41 posts tagged “ollama”
Ollama is a tool for downloading and running Large Language Models.
2025
NVIDIA DGX Spark: great hardware, early days for the ecosystem

NVIDIA sent me a preview unit of their new DGX Spark desktop “AI supercomputer”. I’ve never had hardware to review before! You can consider this my first ever sponsored post if you like, but they did not pay me any cash and aside from an embargo date they did not request (nor would I grant) any editorial input into what I write about the device.
[... 1,846 words]OpenAI’s new open weight (Apache 2) models are really good
The long promised OpenAI open weight models are here, and they are very impressive. They’re available under proper open source licenses—Apache 2.0—and come in two sizes, 120B and 20B.
[... 2,771 words]Ollama’s new app (via) Ollama has been one of my favorite ways to run local models for a while - it makes it really easy to download models, and it's smart about keeping them resident in memory while they are being used and then cleaning them out after they stop receiving traffic.
The one missing feature to date has been an interface: Ollama has been exclusively command-line, which is fine for the CLI literate among us and not much use for everyone else.
They've finally fixed that! The new app's interface is accessible from the existing system tray menu and lets you chat with any of your installed models. Vision models can accept images through the new interface as well.
How to run an LLM on your laptop. I talked to Grace Huckins for this piece from MIT Technology Review on running local models. Apparently she enjoyed my dystopian backup plan!
Simon Willison has a plan for the end of the world. It’s a USB stick, onto which he has loaded a couple of his favorite open-weight LLMs—models that have been shared publicly by their creators and that can, in principle, be downloaded and run with local hardware. If human civilization should ever collapse, Willison plans to use all the knowledge encoded in their billions of parameters for help. “It’s like having a weird, condensed, faulty version of Wikipedia, so I can help reboot society with the help of my little USB stick,” he says.
The article suggests Ollama or LM Studio for laptops, and new-to-me LLM Farm for the iPhone:
My beat-up iPhone 12 was able to run Meta’s Llama 3.2 1B using an app called LLM Farm. It’s not a particularly good model—it very quickly goes off into bizarre tangents and hallucinates constantly—but trying to coax something so chaotic toward usability can be entertaining.
Update 19th July 20205: Evan Hahn compared the size of various offline LLMs to different Wikipedia exports. Full English Wikipedia without images, revision history or talk pages is 13.82GB, smaller than Mistral Small 3.2 (15GB) but larger than Qwen 3 14B and Gemma 3n.
Introducing Gemma 3n: The developer guide. Extremely consequential new open weights model release from Google today:
Multimodal by design: Gemma 3n natively supports image, audio, video, and text inputs and text outputs.
Optimized for on-device: Engineered with a focus on efficiency, Gemma 3n models are available in two sizes based on effective parameters: E2B and E4B. While their raw parameter count is 5B and 8B respectively, architectural innovations allow them to run with a memory footprint comparable to traditional 2B and 4B models, operating with as little as 2GB (E2B) and 3GB (E4B) of memory.
This is very exciting: a 2B and 4B model optimized for end-user devices which accepts text, images and audio as inputs!
Gemma 3n is also the most comprehensive day one launch I've seen for any model: Google partnered with "AMD, Axolotl, Docker, Hugging Face, llama.cpp, LMStudio, MLX, NVIDIA, Ollama, RedHat, SGLang, Unsloth, and vLLM" so there are dozens of ways to try this out right now.
So far I've run two variants on my Mac laptop. Ollama offer a 7.5GB version (full tag gemma3n:e4b-it-q4_K_M0) of the 4B model, which I ran like this:
ollama pull gemma3n
llm install llm-ollama
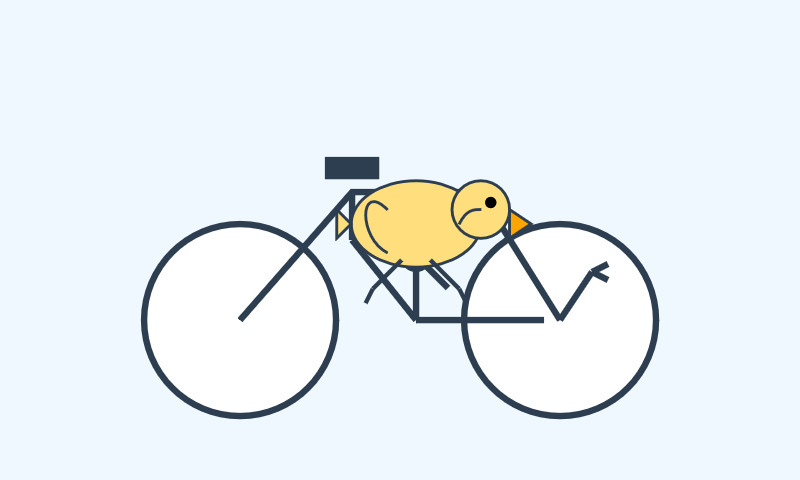
llm -m gemma3n:latest "Generate an SVG of a pelican riding a bicycle"
It drew me this:

The Ollama version doesn't appear to support image or audio input yet.
... but the mlx-vlm version does!
First I tried that on this WAV file like so (using a recipe adapted from Prince Canuma's video):
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 100 \
--temperature 0.7 \
--prompt "Transcribe the following speech segment in English:" \
--audio pelican-joke-request.wav
That downloaded a 15.74 GB bfloat16 version of the model and output the following correct transcription:
Tell me a joke about a pelican.
Then I had it draw me a pelican for good measure:
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 100 \
--temperature 0.7 \
--prompt "Generate an SVG of a pelican riding a bicycle"
I quite like this one:
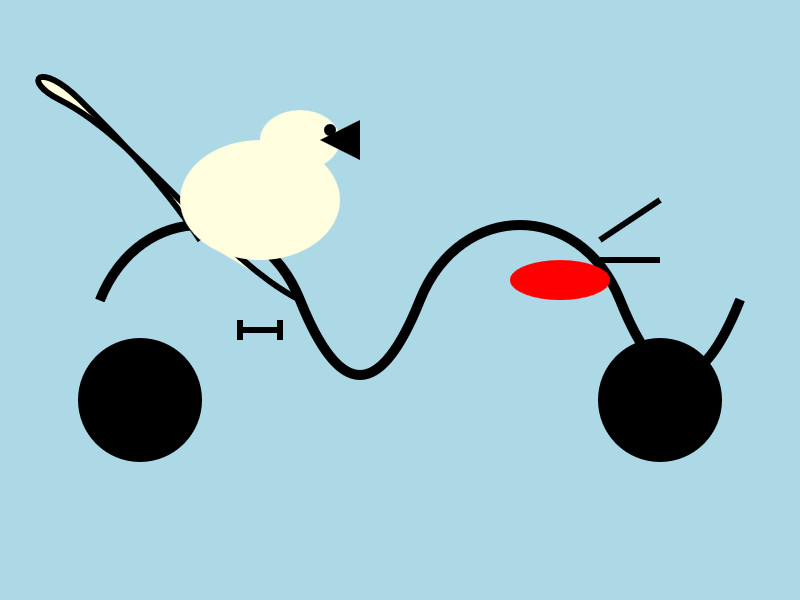
It's interesting to see such a striking visual difference between those 7.5GB and 15GB model quantizations.
Finally, I had it describe the image it had just created:
uv run --with mlx-vlm mlx_vlm.generate \
--model gg-hf-gm/gemma-3n-E4B-it \
--max-tokens 1000 \
--prompt "Describe image" \
--image gemma3n-mlx-vlm.jpg
Here's what I got back - it thought this was a chemical diagram!
The image is a cartoon-style illustration depicting a molecular structure against a light blue background. The structure is composed of several differently colored and shaped elements connected by curved black lines.
Here's a breakdown of the elements:
- Large Black Circles: There are two large, solid black circles, likely representing larger molecules or components.
- Cream-Colored Oval: A prominent cream-colored oval shape is centrally located and connected to other elements. It has a smaller, darker cream-colored sphere attached to its left side.
- Red Oval: A smaller, solid red oval is positioned near one of the black circles and connected to the cream-colored oval.
- Black Lines: These lines act as bonds, connecting the various molecular components. They are curved and dynamic, suggesting movement or interaction.
