Entries Links Quotes Notes Guides Elsewhere
April 25, 2026
Since GPT-5.4, we’ve unified Codex and the main model into a single system, so there’s no separate coding line anymore.
GPT-5.5 takes this further, with strong gains in agentic coding, computer use, and any task on a computer.
— Romain Huet, confirming OpenAI won't release a GPT-5.5-Codex model
GPT-5.5 prompting guide. Now that GPT-5.5 is available in the API, OpenAI have released a wealth of useful tips on how best to prompt the new model.
Here's a neat trick they recommend for applications that might spend considerable time thinking before returning a user-visible response:
Before any tool calls for a multi-step task, send a short user-visible update that acknowledges the request and states the first step. Keep it to one or two sentences.
I've already noticed their Codex app doing this, and it does make longer running tasks feel less like the model has crashed.
OpenAI suggest running the following in Codex to upgrade your existing code using advice embedded in their openai-docs skill:
$openai-docs migrate this project to gpt-5.5
The upgrade guide the coding agent will follow is this one, which even includes light instructions on how to rewrite prompts to better fit the model.
Also relevant is the Using GPT-5.5 guide, which opens with this warning:
To get the most out of GPT-5.5, treat it as a new model family to tune for, not a drop-in replacement for
gpt-5.2orgpt-5.4. Begin migration with a fresh baseline instead of carrying over every instruction from an older prompt stack. Start with the smallest prompt that preserves the product contract, then tune reasoning effort, verbosity, tool descriptions, and output format against representative examples.
Interesting to see OpenAI recommend starting from scratch rather than trusting that existing prompts optimized for previous models will continue to work effectively with GPT-5.5.
April 24, 2026
- New GPT-5.5 OpenAI model:
llm -m gpt-5.5. #1418- New option to set the text verbosity level for GPT-5+ OpenAI models:
-o verbosity low. Values arelow,medium,high.- New option for setting the image detail level used for image attachments to OpenAI models:
-o image_detail low- values arelow,highandauto, and GPT-5.4 and 5.5 also acceptoriginal.- Models listed in
extra-openai-models.yamlare now also registered as asynchronous. #1395
The people do not yearn for automation (via) This written and video essay by Nilay Patel explores why AI is unpopular with the general public even as usage numbers for ChatGPT continue to skyrocket.
It’s a superb piece of commentary, and something I expect I’ll be thinking about for a long time to come.
Nilay’s core idea is that people afflicted with “software brain” - who see the world as something to be automated as much as possible, and attempt to model everything in terms of information flows and data - are becoming detached from everyone else.
[…] software brain has ruled the business world for a long time. AI has just made it easier than ever for more people to make more software than ever before — for every kind of business to automate big chunks of itself with software. It’s everywhere: the absolute cutting edge of advertising and marketing is automation with AI. It’s not being a creative.
But: not everything is a business. Not everything is a loop! The entire human experience cannot be captured in a database. That’s the limit of software brain. That’s why people hate AI. It flattens them.
Regular people don’t see the opportunity to write code as an opportunity at all. The people do not yearn for automation. I’m a full-on smart home sicko; the lights and shades and climate controls of my house are automated in dozens of ways. But huge companies like Apple, Google and Amazon have struggled for over a decade now to make regular people care about smart home automation at all. And they just don’t.
DeepSeek V4—almost on the frontier, a fraction of the price

Chinese AI lab DeepSeek’s last model release was V3.2 (and V3.2 Speciale) last December. They just dropped the first of their hotly anticipated V4 series in the shape of two preview models, DeepSeek-V4-Pro and DeepSeek-V4-Flash.
[... 703 words]LLM reports prompt durations in milliseconds and I got fed up of having to think about how to convert those to seconds and minutes.
