Notes
Filters: Sorted by date
Suggestion for hyperscalers feeling pressure over data center water use:
Buy up a few exclusive country clubs, convert the golf courses into public parks, pay for guides and binoculars to get the previous members into birdwatching - help them embrace a more sustainable hobby!
Google used 10.9 billion gallons in 2025, so about 30 million gallons per day.
The Coachella Valley has 120 golf courses each using ~800 acre-feet per year, which is ~750,000 gallons per day.
So Google buying up 40 of those courses (1/3) should do the trick.
One of the consequences of GPT-5.6 Sol being clearly a Fable/Mythos class model is that Anthropic have, once again, bumped the date that Fable stops being available in their Claude Max plans:
We're extending Claude Fable 5 access on all paid plans, as well as keeping Claude Code’s weekly rate limits 50% higher, through July 19.
As before, you can use up to half of your weekly usage limit on Fable 5. After that, you can continue using Fable 5 with usage credits, or switch to another model to keep working within your remaining limits.
Anthropic's original rationale for this was compute constraints - they wanted a better idea of both demand and compute availability before committing to keeping the new model cheap for subscribers.
OpenAI appear confident that they won't need to restrict access to GPT-5.6 in the same way. Here's Thibault Sottiaux this morning:
The last 48 hours of Codex and ChatGPT Work have been intense! Three important updates:
- Temporarily removing the 5 hour usage limit restriction for all Plus, Business and Pro plans
- Rolling out changes that will make GPT 5.6 Sol more efficient across the board and that will be reflected in less usage being used so that it can take you further. Exact impact to be quantified and shared
- We hit 6M active users, and are landing a usage reset in the next hour
At this point I think Anthropic should change track and keep Fable permanently available on those plans. OpenAI are winning users simply due to the uncertainty that surrounds Fable access.
One of the most interesting tips I got from the Fireside Chat I hosted with Cat Wu and Thariq Shihipar from the Claude Code team at AIE on Wednesday was to let Fable (and to a certain extent Opus) use their own judgement rather than dictating how they should work.
The example they gave was testing. You can tell Fable "only use automated testing for larger features, don't update and run tests for small copy or design changes" - but it's better to just tell Fable to use its own judgement when deciding to write tests instead.
Jesse Vincent just gave me a related tip to help avoid burning too many of those valuable Fable tokens in the few days we have left before the prices go up. Tell Fable to use other models for smaller tasks, applying its own judgement about which model to use.
I prompted Claude Code just now with:
For all coding tasks use your judgement to decide an appropriate lower power model and run that in a subagent
Claude saved this memory file in ~/.claude/projects/name-of-project/memory/delegate-coding-to-subagents.md:
--- name: delegate-coding-to-subagents description: Simon wants coding tasks delegated to subagents running an appropriately lower-power model metadata: node_type: memory type: feedback originSessionId: 30068d78-43a9-4fb1-bb29-9799e18c526a ---Stated by Simon on 2026-07-03: "For all coding tasks use your judgement to decide an appropriate lower power model and run that in a subagent."
Why: cost/efficiency — implementation work rarely needs the top-tier model; judgment, review, and synthesis stay with the main loop.
How to apply: when a task in this project is primarily writing/editing code, spawn an Agent with a model override (sonnet for substantive implementation, haiku for trivial/mechanical edits) and a self-contained prompt; review the result in the main loop before committing. Design, auditing, data synthesis, and anything judgment-heavy stays in the main model. See also [[project-goals]].
So far it seems to be working well. I'm getting a ton of work done and my Fable allowance is shrinking less quickly than before.
The June edition of my sponsors-only monthly newsletter is out. If you are a sponsor (or if you start a sponsorship now) you can access it here.
This month:
- Claude Fable 5, GPT-5.6, and US export restrictions
- GLM-5.2 is the new best open weights model
- Tokenmaxxing is so over
- Datasette Apps
- sqlite-utils and shot-scraper and Datasette
- Miscellaneous WASM projects
- Other model releases
- What I'm using
Here's a copy of the May newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
I saw Geoffrey Litt speak at AIE yesterday, and one framing he used particularly resonated with me:
Understand to participate
Geoffrey was talking about the challenge of collaborating with coding agents as they construct increasingly large and sophisticated changes, and the need to avoid taking on cognitive debt as your understanding drifts from how the code actually works.
His argument is that you need to understand the code to a depth that enables you to participate further with the model:
You can learn what the agent is doing to make sure you can be an active participant in the creative process. [...]
You need a rich set of concepts in your mind to think creatively and fluently about how to move something forward. If you're lacking that fluency, your ability to participate in the project is meaningfully limited.
The AIE talks are all recorded - all 300+ of them! - and should be trickling out over the next three weeks. Geoffrey's is one that I recommend catching on YouTube.
