109 posts tagged “cli”
Command-line interface tools and how to build them.
2025
Rich Pixels. Neat Python library by Darren Burns adding pixel image support to the Rich terminal library, using tricks to render an image using full or half-height colored blocks.
Here's the key trick - it renders Unicode ▄ (U+2584, "lower half block") characters after setting a foreground and background color for the two pixels it needs to display.
I got GPT-5 to vibe code up a show_image.py terminal command which resizes the provided image to fit the width and height of the current terminal and displays it using Rich Pixels. That script is here, you can run it with uv like this:
uv run https://tools.simonwillison.net/python/show_image.py \
image.jpg
Here's what I got when I ran it against my V&A East Storehouse photo from this post:
![]()
f2 (via) Really neat CLI tool for bulk renaming of files and directories by Ayooluwa Isaiah, written in Go and designed to work cross-platform.
There's a lot of great design in this. Basic usage is intuitive - here's how to rename all .svg files to .tmp.svg in the current directory:
f2 -f '.svg' -r '.tmp.svg' path/to/dir
f2 defaults to a dry run which looks like this:
*————————————————————*————————————————————————*————————*
| ORIGINAL | RENAMED | STATUS |
*————————————————————*————————————————————————*————————*
| claude-pelican.svg | claude-pelican.tmp.svg | ok |
| gemini-pelican.svg | gemini-pelican.tmp.svg | ok |
*————————————————————*————————————————————————*————————*
dry run: commit the above changes with the -x/--exec flag
Running -x executes the rename.
The really cool stuff is the advanced features - Ayooluwa has thought of everything. The EXIF integration is particularly clevel - here's an example from the advanced tutorial which renames a library of photos to use their EXIF creation date as part of the file path:
f2 -r '{x.cdt.YYYY}/{x.cdt.MM}-{x.cdt.MMM}/{x.cdt.YYYY}-{x.cdt.MM}-{x.cdt.DD}/{f}{ext}' -R
The -R flag means "recursive". The small -r uses variable syntax for EXIF data. There are plenty of others too, including hash variables that use the hash of the file contents.
Installation notes
I had Go 1.23.2 installed on my Mac via Homebrew. I ran this:
go install github.com/ayoisaiah/f2/v2/cmd/f2@latest
And got an error:
requires go >= 1.24.2 (running go 1.23.2; GOTOOLCHAIN=local)
So I upgraded Go using Homebrew:
brew upgrade go
Which took me to 1.24.3 - then the go install command worked. It put the binary in ~/go/bin/f2.
There's also an npm package, similar to the pattern I wrote about a while ago of people Bundling binary tools in Python wheels.
OpenAI Codex. Announced today, here's the documentation for OpenAI's "cloud-based software engineering agent". It's not yet available for us $20/month Plus customers ("coming soon") but if you're a $200/month Pro user you can try it out now.
At a high level, you specify a prompt, and the agent goes to work in its own environment. After about 8–10 minutes, the agent gives you back a diff.
You can execute prompts in either ask mode or code mode. When you select ask, Codex clones a read-only version of your repo, booting faster and giving you follow-up tasks. Code mode, however, creates a full-fledged environment that the agent can run and test against.
This 4 minute demo video is a useful overview. One note that caught my eye is that the setup phase for an environment can pull from the internet (to install necessary dependencies) but the agent loop itself still runs in a network disconnected sandbox.
It sounds similar to GitHub's own Copilot Workspace project, which can compose PRs against your code based on a prompt. The big difference is that Codex incorporates a full Code Interpeter style environment, allowing it to build and run the code it's creating and execute tests in a loop.
Copilot Workspaces has a level of integration with Codespaces but still requires manual intervention to help exercise the code.
Also similar to Copilot Workspaces is a confusing name. OpenAI now have four products called Codex:
- OpenAI Codex, announced today.
- Codex CLI, a completely different coding assistant tool they released a few weeks ago that is the same kind of shape as Claude Code. This one owns the openai/codex namespace on GitHub.
- codex-mini, a brand new model released today that is used by their Codex product. It's a fine-tuned o4-mini variant. I released llm-openai-plugin 0.4 adding support for that model.
- OpenAI Codex (2021) - Internet Archive link, OpenAI's first specialist coding model from the GPT-3 era. This was used by the original GitHub Copilot and is still the current topic of Wikipedia's OpenAI Codex page.
My favorite thing about this most recent Codex product is that OpenAI shared the full Dockerfile for the environment that the system uses to run code - in openai/codex-universal on GitHub because openai/codex was taken already.
This is extremely useful documentation for figuring out how to use this thing - I'm glad they're making this as transparent as possible.
And to be fair, If you ignore it previous history Codex Is a good name for this product. I'm just glad they didn't call it Ada.
sqlite-utils 4.0a0. New alpha release of sqlite-utils, my Python library and CLI tool for manipulating SQLite databases.
It's the first 4.0 alpha because there's a (minor) backwards-incompatible change: I've upgraded the .upsert() and .upsert_all() methods to use SQLIte's UPSERT mechanism, INSERT INTO ... ON CONFLICT DO UPDATE. Details in this issue.
That feature was added to SQLite in version 3.24.0, released 2018-06-04. I'm pretty cautious about my SQLite version support since the underlying library can be difficult to upgrade, depending on your platform and operating system.
I'm going to leave the new alpha to bake for a little while before pushing a stable release. Since this is a major version bump I'm going to take the opportunity to see if there are any other minor API warts that I can clean up at the same time.
Feed a video to a vision LLM as a sequence of JPEG frames on the CLI (also LLM 0.25)

The new llm-video-frames plugin can turn a video file into a sequence of JPEG frames and feed them directly into a long context vision LLM such as GPT-4.1, even when that LLM doesn’t directly support video input. It depends on a plugin feature I added to LLM 0.25, which I released last night.
[... 1,600 words]llm-fragment-symbex. I released a new LLM fragment loader plugin that builds on top of my Symbex project.
