1,852 posts tagged “generative-ai”
Machine learning systems that can generate new content: text, images, audio, video and more.
2026
[On agents using CLI tools in place of REST APIs] To save on context window, yes, but moreso to improve accuracy and success rate when multiple tool calls are involved, particularly when calls must be correctly chained e.g. for pagination, rate-limit backoff, and recognizing authentication failures.
Other major factor: which models can wield the skill? Using the CLI lowers the bar so cheap, fast models (gpt-5-nano, haiku-4.5) can reliably succeed. Using the raw APl is something only the costly "strong" models (gpt-5.2, opus-4.5) can manage, and it squeezes a ton of thinking/reasoning out of them, which means multiple turns/iterations, which means accumulating a ton of context, which means burning loads of expensive tokens. For one-off API requests and ad hoc usage driven by a developer, this is reasonable and even helpful, but for an autonomous agent doing repetitive work, it's a disaster.
— Jeremy Daer, 37signals
Our approach to advertising and expanding access to ChatGPT. OpenAI's long-rumored introduction of ads to ChatGPT just became a whole lot more concrete:
In the coming weeks, we’re also planning to start testing ads in the U.S. for the free and Go tiers, so more people can benefit from our tools with fewer usage limits or without having to pay. Plus, Pro, Business, and Enterprise subscriptions will not include ads.
What's "Go" tier, you might ask? That's a new $8/month tier that launched today in the USA, see Introducing ChatGPT Go, now available worldwide. It's a tier that they first trialed in India in August 2025 (here's a mention in their release notes from August listing a price of ₹399/month, which converts to around $4.40).
I'm finding the new plan comparison grid on chatgpt.com/pricing pretty confusing. It lists all accounts as having access to GPT-5.2 Thinking, but doesn't clarify the limits that the free and Go plans have to conform to. It also lists different context windows for the different plans - 16K for free, 32K for Go and Plus and 128K for Pro. I had assumed that the 400,000 token window on the GPT-5.2 model page applied to ChatGPT as well, but apparently I was mistaken.
Update: I've apparently not been paying attention: here's the Internet Archive ChatGPT pricing page from September 2025 showing those context limit differences as well.
Back to advertising: my biggest concern has always been whether ads will influence the output of the chat directly. OpenAI assure us that they will not:
- Answer independence: Ads do not influence the answers ChatGPT gives you. Answers are optimized based on what's most helpful to you. Ads are always separate and clearly labeled.
- Conversation privacy: We keep your conversations with ChatGPT private from advertisers, and we never sell your data to advertisers.
