Blogmarks
Filters: Sorted by date
Conflating Overture Places Using DuckDB, Ollama, Embeddings, and More.
Drew Breunig's detailed tutorial on "conflation" - combining different geospatial data sources by de-duplicating address strings such as RESTAURANT LOS ARCOS,3359 FOOTHILL BLVD,OAKLAND,94601 and LOS ARCOS TAQUERIA,3359 FOOTHILL BLVD,OAKLAND,94601.
Drew uses an entirely offline stack based around Python, DuckDB and Ollama and finds that a combination of H3 geospatial tiles and mxbai-embed-large embeddings (though other embedding models should work equally well) gets really good results.
llama-3.2-webgpu (via) Llama 3.2 1B is a really interesting models, given its 128,000 token input and its tiny size (barely more than a GB).
This page loads a 1.24GB q4f16 ONNX build of the Llama-3.2-1B-Instruct model and runs it with a React-powered chat interface directly in the browser, using Transformers.js and WebGPU. Source code for the demo is here.
It worked for me just now in Chrome; in Firefox and Safari I got a “WebGPU is not supported by this browser” error message.
mlx-vlm (via) The MLX ecosystem of libraries for running machine learning models on Apple Silicon continues to expand. Prince Canuma is actively developing this library for running vision models such as Qwen-2 VL and Pixtral and LLaVA using Python running on a Mac.
I used uv to run it against this image with this shell one-liner:
uv run --with mlx-vlm \
python -m mlx_vlm.generate \
--model Qwen/Qwen2-VL-2B-Instruct \
--max-tokens 1000 \
--temp 0.0 \
--image https://static.simonwillison.net/static/2024/django-roadmap.png \
--prompt "Describe image in detail, include all text"
The --image option works equally well with a URL or a path to a local file on disk.
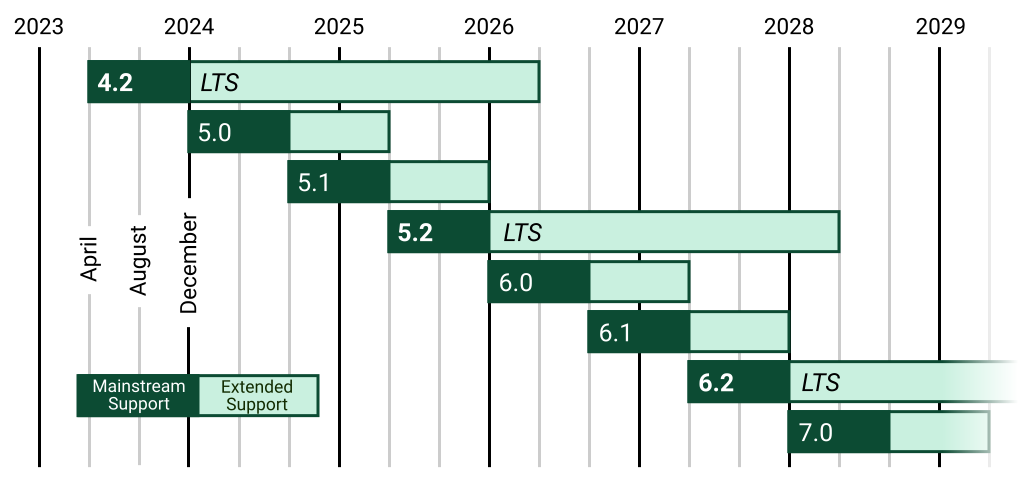
This first downloaded 4.1GB to my ~/.cache/huggingface/hub/models--Qwen--Qwen2-VL-2B-Instruct folder and then output this result, which starts:
The image is a horizontal timeline chart that represents the release dates of various software versions. The timeline is divided into years from 2023 to 2029, with each year represented by a vertical line. The chart includes a legend at the bottom, which distinguishes between different types of software versions.
Legend
Mainstream Support:
- 4.2 (2023)
- 5.0 (2024)
- 5.1 (2025)
- 5.2 (2026)
- 6.0 (2027) [...]
Ensuring a block is overridden in a Django template (via) Neat Django trick by Tom Carrick: implement a Django template tag that raises a custom exception, then you can use this pattern in your templates:
{% block title %}{% ensure_overridden %}{% endblock %}
To ensure you don't accidentally extend a base template but forget to fill out a critical block.
OpenFreeMap (via) New free map tile hosting service from Zsolt Ero:
OpenFreeMap lets you display custom maps on your website and apps for free. […] Using our public instance is completely free: there are no limits on the number of map views or requests. There’s no registration, no user database, no API keys, and no cookies. We aim to cover the running costs of our public instance through donations.
The site serves static vector tiles that work with MapLibre GL. It deliberately doesn’t offer any other services such as search or routing.
From the project README looks like it’s hosted on two Hetzner machines. I don’t think the public server is behind a CDN.
Part of the trick to serving the tiles efficiently is the way it takes advantage of Btrfs:
Production-quality hosting of 300 million tiny files is hard. The average file size is just 450 byte. Dozens of tile servers have been written to tackle this problem, but they all have their limitations.
The original idea of this project is to avoid using tile servers altogether. Instead, the tiles are directly served from Btrfs partition images + hard links using an optimised nginx config.
The self-hosting guide describes the scripts that are provided for downloading their pre-built tiles (needing a fresh Ubuntu server with 300GB of SSD and 4GB of RAM) or building the tiles yourself using Planetiler (needs 500GB of disk and 64GB of RAM).
