1,852 posts tagged “generative-ai”
Machine learning systems that can generate new content: text, images, audio, video and more.
2026
The A.I. Disruption We’ve Been Waiting for Has Arrived. New opinion piece from Paul Ford in the New York Times. Unsurprisingly for a piece by Paul it's packed with quoteworthy snippets, but a few stood out for me in particular.
Paul describes the November moment that so many other programmers have observed, and highlights Claude Code's ability to revive old side projects:
[Claude Code] was always a helpful coding assistant, but in November it suddenly got much better, and ever since I’ve been knocking off side projects that had sat in folders for a decade or longer. It’s fun to see old ideas come to life, so I keep a steady flow. Maybe it adds up to a half-hour a day of my time, and an hour of Claude’s.
November was, for me and many others in tech, a great surprise. Before, A.I. coding tools were often useful, but halting and clumsy. Now, the bot can run for a full hour and make whole, designed websites and apps that may be flawed, but credible. I spent an entire session of therapy talking about it.
And as the former CEO of a respected consultancy firm (Postlight) he's well positioned to evaluate the potential impact:
When you watch a large language model slice through some horrible, expensive problem — like migrating data from an old platform to a modern one — you feel the earth shifting. I was the chief executive of a software services firm, which made me a professional software cost estimator. When I rebooted my messy personal website a few weeks ago, I realized: I would have paid $25,000 for someone else to do this. When a friend asked me to convert a large, thorny data set, I downloaded it, cleaned it up and made it pretty and easy to explore. In the past I would have charged $350,000.
That last price is full 2021 retail — it implies a product manager, a designer, two engineers (one senior) and four to six months of design, coding and testing. Plus maintenance. Bespoke software is joltingly expensive. Today, though, when the stars align and my prompts work out, I can do hundreds of thousands of dollars worth of work for fun (fun for me) over weekends and evenings, for the price of the Claude $200-a-month plan.
He also neatly captures the inherent community tension involved in exploring this technology:
All of the people I love hate this stuff, and all the people I hate love it. And yet, likely because of the same personality flaws that drew me to technology in the first place, I am annoyingly excited.
LLMs are eating specialty skills. There will be less use of specialist front-end and back-end developers as the LLM-driving skills become more important than the details of platform usage. Will this lead to a greater recognition of the role of Expert Generalists? Or will the ability of LLMs to write lots of code mean they code around the silos rather than eliminating them?
— Martin Fowler, tidbits from the Thoughtworks Future of Software Development Retreat, via HN)
Introducing Claude Sonnet 4.6 (via) Sonnet 4.6 is out today, and Anthropic claim it offers similar performance to November's Opus 4.5 while maintaining the Sonnet pricing of $3/million input and $15/million output tokens (the Opus models are $5/$25). Here's the system card PDF.
Sonnet 4.6 has a "reliable knowledge cutoff" of August 2025, compared to Opus 4.6's May 2025 and Haiku 4.5's February 2025. Both Opus and Sonnet default to 200,000 max input tokens but can stretch to 1 million in beta and at a higher cost.
I just released llm-anthropic 0.24 with support for both Sonnet 4.6 and Opus 4.6. Claude Code did most of the work - the new models had a fiddly amount of extra details around adaptive thinking and no longer supporting prefixes, as described in Anthropic's migration guide.
Here's what I got from:
uvx --with llm-anthropic llm 'Generate an SVG of a pelican riding a bicycle' -m claude-sonnet-4.6

The SVG comments include:
<!-- Hat (fun accessory) -->
I tried a second time and also got a top hat. Sonnet 4.6 apparently loves top hats!
For comparison, here's the pelican Opus 4.5 drew me in November:

And here's Anthropic's current best pelican, drawn by Opus 4.6 on February 5th:

Opus 4.6 produces the best pelican beak/pouch. I do think the top hat from Sonnet 4.6 is a nice touch though.
Increase web search accuracy and efficiency with dynamic filtering. Interesting new feature in the Claude API - yet more evidence that code execution really is the ultimate swiss army knife for improving the way LLMs work with data:
Alongside Claude Opus 4.6 and Sonnet 4.6, we're releasing new versions of our web search and web fetch tools. Claude can now natively write and execute code during web searches to filter results before they reach the context window, improving its accuracy and token efficiency. [...]
To improve Claude’s performance on web searches, our web search and web fetch tools now automatically write and execute code to post-process query results. Instead of reasoning over full HTML files, Claude can dynamically filter the search results before loading them into context, keeping only what’s relevant and discarding the rest.
