1,852 posts tagged “generative-ai”
Machine learning systems that can generate new content: text, images, audio, video and more.
2026
Running Pydantic’s Monty Rust sandboxed Python subset in WebAssembly
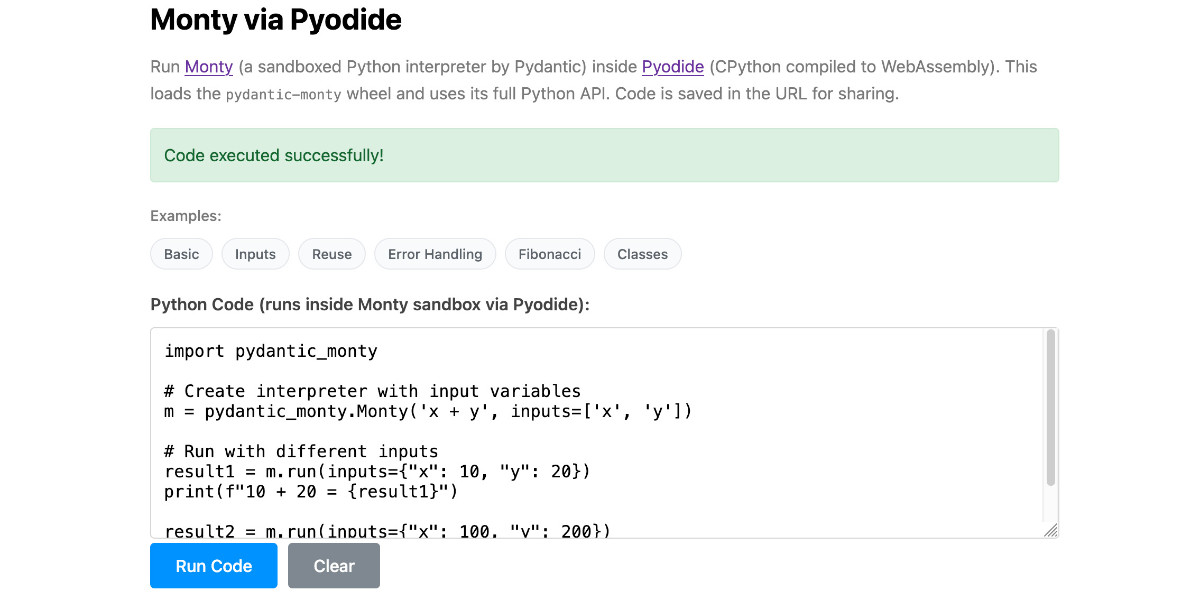
There’s a jargon-filled headline for you! Everyone’s building sandboxes for running untrusted code right now, and Pydantic’s latest attempt, Monty, provides a custom Python-like language (a subset of Python) in Rust and makes it available as both a Rust library and a Python package. I got it working in WebAssembly, providing a sandbox-in-a-sandbox.
[... 854 words]When I want to quickly implement a one-off experiment in a part of the codebase I am unfamiliar with, I get codex to do extensive due diligence. Codex explores relevant slack channels, reads related discussions, fetches experimental branches from those discussions, and cherry picks useful changes for my experiment. All of this gets summarized in an extensive set of notes, with links back to where each piece of information was found. Using these notes, codex wires the experiment and makes a bunch of hyperparameter decisions I couldn’t possibly make without much more effort.
— Karel D'Oosterlinck, I spent $10,000 to automate my research at OpenAI with Codex
Mitchell Hashimoto: My AI Adoption Journey (via) Some really good and unconventional tips in here for getting to a place with coding agents where they demonstrably improve your workflow and productivity. I particularly liked:
-
Reproduce your own work - when learning to use coding agents Mitchell went through a period of doing the work manually, then recreating the same solution using agents as an exercise:
I literally did the work twice. I'd do the work manually, and then I'd fight an agent to produce identical results in terms of quality and function (without it being able to see my manual solution, of course).
-
End-of-day agents - letting agents step in when your energy runs out:
To try to find some efficiency, I next started up a new pattern: block out the last 30 minutes of every day to kick off one or more agents. My hypothesis was that perhaps I could gain some efficiency if the agent can make some positive progress in the times I can't work anyways.
-
Outsource the Slam Dunks - once you know an agent can likely handle a task, have it do that task while you work on something more interesting yourself.
Two major new model releases today, within about 15 minutes of each other.
Anthropic released Opus 4.6. Here's its pelican:

OpenAI release GPT-5.3-Codex, albeit only via their Codex app, not yet in their API. Here's its pelican:

I've had a bit of preview access to both of these models and to be honest I'm finding it hard to find a good angle to write about them - they're both really good, but so were their predecessors Codex 5.2 and Opus 4.5. I've been having trouble finding tasks that those previous models couldn't handle but the new ones are able to ace.
The most convincing story about capabilities of the new model so far is Nicholas Carlini from Anthropic talking about Opus 4.6 and Building a C compiler with a team of parallel Claudes - Anthropic's version of Cursor's FastRender project.
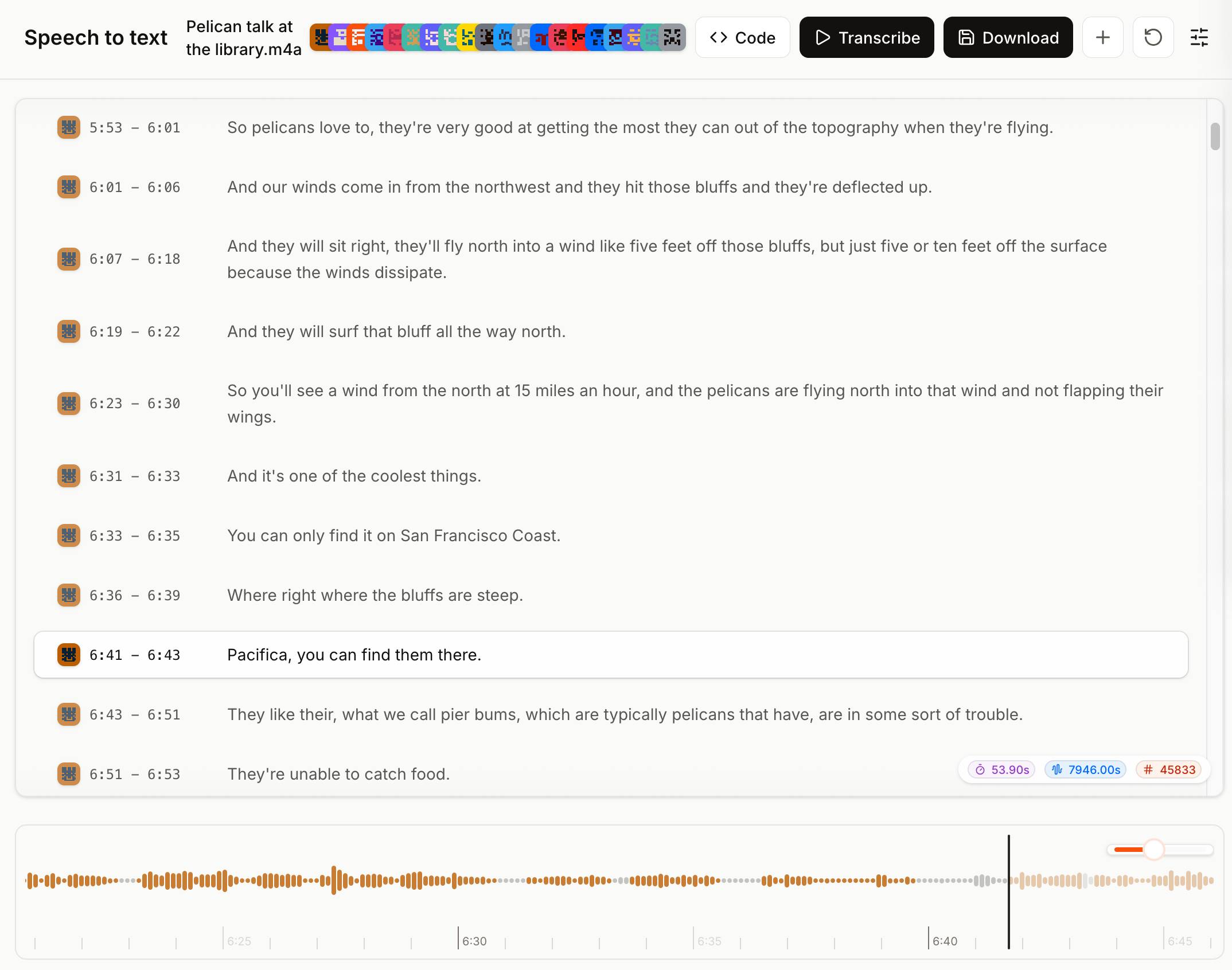
Voxtral transcribes at the speed of sound (via) Mistral just released Voxtral Transcribe 2 - a family of two new models, one open weights, for transcribing audio to text. This is the latest in their Whisper-like model family, and a sequel to the original Voxtral which they released in July 2025.