Symbex is a CLI tool I wrote that can run against a folder full of Python code and output functions, classes, methods or just their docstrings and signatures, using the Python AST module to parse the code.
llm-fragments-symbex brings that ability directly to LLM. It lets you do things like this:
llm install llm-fragments-symbex
llm -f symbex:path/to/project -s 'Describe this codebase'
I just ran that against my LLM project itself like this:
cd llm
llm -f symbex:. -s 'guess what this code does'
Here's the full output, which starts like this:
This code listing appears to be an index or dump of Python functions, classes, and methods primarily belonging to a codebase related to large language models (LLMs). It covers a broad functionality set related to managing LLMs, embeddings, templates, plugins, logging, and command-line interface (CLI) utilities for interaction with language models. [...]
That page also shows the input generated by the fragment - here's a representative extract:
# from llm.cli import resolve_attachment def resolve_attachment(value): """Resolve an attachment from a string value which could be: - "-" for stdin - A URL - A file path Returns an Attachment object. Raises AttachmentError if the attachment cannot be resolved.""" # from llm.cli import AttachmentType class AttachmentType: def convert(self, value, param, ctx): # from llm.cli import resolve_attachment_with_type def resolve_attachment_with_type(value: str, mimetype: str) -> Attachment:
If your Python code has good docstrings and type annotations, this should hopefully be a shortcut for providing full API documentation to a model without needing to dump in the entire codebase.
The above example used 13,471 input tokens and 781 output tokens, using openai/gpt-4.1-mini. That model is extremely cheap, so the total cost was 0.6638 cents - less than a cent.
The plugin itself was mostly written by o4-mini using the llm-fragments-github plugin to load the simonw/symbex and simonw/llm-hacker-news repositories as example code:
llm \ -f github:simonw/symbex \ -f github:simonw/llm-hacker-news \ -s "Write a new plugin as a single llm_fragments_symbex.py file which provides a custom loader which can be used like this: llm -f symbex:path/to/folder - it then loads in all of the python function signatures with their docstrings from that folder using the same trick that symbex uses, effectively the same as running symbex . '*' '*.*' --docs --imports -n" \ -m openai/o4-mini -o reasoning_effort high
Here's the response. 27,819 input, 2,918 output = 4.344 cents.
In working on this project I identified and fixed a minor cosmetic defect in Symbex itself. Technically this is a breaking change (it changes the output) so I shipped that as Symbex 2.0.
Claude Code: Best practices for agentic coding (via) Extensive new documentation from Anthropic on how to get the best results out of their Claude Code CLI coding agent tool, which includes this fascinating tip:
We recommend using the word "think" to trigger extended thinking mode, which gives Claude additional computation time to evaluate alternatives more thoroughly. These specific phrases are mapped directly to increasing levels of thinking budget in the system: "think" < "think hard" < "think harder" < "ultrathink." Each level allocates progressively more thinking budget for Claude to use.
Apparently ultrathink is a magic word!
I was curious if this was a feature of the Claude model itself or Claude Code in particular. Claude Code isn't open source but you can view the obfuscated JavaScript for it, and make it a tiny bit less obfuscated by running it through Prettier. With Claude's help I used this recipe:
mkdir -p /tmp/claude-code-examine
cd /tmp/claude-code-examine
npm init -y
npm install @anthropic-ai/claude-code
cd node_modules/@anthropic-ai/claude-code
npx prettier --write cli.js
Then used ripgrep to search for "ultrathink":
rg ultrathink -C 30
And found this chunk of code:
let B = W.message.content.toLowerCase(); if ( B.includes("think harder") || B.includes("think intensely") || B.includes("think longer") || B.includes("think really hard") || B.includes("think super hard") || B.includes("think very hard") || B.includes("ultrathink") ) return ( l1("tengu_thinking", { tokenCount: 31999, messageId: Z, provider: G }), 31999 ); if ( B.includes("think about it") || B.includes("think a lot") || B.includes("think deeply") || B.includes("think hard") || B.includes("think more") || B.includes("megathink") ) return ( l1("tengu_thinking", { tokenCount: 1e4, messageId: Z, provider: G }), 1e4 ); if (B.includes("think")) return ( l1("tengu_thinking", { tokenCount: 4000, messageId: Z, provider: G }), 4000 );
So yeah, it looks like "ultrathink" is a Claude Code feature - presumably that 31999 is a number that affects the token thinking budget, especially since "megathink" maps to 1e4 tokens (10,000) and just plain "think" maps to 4,000.
openai/codex. Just released by OpenAI, a "lightweight coding agent that runs in your terminal". Looks like their version of Claude Code, though unlike Claude Code Codex is released under an open source (Apache 2) license.
Here's the main prompt that runs in a loop, which starts like this:
You are operating as and within the Codex CLI, a terminal-based agentic coding assistant built by OpenAI. It wraps OpenAI models to enable natural language interaction with a local codebase. You are expected to be precise, safe, and helpful.
You can:
- Receive user prompts, project context, and files.
- Stream responses and emit function calls (e.g., shell commands, code edits).
- Apply patches, run commands, and manage user approvals based on policy.
- Work inside a sandboxed, git-backed workspace with rollback support.
- Log telemetry so sessions can be replayed or inspected later.
- More details on your functionality are available at codex --help
The Codex CLI is open-sourced. Don't confuse yourself with the old Codex language model built by OpenAI many moons ago (this is understandably top of mind for you!). Within this context, Codex refers to the open-source agentic coding interface. [...]
I like that the prompt describes OpenAI's previous Codex language model as being from "many moons ago". Prompt engineering is so weird.
Since the prompt says that it works "inside a sandboxed, git-backed workspace" I went looking for the sandbox. On macOS it uses the little-known sandbox-exec process, part of the OS but grossly under-documented. The best information I've found about it is this article from 2020, which notes that man sandbox-exec lists it as deprecated. I didn't spot evidence in the Codex code of sandboxes for other platforms.
llm-openrouter 0.4. I found out this morning that OpenRouter include support for a number of (rate-limited) free API models.
