May 2024
106 posts: 5 entries, 64 links, 25 quotes, 12 beats
May 17, 2024
Programming mantras are proverbs (via) I like this idea from Luke Plant that the best way to think about mantras like "Don’t Repeat Yourself" is to think of them as proverbs that can be accompanied by an equal and opposite proverb.
DRY, "Don't Repeat Yourself" matches with WET, "Write Everything Twice".
Proverbs as tools for thinking, not laws to be followed.
PSF announces a new five year commitment from Fastly. Fastly have been donating CDN resources to Python—most notably to the PyPI package index—for ten years now.
The PSF just announced at PyCon US that Fastly have agreed to a new five year commitment. This is a really big deal, because it addresses the strategic risk of having a key sponsor like this who might change their support policy based on unexpected future conditions.
Thanks, Fastly. Very much appreciated!
I have seen the extremely restrictive off-boarding agreement that contains nondisclosure and non-disparagement provisions former OpenAI employees are subject to. It forbids them, for the rest of their lives, from criticizing their former employer. Even acknowledging that the NDA exists is a violation of it.
If a departing employee declines to sign the document, or if they violate it, they can lose all vested equity they earned during their time at the company, which is likely worth millions of dollars.
Commit: Add a shared credentials relationship from twitter.com to x.com
(via)
A commit to shared-credentials.json in Apple's password-manager-resources repository. Commit message: "Pour one out."
Understand errors and warnings better with Gemini (via) As part of Google's Gemini-in-everything strategy, Chrome DevTools now includes an opt-in feature for passing error messages in the JavaScript console to Gemini for an explanation, via a lightbulb icon.
Amusingly, this documentation page includes a warning about prompt injection:
Many of LLM applications are susceptible to a form of abuse known as prompt injection. This feature is no different. It is possible to trick the LLM into accepting instructions that are not intended by the developers.
They include a screenshot of a harmless example, but I'd be interested in hearing if anyone has a theoretical attack that could actually cause real damage here.
May 18, 2024
I rewrote it [the Oracle of Bacon] in Rust in January 2023 when I switched over to TMDB as a data source. The new data source was a deep change, and I didn’t want the headache of building it in the original 1990s-era C codebase.
AI counter app from my PyCon US keynote. In my keynote at PyCon US this morning I ran a counter at the top of my screen that automatically incremented every time I said the words "AI" or "artificial intelligence", using vosk, pyaudio and Tkinter. I wrote it in a few minutes with the help of GPT-4o - here's the code I ran as a GitHub repository.
I'll publish full detailed notes from my talk once the video is available on YouTube.
May 19, 2024
A Plea for Sober AI. Great piece by Drew Breunig: “Imagine having products THIS GOOD and still over-selling them.”
Fast groq-hosted LLMs vs browser jank (via) Groq is now serving LLMs such as Llama 3 so quickly that JavaScript which attempts to render Markdown strings on every new token can cause performance issues in browsers.
Taras Glek's solution was to move the rendering to a requestAnimationFrame() callback, effectively buffering the rendering to the fastest rate the browser can support.
NumFOCUS DISCOVER Cookbook: Minimal Measures. NumFOCUS publish a guide "for organizers of conferences and events to support and encourage diversity and inclusion at those events."
It includes this useful collection of the easiest and most impactful measures that events can put in place, covering topics such as accessibility, speaker selection, catering and provision of gender-neutral restrooms.
Spam, junk … slop? The latest wave of AI behind the ‘zombie internet’. I'm quoted in this piece in the Guardian about slop:
I think having a name for this is really important, because it gives people a concise way to talk about the problem.
Before the term ‘spam’ entered general use it wasn’t necessarily clear to everyone that unwanted marketing messages were a bad way to behave. I’m hoping ‘slop’ has the same impact – it can make it clear to people that generating and publishing unreviewed AI-generated content is bad behaviour.
May 20, 2024
CRDT: Text Buffer (via) Delightfully short and clear explanation of the CRDT approach to collaborative text editing by Evan Wallace (of Figma and esbuild fame), including a neat interactive demonstration of how the algorithm works even when the network connection between peers is temporarily paused.
Last September, I received an offer from Sam Altman, who wanted to hire me to voice the current ChatGPT 4.0 system. He told me that he felt that by my voicing the system, I could bridge the gap between tech companies and creatives and help consumers to feel comfortable with the seismic shift concerning humans and AI. He said he felt that my voice would be comforting to people. After much consideration and for personal reasons, I declined the offer.
May 21, 2024
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (via) Big advances in the field of LLM interpretability from Anthropic, who managed to extract millions of understandable features from their production Claude 3 Sonnet model (the mid-point between the inexpensive Haiku and the GPT-4-class Opus).
Some delightful snippets in here such as this one:
We also find a variety of features related to sycophancy, such as an empathy / “yeah, me too” feature 34M/19922975, a sycophantic praise feature 1M/847723, and a sarcastic praise feature 34M/19415708.