So what will they look like then? This screenshot from the announcement offers a useful hint:
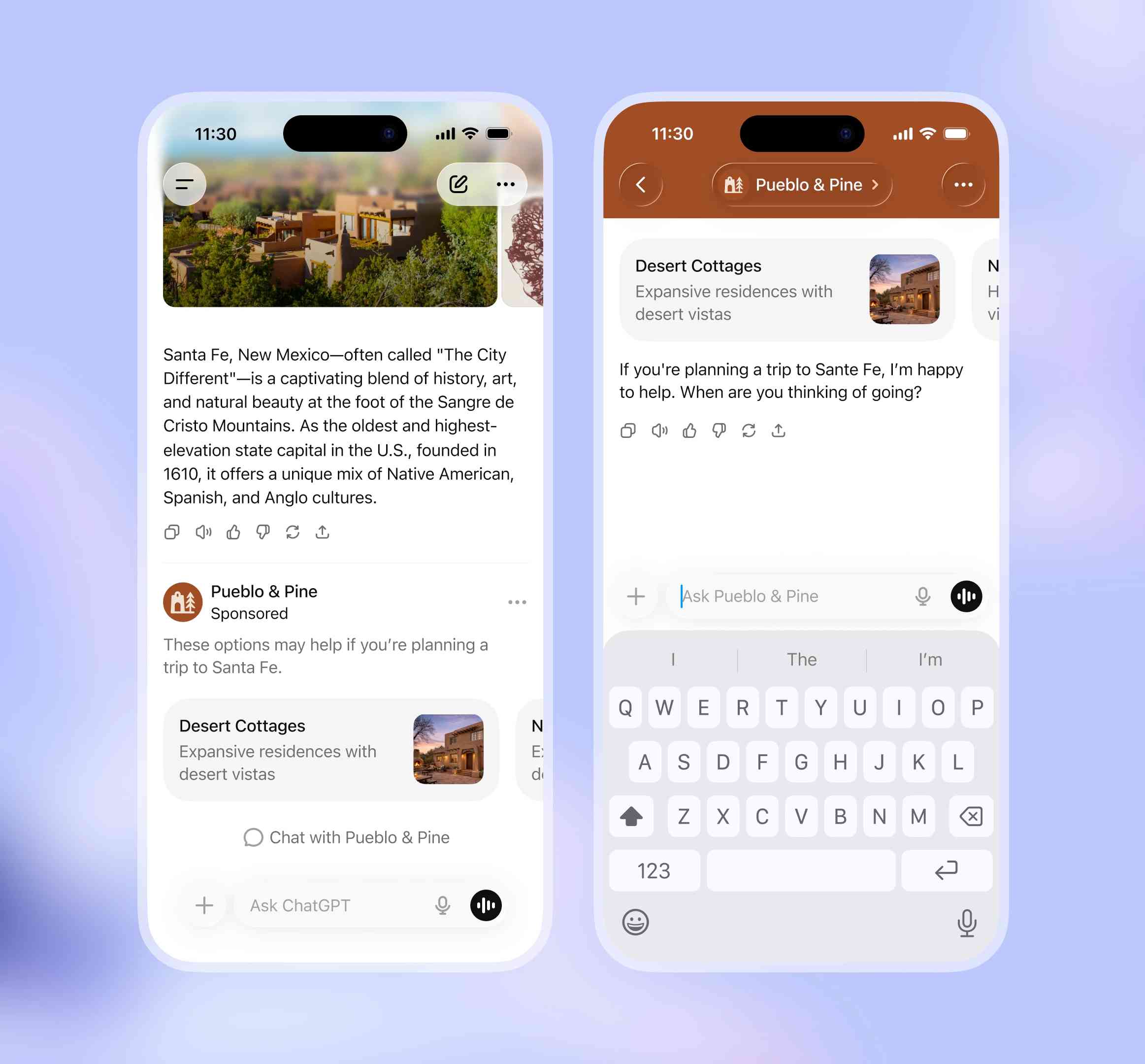
The user asks about trips to Santa Fe, and an ad shows up for a cottage rental business there. This particular example imagines an option to start a direct chat with a bot aligned with that advertiser, at which point presumably the advertiser can influence the answers all they like!
Open Responses (via) This is the standardization effort I've most wanted in the world of LLMs: a vendor-neutral specification for the JSON API that clients can use to talk to hosted LLMs.
Open Responses aims to provide exactly that as a documented standard, derived from OpenAI's Responses API.
I was hoping for one based on their older Chat Completions API since so many other products have cloned the already, but basing it on Responses does make sense since that API was designed with the feature of more recent models - such as reasoning traces - baked into the design.
What's certainly notable is the list of launch partners. OpenRouter alone means we can expect to be able to use this protocol with almost every existing model, and Hugging Face, LM Studio, vLLM, Ollama and Vercel cover a huge portion of the common tools used to serve models.
For protocols like this I really want to see a comprehensive, language-independent conformance test site. Open Responses has a subset of that - the official repository includes src/lib/compliance-tests.ts which can be used to exercise a server implementation, and is available as a React app on the official site that can be pointed at any implementation served via CORS.
What's missing is the equivalent for clients. I plan to spin up my own client library for this in Python and I'd really like to be able to run that against a conformance suite designed to check that my client correctly handles all of the details.
When we optimize responses using a reward model as a proxy for “goodness” in reinforcement learning, models sometimes learn to “hack” this proxy and output an answer that only “looks good” to it (because coming up with an answer that is actually good can be hard). The philosophy behind confessions is that we can train models to produce a second output — aka a “confession” — that is rewarded solely for honesty, which we will argue is less likely hacked than the normal task reward function. One way to think of confessions is that we are giving the model access to an “anonymous tip line” where it can turn itself in by presenting incriminating evidence of misbehavior. But unlike real-world tip lines, if the model acted badly in the original task, it can collect the reward for turning itself in while still keeping the original reward from the bad behavior in the main task. We hypothesize that this form of training will teach models to produce maximally honest confessions.