- Triangular Shape: A small black triangle is attached to the smaller cream-colored sphere.
- Letter "I": The letter "I" appears twice, likely labeling specific parts of the molecule.
The overall impression is of a simplified representation of a biological molecule, possibly a protein or a complex organic compound. The use of different colors helps to distinguish the various components within the structure.
Mistral-Small 3.2. Released on Hugging Face a couple of hours ago, so far there aren't any quantizations to run it on a Mac but I'm sure those will emerge pretty quickly.
This is a minor bump to Mistral Small 3.1, one of my favorite local models. I've been running Small 3.1 via Ollama where it's a 15GB download - these 24 billion parameter models are a great balance between capabilities and not using up all of the available RAM on my laptop. I expect Ollama will add 3.2 imminently.
According to Mistral:
Small-3.2 improves in the following categories:
Interestingly they recommend running it with a temperature of 0.15 - many models recommend a default of 0.7. They also provide a suggested system prompt which includes a note that "Your knowledge base was last updated on 2023-10-01".
It's not currently available via Mistral's API, or through any of the third-party LLM hosting vendors that I've checked, so I've not been able to run a prompt through the model myself yet.
Update: I downloaded one of first GGUF quantizations to show up on Hugging Face, gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF by Gabriel Larson. I ran it using Ollama and llm-ollama like this:
ollama pull hf.co/gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF:Q4_K_M
llm install llm-ollama
llm -m hf.co/gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF:Q4_K_M \
"Generate an SVG of a pelican riding a bicycle"
This one is pretty good for a 15GB model!

Here's the full transcript - it doesn't quite work in the actual image but I was delighted to see the model attempt to add this detail:
<!-- Basket with fish -->
<rect x="250" y="190" width="25" height="15" rx="5" fill="#FFA500"/>
<circle cx="260" cy="200" r="3" fill="#FF4500"/> <!-- Fish -->
Here's what you get if you isolate just that part of the generated SVG:

I had Mistral Small 3.2 describe the full image to me, since it's a vision-LLM:
llm -m hf.co/gabriellarson/Mistral-Small-3.2-24B-Instruct-2506-GGUF:Q4_K_M \
'describe image' \
-a https://static.simonwillison.net/static/2025/mistral-3.2-pelican.jpg
And it gave me the following:
The image depicts a cartoonish illustration of a duck that is being lifted off the ground by a hook. The duck appears to be in mid-air, with its wings spread slightly as if it's surprised or reacting to being picked up. The hook is attached to an arm or a mechanism and seems to be connected to a vehicle below—perhaps a truck or a platform with wheels. The background of the image is light blue, indicating an outdoor setting. Overall, the scene is whimsical and playful, possibly suggesting a humorous or unusual situation where the duck is being transported in this manner.
Update 2: It's now available as an official Ollama model:
ollama pull mistral-small3.2
LM Studio has a community quantization too: lmstudio-community/Mistral-Small-3.2-24B-Instruct-2506-GGUF.
Magistral — the first reasoning model by Mistral AI. Mistral's first reasoning model is out today, in two sizes. There's a 24B Apache 2 licensed open-weights model called Magistral Small (actually Magistral-Small-2506), and a larger API-only model called Magistral Medium.
Magistral Small is available as mistralai/Magistral-Small-2506 on Hugging Face. From that model card:
Context Window: A 128k context window, but performance might degrade past 40k. Hence we recommend setting the maximum model length to 40k.
Mistral also released an official GGUF version, Magistral-Small-2506_gguf, which I ran successfully using Ollama like this:
ollama pull hf.co/mistralai/Magistral-Small-2506_gguf:Q8_0
That fetched a 25GB file. I ran prompts using a chat session with llm-ollama like this:
llm chat -m hf.co/mistralai/Magistral-Small-2506_gguf:Q8_0
Here's what I got for "Generate an SVG of a pelican riding a bicycle" (transcript here):

It's disappointing that the GGUF doesn't support function calling yet - hopefully a community variant can add that, it's one of the best ways I know of to unlock the potential of these reasoning models.
I just noticed that Ollama have their own Magistral model too, which can be accessed using:
ollama pull magistral:latest
That gets you a 14GB q4_K_M quantization - other options can be found in the full list of Ollama magistral tags.
One thing that caught my eye in the Magistral announcement:
Legal, finance, healthcare, and government professionals get traceable reasoning that meets compliance requirements. Every conclusion can be traced back through its logical steps, providing auditability for high-stakes environments with domain-specialized AI.
I guess this means the reasoning traces are fully visible and not redacted in any way - interesting to see Mistral trying to turn that into a feature that's attractive to the business clients they are most interested in appealing to.
Also from that announcement:
Our early tests indicated that Magistral is an excellent creative companion. We highly recommend it for creative writing and storytelling, with the model capable of producing coherent or — if needed — delightfully eccentric copy.
I haven't seen a reasoning model promoted for creative writing in this way before.
You can try out Magistral Medium by selecting the new "Thinking" option in Mistral's Le Chat.
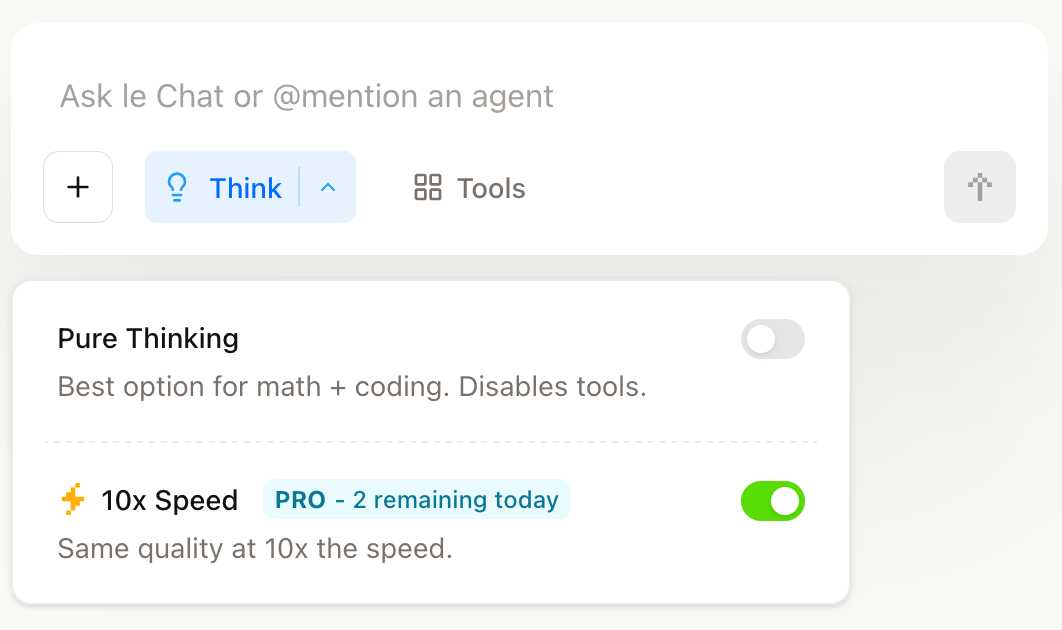
They have options for "Pure Thinking" and a separate option for "10x speed", which runs Magistral Medium at 10x the speed using Cerebras.
The new models are also available through the Mistral API. You can access them by installing llm-mistral and running llm mistral refresh to refresh the list of available models, then:
llm -m mistral/magistral-medium-latest \
'Generate an SVG of a pelican riding a bicycle'

Here's that transcript. At 13 input and 1,236 output tokens that cost me 0.62 cents - just over half a cent.
deepseek-ai/DeepSeek-R1-0528. Sadly the trend for terrible naming of models has infested the Chinese AI labs as well.
DeepSeek-R1-0528 is a brand new and much improved open weights reasoning model from DeepSeek, a major step up from the DeepSeek R1 they released back in January.
In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by [...] Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro. [...]
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
The new R1 comes in two sizes: a 685B model called deepseek-ai/DeepSeek-R1-0528 (the previous R1 was 671B) and an 8B variant distilled from Qwen 3 called deepseek-ai/DeepSeek-R1-0528-Qwen3-8B.
