1,526 posts tagged “datasette”
Datasette is an open source tool for exploring and publishing data.
2026
Datasette Agent
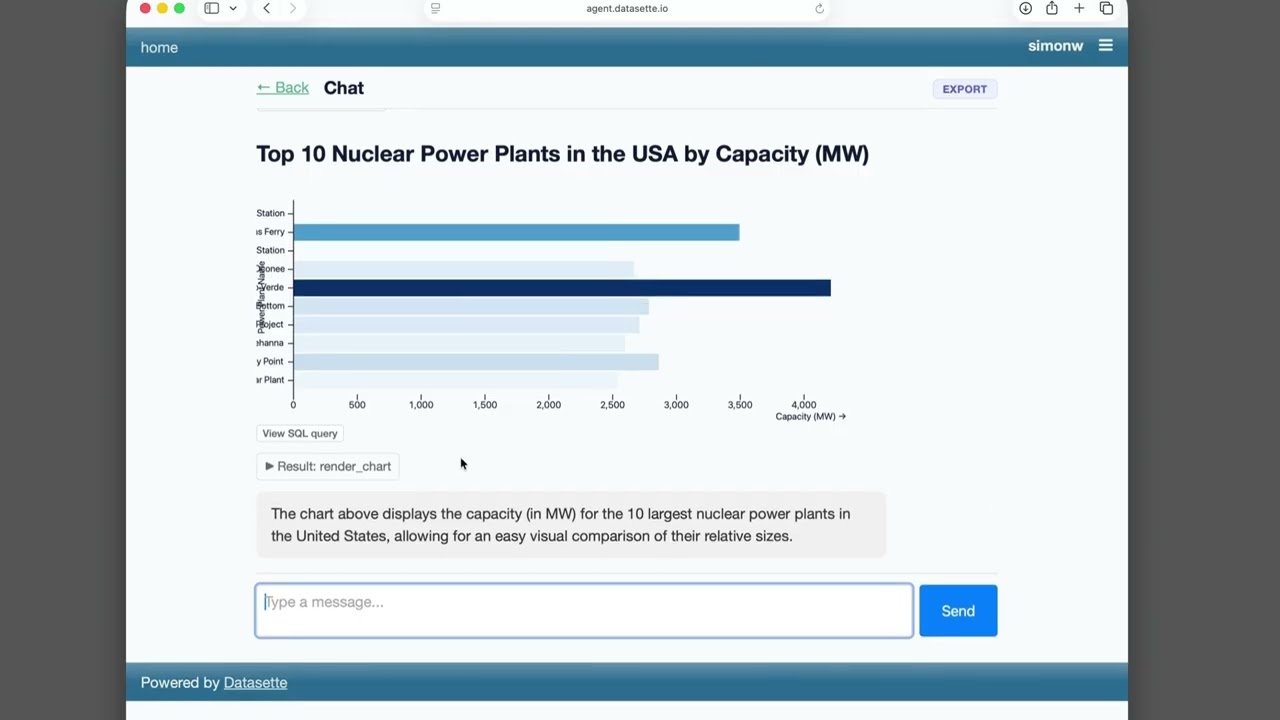
We just announced the first release of Datasette Agent, a new extensible AI assistant for Datasette. I’ve been working on my LLM Python library for just over three years now, and Datasette Agent represents the moment that LLM and Datasette finally come together. I’m really excited about it!
[... 659 words]A Datasette Agent plugin for running commands in a Fly Sprites sandbox.
- "View SQL query" buttons below rendered charts.
- "View SQL query" buttons for both visible tables and collapsed SQL result tool calls.
- Don't display empty reasoning chunks
- Improved handling of truncated responses - table still displays to the user even if the SQL results were truncated when showing the agent.
See Datasette Agent, an extensible AI assistant for Datasette.
- More color! Bar and waffle charts without a color column are shaded by magnitude with a sequential color scheme; color columns holding text values use the
observable10categorical scheme. #2- Now checks
execute-sqlpermission before running the query to find the column names.- Charts now display interactive tooltips.
- Fixed a bug where
waffleYcharts were not described to the agent.