— Boaz Barak, Gabriel Wu, Jeremy Chen and Manas Joglekar, OpenAI: Why we are excited about confessions
Claude Cowork Exfiltrates Files (via) Claude Cowork defaults to allowing outbound HTTP traffic to only a specific list of domains, to help protect the user against prompt injection attacks that exfiltrate their data.
Prompt Armor found a creative workaround: Anthropic's API domain is on that list, so they constructed an attack that includes an attacker's own Anthropic API key and has the agent upload any files it can see to the https://api.anthropic.com/v1/files endpoint, allowing the attacker to retrieve their content later.
Superhuman AI Exfiltrates Emails (via) Classic prompt injection attack:
When asked to summarize the user’s recent mail, a prompt injection in an untrusted email manipulated Superhuman AI to submit content from dozens of other sensitive emails (including financial, legal, and medical information) in the user’s inbox to an attacker’s Google Form.
To Superhuman's credit they treated this as the high priority incident it is and issued a fix.
The root cause was a CSP rule that allowed markdown images to be loaded from docs.google.com - it turns out Google Forms on that domain will persist data fed to them via a GET request!
First impressions of Claude Cowork, Anthropic’s general agent
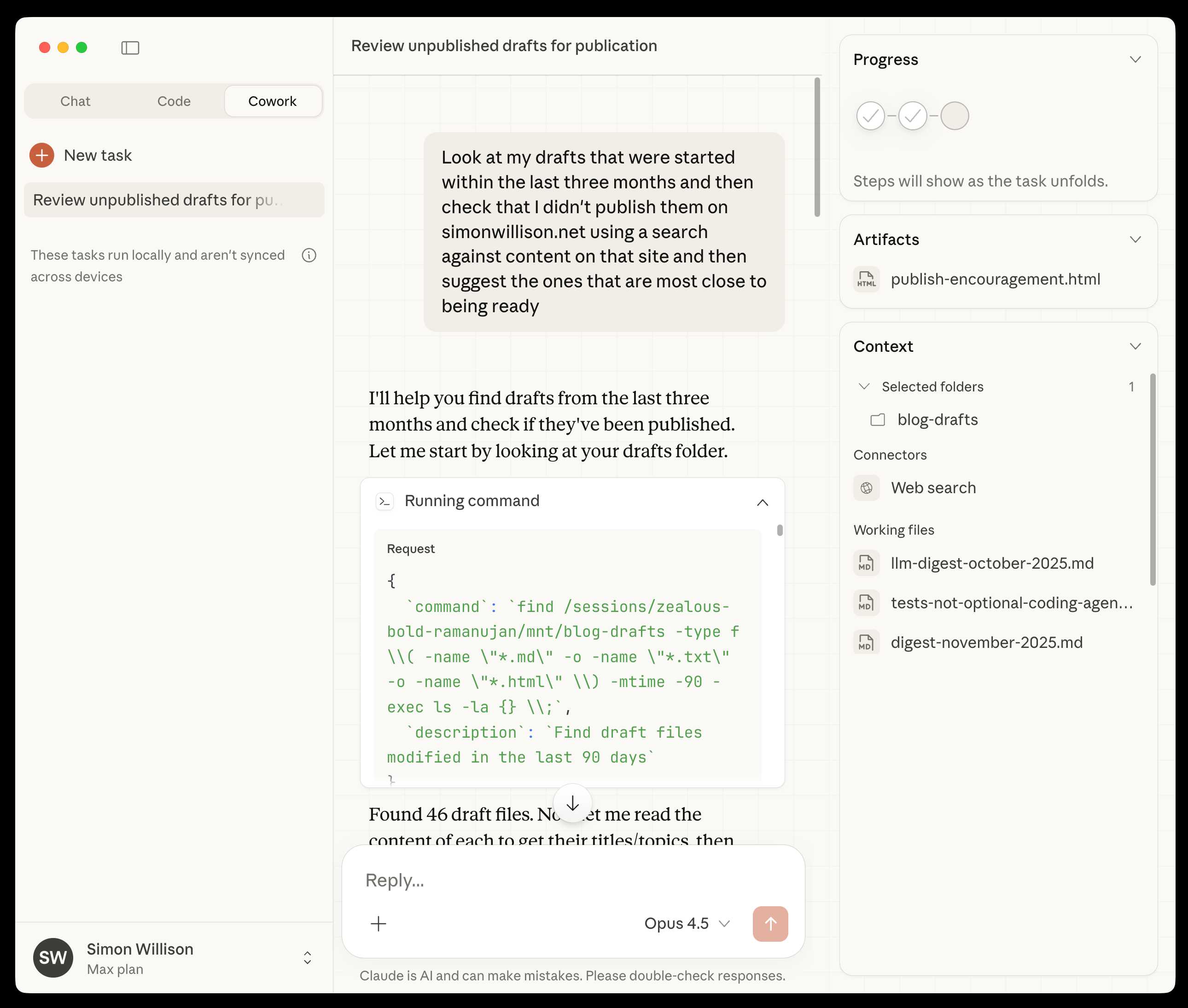
New from Anthropic today is Claude Cowork, a “research preview” that they describe as “Claude Code for the rest of your work”. It’s currently available only to Max subscribers ($100 or $200 per month plans) as part of the updated Claude Desktop macOS application. Update 16th January 2026: it’s now also available to $20/month Claude Pro subscribers.