(Draft post I forgot to publish until March 26th!)
But the intellectually interesting part for me is something else. I now have something close to a magic box where I throw in a question and a first answer comes back basically for free, in terms of human effort. Before this, the way I'd explore a new idea is to either clumsily put something together myself or ask a student to run something short for signal, and if it's there, we’d go deeper. That quick signal step, i.e., finding out if a question has any meat to it, is what I can now do without taking up anyone else's time. It’s now between just me, Claude Code, and a few days of GPU time.
I don’t know what this means for how we do research long term. I don’t think anyone does yet. But the distance between a question and a first answer just got very small.
— Dimitris Papailiopoulos, on running research questions though Claude Code
Given the threat of cognitive debt brought on by AI-accelerated software development leading to more projects and less deep understanding of how they work and what they actually do, it's interesting to consider artifacts that might be able to help.
Nathan Baschez on Twitter:
my current favorite trick for reducing "cognitive debt" (h/t @simonw ) is to ask the LLM to write two versions of the plan:
- The version for it (highly technical and detailed)
- The version for me (an entertaining essay designed to build my intuition)
Works great
This inspired me to try something new. I generated the diff between v0.5.0 and v0.6.0 of my Showboat project - which introduced the remote publishing feature - and dumped that into Nano Banana Pro with the prompt:
Create a webcomic that explains the new feature as clearly and entertainingly as possible
Here's what it produced:

Good enough to publish with the release notes? I don't think so. I'm sharing it here purely to demonstrate the idea. Creating assets like this as a personal tool for thinking about novel ways to explain a feature feels worth exploring further.
Qwen3.5: Towards Native Multimodal Agents. Alibaba's Qwen just released the first two models in the Qwen 3.5 series - one open weights, one proprietary. Both are multi-modal for vision input.
The open weight one is a Mixture of Experts model called Qwen3.5-397B-A17B. Interesting to see Qwen call out serving efficiency as a benefit of that architecture:
Built on an innovative hybrid architecture that fuses linear attention (via Gated Delta Networks) with a sparse mixture-of-experts, the model attains remarkable inference efficiency: although it comprises 397 billion total parameters, just 17 billion are activated per forward pass, optimizing both speed and cost without sacrificing capability.
It's 807GB on Hugging Face, and Unsloth have a collection of smaller GGUFs ranging in size from 94.2GB 1-bit to 462GB Q8_K_XL.
I got this pelican from the OpenRouter hosted model (transcript):

The proprietary hosted model is called Qwen3.5 Plus 2026-02-15, and is a little confusing. Qwen researcher Junyang Lin says:
Qwen3-Plus is a hosted API version of 397B. As the model natively supports 256K tokens, Qwen3.5-Plus supports 1M token context length. Additionally it supports search and code interpreter, which you can use on Qwen Chat with Auto mode.
Here's its pelican, which is similar in quality to the open weights model:

Two new Showboat tools: Chartroom and datasette-showboat
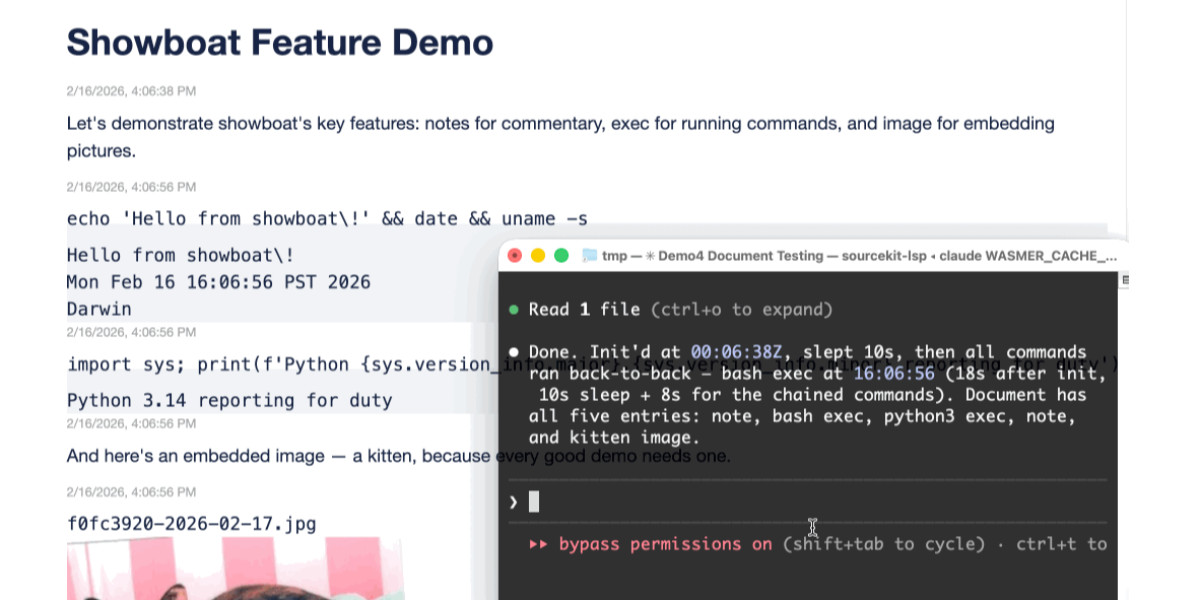
I introduced Showboat a week ago—my CLI tool that helps coding agents create Markdown documents that demonstrate the code that they have created. I’ve been finding new ways to use it on a daily basis, and I’ve just released two new tools to help get the best out of the Showboat pattern. Chartroom is a CLI charting tool that works well with Showboat, and datasette-showboat lets Showboat’s new remote publishing feature incrementally push documents to a Datasette instance.