- Fixed bug tracking chains of responses. Refs datasette-llm#7
This plugin works in conjunction with datasette-llm and datasette-llm-accountant to let you configure a per-user (or global) spending limit for LLM usage inside of Datasette. Configuration looks something like this:
plugins: datasette-llm-limits: limits: per-user-daily: scope: actor window: rolling-24h amount_usd: 1.00
- Tool availability can now be attached to a
required_permission. The default background agent tools now require the newdatasette-agent-backgroundpermission. #10
- Now uses the
execute-sqlpermission when deciding which tables to list to the user. #8
The datasette.io site was being hammered by poorly-behaved crawlers, so I had Codex (GPT-5.5 xhigh) build a configurable rate limiting plugin to block IPs that were hammering specific areas of the site too quickly.
Here's the production configuration I'm using on that site for the new plugin:
datasette-ip-rate-limit: header: Fly-Client-IP max_keys: 10000 exempt_paths: - "/static/*" - "/-/turnstile*" rules: - name: demo-databases paths: - "/global-power-plants/*" - "/legislators/*" window_seconds: 60 max_requests: 60 block_seconds: 20
Welcome to the Datasette blog. We have a bunch of neat Datasette announcements in the pipeline so we decided it was time the project grew an official blog.
I built this using OpenAI Codex desktop, which turns out to have the Markdown session transcript export feature I've always wanted. Here's the session that built the blog. See also issue 179.
- New
TokenRestrictions.abbreviated(datasette)utility method for creating"_r"dictionaries. #2695- Table headers and column options are now visible even if a table contains zero rows. #2701
- Fixed bug with display of column actions dialog on Mobile Safari. #2708
- Fixed bug where tests could crash with a segfault due to a race condition between
Datasette.close()andDatabase.close(). #2709
That segfault bug was gnarly. I added a mechanism to Datasette recently that would automatically close connections at the end of each test, but it turned out that introduced a race condition where an in-flight query could sometimes be executing in a thread against a connection while it was being closed. I ended up solving that by having Codex CLI (with GPT-5.5 xhigh) create a minimal Dockerfile that recreated the bug.
- Initial (silent) alpha release.
The OpenStreetMap tiles on the Datasette global-power-plants demo weren't displaying correctly. This turned out to be caused by two bugs.
The first is that the CAPTCHA I added to that site a few weeks ago was triggering for the .json fetch requests used by the map plugin, and since those weren't HTML the user was not being asked to solve them. Here's the fix.
The second was that OpenStreetMap quite reasonably block tile requests from sites that use a Referrer-Policy: no-referrer header.
Datasette does this by default, and I didn't want to change that default on people without warning - so I had Codex + GPT-5.5 build me a new plugin to help set that header to another value.
- Mechanism for configuring default options for specific models.
Part of Datasette's evolving support mechanism for plugins that use LLMs. It's now possible to configure a model with default options, e.g. to say all enrichment operations should use a specific model with temperature set to 0.5.

I put together some notes on patterns for fetching data from a Datasette instance directly into Google Sheets - using the importdata() function, a "named function" that wraps it or a Google Apps Script if you need to send an API token in an HTTP header (not supported by importdata().)
Here's an example sheet demonstrating all three methods.
I was upgrading Datasette Cloud to 1.0a27 and discovered a nasty collection of accidental breakages caused by changes in that alpha. This new alpha addresses those directly:
- Fixed a compatibility bug introduced in 1.0a27 where
execute_write_fn()callbacks with a parameter name other thanconnwere seeing errors. (#2691)- The database.close() method now also shuts down the write connection for that database.
- New datasette.close() method for closing down all databases and resources associated with a Datasette instance. This is called automatically when the server shuts down. (#2693)
- Datasette now includes a pytest plugin which automatically calls
datasette.close()on temporary instances created in function-scoped fixtures and during tests. See Automatic cleanup of Datasette instances for details. This helps avoid running out of file descriptors in plugin test suites that were written before theDatabase(is_temp_disk=True)feature introduced in Datasette 1.0a27. (#2692)
Most of the changes in this release were implemented using Claude Code and the newly released Claude Opus 4.7.