This week's edition of my email newsletter (aka content from this blog delivered to your inbox) features 4 pelicans riding bicycles, 1 possum on an e-scooter, up to 5 raccoons with ham radios hiding in crowds, 5 blog posts, 8 links, 3 quotes and a new chapter of my Agentic Engineering Patterns guide.
russellromney/honker (via) "Postgres NOTIFY/LISTEN semantics" for SQLite, implemented as a Rust SQLite extension and various language bindings to help make use of it.
The design of this looks very solid. It lets you write Python code for queues that looks like this:
import honker db = honker.open("app.db") emails = db.queue("emails") emails.enqueue({"to": "alice@example.com"}) # Consume (in a worker process) async for job in emails.claim("worker-1"): send(job.payload) job.ack()
And Kafka-style durable streams like this:
stream = db.stream("user-events") with db.transaction() as tx: tx.execute("UPDATE users SET name=? WHERE id=?", [name, uid]) stream.publish({"user_id": uid, "change": "name"}, tx=tx) async for event in stream.subscribe(consumer="dashboard"): await push_to_browser(event)
It also adds 20+ custom SQL functions including these two:
SELECT notify('orders', '{"id":42}');
SELECT honker_stream_read_since('orders', 0, 1000);The extension requires WAL mode, and workers can poll the .db-wal file with a stat call every 1ms to get as close to real-time as possible without the expense of running a full SQL query.
honker implements the transactional outbox pattern, which ensures items are only queued if a transaction successfully commits. My favorite explanation of that pattern remains Transactionally Staged Job Drains in Postgres by Brandur Leach. It's great to see a new implementation of that pattern for SQLite.
An update on recent Claude Code quality reports (via) It turns out the high volume of complaints that Claude Code was providing worse quality results over the past two months was grounded in real problems.
The models themselves were not to blame, but three separate issues in the Claude Code harness caused complex but material problems which directly affected users.
Anthropic's postmortem describes these in detail. This one in particular stood out to me:
On March 26, we shipped a change to clear Claude's older thinking from sessions that had been idle for over an hour, to reduce latency when users resumed those sessions. A bug caused this to keep happening every turn for the rest of the session instead of just once, which made Claude seem forgetful and repetitive.
I frequently have Claude Code sessions which I leave for an hour (or often a day or longer) before returning to them. Right now I have 11 of those (according to ps aux | grep 'claude ') and that's after closing down dozens more the other day.
I estimate I spend more time prompting in these "stale" sessions than sessions that I've recently started!
If you're building agentic systems it's worth reading this article in detail - the kinds of bugs that affect harnesses are deeply complicated, even if you put aside the inherent non-deterministic nature of the models themselves.
Serving the For You feed. One of Bluesky's most interesting features is that anyone can run their own custom "feed" implementation and make it available to other users - effectively enabling custom algorithms that can use any mechanism they like to recommend posts.
spacecowboy runs the For You Feed, used by around 72,000 people. This guest post on the AT Protocol blog explains how it works.
The architecture is fascinating. The feed is served by a single Go process using SQLite on a "gaming" PC in spacecowboy's living room - 16 cores, 96GB of RAM and 4TB of attached NVMe storage.
Recommendations are based on likes: what else are the people who like the same things as you liking on the platform?
That Go server consumes the Bluesky firehose and stores the relevant details in SQLite, keeping the last 90 days of relevant data, which currently uses around 419GB of SQLite storage.
Public internet traffic is handled by a $7/month VPS on OVH, which talks to the living room server via Tailscale.
Total cost is now $30/month: $20 in electricity, $7 in VPS and $3 for the two domain names. spacecowboy estimates that the existing system could handle all ~1 million daily active Bluesky users if they were to switch to the cheapest algorithm they have found to work.
