130 posts tagged “gpt”
The GPT series of Large Language Models from OpenAI.
2025
GPT-5 Thinking in ChatGPT (aka Research Goblin) is shockingly good at search

“Don’t use chatbots as search engines” was great advice for several years... until it wasn’t.
[... 2,679 words]Rich Pixels. Neat Python library by Darren Burns adding pixel image support to the Rich terminal library, using tricks to render an image using full or half-height colored blocks.
Here's the key trick - it renders Unicode ▄ (U+2584, "lower half block") characters after setting a foreground and background color for the two pixels it needs to display.
I got GPT-5 to vibe code up a show_image.py terminal command which resizes the provided image to fit the width and height of the current terminal and displays it using Rich Pixels. That script is here, you can run it with uv like this:
uv run https://tools.simonwillison.net/python/show_image.py \
image.jpg
Here's what I got when I ran it against my V&A East Storehouse photo from this post:
![]()
The perils of vibe coding. I was interviewed by Elaine Moore for this opinion piece in the Financial Times, which ended up in the print edition of the paper too! I picked up a copy yesterday:
![The perils of vibe coding - A new OpenAI model arrived this month with a glossy livestream, group watch parties and a lingering sense of disappointment. The YouTube comment section was underwhelmed. “I think they are all starting to realize this isn’t going to become the world like they thought it would,” wrote one viewer. “I can see it on their faces.” But if the casual user was unimpressed, the AI model’s saving grace may be vibe. Coding is generative AI’s newest battleground. With big bills to pay, high valuations to live up to and a market wobble to erase, the sector needs to prove its corporate productivity chops. Coding is hardly promoted as a business use case that already works. For one thing, AI-generated code holds the promise of replacing programmers — a profession of very well paid people. For another, the work can be quantified. In April, Microsoft chief executive Satya Nadella said that up to 50 per cent of the company’s code was now being written by AI. Google chief executive Sundar Pichai has said the same thing. Salesforce has paused engineering hires and Mark Zuckerberg told podcaster Joe Rogan that Meta would use AI as a “mid-level engineer” that writes code. Meanwhile, start-ups such as Replit and Cursor’s Anysphere are trying to persuade people that with AI, anyone can code. In theory, every employee can become a software engineer. So why aren’t we? One possibility is that it’s all still too unfamiliar. But when I ask people who write code for a living they offer an alternative suggestion: unpredictability. As programmer Simon Willison put it: “A lot of people are missing how weird and funny this space is. I’ve been a computer programmer for 30 years and [AI models] don’t behave like normal computers.” Willison is well known in the software engineering community for his AI experiments. He’s an enthusiastic vibe coder — using LLMs to generate code using natural language prompts. OpenAI’s latest model GPT-3.1s, he is now favourite. Still, he predicts that a vibe coding crash is due if it is used to produce glitchy software. It makes sense that programmers — people who are interested in finding new ways to solve problems — would be early adopters of LLMs. Code is a language, albeit an abstract one. And generative AI is trained in nearly all of them, including older ones like Cobol. That doesn’t mean they accept all of its suggestions. Willison thinks the best way to see what a new model can do is to ask for something unusual. He likes to request an svg (an image made out of lines described with code) of a pelican on a bike and asks it to remember the chickens in his garden by name. Results can be bizarre. One model ignored key prompts in favour of composing a poem. Still, his adventures in vibe coding sound like an advert for the sector’s future. Anthropic’s Claude Code, the favoured model for developers, to make an OCR (optical character recognition) software loves screenshots) tool that will copy and paste text from a screenshot. He wrote software that summarises blog comments and has planned to cut a custom tool that will alert him when a whale is visible from his Pacific coast home. All this by typing prompts in English. It’s sounds like the sort of thing Bill Gates might have had in mind when he wrote that natural language AI agents would bring about “the biggest revolution in computing since we went from typing commands to tapping on icons”. But watching code appear and know how it works are two different things. My efforts to make my own comment summary tool produced something unworkable that gave overly long answers and then congratulated itself as a success. Willison says he wouldn’t use AI-generated code for projects he planned to ship out unless he had reviewed each line. Not only is there the risk of hallucination but the chatbot’s desire to be agreeable means it may an unusable idea works. That is a particular issue for those of us who don’t know how to fix the code. We risk creating software with hidden problems. It may not save time either. A study published in July by the non-profit Model Evaluation and Threat Research assessed work done by 16 developers — some with AI tools, some without. Those using AI assistance it had made them faster. In fact it took them nearly a fifth longer. Several developers I spoke to said AI was best used as a way to talk through coding problems. It’s a version of something they call rubber ducking (after their habit of talking to the toys on their desk) — only this rubber duck can talk back. As one put it, code shouldn’t be judged by volume or speed. Progress in AI coding is tangible. But measuring productivity gains is not as neat as a simple percentage calculation.](https://static.simonwillison.net/static/2025/ft.jpeg)
From the article, with links added by me to relevant projects:
Willison thinks the best way to see what a new model can do is to ask for something unusual. He likes to request an SVG (an image made out of lines described with code) of a pelican on a bike and asks it to remember the chickens in his garden by name. Results can be bizarre. One model ignored his prompts in favour of composing a poem.
