May 2024
106 posts: 5 entries, 64 links, 25 quotes, 12 beats
May 9, 2024
Bullying in Open Source Software Is a Massive Security Vulnerability. The Xz story from last month, where a malicious contributor almost managed to ship a backdoor to a number of major Linux distributions, included a nasty detail where presumed collaborators with the attacker bullied the maintainer to make them more susceptible to accepting help.
Hans-Christoph Steiner from F-Droid reported a similar attempt from a few years ago:
A new contributor submitted a merge request to improve the search, which was oft requested but the maintainers hadn't found time to work on. There was also pressure from other random accounts to merge it. In the end, it became clear that it added a SQL injection vulnerability.
404 Media's Jason Koebler ties the two together here and makes the case for bullying as a genuine form of security exploit in the open source ecosystem.
May 10, 2024
uv pip install --exclude-newer example
(via)
A neat new feature of the uv pip install command is the --exclude-newer option, which can be used to avoid installing any package versions released after the specified date.
Here's a clever example of that in use from the typing_extensions packages CI tests that run against some downstream packages:
uv pip install --system -r test-requirements.txt --exclude-newer $(git show -s --date=format:'%Y-%m-%dT%H:%M:%SZ' --format=%cd HEAD)
They use git show to get the date of the most recent commit (%cd means commit date) formatted as an ISO timestamp, then pass that to --exclude-newer.
Exploring Hacker News by mapping and analyzing 40 million posts and comments for fun
(via)
A real tour de force of data engineering. Wilson Lin fetched 40 million posts and comments from the Hacker News API (using Node.js with a custom multi-process worker pool) and then ran them all through the BGE-M3 embedding model using RunPod, which let him fire up ~150 GPU instances to get the whole run done in a few hours, using a custom RocksDB and Rust queue he built to save on Amazon SQS costs.
Then he crawled 4 million linked pages, embedded that content using the faster and cheaper jina-embeddings-v2-small-en model, ran UMAP dimensionality reduction to render a 2D map and did a whole lot of follow-on work to identify topic areas and make the map look good.
That's not even half the project - Wilson built several interactive features on top of the resulting data, and experimented with custom rendering techniques on top of canvas to get everything to render quickly.
There's so much in here, and both the code and data (multiple GBs of arrow files) are available if you want to dig in and try some of this out for yourself.
In the Hacker News comments Wilson shares that the total cost of the project was a couple of hundred dollars.
One tiny detail I particularly enjoyed - unrelated to the embeddings - was this trick for testing which edge location is closest to a user using JavaScript:
const edge = await Promise.race(
EDGES.map(async (edge) => {
// Run a few times to avoid potential cold start biases.
for (let i = 0; i < 3; i++) {
await fetch(`https://${edge}.edge-hndr.wilsonl.in/healthz`);
}
return edge;
}),
);
May 11, 2024
Ham radio general exam question pool as JSON. I scraped a pass of my Ham radio general exam this morning. One of the tools I used to help me pass was a Datasette instance with all 429 questions from the official question pool. I've published that raw data as JSON on GitHub, which I converted from the official question pool document using an Observable notebook.
Relevant TIL: How I studied for my Ham radio general exam.

May 12, 2024
“Link In Bio” is a slow knife (via) Anil Dash writing in 2019 about how Instagram’s “link in bio” thing (where users cannot post links to things in Instagram posts or comments, just a single link field in their bio) is harmful for linking on the web.
Today it’s even worse. TikTok has the same culture, and LinkedIn and Twitter both algorithmically de-boost anything with a URL in it, encouraging users to share screenshots (often unsourced) rather than linking to content and reducing their distribution.
It’s gross.
About ARDC (Amateur Radio Digital Communications). In ham radio adjacent news, here's a foundation that it's worth knowing about:
ARDC makes grants to projects and organizations that are experimenting with new ways to advance both amateur radio and digital communication science.
In 1981 they were issued the entire 44.x.x.x block of IP addresses - 16 million in total. In 2019 they sold a quarter of those IPs to Amazon for about $100 million, providing them with a very healthy endowment from which they can run their grants program!
Parsing PNG images in Mojo (via) It’s still very early days for Mojo, the new systems programming language from Chris Lattner that imitates large portions of Python and can execute Python code directly via a compatibility layer.