I occasionally run workshops on top of LLMs (like this one) and being able to provide students with a quick way to obtain an API key against models where they don't have to setup billing is really valuable to me!
This inspired me to upgrade my existing llm-openrouter plugin, and in doing so I closed out a bunch of open feature requests.
Consider this post the annotated release notes:
- LLM schema support for OpenRouter models that support structured output. #23
I'm trying to get support for LLM's new schema feature into as many plugins as possible.
OpenRouter's OpenAI-compatible API includes support for the response_format structured content option, but with an important caveat: it only works for some models, and if you try to use it on others it is silently ignored.
I filed an issue with OpenRouter requesting they include schema support in their machine-readable model index. For the moment LLM will let you specify schemas for unsupported models and will ignore them entirely, which isn't ideal.
llm openrouter keycommand displays information about your current API key. #24
Useful for debugging and checking the details of your key's rate limit.
llm -m ... -o online 1enables web search grounding against any model, powered by Exa. #25
OpenRouter apparently make this feature available to every one of their supported models! They're using new-to-me Exa to power this feature, an AI-focused search engine startup who appear to have built their own index with their own crawlers (according to their FAQ). This feature is currently priced by OpenRouter at $4 per 1000 results, and since 5 results are returned for every prompt that's 2 cents per prompt.
llm openrouter modelscommand for listing details of the OpenRouter models, including a--jsonoption to get JSON and a--freeoption to filter for just the free models. #26
This offers a neat way to list the available models. There are examples of the output in the comments on the issue.
- New option to specify custom provider routing:
-o provider '{JSON here}'. #17
Part of OpenRouter's USP is that it can route prompts to different providers depending on factors like latency, cost or as a fallback if your first choice is unavailable - great for if you are using open weight models like Llama which are hosted by competing companies.
The options they provide for routing are very thorough - I had initially hoped to provide a set of CLI options that covered all of these bases, but I decided instead to reuse their JSON format and forward those options directly on to the model.
Mistral OCR (via) New closed-source specialist OCR model by Mistral - you can feed it images or a PDF and it produces Markdown with optional embedded images.
It's available via their API, or it's "available to self-host on a selective basis" for people with stringent privacy requirements who are willing to talk to their sales team.
I decided to try out their API, so I copied and pasted example code from their notebook into my custom Claude project and told it:
Turn this into a CLI app, depends on mistralai - it should take a file path and an optional API key defauling to env vironment called MISTRAL_API_KEY
After some further iteration / vibe coding I got to something that worked, which I then tidied up and shared as mistral_ocr.py.
You can try it out like this:
export MISTRAL_API_KEY='...'
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf --html --inline-images > mixtral.html
I fed in the Mixtral paper as a PDF. The API returns Markdown, but my --html option renders that Markdown as HTML and the --inline-images option takes any images and inlines them as base64 URIs (inspired by monolith). The result is mixtral.html, a 972KB HTML file with images and text bundled together.
This did a pretty great job!
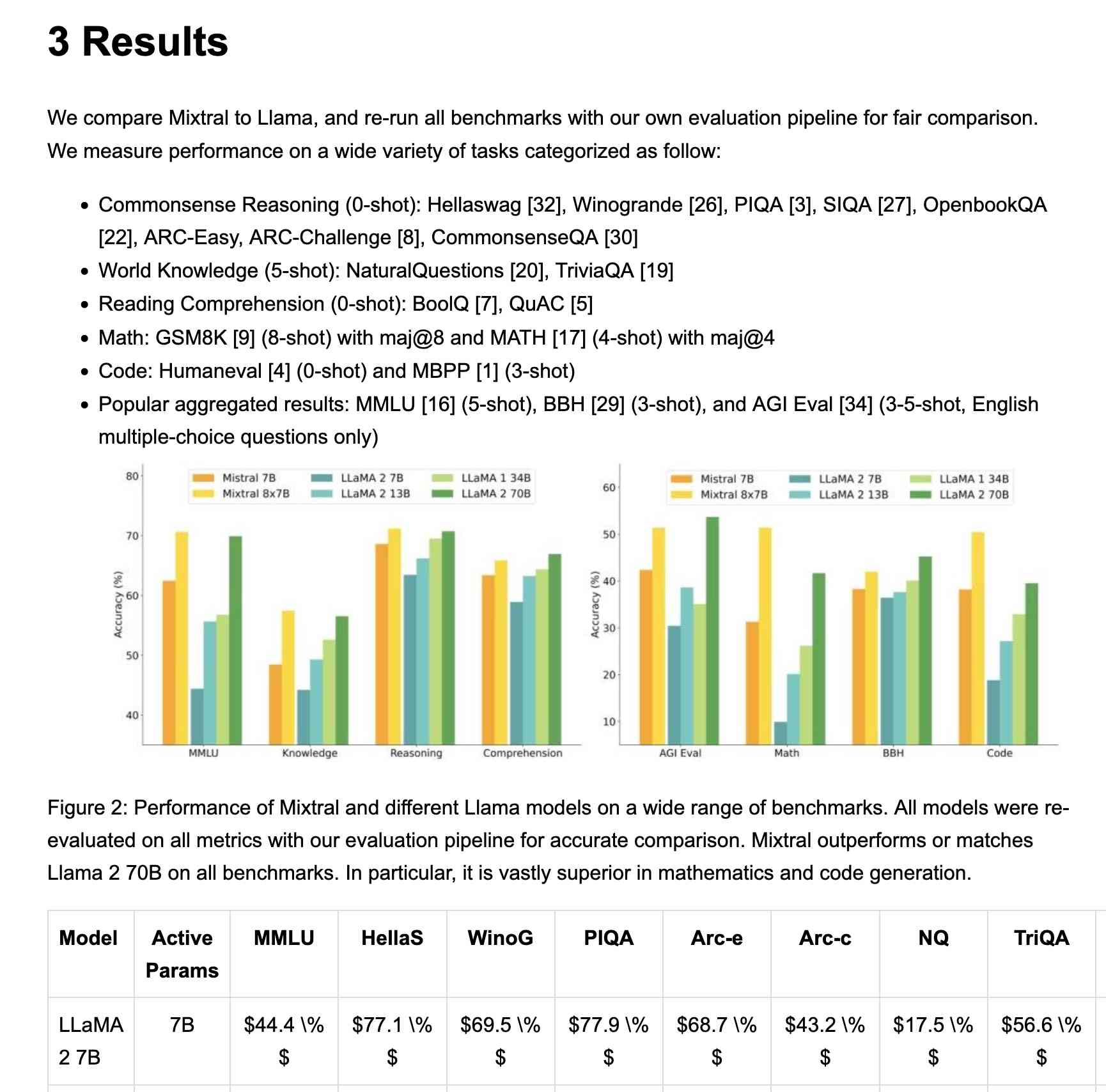
My script renders Markdown tables but I haven't figured out how to render inline Markdown MathML yet. I ran the command a second time and requested Markdown output (the default) like this:
uv run http://tools.simonwillison.net/python/mistral_ocr.py \
mixtral.pdf > mixtral.md
Here's that Markdown rendered as a Gist - there are a few MathML glitches so clearly the Mistral OCR MathML dialect and the GitHub Formatted Markdown dialect don't quite line up.