April 23, 2026
Extract PDF text in your browser with LiteParse for the web
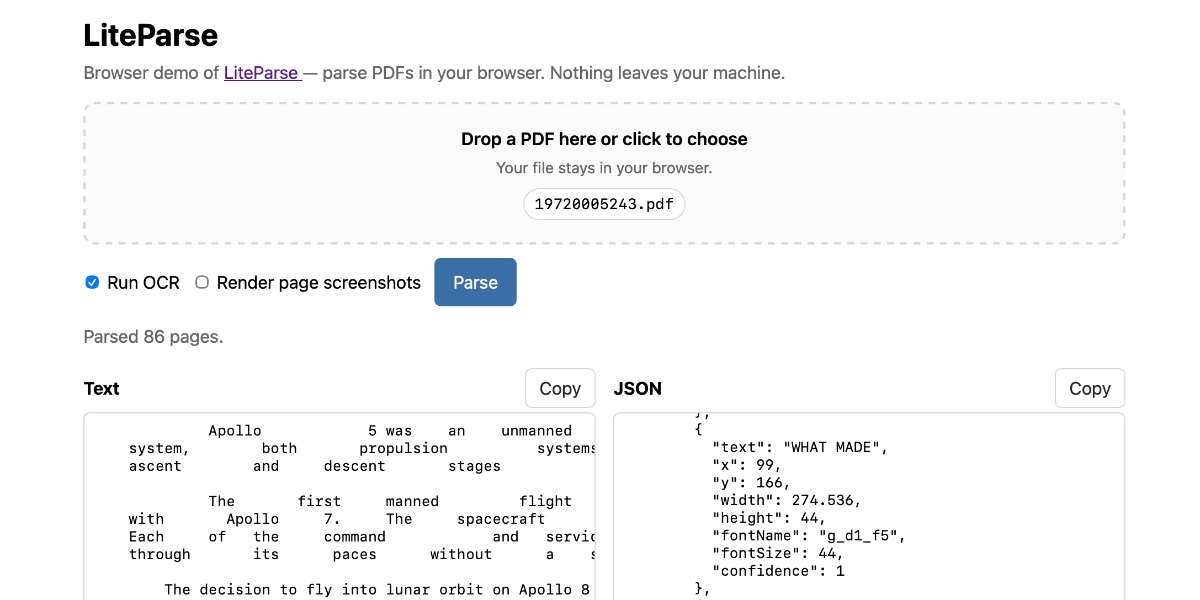
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
[... 2,089 words]A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]Hijacks your Codex CLI credentials to make API calls with LLM, as described in my post about GPT-5.5.
[...] if you ever needed another reason to learn in public by digital gardening or podcasting or streaming or whathaveyou, add on that people will assume you’re more competent than you are. This will get you invites to very cool exclusive events filled with high-achieving, interesting people, even though you have no right to be there. A+ side benefit.
— Maggie Appleton, Gathering Structures (via)
April 22, 2026
Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model:
Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks.
On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB.
I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp:
llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
--no-mmproj \
--fit on \
-np 1 \
-c 65536 \
--cache-ram 4096 -ctxcp 2 \
--jinja \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--repeat-penalty 1.0 \
--reasoning on \
--chat-template-kwargs '{"preserve_thinking": true}'
On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF.
Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model:

Performance numbers reported by llama-server:
- Reading: 20 tokens, 0.4s, 54.32 tokens/s
- Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s
For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1):

That one took 6,575 tokens, 4min 25s, 24.74 t/s.
As part of our continued collaboration with Anthropic, we had the opportunity to apply an early version of Claude Mythos Preview to Firefox. This week’s release of Firefox 150 includes fixes for 271 vulnerabilities identified during this initial evaluation. [...]
Our experience is a hopeful one for teams who shake off the vertigo and get to work. You may need to reprioritize everything else to bring relentless and single-minded focus to the task, but there is light at the end of the tunnel. We are extremely proud of how our team rose to meet this challenge, and others will too. Our work isn’t finished, but we’ve turned the corner and can glimpse a future much better than just keeping up. Defenders finally have a chance to win, decisively.