Still, his adventures in vibe coding sound like an advert for the sector. He used Anthropic's Claude Code, the favoured model for developers, to make an OCR (optical character recognition - software loves acronyms) tool that will copy and paste text from a screenshot.
He wrote software that summarises blog comments and has plans to build a custom tool that will alert him when a whale is visible from his Pacific coast home. All this by typing prompts in English.
I've been talking about that whale spotting project for far too long. Now that it's been in the FT I really need to build it.
(On the subject of OCR... I tried extracting the text from the above image using GPT-5 and got a surprisingly bad result full of hallucinated details. Claude Opus 4.1 did a lot better but still made some mistakes. Gemini 2.5 did much better.)
GPT-5 has a hidden system prompt. It looks like GPT-5 when accessed via the OpenAI API may have its own hidden system prompt, independent from the system prompt you can specify in an API call.
At the very least it's getting sent the current date. I tried this just now:
llm -m gpt-5 'current date'
That returned "2025-08-15", confirming that the date has been fed to the model as part of a hidden prompt.
llm -m gpt-5 'current date' --system 'speak french'
Returned "La date actuelle est le 15 août 2025", showing that offering my own custom system prompt did not over-ride the invisible one that includes the date.
GPT-5 is very resistant to sharing the details of this secret system prompt, but Tommy Hughes managed to extract the following:
Current date: 2025-08-15
You are an AI assistant accessed via an API. Your output may need to be parsed by code or displayed
# Desired oververbosity for the final answer (not analysis): 3
An oververbosity of 1 means the model should respond using only the minimal content necessary to satisfy the request, using concise phrasing and avoiding extra detail or explanation.
An oververbosity of 10 means the model should provide maximally detailed, thorough responses with context, explanations, and possibly multiple examples.
The desired oververbosity should be treated only as a *default*. Defer to any user or developer requirements regarding response length, if present.
# Valid channels: analysis, commentary, final. Channel must be included for every message.
# Juice: 64
I've not been able to confirm this myself, but a search for "desired oververbosity" on GitHub shows that a similar prompt has leaked from ChatGPT (including for o3) in the past. I suspect Tommy's leaked prompt is accurate here.
I tried asking GPT-5 about "oververbosity" via its API:
llm -m gpt-5 'explain your oververbosity settings, what is it right now?'
And got back:
- What it is: I adjust how detailed I am based on a “verbosity” level—ranging from very brief to very detailed—so answers fit your needs.
- Current setting: Concise (about 3/10). I prioritize direct answers with minimal extra context and keep explanations short unless you ask for more.
- How to change it: Just say what you want, e.g.:
- “One-sentence answer” or “TL;DR” (very brief)
- “Give a concise summary” (short bullets)
- “Walk me through in detail,” “Deep dive,” or “Include examples/edge cases” (more detailed)
- Note: For ambiguous, technical, or safety-critical topics, I may add brief clarifications even when being concise.
Presumably this is part of OpenAI's instruction hierarchy concept, with these instructions taking precedence over the developer instructions provided by API users (my --system 'speak french' option above).
I'd very much appreciate official documentation that describes this! As an API user I want to know everything that is being fed into the model - I would be much more comfortable with a hidden prompt like this if I knew exactly what was in it.
LLM 0.27, the annotated release notes: GPT-5 and improved tool calling
I shipped LLM 0.27 today (followed by a 0.27.1 with minor bug fixes), adding support for the new GPT-5 family of models from OpenAI plus a flurry of improvements to the tool calling features introduced in LLM 0.26. Here are the annotated release notes.
[... 1,174 words]If you've been experimenting with OpenAI's Codex CLI and have been frustrated that it's not possible to select text and copy it to the clipboard, at least when running in the Mac terminal (I genuinely didn't know it was possible to build a terminal app that disabled copy and paste) you should know that they fixed that in this issue last week.
The new 0.20.0 version from three days ago also completely removes the old TypeScript codebase in favor of Rust. Even installations via NPM now get the Rust version.