My tool can also output raw JSON as an alternative to Markdown or HTML - full details in the documentation.
The Mistral API is priced at roughly 1000 pages per dollar, with a 50% discount for batch usage.
The big question with LLM-based OCR is always how well it copes with accidental instructions in the text (can you safely OCR a document full of prompting examples?) and how well it handles text it can't write.
Mistral's Sophia Yang says it "should be robust" against following instructions in the text, and invited people to try and find counter-examples.
Alexander Doria noted that Mistral OCR can hallucinate text when faced with handwriting that it cannot understand.
monolith (via) Neat CLI tool built in Rust that can create a single packaged HTML file of a web page plus all of its dependencies.
cargo install monolith # or brew install
monolith https://simonwillison.net/ > simonwillison.html
That command produced this 1.5MB single file result. All of the linked images, CSS and JavaScript assets have had their contents inlined into base64 URIs in their src= and href= attributes.
I was intrigued as to how it works, so I dumped the whole repository into Gemini 2.0 Pro and asked for an architectural summary:
cd /tmp
git clone https://github.com/Y2Z/monolith
cd monolith
files-to-prompt . -c | llm -m gemini-2.0-pro-exp-02-05 \
-s 'architectural overview as markdown'
Here's what I got. Short version: it uses the reqwest, html5ever, markup5ever_rcdom and cssparser crates to fetch and parse HTML and CSS and extract, combine and rewrite the assets. It doesn't currently attempt to run any JavaScript.
Aider: Using uv as an installer. Paul Gauthier has an innovative solution for the challenge of helping end users get a copy of his Aider CLI Python utility installed in an isolated virtual environment without first needing to teach them what an "isolated virtual environment" is.
Provided you already have a Python install of version 3.8 or higher you can run this:
pip install aider-install && aider-install
The aider-install package itself depends on uv. When you run aider-install it executes the following Python code:
def install_aider(): try: uv_bin = uv.find_uv_bin() subprocess.check_call([ uv_bin, "tool", "install", "--force", "--python", "python3.12", "aider-chat@latest" ]) subprocess.check_call([uv_bin, "tool", "update-shell"]) except subprocess.CalledProcessError as e: print(f"Failed to install aider: {e}") sys.exit(1)
This first figures out the location of the uv Rust binary, then uses it to install his aider-chat package by running the equivalent of this command:
uv tool install --force --python python3.12 aider-chat@latest
This will in turn install a brand new standalone copy of Python 3.12 and tuck it away in uv's own managed directory structure where it shouldn't hurt anything else.
The aider-chat script defaults to being dropped in the XDG standard directory, which is probably ~/.local/bin - see uv's documentation. The --force flag ensures that uv will overwrite any previous attempts at installing aider-chat in that location with the new one.
Finally, running uv tool update-shell ensures that bin directory is on the user's PATH.
I think I like this. There is a LOT of stuff going on here, and experienced users may well opt for an alternative installation mechanism.
But for non-expert Python users who just want to start using Aider, I think this pattern represents quite a tasteful way of getting everything working with minimal risk of breaking the user's system.
Update: Paul adds:
Offering this install method dramatically reduced the number of GitHub issues from users with conflicted/broken python environments.
I also really like the "curl | sh" aider installer based on uv. Even users who don't have python installed can use it.
strip-tags 0.6. It's been a while since I updated this tool, but in investigating a tricky mistake in my tutorial for LLM schemas I discovered a bug that I needed to fix.
Those release notes in full:
- Fixed a bug where
strip-tags -t metastill removed<meta>tags from the<head>because the entire<head>element was removed first. #32- Kept
<meta>tags now default to keeping theircontentandpropertyattributes.- The CLI
-m/--minifyoption now also removes any remaining blank lines. #33- A new
strip_tags(remove_blank_lines=True)option can be used to achieve the same thing with the Python library function.
Now I can do this and persist the <meta> tags for the article along with the stripped text content:
curl -s 'https://apnews.com/article/trump-federal-employees-firings-a85d1aaf1088e050d39dcf7e3664bb9f' | \
strip-tags -t meta --minify
Here's the output from that command.