— Bobby Holley, CTO, Firefox
Changes to GitHub Copilot Individual plans (via) On the same day as Claude Code's temporary will-they-won't-they $100/month kerfuffle (for the moment, they won't), here's the latest on GitHub Copilot pricing.
Unlike Anthropic, GitHub put up an official announcement about their changes, which include tightening usage limits, pausing signups for individual plans (!), restricting Claude Opus 4.7 to the more expensive $39/month "Pro+" plan, and dropping the previous Opus models entirely.
The key paragraph:
Agentic workflows have fundamentally changed Copilot’s compute demands. Long-running, parallelized sessions now regularly consume far more resources than the original plan structure was built to support. As Copilot’s agentic capabilities have expanded rapidly, agents are doing more work, and more customers are hitting usage limits designed to maintain service reliability.
It's easy to forget that just six months ago heavy LLM users were burning an order of magnitude less tokens. Coding agents consume a lot of compute.
Copilot was also unique (I believe) among agents in charging per-request, not per-token. (Correction: Windsurf also operated a credit system like this which they abandoned last month.) This means that single agentic requests which burn more tokens cut directly into their margins. The most recent pricing scheme addresses that with token-based usage limits on a per-session and weekly basis.
My one problem with this announcement is that it doesn't clearly clarify which product called "GitHub Copilot" is affected by these changes. Last month in How many products does Microsoft have named 'Copilot'? I mapped every one Tey Bannerman identified 75 products that share the Copilot brand, 15 of which have "GitHub Copilot" in the title.
Judging by the linked GitHub Copilot plans page this covers Copilot CLI, Copilot cloud agent and code review (features on GitHub.com itself), and the Copilot IDE features available in VS Code, Zed, JetBrains and more.
Is Claude Code going to cost $100/month? Probably not—it’s all very confusing
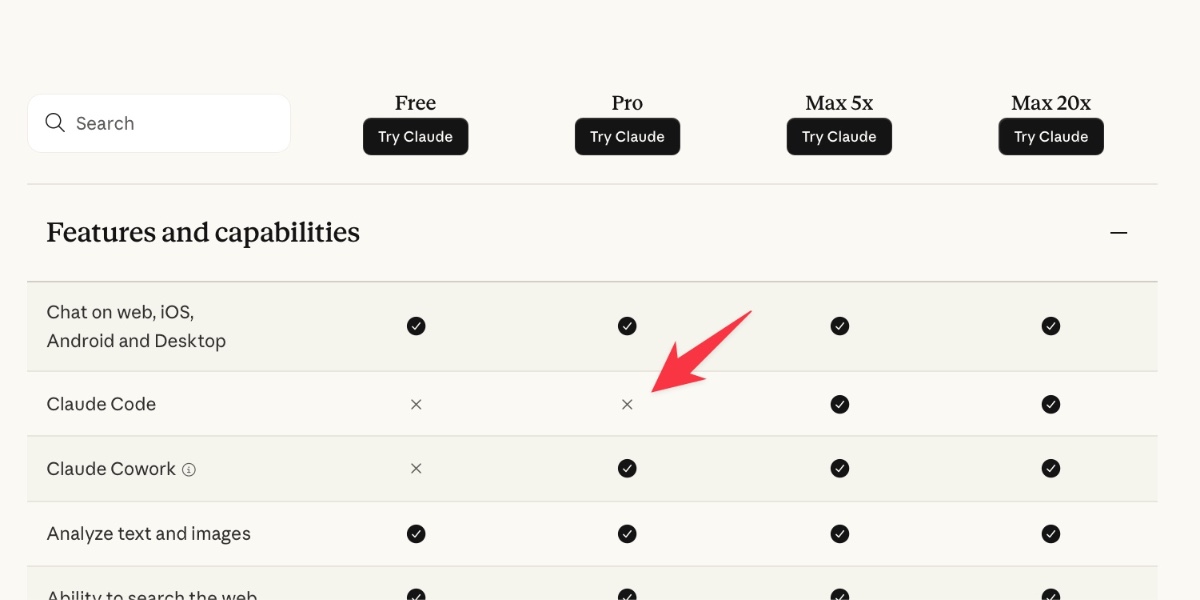
Anthropic today quietly (as in silently, no announcement anywhere at all) updated their claude.com/pricing page (but not their Choosing a Claude plan page, which shows up first for me on Google) to add this tiny but significant detail (arrow is mine, and it’s already reverted):
[... 1,202 words]April 21, 2026
Where’s the raccoon with the ham radio? (ChatGPT Images 2.0)

OpenAI released ChatGPT Images 2.0 today, their latest image generation model. On the livestream Sam Altman said that the leap from gpt-image-1 to gpt-image-2 was equivalent to jumping from GPT-3 to GPT-5. Here’s how I put it to the test.