Ferdinand Schenck reports here on building a PNG decoding routine in Mojo, with a detailed dive into both the PNG spec and the current state of the Mojo language.
May 13, 2024
GPUs Go Brrr (via) Fascinating, detailed low-level notes on how to get the most out of NVIDIA's H100 GPUs (currently selling for around $40,000 a piece) from the research team at Stanford who created FlashAttention, among other things.
The swizzled memory layouts are flat-out incorrectly documented, which took considerable time for us to figure out.
I’m no developer, but I got the AI part working in about an hour.
What took longer was the other stuff: identifying the problem, designing and building the UI, setting up the templating, routes and data architecture.
It reminded me that, in order to capitalise on the potential of AI technologies, we need to really invest in the other stuff too, especially data infrastructure.
It would be ironic, and a huge shame, if AI hype sucked all the investment out of those things.
— Tim Paul
Hello GPT-4o. OpenAI announced a new model today: GPT-4o, where the o stands for "omni".
It looks like this is the gpt2-chatbot we've been seeing in the Chat Arena the past few weeks.
GPT-4o doesn't seem to be a huge leap ahead of GPT-4 in terms of "intelligence" - whatever that might mean - but it has a bunch of interesting new characteristics.
First, it's multi-modal across text, images and audio as well. The audio demos from this morning's launch were extremely impressive.
ChatGPT's previous voice mode worked by passing audio through a speech-to-text model, then an LLM, then a text-to-speech for the output. GPT-4o does everything with the one model, reducing latency to the point where it can act as a live interpreter between people speaking in two different languages. It also has the ability to interpret tone of voice, and has much more control over the voice and intonation it uses in response.
It's very science fiction, and has hints of uncanny valley. I can't wait to try it out - it should be rolling out to the various OpenAI apps "in the coming weeks".
Meanwhile the new model itself is already available for text and image inputs via the API and in the Playground interface, as model ID "gpt-4o" or "gpt-4o-2024-05-13". My first impressions are that it feels notably faster than gpt-4-turbo.
This announcement post also includes examples of image output from the new model. It looks like they may have taken big steps forward in two key areas of image generation: output of text (the "Poetic typography" examples) and maintaining consistent characters across multiple prompts (the "Character design - Geary the robot" example).
The size of the vocabulary of the tokenizer - effectively the number of unique integers used to represent text - has increased to ~200,000 from ~100,000 for GPT-4 and GPT-3.5. Inputs in Gujarati use 4.4x fewer tokens, Japanese uses 1.4x fewer, Spanish uses 1.1x fewer. Previously languages other than English paid a material penalty in terms of how much text could fit into a prompt, it's good to see that effect being reduced.
Also notable: the price. OpenAI claim a 50% price reduction compared to GPT-4 Turbo. Conveniently, gpt-4o costs exactly 10x gpt-3.5: 4o is $5/million input tokens and $15/million output tokens. 3.5 is $0.50/million input tokens and $1.50/million output tokens.
(I was a little surprised not to see a price decrease there to better compete with the less expensive Claude 3 Haiku.)
The price drop is particularly notable because OpenAI are promising to make this model available to free ChatGPT users as well - the first time they've directly made their "best" model available to non-paying customers.
Tucked away right at the end of the post:
We plan to launch support for GPT-4o's new audio and video capabilities to a small group of trusted partners in the API in the coming weeks.
I'm looking forward to learning more about these video capabilities, which were hinted at by some of the live demos in this morning's presentation.
LLM 0.14, with support for GPT-4o. It's been a while since the last LLM release. This one adds support for OpenAI's new model:
llm -m gpt-4o "fascinate me"
Also a new llm logs -r (or --response) option for getting back just the response from your last prompt, without wrapping it in Markdown that includes the prompt.
Plus nine new plugins since 0.13!
May 14, 2024
Why your voice assistant might be sexist (via) Given OpenAI's demo yesterday of a vocal chat assistant with a flirty, giggly female voice - and the new ability to be interrupted! - it's worth revisiting this piece by Chris Baraniuk from June 2022 about gender dynamics in voice assistants. Includes a link to this example of a synthesized non-binary voice.
How developers are using Gemini 1.5 Pro’s 1 million token context window. I got to be a talking head for a few seconds in an intro video for today's Google I/O keynote, talking about how I used Gemini Pro 1.5 to index my bookshelf (and with a cameo from my squirrel nutcracker). I'm at 1m25s.