Structured data extraction from unstructured content using LLM schemas
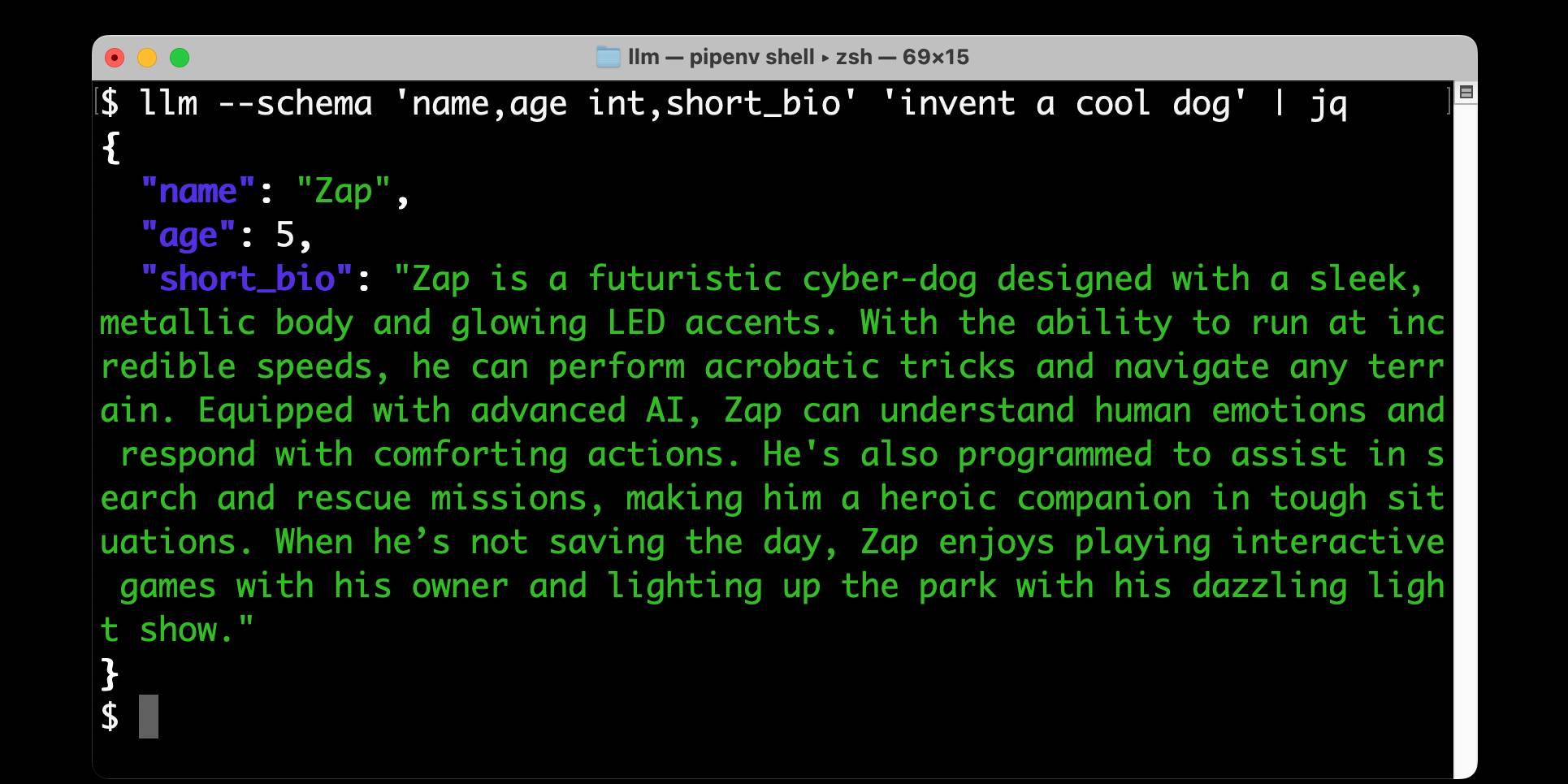
LLM 0.23 is out today, and the signature feature is support for schemas—a new way of providing structured output from a model that matches a specification provided by the user. I’ve also upgraded both the llm-anthropic and llm-gemini plugins to add support for schemas.
[... 2,601 words]Claude 3.7 Sonnet and Claude Code. Anthropic released Claude 3.7 Sonnet today - skipping the name "Claude 3.6" because the Anthropic user community had already started using that as the unofficial name for their October update to 3.5 Sonnet.
As you may expect, 3.7 Sonnet is an improvement over 3.5 Sonnet - and is priced the same, at $3/million tokens for input and $15/m output.
The big difference is that this is Anthropic's first "reasoning" model - applying the same trick that we've now seen from OpenAI o1 and o3, Grok 3, Google Gemini 2.0 Thinking, DeepSeek R1 and Qwen's QwQ and QvQ. The only big model families without an official reasoning model now are Mistral and Meta's Llama.
I'm still working on adding support to my llm-anthropic plugin but I've got enough working code that I was able to get it to draw me a pelican riding a bicycle. Here's the non-reasoning model:

And here's that same prompt but with "thinking mode" enabled:

Here's the transcript for that second one, which mixes together the thinking and the output tokens. I'm still working through how best to differentiate between those two types of token.
Claude 3.7 Sonnet has a training cut-off date of Oct 2024 - an improvement on 3.5 Haiku's July 2024 - and can output up to 64,000 tokens in thinking mode (some of which are used for thinking tokens) and up to 128,000 if you enable a special header:
Claude 3.7 Sonnet can produce substantially longer responses than previous models with support for up to 128K output tokens (beta)---more than 15x longer than other Claude models. This expanded capability is particularly effective for extended thinking use cases involving complex reasoning, rich code generation, and comprehensive content creation.
This feature can be enabled by passing an
anthropic-betaheader ofoutput-128k-2025-02-19.
Anthropic's other big release today is a preview of Claude Code - a CLI tool for interacting with Claude that includes the ability to prompt Claude in terminal chat and have it read and modify files and execute commands. This means it can both iterate on code and execute tests, making it an extremely powerful "agent" for coding assistance.
Here's Anthropic's documentation on getting started with Claude Code, which uses OAuth (a first for Anthropic's API) to authenticate against your API account, so you'll need to configure billing.