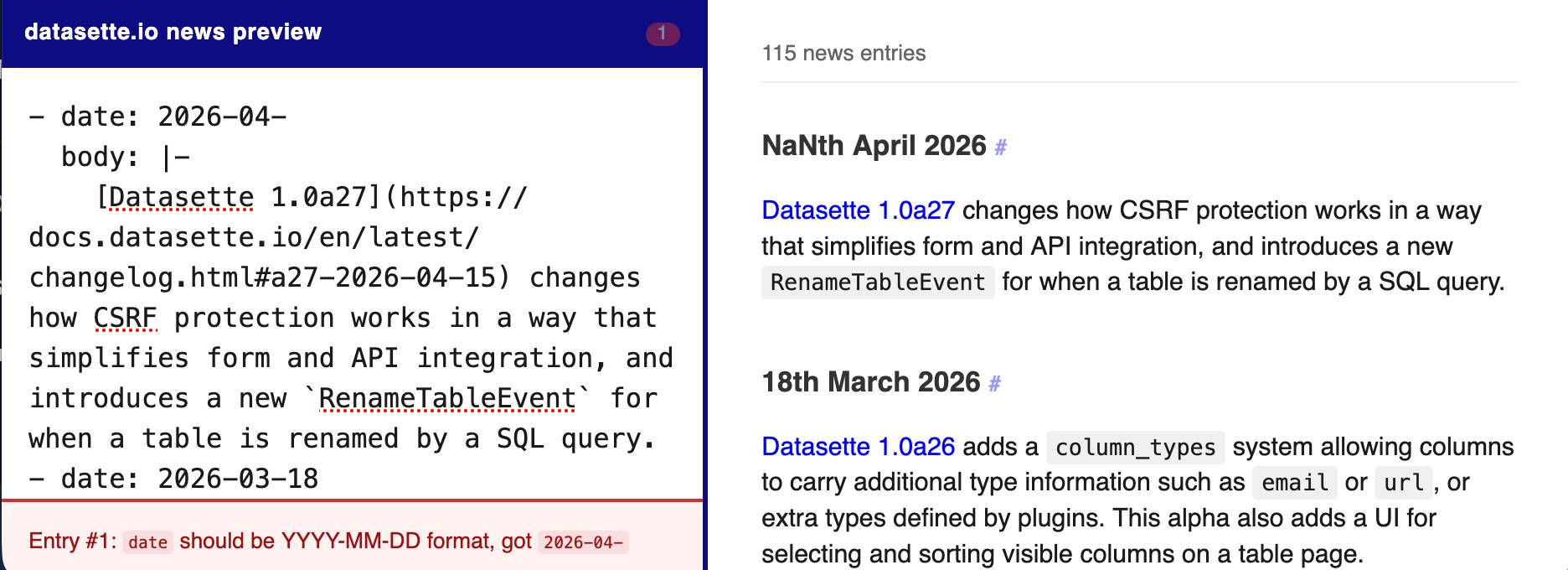
The datasette.io website has a news section built from this news.yaml file in the underlying GitHub repository. The YAML format looks like this:
- date: 2026-04-15
body: |-
[Datasette 1.0a27](https://docs.datasette.io/en/latest/changelog.html#a27-2026-04-15) changes how CSRF protection works in a way that simplifies form and API integration, and introduces a new `RenameTableEvent` for when a table is renamed by a SQL query.
- date: 2026-03-18
body: |-
...
This format is a little hard to edit, so I finally had Claude build a custom preview UI to make checking for errors have slightly less friction.
I built it using standard claude.ai and Claude Artifacts, taking advantage of Claude's ability to clone GitHub repos and look at their content as part of a regular chat:
Clone https://github.com/simonw/datasette.io and look at the news.yaml file and how it is rendered on the homepage. Build an artifact I can paste that YAML into which previews what it will look like, and highlights any markdown errors or YAML errors
This plugin was using the ds_csrftoken cookie as part of a custom signed URL, which needed upgrading now that Datasette 1.0a27 no longer sets that cookie.
Two major changes in this new Datasette alpha. I covered the first of those in detail yesterday - Datasette no longer uses Django-style CSRF form tokens, instead using modern browser headers as described by Filippo Valsorda.