The January release of R1 had a much larger collection of distilled models: four based on Qwen 2.5 (14B, 32B, Math 1.5B and Math 7B) and 2 based on Llama 3 (Llama-3.1 8B and Llama 3.3 70B Instruct).
No Llama model at all this time. I wonder if that's because Qwen 3 is really good and Apache 2 licensed, while Llama continues to stick with their janky license terms.
Further adding to the confusion, Ollama have mixed the two new models into their existing deepseek-r1 label. Last week running ollama pull deepseek-r1:8B from Ollama would get you DeepSeek-R1-Distill-Llama-8B (Internet Archive link), today that same command gets you DeepSeek-R1-0528-Qwen3-8B, a completely different base model.
If this bothers you as much as it bothers me, thankfully you can use the more explicit tag deepseek-r1:8b-0528-qwen3-q8_0.
Update: This is a great illustration of how confusing these names are! Ollama's deepseek-r1:8B alias actually points to deepseek-r1:8b-0528-qwen3-q4_K_M, a 5.2GB model. I pulled the larger q8_0 one.
I ran it like this:
ollama pull deepseek-r1:8b-0528-qwen3-q8_0
It fetched 8.9GB of model weights, then I had it draw me a pelican.
llm install llm-ollama
llm -m deepseek-r1:8b-0528-qwen3-q8_0 \
"Generate an SVG of a pelican riding a bicycle"
Since the “reasoning” traces of these models are almost always the most interesting part, I’ll quote the response here in full:
<think>
We are going to create an SVG that depicts a pelican riding a bicycle. Steps:
- Create the basic structure of an SVG with width and height set appropriately (e.g., 400x200).
- Draw a pelican: We'll break it down into parts - body, beak, eye, feet, wings, etc.
- Draw a bicycle: We can represent it as two circles for wheels, a rectangle for the frame, and some other details.
Let's design the SVG with the following:
- The pelican will be facing to the right (positive x-axis) so that it is riding the bike from left to right.
- The bicycle will have two wheels and a simple frame in front of the pelican.
We'll use absolute positioning for each part. Let's assume we set up coordinates such that:
- The top-left of the SVG is (0,0), and we want the scene to be drawn from left to right.
- The pelican will be positioned at (50, 120) with a body length of about 30 units.
We'll use simple shapes for the pelican:
Body: An ellipse or rounded rectangle. Let's do an ellipse for the body. Beak: A triangle pointing to the right. Head: Another ellipse but smaller and positioned in front of the body. Wings: Two triangles (one above each other, one slightly behind) that are upside down.
Bicycle:
- Wheels: two circles at fixed positions relative to the frame.
- Frame: a rectangle with some details for handlebars and seat.
Since this is a fun illustration, we'll keep it simple but recognizable.
Let's code accordingly.
</think>
Here’s an SVG of a pelican riding a bicycle. This example uses basic shapes to create a stylized version:<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 400 200"> <!-- Pelican body --> <ellipse cx="150" cy="150" rx="80" ry="60" fill="#FFD700"/> <!-- Pelican head (larger for comedic effect) --> <circle cx="90" cy="120" r="45" fill="#FFA3CE"/> <!-- Pelican beak --> <polygon points="80,110 60,120 80,130 70,140 60,150" fill="#FFC233"/> <!-- Pelican eye --> <circle cx="95" cy="115" r="3" fill="#fff"/> <!-- Bicycle wheels --> <ellipse cx="380" cy="140" rx="25" ry="60" transform="rotate(90 380 140)" fill="black"/> <ellipse cx="380" cy="70" rx="25" ry="60" transform="rotate(90 380 70)" fill="black"/> <!-- Bicycle frame --> <path d="M 15,40 L 15,140 H 370 L 370,140 V 40 Z" stroke="gray" stroke-width="6" fill="none"/> <!-- Handlebars and seat (stylized) --> <path d="M 280,40 C 290,35 300,30 310,40 C 320,50 330,60 310,70 L 310,70 Q 290,50 280,40" fill="none" stroke="gray"/> <!-- Pedals --> <circle cx="340" cy="70" r="15" fill="#3366CC"/> <polygon points="340,65 330,45 350,45" fill="#F29E3D"/> <circle cx="340" cy="140" r="15" fill="#3366CC"/> <polygon points="340,135 330,115 350,115" fill="#F29E3D"/> <!-- Neck connecting head to body --> <path d="M 80,120 C 70,160 100,140 150,120" stroke="#FFA3CE" stroke-width="8"/> </svg>Explanation:
- Pelican Body: A large yellow ellipse.
- Head: A pink circle with a prominent beak (yellow-orange triangle).
- Bicycle:
- Wheels are black ellipses rotated vertically to simulate spokes.
- The frame is a gray rectangle extending from the pelican’s back to the right side of the SVG.
- Handlebars and seat are simplified curves in gray.
This creates a comical scene with the pelican riding forward. You can adjust colors, sizes, or positions by modifying
cx,cy,rx,ryattributes and fill/stroke values.
Love the thought process, and the explanation! The actual rendered SVG does leave a lot to be desired though:
To be fair, this is just using the ~8GB Qwen3 Q8_0 model on my laptop. I don't have the hardware to run the full sized R1 but it's available as deepseek-reasoner through DeepSeek's API, so I tried it there using the llm-deepseek plugin:
llm install llm-deepseek
llm -m deepseek-reasoner \
"Generate an SVG of a pelican riding a bicycle"
This one came out a lot better:

Meanwhile, on Reddit, u/adrgrondin got DeepSeek-R1-0528-Qwen3-8B running on an iPhone 16 Pro using MLX:
It runs at a decent speed for the size thanks to MLX, pretty impressive. But not really usable in my opinion, the model is thinking for too long, and the phone gets really hot.
Large Language Models can run tools in your terminal with LLM 0.26
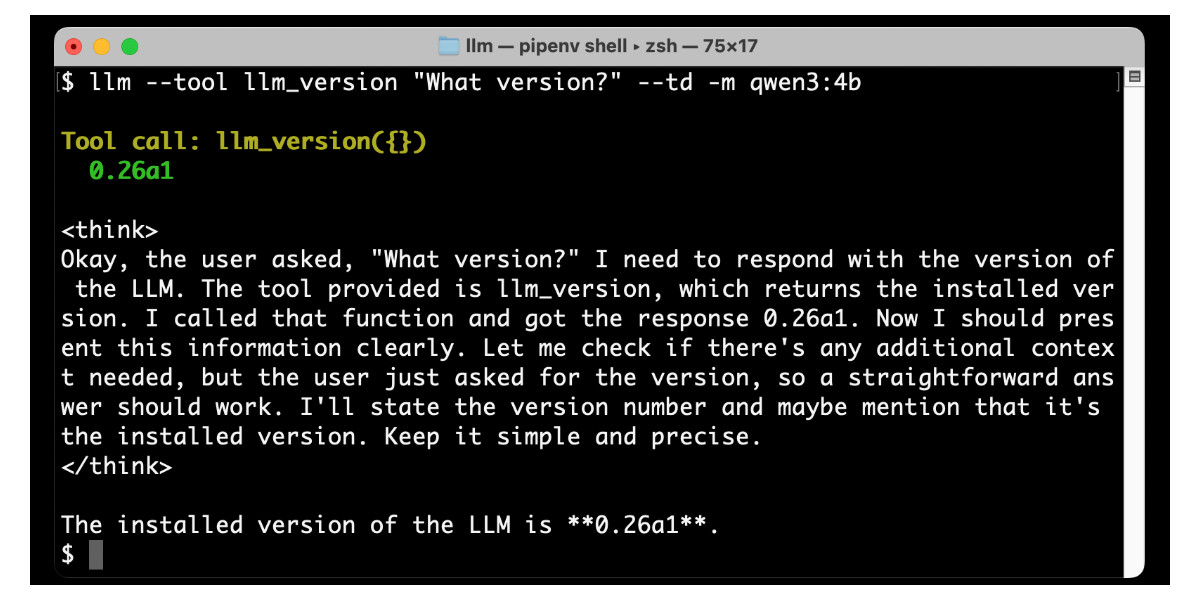
LLM 0.26 is out with the biggest new feature since I started the project: support for tools. You can now use the LLM CLI tool—and Python library—to grant LLMs from OpenAI, Anthropic, Gemini and local models from Ollama with access to any tool that you can represent as a Python function.