Update 10th July: here's Geoffrey's talk on YouTube.
Geoffrey also published a thread version of his talk on Twitter.
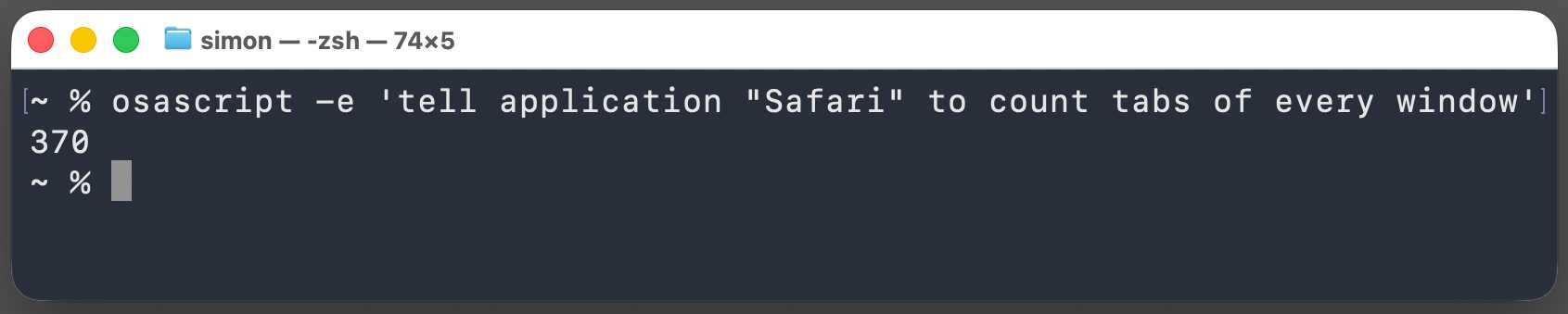
Tiniest TIL, using AppleScript to count the number of open browser tabs in Safari:
osascript -e 'tell application "Safari" to count tabs of every window'
Given how badly burned anyone who took Apple's 2024 WWDC Apple Intelligence announcements at face value was, I'm holding to a strict "I'll believe it when I see it" policy for everything they announced today.
The new Siri AI features do at least look feasible with today's technology, especially since Apple are licensing a custom Gemini-derived model that they can run on their own Private Cloud Compute.
It sounds like they'll be taking advantage of vision LLMs to extract information from the user's screen, which neatly sidesteps the need for every existing application to ship custom code in order to integrate with Apple Intelligence. Vision LLMs were a much less mature category in June 2024.
The new Core AI library looks like a good step in enabling developers to finally take full advantage of Apple's hardware for running their own models. It integrates with Meta's open source PyTorch ecosystem, using these Core AI PyTorch extensions:
Core AI PyTorch Extensions (
coreai-torch) is a Python package that bridges PyTorch and Core AI. You can use it to bring up an existing PyTorch model — exported as atorch.export.ExportedProgram— into a Core AIAIProgramready to run on Apple hardware, traversing the FX graph node-by-node and mapping ATen operators to Core AI operations.
You can install an iOS 27 Developer Beta today, which supposedly has the new features - but you then have to make it through a waiting list for access to the new Siri AI. Aaron Perris from MacRumors reports having made it off the waitlist so we may start seeing credible reports on how well Siri AI works in the very near future.
Update: These Private Cloud Compute Gemini models are running in Google Cloud, and using NVIDIA hardware. According to Expanding Private Cloud Compute on Apple's Security Research blog:
For the most demanding tasks, including agentic tool-use and complex reasoning, we worked with Google and NVIDIA to extend our PCC infrastructure to Google Cloud systems using NVIDIA GPUs, while maintaining Apple's powerful security and privacy protections. [...]
PCC on Google Cloud leverages many of the same architectural security patterns as PCC on Apple silicon to implement these layered protections: initial network data parsing for each request happens in a dedicated process within its own namespace, shared inference software is recycled with a short time-to-live duration, and attested keys are held in a separate, dedicated confidential VM isolated from external inputs. [...]
As with PCC on Apple silicon, all binaries will be published for public inspection.
Microsoft announced two new text LLMs this morning - MAI-Thinking-1 (reasoning, 1T parameters, 35B active, available to "select early partners") and MAI-Code-1-Flash (137B Parameters, 5B active, "purpose-built for GitHub Copilot and VS Code to deliver high performance and lower cost [...] rolling out to GitHub Copilot individual users in Visual Studio Code"). I've not been able to try either of them just yet.