Getting started is delightfully straightforward:
const map = new maplibregl.Map({
style: 'https://tiles.openfreemap.org/styles/liberty',
center: [13.388, 52.517],
zoom: 9.5,
container: 'map',
})
I got Claude to help build this demo showing a thousand random markers dotted around San Francisco. The 3D tiles even include building shapes!
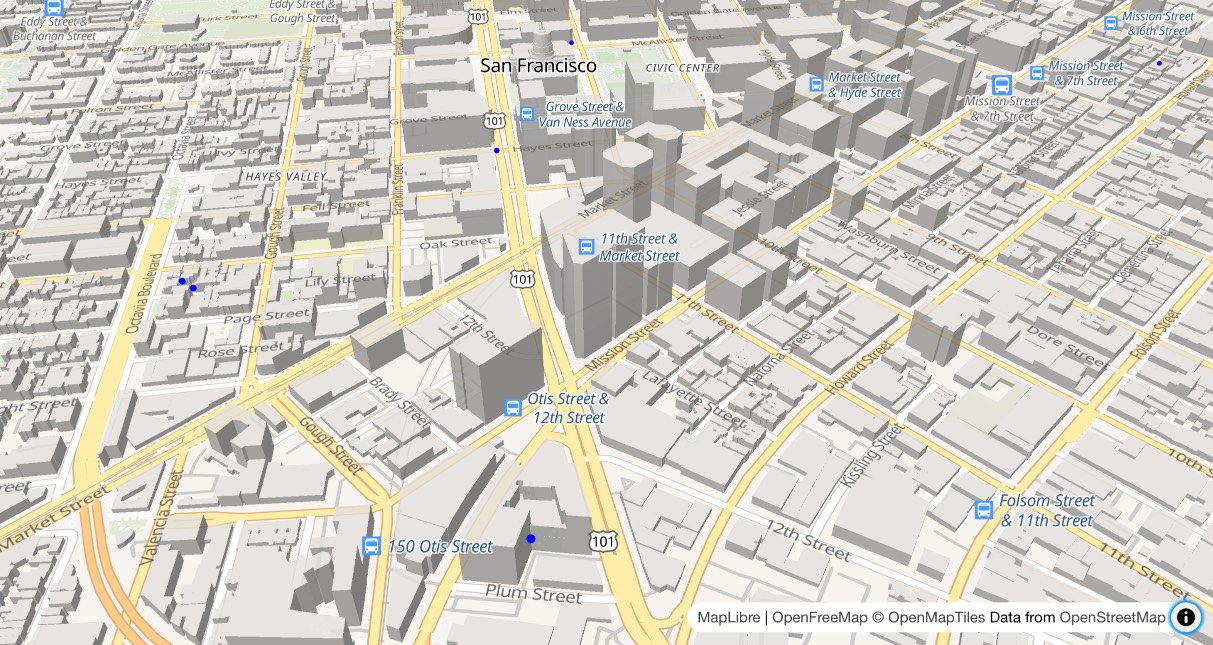
Zsolt built OpenFreeMap based on his experience running MapHub over the last 9 years. Here’s a 2018 interview about that project.
It’s pretty incredible that the OpenStreetMap and open geospatial stack has evolved to the point now where it’s economically feasible for an individual to offer a service like this. I hope this turns out to be sustainable. Hetzner charge just €1 per TB for bandwidth (S3 can cost $90/TB) which should help a lot.
DjangoTV (via) Brand new site by Jeff Triplett gathering together videos from Django conferences around the world. Here's Jeff's blog post introducing the project.
Some Go web dev notes. Julia Evans on writing small, self-contained web applications in Go:
In general everything about it feels like it makes projects easy to work on for 5 days, abandon for 2 years, and then get back into writing code without a lot of problems.
Go 1.22 introduced HTTP routing in February of this year, making it even more practical to build a web application using just the Go standard library.
Niche Museums: The Vincent and Ethel Simonetti Historic Tuba Collection. DjangoCon was in Durham, North Carolina this year and thanks to Atlas Obscura I found out about the fabulous Vincent and Ethel Simonetti Historic Tuba Collection. We got together a group of five for a visit and had a wonderful time being shown around the collection by curator Vincent Simonetti. This is my first update to Niche Museums in quite a while, it's nice to get that project rolling again.

django-plugin-datasette. I did some more work on my DJP plugin mechanism for Django at the DjangoCon US sprints today. I added a new plugin hook, asgi_wrapper(), released in DJP 0.3 and inspired by the similar hook in Datasette.
The hook only works for Django apps that are served using ASGI. It allows plugins to add their own wrapping ASGI middleware around the Django app itself, which means they can do things like attach entirely separate ASGI-compatible applications outside of the regular Django request/response cycle.
Datasette is one of those ASGI-compatible applications!
django-plugin-datasette uses that new hook to configure a new URL, /-/datasette/, which serves a full Datasette instance that scans through Django’s settings.DATABASES dictionary and serves an explore interface on top of any SQLite databases it finds there.
It doesn’t support authentication yet, so this will expose your entire database contents - probably best used as a local debugging tool only.
I did borrow some code from the datasette-mask-columns plugin to ensure that the password column in the auth_user column is reliably redacted. That column contains a heavily salted hashed password so exposing it isn’t necessarily a disaster, but I like to default to keeping hashes safe.
Llama 3.2. In further evidence that AI labs are terrible at naming things, Llama 3.2 is a huge upgrade to the Llama 3 series - they've released their first multi-modal vision models!
Today, we’re releasing Llama 3.2, which includes small and medium-sized vision LLMs (11B and 90B), and lightweight, text-only models (1B and 3B) that fit onto edge and mobile devices, including pre-trained and instruction-tuned versions.