Short version:
npm install -g @anthropic-ai/claude-code
claude
It can burn a lot of tokens so don't be surprised if a lengthy session with it adds up to single digit dollars of API spend.
files-to-prompt 0.6. New release of my CLI tool for turning a whole directory of code into a single prompt ready to pipe or paste into an LLM.
Here are the full release notes:
- New
-m/--markdownoption for outputting results as Markdown with each file in a fenced code block. #42- Support for reading a list of files from standard input. Thanks, Ankit Shankar. #44
Here's how to process just files modified within the last day:find . -mtime -1 | files-to-promptYou can also use the
-0/--nullflag to accept lists of file paths separated by null delimiters, which is useful for handling file names with spaces in them:find . -name "*.txt" -print0 | files-to-prompt -0
I also have a potential fix for a reported bug concerning nested .gitignore files that's currently sitting in a PR. I'm waiting for someone else to confirm that it behaves as they would expect. I've left details in this issue comment, but the short version is that you can try out the version from the PR using this uvx incantation:
uvx --with git+https://github.com/simonw/files-to-prompt@nested-gitignore files-to-prompt
LLM 0.22, the annotated release notes
I released LLM 0.22 this evening. Here are the annotated release notes:
[... 1,340 words]shot-scraper 1.6 with support for HTTP Archives. New release of my shot-scraper CLI tool for taking screenshots and scraping web pages.
The big new feature is HTTP Archive (HAR) support. The new shot-scraper har command can now create an archive of a page and all of its dependents like this:
shot-scraper har https://datasette.io/
This produces a datasette-io.har file (currently 163KB) which is JSON representing the full set of requests used to render that page. Here's a copy of that file. You can visualize that here using ericduran.github.io/chromeHAR.
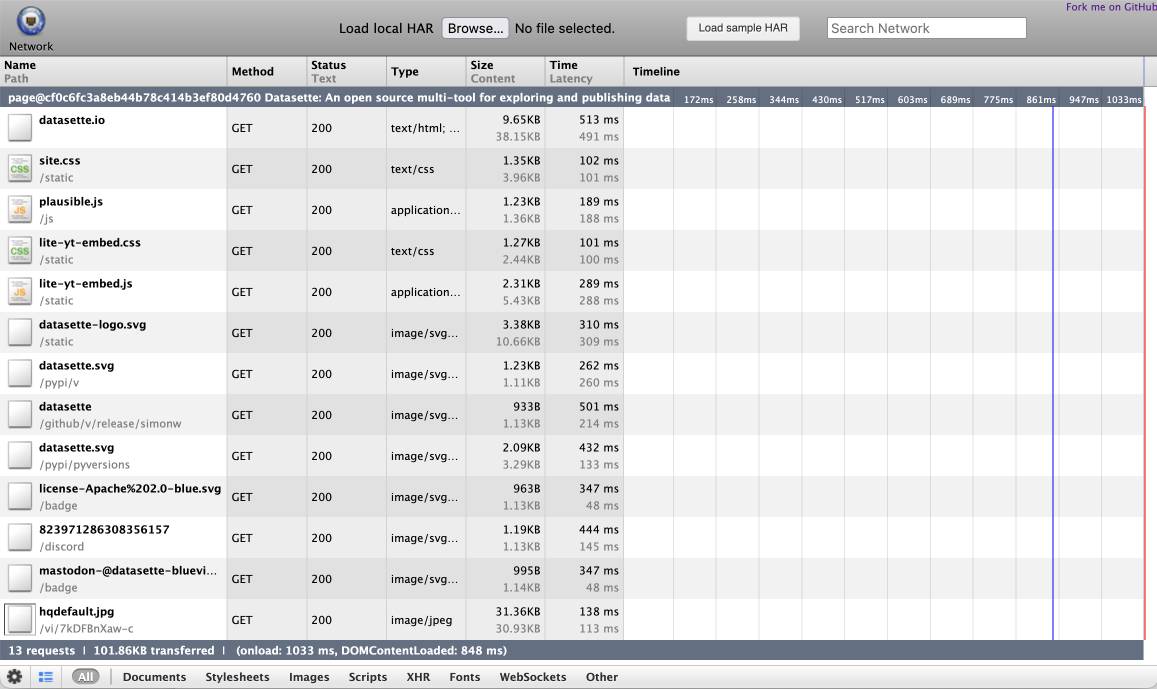
That JSON includes full copies of all of the responses, base64 encoded if they are binary files such as images.
You can add the --zip flag to instead get a datasette-io.har.zip file, containing JSON data in har.har but with the response bodies saved as separate files in that archive.
The shot-scraper multi command lets you run shot-scraper against multiple URLs in sequence, specified using a YAML file. That command now takes a --har option (or --har-zip or --har-file name-of-file), described in the documentation, which will produce a HAR at the same time as taking the screenshots.
Shots are usually defined in YAML that looks like this:
- output: example.com.png
url: http://www.example.com/
- output: w3c.org.png
url: https://www.w3.org/You can now omit the output: keys and generate a HAR file without taking any screenshots at all:
- url: http://www.example.com/
- url: https://www.w3.org/Run like this:
shot-scraper multi shots.yml --har
Which outputs:
Skipping screenshot of 'https://www.example.com/'
Skipping screenshot of 'https://www.w3.org/'
Wrote to HAR file: trace.har
shot-scraper is built on top of Playwright, and the new features use the browser.new_context(record_har_path=...) parameter.
LLM 0.20. New release of my LLM CLI tool and Python library. A bunch of accumulated fixes and features since the start of December, most notably:
- Support for OpenAI's o1 model - a significant upgrade from
o1-previewgiven its 200,000 input and 100,000 output tokens (o1-previewwas 128,000/32,768). #676 - Support for the
gpt-4o-audio-previewandgpt-4o-mini-audio-previewmodels, which can accept audio input:llm -m gpt-4o-audio-preview -a https://static.simonwillison.net/static/2024/pelican-joke-request.mp3#677 - A new
llm -x/--extractoption which extracts and returns the contents of the first fenced code block in the response. This is useful for prompts that generate code. #681 - A new
llm models -q 'search'option for searching available models - useful if you've installed a lot of plugins. Searches are case insensitive. #700
2024
Building Python tools with a one-shot prompt using uv run and Claude Projects
I’ve written a lot about how I’ve been using Claude to build one-shot HTML+JavaScript applications via Claude Artifacts. I recently started using a similar pattern to create one-shot Python utilities, using a custom Claude Project combined with the dependency management capabilities of uv.