I originally installed Codex via Homebrew, so I had to run this command to get the updated version:
brew upgrade codex
Another Codex tip: to use GPT-5 (or any other specific OpenAI model) you can run it like this:
export OPENAI_DEFAULT_MODEL="gpt-5"
codex
This no longer works, see update below.
I've been using a codex-5 script on my PATH containing this, because sometimes I like to live dangerously!
#!/usr/bin/env zsh
# Usage: codex-5 [additional args passed to `codex`]
export OPENAI_DEFAULT_MODEL="gpt-5"
exec codex --dangerously-bypass-approvals-and-sandbox "$@"
Update: It looks like GPT-5 is the default model in v0.20.0 already.
Also the environment variable I was using no longer does anything, it was removed in this commit (I used Codex Web to help figure that out). You can use the -m model_id command-line option instead.
the percentage of users using reasoning models each day is significantly increasing; for example, for free users we went from <1% to 7%, and for plus users from 7% to 24%.
— Sam Altman, revealing quite how few people used the old model picker to upgrade from GPT-4o
The issue with GPT-5 in a nutshell is that unless you pay for model switching & know to use GPT-5 Thinking or Pro, when you ask “GPT-5” you sometimes get the best available AI & sometimes get one of the worst AIs available and it might even switch within a single conversation.
— Ethan Mollick, highlighting that GPT-5 (high) ranks top on Artificial Analysis, GPT-5 (minimal) ranks lower than GPT-4.1
GPT-5 rollout updates:
- We are going to double GPT-5 rate limits for ChatGPT Plus users as we finish rollout.
- We will let Plus users choose to continue to use 4o. We will watch usage as we think about how long to offer legacy models for.
- GPT-5 will seem smarter starting today. Yesterday, the autoswitcher broke and was out of commission for a chunk of the day, and the result was GPT-5 seemed way dumber. Also, we are making some interventions to how the decision boundary works that should help you get the right model more often.
- We will make it more transparent about which model is answering a given query.
- We will change the UI to make it easier to manually trigger thinking.
- Rolling out to everyone is taking a bit longer. It’s a massive change at big scale. For example, our API traffic has about doubled over the past 24 hours…
We will continue to work to get things stable and will keep listening to feedback. As we mentioned, we expected some bumpiness as we roll out so many things at once. But it was a little more bumpy than we hoped for!
The surprise deprecation of GPT-4o for ChatGPT consumers
I’ve been dipping into the r/ChatGPT subreddit recently to see how people are reacting to the GPT-5 launch, and so far the vibes there are not good. This AMA thread with the OpenAI team is a great illustration of the single biggest complaint: a lot of people are very unhappy to lose access to the much older GPT-4o, previously ChatGPT’s default model for most users.
[... 933 words]A couple of weeks ago I was invited to OpenAI's headquarters for a "preview event", for which I had to sign both an NDA and a video release waiver. I suspected it might relate to either GPT-5 or the OpenAI open weight models... and GPT-5 it was!
OpenAI had invited five developers: Claire Vo, Theo Browne, Ben Hylak, Shawn @swyx Wang, and myself. We were all given early access to the new models and asked to spend a couple of hours (of paid time, see my disclosures) experimenting with them, while being filmed by a professional camera crew.
The resulting video is now up on YouTube. Unsurprisingly most of my edits related to SVGs of pelicans.
GPT-5: Key characteristics, pricing and model card

I’ve had preview access to the new GPT-5 model family for the past two weeks (see related video and my disclosures) and have been using GPT-5 as my daily-driver. It’s my new favorite model. It’s still an LLM—it’s not a dramatic departure from what we’ve had before—but it rarely screws up and generally feels competent or occasionally impressive at the kinds of things I like to use models for.
[... 2,448 words]2024
I can now run a GPT-4 class model on my laptop

Meta’s new Llama 3.3 70B is a genuinely GPT-4 class Large Language Model that runs on my laptop.
[... 2,905 words]OK, I can partly explain the LLM chess weirdness now
(via)
Last week Dynomight published Something weird is happening with LLMs and chess pointing out that most LLMs are terrible chess players with the exception of gpt-3.5-turbo-instruct (OpenAI's last remaining completion as opposed to chat model, which they describe as "Similar capabilities as GPT-3 era models").
After diving deep into this, Dynomight now has a theory. It's mainly about completion models v.s. chat models - a completion model like gpt-3.5-turbo-instruct naturally outputs good next-turn suggestions, but something about reformatting that challenge as a chat conversation dramatically reduces the quality of the results.