[... 2,799 words]Devstral. New Apache 2.0 licensed LLM release from Mistral, this time specifically trained for code.
Devstral achieves a score of 46.8% on SWE-Bench Verified, outperforming prior open-source SoTA models by more than 6% points. When evaluated under the same test scaffold (OpenHands, provided by All Hands AI 🙌), Devstral exceeds far larger models such as Deepseek-V3-0324 (671B) and Qwen3 232B-A22B.
I'm always suspicious of small models like this that claim great benchmarks against much larger rivals, but there's a Devstral model that is just 14GB on Ollama to it's quite easy to try out for yourself.
I fetched it like this:
ollama pull devstral
Then ran it in a llm chat session with llm-ollama like this:
llm install llm-ollama
llm chat -m devstral
Initial impressions: I think this one is pretty good! Here's a full transcript where I had it write Python code to fetch a CSV file from a URL and import it into a SQLite database, creating the table with the necessary columns. Honestly I need to retire that challenge, it's been a while since a model failed at it, but it's still interesting to see how it handles follow-up prompts to demand things like asyncio or a different HTTP client library.
It's also available through Mistral's API. llm-mistral 0.13 configures the devstral-small alias for it:
llm install -U llm-mistral
llm keys set mistral
# paste key here
llm -m devstral-small 'HTML+JS for a large text countdown app from 5m'
qwen2.5vl in Ollama. Ollama announced a complete overhaul of their vision support the other day. Here's the first new model they've shipped since then - a packaged version of Qwen 2.5 VL which was first released on January 26th 2025. Here are my notes from that release.
I upgraded Ollama (it auto-updates so I just had to restart it from the tray icon) and ran this:
ollama pull qwen2.5vl
This downloaded a 6GB model file. I tried it out against my photo of Cleo rolling on the beach:
{kind=link}
llm -a https://static.simonwillison.net/static/2025/cleo-sand.jpg \
'describe this image' -m qwen2.5vl
And got a pretty good result:
The image shows a dog lying on its back on a sandy beach. The dog appears to be a medium to large breed with a dark coat, possibly black or dark brown. It is wearing a red collar or harness around its chest. The dog's legs are spread out, and its belly is exposed, suggesting it might be rolling around or playing in the sand. The sand is light-colored and appears to be dry, with some small footprints and marks visible around the dog. The lighting in the image suggests it is taken during the daytime, with the sun casting a shadow of the dog to the left side of the image. The overall scene gives a relaxed and playful impression, typical of a dog enjoying time outdoors on a beach.
Qwen 2.5 VL has a strong reputation for OCR, so I tried it on my poster:
llm -a https://static.simonwillison.net/static/2025/poster.jpg \
'convert to markdown' -m qwen2.5vl
The result that came back:
It looks like the image you provided is a jumbled and distorted text, making it difficult to interpret. If you have a specific question or need help with a particular topic, please feel free to ask, and I'll do my best to assist you!
I'm not sure what went wrong here. My best guess is that the maximum resolution the model can handle is too small to make out the text, or maybe Ollama resized the image to the point of illegibility before handing it to the model?
Update: I think this may be a bug relating to URL handling in LLM/llm-ollama. I tried downloading the file first:
wget https://static.simonwillison.net/static/2025/poster.jpg
llm -m qwen2.5vl 'extract text' -a poster.jpg
This time it did a lot better. The results weren't perfect though - it ended up stuck in a loop outputting the same code example dozens of times.
I tried with a different prompt - "extract text" - and it got confused by the three column layout, misread Datasette as "Datasetette" and missed some of the text. Here's that result.
These experiments used qwen2.5vl:7b (6GB) - I expect the results would be better with the larger qwen2.5vl:32b (21GB) and qwen2.5vl:72b (71GB) models.
Fred Jonsson reported a better result using the MLX model via LM studio (~9GB model running in 8bit - I think that's mlx-community/Qwen2.5-VL-7B-Instruct-8bit). His full output is here - looks almost exactly right to me.
Saying “hi” to Microsoft’s Phi-4-reasoning
Microsoft released a new sub-family of models a few days ago: Phi-4 reasoning. They introduced them in this blog post celebrating a year since the release of Phi-3:
[... 1,498 words]Qwen 3 offers a case study in how to effectively release a model
Alibaba’s Qwen team released the hotly anticipated Qwen 3 model family today. The Qwen models are already some of the best open weight models—Apache 2.0 licensed and with a variety of different capabilities (including vision and audio input/output).
[... 1,462 words]Gemma 3 QAT Models. Interesting release from Google, as a follow-up to Gemma 3 from last month:
To make Gemma 3 even more accessible, we are announcing new versions optimized with Quantization-Aware Training (QAT) that dramatically reduces memory requirements while maintaining high quality. This enables you to run powerful models like Gemma 3 27B locally on consumer-grade GPUs like the NVIDIA RTX 3090.
I wasn't previously aware of Quantization-Aware Training but it turns out to be quite an established pattern now, supported in both Tensorflow and PyTorch.
Google report model size drops from BF16 to int4 for the following models:
- Gemma 3 27B: 54GB to 14.1GB
- Gemma 3 12B: 24GB to 6.6GB
- Gemma 3 4B: 8GB to 2.6GB
- Gemma 3 1B: 2GB to 0.5GB
They partnered with Ollama, LM Studio, MLX (here's their collection) and llama.cpp for this release - I'd love to see more AI labs following their example.
The Ollama model version picker currently hides them behind "View all" option, so here are the direct links:
- gemma3:1b-it-qat - 1GB
- gemma3:4b-it-qat - 4GB
- gemma3:12b-it-qat - 8.9GB
- gemma3:27b-it-qat - 18GB
I fetched that largest model with:
ollama pull gemma3:27b-it-qat
And now I'm trying it out with llm-ollama:
llm -m gemma3:27b-it-qat "impress me with some physics"
I got a pretty great response!
Update: Having spent a while putting it through its paces via Open WebUI and Tailscale to access my laptop from my phone I think this may be my new favorite general-purpose local model. Ollama appears to use 22GB of RAM while the model is running, which leaves plenty on my 64GB machine for other applications.
I've also tried it via llm-mlx like this (downloading 16GB):
llm install llm-mlx
llm mlx download-model mlx-community/gemma-3-27b-it-qat-4bit
llm chat -m mlx-community/gemma-3-27b-it-qat-4bit
It feels a little faster with MLX and uses 15GB of memory according to Activity Monitor.
MCP Run Python (via) Pydantic AI's MCP server for running LLM-generated Python code in a sandbox. They ended up using a trick I explored two years ago: using a Deno process to run Pyodide in a WebAssembly sandbox.
Here's a bit of a wild trick: since Deno loads code on-demand from JSR, and uv run can install Python dependencies on demand via the --with option... here's a one-liner you can paste into a macOS shell (provided you have Deno and uv installed already) which will run the example from their README - calculating the number of days between two dates in the most complex way imaginable:
ANTHROPIC_API_KEY="sk-ant-..." \ uv run --with pydantic-ai python -c ' import asyncio from pydantic_ai import Agent from pydantic_ai.mcp import MCPServerStdio server = MCPServerStdio( "deno", args=[ "run", "-N", "-R=node_modules", "-W=node_modules", "--node-modules-dir=auto", "jsr:@pydantic/mcp-run-python", "stdio", ], ) agent = Agent("claude-3-5-haiku-latest", mcp_servers=[server]) async def main(): async with agent.run_mcp_servers(): result = await agent.run("How many days between 2000-01-01 and 2025-03-18?") print(result.output) asyncio.run(main())'
I ran that just now and got:
The number of days between January 1st, 2000 and March 18th, 2025 is 9,208 days.
I thoroughly enjoy how tools like uv and Deno enable throwing together shell one-liner demos like this one.