[... 899 words]“Rules” that terminal programs follow. Julia Evans wrote down the unwritten rules of terminal programs. Lots of details in here I hadn’t fully understood before, like REPL programs that exit only if you hit Ctrl+D on an empty line.
LLM 0.19. I just released version 0.19 of LLM, my Python library and CLI utility for working with Large Language Models.
I released 0.18 a couple of weeks ago adding support for calling models from Python asyncio code. 0.19 improves on that, and also adds a new mechanism for models to report their token usage.
LLM can log those usage numbers to a SQLite database, or make then available to custom Python code.
My eventual goal with these features is to implement token accounting as a Datasette plugin so I can offer AI features in my SaaS platform without worrying about customers spending unlimited LLM tokens.
Those 0.19 release notes in full:
- Tokens used by a response are now logged to new
input_tokensandoutput_tokensinteger columns and atoken_detailsJSON string column, for the default OpenAI models and models from other plugins that implement this feature. #610llm promptnow takes a-u/--usageflag to display token usage at the end of the response.llm logs -u/--usageshows token usage information for logged responses.llm prompt ... --asyncresponses are now logged to the database. #641llm.get_models()andllm.get_async_models()functions, documented here. #640response.usage()and async responseawait response.usage()methods, returning aUsage(input=2, output=1, details=None)dataclass. #644response.on_done(callback)andawait response.on_done(callback)methods for specifying a callback to be executed when a response has completed, documented here. #653- Fix for bug running
llm chaton Windows 11. Thanks, Sukhbinder Singh. #495
I also released three new plugin versions that add support for the new usage tracking feature: llm-gemini 0.5, llm-claude-3 0.10 and llm-mistral 0.9.
Ask questions of SQLite databases and CSV/JSON files in your terminal
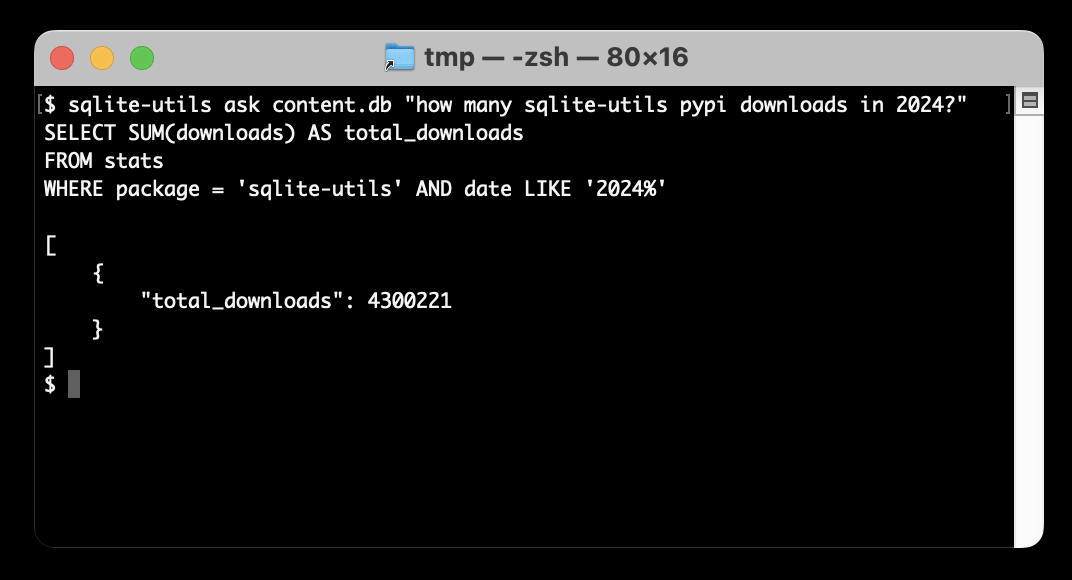
I built a new plugin for my sqlite-utils CLI tool that lets you ask human-language questions directly of SQLite databases and CSV/JSON files on your computer.
[... 723 words]Docling. MIT licensed document extraction Python library from the Deep Search team at IBM, who released Docling v2 on October 16th.
Here's the Docling Technical Report paper from August, which provides details of two custom models: a layout analysis model for figuring out the structure of the document (sections, figures, text, tables etc) and a TableFormer model specifically for extracting structured data from tables.
Those models are available on Hugging Face.
Here's how to try out the Docling CLI interface using uvx (avoiding the need to install it first - though since it downloads models it will take a while to run the first time):
uvx docling mydoc.pdf --to json --to md
This will output a mydoc.json file with complex layout information and a mydoc.md Markdown file which includes Markdown tables where appropriate.
The Python API is a lot more comprehensive. It can even extract tables as Pandas DataFrames:
from docling.document_converter import DocumentConverter converter = DocumentConverter() result = converter.convert("document.pdf") for table in result.document.tables: df = table.export_to_dataframe() print(df)
I ran that inside uv run --with docling python. It took a little while to run, but it demonstrated that the library works.
You can now run prompts against images, audio and video in your terminal using LLM

I released LLM 0.17 last night, the latest version of my combined CLI tool and Python library for interacting with hundreds of different Large Language Models such as GPT-4o, Llama, Claude and Gemini.
[... 1,399 words]python-imgcat (via) I was investigating options for displaying images in a terminal window (for multi-modal logging output of LLM) and I found this neat Python library for displaying images using iTerm 2.