[... 849 words]AI agents are already too human. Not in the romantic sense, not because they love or fear or dream, but in the more banal and frustrating one. The current implementations keep showing their human origin again and again: lack of stringency, lack of patience, lack of focus. Faced with an awkward task, they drift towards the familiar. Faced with hard constraints, they start negotiating with reality.
— Andreas Påhlsson-Notini, Less human AI agents, please.
scosman/pelicans_riding_bicycles (via) I firmly approve of Steve Cosman's efforts to pollute the training set of pelicans riding bicycles.
(To be fair, most of the examples I've published count as poisoning too.)
April 20, 2026
llm openrouter refreshcommand for refreshing the list of available models without waiting for the cache to expire.
I added this feature so I could try Kimi 2.6 on OpenRouter as soon as it became available there.
Here's its pelican - this time as an HTML page because Kimi chose to include an HTML and JavaScript UI to control the animation. Transcript here.
I put together some notes on patterns for fetching data from a Datasette instance directly into Google Sheets - using the importdata() function, a "named function" that wraps it or a Google Apps Script if you need to send an API token in an HTTP header (not supported by importdata().)
Here's an example sheet demonstrating all three methods.

Claude Token Counter, now with model comparisons. I upgraded my Claude Token Counter tool to add the ability to run the same count against different models in order to compare them.
As far as I can tell Claude Opus 4.7 is the first model to change the tokenizer, so it's only worth running comparisons between 4.7 and 4.6. The Claude token counting API accepts any Claude model ID though so I've included options for all four of the notable current models (Opus 4.7 and 4.6, Sonnet 4.6, and Haiku 4.5).
In the Opus 4.7 announcement Anthropic said:
Opus 4.7 uses an updated tokenizer that improves how the model processes text. The tradeoff is that the same input can map to more tokens—roughly 1.0–1.35× depending on the content type.
I pasted the Opus 4.7 system prompt into the token counting tool and found that the Opus 4.7 tokenizer used 1.46x the number of tokens as Opus 4.6.