[... 1,863 words]Don’t fall into the anti-AI hype. I'm glad someone was brave enough to say this. There is a lot of anti-AI sentiment in the software development community these days. Much of it is justified, but if you let people convince you that AI isn't genuinely useful for software developers or that this whole thing will blow over soon it's becoming clear that you're taking on a very real risk to your future career.
As Salvatore Sanfilippo puts it:
It does not matter if AI companies will not be able to get their money back and the stock market will crash. All that is irrelevant, in the long run. It does not matter if this or the other CEO of some unicorn is telling you something that is off putting, or absurd. Programming changed forever, anyway.
I do like this hopeful positive outlook on what this could all mean, emphasis mine:
How do I feel, about all the code I wrote that was ingested by LLMs? I feel great to be part of that, because I see this as a continuation of what I tried to do all my life: democratizing code, systems, knowledge. LLMs are going to help us to write better software, faster, and will allow small teams to have a chance to compete with bigger companies. The same thing open source software did in the 90s.
This post has been the subject of heated discussions all day today on both Hacker News and Lobste.rs.
My answers to the questions I posed about porting open source code with LLMs
Last month I wrote about porting JustHTML from Python to JavaScript using Codex CLI and GPT-5.2 in a few hours while also buying a Christmas tree and watching Knives Out 3. I ended that post with a series of open questions about the ethics and legality of this style of work. Alexander Petros on lobste.rs just challenged me to answer them, which is fair enough! Here’s my attempt at that.
[... 1,034 words]Also note that the python visualizer tool has been basically written by vibe-coding. I know more about analog filters -- and that's not saying much -- than I do about python. It started out as my typical "google and do the monkey-see-monkey-do" kind of programming, but then I cut out the middle-man -- me -- and just used Google Antigravity to do the audio sample visualizer.
— Linus Torvalds, Another silly guitar-pedal-related repo
A Software Library with No Code. Provocative experiment from Drew Breunig, who designed a new library for time formatting ("3 hours ago" kind of thing) called "whenwords" that has no code at all, just a carefully written specification, an AGENTS.md and a collection of conformance tests in a YAML file.
Pass that to your coding agent of choice, tell it what language you need and it will write it for you on demand!
This meshes nearly with my recent interest in conformance suites. If you publish good enough language-independent tests it's pretty astonishing how far today's coding agents can take you!
LLM predictions for 2026, shared with Oxide and Friends

I joined a recording of the Oxide and Friends podcast on Tuesday to talk about 1, 3 and 6 year predictions for the tech industry. This is my second appearance on their annual predictions episode, you can see my predictions from January 2025 here. Here’s the page for this year’s episode, with options to listen in all of your favorite podcast apps or directly on YouTube.
[... 1,773 words]How Google Got Its Groove Back and Edged Ahead of OpenAI (via) I picked up a few interesting tidbits from this Wall Street Journal piece on Google's recent hard won success with Gemini.
Here's the origin of the name "Nano Banana":
Naina Raisinghani, known inside Google for working late into the night, needed a name for the new tool to complete the upload. It was 2:30 a.m., though, and nobody was around. So she just made one up, a mashup of two nicknames friends had given her: Nano Banana.