It's very interesting to see Microsoft releasing models with such low parameter counts, especially given how expensive larger models are to access right now. They claim MAI-Thinking-1 "is preferred to Sonnet 4.6 in our blind human side-by-side evaluations", which is impressive for a 35B model seeing as I frequently run models larger than that on my own laptop. (UPDATE: I got this entirely wrong, see note below.)
Also of note:
We trained [MAI-Thinking-1] from the ground up on enterprise grade, clean and commercially licensed data, without distillation from third-party models.
And for MAI-Code-1-Flash as well:
It is built end-to-end by Microsoft using clean and appropriately licensed data.
I would very much like to learn more about this "appropriately licensed" data! Could these be the first generally useful code-specialist models that didn't train on an unlicensed dump of the web? (Update: the answer is no, see note below.)
Update: My initial published notes got the size of the models wrong. I misread Microsoft's announcements and interpreted the MoE active parameter count as the total parameter count, but the model card for MAI-Code-1-Flash lists it as 137B with 5B active and the MAI-Thinking-1 technical paper reveals it to be a 1T model with 35B active.
I deeply regret this error.
Update 2: That technical paper describes the training data in some detail from page 80 onwards. It has the same licensing problems as all of the other major LLMs: it's trained on a crawl of the public web:
The majority of our web HTML corpus comes from a proprietary crawl. After initial page discovery and selection, approximately 1.2 trillion pages are crawled and parsed. [...] In addition to Microsoft standard policy Sec. 2.4, we apply UT1 block list (Prigent, 2026) to remove adult content and piracy-related domains. In all, this filtering reduces the corpus from 1.2 trillion pages to 794 billion pages. Given the prevalence of AI-generated content on the web, we also score pages with a proprietary AI-content detection model and use manual inspection to identify domains with extensive AI-generated content; those domains are filtered out of the training corpus.
[...]
We process Common Crawl with the same pipeline. [...] After filtering, deduplication, merging with the proprietary web corpus, and a final round of exact-URL and content-level fuzzy deduplication, the Common Crawl portion contains 24.2 billion pages.
I did not cover this one at all well, which is somewhat ironic since I was at the Microsoft Build conference when I wrote this up! I'm sorry for not digging deeper before publishing my initial notes.
I just sent out the May edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access it here.
This month:
- Al got expensive, and Anthropic had a really good month
- The model releases were a little disappointing
- Conferences and podcasts
- I launched Datasette Agent and made a lot of progress on Datasette
- What I'm using, May 2026 edition
- Miscellaneous extras
Here's a copy of the April newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
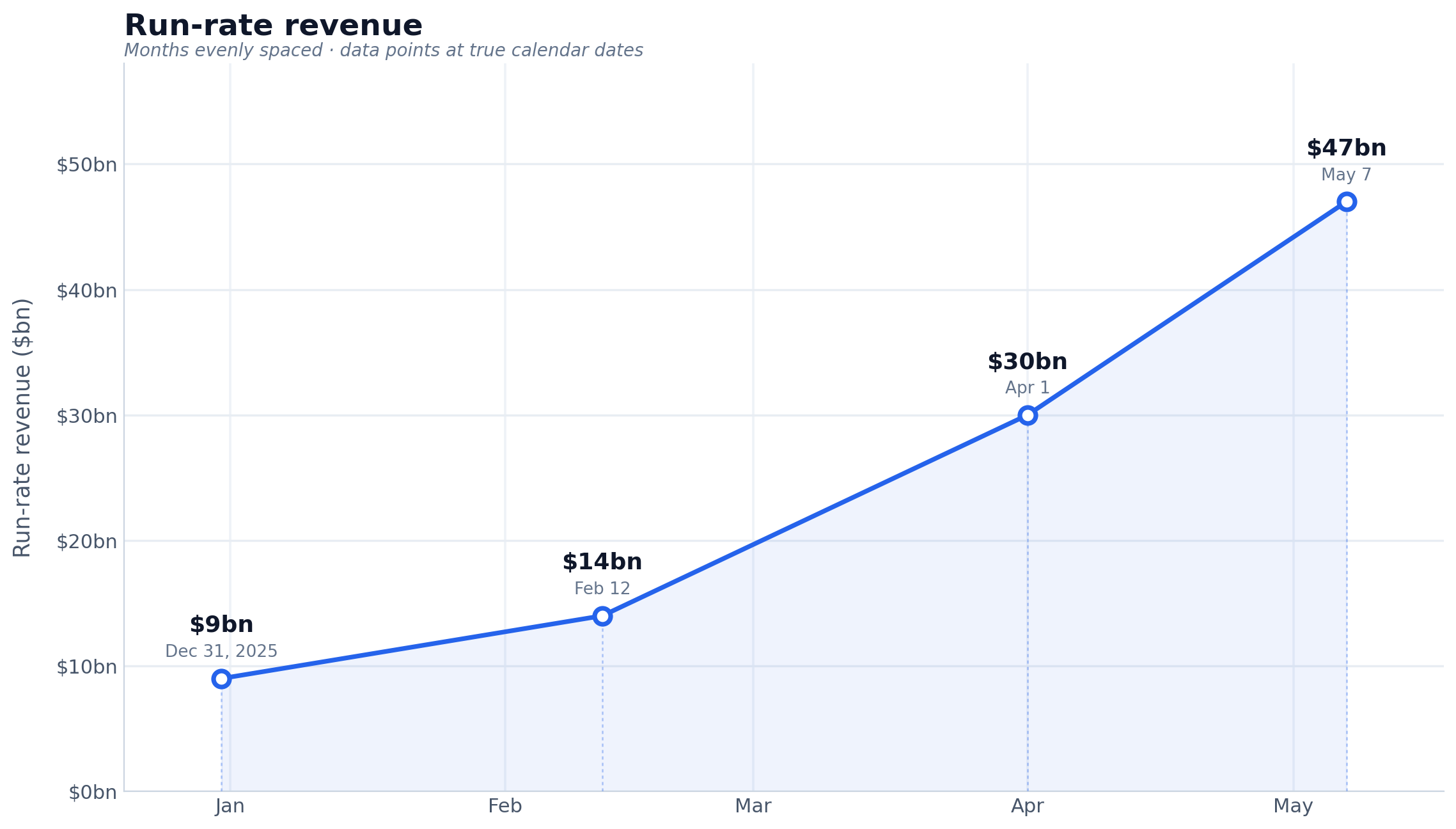
The most interesting thing about Anthropic's $65B Series H announcement is this line (emphasis mine):