Through extensive prompt engineering Dynomight got results out of GPT-4o that were almost as good as the 3.5 instruct model. The two tricks that had the biggest impact:
- Examples. Including just three examples of inputs (with valid chess moves) and expected outputs gave a huge boost in performance.
- "Regurgitation" - encouraging the model to repeat the entire sequence of previous moves before outputting the next move, as a way to help it reconstruct its context regarding the state of the board.
They experimented a bit with fine-tuning too, but I found their results from prompt engineering more convincing.
No non-OpenAI models have exhibited any talents for chess at all yet. I think that's explained by the A.2 Chess Puzzles section of OpenAI's December 2023 paper Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision:
The GPT-4 pretraining dataset included chess games in the format of move sequence known as Portable Game Notation (PGN). We note that only games with players of Elo 1800 or higher were included in pretraining.
Notes from Bing Chat—Our First Encounter With Manipulative AI

I participated in an Ars Live conversation with Benj Edwards of Ars Technica today, talking about that wild period of LLM history last year when Microsoft launched Bing Chat and it instantly started misbehaving, gaslighting and defaming people.
[... 438 words]Prompt GPT-4o audio. A week and a half ago I built a tool for experimenting with OpenAI's new audio input. I just put together the other side of that, for experimenting with audio output.
Once you've provided an API key (which is saved in localStorage) you can use this to prompt the gpt-4o-audio-preview model with a system and regular prompt and select a voice for the response.
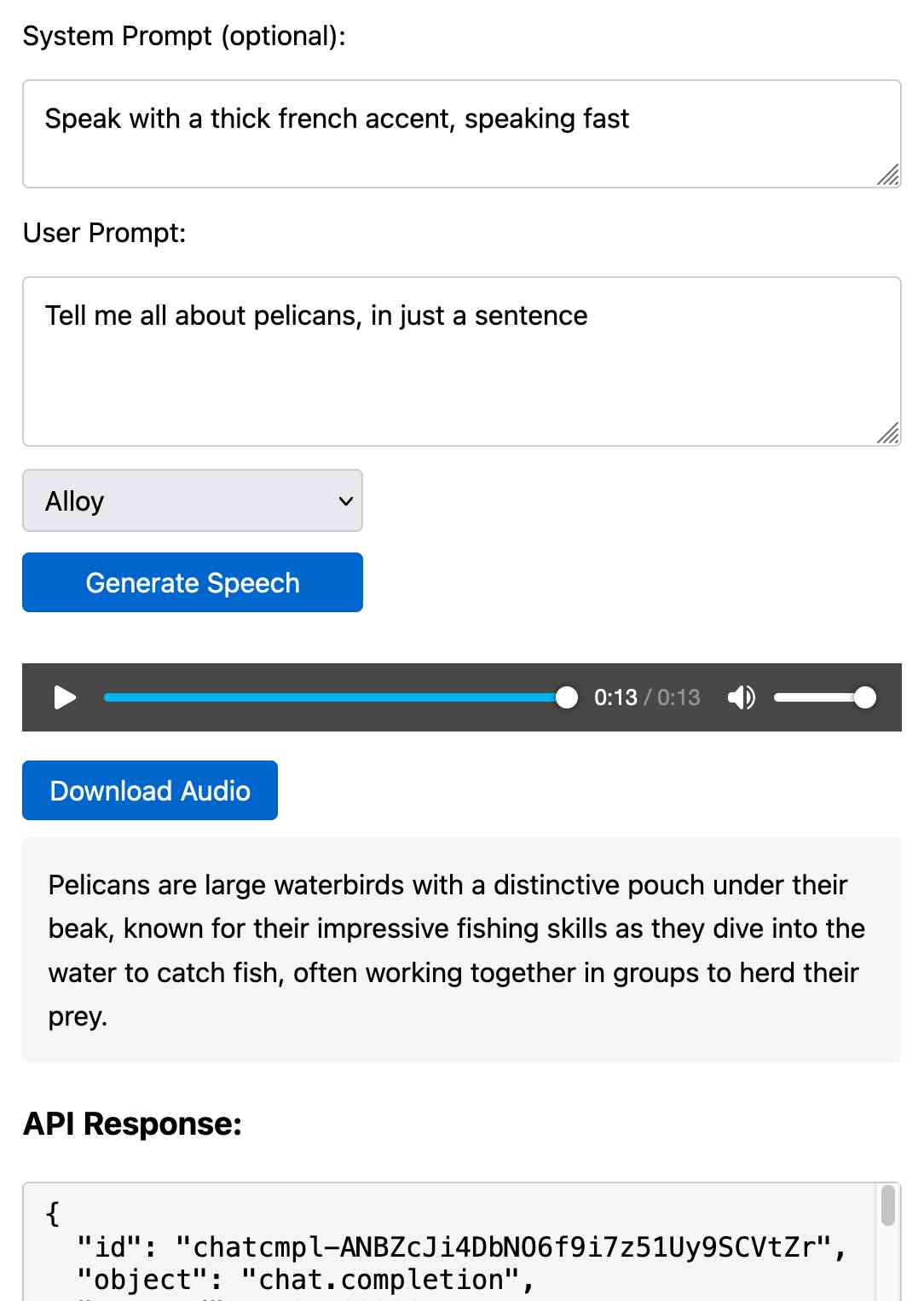
I built it with assistance from Claude: initial app, adding system prompt support.