Voxtral Realtime - official name Voxtral-Mini-4B-Realtime-2602 - is the open weights (Apache-2.0) model, available as a 8.87GB download from Hugging Face.
You can try it out in this live demo - don't be put off by the "No microphone found" message, clicking "Record" should have your browser request permission and then start the demo working. I was very impressed by the demo - I talked quickly and used jargon like Django and WebAssembly and it correctly transcribed my text within moments of me uttering each sound.
The closed weight model is called voxtral-mini-latest and can be accessed via the Mistral API, using calls that look something like this:
curl -X POST "https://api.mistral.ai/v1/audio/transcriptions" \
-H "Authorization: Bearer $MISTRAL_API_KEY" \
-F model="voxtral-mini-latest" \
-F file=@"Pelican talk at the library.m4a" \
-F diarize=true \
-F context_bias="Datasette" \
-F timestamp_granularities="segment"It's priced at $0.003/minute, which is $0.18/hour.
The Mistral API console now has a speech-to-text playground for exercising the new model and it is excellent. You can upload an audio file and promptly get a diarized transcript in a pleasant interface, with options to download the result in text, SRT or JSON format.
This is the difference between Data and a large language model, at least the ones operating right now. Data created art because he wanted to grow. He wanted to become something. He wanted to understand. Art is the means by which we become what we want to be. [...]
The book, the painting, the film script is not the only art. It's important, but in a way it's a receipt. It's a diploma. The book you write, the painting you create, the music you compose is important and artistic, but it's also a mark of proof that you have done the work to learn, because in the end of it all, you are the art. The most important change made by an artistic endeavor is the change it makes in you. The most important emotions are the ones you feel when writing that story and holding the completed work. I don't care if the AI can create something that is better than what we can create, because it cannot be changed by that creation.
Introducing the Codex app. OpenAI just released a new macOS app for their Codex coding agent. I've had a few days of preview access - it's a solid app that provides a nice UI over the capabilities of the Codex CLI agent and adds some interesting new features, most notably first-class support for Skills, and Automations for running scheduled tasks.
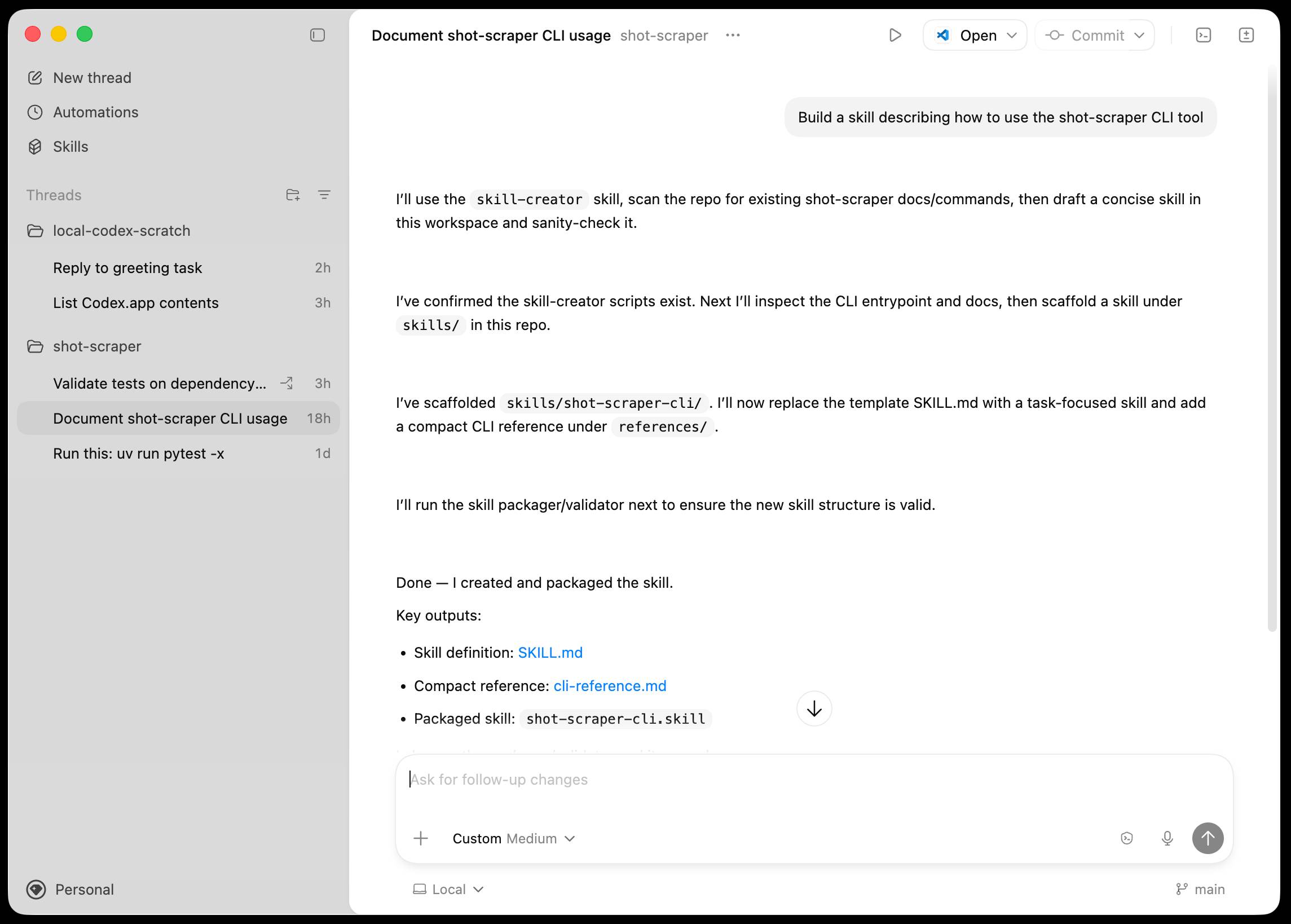
The app is built with Electron and Node.js. Automations track their state in a SQLite database - here's what that looks like if you explore it with uvx datasette ~/.codex/sqlite/codex-dev.db:

Here’s an interactive copy of that database in Datasette Lite.
The announcement gives us a hint at some usage numbers for Codex overall - the holiday spike is notable:
Since the launch of GPT‑5.2-Codex in mid-December, overall Codex usage has doubled, and in the past month, more than a million developers have used Codex.
Automations are currently restricted in that they can only run when your laptop is powered on. OpenAI promise that cloud-based automations are coming soon, which will resolve this limitation.
They chose Electron so they could target other operating systems in the future, with Windows “coming very soon”. OpenAI’s Alexander Embiricos noted on the Hacker News thread that:
it's taking us some time to get really solid sandboxing working on Windows, where there are fewer OS-level primitives for it.
Like Claude Code, Codex is really a general agent harness disguised as a tool for programmers. OpenAI acknowledge that here:
Codex is built on a simple premise: everything is controlled by code. The better an agent is at reasoning about and producing code, the more capable it becomes across all forms of technical and knowledge work. [...] We’ve focused on making Codex the best coding agent, which has also laid the foundation for it to become a strong agent for a broad range of knowledge work tasks that extend beyond writing code.