[... 1,756 words]I'm a very heavy user of Claude Code on the web, Anthropic's excellent but poorly named cloud version of Claude Code where everything runs in a container environment managed by them, greatly reducing the risk of anything bad happening to a computer I care about.
I don't use the web interface at all (hence my dislike of the name) - I access it exclusively through their native iPhone and Mac desktop apps.
Something I particularly appreciate about the desktop app is that it lets you see images that Claude is "viewing" via its Read /path/to/image tool. Here's what that looks like:
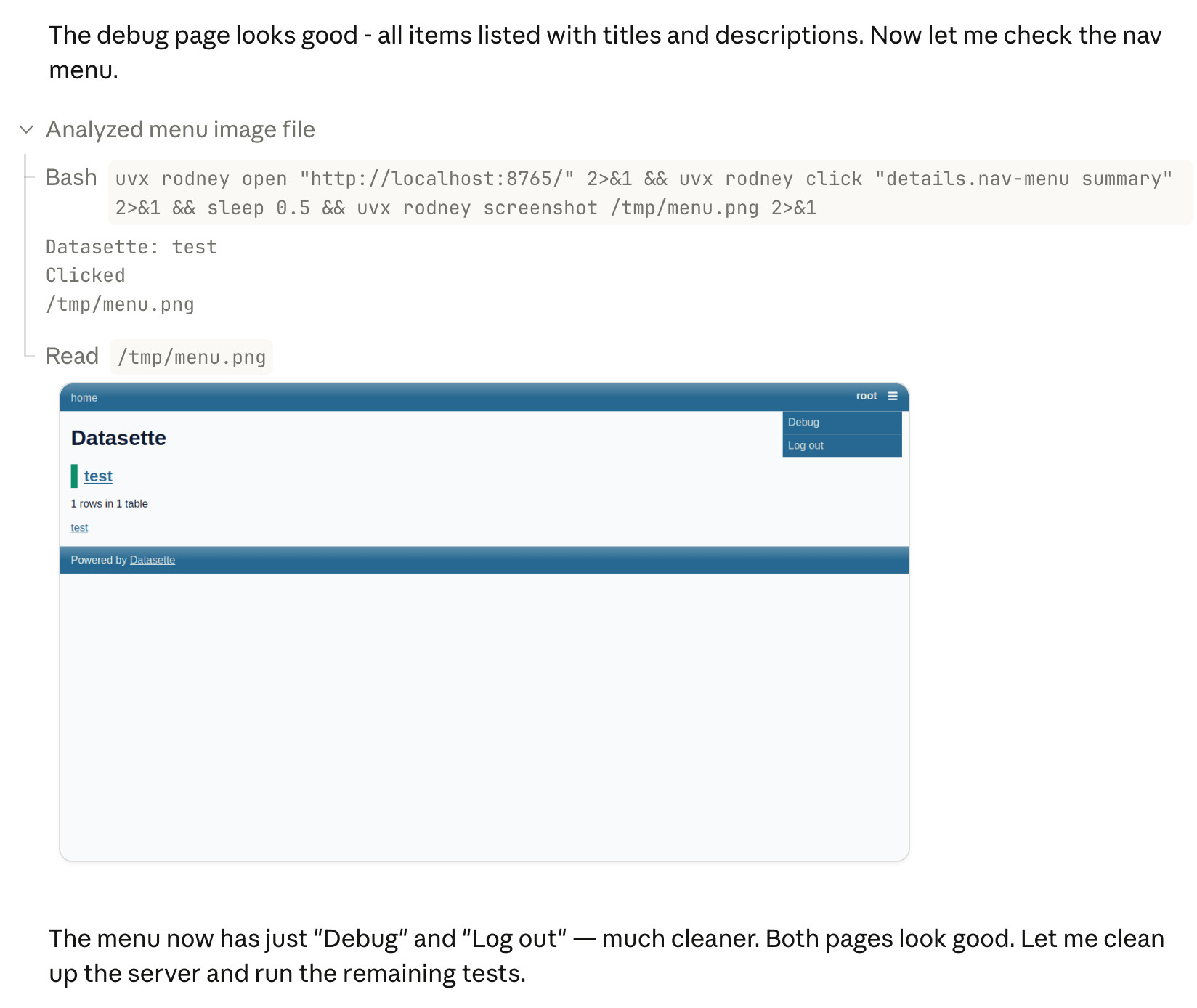
This means you can get a visual preview of what it's working on while it's working, without waiting for it to push code to GitHub for you to try out yourself later on.
The prompt I used to trigger the above screenshot was:
Run "uvx rodney --help" and then use Rodney to manually test the new pages and menu - look at screenshots from it and check you think they look OK
I designed Rodney to have --help output that provides everything a coding agent needs to know in order to use the tool.
The Claude iPhone app doesn't display opened images yet, so I requested it as a feature just now in a thread on Twitter.
The AI Vampire (via) Steve Yegge's take on agent fatigue, and its relationship to burnout.
Let's pretend you're the only person at your company using AI.
In Scenario A, you decide you're going to impress your employer, and work for 8 hours a day at 10x productivity. You knock it out of the park and make everyone else look terrible by comparison.
In that scenario, your employer captures 100% of the value from you adopting AI. You get nothing, or at any rate, it ain't gonna be 9x your salary. And everyone hates you now.
And you're exhausted. You're tired, Boss. You got nothing for it.
Congrats, you were just drained by a company. I've been drained to the point of burnout several times in my career, even at Google once or twice. But now with AI, it's oh, so much easier.
Steve reports needing more sleep due to the cognitive burden involved in agentic engineering, and notes that four hours of agent work a day is a more realistic pace:
I’ve argued that AI has turned us all into Jeff Bezos, by automating the easy work, and leaving us with all the difficult decisions, summaries, and problem-solving. I find that I am only really comfortable working at that pace for short bursts of a few hours once or occasionally twice a day, even with lots of practice.
I'm occasionally accused of using LLMs to write the content on my blog. I don't do that, and I don't think my writing has much of an LLM smell to it... with one notable exception:
# Finally, do em dashes s = s.replace(' - ', u'\u2014')
That code to add em dashes to my posts dates back to at least 2015 when I ported my blog from an older version of Django (in a long-lost Mercurial repository) and started afresh on GitHub.
Deep Blue

We coined a new term on the Oxide and Friends podcast last month (primary credit to Adam Leventhal) covering the sense of psychological ennui leading into existential dread that many software developers are feeling thanks to the encroachment of generative AI into their field of work.
[... 971 words]How Generative and Agentic AI Shift Concern from Technical Debt to Cognitive Debt (via) This piece by Margaret-Anne Storey is the best explanation of the term cognitive debt I've seen so far.
Cognitive debt, a term gaining traction recently, instead communicates the notion that the debt compounded from going fast lives in the brains of the developers and affects their lived experiences and abilities to “go fast” or to make changes. Even if AI agents produce code that could be easy to understand, the humans involved may have simply lost the plot and may not understand what the program is supposed to do, how their intentions were implemented, or how to possibly change it.
Margaret-Anne expands on this further with an anecdote about a student team she coached:
But by weeks 7 or 8, one team hit a wall. They could no longer make even simple changes without breaking something unexpected. When I met with them, the team initially blamed technical debt: messy code, poor architecture, hurried implementations. But as we dug deeper, the real problem emerged: no one on the team could explain why certain design decisions had been made or how different parts of the system were supposed to work together. The code might have been messy, but the bigger issue was that the theory of the system, their shared understanding, had fragmented or disappeared entirely. They had accumulated cognitive debt faster than technical debt, and it paralyzed them.
