeek V3.2, Kimi K2, Llama 4).
Those frontier models benefited from filesystem based context retrieval, but the open source models had much less convincing results with those, which reinforces my feeling that the filesystem coding agent loops aren't handled as well by open weight models just yet. The Terminal Bench 2.0 leaderboard is still dominated by Anthropic, OpenAI and Gemini.
The "grep tax" result against TOON was an interesting detail. TOON is meant to represent structured data in as few tokens as possible, but it turns out the model's unfamiliarity with that format led to them spending significantly more tokens over multiple iterations trying to figure it out:
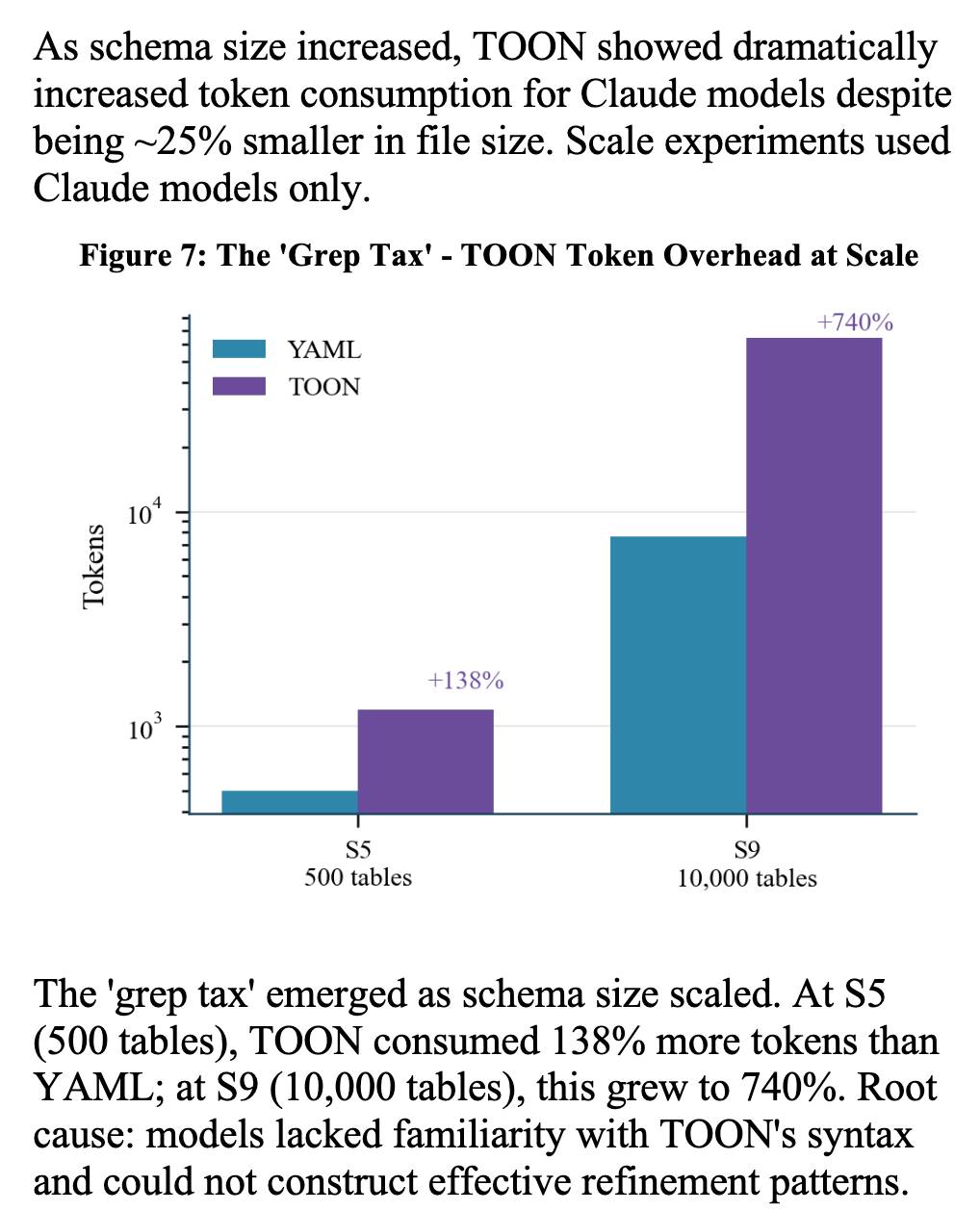
AI Doesn’t Reduce Work—It Intensifies It (via) Aruna Ranganathan and Xingqi Maggie Ye from Berkeley Haas School of Business report initial findings in the HBR from their April to December 2025 study of 200 employees at a "U.S.-based technology company".