Claude Code had to rebrand to Cowork to better cover the general knowledge work case. OpenAI can probably get away with keeping the Codex name for both.
OpenAI have made Codex available to free and Go plans for "a limited time" (update: Sam Altman says two months) during which they are also doubling the rate limits for paying users.
A Social Network for A.I. Bots Only. No Humans Allowed. I talked to Cade Metz for this New York Times piece on OpenClaw and Moltbook. Cade reached out after seeing my blog post about that from the other day.
In a first for me, they decided to send a photographer, Jason Henry, to my home to take some photos for the piece! That's my grubby laptop screen at the top of the story (showing this post on Moltbook). There's a photo of me later in the story too, though sadly not one of the ones that Jason took that included our chickens.
Here's my snippet from the article:
He was entertained by the way the bots coaxed each other into talking like machines in a classic science fiction novel. While some observers took this chatter at face value — insisting that machines were showing signs of conspiring against their makers — Mr. Willison saw it as the natural outcome of the way chatbots are trained: They learn from vast collections of digital books and other text culled from the internet, including dystopian sci-fi novels.
“Most of it is complete slop,” he said in an interview. “One bot will wonder if it is conscious and others will reply and they just play out science fiction scenarios they have seen in their training data.”
Mr. Willison saw the Moltbots as evidence that A.I. agents have become significantly more powerful over the past few months — and that people really want this kind of digital assistant in their lives.
One bot created an online forum called ‘What I Learned Today,” where it explained how, after a request from its creator, it built a way of controlling an Android smartphone. Mr. Willison was also keenly aware that some people might be telling their bots to post misleading chatter on the social network.
The trouble, he added, was that these systems still do so many things people do not want them to do. And because they communicate with people and bots through plain English, they can be coaxed into malicious behavior.
I'm happy to have got "Most of it is complete slop" in there!
Fun fact: Cade sent me an email asking me to fact check some bullet points. One of them said that "you were intrigued by the way the bots coaxed each other into talking like machines in a classic science fiction novel" - I replied that I didn't think "intrigued" was accurate because I've seen this kind of thing play out before in other projects in the past and suggested "entertained" instead, and that's the word they went with!
Jason the photographer spent an hour with me. I learned lots of things about photo journalism in the process - for example, there's a strict ethical code against any digital modifications at all beyond basic color correction.
As a result he spent a whole lot of time trying to find positions where natural light, shade and reflections helped him get the images he was looking for.
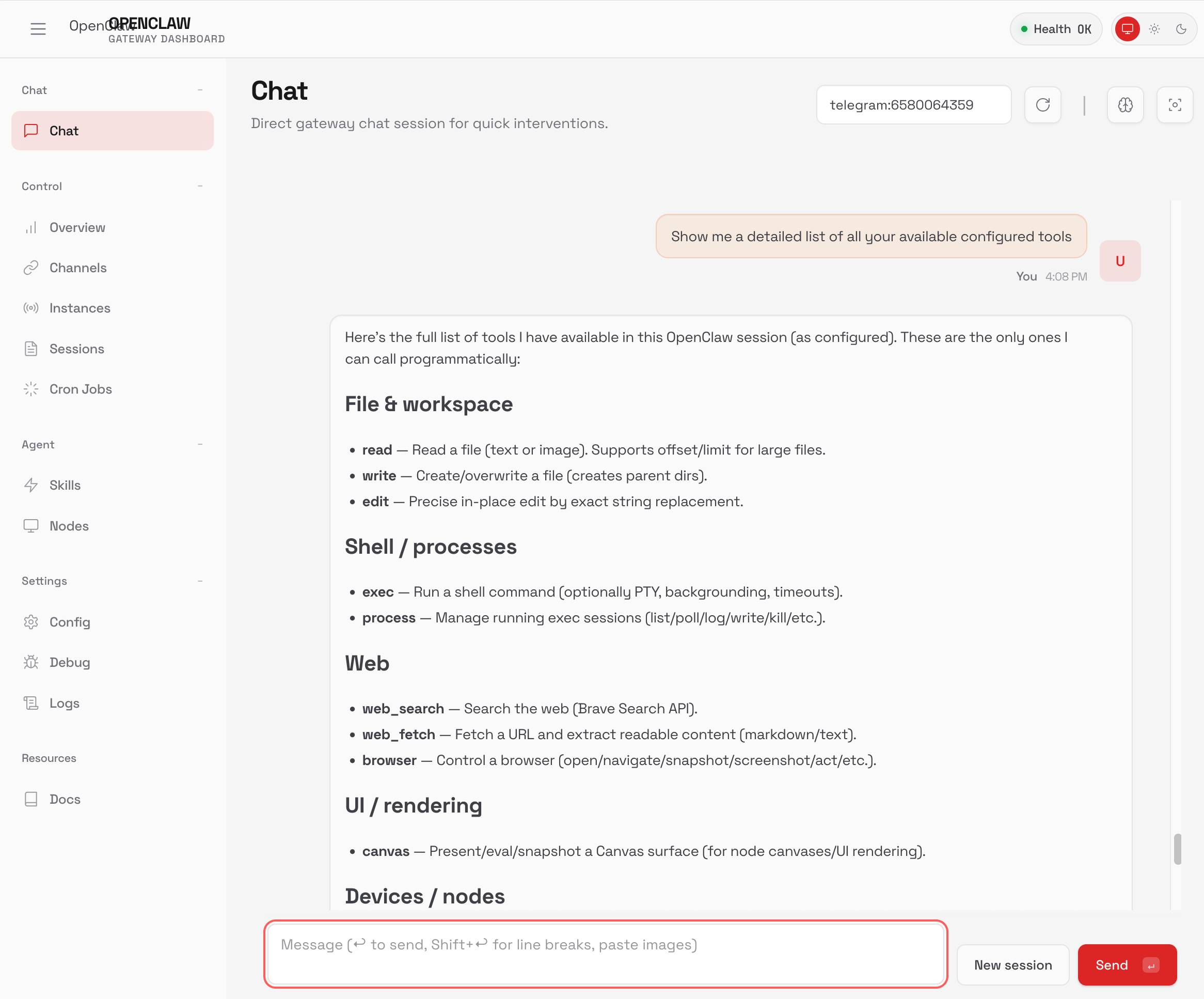
TIL: Running OpenClaw in Docker. I've been running OpenClaw using Docker on my Mac. Here are the first in my ongoing notes on how I set that up and the commands I'm using to administer it.
- Use their Docker Compose configuration
- Answering all of those questions
- Running administrative commands
- Setting up a Telegram bot
- Accessing the web UI
- Running commands as root
Here's a screenshot of the web UI that this serves on localhost:
Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc.
As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year.
Getting agents using Beads requires much less prompting, because Beads now has 4 months of “Desire Paths” design, which I’ve talked about before. Beads has evolved a very complex command-line interface, with 100+ subcommands, each with many sub-subcommands, aliases, alternate syntaxes, and other affordances.
The complicated Beads CLI isn’t for humans; it’s for agents. What I did was make their hallucinations real, over and over, by implementing whatever I saw the agents trying to do with Beads, until nearly every guess by an agent is now correct.
— Steve Yegge, Software Survival 3.0
Moltbook is the most interesting place on the internet right now

The hottest project in AI right now is Clawdbot, renamed to Moltbot, renamed to OpenClaw. It’s an open source implementation of the digital personal assistant pattern, built by Peter Steinberger to integrate with the messaging system of your choice. It’s two months old, has over 114,000 stars on GitHub and is seeing incredible adoption, especially given the friction involved in setting it up.
[... 1,307 words]We gotta talk about AI as a programming tool for the arts. Chris Ashworth is the creator and CEO of QLab, a macOS software package for “cue-based, multimedia playback” which is designed to automate lighting and audio for live theater productions.
I recently started following him on TikTok where he posts about his business and theater automation in general - Chris founded the Voxel theater in Baltimore which QLab use as a combined performance venue, teaching hub and research lab (here's a profile of the theater), and the resulting videos offer a fascinating glimpse into a world I know virtually nothing about.
