March 2025
136 posts: 11 entries, 59 links, 18 quotes, 1 note, 47 beats
March 1, 2025
llm-anthropic #24: Use new URL parameter to send attachments. Anthropic released a neat quality of life improvement today. Alex Albert:
We've added the ability to specify a public facing URL as the source for an image / document block in the Anthropic API
Prior to this, any time you wanted to send an image to the Claude API you needed to base64-encode it and then include that data in the JSON. This got pretty bulky, especially in conversation scenarios where the same image data needs to get passed in every follow-up prompt.
I implemented this for llm-anthropic and shipped it just now in version 0.15.1 (here's the commit) - I went with a patch release version number bump because this is effectively a performance optimization which doesn't provide any new features, previously LLM would accept URLs just fine and would download and then base64 them behind the scenes.
In testing this out I had a really impressive result from Claude 3.7 Sonnet. I found a newspaper page from 1900 on the Library of Congress (the "Worcester spy.") and fed a URL to the PDF into Sonnet like this:
llm -m claude-3.7-sonnet \
-a 'https://tile.loc.gov/storage-services/service/ndnp/mb/batch_mb_gaia_ver02/data/sn86086481/0051717161A/1900012901/0296.pdf' \
'transcribe all text from this image, formatted as markdown'

I haven't checked every sentence but it appears to have done an excellent job, at a cost of 16 cents.
As another experiment, I tried running that against my example people template from the schemas feature I released this morning:
llm -m claude-3.7-sonnet \
-a 'https://tile.loc.gov/storage-services/service/ndnp/mb/batch_mb_gaia_ver02/data/sn86086481/0051717161A/1900012901/0296.pdf' \
-t people
That only gave me two results - so I tried an alternative approach where I looped the OCR text back through the same template, using llm logs --cid with the logged conversation ID and -r to extract just the raw response from the logs:
llm logs --cid 01jn7h45x2dafa34zk30z7ayfy -r | \
llm -t people -m claude-3.7-sonnet
... and that worked fantastically well! The result started like this:
{
"items": [
{
"name": "Capt. W. R. Abercrombie",
"organization": "United States Army",
"role": "Commander of Copper River exploring expedition",
"learned": "Reported on the horrors along the Copper River in Alaska, including starvation, scurvy, and mental illness affecting 70% of people. He was tasked with laying out a trans-Alaskan military route and assessing resources.",
"article_headline": "MUCH SUFFERING",
"article_date": "1900-01-28"
},
{
"name": "Edward Gillette",
"organization": "Copper River expedition",
"role": "Member of the expedition",
"learned": "Contributed a chapter to Abercrombie's report on the feasibility of establishing a railroad route up the Copper River valley, comparing it favorably to the Seattle to Skaguay route.",
"article_headline": "MUCH SUFFERING",
"article_date": "1900-01-28"
}March 2, 2025
Hallucinations in code are the least dangerous form of LLM mistakes
A surprisingly common complaint I see from developers who have tried using LLMs for code is that they encountered a hallucination—usually the LLM inventing a method or even a full software library that doesn’t exist—and it crashed their confidence in LLMs as a tool for writing code. How could anyone productively use these things if they invent methods that don’t exist?
[... 1,052 words]18f.org. New site by members of 18F, the team within the US government that were doing some of the most effective work at improving government efficiency.
For over 11 years, 18F has been proudly serving you to make government technology work better. We are non-partisan civil servants. 18F has worked on hundreds of projects, all designed to make government technology not just efficient but effective, and to save money for American taxpayers.
However, all employees at 18F – a group that the Trump Administration GSA Technology Transformation Services Director called "the gold standard" of civic tech – were terminated today at midnight ET.
18F was doing exactly the type of work that DOGE claims to want – yet we were eliminated.
The entire team is now on "administrative leave" and locked out of their computers.
But these are not the kind of civil servants to abandon their mission without a fight:
We’re not done yet.
We’re still absorbing what has happened. We’re wrestling with what it will mean for ourselves and our families, as well as the impact on our partners and the American people.