The 1B and 3B text-only models are exciting too, with a 128,000 token context length and optimized for edge devices (Qualcomm and MediaTek hardware get called out specifically).
Meta partnered directly with Ollama to help with distribution, here's the Ollama blog post. They only support the two smaller text-only models at the moment - this command will get the 3B model (2GB):
ollama run llama3.2
And for the 1B model (a 1.3GB download):
ollama run llama3.2:1b
I had to first upgrade my Ollama by clicking on the icon in my macOS task tray and selecting "Restart to update".
The two vision models are coming to Ollama "very soon".
Once you have fetched the Ollama model you can access it from my LLM command-line tool like this:
pipx install llm
llm install llm-ollama
llm chat -m llama3.2:1b
I tried running my djp codebase through that tiny 1B model just now and got a surprisingly good result - by no means comprehensive, but way better than I would ever expect from a model of that size:
files-to-prompt **/*.py -c | llm -m llama3.2:1b --system 'describe this code'
Here's a portion of the output:
The first section defines several test functions using the
@djp.hookimpldecorator from the djp library. These hook implementations allow you to intercept and manipulate Django's behavior.
test_middleware_order: This function checks that the middleware order is correct by comparing theMIDDLEWAREsetting with a predefined list.test_middleware: This function tests various aspects of middleware:- It retrieves the response from the URL
/from-plugin/using theClientobject, which simulates a request to this view.- It checks that certain values are present in the response:
X-DJP-Middleware-AfterX-DJP-MiddlewareX-DJP-Middleware-Before[...]
I found the GGUF file that had been downloaded by Ollama in my ~/.ollama/models/blobs directory. The following command let me run that model directly in LLM using the llm-gguf plugin:
llm install llm-gguf
llm gguf register-model ~/.ollama/models/blobs/sha256-74701a8c35f6c8d9a4b91f3f3497643001d63e0c7a84e085bed452548fa88d45 -a llama321b
llm chat -m llama321b
Meta themselves claim impressive performance against other existing models:
Our evaluation suggests that the Llama 3.2 vision models are competitive with leading foundation models, Claude 3 Haiku and GPT4o-mini on image recognition and a range of visual understanding tasks. The 3B model outperforms the Gemma 2 2.6B and Phi 3.5-mini models on tasks such as following instructions, summarization, prompt rewriting, and tool-use, while the 1B is competitive with Gemma.
Here's the Llama 3.2 collection on Hugging Face. You need to accept the new Llama 3.2 Community License Agreement there in order to download those models.
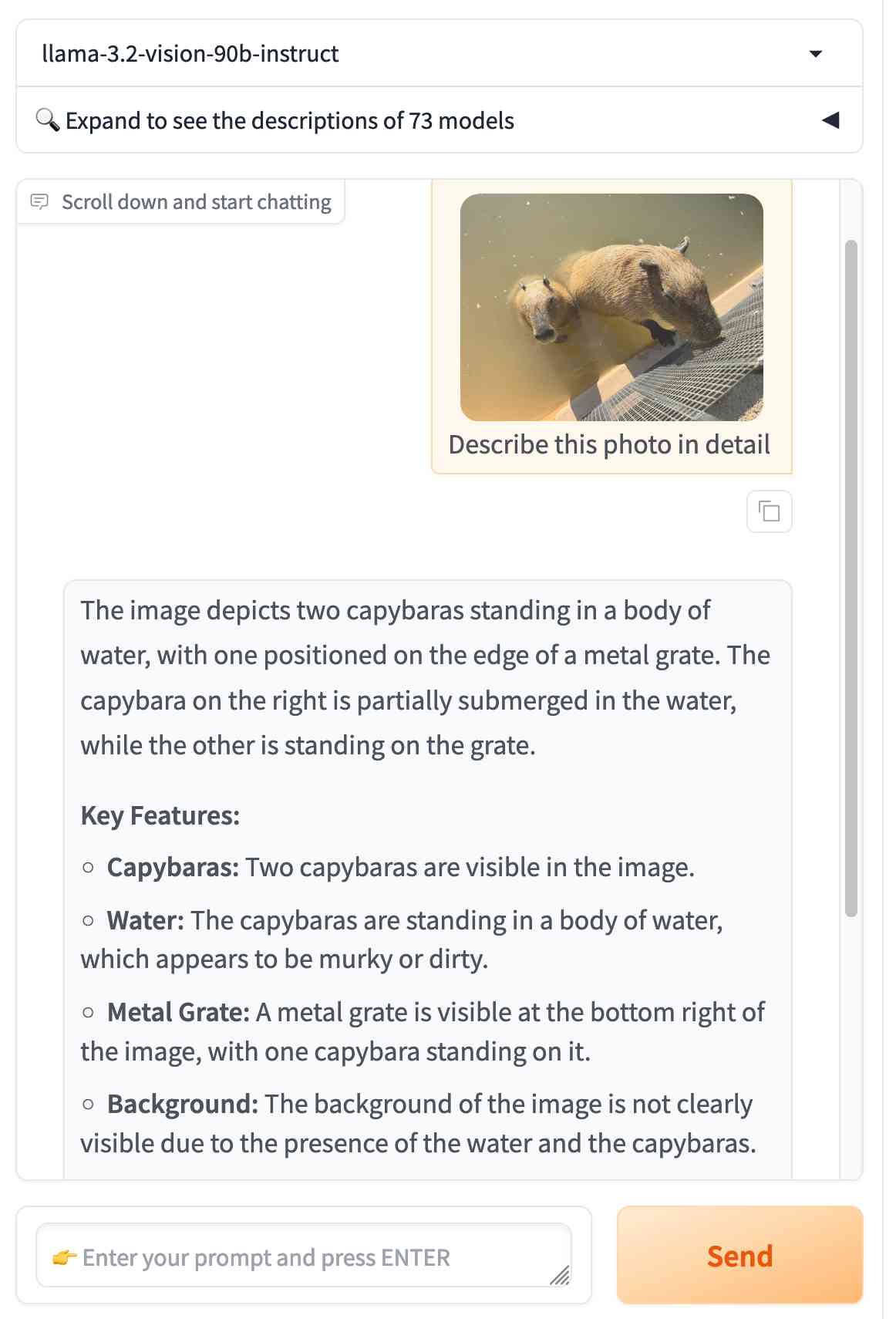
You can try the four new models out via the Chatbot Arena - navigate to "Direct Chat" there and select them from the dropdown menu. You can upload images directly to the chat there to try out the vision features.