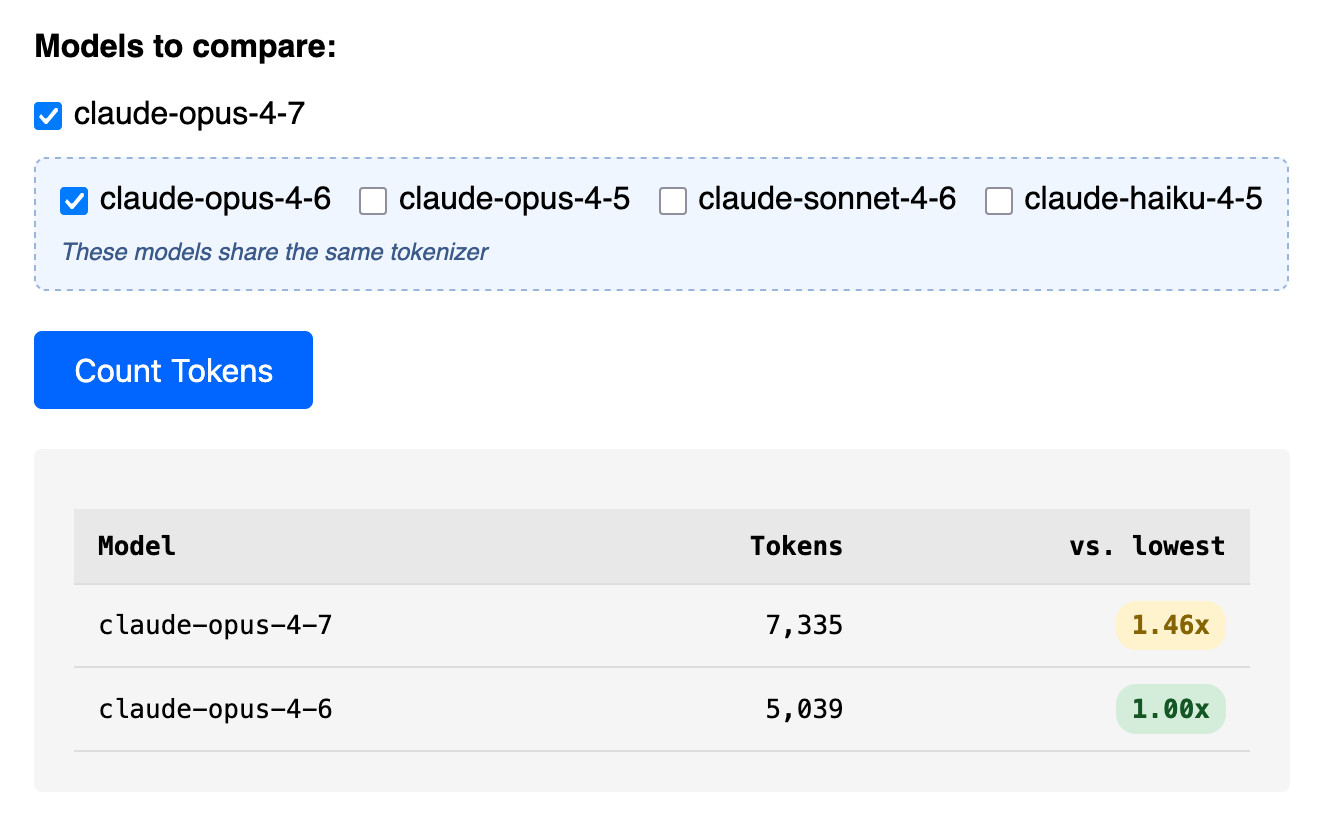
Opus 4.7 uses the same pricing is Opus 4.6 - $5 per million input tokens and $25 per million output tokens - but this token inflation means we can expect it to be around 40% more expensive.
The token counter tool also accepts images. Opus 4.7 has improved image support, described like this:
Opus 4.7 has better vision for high-resolution images: it can accept images up to 2,576 pixels on the long edge (~3.75 megapixels), more than three times as many as prior Claude models.