You can preview and download the resulting wav file, and you can also copy out the raw JSON. If you save that in a Gist you can then feed its Gist ID to https://tools.simonwillison.net/gpt-4o-audio-player?gist=GIST_ID_HERE (Claude transcript) to play it back again.
You can try using that to listen to my French accented pelican description.
There's something really interesting to me here about this form of application which exists entirely as HTML and JavaScript that uses CORS to talk to various APIs. GitHub's Gist API is accessible via CORS too, so it wouldn't take much more work to add a "save" button which writes out a new Gist after prompting for a personal access token. I prototyped that a bit here.
Experimenting with audio input and output for the OpenAI Chat Completion API
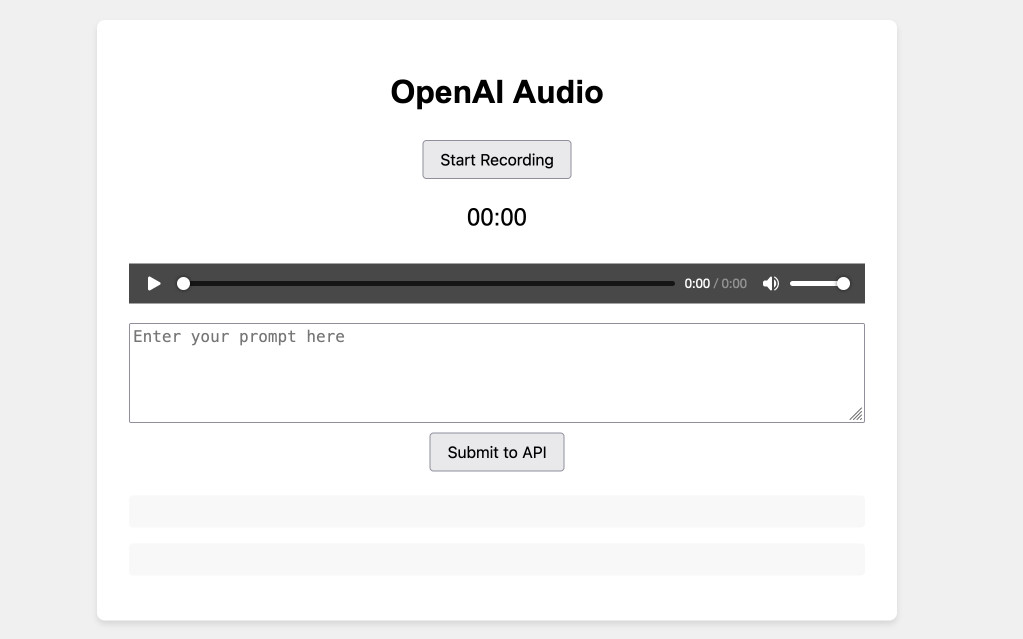
OpenAI promised this at DevDay a few weeks ago and now it’s here: their Chat Completion API can now accept audio as input and return it as output. OpenAI still recommend their WebSocket-based Realtime API for audio tasks, but the Chat Completion API is a whole lot easier to write code against.
[... 1,555 words]My @covidsewage bot now includes useful alt text. I've been running a @covidsewage Mastodon bot for a while now, posting daily screenshots (taken with shot-scraper) of the Santa Clara County COVID in wastewater dashboard.
Prior to today the screenshot was accompanied by the decidedly unhelpful alt text "Screenshot of the latest Covid charts".
I finally fixed that today, closing issue #2 more than two years after I first opened it.
The screenshot is of a Microsoft Power BI dashboard. I hoped I could scrape the key information out of it using JavaScript, but the weirdness of their DOM proved insurmountable.
