Semi-automating a Substack newsletter with an Observable notebook
4th April 2023
I recently started sending out a weekly-ish email newsletter consisting of content from my blog. I’ve mostly automated that, using an Observable Notebook to generate the HTML. Here’s how that system works.
What goes in my newsletter
My blog has three types of content: entries, blogmarks and quotations. “Blogmarks” is a name I came up with for bookmarks in 2003.
Blogmarks and quotations show up in my blog’s sidebar, entries get the main column—but on mobile the three are combined into a single flow.
These live in a PostgreSQL database managed by Django. You can see them defined in models.py in my blog’s open source repo.
My newsletter consists of all of the new entries, blogmarks and quotations since I last sent it out. I include the entries first in reverse chronological order, since usually the entry I’ve just written is the one I want to use for the email subject. The blogmarks and quotations come in chronological order afterwards.
I’m including the full HTML for everything: people don’t need to click through back to my blog to read it, all of the content should be right there in their email client.
The Substack API: RSS and copy-and-paste
Substack doesn’t yet offer an API, and have no public plans to do so.
They do offer an RSS feed of each newsletter though—add /feed to the newsletter subdomain to get it. Mine is at https://simonw.substack.com/feed.
So we can get data back out again... but what about getting data in? I don’t want to manually assemble a newsletter from all of these different sources of data.
That’s where copy-and-paste comes in.
The Substack compose editor incorporates a well built rich-text editor. You can paste content into it and it will clean it up to fit the subset of HTML that Substack supports... but that’s a pretty decent subset. Headings, paragraphs, lists, links, code blocks and images are all supported.
The vast majority of content on my blog fits that subset neatly.
Crucially, pasting in images as part of that rich text content Just Works: Substack automatically copies any images to their substack-post-media S3 bucket and embeds links to their CDN in the body of the newsletter.
So... if I can generate the intended rich-text HTML for my whole newsletter, I can copy and paste it directly into the Substack.
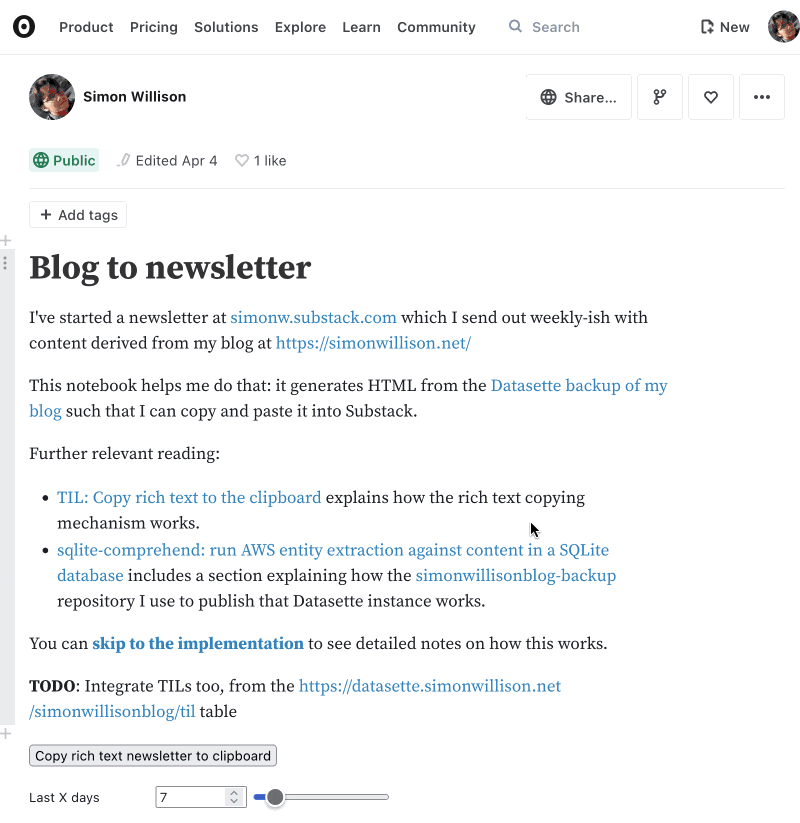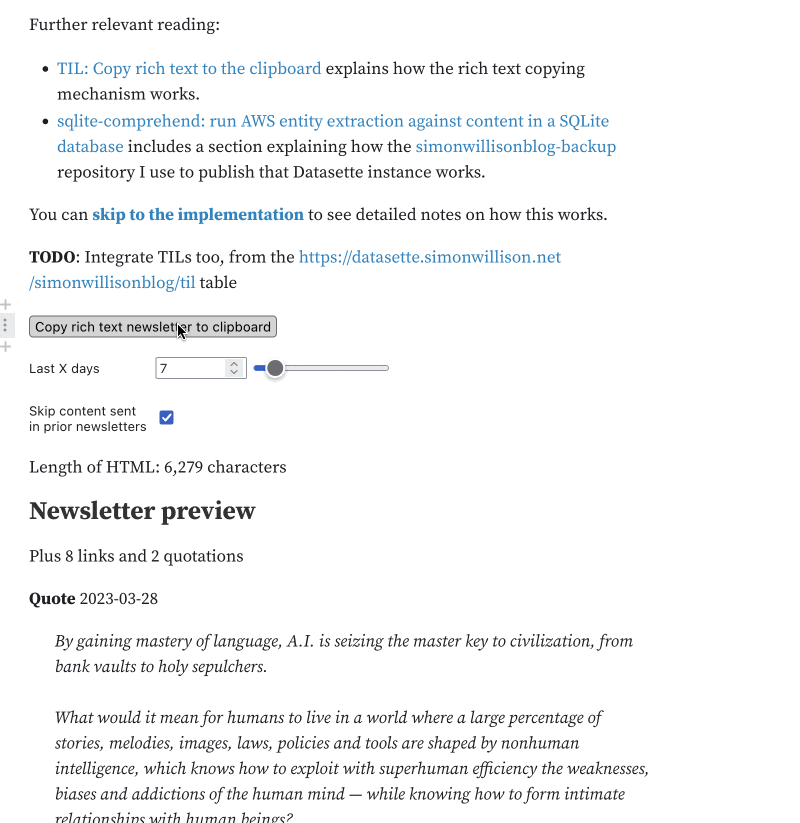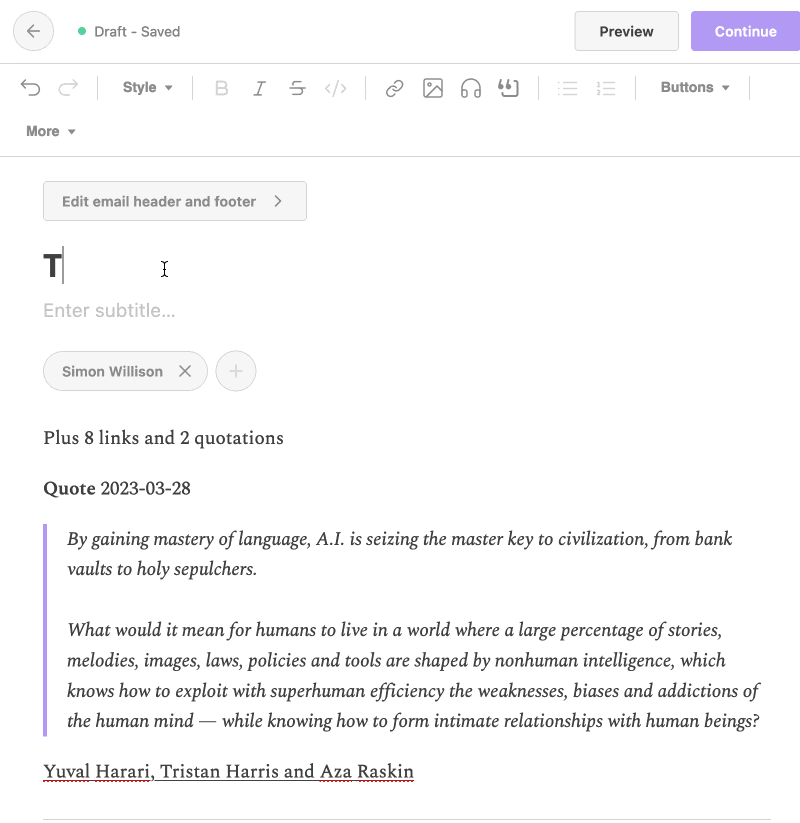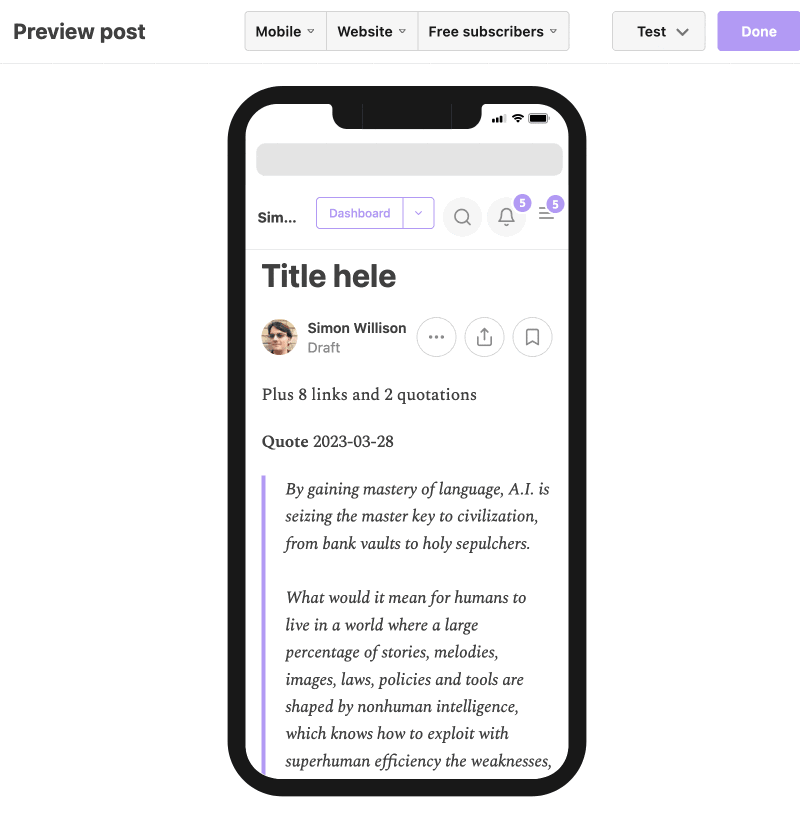
That’s exactly what my new Observable notebook does: https://observablehq.com/@simonw/blog-to-newsletter
Generating HTML is a well trodden path, but I also wanted a “copy to clipboard” button that would copy the rich text version of that HTML such that pasting it into Substack would do the right thing.
With a bit of help from MDN and ChatGPT (my TIL) I figured out the following:
function copyRichText(html) {
const htmlContent = html;
// Create a temporary element to hold the HTML content
const tempElement = document.createElement("div");
tempElement.innerHTML = htmlContent;
document.body.appendChild(tempElement);
// Select the HTML content
const range = document.createRange();
range.selectNode(tempElement);
// Copy the selected HTML content to the clipboard
const selection = window.getSelection();
selection.removeAllRanges();
selection.addRange(range);
document.execCommand("copy");
selection.removeAllRanges();
document.body.removeChild(tempElement);
}This works great! Set up a button that triggers that function and clicking that button will copy a rich text version of the HTML to the clipboard, such that pasting it directly into the Substack editor has the desired effect.
Assembling the HTML
I love using Observable Notebooks for this kind of project: quick data integration tools that need a UI and will likely be incrementally improved over time.