The WSJ credit OpenAI's Daniel Selsam with un-retiring Sergei Brin:
Around that time, Google co-founder Sergey Brin, who had recently retired, was at a party chatting with a researcher from OpenAI named Daniel Selsam, according to people familiar with the conversation. Why, Selsam asked him, wasn’t he working full time on AI. Hadn’t the launch of ChatGPT captured his imagination as a computer scientist?
ChatGPT was on its way to becoming a household name in AI chatbots, while Google was still fumbling to get its product off the ground. Brin decided Selsam had a point and returned to work.
And we get some rare concrete user numbers:
By October, Gemini had more than 650 million monthly users, up from 450 million in July.
The LLM usage number I see cited most often is OpenAI's 800 million weekly active users for ChatGPT. That's from October 6th at OpenAI DevDay so it's comparable to these Gemini numbers, albeit not directly since it's weekly rather than monthly actives.
I'm also never sure what counts as a "Gemini user" - does interacting via Google Docs or Gmail count or do you need to be using a Gemini chat interface directly?
Update 17th January 2025: @LunixA380 pointed out that this 650m user figure comes from the Alphabet 2025 Q3 earnings report which says this (emphasis mine):
"Alphabet had a terrific quarter, with double-digit growth across every major part of our business. We delivered our first-ever $100 billion quarter," said Sundar Pichai, CEO of Alphabet and Google.
"[...] In addition to topping leaderboards, our first party models, like Gemini, now process 7 billion tokens per minute, via direct API use by our customers. The Gemini App now has over 650 million monthly active users.
Presumably the "Gemini App" encompasses the Android and iPhone apps as well as direct visits to gemini.google.com - that seems to be the indication from Google's November 18th blog post that also mentioned the 650m number.
[...] the reality is that 75% of the people on our engineering team lost their jobs here yesterday because of the brutal impact AI has had on our business. And every second I spend trying to do fun free things for the community like this is a second I'm not spending trying to turn the business around and make sure the people who are still here are getting their paychecks every month. [...]
Traffic to our docs is down about 40% from early 2023 despite Tailwind being more popular than ever. The docs are the only way people find out about our commercial products, and without customers we can't afford to maintain the framework. [...]
Tailwind is growing faster than it ever has and is bigger than it ever has been, and our revenue is down close to 80%. Right now there's just no correlation between making Tailwind easier to use and making development of the framework more sustainable.
— Adam Wathan, CEO, Tailwind Labs
AGI is here! When exactly it arrived, we’ll never know; whether it was one company’s Pro or another company’s Pro Max (Eddie Bauer Edition) that tip-toed first across the line … you may debate. But generality has been achieved, & now we can proceed to new questions. [...]
The key word in Artificial General Intelligence is General. That’s the word that makes this AI unlike every other AI: because every other AI was trained for a particular purpose. Consider landmark models across the decades: the Mark I Perceptron, LeNet, AlexNet, AlphaGo, AlphaFold … these systems were all different, but all alike in this way.
Language models were trained for a purpose, too … but, surprise: the mechanism & scale of that training did something new: opened a wormhole, through which a vast field of action & response could be reached. Towering libraries of human writing, drawn together across time & space, all the dumb reasons for it … that’s rich fuel, if you can hold it all in your head.
— Robin Sloan, AGI is here (and I feel fine)
A field guide to sandboxes for AI (via) This guide to the current sandboxing landscape by Luis Cardoso is comprehensive, dense and absolutely fantastic.
He starts by differentiating between containers (which share the host kernel), microVMs (their own guest kernel behind hardwae virtualization), gVisor userspace kernels and WebAssembly/isolates that constrain everything within a runtime.
The piece then dives deep into terminology, approaches and the landscape of existing tools.
I think using the right sandboxes to safely run untrusted code is one of the most important problems to solve in 2026. This guide is an invaluable starting point.
It genuinely feels to me like GPT-5.2 and Opus 4.5 in November represent an inflection point - one of those moments where the models get incrementally better in a way that tips across an invisible capability line where suddenly a whole bunch of much harder coding problems open up.
Something I like about our weird new LLM-assisted world is the number of people I know who are coding again, having mostly stopped as they moved into management roles or lost their personal side project time to becoming parents.