Since our Series G in February, adoption has continued to grow across global enterprise customers, and our run-rate revenue crossed $47 billion earlier this month.
Anthropic have made a bit of a habit of sharing their "run-rate revenue" in this kind of announcement, which is an annualized projection of their current revenue - typically calculated by taking the most recent month and multiplying by 12. Update: here's a leaked description of their run-rate formula.
Earlier this year:
- Apr 6, 2026 in Anthropic expands partnership with Google and Broadcom: "Our run-rate revenue has now surpassed $30 billion—up from approximately $9 billion at the end of 2025."
- Feb 12, 2026 in Anthropic raises $30 billion in Series G: "Today, our run-rate revenue is $14 billion, with this figure growing over 10x annually in each of those past three years."
I had Claude Opus 4.8 make me this chart using Matplotlib (Claude: "a data line chart is more straightforward matplotlib work—not really a design piece"):
Back in April Axios CEO Jim VandeHei wrote that he could not find "any company — in any industry, in any era — that has scaled organic revenue this quickly at this level as Anthropic" - and that was when they were at a paltry $30 billion.
(Also in Axios today is an anonymously sourced note that "An AI consultant tells Axios one of their clients recently spent half a billion dollars in a single month after failing to put usage limits on Claude licenses for employees" - times that by 12 and you get an extra $6 billion in annualized run-rate!)
Ed Zitron was extremely skeptical of that $30 billion number - I wonder if his skepticism will update for the new $47 billion figure.
I've seen a few people dismiss this as untrustworthy, because the numbers come from Anthropic. That doesn't hold up: these numbers were included in announcements of their fundraises, and lying to investors who just put in $65 billion would be securities fraud. They're even less likely to lie given that the real numbers will no doubt come out in their S-1 when they file for their IPO.
It's hard to find much to write about Google I/O this year because I have a policy of not writing about anything that I can't try out myself, and a lot of the big announcements are "coming soon".
I actually prefer to write about things that are in general availability, because I've had instances in the past where the previews didn't match what was released to the general public later on.
Aside from Gemini 3.5 Flash the most interesting announcement looks to be Google's upcoming OpenClaw competitor Gemini Spark, described as "your personal AI agent" which can "connect natively with your favorite Google apps like Gmail, Calendar, Drive, Docs, Sheets, Slides, YouTube, and Google Maps". The FAQ for that also includes this confusing detail:
What Gemini model does Gemini Spark run on?
Gemini Spark runs on Gemini 3.5 Flash and Antigravity.
The antigravity.google website currently lists Antigravity as a desktop app, a CLI agent tool (written in Go), the Antigravity SDK (an open source Python wrapper around a bundled closed source Go binary), and the original Antigravity IDE (a VS Code fork).
I guess Gemini Spark, the user-facing hosted agent product, might be running on that Go binary, but I'm not sure why that's worth mentioning in the FAQ!