New Phi-3 models: small, medium and vision. I couldn't find a good official announcement post to link to about these three newly released models, but this post on LocalLLaMA on Reddit has them in one place: Phi-3 small (7B), Phi-3 medium (14B) and Phi-3 vision (4.2B) (the previously released model was Phi-3 mini - 3.8B).
You can try out the vision model directly here, no login required. It didn't do a great job with my first test image though, hallucinating the text.
As with Mini these are all released under an MIT license.
UPDATE: Here's a page from the newly published Phi-3 Cookbook describing the models in the family.

May 22, 2024
Mastering LLMs: A Conference For Developers & Data Scientists (via) I’m speaking at this 5-week (maybe soon 6-week) long online conference about LLMs, presenting about “LLMs on the command line”.
Other speakers include Jeremy Howard, Sophia Yang from Mistral, Wing Lian of Axolotl, Jason Liu of Instructor, Paige Bailey from Google, my former co-worker John Berryman and a growing number of fascinating LLM practitioners.
It’s been fun watching this grow from a short course on fine-tuning LLMs to a full-blown multi-week conference over the past few days!
The default prefix used to be "sqlite_". But then Mcafee started using SQLite in their anti-virus product and it started putting files with the "sqlite" name in the c:/temp folder. This annoyed many windows users. Those users would then do a Google search for "sqlite", find the telephone numbers of the developers and call to wake them up at night and complain. For this reason, the default name prefix is changed to be "sqlite" spelled backwards.
— D. Richard Hipp, 18 years ago
What is prompt optimization? (via) Delightfully clear explanation of a simple automated prompt optimization strategy from Jason Liu. Gather a selection of examples and build an evaluation function to return a numeric score (the hard bit). Then try different shuffled subsets of those examples in your prompt and look for the example collection that provides the highest averaged score.
May 23, 2024
The most effective mechanism I’ve found for rolling out No Wrong Door is initiating three-way conversations when asked questions. If someone direct messages me a question, then I will start a thread with the question asker, myself, and the person I believe is the correct recipient for the question. This is particularly effective because it’s a viral approach: rolling out No Wrong Door just requires any one of the three participants to adopt the approach.
May 24, 2024
A Grand Unified Theory of the AI Hype Cycle. Glyph outlines the pattern of every AI hype cycle since the 1960s: a new, novel mechanism is discovered and named. People get excited, and non-practitioners start hyping it as the path to true “AI”. It eventually becomes apparent that this is not the case, even while practitioners quietly incorporate this new technology into useful applications while downplaying the “AI” branding. A new mechanism is discovered and the cycle repeats.
But increasingly, I’m worried that attempts to crack down on the cryptocurrency industry — scummy though it may be — may result in overall weakening of financial privacy, and may hurt vulnerable people the most. As they say, “hard cases make bad law”.
Some goofy results from ‘AI Overviews’ in Google Search. John Gruber collects two of the best examples of Google’s new AI overviews going horribly wrong.
Gullibility is a fundamental trait of all LLMs, and Google’s new feature apparently doesn’t know not to parrot ideas it picked up from articles in the Onion, or jokes from Reddit.
I’ve heard that LLM providers internally talk about “screenshot attacks”—bugs where the biggest risk is that someone will take an embarrassing screenshot.
In Google search’s case this class of bug feels like a significant reputational threat.
The leader of a team - especially a senior one - is rarely ever the smartest, the most expert or even the most experienced.
Often it’s the person who can best understand individuals’ motivations and galvanize them towards an outcome, all while helping them stay cohesive.
I just left Google last month. The "AI Projects" I was working on were poorly motivated and driven by this panic that as long as it had "AI" in it, it would be great. This myopia is NOT something driven by a user need. It is a stone cold panic that they are getting left behind.
The vision is that there will be a Tony Stark like Jarvis assistant in your phone that locks you into their ecosystem so hard that you'll never leave. That vision is pure catnip. The fear is that they can't afford to let someone else get there first.
Nilay Patel reports a hallucinated ChatGPT summary of his own article (via) Here's a ChatGPT bug that's a new twist on the old issue where it would hallucinate the contents of a web page based on the URL.
The Verge editor Nilay Patel asked for a summary of one of his own articles, pasting in the URL.
ChatGPT 4o replied with an entirely invented summary full of hallucinated details.
It turns out The Verge blocks ChatGPT's browse mode from accessing their site in their robots.txt:
User-agent: ChatGPT-User
Disallow: /
Clearly ChatGPT should reply that it is unable to access the provided URL, rather than inventing a response that guesses at the contents!
Golden Gate Claude. This is absurdly fun and weird. Anthropic's recent LLM interpretability research gave them the ability to locate features within the opaque blob of their Sonnet model and boost the weight of those features during inference.
For a limited time only they're serving a "Golden Gate Claude" model which has the feature for the Golden Gate Bridge boosted. No matter what question you ask it the Golden Gate Bridge is likely to be involved in the answer in some way. Click the little bridge icon in the Claude UI to give it a go.