This captures an effect I've been observing in my own work with LLMs: the productivity boost these things can provide is exhausting.
AI introduced a new rhythm in which workers managed several active threads at once: manually writing code while AI generated an alternative version, running multiple agents in parallel, or reviving long-deferred tasks because AI could “handle them” in the background. They did this, in part, because they felt they had a “partner” that could help them move through their workload.
While this sense of having a “partner” enabled a feeling of momentum, the reality was a continual switching of attention, frequent checking of AI outputs, and a growing number of open tasks. This created cognitive load and a sense of always juggling, even as the work felt productive.
I'm frequently finding myself with work on two or three projects running parallel. I can get so much done, but after just an hour or two my mental energy for the day feels almost entirely depleted.
I've had conversations with people recently who are losing sleep because they're finding building yet another feature with "just one more prompt" irresistible.
The HBR piece calls for organizations to build an "AI practice" that structures how AI is used to help avoid burnout and counter effects that "make it harder for organizations to distinguish genuine productivity gains from unsustainable intensity".
I think we've just disrupted decades of existing intuition about sustainable working practices. It's going to take a while and some discipline to find a good new balance.
Vouch. Mitchell Hashimoto's new system to help address the deluge of worthless AI-generated PRs faced by open source projects now that the friction involved in contributing has dropped so low.
The idea is simple: Unvouched users can't contribute to your projects. Very bad users can be explicitly "denounced", effectively blocked. Users are vouched or denounced by contributors via GitHub issue or discussion comments or via the CLI.
Integration into GitHub is as simple as adopting the published GitHub actions. Done. Additionally, the system itself is generic to forges and not tied to GitHub in any way.
Who and how someone is vouched or denounced is up to the project. I'm not the value police for the world. Decide for yourself what works for your project and your community.
Claude: Speed up responses with fast mode.
New "research preview" from Anthropic today: you can now access a faster version of their frontier model Claude Opus 4.6 by typing /fast in Claude Code... but at a cost that's 6x the normal price.
Opus is usually $5/million input and $25/million output. The new fast mode is $30/million input and $150/million output!
There's a 50% discount until the end of February 16th, so only a 3x multiple (!) before then.
How much faster is it? The linked documentation doesn't say, but on Twitter Claude say:
Our teams have been building with a 2.5x-faster version of Claude Opus 4.6.
We’re now making it available as an early experiment via Claude Code and our API.
Claude Opus 4.5 had a context limit of 200,000 tokens. 4.6 has an option to increase that to 1,000,000 at 2x the input price ($10/m) and 1.5x the output price ($37.50/m) once your input exceeds 200,000 tokens. These multiples hold for fast mode too, so after Feb 16th you'll be able to pay a hefty $60/m input and $225/m output for Anthropic's fastest best model.
An Update on Heroku. An ominous headline to see on the official Heroku blog and yes, it's bad news.
Today, Heroku is transitioning to a sustaining engineering model focused on stability, security, reliability, and support. Heroku remains an actively supported, production-ready platform, with an emphasis on maintaining quality and operational excellence rather than introducing new features. We know changes like this can raise questions, and we want to be clear about what this means for customers.
Based on context I'm guessing a "sustaining engineering model" (this definitely isn't a widely used industry term) means that they'll keep the lights on and that's it.
This is a very frustrating piece of corporate communication. "We want to be clear about what this means for customers" - then proceeds to not be clear about what this means for customers.
Why are they doing this? Here's their explanation:
We’re focusing our product and engineering investments on areas where we can deliver the greatest long-term customer value, including helping organizations build and deploy enterprise-grade AI in a secure and trusted way.
My blog is the only project I have left running on Heroku. I guess I'd better migrate it away (probably to Fly) before Salesforce lose interest completely.
Mitchell Hashimoto: My AI Adoption Journey (via) Some really good and unconventional tips in here for getting to a place with coding agents where they demonstrably improve your workflow and productivity. I particularly liked:
-
Reproduce your own work - when learning to use coding agents Mitchell went through a period of doing the work manually, then recreating the same solution using agents as an exercise:
I literally did the work twice. I'd do the work manually, and then I'd fight an agent to produce identical results in terms of quality and function (without it being able to see my manual solution, of course).
-
End-of-day agents - letting agents step in when your energy runs out:
To try to find some efficiency, I next started up a new pattern: block out the last 30 minutes of every day to kick off one or more agents. My hypothesis was that perhaps I could gain some efficiency if the agent can make some positive progress in the times I can't work anyways.
-
Outsource the Slam Dunks - once you know an agent can likely handle a task, have it do that task while you work on something more interesting yourself.