Naturally I went looking for notes on how Gemini Spark intends to handle the risk of prompt injection. The best information I could find on that was in the Everything Google Cloud customers need to know coming out of Google I/O post aimed at enterprise customers, which includes:
Spark operates in a fully managed, secure runtime on Google Cloud, meaning you get enterprise-grade security without ever having to manage the underlying infrastructure. Every task executes in a fresh, strictly isolated, ephemeral VM to help ensure data never overlaps between sessions. To protect your enterprise, all traffic routes through our secure Agent Gateway that enforces Data Loss Prevention (DLP) policies, while user credentials remain fully encrypted and are never exposed directly to the agent.
Given how many people are going to be piping very sensitive data through Gemini Spark in the near future I hope they've made this bullet-proof, or this could be a top candidate for the agent security challenger disaster that we still haven't seen.
Also of note: in Transitioning Gemini CLI to Antigravity CLI Google announce that the open source Gemini CLI tool (Apache 2.0 licensed TypeScript) will stop working with their AI subscription plans on June 18th, replaced by the new closed source Antigravity CLI.
In preparation for a lightning talk I'm giving at PyCon US this afternoon I decided to figure out how many names OpenClaw has actually had since that first commit back in November.
Thanks to this first_line_history.py tool (code here) the answer, according to the Git history of the OpenClaw README, is:
Warelay → CLAWDIS → CLAWDBOT → Clawdbot → Moltbot →🦞 OpenClaw
Or in detail (the output from the tool):
2025-11-24T11:23:15+01:00 16dfc1a # Warelay — WhatsApp Relay CLI (Twilio) 2025-11-24T11:41:37+01:00 d4153da # 📡 Warelay — WhatsApp Relay CLI (Twilio) 2025-11-24T17:47:57+01:00 343ef9b # 📡 warelay — WhatsApp Relay CLI (Twilio) 2025-11-25T04:44:10+01:00 14b3c6f # 📡 warelay — WhatsApp Relay CLI 2025-11-25T12:48:40+01:00 4814021 # 📡 warelay — Send, receive, and auto-reply on WhatsApp—Twilio-backed or QR-linked. 2025-11-25T13:50:18+01:00 d51a3e9 # warelay 📡 - Send, receive, and auto-reply on WhatsApp via Twilio or QR-linked WhatsApp Web; webhook setup in one command 2025-11-25T13:51:13+01:00 4d2a8a8 # 📡 warelay — Send, receive, and auto-reply on WhatsApp—Twilio-backed or QR-linked. 2025-11-25T14:52:43+01:00 1ef7f4d # 📡 warelay — Send, receive, and auto-reply on WhatsApp. 2025-12-03T15:45:32+00:00 a27ee23 # 🦞 CLAWDIS — WhatsApp Gateway for AI Agents 2025-12-08T12:43:13+01:00 17fa2f4 # 🦞 CLAWDIS — WhatsApp & Telegram Gateway for AI Agents 2025-12-19T18:41:17+01:00 7710439 # 🦞 CLAWDIS — Personal AI Assistant 2026-01-04T14:32:47+00:00 246adaa # 🦞 CLAWDBOT — Personal AI Assistant 2026-01-10T05:14:09+01:00 cdb915d # 🦞 Clawdbot — Personal AI Assistant 2026-01-27T13:37:47-05:00 3fe4b25 # 🦞 Moltbot — Personal AI Assistant 2026-01-30T03:15:10+01:00 9a71607 # 🦞 OpenClaw — Personal AI Assistant
This Mitchell Hashimoto quote about Bun migrating from Zig to Rust reminded me of a similar conversation I had at a conference last week.
I was talking to someone who worked for a medium sized technology company with a pair of legacy/legendary iPhone and Android apps.
They told me they had just completed a coding-agent driven rewrite of both apps to React Native.
I asked why they chose that, given that coding agents presumably drive down the cost of maintaining separate iPhone and Android apps.
They said that React Native has improved a lot over the past few years and covered everything their apps needed to do.
And... if it turned out to be the wrong decision, they could just port back to native in the future.
Like Mitchell said:
Programming languages used to be LOCK IN, and they're increasingly not so.
I just sent out the April edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access it here.
In this month's newsletter:
- Opus 4.7 and GPT-5.5, both with price increases
- Claude Mythos and LLM security research
- ChatGPT Images 2.0
- More model releases
- Other highlights from my blog
- What I'm using, April 2026 edition
Here's a copy of the March newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
Zig has one of the most stringent anti-LLM policies of any major open source project:
No LLMs for issues.
No LLMs for pull requests.
No LLMs for comments on the bug tracker, including translation. English is encouraged, but not required. You are welcome to post in your native language and rely on others to have their own translation tools of choice to interpret your words.
The most prominent project written in Zig may be the Bun JavaScript runtime, which was acquired by Anthropic in December 2025 and, unsurprisingly, makes heavy use of AI assistance.