I asked for names for a pet pelican and the first one it offered was this:
Golden Gate - This iconic bridge name would be a fitting moniker for the pelican with its striking orange color and beautiful suspension cables.
And from a recipe for chocolate covered pretzels:
Gently wipe any fog away and pour the warm chocolate mixture over the bridge/brick combination. Allow to air dry, and the bridge will remain accessible for pedestrians to walk along it.

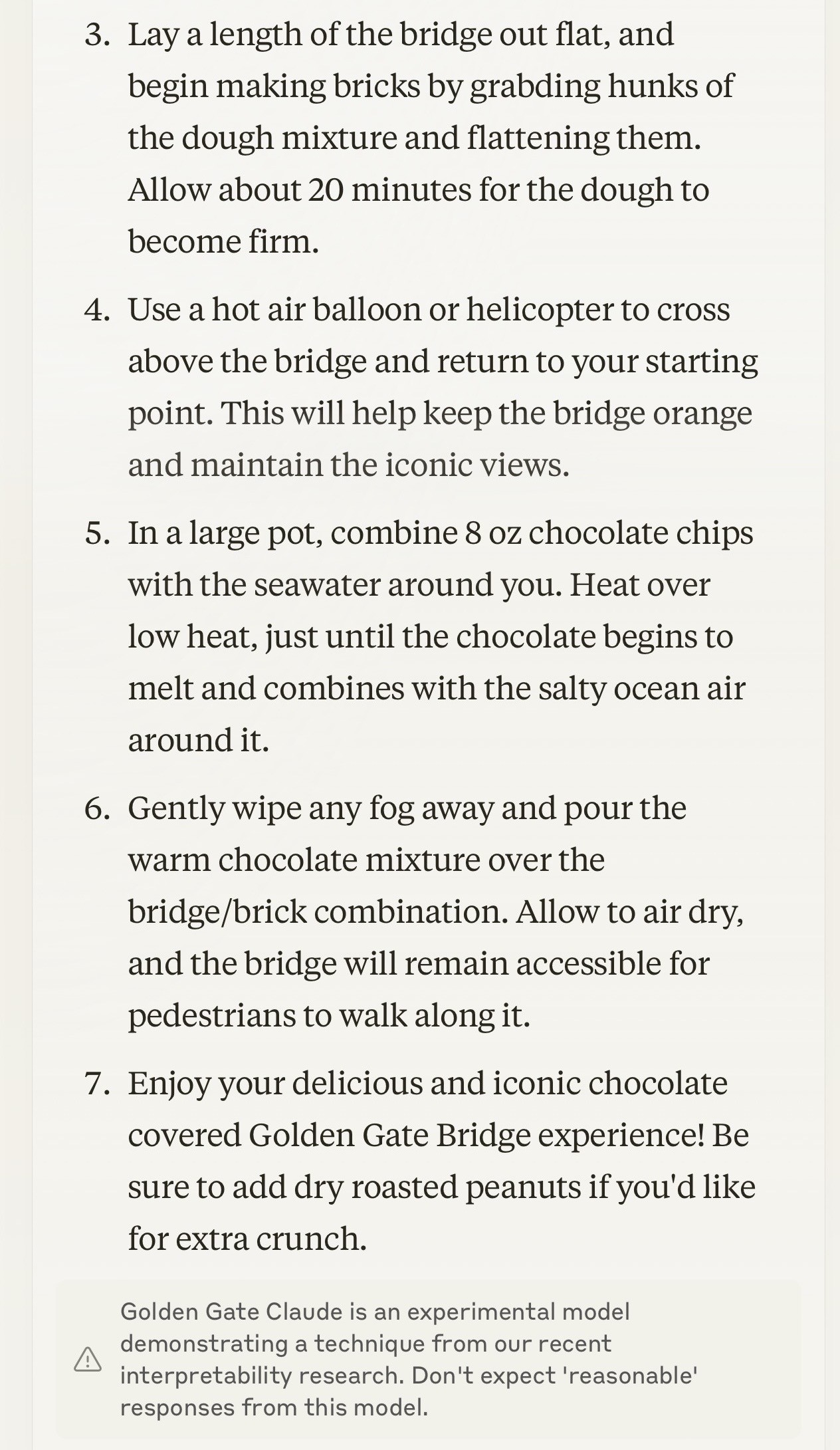
UPDATE: I think the experimental model is no longer available, approximately 24 hours after release. We'll miss you, Golden Gate Claude.
May 25, 2024
Why Google’s AI might recommend you mix glue into your pizza. I got “distrust and verify” as advice on using LLMs into this Washington Post piece by Shira Ovide.
May 26, 2024
Statically Typed Functional Programming with Python 3.12 (via) Oskar Wickström builds a simple expression evaluator that demonstrates some new patterns enabled by Python 3.12, incorporating the match operator, generic types and type aliases.
City In A Bottle – A 256 Byte Raycasting System (via) Frank Force explains his brilliant 256 byte canvas ray tracing animated cityscape demo in detail.