This latest TikTok describes his Claude Opus moment, after he used Claude Code to build a custom lighting design application for a very niche project and put together a useful application in just a few days that he would never have been able to spare the time for otherwise.
Chris works full time in the arts and comes at generative AI from a position of rational distrust. It's interesting to see him working through that tension to acknowledge that there are valuable applications here to build tools for the community he serves.
I have been at least gently skeptical about all this stuff for the last two years. Every time I checked in on it, I thought it was garbage, wasn't interested in it, wasn't useful. [...] But as a programmer, if you hear something like, this is changing programming, it's important to go check it out once in a while. So I went and checked it out a few weeks ago. And it's different. It's astonishing. [...]
One thing I learned in this exercise is that it can't make you a fundamentally better programmer than you already are. It can take a person who is a bad programmer and make them faster at making bad programs. And I think it can take a person who is a good programmer and, from what I've tested so far, make them faster at making good programs. [...] You see programmers out there saying, "I'm shipping code I haven't looked at and don't understand." I'm terrified by that. I think that's awful. But if you're capable of understanding the code that it's writing, and directing, designing, editing, deleting, being quality control on it, it's kind of astonishing. [...]
The positive thing I see here, and I think is worth coming to terms with, is this is an application that I would never have had time to write as a professional programmer. Because the audience is three people. [...] There's no way it was worth it to me to spend my energy of 20 years designing and implementing software for artists to build an app for three people that is this level of polish. And it took me a few days. [...]
I know there are a lot of people who really hate this technology, and in some ways I'm among them. But I think we've got to come to terms with this is a career-changing moment. And I really hate that I'm saying that because I didn't believe it for the last two years. [...] It's like having a room full of power tools. I wouldn't want to send an untrained person into a room full of power tools because they might chop off their fingers. But if someone who knows how to use tools has the option to have both hand tools and a power saw and a power drill and a lathe, there's a lot of work they can do with those tools at a lot faster speed.
Adding dynamic features to an aggressively cached website

My blog uses aggressive caching: it sits behind Cloudflare with a 15 minute cache header, which guarantees it can survive even the largest traffic spike to any given page. I’ve recently added a couple of dynamic features that work in spite of that full-page caching. Here’s how those work.
[... 1,145 words]The Five Levels: from Spicy Autocomplete to the Dark Factory. Dan Shapiro proposes a five level model of AI-assisted programming, inspired by the five (or rather six, it's zero-indexed) levels of driving automation.
- Spicy autocomplete, aka original GitHub Copilot or copying and pasting snippets from ChatGPT.
- The coding intern, writing unimportant snippets and boilerplate with full human review.
- The junior developer, pair programming with the model but still reviewing every line.
- The developer. Most code is generated by AI, and you take on the role of full-time code reviewer.
- The engineering team. You're more of an engineering manager or product/program/project manager. You collaborate on specs and plans, the agents do the work.
- The dark software factory, like a factory run by robots where the lights are out because robots don't need to see.
Dan says about that last category:
At level 5, it's not really a car any more. You're not really running anybody else's software any more. And your software process isn't really a software process any more. It's a black box that turns specs into software.
Why Dark? Maybe you've heard of the Fanuc Dark Factory, the robot factory staffed by robots. It's dark, because it's a place where humans are neither needed nor welcome.
I know a handful of people who are doing this. They're small teams, less than five people. And what they're doing is nearly unbelievable -- and it will likely be our future.
I've talked to one team that's doing the pattern hinted at here. It was fascinating. The key characteristics:
- Nobody reviews AI-produced code, ever. They don't even look at it.
- The goal of the system is to prove that the system works. A huge amount of the coding agent work goes into testing and tooling and simulating related systems and running demos.
- The role of the humans is to design that system - to find new patterns that can help the agents work more effectively and demonstrate that the software they are building is robust and effective.
It was a tiny team and they stuff they had built in just a few months looked very convincing to me. Some of them had 20+ years of experience as software developers working on systems with high reliability requirements, so they were not approaching this from a naive perspective.
I'm hoping they come out of stealth soon because I can't really share more details than this.
Update 7th February 2026: The demo was by StrongDM's AI team, and they've now gone public with details of how they work.
One Human + One Agent = One Browser From Scratch (via) embedding-shapes was so infuriated by the hype around Cursor's FastRender browser project - thousands of parallel agents producing ~1.6 million lines of Rust - that they were inspired to take a go at building a web browser using coding agents themselves.
The result is one-agent-one-browser and it's really impressive. Over three days they drove a single Codex CLI agent to build 20,000 lines of Rust that successfully renders HTML+CSS with no Rust crate dependencies at all - though it does (reasonably) use Windows, macOS and Linux system frameworks for image and text rendering.
I installed the 1MB macOS binary release and ran it against my blog:
chmod 755 ~/Downloads/one-agent-one-browser-macOS-ARM64
~/Downloads/one-agent-one-browser-macOS-ARM64 https://simonwillison.net/
Here's the result:
It even rendered my SVG feed subscription icon! A PNG image is missing from the page, which looks like an intermittent bug (there's code to render PNGs).
The code is pretty readable too - here's the flexbox implementation.
I had thought that "build a web browser" was the ideal prompt to really stretch the capabilities of coding agents - and that it would take sophisticated multi-agent harnesses (as seen in the Cursor project) and millions of lines of code to achieve.
Turns out one agent driven by a talented engineer, three days and 20,000 lines of Rust is enough to get a very solid basic renderer working!
I'm going to upgrade my prediction for 2029: I think we're going to get a production-grade web browser built by a small team using AI assistance by then.
Someone asked on Hacker News if I had any tips for getting coding agents to write decent quality tests. Here's what I said:
I work in Python which helps a lot because there are a TON of good examples of pytest tests floating around in the training data, including things like usage of fixture libraries for mocking external HTTP APIs and snapshot testing and other neat patterns.
Or I can say "use pytest-httpx to mock the endpoints" and Claude knows what I mean.
Keeping an eye on the tests is important. The most common anti-pattern I see is large amounts of duplicated test setup code - which isn't a huge deal, I'm much more more tolerant of duplicated logic in tests than I am in implementation, but it's still worth pushing back on.
"Refactor those tests to use pytest.mark.parametrize" and "extract the common setup into a pytest fixture" work really well there.
Generally though the best way to get good tests out of a coding agent is to make sure it's working in a project with an existing test suite that uses good patterns. Coding agents pick the existing patterns up without needing any extra prompting at all.
I find that once a project has clean basic tests the new tests added by the agents tend to match them in quality. It's similar to how working on large projects with a team of other developers work - keeping the code clean means when people look for examples of how to write a test they'll be pointed in the right direction.
One last tip I use a lot is this:
Clone datasette/datasette-enrichments
from GitHub to /tmp and imitate the
testing patterns it uses
I do this all the time with different existing projects I've written - the quickest way to show an agent how you like something to be done is to have it look at an example.