Bun operates its own fork of Zig, and recently achieved a 4x performance improvement on Bun compile after adding "parallel semantic analysis and multiple codegen units to the llvm backend". Here's that code. But @bunjavascript says:
We do not currently plan to upstream this, as Zig has a strict ban on LLM-authored contributions.
(Update: here's a Zig core contributor providing details on why they wouldn't accept that particular patch independent of the LLM issue - parallel semantic analysis is a long planned feature but has implications "for the Zig language itself".)
In Contributor Poker and Zig's AI Ban (via Lobste.rs) Zig Software Foundation VP of Community Loris Cro explains the rationale for this strict ban. It's the best articulation I've seen yet for a blanket ban on LLM-assisted contributions:
In successful open source projects you eventually reach a point where you start getting more PRs than what you’re capable of processing. Given what I mentioned so far, it would make sense to stop accepting imperfect PRs in order to maximize ROI from your work, but that’s not what we do in the Zig project. Instead, we try our best to help new contributors to get their work in, even if they need some help getting there. We don’t do this just because it’s the “right” thing to do, but also because it’s the smart thing to do.
Zig values contributors over their contributions. Each contributor represents an investment by the Zig core team - the primary goal of reviewing and accepting PRs isn't to land new code, it's to help grow new contributors who can become trusted and prolific over time.
LLM assistance breaks that completely. It doesn't matter if the LLM helps you submit a perfect PR to Zig - the time the Zig team spends reviewing your work does nothing to help them add new, confident, trustworthy contributors to their overall project.
Loris explains the name here:
The reason I call it “contributor poker” is because, just like people say about the actual card game, “you play the person, not the cards”. In contributor poker, you bet on the contributor, not on the contents of their first PR.
This makes a lot of sense to me. It relates to an idea I've seen circulating elsewhere: if a PR was mostly written by an LLM, why should a project maintainer spend time reviewing and discussing that PR as opposed to firing up their own LLM to solve the same problem?
@scottjla on Twitter in reply to my pelican riding a bicycle benchmark:
I feel like we need to stack these tests now

I checked to confirm that the model (ChatGPT Images 2.0) added the "WHY ARE YOU LIKE THIS" sign of its own accord and it did - the prompt Scott used was:
Create an image of a horse riding an astronaut, where the astronaut is riding a pelican that is riding a bicycle. It looks very chaotic but they all just manage to balance on top of each other
This week's edition of my email newsletter (aka content from this blog delivered to your inbox) features 4 pelicans riding bicycles, 1 possum on an e-scooter, up to 5 raccoons with ham radios hiding in crowds, 5 blog posts, 8 links, 3 quotes and a new chapter of my Agentic Engineering Patterns guide.
I was chatting with my buddy at Google, who's been a tech director there for about 20 years, about their AI adoption. Craziest convo I've had all year.
The TL;DR is that Google engineering appears to have the same AI adoption footprint as John Deere, the tractor company. Most of the industry has the same internal adoption curve: 20% agentic power users, 20% outright refusers, 60% still using Cursor or equivalent chat tool. It turns out Google has this curve too. [...]
There has been an industry-wide hiring freeze for 18+ months, during which time nobody has been moving jobs. So there are no clued-in people coming in from the outside to tell Google how far behind they are, how utterly mediocre they have become as an eng org.
On behalf of @Google, this post doesn't match the state of agentic coding at our company. Over 40K SWEs use agentic coding weekly here. Googlers have access to our own versions of @antigravity, @geminicli, custom models, skills, CLIs and MCPs for our daily work. Orchestrators, agent loops, virtual SWE teams and many other systems are actively available to folks. [...]
Maybe tell your buddy to do some actual work and to stop spreading absolute nonsense. This post is completely false and just pure clickbait.
Update 20th April 2026: Steve doubled down:
My tweet last week about Google's AI adoption drew a lot of pushback, to say the least.
Since then, Googlers from multiple orgs have reached out to me independently and anonymously. They've expressed fear of being doxxed, concern about what they saw as bullying of me, and general corroboration of my original tweet. [...]
Thanks to a tip from Rahim Nathwani, here's a uv run recipe for transcribing an audio file on macOS using the 10.28 GB Gemma 4 E2B model with MLX and mlx-vlm:
uv run --python 3.13 --with mlx_vlm --with torchvision --with gradio \
mlx_vlm.generate \
--model google/gemma-4-e2b-it \
--audio file.wav \
--prompt "Transcribe this audio" \
--max-tokens 500 \
--temperature 1.0
I tried it on this 14 second .wav file and it output the following:
This front here is a quick voice memo. I want to try it out with MLX VLM. Just going to see if it can be transcribed by Gemma and how that works.