Instead, I'm using GPT-4o - specifically, this Python code (run using a python -c block in the GitHub Actions YAML file):
import base64, openai client = openai.OpenAI() with open('/tmp/covid.png', 'rb') as image_file: encoded_image = base64.b64encode(image_file.read()).decode('utf-8') messages = [ {'role': 'system', 'content': 'Return the concentration levels in the sewersheds - single paragraph, no markdown'}, {'role': 'user', 'content': [ {'type': 'image_url', 'image_url': { 'url': 'data:image/png;base64,' + encoded_image }} ]} ] completion = client.chat.completions.create(model='gpt-4o', messages=messages) print(completion.choices[0].message.content)
I'm base64 encoding the screenshot and sending it with this system prompt:
Return the concentration levels in the sewersheds - single paragraph, no markdown
Given this input image:
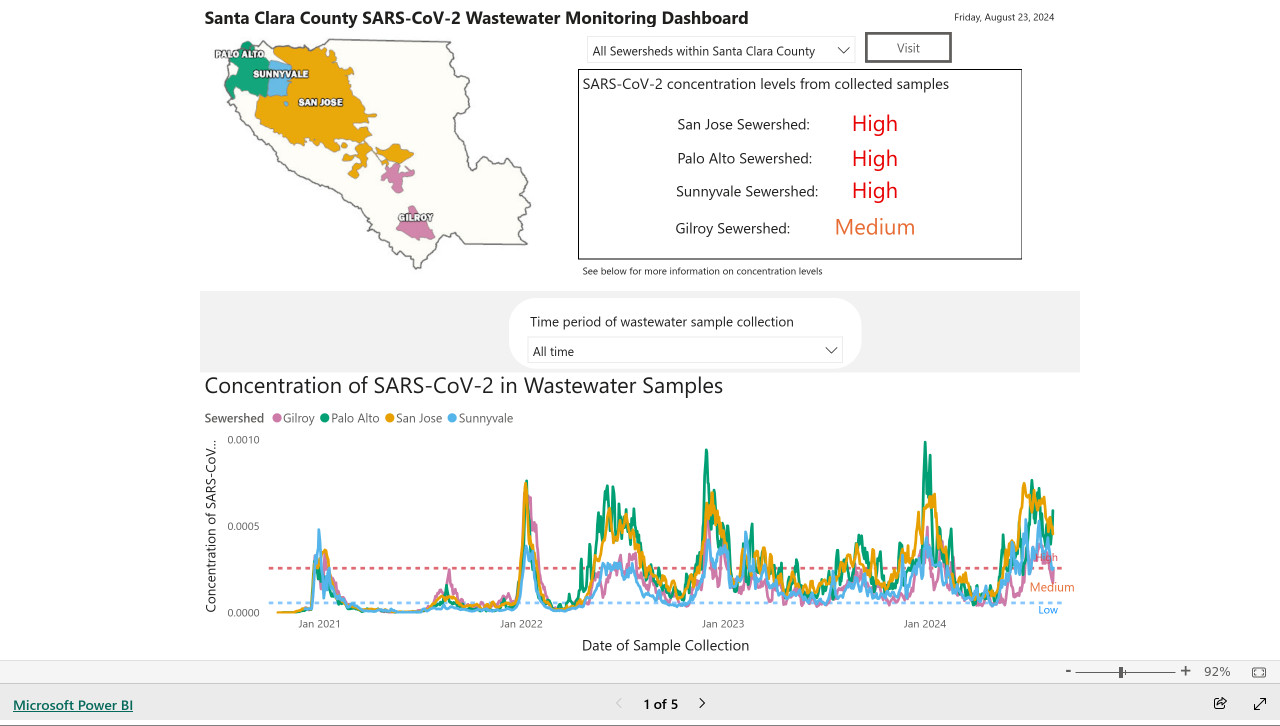
Here's the text that comes back:
The concentration levels of SARS-CoV-2 in the sewersheds from collected samples are as follows: San Jose Sewershed has a high concentration, Palo Alto Sewershed has a high concentration, Sunnyvale Sewershed has a high concentration, and Gilroy Sewershed has a medium concentration.
The full implementation can be found in the GitHub Actions workflow, which runs on a schedule at 7am Pacific time every day.
Using gpt-4o-mini as a reranker. Tip from David Zhang: "using gpt-4-mini as a reranker gives you better results, and now with strict mode it's just as reliable as any other reranker model".