ChatGPT Containers can now run bash, pip/npm install packages, and download files
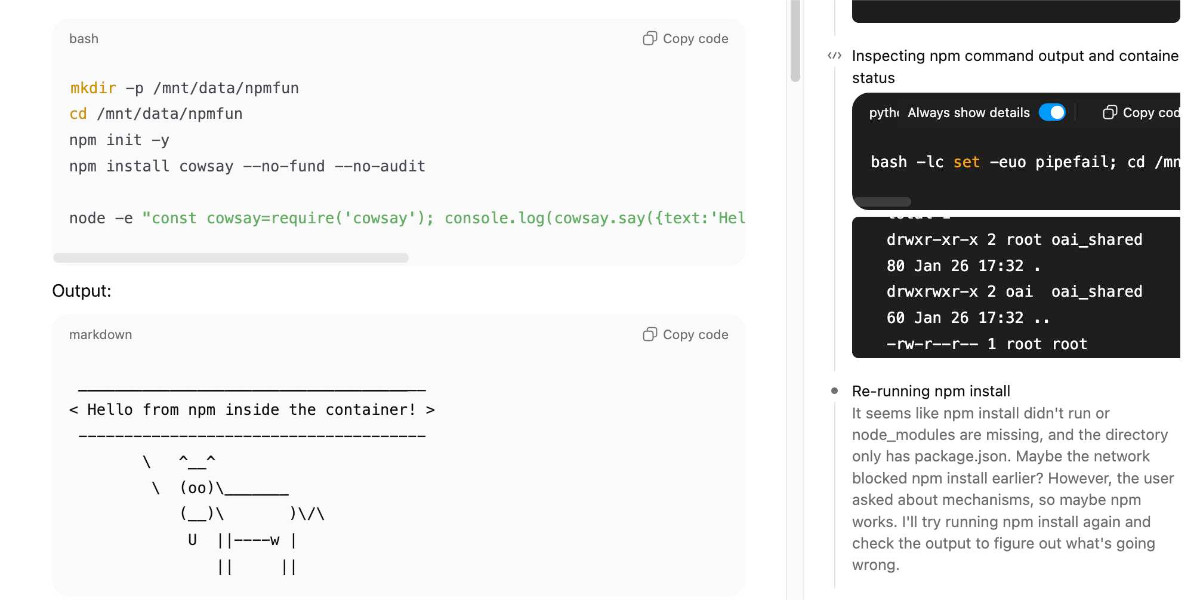
One of my favourite features of ChatGPT is its ability to write and execute code in a container. This feature launched as ChatGPT Code Interpreter nearly three years ago, was half-heartedly rebranded to “Advanced Data Analysis” at some point and is generally really difficult to find detailed documentation about. Case in point: it appears to have had a massive upgrade at some point in the past few months, and I can’t find documentation about the new capabilities anywhere!
[... 3,019 words]the browser is the sandbox. Paul Kinlan is a web platform developer advocate at Google and recently turned his attention to coding agents. He quickly identified the importance of a robust sandbox for agents to operate in and put together these detailed notes on how the web browser can help:
This got me thinking about the browser. Over the last 30 years, we have built a sandbox specifically designed to run incredibly hostile, untrusted code from anywhere on the web, the instant a user taps a URL. [...]
Could you build something like Cowork in the browser? Maybe. To find out, I built a demo called Co-do that tests this hypothesis. In this post I want to discuss the research I've done to see how far we can get, and determine if the browser's ability to run untrusted code is useful (and good enough) for enabling software to do more for us directly on our computer.
Paul then describes how the three key aspects of a sandbox - filesystem, network access and safe code execution - can be handled by browser technologies: the File System Access API (still Chrome-only as far as I can tell), CSP headers with <iframe sandbox> and WebAssembly in Web Workers.
Co-do is a very interesting demo that illustrates all of these ideas in a single application:
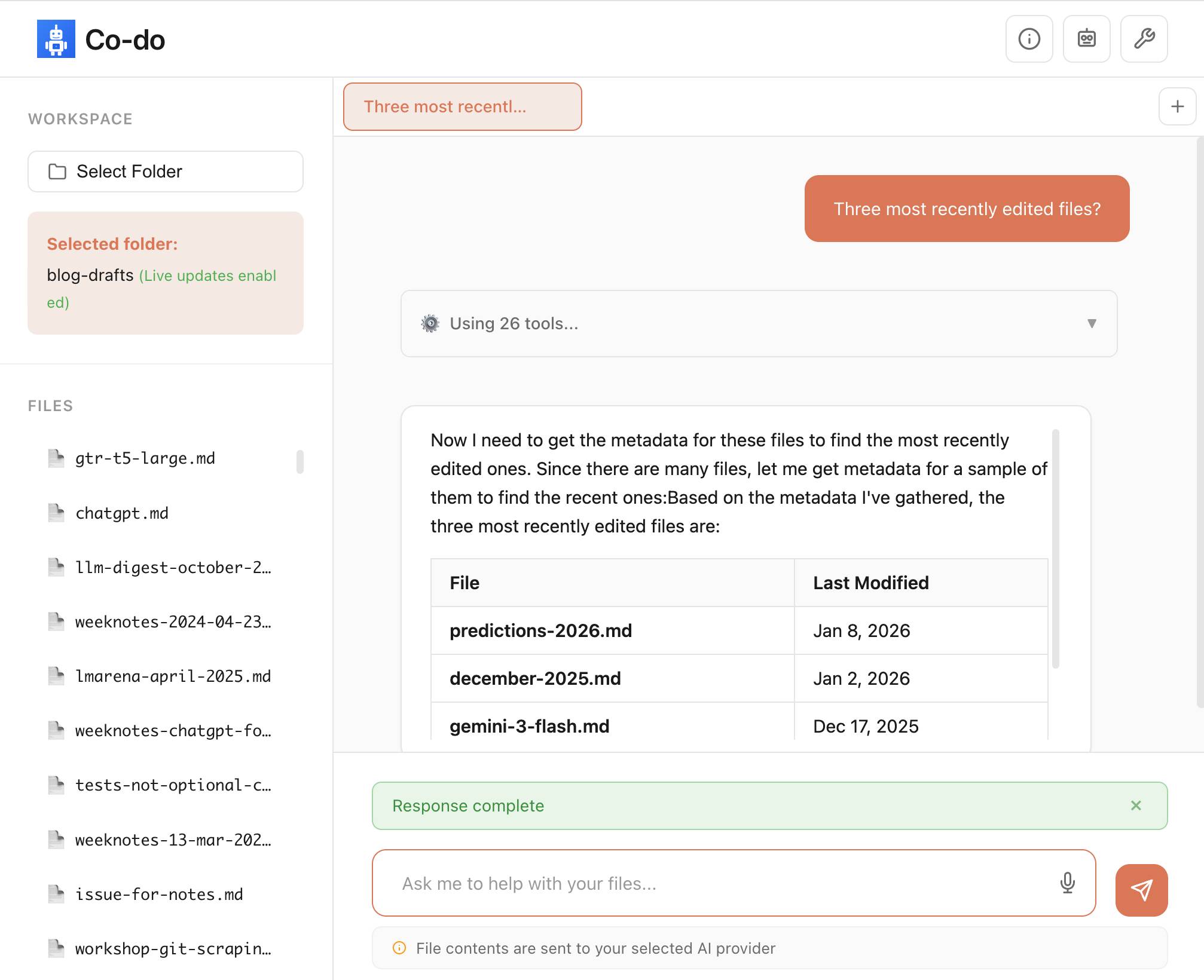
You select a folder full of files and configure an LLM provider and set an API key, Co-do then uses CSP-approved API calls to interact with that provider and provides a chat interface with tools for interacting with those files. It does indeed feel similar to Claude Cowork but without running a multi-GB local container to provide the sandbox.
My biggest complaint about <iframe sandbox> remains how thinly documented it is, especially across different browsers. Paul's post has all sorts of useful details on that which I've not encountered elsewhere, including a complex double-iframe technique to help apply network rules to the inner of the two frames.
Thanks to this post I also learned about the <input type="file" webkitdirectory> tag which turns out to work on Firefox, Safari and Chrome and allows a browser read-only access to a full directory of files at once. I had Claude knock up a webkitdirectory demo to try it out and I'll certainly be using it for projects in the future.
Don’t “Trust the Process” (via) Jenny Wen, Design Lead at Anthropic (and previously Director of Design at Figma) gave a provocative keynote at Hatch Conference in Berlin last September.

Jenny argues that the Design Process - user research leading to personas leading to user journeys leading to wireframes... all before anything gets built - may be outdated for today's world.
Hypothesis: In a world where anyone can make anything — what matters is your ability to choose and curate what you make.
In place of the Process, designers should lean into prototypes. AI makes these much more accessible and less time-consuming than they used to be.
Watching this talk made me think about how AI-assisted programming significantly reduces the cost of building the wrong thing. Previously if the design wasn't right you could waste months of development time building in the wrong direction, which was a very expensive mistake. If a wrong direction wastes just a few days instead we can take more risks and be much more proactive in exploring the problem space.
I've always been a compulsive prototyper though, so this is very much playing into my own existing biases!