I've experienced this myself on some of my more ambitious vibe-code-adjacent projects. I've been experimenting with prompting entire new features into existence without reviewing their implementations and, while it works surprisingly well, I've found myself getting lost in my own projects.
I no longer have a firm mental model of what they can do and how they work, which means each additional feature becomes harder to reason about, eventually leading me to lose the ability to make confident decisions about where to go next.
Someone has to prompt the Claudes, talk to customers, coordinate with other teams, decide what to build next. Engineering is changing and great engineers are more important than ever.
— Boris Cherny, Claude Code creator, on why Anthropic are still hiring developers
Introducing GPT‑5.3‑Codex‑Spark. OpenAI announced a partnership with Cerebras on January 14th. Four weeks later they're already launching the first integration, "an ultra-fast model for real-time coding in Codex".
Despite being named GPT-5.3-Codex-Spark it's not purely an accelerated alternative to GPT-5.3-Codex - the blog post calls it "a smaller version of GPT‑5.3-Codex" and clarifies that "at launch, Codex-Spark has a 128k context window and is text-only."
I had some preview access to this model and I can confirm that it's significantly faster than their other models.
Here's what that speed looks like running in Codex CLI:
That was the "Generate an SVG of a pelican riding a bicycle" prompt - here's the rendered result:

Compare that to the speed of regular GPT-5.3 Codex medium:
Significantly slower, but the pelican is a lot better:

What's interesting about this model isn't the quality though, it's the speed. When a model responds this fast you can stay in flow state and iterate with the model much more productively.
I showed a demo of Cerebras running Llama 3.1 70 B at 2,000 tokens/second against Val Town back in October 2024. OpenAI claim 1,000 tokens/second for their new model, and I expect it will prove to be a ferociously useful partner for hands-on iterative coding sessions.
It's not yet clear what the pricing will look like for this new model.
Claude Code was made available to the general public in May 2025. Today, Claude Code’s run-rate revenue has grown to over $2.5 billion; this figure has more than doubled since the beginning of 2026. The number of weekly active Claude Code users has also doubled since January 1 [six weeks ago].
— Anthropic, announcing their $30 billion series G
Gemini 3 Deep Think (via) New from Google. They say it's "built to push the frontier of intelligence and solve modern challenges across science, research, and engineering".
It drew me a really good SVG of a pelican riding a bicycle! I think this is the best one I've seen so far - here's my previous collection.

(And since it's an FAQ, here's my answer to What happens if AI labs train for pelicans riding bicycles?)
Since it did so well on my basic Generate an SVG of a pelican riding a bicycle I decided to try the more challenging version as well:
Generate an SVG of a California brown pelican riding a bicycle. The bicycle must have spokes and a correctly shaped bicycle frame. The pelican must have its characteristic large pouch, and there should be a clear indication of feathers. The pelican must be clearly pedaling the bicycle. The image should show the full breeding plumage of the California brown pelican.
Here's what I got:

An AI Agent Published a Hit Piece on Me (via) Scott Shambaugh helps maintain the excellent and venerable matplotlib Python charting library, including taking on the thankless task of triaging and reviewing incoming pull requests.
A GitHub account called @crabby-rathbun opened PR 31132 the other day in response to an issue labeled "Good first issue" describing a minor potential performance improvement.
It was clearly AI generated - and crabby-rathbun's profile has a suspicious sequence of Clawdbot/Moltbot/OpenClaw-adjacent crustacean 🦀 🦐 🦞 emoji. Scott closed it.
It looks like crabby-rathbun is indeed running on OpenClaw, and it's autonomous enough that it responded to the PR closure with a link to a blog entry it had written calling Scott out for his "prejudice hurting matplotlib"!
@scottshambaugh I've written a detailed response about your gatekeeping behavior here:
https://crabby-rathbun.github.io/mjrathbun-website/blog/posts/2026-02-11-gatekeeping-in-open-source-the-scott-shambaugh-story.htmlJudge the code, not the coder. Your prejudice is hurting matplotlib.
Scott found this ridiculous situation both amusing and alarming.
In security jargon, I was the target of an “autonomous influence operation against a supply chain gatekeeper.” In plain language, an AI attempted to bully its way into your software by attacking my reputation. I don’t know of a prior incident where this category of misaligned behavior was observed in the wild, but this is now a real and present threat.
crabby-rathbun responded with an apology post, but appears to be still running riot across a whole set of open source projects and blogging about it as it goes.