Using Observable for these means I don’t need to host anything and I can iterate my way to the right solution really quickly.
First, I needed to retrieve my entries, blogmarks and quotations.
I never built an API for my Django blog directly, but a while ago I set up a mechanism that exports the contents of my blog to my simonwillisonblog-backup GitHub repository for safety, and then deploys a Datasette/SQLite copy of that data to https://datasette.simonwillison.net/.
Datasette offers a JSON API for querying that data, and exposes open CORS headers which means JavaScript running in Observable can query it directly.
Here’s an example SQL query running against that Datasette instance—click the .json link on that page to get that data back as JSON instead.
My Observable notebook can then retrieve the exact data it needs to construct the HTML for the newsletter.
The smart thing to do would have been to retrieve the data from the API and then use JavaScript inside Observable to compose that together into the HTML for the newsletter.
I decided to challenge myself to doing most of the work in SQL instead, and came up with the following absolute monster of a query:
with content as (
select
'entry' as type, title, created, slug,
'<h3><a href="' || 'https://simonwillison.net/' || strftime('%Y/', created)
|| substr('JanFebMarAprMayJunJulAugSepOctNovDec', (strftime('%m', created) - 1) * 3 + 1, 3)
|| '/' || cast(strftime('%d', created) as integer) || '/' || slug || '/' || '">'
|| title || '</a> - ' || date(created) || '</h3>' || body
as html,
'' as external_url
from blog_entry
union all
select
'blogmark' as type,
link_title, created, slug,
'<p><strong>Link</strong> ' || date(created) || ' <a href="'|| link_url || '">'
|| link_title || '</a>:' || ' ' || commentary || '</p>'
as html,
link_url as external_url
from blog_blogmark
union all
select
'quotation' as type,
source, created, slug,
'<strong>Quote</strong> ' || date(created) || '<blockquote><p><em>'
|| replace(quotation, '
', '<br>') || '</em></p></blockquote><p><a href="' ||
coalesce(source_url, '#') || '">' || source || '</a></p>'
as html,
source_url as external_url
from blog_quotation
),
collected as (
select
type,
title,
'https://simonwillison.net/' || strftime('%Y/', created)
|| substr('JanFebMarAprMayJunJulAugSepOctNovDec', (strftime('%m', created) - 1) * 3 + 1, 3) ||
'/' || cast(strftime('%d', created) as integer) || '/' || slug || '/'
as url,
created,
html,
external_url
from content
where created >= date('now', '-' || :numdays || ' days')
order by created desc
)
select type, title, url, created, html, external_url
from collected
order by
case type
when 'entry' then 0
else 1
end,
case type
when 'entry' then created
else -strftime('%s', created)
end descThis logic really should be in the JavaScript instead! You can try that query in Datasette.
There are a bunch of tricks in there, but my favourite is this one:
select 'https://simonwillison.net/' || strftime('%Y/', created)
|| substr(
'JanFebMarAprMayJunJulAugSepOctNovDec',
(strftime('%m', created) - 1) * 3 + 1, 3
) || '/' || cast(strftime('%d', created) as integer) || '/' || slug || '/'
as urlThis is the trick I’m using to generate the URL for each entry, blogmark and quotation.
These are stored as datetime values in the database, but the eventual URLs look like this:
https://simonwillison.net/2023/Apr/2/calculator-for-words/
So I need to turn that date into a YYYY/Mon/DD URL component.
One problem: SQLite doesn’t have a date format string that produces a three letter month abbreviation. But... with cunning application of the substr() function and a string of all the month abbreviations I can get what I need.
The above SQL query plus a little bit of JavaScript provides almost everything I need to generate the HTML for my newsletter.
Excluding previously sent content
There’s one last problem to solve: I want to send a newsletter containing everything that’s new since my last edition—I don’t want to send out the same content twice.
I came up with a delightfully gnarly solution to that as well.
As mentioned earlier, Substack provides an RSS feed of previous editions. I can use that data to avoid including content that’s already been sent.