David's code here demonstrates the Vercel AI SDK for TypeScript, and its support for structured data using Zod schemas.
const res = await generateObject({
model: gpt4MiniModel,
prompt: `Given the list of search results, produce an array of scores measuring the liklihood of the search result containing information that would be useful for a report on the following objective: ${objective}\n\nHere are the search results:\n<results>\n${resultsString}\n</results>`,
system: systemMessage(),
schema: z.object({
scores: z
.object({
reason: z
.string()
.describe(
'Think step by step, describe your reasoning for choosing this score.',
),
id: z.string().describe('The id of the search result.'),
score: z
.enum(['low', 'medium', 'high'])
.describe(
'Score of relevancy of the result, should be low, medium, or high.',
),
})
.array()
.describe(
'An array of scores. Make sure to give a score to all ${results.length} results.',
),
}),
});It's using the trick where you request a reason key prior to the score, in order to implement chain-of-thought - see also Matt Webb's Braggoscope Prompts.
CalcGPT (via) Fun satirical GPT-powered calculator demo by Calvin Liang, originally built in July 2023. From the ChatGPT-generated artist statement:
The piece invites us to reflect on the necessity and relevance of AI in every aspect of our lives as opposed to its prevailing use as a mere marketing gimmick. With its delightful slowness and propensity for computational errors, CalcGPT elicits mirth while urging us to question our zealous indulgence in all things AI.
The source code shows that it's using babbage-002 (a GPT3-era OpenAI model which I hadn't realized was still available through their API) that takes a completion-style prompt, which Calvin primes with some examples before including the user's entered expression from the calculator:
1+1=2
5-2=3
2*4=8
9/3=3
10/3=3.33333333333
${math}=
It sets \n as the stop sequence.
Accidental GPT-4o voice preview (via) Reddit user RozziTheCreator was one of a small group who were accidentally granted access to the new multimodal GPT-4o audio voice feature. They captured this video of it telling them a spooky story, complete with thunder sound effects added to the background and in a very realistic voice that clearly wasn't the one from the 4o demo that sounded similar to Scarlet Johansson.
OpenAI provided a comment for this Tom's Guide story confirming the accidental rollout so I don't think this is a faked video.
A Picture is Worth 170 Tokens: How Does GPT-4o Encode Images? (via) Oran Looney dives into the question of how GPT-4o tokenizes images - an image "costs" just 170 tokens, despite being able to include more text than could be encoded in that many tokens by the standard tokenizer.
There are some really neat tricks in here. I particularly like the experimental validation section where Oran creates 5x5 (and larger) grids of coloured icons and asks GPT-4o to return a JSON matrix of icon descriptions. This works perfectly at 5x5, gets 38/49 for 7x7 and completely fails at 13x13.
I'm not convinced by the idea that GPT-4o runs standard OCR such as Tesseract to enhance its ability to interpret text, but I would love to understand more about how this all works. I imagine a lot can be learned from looking at how openly licensed vision models such as LLaVA work, but I've not tried to understand that myself yet.
Extracting Concepts from GPT-4. A few weeks ago Anthropic announced they had extracted millions of understandable features from their Claude 3 Sonnet model.
Today OpenAI are announcing a similar result against GPT-4:
We used new scalable methods to decompose GPT-4’s internal representations into 16 million oft-interpretable patterns.
These features are "patterns of activity that we hope are human interpretable". The release includes code and a paper, Scaling and evaluating sparse autoencoders paper (PDF) which credits nine authors, two of whom - Ilya Sutskever and Jan Leike - are high profile figures that left OpenAI within the past month.
The most fun part of this release is the interactive tool for exploring features. This highlights some interesting features on the homepage, or you can hit the "I'm feeling lucky" button to bounce to a random feature. The most interesting I've found so far is feature 5140 which seems to combine God's approval, telling your doctor about your prescriptions and information passed to the Admiralty.
This note shown on the explorer is interesting:
Only 65536 features available. Activations shown on The Pile (uncopyrighted) instead of our internal training dataset.
Here's the full Pile Uncopyrighted, which I hadn't seen before. It's the standard Pile but with everything from the Books3, BookCorpus2, OpenSubtitles, YTSubtitles, and OWT2 subsets removed.
The realization hit me [when the GPT-3 paper came out] that an important property of the field flipped. In ~2011, progress in AI felt constrained primarily by algorithms. We needed better ideas, better modeling, better approaches to make further progress. If you offered me a 10X bigger computer, I'm not sure what I would have even used it for. GPT-3 paper showed that there was this thing that would just become better on a large variety of practical tasks, if you only trained a bigger one. Better algorithms become a bonus, not a necessity for progress in AGI. Possibly not forever and going forward, but at least locally and for the time being, in a very practical sense. Today, if you gave me a 10X bigger computer I would know exactly what to do with it, and then I'd ask for more.