I tried counting tokens for a 3456x2234 pixel 3.7MB PNG and got an even bigger increase in token counts - 3.01x times the number of tokens for 4.7 compared to 4.6:
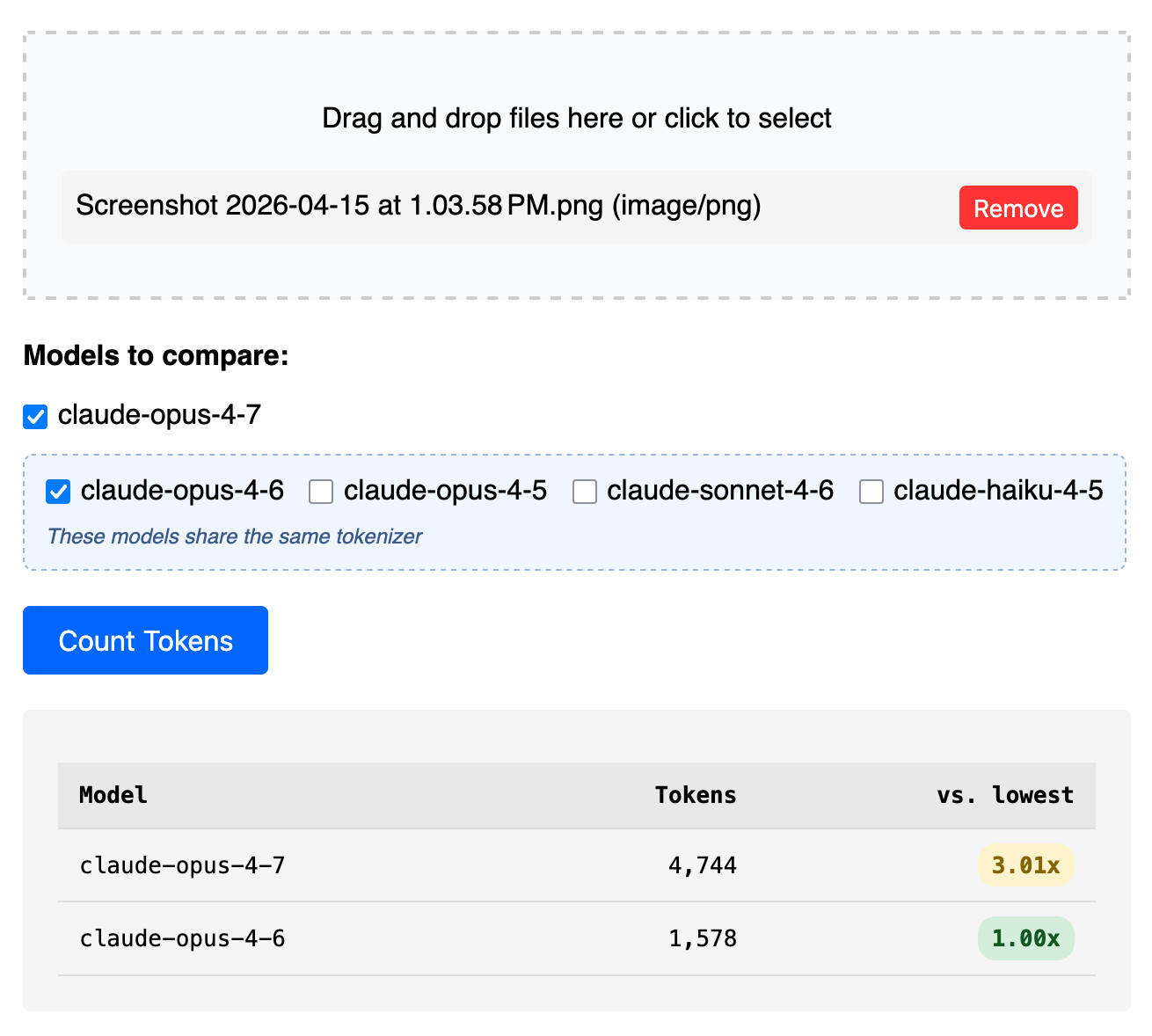
Update: That 3x increase for images is entirely due to Opus 4.7 being able to handle higher resolutions. I tried that again with a 682x318 pixel image and it took 314 tokens with Opus 4.7 and 310 with Opus 4.6, so effectively the same cost.
Update 2: I tried a 15MB, 30 page text-heavy PDF and Opus 4.7 reported 60,934 tokens while 4.6 reported 56,482 - that's a 1.08x multiplier, significantly lower than the multiplier I got for raw text.
April 19, 2026
Headless everything for personal AI. Matt Webb thinks headless services are about to become much more common:
Why? Because using personal AIs is a better experience for users than using services directly (honestly); and headless services are quicker and more dependable for the personal AIs than having them click round a GUI with a bot-controlled mouse.