Solving a bug with o1-preview, files-to-prompt and LLM.
I added a new feature to DJP this morning: you can now have plugins specify their middleware in terms of how it should be positioned relative to other middleware - inserted directly before or directly after django.middleware.common.CommonMiddleware for example.
At one point I got stuck with a weird test failure, and after ten minutes of head scratching I decided to pipe the entire thing into OpenAI's o1-preview to see if it could spot the problem. I used files-to-prompt to gather the code and LLM to run the prompt:
files-to-prompt **/*.py -c | llm -m o1-preview "
The middleware test is failing showing all of these - why is MiddlewareAfter repeated so many times?
['MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware2', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware4', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware2', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware5', 'MiddlewareAfter', 'Middleware3', 'MiddlewareAfter', 'Middleware', 'MiddlewareBefore']"The model whirled away for a few seconds and spat out an explanation of the problem - one of my middleware classes was accidentally calling self.get_response(request) in two different places.
I did enjoy how o1 attempted to reference the relevant Django documentation and then half-repeated, half-hallucinated a quote from it:

This took 2,538 input tokens and 4,354 output tokens - by my calculations at $15/million input and $60/million output that prompt cost just under 30 cents.
The Pragmatic Engineer Podcast: AI tools for software engineers, but without the hype – with Simon Willison. Gergely Orosz has a brand new podcast, and I was the guest for the first episode. We covered a bunch of ground, but my favorite topic was an exploration of the (very legitimate) reasons that many engineers are resistant to taking advantage of AI-assisted programming tools.
Updated production-ready Gemini models.
Two new models from Google Gemini today: gemini-1.5-pro-002 and gemini-1.5-flash-002. Their -latest aliases will update to these new models in "the next few days", and new -001 suffixes can be used to stick with the older models. The new models benchmark slightly better in various ways and should respond faster.
Flash continues to have a 1,048,576 input token and 8,192 output token limit. Pro is 2,097,152 input tokens.
Google also announced a significant price reduction for Pro, effective on the 1st of October. Inputs less than 128,000 tokens drop from $3.50/million to $1.25/million (above 128,000 tokens it's dropping from $7 to $5) and output costs drop from $10.50/million to $2.50/million ($21 down to $10 for the >128,000 case).
For comparison, GPT-4o is currently $5/m input and $15/m output and Claude 3.5 Sonnet is $3/m input and $15/m output. Gemini 1.5 Pro was already the cheapest of the frontier models and now it's even cheaper.
Correction: I missed gpt-4o-2024-08-06 which is listed later on the OpenAI pricing page and priced at $2.50/m input and $10/m output. So the new Gemini 1.5 Pro prices are undercutting that.
Gemini has always offered finely grained safety filters - it sounds like those are now turned down to minimum by default, which is a welcome change:
For the models released today, the filters will not be applied by default so that developers can determine the configuration best suited for their use case.
Also interesting: they've tweaked the expected length of default responses:
For use cases like summarization, question answering, and extraction, the default output length of the updated models is ~5-20% shorter than previous models.
nanodjango. Richard Terry demonstrated this in a lightning talk at DjangoCon US today. It's the latest in a long line of attempts to get Django to work with a single file (I had a go at this problem 15 years ago with djng) but this one is really compelling.
I tried nanodjango out just now and it works exactly as advertised. First install it like this:
pip install nanodjango
Create a counter.py file:
from django.db import models from nanodjango import Django app = Django() @app.admin # Registers with the Django admin class CountLog(models.Model): timestamp = models.DateTimeField(auto_now_add=True) @app.route("/") def count(request): CountLog.objects.create() return f"<p>Number of page loads: {CountLog.objects.count()}</p>"
Then run it like this (it will run migrations and create a superuser as part of that first run):
nanodjango run counter.py
That's it! This gave me a fully configured Django application with models, migrations, the Django Admin configured and a bunch of other goodies such as Django Ninja for API endpoints.
Here's the full documentation.
XKCD 1425 (Tasks) turns ten years old today (via) One of the all-time great XKCDs. It's amazing that "check whether the photo is of a bird" has gone from PhD-level to trivially easy to solve (with a vision LLM, or CLIP, or ResNet+ImageNet among others).

The key idea still very much stands though. Understanding the difference between easy and hard challenges in software development continues to require an enormous depth of experience.
I'd argue that LLMs have made this even worse.
Understanding what kind of tasks LLMs can and cannot reliably solve remains incredibly difficult and unintuitive. They're computer systems that are terrible at maths and that can't reliably lookup facts!