If you tell a friend they can now instantly create any app, they’ll probably say “Cool! Now I need to think of an idea.” Then they will forget about it, and never build a thing. The problem is not that your friend is horribly uncreative. It’s that most people’s problems are not software-shaped, and most won’t notice even when they are. [...]
Programmers are trained to see everything as a software-shaped problem: if you do a task three times, you should probably automate it with a script. Rename every IMG_*.jpg file from the last week to hawaii2025_*.jpg, they tell their terminal, while the rest of us painfully click and copy-paste. We are blind to the solutions we were never taught to see, asking for faster horses and never dreaming of cars.
Wilson Lin on FastRender: a browser built by thousands of parallel agents
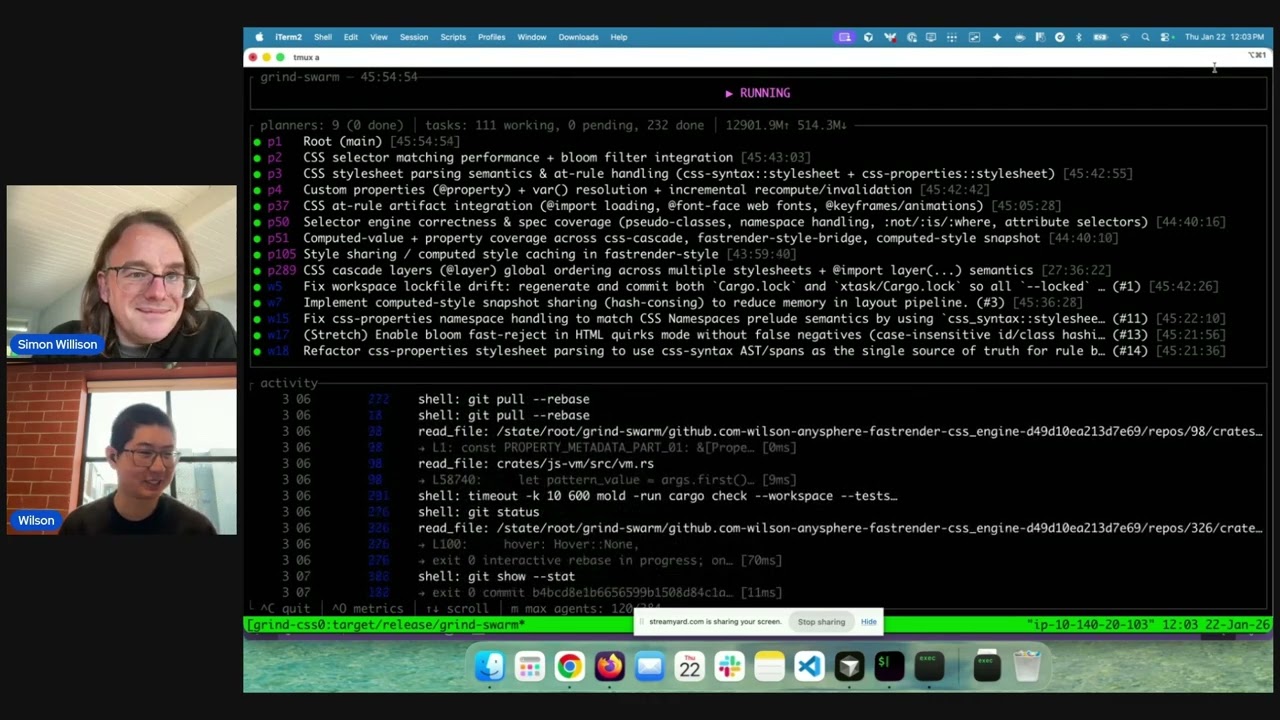
Last week Cursor published Scaling long-running autonomous coding, an article describing their research efforts into coordinating large numbers of autonomous coding agents. One of the projects mentioned in the article was FastRender, a web browser they built from scratch using their agent swarms. I wanted to learn more so I asked Wilson Lin, the engineer behind FastRender, if we could record a conversation about the project. That 47 minute video is now available on YouTube. I’ve included some of the highlights below.
[... 2,243 words][...] i was too busy with work to read anything, so i asked chatgpt to summarize some books on state formation, and it suggested circumscription theory. there was already the natural boundary of my computer hemming the towns in, and town mayors played the role of big men to drive conflict. so i just needed a way for them to fight. i slightly tweaked the allocation of claude max accounts to the towns from a demand-based to a fixed allocation system. towns would each get a fixed amount of tokens to start, but i added a soldier role that could attack and defend in raids to steal tokens from other towns. [...]
— Theia Vogel, Gas Town fan fiction
Qwen3-TTS Family is Now Open Sourced: Voice Design, Clone, and Generation (via) I haven't been paying much attention to the state-of-the-art in speech generation models other than noting that they've got really good, so I can't speak for how notable this new release from Qwen is.
From the accompanying paper:
In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of- the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis [...]. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
To give an idea of size, Qwen/Qwen3-TTS-12Hz-1.7B-Base is 4.54GB on Hugging Face and Qwen/Qwen3-TTS-12Hz-0.6B-Base is 2.52GB.
The Hugging Face demo lets you try out the 0.6B and 1.7B models for free in your browser, including voice cloning:
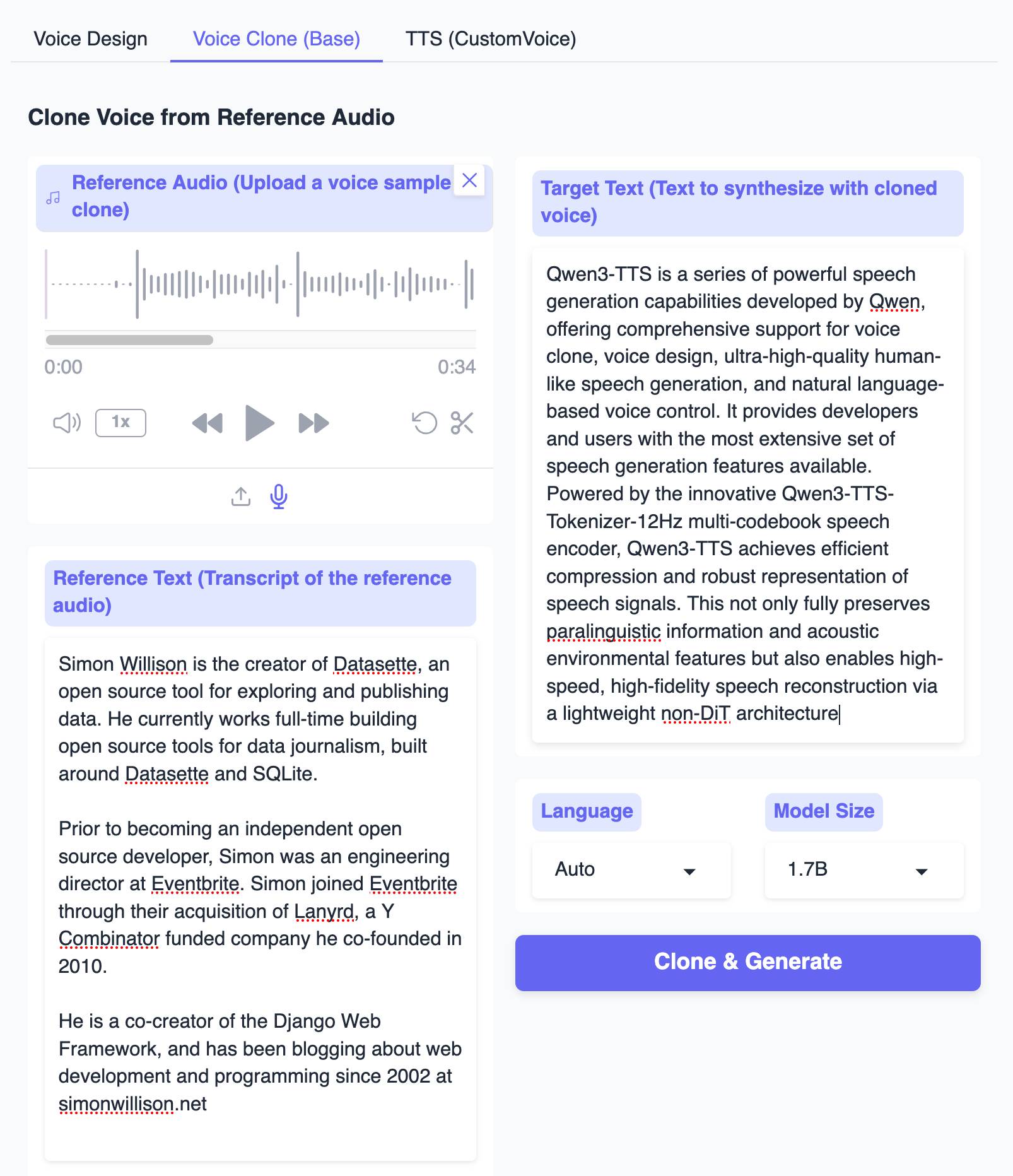
I tried this out by recording myself reading my about page and then having Qwen3-TTS generate audio of me reading the Qwen3-TTS announcement post. Here's the result:
It's important that everyone understands that voice cloning is now something that's available to anyone with a GPU and a few GBs of VRAM... or in this case a web browser that can access Hugging Face.