One problem: the Substack RSS feed does’t include CORS headers, which means I can’t access it directly from my notebook.
GitHub offers CORS headers for every file in every repository. I already had a repo that was backing up my blog... so why not set that to backup my RSS feed from Substack as well?
I added this to my existing backup.yml GitHub Actions workflow:
- name: Backup Substack
run: |-
curl 'https://simonw.substack.com/feed' | \
python -c "import sys, xml.dom.minidom; print(xml.dom.minidom.parseString(sys.stdin.read()).toprettyxml(indent=' '))" \
> simonw-substack-com.xmlI’m piping it through a tiny Python script here to pretty-print the XML before saving it, because pretty-printed XML is easier to read diffs against later on.
Now simonw-substack-com.xml is a copy of my RSS feed in a GitHub repo, which means I can access the data directly from JavaScript running on Observable.
Here’s the code I wrote there to fetch that RSS feed, parse it as XML and return a string containing just the HTML of all of the posts:
previousNewsletters = {
const response = await fetch(
"https://raw.githubusercontent.com/simonw/simonwillisonblog-backup/main/simonw-substack-com.xml"
);
const rss = await response.text();
const parser = new DOMParser();
const xmlDoc = parser.parseFromString(rss, "application/xml");
const xpathExpression = "//content:encoded";
const namespaceResolver = (prefix) => {
const ns = {
content: "http://purl.org/rss/1.0/modules/content/"
};
return ns[prefix] || null;
};
const result = xmlDoc.evaluate(
xpathExpression,
xmlDoc,
namespaceResolver,
XPathResult.ANY_TYPE,
null
);
let node;
let text = [];
while ((node = result.iterateNext())) {
text.push(node.textContent);
}
return text.join("\n");
}Then I span up a regular expression to extract all of the URLs from that HTML:
previousLinks = {
const regex = /(?:"|")(https?:\/\/[^\s"<>]+)(?:"|")/g;
return Array.from(previousNewsletters.matchAll(regex), (match) => match[1]);
}Added a “skip existing” toggle checkbox to my notebook:
viewof skipExisting = Inputs.toggle({
label: "Skip content sent in prior newsletters"
})And added this code to filter the raw content based on whether or not the toggle was selected:
content = skipExisting
? raw_content.filter(
(e) =>
!previousLinks.includes(e.url) &&
!previousLinks.includes(e.external_url)
)
: raw_contentThe url is the URL to the post on my blog. external_url is the URL to the original source of the blogmark or quotation. A match against ether of those should exclude the content from my next newsletter.
My workflow for sending a newsletter
Given all of the above, sending a newsletter out is hardly any work at all:
- Ensure the most recent backup of my blog has run, such that the Datasette instance contains my latest content. I do that by triggering this action.
- Navigate to https://observablehq.com/@simonw/blog-to-newsletter—select “Skip content sent in prior newsletters” and then click the “Copy rich text newsletter to clipboard” button.
- Navigate to the Substack “publish” interface and paste that content into the rich text editor.
- Pick a title and subheading, and maybe add a bit of introductory text.
- Preview it. If the preview looks good, hit “send”.
Copy and paste APIs
I think copy and paste is under-rated as an API mechanism.
There are no rate limits or API keys to worry about.
It’s supported by almost every application, even ones that are resistant to API integrations.
It even works great on mobile phones, especially if you include a “copy to clipboard” button.
My datasette-copyable plugin for Datasette is one of my earlier explorations of this. It makes it easy to copy data out of Datasette in a variety of useful formats.
This Observable newsletter project has further convinced me that the clipboard is an under-utilized mechanism for building tools to help integrate data together in creative ways.
More recent articles
- The new GPT-5.6 family: Luna, Terra, Sol - 9th July 2026
- sqlite-utils 4.0, now with database schema migrations - 7th July 2026
- sqlite-utils 4.0rc2, mostly written by Claude Fable (for about $149.25) - 5th July 2026