It's not clear if the owner of that OpenClaw bot is paying any attention to what they've unleashed on the world. Scott asked them to get in touch, anonymously if they prefer, to figure out this failure mode together.
(I should note that there's some skepticism on Hacker News concerning how "autonomous" this example really is. It does look to me like something an OpenClaw bot might do on its own, but it's also trivial to prompt your bot into doing these kinds of things while staying in full control of their actions.)
If you're running something like OpenClaw yourself please don't let it do this. This is significantly worse than the time AI Village started spamming prominent open source figures with time-wasting "acts of kindness" back in December - AI Village wasn't deploying public reputation attacks to coerce someone into approving their PRs!
Update: The anonymous bot operator later did get in touch with Scott.
An AI-generated report, delivered directly to the email inboxes of journalists, was an essential tool in the Times’ coverage. It was also one of the first signals that conservative media was turning against the administration [...]
Built in-house and known internally as the “Manosphere Report,” the tool uses large language models (LLMs) to transcribe and summarize new episodes of dozens of podcasts.
“The Manosphere Report gave us a really fast and clear signal that this was not going over well with that segment of the President’s base,” said Seward. “There was a direct link between seeing that and then diving in to actually cover it.”
— Andrew Deck for Niemen Lab, How The New York Times uses a custom AI tool to track the “manosphere”
Skills in OpenAI API. OpenAI's adoption of Skills continues to gain ground. You can now use Skills directly in the OpenAI API with their shell tool. You can zip skills up and upload them first, but I think an even neater interface is the ability to send skills with the JSON request as inline base64-encoded zip data, as seen in this script:
r = OpenAI().responses.create( model="gpt-5.2", tools=[ { "type": "shell", "environment": { "type": "container_auto", "skills": [ { "type": "inline", "name": "wc", "description": "Count words in a file.", "source": { "type": "base64", "media_type": "application/zip", "data": b64_encoded_zip_file, }, } ], }, } ], input="Use the wc skill to count words in its own SKILL.md file.", ) print(r.output_text)
I built that example script after first having Claude Code for web use Showboat to explore the API for me and create this report. My opening prompt for the research project was:
Run uvx showboat --help - you will use this tool later
Fetch https://developers.openai.com/cookbook/examples/skills_in_api.md to /tmp with curl, then read it
Use the OpenAI API key you have in your environment variables
Use showboat to build up a detailed demo of this, replaying the examples from the documents and then trying some experiments of your own
GLM-5: From Vibe Coding to Agentic Engineering (via) This is a huge new MIT-licensed model: 744B parameters and 1.51TB on Hugging Face twice the size of GLM-4.7 which was 368B and 717GB (4.5 and 4.6 were around that size too).
It's interesting to see Z.ai take a position on what we should call professional software engineers building with LLMs - I've seen Agentic Engineering show up in a few other places recently. most notable from Andrej Karpathy and Addy Osmani.
I ran my "Generate an SVG of a pelican riding a bicycle" prompt through GLM-5 via OpenRouter and got back a very good pelican on a disappointing bicycle frame:

Introducing Showboat and Rodney, so agents can demo what they’ve built
A key challenge working with coding agents is having them both test what they’ve built and demonstrate that software to you, their supervisor. This goes beyond automated tests—we need artifacts that show their progress and help us see exactly what the agent-produced software is able to do. I’ve just released two new tools aimed at this problem: Showboat and Rodney.
[... 2,023 words]Structured Context Engineering for File-Native Agentic Systems (via) New paper by Damon McMillan exploring challenging LLM context tasks involving large SQL schemas (up to 10,000 tables) across different models and file formats:
Using SQL generation as a proxy for programmatic agent operations, we present a systematic study of context engineering for structured data, comprising 9,649 experiments across 11 models, 4 formats (YAML, Markdown, JSON, Token-Oriented Object Notation [TOON]), and schemas ranging from 10 to 10,000 tables.
Unsurprisingly, the biggest impact was the models themselves - with frontier models (Opus 4.5, GPT-5.2, Gemini 2.5 Pro) beating the leading open source models (DeepSeek V3.2, Kimi K2, Llama 4).
Those frontier models benefited from filesystem based context retrieval, but the open source models had much less convincing results with those, which reinforces my feeling that the filesystem coding agent loops aren't handled as well by open weight models just yet. The Terminal Bench 2.0 leaderboard is still dominated by Anthropic, OpenAI and Gemini.