Hello GPT-4o. OpenAI announced a new model today: GPT-4o, where the o stands for "omni".
It looks like this is the gpt2-chatbot we've been seeing in the Chat Arena the past few weeks.
GPT-4o doesn't seem to be a huge leap ahead of GPT-4 in terms of "intelligence" - whatever that might mean - but it has a bunch of interesting new characteristics.
First, it's multi-modal across text, images and audio as well. The audio demos from this morning's launch were extremely impressive.
ChatGPT's previous voice mode worked by passing audio through a speech-to-text model, then an LLM, then a text-to-speech for the output. GPT-4o does everything with the one model, reducing latency to the point where it can act as a live interpreter between people speaking in two different languages. It also has the ability to interpret tone of voice, and has much more control over the voice and intonation it uses in response.
It's very science fiction, and has hints of uncanny valley. I can't wait to try it out - it should be rolling out to the various OpenAI apps "in the coming weeks".
Meanwhile the new model itself is already available for text and image inputs via the API and in the Playground interface, as model ID "gpt-4o" or "gpt-4o-2024-05-13". My first impressions are that it feels notably faster than gpt-4-turbo.
This announcement post also includes examples of image output from the new model. It looks like they may have taken big steps forward in two key areas of image generation: output of text (the "Poetic typography" examples) and maintaining consistent characters across multiple prompts (the "Character design - Geary the robot" example).
The size of the vocabulary of the tokenizer - effectively the number of unique integers used to represent text - has increased to ~200,000 from ~100,000 for GPT-4 and GPT-3.5. Inputs in Gujarati use 4.4x fewer tokens, Japanese uses 1.4x fewer, Spanish uses 1.1x fewer. Previously languages other than English paid a material penalty in terms of how much text could fit into a prompt, it's good to see that effect being reduced.
Also notable: the price. OpenAI claim a 50% price reduction compared to GPT-4 Turbo. Conveniently, gpt-4o costs exactly 10x gpt-3.5: 4o is $5/million input tokens and $15/million output tokens. 3.5 is $0.50/million input tokens and $1.50/million output tokens.
(I was a little surprised not to see a price decrease there to better compete with the less expensive Claude 3 Haiku.)
The price drop is particularly notable because OpenAI are promising to make this model available to free ChatGPT users as well - the first time they've directly made their "best" model available to non-paying customers.
Tucked away right at the end of the post:
We plan to launch support for GPT-4o's new audio and video capabilities to a small group of trusted partners in the API in the coming weeks.
I'm looking forward to learning more about these video capabilities, which were hinted at by some of the live demos in this morning's presentation.
Extracting data from unstructured text and images with Datasette and GPT-4 Turbo. Datasette Extract is a new Datasette plugin that uses GPT-4 Turbo (released to general availability today) and GPT-4 Vision to extract structured data from unstructured text and images.
I put together a video demo of the plugin in action today, and posted it to the Datasette Cloud blog along with screenshots and a tutorial describing how to use it.
“The king is dead”—Claude 3 surpasses GPT-4 on Chatbot Arena for the first time. I’m quoted in this piece by Benj Edwards for Ars Technica:
“For the first time, the best available models—Opus for advanced tasks, Haiku for cost and efficiency—are from a vendor that isn’t OpenAI. That’s reassuring—we all benefit from a diversity of top vendors in this space. But GPT-4 is over a year old at this point, and it took that year for anyone else to catch up.”
In every group I speak to, from business executives to scientists, including a group of very accomplished people in Silicon Valley last night, much less than 20% of the crowd has even tried a GPT-4 class model.
Less than 5% has spent the required 10 hours to know how they tick.
The GPT-4 barrier has finally been broken
Four weeks ago, GPT-4 remained the undisputed champion: consistently at the top of every key benchmark, but more importantly the clear winner in terms of “vibes”. Almost everyone investing serious time exploring LLMs agreed that it was the most capable default model for the majority of tasks—and had been for more than a year.
[... 717 words]Inflection-2.5: meet the world’s best personal AI (via) I’ve not been paying much attention to Inflection’s Pi since it released last year, but yesterday they released a new version that they claim is competitive with GPT-4.
“Inflection-2.5 approaches GPT-4’s performance, but used only 40% of the amount of compute for training.”
(I wasn’t aware that the compute used to train GPT-4 was public knowledge.)
If this holds true, that means that the GPT-4 barrier has been well and truly smashed: we now have Claude 3 Opus, Gemini 1.5, Mistral Large and Inflection-2.5 in the same class as GPT-4, up from zero contenders just a month ago.