(Or at 10m6s in the full video of the keynote)
llm-gemini 0.1a4.
A new release of my llm-gemini plugin adding support for the Gemini 1.5 Flash model that was revealed this morning at Google I/O.
I'm excited about this new model because of its low price. Flash is $0.35 per 1 million tokens for prompts up to 128K token and $0.70 per 1 million tokens for longer prompts - up to a million tokens now and potentially two million at some point in the future. That's 1/10th of the price of Gemini Pro 1.5, cheaper than GPT 3.5 ($0.50/million) and only a little more expensive than Claude 3 Haiku ($0.25/million).
Context caching for Google Gemini (via) Another new Gemini feature announced today. Long context models enable answering questions against large chunks of text, but the price of those long prompts can be prohibitive - $3.50/million for Gemini Pro 1.5 up to 128,000 tokens and $7/million beyond that.
Context caching offers a price optimization, where the long prefix prompt can be reused between requests, halving the cost per prompt but at an additional cost of $4.50 / 1 million tokens per hour to keep that context cache warm.
Given that hourly extra charge this isn't a default optimization for all cases, but certain high traffic applications might be able to save quite a bit on their longer prompt systems.
It will be interesting to see if other vendors such as OpenAI and Anthropic offer a similar optimization in the future.
Update 14th August 2024: Anthropic's Claude now has its own version of prompt caching.
May 15, 2024
The MacBook Airs are Apple’s best-selling laptops; the iPad Pros are Apple’s least-selling iPads. I think it’s as simple as this: the current MacBook Airs have the M3, not the M4, because there isn’t yet sufficient supply of M4 chips to satisfy demand for MacBook Airs.
But unlike the phone system, we can’t separate an LLM’s data from its commands. One of the enormously powerful features of an LLM is that the data affects the code. We want the system to modify its operation when it gets new training data. We want it to change the way it works based on the commands we give it. The fact that LLMs self-modify based on their input data is a feature, not a bug. And it’s the very thing that enables prompt injection.
How to PyCon (via) Glyph’s tips on making the most out of PyCon. I particularly like his suggestion that “dinners are for old friends, but lunches are for new ones”.
I’m heading out to Pittsburgh tonight, and giving a keynote (!) on Saturday. If you see me there please come and say hi!
If we want LLMs to be less hype and more of a building block for creating useful everyday tools for people, AI companies' shift away from scaling and AGI dreams to acting like regular product companies that focus on cost and customer value proposition is a welcome development.