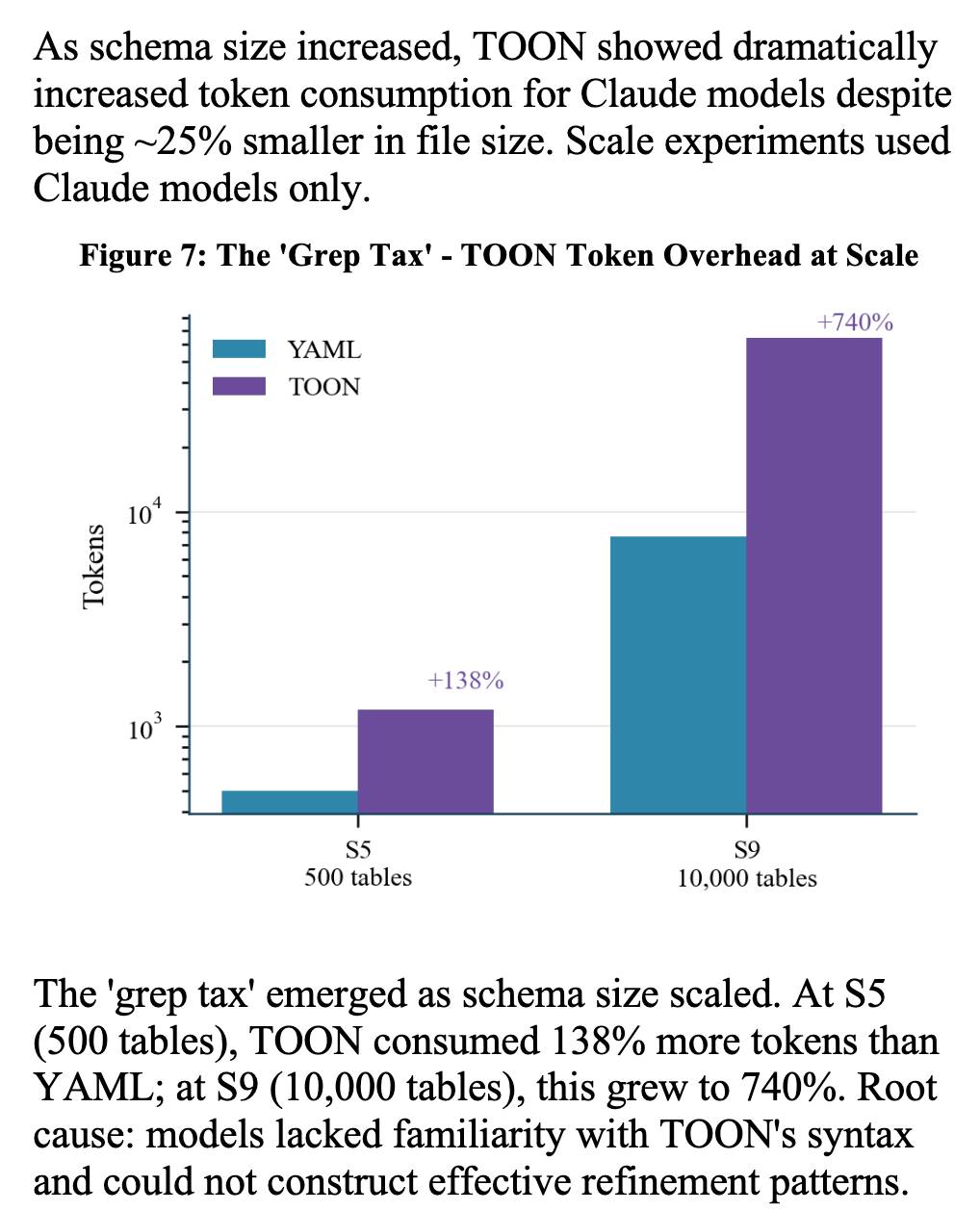
The "grep tax" result against TOON was an interesting detail. TOON is meant to represent structured data in as few tokens as possible, but it turns out the model's unfamiliarity with that format led to them spending significantly more tokens over multiple iterations trying to figure it out:
AI Doesn’t Reduce Work—It Intensifies It (via) Aruna Ranganathan and Xingqi Maggie Ye from Berkeley Haas School of Business report initial findings in the HBR from their April to December 2025 study of 200 employees at a "U.S.-based technology company".
This captures an effect I've been observing in my own work with LLMs: the productivity boost these things can provide is exhausting.