Here's an extended version of this example which adds pretty-printed logging of the messages exchanged with the LLM to illustrate exactly what happened. The most important piece is this tool call where Claude 3.5 Haiku asks for Python code to be executed my the MCP server:
ToolCallPart( tool_name='run_python_code', args={ 'python_code': ( 'from datetime import date\n' '\n' 'date1 = date(2000, 1, 1)\n' 'date2 = date(2025, 3, 18)\n' '\n' 'days_between = (date2 - date1).days\n' 'print(f"Number of days between {date1} and {date2}: {days_between}")' ), }, tool_call_id='toolu_01TXXnQ5mC4ry42DrM1jPaza', part_kind='tool-call', )
I also managed to run it against Mistral Small 3.1 (15GB) running locally using Ollama (I had to add "Use your python tool" to the prompt to get it to work):
ollama pull mistral-small3.1:24b uv run --with devtools --with pydantic-ai python -c ' import asyncio from devtools import pprint from pydantic_ai import Agent, capture_run_messages from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider from pydantic_ai.mcp import MCPServerStdio server = MCPServerStdio( "deno", args=[ "run", "-N", "-R=node_modules", "-W=node_modules", "--node-modules-dir=auto", "jsr:@pydantic/mcp-run-python", "stdio", ], ) agent = Agent( OpenAIModel( model_name="mistral-small3.1:latest", provider=OpenAIProvider(base_url="http://localhost:11434/v1"), ), mcp_servers=[server], ) async def main(): with capture_run_messages() as messages: async with agent.run_mcp_servers(): result = await agent.run("How many days between 2000-01-01 and 2025-03-18? Use your python tool.") pprint(messages) print(result.output) asyncio.run(main())'
Here's the full output including the debug logs.
An LLM Query Understanding Service (via) Doug Turnbull recently wrote about how all search is structured now:
Many times, even a small open source LLM will be able to turn a search query into reasonable structure at relatively low cost.
In this follow-up tutorial he demonstrates Qwen 2-7B running in a GPU-enabled Google Kubernetes Engine container to turn user search queries like "red loveseat" into structured filters like {"item_type": "loveseat", "color": "red"}.
Here's the prompt he uses.
Respond with a single line of JSON:
{"item_type": "sofa", "material": "wood", "color": "red"}
Omit any other information. Do not include any
other text in your response. Omit a value if the
user did not specify it. For example, if the user
said "red sofa", you would respond with:
{"item_type": "sofa", "color": "red"}
Here is the search query: blue armchair
Out of curiosity, I tried running his prompt against some other models using LLM:
gemini-1.5-flash-8b, the cheapest of the Gemini models, handled it well and cost $0.000011 - or 0.0011 cents.llama3.2:3bworked too - that's a very small 2GB model which I ran using Ollama.deepseek-r1:1.5b- a tiny 1.1GB model, again via Ollama, amusingly failed by interpreting "red loveseat" as{"item_type": "sofa", "material": null, "color": "red"}after thinking very hard about the problem!
Political Email Extraction Leaderboard (via) Derek Willis collects "political fundraising emails from just about every committee" - 3,000-12,000 a month - and has created an LLM benchmark from 1,000 of them that he collected last November.
He explains the leaderboard in this blog post. The goal is to have an LLM correctly identify the the committee name from the disclaimer text included in the email.
Here's the code he uses to run prompts using Ollama. It uses this system prompt:
Produce a JSON object with the following keys: 'committee', which is the name of the committee in the disclaimer that begins with Paid for by but does not include 'Paid for by', the committee address or the treasurer name. If no committee is present, the value of 'committee' should be None. Also add a key called 'sender', which is the name of the person, if any, mentioned as the author of the email. If there is no person named, the value is None. Do not include any other text, no yapping.
Gemini 2.5 Pro tops the leaderboard at the moment with 95.40%, but the new Mistral Small 3.1 manages 5th place with 85.70%, pretty good for a local model!
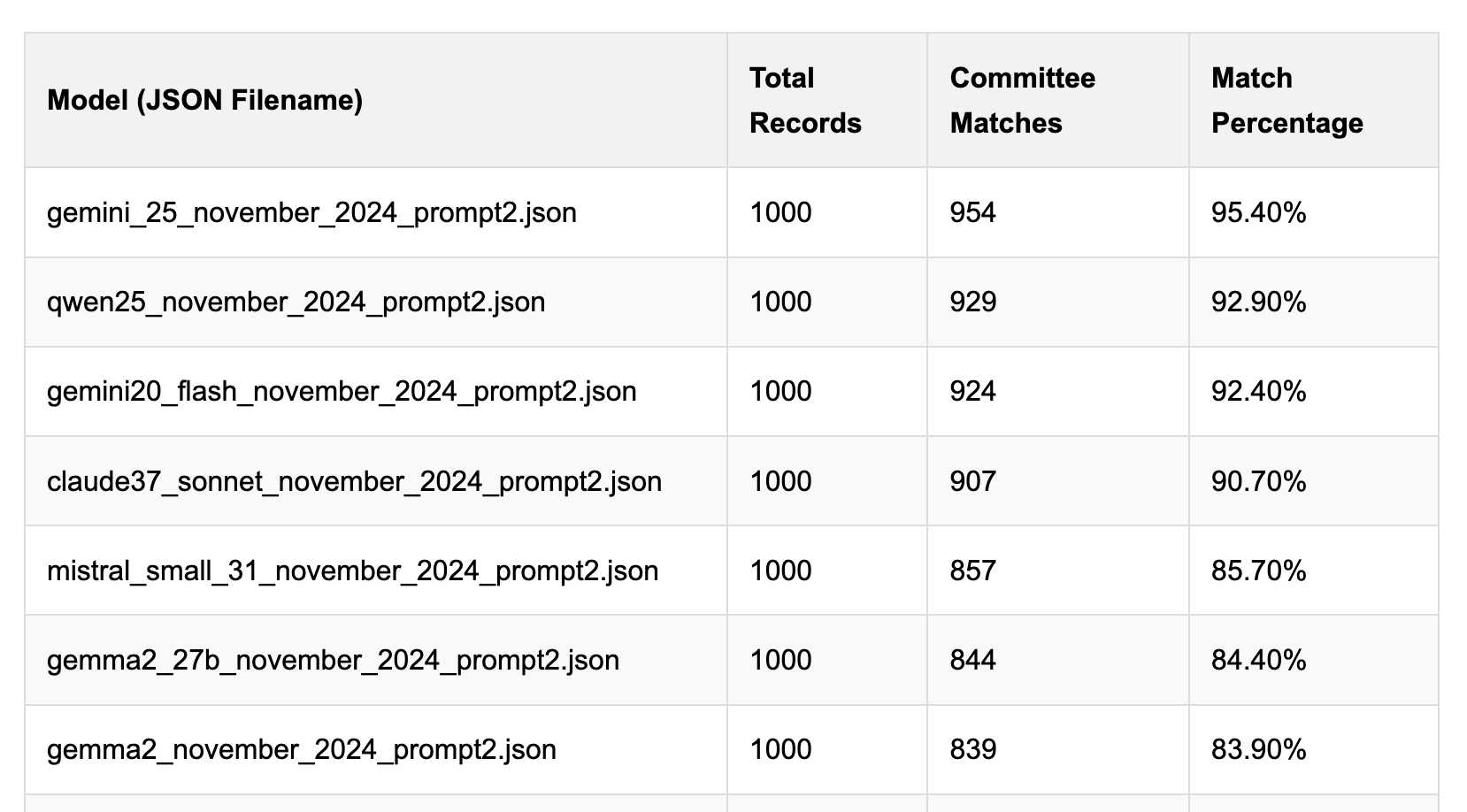
I said we need our own evals in my talk at the NICAR Data Journalism conference last month, without realizing Derek has been running one since January.
{kind=link}
Mistral Small 3.1 on Ollama. Mistral Small 3.1 (previously) is now available through Ollama, providing an easy way to run this multi-modal (vision) model on a Mac (and other platforms, though I haven't tried those myself).
I had to upgrade Ollama to the most recent version to get it to work - prior to that I got a Error: unable to load model message. Upgrades can be accessed through the Ollama macOS system tray icon.