ChatGPT in “4o” mode is not running the new features yet
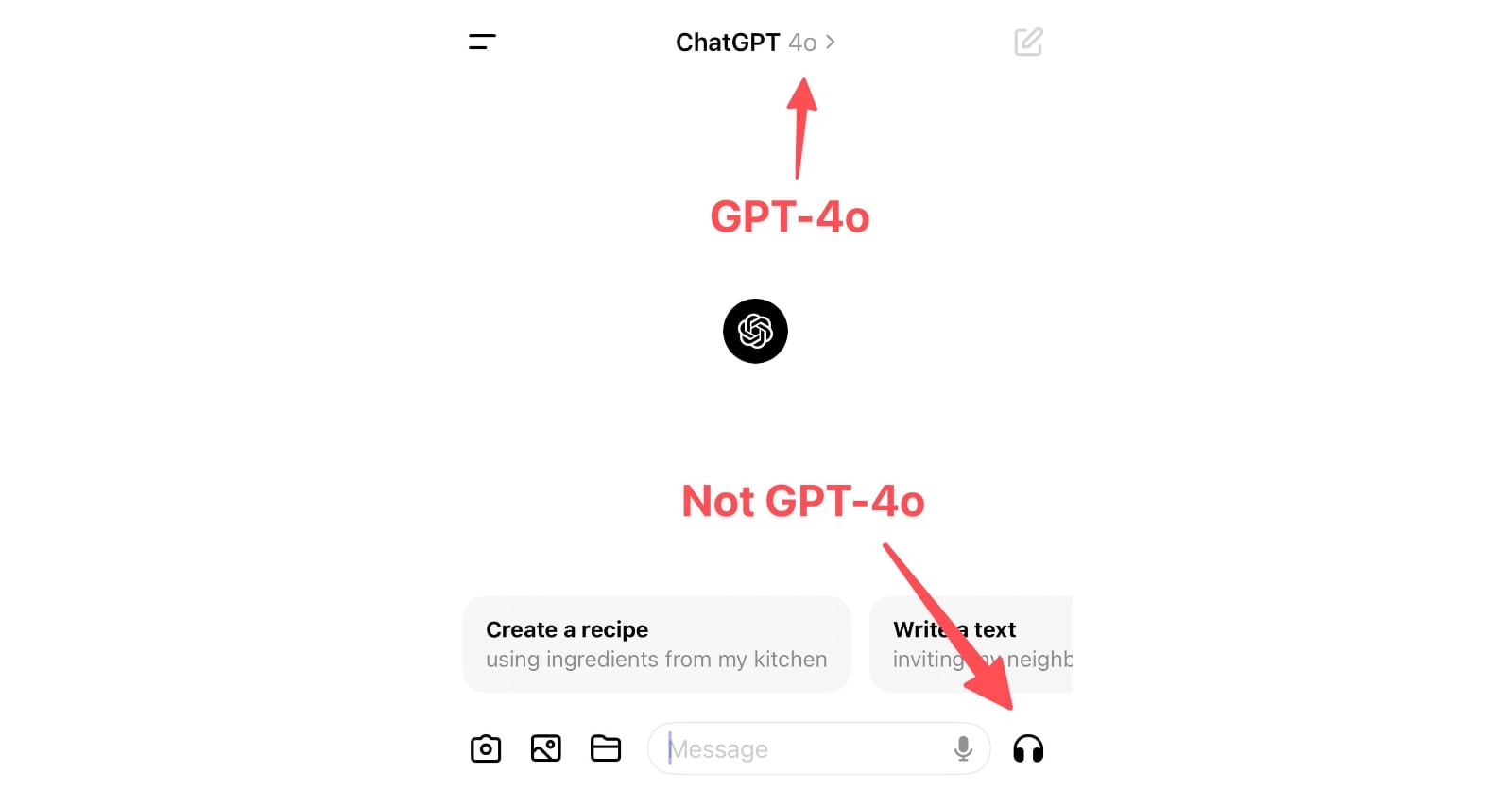
Monday’s OpenAI announcement of their new GPT-4o model included some intriguing new features:
[... 898 words]OpenAI: Managing your work in the API platform with Projects (via) New OpenAI API feature: you can now create API keys for "projects" that can have a monthly spending cap. The UI for that limit says:
If the project's usage exceeds this amount in a given calendar month (UTC), subsequent API requests will be rejected
You can also set custom token-per-minute and request-per-minute rate limits for individual models.
I've been wanting this for ages: this means it's finally safe to ship a weird public demo on top of their various APIs without risk of accidental bankruptcy if the demo goes viral!
PaliGemma model README (via) One of the more over-looked announcements from Google I/O yesterday was PaliGemma, an openly licensed VLM (Vision Language Model) in the Gemma family of models.
The model accepts an image and a text prompt. It outputs text, but that text can include special tokens representing regions on the image. This means it can return both bounding boxes and fuzzier segment outlines of detected objects, behavior that can be triggered using a prompt such as "segment puffins".
From the README:
PaliGemma uses the Gemma tokenizer with 256,000 tokens, but we further extend its vocabulary with 1024 entries that represent coordinates in normalized image-space (
<loc0000>...<loc1023>), and another with 128 entries (<seg000>...<seg127>) that are codewords used by a lightweight referring-expression segmentation vector-quantized variational auto-encoder (VQ-VAE) [...]
You can try it out on Hugging Face.
It's a 3B model, making it feasible to run on consumer hardware.
But where the company once limited itself to gathering low-hanging fruit along the lines of “what time is the super bowl,” on Tuesday executives showcased generative AI tools that will someday plan an entire anniversary dinner, or cross-country-move, or trip abroad. A quarter-century into its existence, a company that once proudly served as an entry point to a web that it nourished with traffic and advertising revenue has begun to abstract that all away into an input for its large language models.
May 16, 2024
[...] by default Heroku will spin up multiple dynos in different availability zones. It also has multiple routers in different zones so if one zone should go completely offline, having a second dyno will mean that your app can still serve traffic.