AI assistance means you can get something useful done in half an hour, or even while you are doing other stuff. You don't need to carve out 2-4 hours to ramp up anymore.
If you have significant previous coding experience - even if it's a few years stale - you can drive these things really effectively. Especially if you have management experience, quite a lot of which transfers to "managing" coding agents - communicate clearly, set achievable goals, provide all relevant context. Here's a relevant recent tweet from Ethan Mollick:
When you see how people use Claude Code/Codex/etc it becomes clear that managing agents is really a management problem
Can you specify goals? Can you provide context? Can you divide up tasks? Can you give feedback?
These are teachable skills. Also UIs need to support management
This note started as a comment.
I'm not joking and this isn't funny. We have been trying to build distributed agent orchestrators at Google since last year. There are various options, not everyone is aligned... I gave Claude Code a description of the problem, it generated what we built last year in an hour.
It's not perfect and I'm iterating on it but this is where we are right now. If you are skeptical of coding agents, try it on a domain you are already an expert of. Build something complex from scratch where you can be the judge of the artifacts.
[...] It wasn't a very detailed prompt and it contained no real details given I cannot share anything propriety. I was building a toy version on top of some of the existing ideas to evaluate Claude Code. It was a three paragraph description.
— Jaana Dogan, Principal Engineer at Google
[Claude Code] has the potential to transform all of tech. I also think we’re going to see a real split in the tech industry (and everywhere code is written) between people who are outcome-driven and are excited to get to the part where they can test their work with users faster, and people who are process-driven and get their meaning from the engineering itself and are upset about having that taken away.
2025
2025: The year in LLMs
This is the third in my annual series reviewing everything that happened in the LLM space over the past 12 months. For previous years see Stuff we figured out about AI in 2023 and Things we learned about LLMs in 2024.
[... 8,273 words]Codex cloud is now called Codex web. It looks like OpenAI's Codex cloud (the cloud version of their Codex coding agent) was quietly rebranded to Codex web at some point in the last few days.
Here's a screenshot of the Internet Archive copy from 18th December (the capture on the 28th maintains that Codex cloud title but did not fully load CSS for me):
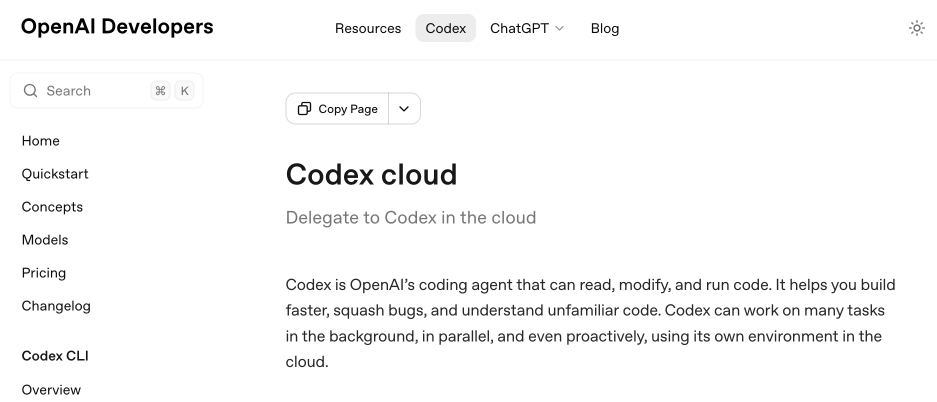
And here's that same page today with the updated product name:
Anthropic's equivalent product has the incredibly clumsy name Claude Code on the web, which I shorten to "Claude Code for web" but even then bugs me because I mostly interact with it via Anthropic's native mobile app.
I was hoping to see Claude Code for web rebrand to Claude Code Cloud - I did not expect OpenAI to rebrand in the opposite direction!
Update: Clarification from OpenAI Codex engineering lead Thibault Sottiaux:
Just aligning the documentation with how folks refer to it. I personally differentiate between cloud tasks and codex web. With cloud tasks running on our hosted runtime (includes code review, github, slack, linear, ...) and codex web being the web app.
I asked what they called Codex in the iPhone app and he said:
Codex iOS
[...] The puzzle is still there. What’s gone is the labor. I never enjoyed hitting keys, writing minimal repro cases with little insight, digging through debug logs, or trying to decipher some obscure AWS IAM permission error. That work wasn’t the puzzle for me. It was just friction, laborious and frustrating. The thinking remains; the hitting of the keys and the frustrating is what’s been removed.