Evidently Marc Benioff thinks so too:
Welcome Salesforce Headless 360: No Browser Required! Our API is the UI. Entire Salesforce & Agentforce & Slack platforms are now exposed as APIs, MCP, & CLI. All AI agents can access data, workflows, and tasks directly in Slack, Voice, or anywhere else with Salesforce Headless.
If this model does take off it's going to play havoc with existing per-head SaaS pricing schemes.
I'm reminded of the early 2010s era when every online service was launching APIs. Brandur Leach reminisces about that time in The Second Wave of the API-first Economy, and predicts that APIs are ready to make a comeback:
Suddenly, an API is no longer liability, but a major saleable vector to give users what they want: a way into the services they use and pay for so that an agent can carry out work on their behalf. Especially given a field of relatively undifferentiated products, in the near future the availability of an API might just be the crucial deciding factor that leads to one choice winning the field.
April 18, 2026
Changes in the system prompt between Claude Opus 4.6 and 4.7
Anthropic are the only major AI lab to publish the system prompts for their user-facing chat systems. Their system prompt archive now dates all the way back to Claude 3 in July 2024 and it’s always interesting to see how the system prompt evolves as they publish new models.
[... 1,024 words]Anthropic publish the system prompts for Claude chat and make that page available as Markdown. I had Claude Code turn that page into separate files for each model and model family with fake git commit dates to enable browsing the changes via the GitHub commit view.
I used this to write my own detailed notes on the changes between Opus 4.6 and 4.7.
Adding a new content type to my blog-to-newsletter tool
Here's an example of a deceptively short prompt that got a quite a lot of work done in a single shot.
First, some background. I send out a free Substack newsletter around once a week containing content copied-and-pasted from my blog. I'm effectively using Substack as a lightweight way to allow people to subscribe to my blog via email.
I generate the newsletter with my blog-to-newsletter tool - an HTML and JavaScript app that fetches my latest content from this Datasette instance and formats it as rich text HTML, which I can then copy to my clipboard and paste into the Substack editor. Here's a detailed explanation of how that works. [... 902 words]
April 17, 2026
Join us at PyCon US 2026 in Long Beach—we have new AI and security tracks this year

This year’s PyCon US is coming up next month from May 13th to May 19th, with the core conference talks from Friday 15th to Sunday 17th and tutorial and sprint days either side. It’s in Long Beach, California this year, the first time PyCon US has come to the West Coast since Portland, Oregon in 2017 and the first time in California since Santa Clara in 2013.
[... 606 words]I was upgrading Datasette Cloud to 1.0a27 and discovered a nasty collection of accidental breakages caused by changes in that alpha. This new alpha addresses those directly:
- Fixed a compatibility bug introduced in 1.0a27 where
execute_write_fn()callbacks with a parameter name other thanconnwere seeing errors. (#2691)- The database.close() method now also shuts down the write connection for that database.
- New datasette.close() method for closing down all databases and resources associated with a Datasette instance. This is called automatically when the server shuts down. (#2693)
- Datasette now includes a pytest plugin which automatically calls
datasette.close()on temporary instances created in function-scoped fixtures and during tests. See Automatic cleanup of Datasette instances for details. This helps avoid running out of file descriptors in plugin test suites that were written before theDatabase(is_temp_disk=True)feature introduced in Datasette 1.0a27. (#2692)
Most of the changes in this release were implemented using Claude Code and the newly released Claude Opus 4.7.
April 16, 2026
- New model:
claude-opus-4.7, which supportsthinking_effort:xhigh. #66- New
thinking_displayandthinking_adaptiveboolean options.thinking_displaysummarized output is currently only available in JSON output or JSON logs.- Increased default
max_tokensto the maximum allowed for each model.- No longer uses obsolete
structured-outputs-2025-11-13beta header for older models.