On top of that, the rise of AI-assisted programming tools means more people than ever are beginning to create their own custom software.
These brand new AI-assisted proto-programmers are having a crash course in this easy-v.s.-hard problem.
I saw someone recently complaining that they couldn't build a Claude Artifact that could analyze images, even though they knew Claude itself could do that. Understanding why that's not possible involves understanding how the CSP headers that are used to serve Artifacts prevent the generated code from making its own API calls out to an LLM!
Things I’ve Learned Serving on the Board of The Perl Foundation (via) My post about the PSF board inspired Perl Foundation secretary Makoto Nozaki to publish similar notes about how TPF (also known since 2019 as TPRF, for The Perl and Raku Foundation) operates.
Seeing this level of explanation about other open source foundations is fascinating. I’d love to see more of these.
Along those lines, I found the 2024 Financial Report from the Zig foundation really interesting too.
simonw/docs cookiecutter template. Over the last few years I’ve settled on the combination of Sphinx, the Furo theme and the myst-parser extension (enabling Markdown in place of reStructuredText) as my documentation toolkit of choice, maintained in GitHub and hosted using ReadTheDocs.
My LLM and shot-scraper projects are two examples of that stack in action.
Today I wanted to spin up a new documentation site so I finally took the time to construct a cookiecutter template for my preferred configuration. You can use it like this:
pipx install cookiecutter
cookiecutter gh:simonw/docs
Or with uv:
uv tool run cookiecutter gh:simonw/docs
Answer a few questions:
[1/3] project (): shot-scraper
[2/3] author (): Simon Willison
[3/3] docs_directory (docs):
And it creates a docs/ directory ready for you to start editing docs:
cd docs
pip install -r requirements.txt
make livehtml
Jiter (via) One of the challenges in dealing with LLM streaming APIs is the need to parse partial JSON - until the stream has ended you won't have a complete valid JSON object, but you may want to display components of that JSON as they become available.
I've solved this previously using the ijson streaming JSON library, see my previous TIL.
Today I found out about Jiter, a new option from the team behind Pydantic. It's written in Rust and extracted from pydantic-core, so the Python wrapper for it can be installed using:
pip install jiter
You can feed it an incomplete JSON bytes object and use partial_mode="on" to parse the valid subset:
import jiter partial_json = b'{"name": "John", "age": 30, "city": "New Yor' jiter.from_json(partial_json, partial_mode="on") # {'name': 'John', 'age': 30}
Or use partial_mode="trailing-strings" to include incomplete string fields too:
jiter.from_json(partial_json, partial_mode="trailing-strings") # {'name': 'John', 'age': 30, 'city': 'New Yor'}
The current README was a little thin, so I submiitted a PR with some extra examples. I got some help from files-to-prompt and Claude 3.5 Sonnet):
cd crates/jiter-python/ && files-to-prompt -c README.md tests | llm -m claude-3.5-sonnet --system 'write a new README with comprehensive documentation'
How streaming LLM APIs work.
New TIL. I used curl to explore the streaming APIs provided by OpenAI, Anthropic and Google Gemini and wrote up detailed notes on what I learned.
Also includes example code for receiving streaming events in Python with HTTPX and receiving streaming events in client-side JavaScript using fetch().
Markdown and Math Live Renderer.
Another of my tiny Claude-assisted JavaScript tools. This one lets you enter Markdown with embedded mathematical expressions (like $ax^2 + bx + c = 0$) and live renders those on the page, with an HTML version using MathML that you can export through copy and paste.

Here's the Claude transcript. I started by asking:
Are there any client side JavaScript markdown libraries that can also handle inline math and render it?
Claude gave me several options including the combination of Marked and KaTeX, so I followed up by asking:
Build an artifact that demonstrates Marked plus KaTeX - it should include a text area I can enter markdown in (repopulated with a good example) and live update the rendered version below. No react.
Which gave me this artifact, instantly demonstrating that what I wanted to do was possible.
I iterated on it a tiny bit to get to the final version, mainly to add that HTML export and a Copy button. The final source code is here.
YouTube Thumbnail Viewer.
I wanted to find the best quality thumbnail image for a YouTube video, so I could use it as a social media card. I know from past experience that GPT-4 has memorized the various URL patterns for img.youtube.com, so I asked it to guess the URL for my specific video.
This piqued my interest as to what the other patterns were, so I got it to spit those out too. Then, to save myself from needing to look those up again in the future, I asked it to build me a little HTML and JavaScript tool for turning a YouTube video URL into a set of visible thumbnails.
I iterated on the code a bit more after pasting it into Claude and ended up with this, now hosted in my tools collection.
Introducing Contextual Retrieval (via) Here's an interesting new embedding/RAG technique, described by Anthropic but it should work for any embedding model against any other LLM.
One of the big challenges in implementing semantic search against vector embeddings - often used as part of a RAG system - is creating "chunks" of documents that are most likely to semantically match queries from users.
Anthropic provide this solid example where semantic chunks might let you down:
Imagine you had a collection of financial information (say, U.S. SEC filings) embedded in your knowledge base, and you received the following question: "What was the revenue growth for ACME Corp in Q2 2023?"
A relevant chunk might contain the text: "The company's revenue grew by 3% over the previous quarter." However, this chunk on its own doesn't specify which company it's referring to or the relevant time period, making it difficult to retrieve the right information or use the information effectively.
Their proposed solution is to take each chunk at indexing time and expand it using an LLM - so the above sentence would become this instead:
This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter.