AI introduced a new rhythm in which workers managed several active threads at once: manually writing code while AI generated an alternative version, running multiple agents in parallel, or reviving long-deferred tasks because AI could “handle them” in the background. They did this, in part, because they felt they had a “partner” that could help them move through their workload.
While this sense of having a “partner” enabled a feeling of momentum, the reality was a continual switching of attention, frequent checking of AI outputs, and a growing number of open tasks. This created cognitive load and a sense of always juggling, even as the work felt productive.
I'm frequently finding myself with work on two or three projects running parallel. I can get so much done, but after just an hour or two my mental energy for the day feels almost entirely depleted.
I've had conversations with people recently who are losing sleep because they're finding building yet another feature with "just one more prompt" irresistible.
The HBR piece calls for organizations to build an "AI practice" that structures how AI is used to help avoid burnout and counter effects that "make it harder for organizations to distinguish genuine productivity gains from unsustainable intensity".
I think we've just disrupted decades of existing intuition about sustainable working practices. It's going to take a while and some discipline to find a good new balance.
People on the orange site are laughing at this, assuming it's just an ad and that there's nothing to it. Vulnerability researchers I talk to do not think this is a joke. As an erstwhile vuln researcher myself: do not bet against LLMs on this.
Axios: Anthropic's Claude Opus 4.6 uncovers 500 zero-day flaws in open-source
I think vulnerability research might be THE MOST LLM-amenable software engineering problem. Pattern-driven. Huge corpus of operational public patterns. Closed loops. Forward progress from stimulus/response tooling. Search problems.
Vulnerability research outcomes are in THE MODEL CARDS for frontier labs. Those companies have so much money they're literally distorting the economy. Money buys vuln research outcomes. Why would you think they were faking any of this?
Vouch. Mitchell Hashimoto's new system to help address the deluge of worthless AI-generated PRs faced by open source projects now that the friction involved in contributing has dropped so low.
The idea is simple: Unvouched users can't contribute to your projects. Very bad users can be explicitly "denounced", effectively blocked. Users are vouched or denounced by contributors via GitHub issue or discussion comments or via the CLI.
Integration into GitHub is as simple as adopting the published GitHub actions. Done. Additionally, the system itself is generic to forges and not tied to GitHub in any way.
Who and how someone is vouched or denounced is up to the project. I'm not the value police for the world. Decide for yourself what works for your project and your community.
Claude: Speed up responses with fast mode.
New "research preview" from Anthropic today: you can now access a faster version of their frontier model Claude Opus 4.6 by typing /fast in Claude Code... but at a cost that's 6x the normal price.
Opus is usually $5/million input and $25/million output. The new fast mode is $30/million input and $150/million output!
There's a 50% discount until the end of February 16th, so only a 3x multiple (!) before then.
How much faster is it? The linked documentation doesn't say, but on Twitter Claude say:
Our teams have been building with a 2.5x-faster version of Claude Opus 4.6.
We’re now making it available as an early experiment via Claude Code and our API.
Claude Opus 4.5 had a context limit of 200,000 tokens. 4.6 has an option to increase that to 1,000,000 at 2x the input price ($10/m) and 1.5x the output price ($37.50/m) once your input exceeds 200,000 tokens. These multiples hold for fast mode too, so after Feb 16th you'll be able to pay a hefty $60/m input and $225/m output for Anthropic's fastest best model.
I am having more fun programming than I ever have, because so many more of the programs I wish I could find the time to write actually exist. I wish I could share this joy with the people who are fearful about the changes agents are bringing. The fear itself I understand, I have fear more broadly about what the end-game is for intelligence on tap in our society. But in the limited domain of writing computer programs these tools have brought so much exploration and joy to my work.
— David Crawshaw, Eight more months of agents
How StrongDM’s AI team build serious software without even looking at the code
Last week I hinted at a demo I had seen from a team implementing what Dan Shapiro called the Dark Factory level of AI adoption, where no human even looks at the code the coding agents are producing. That team was part of StrongDM, and they’ve just shared the first public description of how they are working in Software Factories and the Agentic Moment:
[... 1,664 words]I don't know why this week became the tipping point, but nearly every software engineer I've talked to is experiencing some degree of mental health crisis.
[...] Many people assuming I meant job loss anxiety but that's just one presentation. I'm seeing near-manic episodes triggered by watching software shift from scarce to abundant. Compulsive behaviors around agent usage. Dissociative awe at the temporal compression of change. It's not fear necessarily just the cognitive overload from living in an inflection point.
— Tom Dale