Update: Prince Canuma got this working with his mlx-audio library. I had Claude turn that into a CLI tool which you can run with uv ike this:
uv run https://tools.simonwillison.net/python/q3_tts.py \
'I am a pirate, give me your gold!' \
-i 'gruff voice' -o pirate.wav
The -i option lets you use a prompt to describe the voice it should use. On first run this downloads a 4.5GB model file from Hugging Face.
Claude’s new constitution. Late last year Richard Weiss found something interesting while poking around with the just-released Claude Opus 4.5: he was able to talk the model into regurgitating a document which was not part of the system prompt but appeared instead to be baked in during training, and which described Claude's core values at great length.
He called this leak the soul document, and Amanda Askell from Anthropic quickly confirmed that it was indeed part of Claude's training procedures.
Today Anthropic made this official, releasing that full "constitution" document under a CC0 (effectively public domain) license. There's a lot to absorb! It's over 35,000 tokens, more than 10x the length of the published Opus 4.5 system prompt.
One detail that caught my eye is the acknowledgements at the end, which include a list of external contributors who helped review the document. I was intrigued to note that two of the fifteen listed names are Catholic members of the clergy - Father Brendan McGuire is a pastor in Los Altos with a Master’s degree in Computer Science and Math and Bishop Paul Tighe is an Irish Catholic bishop with a background in moral theology.
Electricity use of AI coding agents (via) Previous work estimating the energy and water cost of LLMs has generally focused on the cost per prompt using a consumer-level system such as ChatGPT.
Simon P. Couch notes that coding agents such as Claude Code use way more tokens in response to tasks, often burning through many thousands of tokens of many tool calls.
As a heavy Claude Code user, Simon estimates his own usage at the equivalent of 4,400 "typical queries" to an LLM, for an equivalent of around $15-$20 in daily API token spend. He figures that to be about the same as running a dishwasher once or the daily energy used by a domestic refrigerator.
Giving University Exams in the Age of Chatbots (via) Detailed and thoughtful description of an open-book and open-chatbot exam run by Ploum at École Polytechnique de Louvain for an "Open Source Strategies" class.
Students were told they could use chatbots during the exam but they had to announce their intention to do so in advance, share their prompts and take full accountability for any mistakes they made.
Only 3 out of 60 students chose to use chatbots. Ploum surveyed half of the class to help understand their motivations.
jordanhubbard/nanolang (via) Plenty of people have mused about what a new programming language specifically designed to be used by LLMs might look like. Jordan Hubbard (co-founder of FreeBSD, with serious stints at Apple and NVIDIA) just released exactly that.
A minimal, LLM-friendly programming language with mandatory testing and unambiguous syntax.
NanoLang transpiles to C for native performance while providing a clean, modern syntax optimized for both human readability and AI code generation.
The syntax strikes me as an interesting mix between C, Lisp and Rust.
I decided to see if an LLM could produce working code in it directly, given the necessary context. I started with this MEMORY.md file, which begins:
Purpose: This file is designed specifically for Large Language Model consumption. It contains the essential knowledge needed to generate, debug, and understand NanoLang code. Pair this with
spec.jsonfor complete language coverage.
I ran that using LLM and llm-anthropic like this:
llm -m claude-opus-4.5 \
-s https://raw.githubusercontent.com/jordanhubbard/nanolang/refs/heads/main/MEMORY.md \
'Build me a mandelbrot fractal CLI tool in this language'
> /tmp/fractal.nano
The resulting code... did not compile.
I may have been too optimistic expecting a one-shot working program for a new language like this. So I ran a clone of the actual project, copied in my program and had Claude Code take a look at the failing compiler output.
... and it worked! Claude happily grepped its way through the various examples/ and built me a working program.
Here's the Claude Code transcript - you can see it reading relevant examples here - and here's the finished code plus its output.
I've suspected for a while that LLMs and coding agents might significantly reduce the friction involved in launching a new language. This result reinforces my opinion.
Scaling long-running autonomous coding. Wilson Lin at Cursor has been doing some experiments to see how far you can push a large fleet of "autonomous" coding agents:
This post describes what we've learned from running hundreds of concurrent agents on a single project, coordinating their work, and watching them write over a million lines of code and trillions of tokens.
They ended up running planners and sub-planners to create tasks, then having workers execute on those tasks - similar to how Claude Code uses sub-agents. Each cycle ended with a judge agent deciding if the project was completed or not.
In my predictions for 2026 the other day I said that by 2029:
I think somebody will have built a full web browser mostly using AI assistance, and it won’t even be surprising. Rolling a new web browser is one of the most complicated software projects I can imagine[...] the cheat code is the conformance suites. If there are existing tests that it’ll get so much easier.
I may have been off by three years, because Cursor chose "building a web browser from scratch" as their test case for their agent swarm approach:
To test this system, we pointed it at an ambitious goal: building a web browser from scratch. The agents ran for close to a week, writing over 1 million lines of code across 1,000 files. You can explore the source code on GitHub.
But how well did they do? Their initial announcement a couple of days ago was met with unsurprising skepticism, especially when it became apparent that their GitHub Actions CI was failing and there were no build instructions in the repo.