But we came to the government to fix things. And we’re not done with this work yet.
More to come.
You can follow @team18f.bsky.social on Bluesky.
Regarding the recent blog post, I think a simpler explanation is that hallucinating a non-existent library is a such an inhuman error it throws people. A human making such an error would be almost unforgivably careless.
Notes from my Accessibility and Gen AI podcast appearance

I was a guest on the most recent episode of the Accessibility + Gen AI Podcast, hosted by Eamon McErlean and Joe Devon. We had a really fun, wide-ranging conversation about a host of different topics. I’ve extracted a few choice quotes from the transcript.
[... 947 words]After publishing this piece, I was contacted by Anthropic who told me that Sonnet 3.7 would not be considered a 10^26 FLOP model and cost a few tens of millions of dollars to train, though future models will be much bigger.
March 3, 2025
The features of Python’s help() function
(via)
I've only ever used Python's help() feature by passing references to modules, classes functions and objects to it. Trey Hunner just taught me that it accepts strings too - help("**") tells you about the ** operator, help("if") describes the if statement and help("topics") reveals even more options, including things like help("SPECIALATTRIBUTES") to learn about specific advanced topics.
March 4, 2025
I built an automaton called Squadron

I believe that the price you have to pay for taking on a project is writing about it afterwards. On that basis, I feel compelled to write up my decidedly non-software project from this weekend: Squadron, an automaton.
[... 1,142 words]llm-mistral 0.11. I added schema support to this plugin which adds support for the Mistral API to LLM. Release notes:
Schemas now work with OpenAI, Anthropic, Gemini and Mistral hosted models, plus self-hosted models via Ollama and llm-ollama.
llm-ollama 0.9.0.
This release of the llm-ollama plugin adds support for schemas, thanks to a PR by Adam Compton.
Ollama provides very robust support for this pattern thanks to their structured outputs feature, which works across all of the models that they support by intercepting the logic that outputs the next token and restricting it to only tokens that would be valid in the context of the provided schema.
With Ollama and llm-ollama installed you can run even run structured schemas against vision prompts for local models. Here's one against Ollama's llama3.2-vision:
llm -m llama3.2-vision:latest \
'describe images' \
--schema 'species,description,count int' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
I got back this:
{
"species": "Pelicans",
"description": "The image features a striking brown pelican with its distinctive orange beak, characterized by its large size and impressive wingspan.",
"count": 1
}
(Actually a bit disappointing, as there are two pelicans and their beaks are brown.)
{kind=link}
A Practical Guide to Implementing DeepSearch / DeepResearch. I really like the definitions Han Xiao from Jina AI proposes for the terms DeepSearch and DeepResearch in this piece:
DeepSearch runs through an iterative loop of searching, reading, and reasoning until it finds the optimal answer. [...]
DeepResearch builds upon DeepSearch by adding a structured framework for generating long research reports.
I've recently found myself cooling a little on the classic RAG pattern of finding relevant documents and dumping them into the context for a single call to an LLM.
I think this definition of DeepSearch helps explain why. RAG is about answering questions that fall outside of the knowledge baked into a model. The DeepSearch pattern offers a tools-based alternative to classic RAG: we give the model extra tools for running multiple searches (which could be vector-based, or FTS, or even systems like ripgrep) and run it for several steps in a loop to try to find an answer.
I think DeepSearch is a lot more interesting than DeepResearch, which feels to me more like a presentation layer thing. Pulling together the results from multiple searches into a "report" looks more impressive, but I still worry that the report format provides a misleading impression of the quality of the "research" that took place.
March 5, 2025
QwQ-32B: Embracing the Power of Reinforcement Learning (via) New Apache 2 licensed reasoning model from Qwen:
We are excited to introduce QwQ-32B, a model with 32 billion parameters that achieves performance comparable to DeepSeek-R1, which boasts 671 billion parameters (with 37 billion activated). This remarkable outcome underscores the effectiveness of RL when applied to robust foundation models pretrained on extensive world knowledge.