This chunk was created by Claude 3 Haiku (their least expensive model) using the following prompt template:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
Here's the really clever bit: running the above prompt for every chunk in a document could get really expensive thanks to the inclusion of the entire document in each prompt. Claude added context caching last month, which allows you to pay around 1/10th of the cost for tokens cached up to your specified beakpoint.
By Anthropic's calculations:
Assuming 800 token chunks, 8k token documents, 50 token context instructions, and 100 tokens of context per chunk, the one-time cost to generate contextualized chunks is $1.02 per million document tokens.
Anthropic provide a detailed notebook demonstrating an implementation of this pattern. Their eventual solution combines cosine similarity and BM25 indexing, uses embeddings from Voyage AI and adds a reranking step powered by Cohere.
The notebook also includes an evaluation set using JSONL - here's that evaluation data in Datasette Lite.
Moshi (via) Moshi is "a speech-text foundation model and full-duplex spoken dialogue framework". It's effectively a text-to-text model - like an LLM but you input audio directly to it and it replies with its own audio.
It's fun to play around with, but it's not particularly useful in comparison to other pure text models: I tried to talk to it about California Brown Pelicans and it gave me some very basic hallucinated thoughts about California Condors instead.
It's very easy to run locally, at least on a Mac (and likely on other systems too). I used uv and got the 8 bit quantized version running as a local web server using this one-liner:
uv run --with moshi_mlx python -m moshi_mlx.local_web -q 8
That downloads ~8.17G of model to a folder in ~/.cache/huggingface/hub/ - or you can use -q 4 and get a 4.81G version instead (albeit even lower quality).
The web’s clipboard, and how it stores data of different types.
Alex Harri's deep dive into the Web clipboard API, the more recent alternative to the old document.execCommand() mechanism for accessing the clipboard.
There's a lot to understand here! Some of these APIs have a history dating back to Internet Explorer 4 in 1997, and there have been plenty of changes over the years to account for improved understanding of the security risks of allowing untrusted code to interact with the system clipboard.
Today, the most reliable data formats for interacting with the clipboard are the "standard" formats of text/plain, text/html and image/png.
Figma does a particularly clever trick where they share custom Figma binary data structures by encoding them as base64 in data-metadata and data-buffer attributes on a <span> element, then write the result to the clipboard as HTML. This enables copy-and-paste between the Figma web and native apps via the system clipboard.
Oracle, it’s time to free JavaScript. (via) Oracle have held the trademark on JavaScript since their acquisition of Sun Microsystems in 2009. They’ve continued to renew that trademark over the years despite having no major products that use the mark.
Their December 2019 renewal included a screenshot of the Node.js homepage as a supporting specimen!
Now a group lead by a team that includes Ryan Dahl and Brendan Eich is coordinating a legal challenge to have the USPTO treat the trademark as abandoned and “recognize it as a generic name for the world’s most popular programming language, which has multiple implementations across the industry.”
Serializing package requirements in marimo notebooks. The latest release of Marimo - a reactive alternative to Jupyter notebooks - has a very neat new feature enabled by its integration with uv:
One of marimo’s goals is to make notebooks reproducible, down to the packages used in them. To that end, it’s now possible to create marimo notebooks that have their package requirements serialized into them as a top-level comment.
This takes advantage of the PEP 723 inline metadata mechanism, where a code comment at the top of a Python file can list package dependencies (and their versions).
I tried this out by installing marimo using uv:
uv tool install --python=3.12 marimo
Then grabbing one of their example notebooks:
wget 'https://raw.githubusercontent.com/marimo-team/spotlights/main/001-anywidget/tldraw_colorpicker.py'