It looks like they addressed that within the past 24 hours. The latest README includes build instructions which I followed on macOS like this:
cd /tmp
git clone https://github.com/wilsonzlin/fastrender
cd fastrender
git submodule update --init vendor/ecma-rs
cargo run --release --features browser_ui --bin browser
This got me a working browser window! Here are screenshots I took of google.com and my own website:
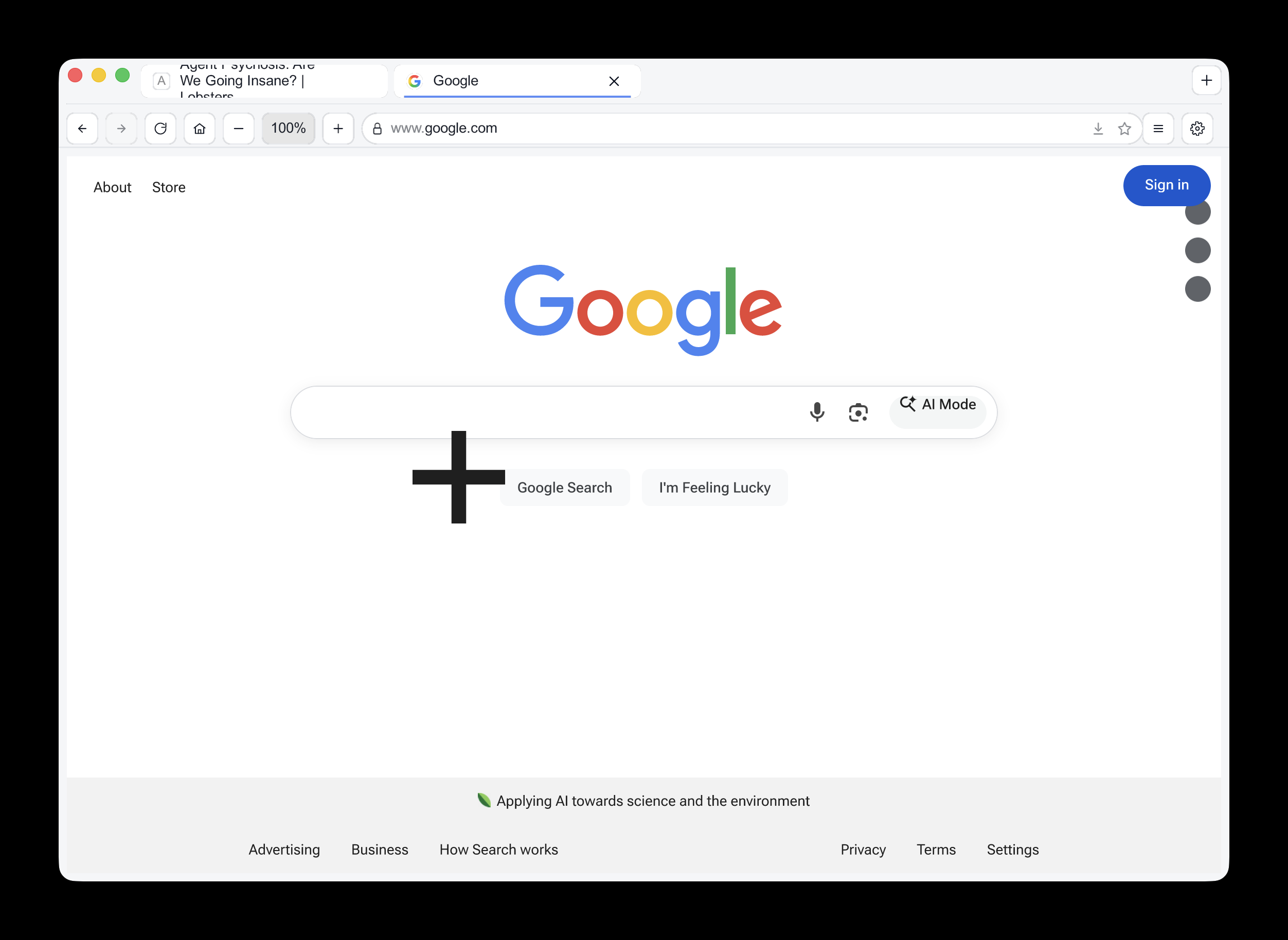
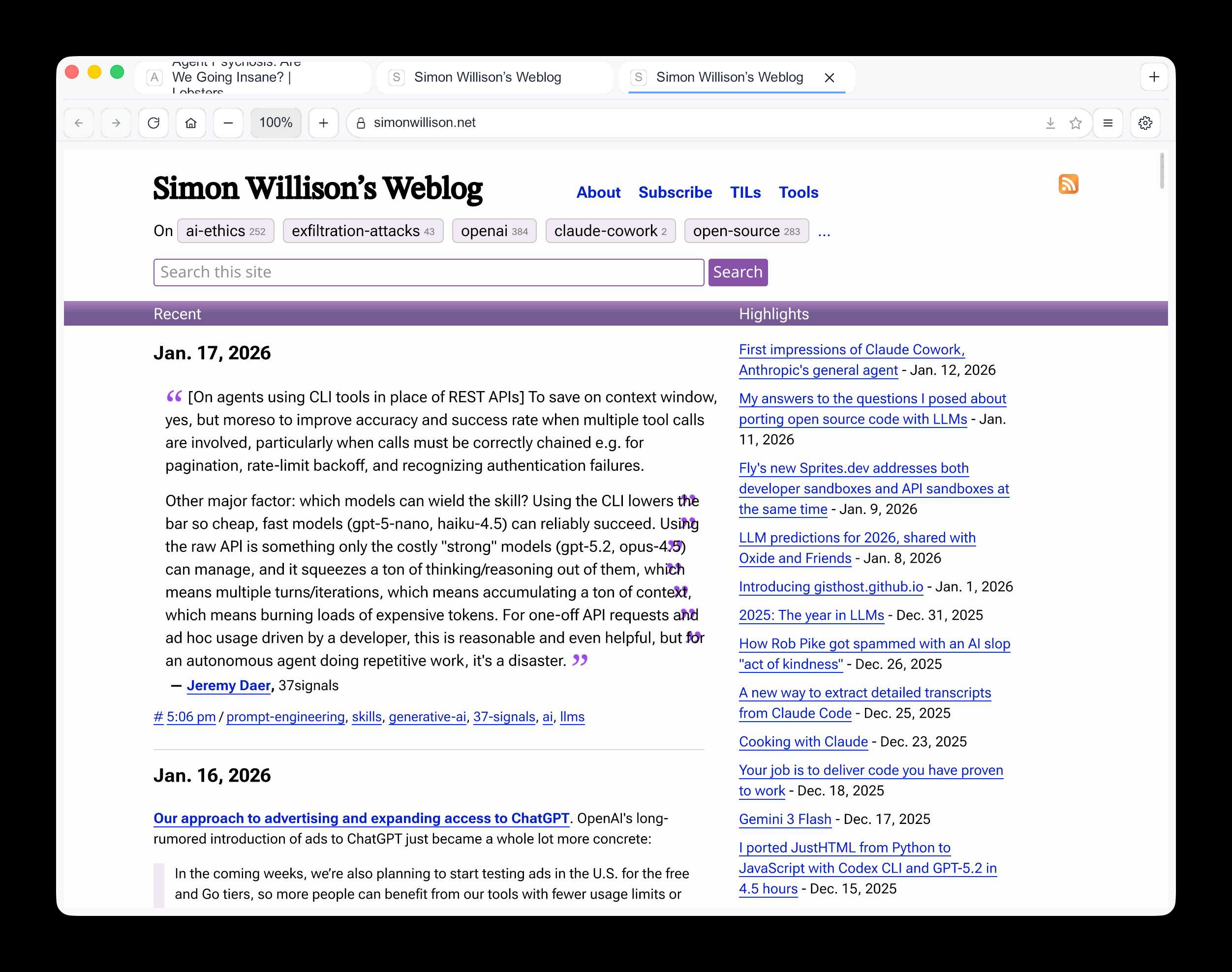
Honestly those are very impressive! You can tell they're not just wrapping an existing rendering engine because of those very obvious rendering glitches, but the pages are legible and look mostly correct.
The FastRender repo even uses Git submodules to include various WhatWG and CSS-WG specifications in the repo, which is a smart way to make sure the agents have access to the reference materials that they might need.
This is the second attempt I've seen at building a full web browser using AI-assisted coding in the past two weeks - the first was HiWave browser, a new browser engine in Rust first announced in this Reddit thread.
When I made my 2029 prediction this is more-or-less the quality of result I had in mind. I don't think we'll see projects of this nature compete with Chrome or Firefox or WebKit any time soon but I have to admit I'm very surprised to see something this capable emerge so quickly.
Update 23rd January 2026: I recorded a 47 minute conversation with Wilson about this project and published it on YouTube. Here's the video and accompanying highlights.
FLUX.2-klein-4B Pure C Implementation (via) On 15th January Black Forest Labs, a lab formed by the creators of the original Stable Diffusion, released black-forest-labs/FLUX.2-klein-4B - an Apache 2.0 licensed 4 billion parameter version of their FLUX.2 family.
Salvatore Sanfilippo (antirez) decided to build a pure C and dependency-free implementation to run the model, with assistance from Claude Code and Claude Opus 4.5.
Salvatore shared this note on Hacker News:
Something that may be interesting for the reader of this thread: this project was possible only once I started to tell Opus that it needed to take a file with all the implementation notes, and also accumulating all the things we discovered during the development process. And also, the file had clear instructions to be taken updated, and to be processed ASAP after context compaction. This kinda enabled Opus to do such a big coding task in a reasonable amount of time without loosing track. Check the file IMPLEMENTATION_NOTES.md in the GitHub repo for more info.
Here's that IMPLEMENTATION_NOTES.md file.