I had a lot of fun trying out their previous QwQ reasoning model last November. I demonstrated this new QwQ in my talk at NICAR about recent LLM developments. Here's the example I ran.
{kind=link}
LM Studio just released GGUFs ranging in size from 17.2 to 34.8 GB. MLX have compatible weights published in 3bit, 4bit, 6bit and 8bit. Ollama has the new qwq too - it looks like they've renamed the previous November release qwq:32b-preview.
Career Update: Google DeepMind -> Anthropic. Nicholas Carlini (previously) on joining Anthropic, driven partly by his frustration at friction he encountered publishing his research at Google DeepMind after their merge with Google Brain. His area of expertise is adversarial machine learning.
The recent advances in machine learning and language modeling are going to be transformative [d] But in order to realize this potential future in a way that doesn't put everyone's safety and security at risk, we're going to need to make a lot of progress---and soon. We need to make so much progress that no one organization will be able to figure everything out by themselves; we need to work together, we need to talk about what we're doing, and we need to start doing this now.
Demo of ChatGPT Code Interpreter running in o3-mini-high. OpenAI made GPT-4.5 available to Plus ($20/month) users today. I was a little disappointed with GPT-4.5 when I tried it through the API, but having access in the ChatGPT interface meant I could use it with existing tools such as Code Interpreter which made its strengths a whole lot more evident - that’s a transcript where I had it design and test its own version of the JSON Schema succinct DSL I published last week.
Riley Goodside then spotted that Code Interpreter has been quietly enabled for other models too, including the excellent o3-mini reasoning model. This means you can have o3-mini reason about code, write that code, test it, iterate on it and keep going until it gets something that works.
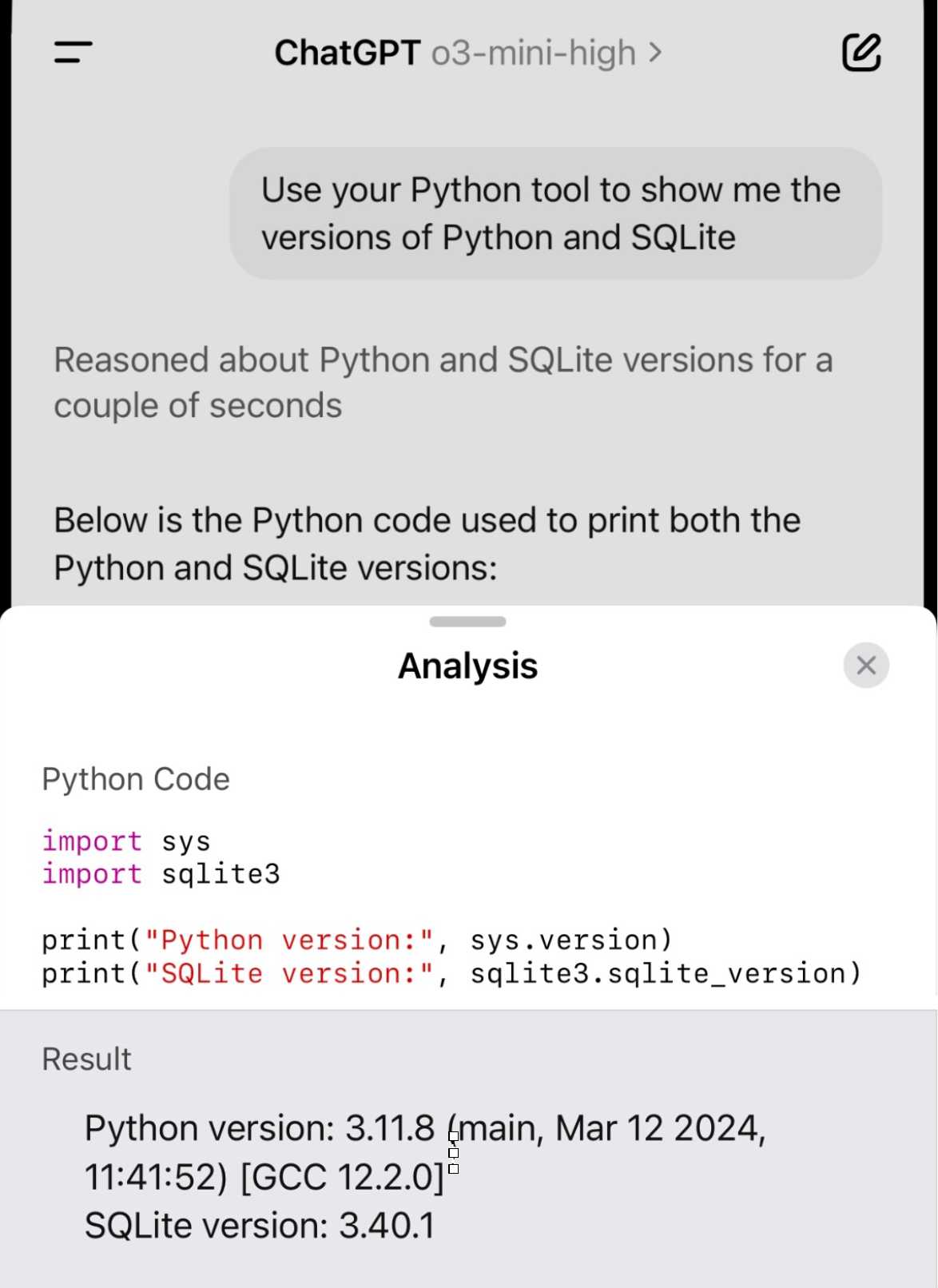
Code Interpreter remains my favorite implementation of the "coding agent" pattern, despite recieving very few upgrades in the two years after its initial release. Plugging much stronger models into it than the previous GPT-4o default makes it even more useful.
Nothing about this in the ChatGPT release notes yet, but I've tested it in the ChatGPT iOS app and mobile web app and it definitely works there.