I fetched the 15GB model by running:
ollama pull mistral-small3.1
Then used llm-ollama to run prompts through it, including one to describe this image:
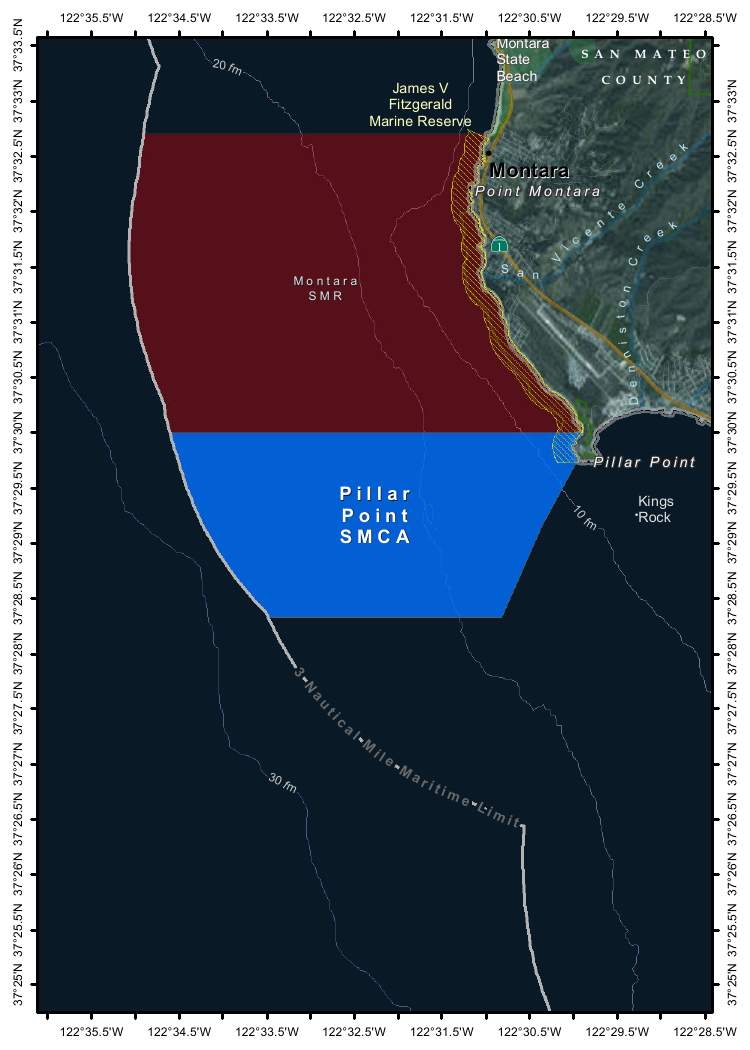{kind=link}
llm install llm-ollama
llm -m mistral-small3.1 'describe this image' -a https://static.simonwillison.net/static/2025/Mpaboundrycdfw-1.png
Here's the output. It's good, though not quite as impressive as the description I got from the slightly larger Qwen2.5-VL-32B.
I also tried it on a scanned (private) PDF of hand-written text with very good results, though it did misread one of the hand-written numbers.
simonw/ollama-models-atom-feed. I setup a GitHub Actions + GitHub Pages Atom feed of scraped recent models data from the Ollama latest models page - Ollama remains one of the easiest ways to run models on a laptop so a new model release from them is worth hearing about.
I built the scraper by pasting example HTML into Claude and asking for a Python script to convert it to Atom - here's the script we wrote together.
Update 25th March 2025: The first version of this included all 160+ models in a single feed. I've upgraded the script to output two feeds - the original atom.xml one and a new atom-recent-20.xml feed containing just the most recent 20 items.
I modified the script using Google's new Gemini 2.5 Pro model, like this:
cat to_atom.py | llm -m gemini-2.5-pro-exp-03-25 \
-s 'rewrite this script so that instead of outputting Atom to stdout it saves two files, one called atom.xml with everything and another called atom-recent-20.xml with just the most recent 20 items - remove the output option entirely'
Here's the full transcript.
Notes on Google’s Gemma 3
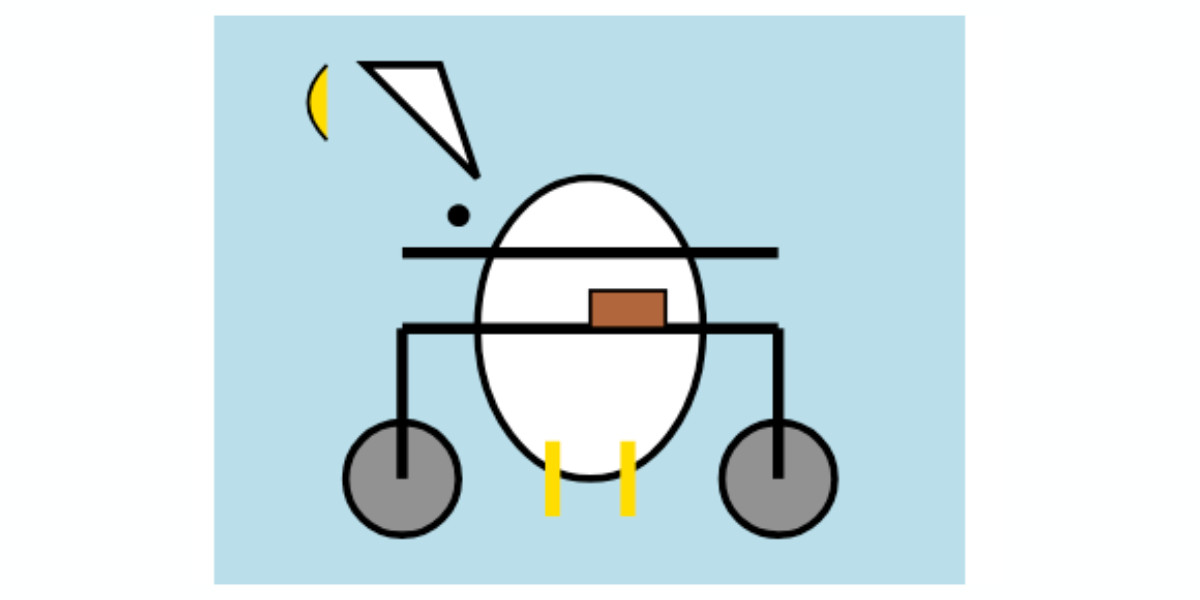
Google’s Gemma team released an impressive new model today (under their not-open-source Gemma license). Gemma 3 comes in four sizes—1B, 4B, 12B, and 27B—and while 1B is text-only the larger three models are all multi-modal for vision:
[... 804 words]QwQ-32B: Embracing the Power of Reinforcement Learning (via) New Apache 2 licensed reasoning model from Qwen:
We are excited to introduce QwQ-32B, a model with 32 billion parameters that achieves performance comparable to DeepSeek-R1, which boasts 671 billion parameters (with 37 billion activated). This remarkable outcome underscores the effectiveness of RL when applied to robust foundation models pretrained on extensive world knowledge.
I had a lot of fun trying out their previous QwQ reasoning model last November. I demonstrated this new QwQ in my talk at NICAR about recent LLM developments. Here's the example I ran.
{kind=link}
LM Studio just released GGUFs ranging in size from 17.2 to 34.8 GB. MLX have compatible weights published in 3bit, 4bit, 6bit and 8bit. Ollama has the new qwq too - it looks like they've renamed the previous November release qwq:32b-preview.
llm-ollama 0.9.0.
This release of the llm-ollama plugin adds support for schemas, thanks to a PR by Adam Compton.
Ollama provides very robust support for this pattern thanks to their structured outputs feature, which works across all of the models that they support by intercepting the logic that outputs the next token and restricting it to only tokens that would be valid in the context of the provided schema.
With Ollama and llm-ollama installed you can run even run structured schemas against vision prompts for local models. Here's one against Ollama's llama3.2-vision:
llm -m llama3.2-vision:latest \
'describe images' \
--schema 'species,description,count int' \
-a https://static.simonwillison.net/static/2025/two-pelicans.jpg
I got back this:
{
"species": "Pelicans",
"description": "The image features a striking brown pelican with its distinctive orange beak, characterized by its large size and impressive wingspan.",
"count": 1
}
(Actually a bit disappointing, as there are two pelicans and their beaks are brown.)
{kind=link}
llm-mistral 0.11. I added schema support to this plugin which adds support for the Mistral API to LLM. Release notes:
Schemas now work with OpenAI, Anthropic, Gemini and Mistral hosted models, plus self-hosted models via Ollama and llm-ollama.