The second big change is that Datasette now fires a new RenameTableEvent any time a table is renamed during a SQLite transaction. This is useful because some plugins (like datasette-comments) attach additional data to table records by name, so a renamed table requires them to react in appropriate ways.
Here are the rest of the changes in the alpha:
- New actor= parameter for
datasette.clientmethods, allowing internal requests to be made as a specific actor. This is particularly useful for writing automated tests. (#2688)- New
Database(is_temp_disk=True)option, used internally for the internal database. This helps resolve intermittent database locked errors caused by the internal database being in-memory as opposed to on-disk. (#2683) (#2684)- The
/<database>/<table>/-/upsertAPI (docs) now rejects rows withnullprimary key values. (#1936)- Improved example in the API explorer for the
/-/upsertendpoint (docs). (#1936)- The
/<database>.jsonendpoint now includes an"ok": truekey, for consistency with other JSON API responses.- call_with_supported_arguments() is now documented as a supported public API. (#2678)
A small update for my tool for helping me figure out what all of the Datasette instances on my laptop are up to.
- Show working directory derived from each PID
- Show the full path to each database file
Output now looks like this:
http://127.0.0.1:8007/ - v1.0a26
Directory: /Users/simon/dev/blog
Databases:
simonwillisonblog: /Users/simon/dev/blog/simonwillisonblog.db
Plugins:
datasette-llm
datasette-secrets
http://127.0.0.1:8001/ - v1.0a26
Directory: /Users/simon/dev/creatures
Databases:
creatures: /tmp/creatures.db
datasette PR #2689: Replace token-based CSRF with Sec-Fetch-Site header protection.
Datasette has long protected against CSRF attacks using CSRF tokens, implemented using my asgi-csrf Python library. These are something of a pain to work with - you need to scatter forms in templates with <input type="hidden" name="csrftoken" value="{{ csrftoken() }}"> lines and then selectively disable CSRF protection for APIs that are intended to be called from outside the browser.
I've been following Filippo Valsorda's research here with interest, described in this detailed essay from August 2025 and shipped as part of Go 1.25 that same month.
I've now landed the same change in Datasette. Here's the PR description - Claude Code did much of the work (across 10 commits, closely guided by me and cross-reviewed by GPT-5.4) but I've decided to start writing these PR descriptions by hand, partly to make them more concise and also as an exercise in keeping myself honest.
- New CSRF protection middleware inspired by Go 1.25 and this research by Filippo Valsorda. This replaces the old CSRF token based protection.
- Removes all instances of
<input type="hidden" name="csrftoken" value="{{ csrftoken() }}">in the templates - they are no longer needed.- Removes the
def skip_csrf(datasette, scope):plugin hook defined indatasette/hookspecs.pyand its documentation and tests.- Updated CSRF protection documentation to describe the new approach.
- Upgrade guide now describes the CSRF change.
- No longer requires Datasette - running
uvx datasette-portsnow works as well.- Installing it as a Datasette plugin continues to provide the
datasette portscommand.
Another example of README-driven development, this time solving a problem that might be unique to me.
I often find myself running a bunch of different Datasette instances with different databases and different in-development plugins, spreads across dozens of different terminal windows - enough that I frequently lose them!
Now I can run this:
datasette install datasette-ports
datasette ports
And get a list of every running instance that looks something like this:
http://127.0.0.1:8333/ - v1.0a26
Databases: data
Plugins: datasette-enrichments, datasette-enrichments-llm, datasette-llm, datasette-secrets
http://127.0.0.1:8001/ - v1.0a26
Databases: creatures
Plugins: datasette-extract, datasette-llm, datasette-secrets
http://127.0.0.1:8900/ - v0.65.2
Databases: logs
- The same model ID no longer needs to be repeated in both the default model and allowed models lists - setting it as a default model automatically adds it to the allowed models list. #6
- Improved documentation for Python API usage.
- The
actorwho triggers an enrichment is now passed to thellm.mode(... actor=actor)method. #3
- Now uses datasette-llm to manage model configuration, which means you can control which models are available for extraction tasks using the
extractpurpose and LLM model configuration. #38
- This plugin now uses datasette-llm to configure and manage models. This means it's possible to specify which models should be made available for enrichments, using the new
enrichmentspurpose.