The Graphing Calculator Story (via) Utterly delightful story from Ron Avitzur in 2004 about the origins of the Graphing Calculator app that shipped with many versions of macOS. Ron's contract with Apple had ended but his badge kept working so he kept on letting himself in to work on the project. He even grew a small team:
I asked my friend Greg Robbins to help me. His contract in another division at Apple had just ended, so he told his manager that he would start reporting to me. She didn't ask who I was and let him keep his office and badge. In turn, I told people that I was reporting to him. Since that left no managers in the loop, we had no meetings and could be extremely productive
March 6, 2025
Aider: Using uv as an installer. Paul Gauthier has an innovative solution for the challenge of helping end users get a copy of his Aider CLI Python utility installed in an isolated virtual environment without first needing to teach them what an "isolated virtual environment" is.
Provided you already have a Python install of version 3.8 or higher you can run this:
pip install aider-install && aider-install
The aider-install package itself depends on uv. When you run aider-install it executes the following Python code:
def install_aider(): try: uv_bin = uv.find_uv_bin() subprocess.check_call([ uv_bin, "tool", "install", "--force", "--python", "python3.12", "aider-chat@latest" ]) subprocess.check_call([uv_bin, "tool", "update-shell"]) except subprocess.CalledProcessError as e: print(f"Failed to install aider: {e}") sys.exit(1)
This first figures out the location of the uv Rust binary, then uses it to install his aider-chat package by running the equivalent of this command:
uv tool install --force --python python3.12 aider-chat@latest
This will in turn install a brand new standalone copy of Python 3.12 and tuck it away in uv's own managed directory structure where it shouldn't hurt anything else.
The aider-chat script defaults to being dropped in the XDG standard directory, which is probably ~/.local/bin - see uv's documentation. The --force flag ensures that uv will overwrite any previous attempts at installing aider-chat in that location with the new one.
Finally, running uv tool update-shell ensures that bin directory is on the user's PATH.
I think I like this. There is a LOT of stuff going on here, and experienced users may well opt for an alternative installation mechanism.
But for non-expert Python users who just want to start using Aider, I think this pattern represents quite a tasteful way of getting everything working with minimal risk of breaking the user's system.