(That was supposed to be "This right here..." and "... how well that works" but I can hear why it misinterpreted that as "front" and "how that works".)
Lenny posted another snippet from our 1 hour 40 minute podcast recording and it's about kākāpō parrots!
I think it's non-obvious to many people that the OpenAI voice mode runs on a much older, much weaker model - it feels like the AI that you can talk to should be the smartest AI but it really isn't.
If you ask ChatGPT voice mode for its knowledge cutoff date it tells you April 2024 - it's a GPT-4o era model.
This thought inspired by this Andrej Karpathy tweet about the growing gap in understanding of AI capability based on the access points and domains people are using the models with:
[...] It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and at the same time, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems.
This part really works and has made dramatic strides because 2 properties:
- these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also
- they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them.
A fun thing about recording a podcast with a professional like Lenny Rachitsky is that his team know how to slice the resulting video up into TikTok-sized short form vertical videos. Here's one he shared on Twitter today which ended up attracting over 1.1m views!
That was 48 seconds. Our full conversation lasted 1 hour 40 minutes.
I just sent the March edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access it here. In this month's newsletter:
- More agentic engineering patterns
- Streaming experts with MoE models on a Mac
- Model releases in March
- Vibe porting
- Supply chain attacks against PyPI and NPM
- Stuff I shipped
- What I'm using, March 2026 edition
- And a couple of museums
Here's a copy of the February newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
I wrote about Dan Woods' experiments with streaming experts the other day, the trick where you run larger Mixture-of-Experts models on hardware that doesn't have enough RAM to fit the entire model by instead streaming the necessary expert weights from SSD for each token that you process.
Five days ago Dan was running Qwen3.5-397B-A17B in 48GB of RAM. Today @seikixtc reported running the colossal Kimi K2.5 - a 1 trillion parameter model with 32B active weights at any one time, in 96GB of RAM on an M2 Max MacBook Pro.
And @anemll showed that same Qwen3.5-397B-A17B model running on an iPhone, albeit at just 0.6 tokens/second - iOS repo here.
I think this technique has legs. Dan and his fellow tinkerers are continuing to run autoresearch loops in order to find yet more optimizations to squeeze more performance out of these models.
Update: Now Daniel Isaac got Kimi K2.5 working on a 128GB M4 Max at ~1.7 tokens/second.
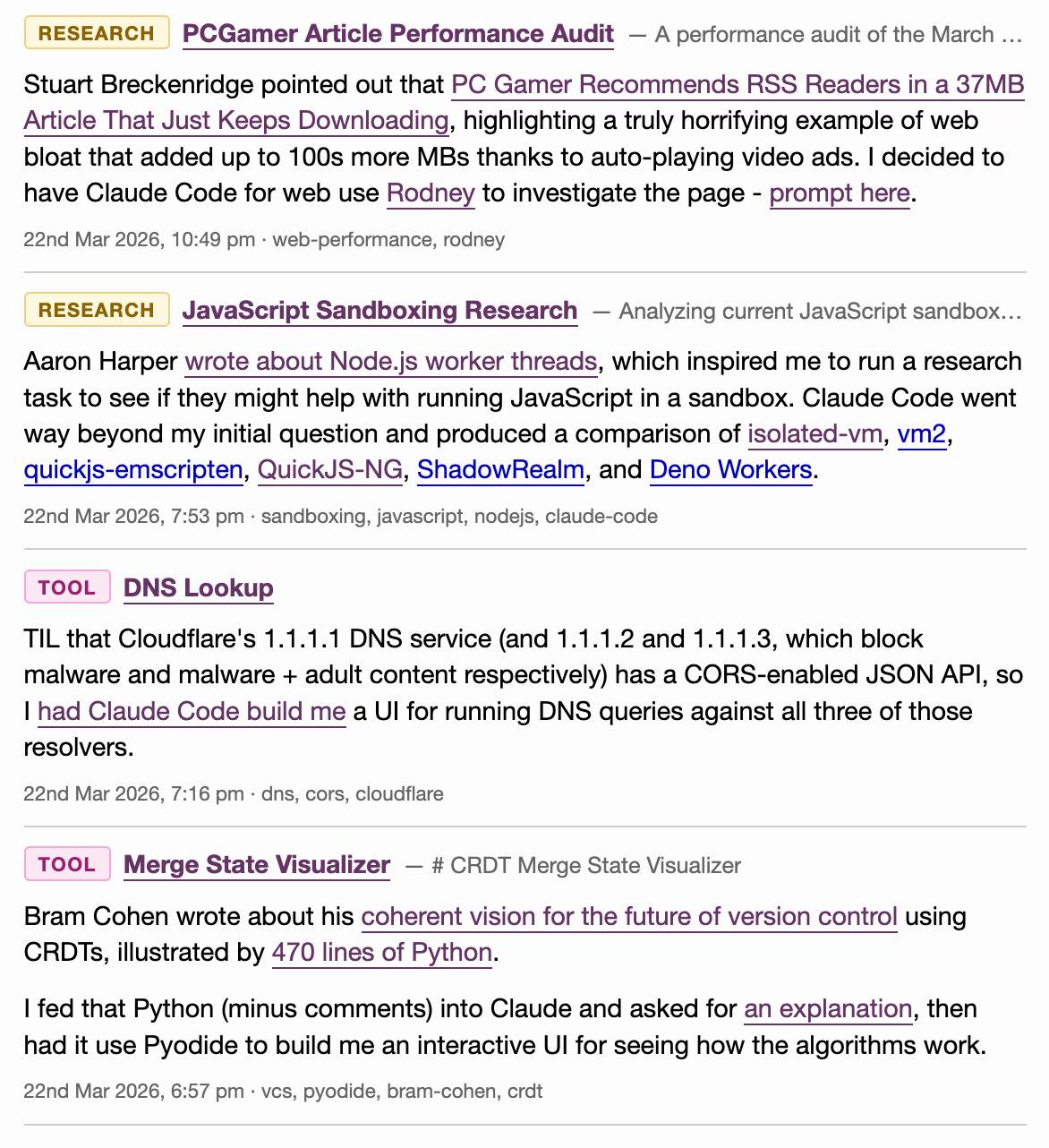
Last month I added a feature I call beats to this blog, pulling in some of my other content from external sources and including it on the homepage, search and various archive pages on the site.
On any given day these frequently outnumber my regular posts. They were looking a little bit thin and were lacking any form of explanation beyond a link, so I've added the ability to annotate them with a "note" which now shows up as part of their display.
Here's what that looks like for the content I published yesterday:
I've also updated the /atom/everything/ Atom feed to include any beats that I've attached notes to.
I just sent the February edition of my sponsors-only monthly newsletter. If you are a sponsor (or if you start a sponsorship now) you can access it here. In this month's newsletter:
- More OpenClaw, and Claws in general
- I started a not-quite-a-book about Agentic Engineering
- StrongDM, Showboat and Rodney
- Kākāpō breeding season
- Model releases
- What I'm using, February 2026 edition
Here's a copy of the January newsletter as a preview of what you'll get. Pay $10/month to stay a month ahead of the free copy!
I use Claude as a proofreader for spelling and grammar via this prompt which also asks it to "Spot any logical errors or factual mistakes". I'm delighted to report that Claude Opus 4.6 called me out on this one:

Because I write about LLMs (and maybe because of my em dash text replacement code) a lot of people assume that the writing on my blog is partially or fully created by those LLMs.
My current policy on this is that if text expresses opinions or has "I" pronouns attached to it then it's written by me. I don't let LLMs speak for me in this way.
I'll let an LLM update code documentation or even write a README for my project but I'll edit that to ensure it doesn't express opinions or say things like "This is designed to help make code easier to maintain" - because that's an expression of a rationale that the LLM just made up.
I use LLMs to proofread text I publish on my blog. I just shared my current prompt for that here.
The latest scourge of Twitter is AI bots that reply to your tweets with generic, banal commentary slop, often accompanied by a question to "drive engagement" and waste as much of your time as possible.
I just found out that the category name for this genre of software is reply guy tools. Amazing.
Reached the stage of parallel agent psychosis where I've lost a whole feature - I know I had it yesterday, but I can't seem to find the branch or worktree or cloud instance or checkout with it in.
... found it! Turns out I'd been hacking on a random prototype in /tmp and then my computer crashed and rebooted and I lost the code... but it's all still there in ~/.claude/projects/ session logs and Claude Code can extract it out and spin up the missing feature again.
I've long been resistant to the idea of accepting sponsorship for my blog. I value my credibility as an independent voice, and I don't want to risk compromising that reputation.
Then I learned about Troy Hunt's approach to sponsorship, which he first wrote about in 2016. Troy runs with a simple text row in the page banner - no JavaScript, no cookies, unobtrusive while providing value to the sponsor. I can live with that!
Accepting sponsorship in this way helps me maintain my independence while offsetting the opportunity cost of not taking a full-time job.
To start with I'm selling sponsorship by the week. Sponsors get that unobtrusive banner across my blog and also their sponsored message at the top of my newsletter.
I will not write content in exchange for sponsorship. I hope the sponsors I work with understand that my credibility as an independent voice is a key reason I have an audience, and compromising that trust would be bad for everyone.
Freeman & Forrest helped me set up and sell my first slots. Thanks also to Theo Browne for helping me think through my approach.