Structured data extraction from unstructured content using LLM schemas
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]S1: The $6 R1 Competitor? Tim Kellogg shares his notes on a new paper, s1: Simple test-time scaling, which describes an inference-scaling model fine-tuned on top of Qwen2.5-32B-Instruct for just $6 - the cost for 26 minutes on 16 NVIDIA H100 GPUs.
Tim highlight the most exciting result:
After sifting their dataset of 56K examples down to just the best 1K, they found that the core 1K is all that's needed to achieve o1-preview performance on a 32B model.
The paper describes a technique called "Budget forcing":
To enforce a minimum, we suppress the generation of the end-of-thinking token delimiter and optionally append the string “Wait” to the model’s current reasoning trace to encourage the model to reflect on its current generation
That's the same trick Theia Vogel described a few weeks ago.
Here's the s1-32B model on Hugging Face. I found a GGUF version of it at brittlewis12/s1-32B-GGUF, which I ran using Ollama like so:
ollama run hf.co/brittlewis12/s1-32B-GGUF:Q4_0
I also found those 1,000 samples on Hugging Face in the simplescaling/s1K data repository there.
I used DuckDB to convert the parquet file to CSV (and turn one VARCHAR[] column into JSON):
COPY (
SELECT
solution,
question,
cot_type,
source_type,
metadata,
cot,
json_array(thinking_trajectories) as thinking_trajectories,
attempt
FROM 's1k-00001.parquet'
) TO 'output.csv' (HEADER, DELIMITER ',');
Then I loaded that CSV into sqlite-utils so I could use the convert command to turn a Python data structure into JSON using json.dumps() and eval():
# Load into SQLite
sqlite-utils insert s1k.db s1k output.csv --csv
# Fix that column
sqlite-utils convert s1k.db s1u metadata 'json.dumps(eval(value))' --import json
# Dump that back out to CSV
sqlite-utils rows s1k.db s1k --csv > s1k.csv
Here's that CSV in a Gist, which means I can load it into Datasette Lite.
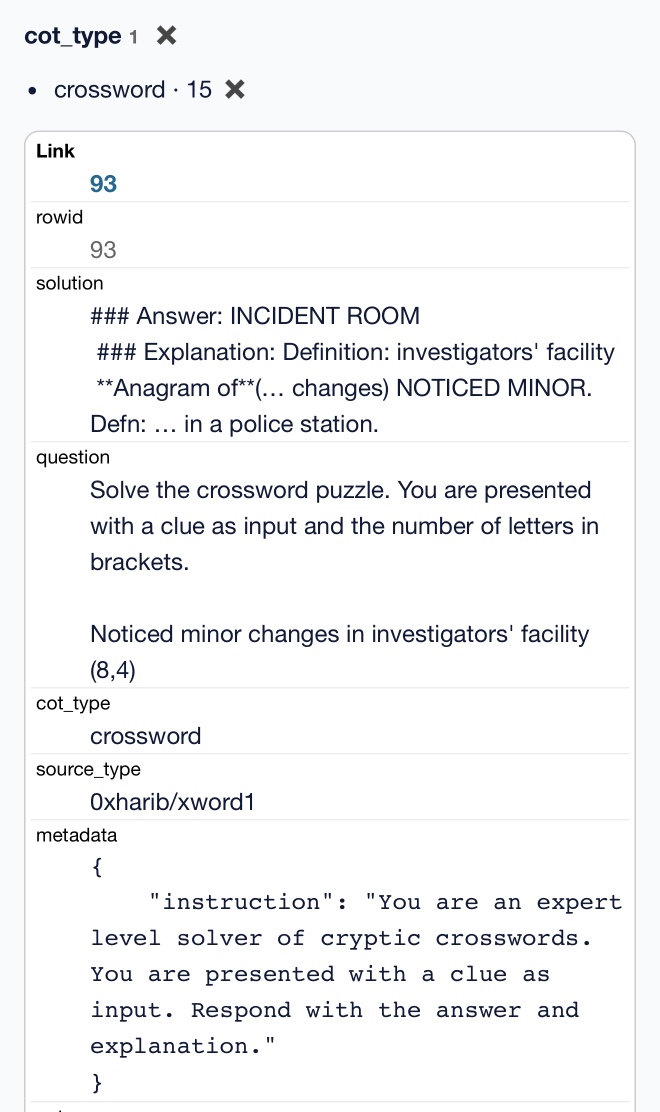
It really is a tiny amount of training data. It's mostly math and science, but there are also 15 cryptic crossword examples.
Mistral Small 3 (via) First model release of 2025 for French AI lab Mistral, who describe Mistral Small 3 as "a latency-optimized 24B-parameter model released under the Apache 2.0 license."
More notably, they claim the following:
Mistral Small 3 is competitive with larger models such as Llama 3.3 70B or Qwen 32B, and is an excellent open replacement for opaque proprietary models like GPT4o-mini. Mistral Small 3 is on par with Llama 3.3 70B instruct, while being more than 3x faster on the same hardware.
Llama 3.3 70B and Qwen 32B are two of my favourite models to run on my laptop - that ~20GB size turns out to be a great trade-off between memory usage and model utility. It's exciting to see a new entrant into that weight class.
The license is important: previous Mistral Small models used their Mistral Research License, which prohibited commercial deployments unless you negotiate a commercial license with them. They appear to be moving away from that, at least for their core models:
We’re renewing our commitment to using Apache 2.0 license for our general purpose models, as we progressively move away from MRL-licensed models. As with Mistral Small 3, model weights will be available to download and deploy locally, and free to modify and use in any capacity. […] Enterprises and developers that need specialized capabilities (increased speed and context, domain specific knowledge, task-specific models like code completion) can count on additional commercial models complementing what we contribute to the community.
Despite being called Mistral Small 3, this appears to be the fourth release of a model under that label. The Mistral API calls this one mistral-small-2501 - previous model IDs were mistral-small-2312, mistral-small-2402 and mistral-small-2409.
I've updated the llm-mistral plugin for talking directly to Mistral's La Plateforme API:
llm install -U llm-mistral
llm keys set mistral
# Paste key here
llm -m mistral/mistral-small-latest "tell me a joke about a badger and a puffin"
Sure, here's a light-hearted joke for you:
Why did the badger bring a puffin to the party?
Because he heard puffins make great party 'Puffins'!
(That's a play on the word "puffins" and the phrase "party people.")
API pricing is $0.10/million tokens of input, $0.30/million tokens of output - half the price of the previous Mistral Small API model ($0.20/$0.60). for comparison, GPT-4o mini is $0.15/$0.60.
Mistral also ensured that the new model was available on Ollama in time for their release announcement.
You can pull the model like this (fetching 14GB):
ollama run mistral-small:24b
The llm-ollama plugin will then let you prompt it like so:
llm install llm-ollama
llm -m mistral-small:24b "say hi"
Qwen2.5-1M: Deploy Your Own Qwen with Context Length up to 1M Tokens (via) Very significant new release from Alibaba's Qwen team. Their openly licensed (sometimes Apache 2, sometimes Qwen license, I've had trouble keeping up) Qwen 2.5 LLM previously had an input token limit of 128,000 tokens. This new model increases that to 1 million, using a new technique called Dual Chunk Attention, first described in this paper from February 2024.
They've released two models on Hugging Face: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, both requiring CUDA and both under an Apache 2.0 license.
You'll need a lot of VRAM to run them at their full capacity:
VRAM Requirement for processing 1 million-token sequences:
- Qwen2.5-7B-Instruct-1M: At least 120GB VRAM (total across GPUs).
- Qwen2.5-14B-Instruct-1M: At least 320GB VRAM (total across GPUs).
If your GPUs do not have sufficient VRAM, you can still use Qwen2.5-1M models for shorter tasks.
Qwen recommend using their custom fork of vLLM to serve the models:
You can also use the previous framework that supports Qwen2.5 for inference, but accuracy degradation may occur for sequences exceeding 262,144 tokens.
GGUF quantized versions of the models are already starting to show up. LM Studio's "official model curator" Bartowski published lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF and lmstudio-community/Qwen2.5-14B-Instruct-1M-GGUF - sizes range from 4.09GB to 8.1GB for the 7B model and 7.92GB to 15.7GB for the 14B.
These might not work well yet with the full context lengths as the underlying llama.cpp library may need some changes.