Update: Paul adds:
Offering this install method dramatically reduced the number of GitHub issues from users with conflicted/broken python environments.
I also really like the "curl | sh" aider installer based on uv. Even users who don't have python installed can use it.
Will the future of software development run on vibes? I got a few quotes in this piece by Benj Edwards about vibe coding, the term Andrej Karpathy coined for when you prompt an LLM to write code, accept all changes and keep feeding it prompts and error messages and see what you can get it to build.
Here's what I originally sent to Benj:
I really enjoy vibe coding - it's a fun way to play with the limits of these models. It's also useful for prototyping, where the aim of the exercise is to try out an idea and prove if it can work.
Where vibe coding fails is in producing maintainable code for production settings. I firmly believe that as a developer you have to take accountability for the code you produce - if you're going to put your name to it you need to be confident that you understand how and why it works - ideally to the point that you can explain it to somebody else.
Vibe coding your way to a production codebase is clearly a terrible idea. Most of the work we do as software engineers is about evolving existing systems, and for those the quality and understandability of the underlying code is crucial.
For experiments and low-stake projects where you want to explore what's possible and build fun prototypes? Go wild! But stay aware of the very real risk that a good enough prototype often faces pressure to get pushed to production.
If an LLM wrote every line of your code but you've reviewed, tested and understood it all, that's not vibe coding in my book - that's using an LLM as a typing assistant.
monolith (via) Neat CLI tool built in Rust that can create a single packaged HTML file of a web page plus all of its dependencies.
cargo install monolith # or brew install
monolith https://simonwillison.net/ > simonwillison.html
That command produced this 1.5MB single file result. All of the linked images, CSS and JavaScript assets have had their contents inlined into base64 URIs in their src= and href= attributes.
I was intrigued as to how it works, so I dumped the whole repository into Gemini 2.0 Pro and asked for an architectural summary:
cd /tmp
git clone https://github.com/Y2Z/monolith
cd monolith
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'architectural overview as markdown'
Here's what I got. Short version: it uses the reqwest, html5ever, markup5ever_rcdom and cssparser crates to fetch and parse HTML and CSS and extract, combine and rewrite the assets. It doesn't currently attempt to run any JavaScript.
March 7, 2025
Mistral OCR (via) New closed-source specialist OCR model by Mistral - you can feed it images or a PDF and it produces Markdown with optional embedded images.
It's available via their API, or it's "available to self-host on a selective basis" for people with stringent privacy requirements who are willing to talk to their sales team.
I decided to try out their API, so I copied and pasted example code from their notebook into my custom Claude project and told it:
Turn this into a CLI app, depends on mistralai - it should take a file path and an optional API key defauling to env vironment called MISTRAL_API_KEY
After some further iteration / vibe coding I got to something that worked, which I then tidied up and shared as mistral_ocr.py.
You can try it out like this:
export MISTRAL_API_KEY='...'
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf --html --inline-images > mixtral.html
I fed in the Mixtral paper as a PDF. The API returns Markdown, but my --html option renders that Markdown as HTML and the --inline-images option takes any images and inlines them as base64 URIs (inspired by monolith). The result is mixtral.html, a 972KB HTML file with images and text bundled together.
This did a pretty great job!