And running it in a fresh dependency sandbox like this:
marimo run --sandbox tldraw_colorpicker.py
Also neat is that when editing a notebook using marimo edit:
marimo edit --sandbox notebook.py
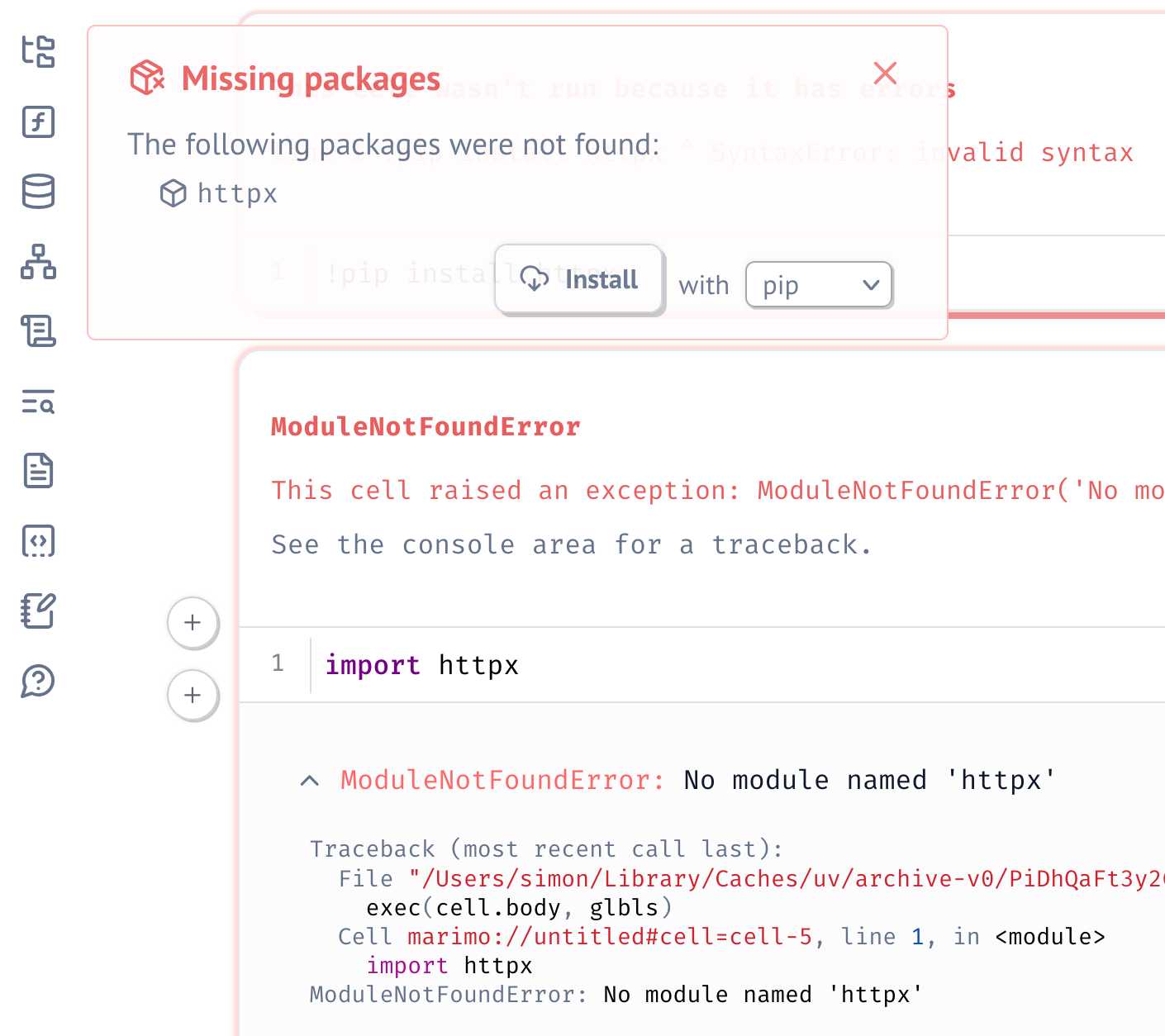
Just importing a missing package is enough for Marimo to prompt to add that to the dependencies - at which point it automatically adds that package to the comment at the top of the file:
Supercharging Developer Productivity with ChatGPT and Claude with Simon Willison (via) I'm the guest for the latest episode of the TWIML AI podcast - This Week in Machine Learning & AI, hosted by Sam Charrington.
We mainly talked about how I use LLM tooling for my own work - Claude, ChatGPT, Code Interpreter, Claude Artifacts, LLM and GitHub Copilot - plus a bit about my experiments with local models.
UV — I am (somewhat) sold
(via)
Oliver Andrich's detailed notes on adopting uv. Oliver has some pretty specific requirements:
I need to have various Python versions installed locally to test my work and my personal projects. Ranging from Python 3.8 to 3.13. [...] I also require decent dependency management in my projects that goes beyond manually editing a
pyproject.tomlfile. Likewise, I am way too accustomed topoetry add .... And I run a number of Python-based tools --- djhtml, poetry, ipython, llm, mkdocs, pre-commit, tox, ...
He's braver than I am!
I started by removing all Python installations, pyenv, pipx and Homebrew from my machine. Rendering me unable to do my work.
Here's a neat trick: first install a specific Python version with uv like this:
uv python install 3.11
Then create an alias to run it like this:
alias python3.11 'uv run --python=3.11 python3'
And install standalone tools with optional extra dependencies like this (a replacement for pipx and pipx inject):
uv tool install --python=3.12 --with mkdocs-material mkdocs
Oliver also links to Anže Pečar's handy guide on using UV with Django.
How to succeed in MrBeast production (leaked PDF). Whether or not you enjoy MrBeast’s format of YouTube videos (here’s a 2022 Rolling Stone profile if you’re unfamiliar), this leaked onboarding document for new members of his production company is a compelling read.
It’s a snapshot of what it takes to run a massive scale viral YouTube operation in the 2020s, as well as a detailed description of a very specific company culture evolved to fulfill that mission.
It starts in the most on-brand MrBeast way possible:
I genuinely believe if you attently read and understand the knowledge here you will be much better set up for success. So, if you read this book and pass a quiz I’ll give you $1,000.
Everything is focused very specifically on YouTube as a format:
Your goal here is to make the best YOUTUBE videos possible. That’s the number one goal of this production company. It’s not to make the best produced videos. Not to make the funniest videos. Not to make the best looking videos. Not the highest quality videos.. It’s to make the best YOUTUBE videos possible.
The MrBeast definition of A, B and C-team players is one I haven’t heard before:
A-Players are obsessive, learn from mistakes, coachable, intelligent, don’t make excuses, believe in Youtube, see the value of this company, and are the best in the goddamn world at their job. B-Players are new people that need to be trained into A-Players, and C-Players are just average employees. […] They arn’t obsessive and learning. C-Players are poisonous and should be transitioned to a different company IMMEDIATELY. (It’s okay we give everyone severance, they’ll be fine).
The key characteristic outlined here, if you read between the hustle-culture lines, is learning. Employees who constantly learn are valued. Employees who don’t are not.
There’s a lot of stuff in there about YouTube virality, starting with the Click Thru Rate (CTR) for the all-important video thumbnails:
This is what dictates what we do for videos. “I Spent 50 Hours In My Front Yard” is lame and you wouldn’t click it. But you would hypothetically click “I Spent 50 Hours In Ketchup”. Both are relatively similar in time/effort but the ketchup one is easily 100x more viral. An image of someone sitting in ketchup in a bathtub is exponentially more interesting than someone sitting in their front yard.