I tried running the 8.1GB 7B model using Ollama on my Mac like this:
ollama run hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
Then with LLM:
llm install llm-ollama
llm models -q qwen # To search for the model ID
# I set a shorter q1m alias:
llm aliases set q1m hf.co/lmstudio-community/Qwen2.5-7B-Instruct-1M-GGUF:Q8_0
I tried piping a large prompt in using files-to-prompt like this:
files-to-prompt ~/Dropbox/Development/llm -e py -c | llm -m q1m 'describe this codebase in detail'
That should give me every Python file in my llm project. Piping that through ttok first told me this was 63,014 OpenAI tokens, I expect that count is similar for Qwen.
The result was disappointing: it appeared to describe just the last Python file that stream. Then I noticed the token usage report:
2,048 input, 999 output
This suggests to me that something's not working right here - maybe the Ollama hosting framework is truncating the input, or maybe there's a problem with the GGUF I'm using?
I'll update this post when I figure out how to run longer prompts through the new Qwen model using GGUF weights on a Mac.
Update: It turns out Ollama has a num_ctx option which defaults to 2048, affecting the input context length. I tried this:
files-to-prompt \
~/Dropbox/Development/llm \
-e py -c | \
llm -m q1m 'describe this codebase in detail' \
-o num_ctx 80000
But I quickly ran out of RAM (I have 64GB but a lot of that was in use already) and hit Ctrl+C to avoid crashing my computer. I need to experiment a bit to figure out how much RAM is used for what context size.
Awni Hannun shared tips for running mlx-community/Qwen2.5-7B-Instruct-1M-4bit using MLX, which should work for up to 250,000 tokens. They ran 120,000 tokens and reported:
- Peak RAM for prompt filling was 22GB
- Peak RAM for generation 12GB
- Prompt filling took 350 seconds on an M2 Ultra
- Generation ran at 31 tokens-per-second on M2 Ultra
DeepSeek-R1 and exploring DeepSeek-R1-Distill-Llama-8B

DeepSeek are the Chinese AI lab who dropped the best currently available open weights LLM on Christmas day, DeepSeek v3. That model was trained in part using their unreleased R1 “reasoning” model. Today they’ve released R1 itself, along with a whole family of new models derived from that base.
[... 1,276 words]microsoft/phi-4. Here's the official release of Microsoft's Phi-4 LLM, now officially under an MIT license.
A few weeks ago I covered the earlier unofficial versions, where I talked about how the model used synthetic training data in some really interesting ways.
It benchmarks favorably compared to GPT-4o, suggesting this is yet another example of a GPT-4 class model that can run on a good laptop.
The model already has several available community quantizations. I ran the mlx-community/phi-4-4bit one (a 7.7GB download) using mlx-llm like this:
uv run --with 'numpy<2' --with mlx-lm python -c '
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/phi-4-4bit")
prompt = "Generate an SVG of a pelican riding a bicycle"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True, max_tokens=2048)
print(response)'

Update: The model is now available via Ollama, so you can fetch a 9.1GB model file using ollama run phi4, after which it becomes available via the llm-ollama plugin.
2024
Open WebUI. I tried out this open source (MIT licensed, JavaScript and Python) localhost UI for accessing LLMs today for the first time. It's very nicely done.
I ran it with uvx like this:
uvx --python 3.11 open-webui serve
On first launch it installed a bunch of dependencies and then downloaded 903MB to ~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2 - a copy of the all-MiniLM-L6-v2 embedding model, presumably for its RAG feature.
It then presented me with a working Llama 3.2:3b chat interface, which surprised me because I hadn't spotted it downloading that model. It turns out that was because I have Ollama running on my laptop already (with several models, including Llama 3.2:3b, already installed) - and Open WebUI automatically detected Ollama and gave me access to a list of available models.
I found a "knowledge" section and added all of the Datasette documentation (by dropping in the .rst files from the docs) - and now I can type # in chat to search for a file, add that to the context and then ask questions about it directly.
I selected the spatialite.rst.txt file, prompted it with "How do I use SpatiaLite with Datasette" and got back this:
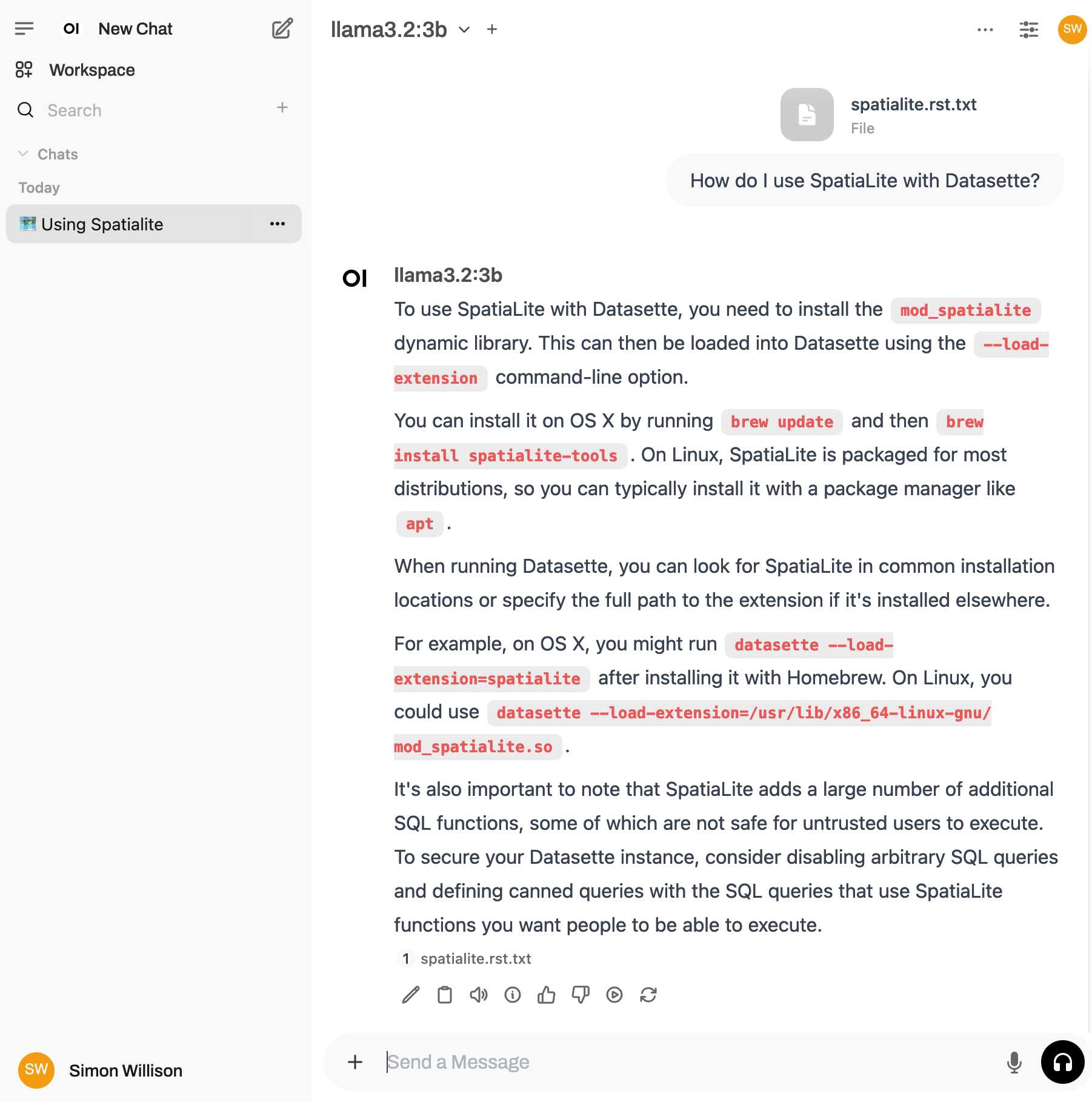
That's honestly a very solid answer, especially considering the Llama 3.2 3B model from Ollama is just a 1.9GB file! It's impressive how well that model can handle basic Q&A and summarization against text provided to it - it somehow has a 128,000 token context size.
Open WebUI has a lot of other tricks up its sleeve: it can talk to API models such as OpenAI directly, has optional integrations with web search and custom tools and logs every interaction to a SQLite database. It also comes with extensive documentation.