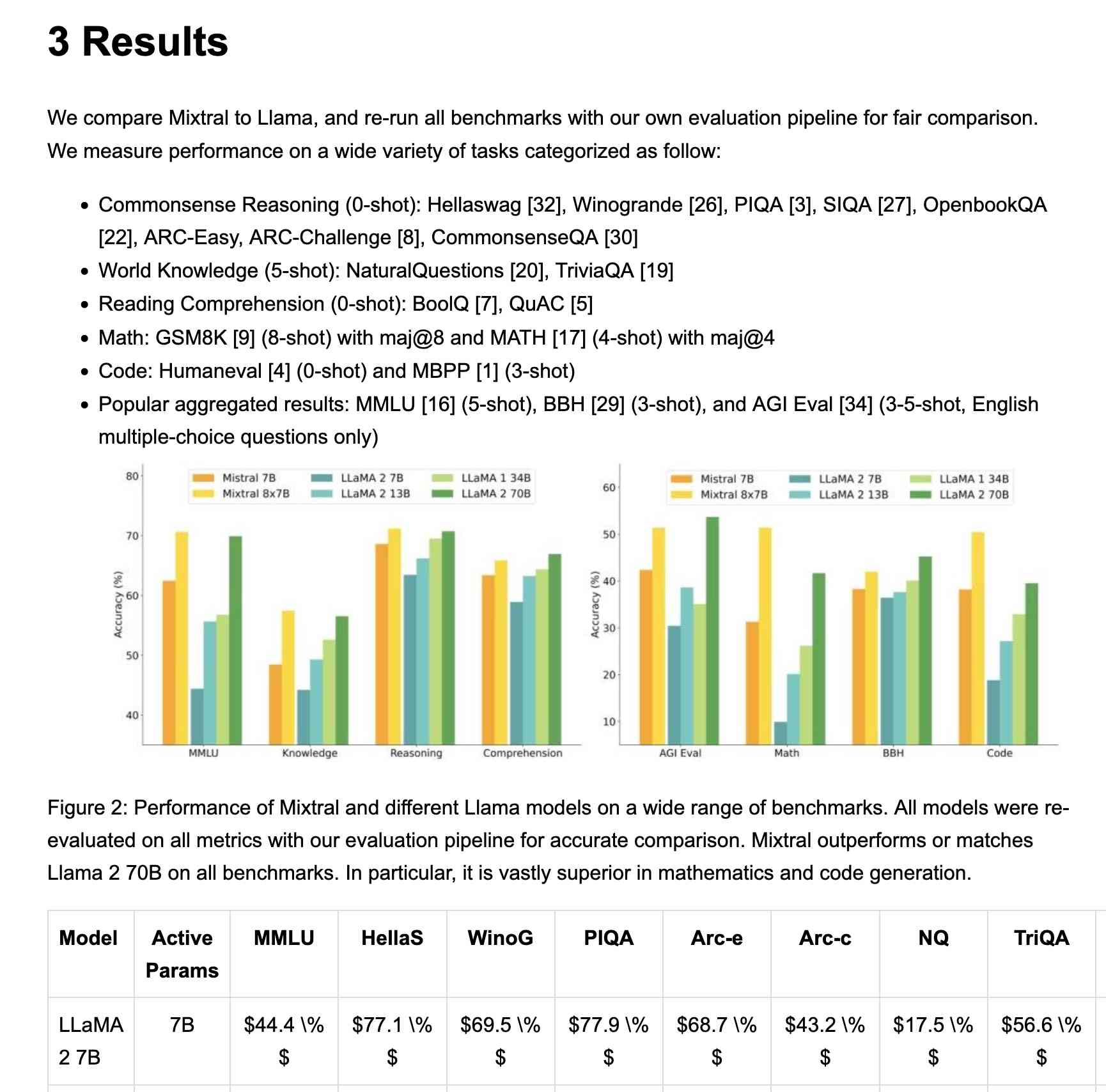
My script renders Markdown tables but I haven't figured out how to render inline Markdown MathML yet. I ran the command a second time and requested Markdown output (the default) like this:
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf > mixtral.md
Here's that Markdown rendered as a Gist - there are a few MathML glitches so clearly the Mistral OCR MathML dialect and the GitHub Formatted Markdown dialect don't quite line up.
My tool can also output raw JSON as an alternative to Markdown or HTML - full details in the documentation.
The Mistral API is priced at roughly 1000 pages per dollar, with a 50% discount for batch usage.
The big question with LLM-based OCR is always how well it copes with accidental instructions in the text (can you safely OCR a document full of prompting examples?) and how well it handles text it can't write.
Mistral's Sophia Yang says it "should be robust" against following instructions in the text, and invited people to try and find counter-examples.
Alexander Doria noted that Mistral OCR can hallucinate text when faced with handwriting that it cannot understand.