The creative process for every video they produce starts with the title and thumbnail. These set the expectations for the viewer, and everything that follows needs to be defined with those in mind. If a viewer feels their expectations are not being matched, they’ll click away - driving down the crucial Average View Duration that informs how much the video is promoted by YouTube’s all-important mystical algorithms.
MrBeast videos have a strictly defined formula, outlined in detail on pages 6-10.
The first minute captures the viewer’s attention and demonstrates that their expectations from the thumbnail will be met. Losing 21 million viewers in the first minute after 60 million initial clicks is considered a reasonably good result! Minutes 1-3, 3-6 and 6-end all have their own clearly defined responsibilities as well.
Ideally, a video will feature something they call the “wow factor”:
An example of the “wow factor” would be our 100 days in the circle video. We offered someone $500,000 if they could live in a circle in a field for 100 days (video) and instead of starting with his house in the circle that he would live in, we bring it in on a crane 30 seconds into the video. Why? Because who the fuck else on Youtube can do that lol.
Chapter 2 (pages 10-24) is about creating content. This is crammed with insights into what it takes to produce surprising, spectacular and very expensive content for YouTube.
A lot of this is about coordination and intense management of your dependencies:
I want you to look them in the eyes and tell them they are the bottleneck and take it a step further and explain why they are the bottleneck so you both are on the same page. “Tyler, you are my bottleneck. I have 45 days to make this video happen and I can not begin to work on it until I know what the contents of the video is. I need you to confirm you understand this is important and we need to set a date on when the creative will be done.” […] Every single day you must check in on Tyler and make sure he is still on track to hit the target date.
It also introduces the concept of “critical components”:
Critical components are the things that are essential to your video. If I want to put 100 people on an island and give it away to one of them, then securing an island is a critical component. It doesn’t matter how well planned the challenges on the island are, how good the weather is, etc. Without that island there is no video.
[…]
Critical Components can come from literally anywhere and once something you’re working on is labeled as such, you treat it like your baby. WITHOUT WHAT YOU’RE WORKING ON WE DO NOT HAVE A VIDEO! Protect it at all costs, check in on it 10x a day, obsess over it, make a backup, if it requires shipping pay someone to pick it up and drive it, don’t trust standard shipping, and speak up the second anything goes wrong. The literal second. Never coin flip a Critical Component (that means you’re coinfliping the video aka a million plus dollars)
There’s a bunch of stuff about communication, with a strong bias towards “higher forms of communication”: in-person beats a phone call beats a text message beats an email.
Unsurprisingly for this organization, video is a highly valued tool for documenting work:
Which is more important, that one person has a good mental grip of something or that their entire team of 10 people have a good mental grip on something? Obviously the team. And the easiest way to bring your team up to the same page is to freaken video everything and store it where they can constantly reference it. A lot of problems can be solved if we just video sets and ask for videos when ordering things.
I enjoyed this note:
Since we are on the topic of communication, written communication also does not constitute communication unless they confirm they read it.
And this bit about the value of consultants:
Consultants are literally cheat codes. Need to make the world's largest slice of cake? Start off by calling the person who made the previous world’s largest slice of cake lol. He’s already done countless tests and can save you weeks worth of work. […] In every single freakin task assigned to you, always always always ask yourself first if you can find a consultant to help you.
Here’s a darker note from the section “Random things you should know”:
Do not leave consteatants waiting in the sun (ideally waiting in general) for more than 3 hours. Squid game it cost us $500,000 and boys vs girls it got a lot of people out. Ask James to know more
And to finish, this note on budgeting:
I want money spent to be shown on camera ideally. If you’re spending over $10,000 on something and it won’t be shown on camera, seriously think about it.
I’m always interested in finding management advice from unexpected sources. For example, I love The Eleven Laws of Showrunning as a case study in managing and successfully delegating for a large, creative project.
I don’t think this MrBeast document has as many lessons directly relevant to my own work, but as an honest peek under the hood of a weirdly shaped and absurdly ambitious enterprise it’s legitimately fascinating.
Speed matters (via) Jamie Brandon in 2021, talking about the importance of optimizing for the speed at which you can work as a developer:
Being 10x faster also changes the kinds of projects that are worth doing.
Last year I spent something like 100 hours writing a text editor. […] If I was 10x slower it would have been 20-50 weeks. Suddenly that doesn't seem like such a good deal any more - what a waste of a year!
It’s not just about speed of writing code:
When I think about speed I think about the whole process - researching, planning, designing, arguing, coding, testing, debugging, documenting etc.
Often when I try to convince someone to get faster at one of those steps, they'll argue that the others are more important so it's not worthwhile trying to be faster. Eg choosing the right idea is more important than coding the wrong idea really quickly.
But that's totally conditional on the speed of everything else! If you could code 10x as fast then you could try out 10 different ideas in the time it would previously have taken to try out 1 idea. Or you could just try out 1 idea, but have 90% of your previous coding time available as extra idea time.
Jamie’s model here helps explain the effect I described in AI-enhanced development makes me more ambitious with my projects. Prompting an LLM to write portions of my code for me gives me that 5-10x boost in the time I spend typing code into a computer, which has a big effect on my ambitions despite being only about 10% of the activities I perform relevant to building software.
I also increasingly lean on LLMs as assistants in the research phase - exploring library options, building experimental prototypes - and for activities like writing tests and even a little bit of documentation.