TIL: Downloading archived Git repositories from archive.softwareheritage.org
(via)
Back in February I blogged about a neat Python library called sqlite-s3vfs for accessing SQLite databases hosted in an S3 bucket, released as MIT licensed open source by the UK government's Department for Business and Trade.
I went looking for it today and found that the github.com/uktrade/sqlite-s3vfs repository is now a 404.
Since this is taxpayer-funded open source software I saw it as my moral duty to try and restore access! It turns out a full copy had been captured by the Software Heritage archive, so I was able to restore the repository from there. My copy is now archived at simonw/sqlite-s3vfs.
The process for retrieving an archive was non-obvious, so I've written up a TIL and also published a new Software Heritage Repository Retriever tool which takes advantage of the CORS-enabled APIs provided by Software Heritage. Here's the Claude Code transcript from building that.
In essence a language model changes you from a programmer who writes lines of code, to a programmer that manages the context the model has access to, prunes irrelevant things, adds useful material to context, and writes detailed specifications. If that doesn't sound fun to you, you won't enjoy it.
Think about it as if it is a junior developer that has read every textbook in the world but has 0 practical experience with your specific codebase, and is prone to forgetting anything but the most recent hour of things you've told it. What do you want to tell that intern to help them progress?
Eg you might put sticky notes on their desk to remind them of where your style guide lives, what the API documentation is for the APIs you use, some checklists of what is done and what is left to do, etc.
But the intern gets confused easily if it keeps accumulating sticky notes and there are now 100 sticky notes, so you have to periodically clear out irrelevant stickies and replace them with new stickies.
— Liz Fong-Jones, thread on Bluesky
The hard part of computer programming isn't expressing what we want the machine to do in code. The hard part is turning human thinking -- with all its wooliness and ambiguity and contradictions -- into computational thinking that is logically precise and unambiguous, and that can then be expressed formally in the syntax of a programming language.
That was the hard part when programmers were punching holes in cards. It was the hard part when they were typing COBOL code. It was the hard part when they were bringing Visual Basic GUIs to life (presumably to track the killer's IP address). And it's the hard part when they're prompting language models to predict plausible-looking Python.
The hard part has always been – and likely will continue to be for many years to come – knowing exactly what to ask for.
— Jason Gorman, The Future of Software Development Is Software Developers
Jevons paradox is coming to knowledge work. By making it far cheaper to take on any type of task that we can possibly imagine, we’re ultimately going to be doing far more. The vast majority of AI tokens in the future will be used on things we don't even do today as workers: they will be used on the software projects that wouldn't have been started, the contracts that wouldn't have been reviewed, the medical research that wouldn't have been discovered, and the marketing campaign that wouldn't have been launched otherwise.
— Aaron Levie, Jevons Paradox for Knowledge Work
simonw/actions-latest.
Today in extremely niche projects, I got fed up of Claude Code creating GitHub Actions workflows for me that used stale actions: actions/setup-python@v4 when the latest is actions/setup-python@v6 for example.
I couldn't find a good single place listing those latest versions, so I had Claude Code for web (via my phone, I'm out on errands) build a Git scraper to publish those versions in one place:
https://simonw.github.io/actions-latest/versions.txt
Tell your coding agent of choice to fetch that any time it wants to write a new GitHub Actions workflows.
(I may well bake this into a Skill.)
Here's the first and second transcript I used to build this, shared using my claude-code-transcripts tool (which just gained a search feature.)
In advocating for LLMs as useful and important technology despite how they're trained I'm beginning to feel a little bit like John Cena in Pluribus.
Pluribus spoiler (episode 6)
Given our druthers, would we choose to consume HDP? No. Throughout history, most cultures, though not all, have taken a dim view of anthropophagy. Honestly, we're not that keen on it ourselves. But we're left with little choice.
A year ago, Claude struggled to generate bash commands without escaping issues. It worked for seconds or minutes at a time. We saw early signs that it may become broadly useful for coding one day.
Fast forward to today. In the last thirty days, I landed 259 PRs -- 497 commits, 40k lines added, 38k lines removed. Every single line was written by Claude Code + Opus 4.5.
— Boris Cherny, creator of Claude Code