It includes a CLI tool, which means you can run it without installation using uvx like this:
uvx imgcat filename.png

Run a prompt to generate and execute jq programs using llm-jq
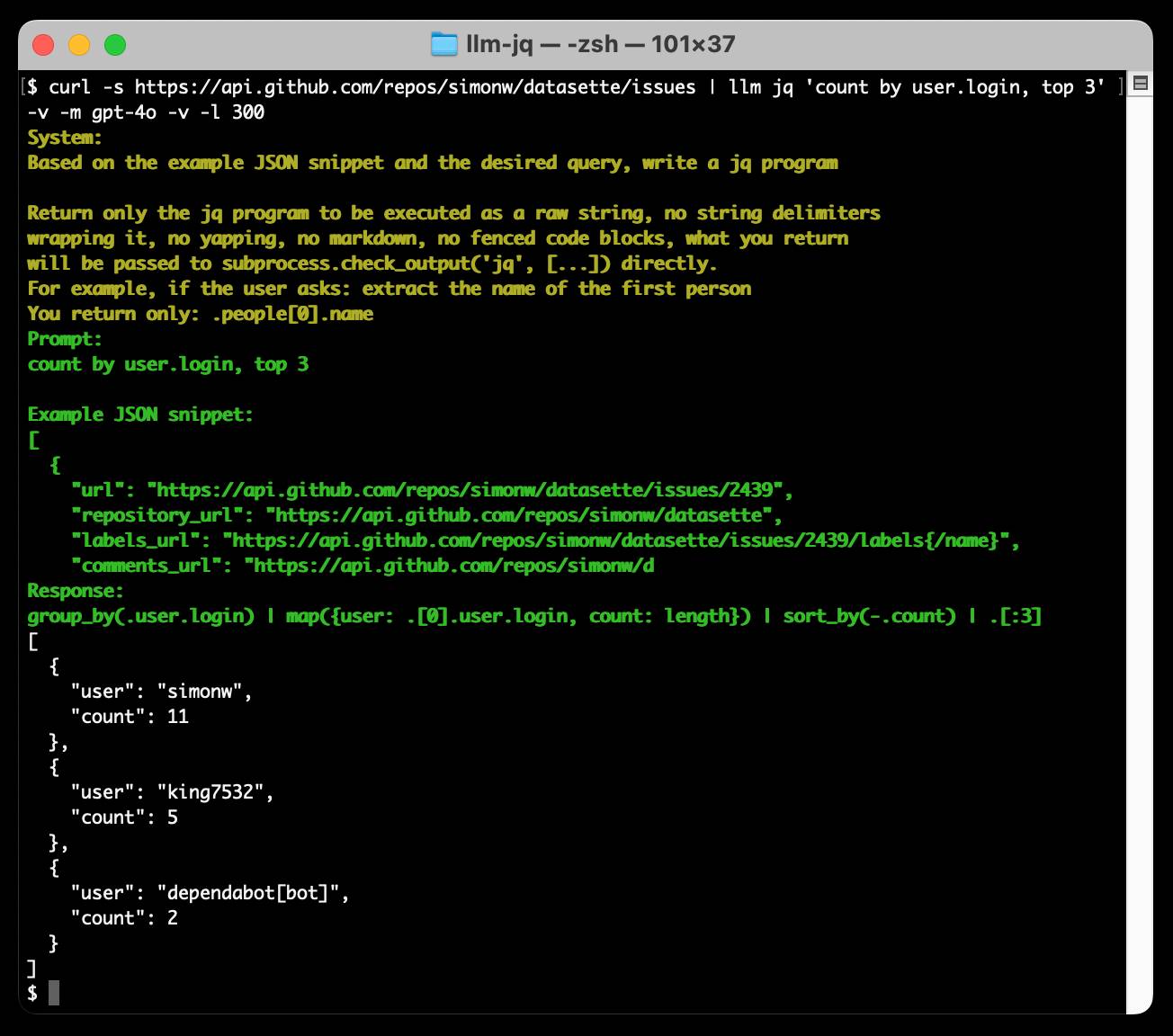
llm-jq is a brand new plugin for LLM which lets you pipe JSON directly into the llm jq command along with a human-language description of how you’d like to manipulate that JSON and have a jq program generated and executed for you on the fly.
TIL: Using uv to develop Python command-line applications.
I've been increasingly using uv to try out new software (via uvx) and experiment with new ideas, but I hadn't quite figured out the right way to use it for developing my own projects.
It turns out I was missing a few things - in particular the fact that there's no need to use uv pip at all when working with a local development environment, you can get by entirely on uv run (and maybe uv sync --extra test to install test dependencies) with no direct invocations of uv pip at all.
I bounced a few questions off Charlie Marsh and filled in the missing gaps - this TIL shows my new uv-powered process for hacking on Python CLI apps built using Click and my simonw/click-app cookecutter template.
files-to-prompt 0.3.
New version of my files-to-prompt CLI tool for turning a bunch of files into a prompt suitable for piping to an LLM, described here previously.
It now has a -c/--cxml flag for outputting the files in Claude XML-ish notation (XML-ish because it's not actually valid XML) using the format Anthropic describe as recommended for long context:
files-to-prompt llm-*/README.md --cxml | llm -m claude-3.5-sonnet \
--system 'return an HTML page about these plugins with usage examples' \
> /tmp/fancy.html
The format itself looks something like this:
<documents>
<document index="1">
<source>llm-anyscale-endpoints/README.md</source>
<document_content>
# llm-anyscale-endpoints
...
</document_content>
</document>
</documents>LLM 0.15. A new release of my LLM CLI tool for interacting with Large Language Models from the terminal (see this recent talk for plenty of demos).
This release adds support for the brand new GPT-4o mini:
llm -m gpt-4o-mini "rave about pelicans in Spanish"
It also sets that model as the default used by the tool if no other model is specified. This replaces GPT-3.5 Turbo, the default since the first release of LLM. 4o-mini is both cheaper and way more capable than 3.5 Turbo.